लेखक द्वारा छवि
स्किकिट-लर्न पाइपलाइनों का उपयोग आपके प्रीप्रोसेसिंग और मॉडलिंग चरणों को सरल बना सकता है, कोड जटिलता को कम कर सकता है, डेटा प्रीप्रोसेसिंग में स्थिरता सुनिश्चित कर सकता है, हाइपरपैरामीटर ट्यूनिंग में मदद कर सकता है, और आपके वर्कफ़्लो को अधिक व्यवस्थित और बनाए रखने में आसान बना सकता है। एकाधिक परिवर्तनों और अंतिम मॉडल को एक इकाई में एकीकृत करके, पाइपलाइन प्रतिलिपि प्रस्तुत करने योग्यता को बढ़ाती हैं और हर चीज़ को अधिक कुशल बनाती हैं।
इस ट्यूटोरियल में, हम इसके साथ काम करेंगे बैंक मंथन रैंडम फ़ॉरेस्ट क्लासिफ़ायर को प्रशिक्षित करने के लिए कागल से डेटासेट। हम स्किकिट-लर्न पाइपलाइनों और कॉलमट्रांसफॉर्मर्स का उपयोग करके अधिक कुशल विधि के साथ डेटा प्रीप्रोसेसिंग और मॉडल प्रशिक्षण के पारंपरिक दृष्टिकोण की तुलना करेंगे।
डेटा प्रोसेसिंग पाइपलाइन में, हम सीखेंगे कि श्रेणीबद्ध और संख्यात्मक दोनों कॉलमों को अलग-अलग कैसे बदला जाए। हम कोड की पारंपरिक शैली से शुरुआत करेंगे और फिर समान प्रसंस्करण करने का बेहतर तरीका दिखाएंगे।
ज़िप फ़ाइल से डेटा निकालने के बाद, इंडेक्स कॉलम के रूप में "id" के साथ `train.csv` फ़ाइल लोड करें। अनावश्यक कॉलम हटाएं और डेटासेट में फेरबदल करें।
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
bank_df.head()
हमारे पास श्रेणीबद्ध, पूर्णांक और फ्लोट कॉलम हैं। डेटासेट काफ़ी साफ़ दिखता है.

सरल स्किकिट-लर्न कोड
एक डेटा वैज्ञानिक के रूप में, मैंने यह कोड कई बार लिखा है। हमारा उद्देश्य श्रेणीबद्ध और संख्यात्मक दोनों विशेषताओं के लिए लुप्त मानों को भरना है। इसे प्राप्त करने के लिए, हम प्रत्येक प्रकार की सुविधा के लिए अलग-अलग रणनीतियों के साथ `सिंपलइम्प्यूटर` का उपयोग करेंगे।
लुप्त मान भरने के बाद, हम श्रेणीगत विशेषताओं को पूर्णांकों में बदल देंगे और संख्यात्मक सुविधाओं पर न्यूनतम-अधिकतम स्केलिंग लागू करेंगे।
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()
परिणामस्वरूप, हमें एक ऐसा डेटासेट मिला जो साफ़ है और केवल पूर्णांक या फ़्लोट मानों के साथ रूपांतरित है।
स्किकिट-लर्न पाइपलाइन कोड
आइए `पाइपलाइन` और `कॉलमट्रांसफॉर्मर` का उपयोग करके उपरोक्त कोड को कनवर्ट करें। प्रीप्रोसेसिंग तकनीक लागू करने के बजाय, हम दो पाइपलाइन बनाएंगे। एक संख्यात्मक स्तंभों के लिए है, और एक श्रेणीबद्ध स्तंभों के लिए है।
- संख्यात्मक पाइपलाइन में, हमने "माध्य" रणनीति के साथ एक सरल प्रतिरूपण का उपयोग किया है और सामान्यीकरण के लिए न्यूनतम-अधिकतम स्केलर लागू किया है।
- श्रेणीबद्ध पाइपलाइन में, हमने श्रेणियों को संख्यात्मक मानों में बदलने के लिए "most_frequent" रणनीति और मूल एनकोडर के साथ सरल इंप्यूटर का उपयोग किया।
हमने कॉलमट्रांसफॉर्मर का उपयोग करके दो पाइपलाइनों को संयोजित किया और प्रत्येक को कॉलम इंडेक्स प्रदान किया। यह आपको इन पाइपलाइनों को कुछ स्तंभों पर लागू करने में मदद करेगा। उदाहरण के लिए, एक श्रेणीगत ट्रांसफार्मर पाइपलाइन केवल कॉलम 1 और 2 पर लागू की जाएगी।
नोट: शेष = "पासथ्रू" का अर्थ है कि जिन स्तंभों पर कार्रवाई नहीं की गई है उन्हें अंत में जोड़ा जाएगा। हमारे मामले में, यह लक्ष्य स्तंभ है.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
परिवर्तन के बाद, परिणामी सरणी में कॉलम ट्रांसफार्मर में पाइपलाइनों के क्रम के आधार पर प्रारंभ में संख्यात्मक परिवर्तन मान और अंत में श्रेणीबद्ध परिवर्तन मान होता है।
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
पाइपलाइन की कल्पना करने के लिए आप ज्यूपिटर नोटबुक में पाइपलाइन ऑब्जेक्ट चला सकते हैं। सुनिश्चित करें कि आपके पास स्किकिट-लर्न का नवीनतम संस्करण है।
preproc_pipe

अपने मॉडल को प्रशिक्षित और मूल्यांकन करने के लिए, हमें अपने डेटासेट को दो उपसमूहों में विभाजित करने की आवश्यकता है: प्रशिक्षण और परीक्षण।
ऐसा करने के लिए, हम पहले आश्रित और स्वतंत्र चर बनाएंगे और उन्हें NumPy सरणियों में परिवर्तित करेंगे। फिर, हम डेटासेट को दो सबसेट में विभाजित करने के लिए `train_test_split` फ़ंक्शन का उपयोग करेंगे।
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)सरल स्किकिट-लर्न कोड
प्रशिक्षण कोड लिखने का पारंपरिक तरीका पहले 'SelectKBest' का उपयोग करके फीचर चयन करना है और फिर हमारे रैंडम फॉरेस्ट क्लासिफायर मॉडल को नई सुविधा प्रदान करना है।
हम पहले प्रशिक्षण सेट का उपयोग करके मॉडल को प्रशिक्षित करेंगे और परीक्षण डेटासेट का उपयोग करके परिणामों का मूल्यांकन करेंगे।
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
हमने काफी अच्छा सटीकता स्कोर हासिल किया।
0.8613035487063481स्किकिट-लर्न पाइपलाइन कोड
आइए दोनों प्रशिक्षण चरणों को एक पाइपलाइन में संयोजित करने के लिए `पाइपलाइन` फ़ंक्शन का उपयोग करें। फिर हम मॉडल को प्रशिक्षण सेट पर फिट कर सकते हैं और परीक्षण सेट पर इसका मूल्यांकन कर सकते हैं।
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
हमने समान परिणाम प्राप्त किए, लेकिन कोड अधिक कुशल और सीधा प्रतीत होता है। प्रशिक्षण पाइपलाइन में नए चरण जोड़ना या हटाना काफी आसान है।
0.8613035487063481
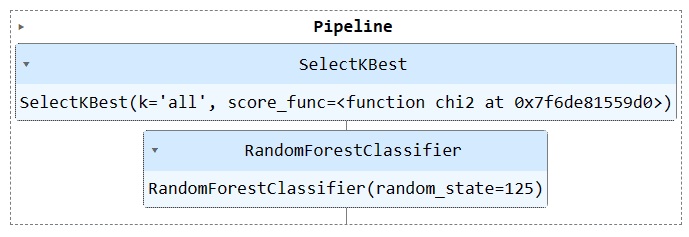
पाइपलाइन को देखने के लिए पाइपलाइन ऑब्जेक्ट चलाएँ।
train_pipe
अब, हम एक और पाइपलाइन बनाकर और दोनों पाइपलाइनों को जोड़कर प्रीप्रोसेसिंग और प्रशिक्षण पाइपलाइन दोनों को जोड़ देंगे।
यहाँ पूरा कोड है:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
आउटपुट:
0.8592837955201874
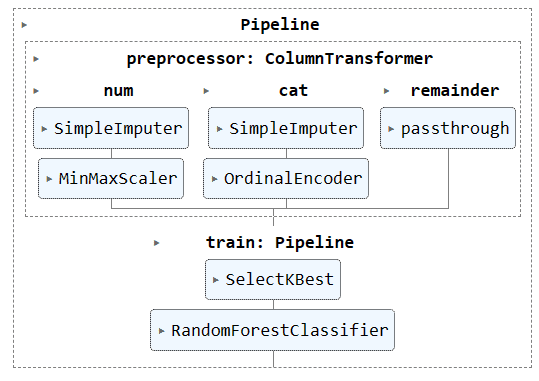
संपूर्ण पाइपलाइन का दृश्यांकन.
complete_pipe

पाइपलाइनों का उपयोग करने का एक प्रमुख लाभ यह है कि आप मॉडल के साथ पाइपलाइन को बचा सकते हैं। अनुमान के दौरान, आपको केवल पाइपलाइन ऑब्जेक्ट को लोड करना होगा, जो कच्चे डेटा को संसाधित करने और आपको सटीक भविष्यवाणियां प्रदान करने के लिए तैयार होगा। आपको ऐप फ़ाइल में प्रोसेसिंग और ट्रांसफ़ॉर्मेशन फ़ंक्शंस को दोबारा लिखने की ज़रूरत नहीं है, क्योंकि यह बॉक्स से बाहर काम करेगा। यह मशीन लर्निंग वर्कफ़्लो को अधिक कुशल बनाता है और समय बचाता है।
आइए सबसे पहले इसका उपयोग करके पाइपलाइन को बचाएं स्कोप्स-डेव/स्कोप्स पुस्तकालय।
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
फिर, सहेजी गई पाइपलाइन को लोड करें और पाइपलाइन को प्रदर्शित करें।
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
जैसा कि हम देख सकते हैं, हमने पाइपलाइन को सफलतापूर्वक लोड कर लिया है।
हमारी लोड की गई पाइपलाइन का मूल्यांकन करने के लिए, हम परीक्षण सेट पर भविष्यवाणियां करेंगे और फिर सटीकता और एफ1 स्कोर की गणना करेंगे।
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
इससे पता चलता है कि हमें अपने F1 स्कोर को बेहतर बनाने के लिए अल्पसंख्यक वर्गों पर ध्यान केंद्रित करने की आवश्यकता है।
Accuracy: 86.0% F1: 0.76
प्रोजेक्ट फ़ाइलें और कोड यहां उपलब्ध है डीपनोट कार्यक्षेत्र. कार्यक्षेत्र में दो नोटबुक हैं: एक स्किकिट-लर्न पाइपलाइन के साथ और एक इसके बिना।
इस ट्यूटोरियल में, हमने सीखा कि कैसे स्किकिट-लर्न पाइपलाइन डेटा ट्रांसफॉर्म और मॉडल के अनुक्रमों को एक साथ जोड़कर मशीन लर्निंग वर्कफ़्लो को सुव्यवस्थित करने में मदद कर सकती है। प्रीप्रोसेसिंग और मॉडल प्रशिक्षण को एक ही पाइपलाइन ऑब्जेक्ट में जोड़कर, हम कोड को सरल बना सकते हैं, लगातार डेटा परिवर्तन सुनिश्चित कर सकते हैं, और अपने वर्कफ़्लो को अधिक व्यवस्थित और प्रतिलिपि प्रस्तुत करने योग्य बना सकते हैं।
आबिद अली अवनी (@1अबिदलियावान) एक प्रमाणित डेटा वैज्ञानिक पेशेवर है जो मशीन लर्निंग मॉडल बनाना पसंद करता है। वर्तमान में, वह सामग्री निर्माण और मशीन लर्निंग और डेटा विज्ञान प्रौद्योगिकियों पर तकनीकी ब्लॉग लिखने पर ध्यान केंद्रित कर रहा है। आबिद के पास प्रौद्योगिकी प्रबंधन में मास्टर डिग्री और दूरसंचार इंजीनियरिंग में स्नातक की डिग्री है। उनका दृष्टिकोण मानसिक बीमारी से जूझ रहे छात्रों के लिए ग्राफ न्यूरल नेटवर्क का उपयोग करके एआई उत्पाद बनाना है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

