परिचय
के बीच में डेटा विज्ञान झूठ के आँकड़े, जो सदियों से अस्तित्व में हैं, फिर भी आज के डिजिटल युग में मौलिक रूप से आवश्यक बने हुए हैं। क्यों? क्योंकि बुनियादी सांख्यिकी अवधारणाएँ इसकी रीढ़ हैं डेटा विश्लेषण, हमें प्रतिदिन उत्पन्न होने वाले विशाल मात्रा में डेटा को समझने में सक्षम बनाता है। यह डेटा के साथ बातचीत करने जैसा है, जहां आंकड़े हमें सही प्रश्न पूछने और डेटा द्वारा बताई गई कहानियों को समझने में मदद करते हैं।
भविष्य के रुझानों की भविष्यवाणी करने और डेटा के आधार पर निर्णय लेने से लेकर परिकल्पनाओं का परीक्षण करने और प्रदर्शन को मापने तक, सांख्यिकी वह उपकरण है जो डेटा-संचालित निर्णयों के पीछे की अंतर्दृष्टि को शक्ति प्रदान करता है। यह कच्चे डेटा और कार्रवाई योग्य अंतर्दृष्टि के बीच का पुल है, जो इसे डेटा विज्ञान का एक अनिवार्य हिस्सा बनाता है।
इस लेख में, मैंने शीर्ष 15 मौलिक सांख्यिकी अवधारणाओं को संकलित किया है जिन्हें प्रत्येक डेटा विज्ञान शुरुआतकर्ता को जानना चाहिए!

विषय - सूची
1. सांख्यिकीय नमूनाकरण और डेटा संग्रह
हम कुछ बुनियादी सांख्यिकी अवधारणाओं को सीखेंगे, लेकिन डेटा के महासागर में गहराई से उतरने से पहले यह समझना आवश्यक है कि हमारा डेटा कहां से आता है और हम इसे कैसे इकट्ठा करते हैं। यहीं पर जनसंख्या, नमूने और विभिन्न नमूनाकरण तकनीकें काम आती हैं।
कल्पना कीजिए कि हम किसी शहर में लोगों की औसत ऊंचाई जानना चाहते हैं। सभी को मापना व्यावहारिक है, इसलिए हम बड़ी आबादी का प्रतिनिधित्व करने वाला एक छोटा समूह (नमूना) लेते हैं। चाल इस बात में निहित है कि हम इस नमूने का चयन कैसे करते हैं। यादृच्छिक, स्तरीकृत या क्लस्टर नमूनाकरण जैसी तकनीकें सुनिश्चित करती हैं कि हमारा नमूना अच्छी तरह से प्रस्तुत किया गया है, पूर्वाग्रह को कम करता है और हमारे निष्कर्षों को अधिक विश्वसनीय बनाता है।
आबादी और नमूनों को समझकर, हम आत्मविश्वास से अपनी अंतर्दृष्टि को नमूने से पूरी आबादी तक बढ़ा सकते हैं, और हर किसी का सर्वेक्षण करने की आवश्यकता के बिना सूचित निर्णय ले सकते हैं।
2. डेटा के प्रकार और माप पैमाने
डेटा विभिन्न स्वादों में आता है, और सही सांख्यिकीय उपकरण और तकनीक चुनने के लिए यह जानना महत्वपूर्ण है कि आप किस प्रकार के डेटा के साथ काम कर रहे हैं।
मात्रात्मक एवं गुणात्मक डेटा
- मात्रात्मक डेटा: इस प्रकार का डेटा संख्याओं के बारे में है। यह मापने योग्य है और इसका उपयोग गणितीय गणनाओं के लिए किया जा सकता है। मात्रात्मक डेटा हमें "कितना" या "कितने" बताता है, जैसे किसी वेबसाइट पर जाने वाले उपयोगकर्ताओं की संख्या या किसी शहर का तापमान। यह सीधा और वस्तुनिष्ठ है, संख्यात्मक मूल्यों के माध्यम से एक स्पष्ट तस्वीर प्रदान करता है।
- गुणात्मक तथ्य: इसके विपरीत, गुणात्मक डेटा विशेषताओं और विवरणों से संबंधित है। यह "किस प्रकार" या "किस श्रेणी" के बारे में है। इसे उस डेटा के रूप में सोचें जो गुणों या विशेषताओं का वर्णन करता है, जैसे कार का रंग या पुस्तक की शैली। यह डेटा व्यक्तिपरक है, माप के बजाय अवलोकन पर आधारित है।
मापन के चार पैमाने
- नियुनतम स्तर: यह माप का सबसे सरल रूप है जिसका उपयोग किसी विशिष्ट क्रम के बिना डेटा को वर्गीकृत करने के लिए किया जाता है। उदाहरणों में भोजन के प्रकार, रक्त समूह या राष्ट्रीयता शामिल हैं। यह बिना किसी मात्रात्मक मूल्य के लेबलिंग के बारे में है।
- क्रमसूचक पैमाना: यहां डेटा को ऑर्डर या रैंक किया जा सकता है, लेकिन मानों के बीच के अंतराल को परिभाषित नहीं किया गया है। संतुष्ट, तटस्थ और असंतुष्ट जैसे विकल्पों के साथ संतुष्टि सर्वेक्षण के बारे में सोचें। यह हमें क्रम बताता है लेकिन रैंकिंग के बीच की दूरी नहीं।
- अंतराल स्केल: अंतराल स्केल डेटा को क्रमबद्ध करता है और प्रविष्टियों के बीच अंतर को मापता है। हालाँकि, कोई वास्तविक शून्य बिंदु नहीं है। एक अच्छा उदाहरण सेल्सियस में तापमान है; 10°C और 20°C के बीच का अंतर 20°C और 30°C के बीच के समान है, लेकिन 0°C का मतलब तापमान की अनुपस्थिति नहीं है।
- अनुपात पैमाना: सबसे जानकारीपूर्ण पैमाने में अंतराल पैमाने के सभी गुण और एक सार्थक शून्य बिंदु होता है, जो परिमाण की सटीक तुलना की अनुमति देता है। उदाहरणों में वजन, ऊंचाई और आय शामिल हैं। यहां, हम कह सकते हैं कि कोई चीज़ किसी चीज़ से दोगुनी है।
3। वर्णनात्मक आँकड़े
Imagine वर्णनात्मक आँकड़े आपके डेटा के साथ आपकी पहली तारीख के रूप में। यह बुनियादी बातों को जानने के बारे में है, व्यापक स्ट्रोक्स जो बताते हैं कि आपके सामने क्या है। वर्णनात्मक सांख्यिकी के दो मुख्य प्रकार हैं: केंद्रीय प्रवृत्ति और परिवर्तनशीलता उपाय।
केंद्रीय प्रवृत्ति के उपाय: ये डेटा के गुरुत्वाकर्षण केंद्र की तरह हैं। वे हमें हमारे डेटा सेट का विशिष्ट या प्रतिनिधि एकल मान देते हैं।
मतलब: औसत की गणना सभी मूल्यों को जोड़कर और मूल्यों की संख्या से विभाजित करके की जाती है। यह सभी समीक्षाओं के आधार पर किसी रेस्तरां की समग्र रेटिंग की तरह है। औसत का गणितीय सूत्र नीचे दिया गया है:

माध्य: मध्य मान जब डेटा को सबसे छोटे से सबसे बड़े तक क्रमित किया जाता है। यदि प्रेक्षणों की संख्या सम है, तो यह दो मध्य संख्याओं का औसत है। इसका उपयोग पुल के मध्य बिंदु को खोजने के लिए किया जाता है।
यदि n सम है, तो माध्यिका दो केंद्रीय संख्याओं का औसत है।
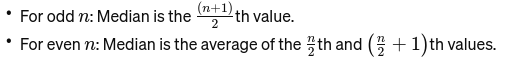
विधि: यह किसी डेटा सेट में सबसे अधिक बार आने वाला मान। इसे किसी रेस्तरां में सबसे लोकप्रिय व्यंजन के रूप में सोचें।
परिवर्तनशीलता के उपाय: जहां केंद्रीय प्रवृत्ति के माप हमें केंद्र में लाते हैं, वहीं परिवर्तनशीलता के माप हमें फैलाव या फैलाव के बारे में बताते हैं।
रेंज: उच्चतम और निम्नतम मूल्यों के बीच का अंतर. यह प्रसार का एक बुनियादी विचार देता है।
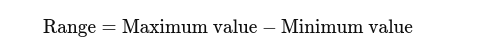
विचरण: यह मापता है कि समुच्चय में प्रत्येक संख्या माध्य से कितनी दूर है और इस प्रकार समुच्चय में प्रत्येक अन्य संख्या से कितनी दूर है। एक नमूने के लिए, इसे इस प्रकार निर्धारित किया गया है:
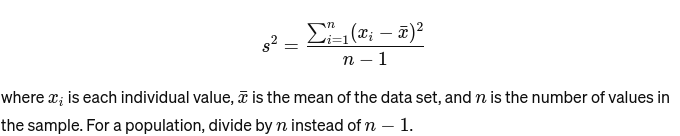
मानक विचलन: विचरण का वर्गमूल माध्य से औसत दूरी का माप प्रदान करता है। यह बेकर के केक के आकार की स्थिरता का आकलन करने जैसा है। इसे इस प्रकार दर्शाया गया है:
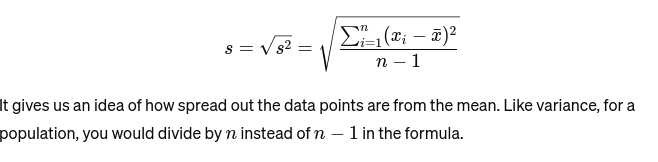
इससे पहले कि हम अगली बुनियादी सांख्यिकी अवधारणा पर जाएँ, यहाँ एक है सांख्यिकीय विश्लेषण के लिए शुरुआती मार्गदर्शिका आप के लिए!
4. डेटा विज़ुअलाइज़ेशन
डेटा विज़ुअलाइज़ेशन डेटा के साथ कहानियां कहने की कला और विज्ञान है। यह हमारे विश्लेषण के जटिल परिणामों को ठोस और समझने योग्य चीज़ में बदल देता है। यह खोजपूर्ण डेटा विश्लेषण के लिए महत्वपूर्ण है, जहां लक्ष्य औपचारिक निष्कर्ष निकाले बिना डेटा से पैटर्न, सहसंबंध और अंतर्दृष्टि को उजागर करना है।
- चार्ट और ग्राफ़: बुनियादी बातों से शुरू करके, बार चार्ट, लाइन ग्राफ़ और पाई चार्ट डेटा में मूलभूत अंतर्दृष्टि प्रदान करते हैं। वे डेटा विज़ुअलाइज़ेशन के एबीसी हैं, जो किसी भी डेटा स्टोरीटेलर के लिए आवश्यक हैं।
हमारे पास नीचे एक बार चार्ट (बाएं) और एक लाइन चार्ट (दाएं) का उदाहरण है।
- उन्नत विज़ुअलाइज़ेशन: जैसे-जैसे हम गहराई में उतरते हैं, हीट मैप, स्कैटर प्लॉट और हिस्टोग्राम अधिक सूक्ष्म विश्लेषण की अनुमति देते हैं। ये उपकरण रुझानों, वितरणों और आउटलेर्स की पहचान करने में मदद करते हैं।
नीचे स्कैटर प्लॉट और हिस्टोग्राम का एक उदाहरण दिया गया है

विज़ुअलाइज़ेशन कच्चे डेटा और मानवीय अनुभूति को जोड़ता है, जिससे हमें जटिल डेटासेट की शीघ्रता से व्याख्या करने और समझने में मदद मिलती है।
5. संभाव्यता मूल बातें
संभावना सांख्यिकी की भाषा का व्याकरण है. यह घटनाओं के घटित होने की संभावना या संभावना के बारे में है। सांख्यिकीय परिणामों की व्याख्या करने और भविष्यवाणियाँ करने के लिए संभाव्यता में अवधारणाओं को समझना आवश्यक है।
- स्वतंत्र और आश्रित घटनाएँ:
- स्वतंत्र घटनाएँ: एक घटना का परिणाम दूसरे के परिणाम को प्रभावित नहीं करता है। सिक्के को उछालने की तरह, एक उछाल पर चित आने से अगली उछाल की संभावना नहीं बदलती।
- आश्रित घटनाएँ: एक घटना का परिणाम दूसरे के परिणाम को प्रभावित करता है। उदाहरण के लिए, यदि आप डेक से एक कार्ड निकालते हैं और उसे नहीं बदलते हैं, तो दूसरा विशिष्ट कार्ड निकालने की संभावना बदल जाती है।
संभाव्यता डेटा के बारे में अनुमान लगाने के लिए आधार प्रदान करती है और सांख्यिकीय महत्व और परिकल्पना परीक्षण को समझने के लिए महत्वपूर्ण है।
6. सामान्य संभाव्यता वितरण
संभाव्यता वितरण सांख्यिकी पारिस्थितिकी तंत्र में विभिन्न प्रजातियों की तरह हैं, प्रत्येक अपने-अपने अनुप्रयोगों के लिए अनुकूलित है।
- सामान्य वितरण: इसके आकार के कारण इसे अक्सर घंटी वक्र कहा जाता है, इस वितरण की विशेषता इसका माध्य और मानक विचलन है। कई सांख्यिकीय परीक्षणों में यह एक आम धारणा है क्योंकि वास्तविक दुनिया में कई चर स्वाभाविक रूप से इसी तरह वितरित होते हैं।
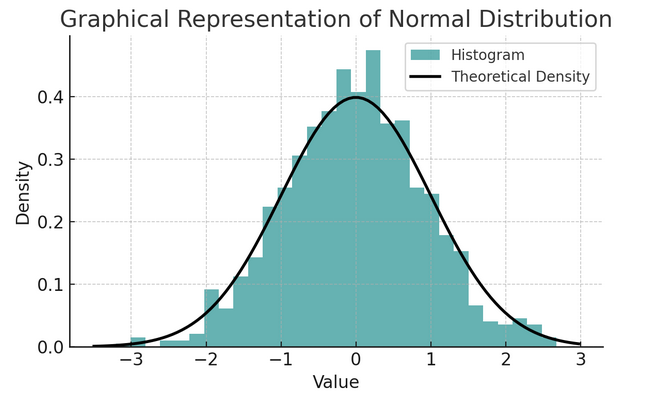
नियमों का एक सेट जिसे अनुभवजन्य नियम या 68-95-99.7 नियम के रूप में जाना जाता है, सामान्य वितरण की विशेषताओं का सारांश देता है, जो बताता है कि डेटा माध्य के आसपास कैसे फैला हुआ है।
68-95-99.7 नियम (अनुभवजन्य नियम)
यह नियम बिल्कुल सामान्य वितरण पर लागू होता है और निम्नलिखित की रूपरेखा तैयार करता है:
- 68% तक डेटा का औसत (μ) के एक मानक विचलन (σ) के भीतर आता है।
- 95% तक डेटा का औसत माध्य के दो मानक विचलन के भीतर आता है।
- लगभग 99.7% तक डेटा का औसत माध्य के तीन मानक विचलन के भीतर आता है।
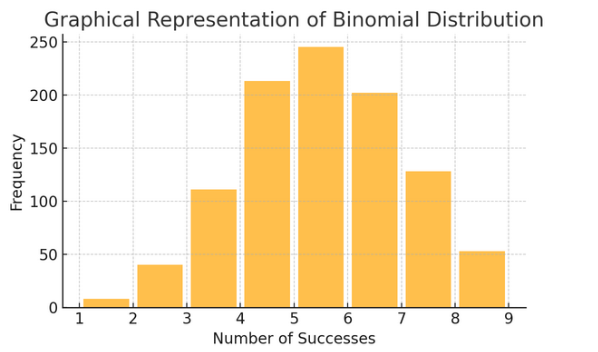
द्विपद वितरण: यह वितरण उन स्थितियों पर लागू होता है जिनमें दो परिणाम (जैसे सफलता या विफलता) कई बार दोहराए जाते हैं। यह सिक्का उछालने या सही/गलत परीक्षा लेने जैसी घटनाओं का मॉडल तैयार करने में मदद करता है।
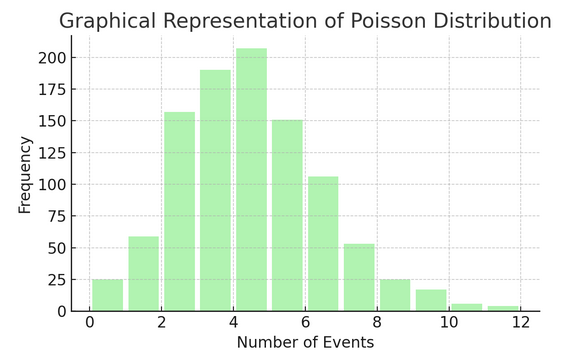
पॉसों वितरण किसी विशिष्ट अंतराल या स्थान पर कुछ घटित होने की संख्या की गणना करता है। यह उन स्थितियों के लिए आदर्श है जहां घटनाएं स्वतंत्र रूप से और लगातार घटित होती हैं, जैसे कि आपको प्राप्त होने वाले दैनिक ईमेल।
प्रत्येक वितरण के सूत्रों और विशेषताओं का अपना सेट होता है, और सही वितरण का चयन आपके डेटा की प्रकृति और आप क्या पता लगाने की कोशिश कर रहे हैं उस पर निर्भर करता है। इन वितरणों को समझने से सांख्यिकीविदों और डेटा वैज्ञानिकों को वास्तविक दुनिया की घटनाओं का मॉडल बनाने और भविष्य की घटनाओं की सटीक भविष्यवाणी करने की अनुमति मिलती है।
7 . परिकल्पना परीक्षण
के बारे में सोचो परिकल्पना परीक्षण सांख्यिकी में जासूसी कार्य के रूप में। यह परीक्षण करने की एक विधि है कि क्या हमारे डेटा के बारे में कोई विशेष सिद्धांत सत्य हो सकता है। यह प्रक्रिया दो विपरीत परिकल्पनाओं से शुरू होती है:
- शून्य परिकल्पना (H0): यह डिफ़ॉल्ट धारणा है, जो किसी प्रभाव या अंतर का सुझाव देती है। यह कह रहा है, "नहीं" यहाँ नया है।
- अल "वैकल्पिक परिकल्पना (H1 या Ha): यह यथास्थिति को चुनौती देता है, प्रभाव या अंतर का प्रस्ताव देता है। यह दावा करता है, "कुछ दिलचस्प चल रहा है।"
उदाहरण: यह परीक्षण करना कि क्या किसी नए आहार कार्यक्रम का पालन न करने की तुलना में वजन कम होता है।
- शून्य परिकल्पना (H0): नए आहार कार्यक्रम से वजन कम नहीं होता है (नए आहार कार्यक्रम का पालन करने वालों और न करने वालों के बीच वजन घटाने में कोई अंतर नहीं होता है)।
- वैकल्पिक परिकल्पना (H1): नए आहार कार्यक्रम से वजन कम होता है (जो लोग इसका पालन करते हैं और जो इसका पालन नहीं करते हैं उनके बीच वजन घटाने में अंतर होता है)।
परिकल्पना परीक्षण में साक्ष्य (हमारे डेटा) के आधार पर इन दोनों के बीच चयन करना शामिल है।
प्रकार I और II त्रुटि और महत्व स्तर:
- टाइप I त्रुटि: ऐसा तब होता है जब हम शून्य परिकल्पना को गलत तरीके से अस्वीकार कर देते हैं। यह एक निर्दोष व्यक्ति को दोषी ठहराता है।
- टाइप II त्रुटि: ऐसा तब होता है जब हम झूठी शून्य परिकल्पना को अस्वीकार करने में विफल हो जाते हैं। यह एक दोषी व्यक्ति को मुक्त कर देता है।
- महत्व स्तर (α): यह है यह तय करने की सीमा कि शून्य परिकल्पना को अस्वीकार करने के लिए कितना सबूत पर्याप्त है। इसे अक्सर 5% (0.05) पर सेट किया जाता है, जो टाइप I त्रुटि के 5% जोखिम को दर्शाता है।
8. आत्मविश्वास अंतराल
विश्वास अंतराल हमें मूल्यों की एक श्रृंखला दें जिसके भीतर हम वैध जनसंख्या पैरामीटर (जैसे माध्य या अनुपात) को एक निश्चित आत्मविश्वास स्तर (आमतौर पर 95%) के साथ गिरने की उम्मीद करते हैं। यह किसी खेल टीम के अंतिम स्कोर की त्रुटि की संभावना के साथ भविष्यवाणी करने जैसा है; हम कह रहे हैं, "हमें 95% विश्वास है कि वास्तविक स्कोर इसी सीमा के भीतर होगा।"
आत्मविश्वास अंतराल का निर्माण और व्याख्या करने से हमें अपने अनुमानों की सटीकता को समझने में मदद मिलती है। अंतराल जितना व्यापक होगा, हमारा अनुमान उतना कम सटीक होगा, और इसके विपरीत।
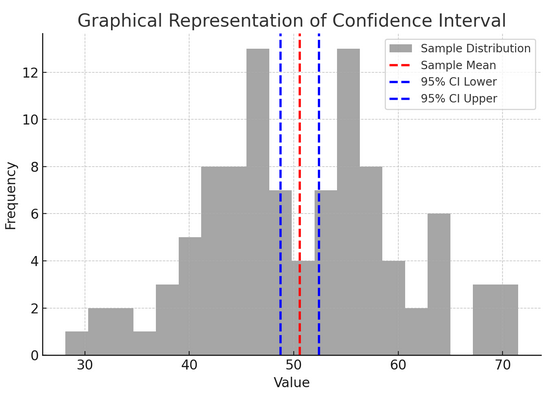
उपरोक्त आंकड़ा नमूना वितरण और नमूना माध्य के आसपास इसके 95% विश्वास अंतराल का उपयोग करते हुए आंकड़ों में आत्मविश्वास अंतराल (सीआई) की अवधारणा को दर्शाता है।
यहां चित्र में महत्वपूर्ण घटकों का विवरण दिया गया है:
- नमूना वितरण (ग्रे हिस्टोग्राम): यह 100 के माध्य और 50 के मानक विचलन के साथ सामान्य वितरण से यादृच्छिक रूप से उत्पन्न 10 डेटा बिंदुओं के वितरण को दर्शाता है। हिस्टोग्राम स्पष्ट रूप से दर्शाता है कि डेटा बिंदु माध्य के चारों ओर कैसे फैले हुए हैं।
- नमूना माध्य (लाल धराशायी रेखा): यह पंक्ति नमूना डेटा के माध्य (औसत) मान को इंगित करती है। यह उस बिंदु अनुमान के रूप में कार्य करता है जिसके चारों ओर हम विश्वास अंतराल का निर्माण करते हैं। इस मामले में, यह सभी नमूना मूल्यों के औसत का प्रतिनिधित्व करता है।
- 95% आत्मविश्वास अंतराल (नीली धराशायी रेखाएँ): ये दो रेखाएँ नमूना माध्य के आसपास 95% विश्वास अंतराल की निचली और ऊपरी सीमा को चिह्नित करती हैं। अंतराल की गणना माध्य (एसईएम) की मानक त्रुटि और वांछित आत्मविश्वास स्तर (1.96% आत्मविश्वास के लिए 95) के अनुरूप जेड-स्कोर का उपयोग करके की जाती है। आत्मविश्वास अंतराल से पता चलता है कि हम 95% आश्वस्त हैं कि जनसंख्या माध्य इस सीमा के भीतर है।
9. सहसंबंध और कारण
सहसंबंध और कारण अक्सर मिश्रित हो जाते हैं, लेकिन वे भिन्न होते हैं:
- सह - संबंध: दो चरों के बीच संबंध या जुड़ाव को दर्शाता है। जब एक बदलता है तो दूसरा भी बदल जाता है। सहसंबंध को -1 से 1 तक के सहसंबंध गुणांक द्वारा मापा जाता है। 1 या -1 के करीब का मान एक मजबूत संबंध को इंगित करता है, जबकि 0 कोई संबंध नहीं दर्शाता है।
- कारण: इसका तात्पर्य यह है कि एक चर में परिवर्तन सीधे दूसरे में परिवर्तन का कारण बनता है। यह सहसंबंध की तुलना में अधिक मजबूत दावा है और इसके लिए कठोर परीक्षण की आवश्यकता है।
सिर्फ इसलिए कि दो चर सहसंबद्ध हैं इसका मतलब यह नहीं है कि एक दूसरे का कारण बनता है। यह "सहसंबंध" को "कारण" के साथ भ्रमित न करने का एक उत्कृष्ट मामला है।
10. सरल रैखिक प्रतिगमन
सरल रेखीय प्रतिगमन प्रेक्षित डेटा में एक रैखिक समीकरण फिट करके दो चरों के बीच संबंध को मॉडल करने का एक तरीका है। एक चर को व्याख्यात्मक चर (स्वतंत्र) माना जाता है, और दूसरे को आश्रित चर माना जाता है।
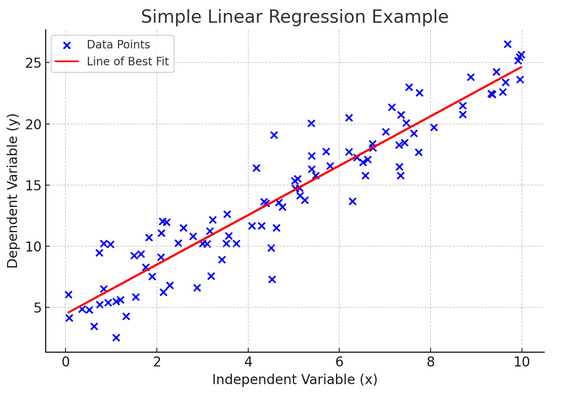
सरल रेखीय प्रतिगमन हमें यह समझने में मदद करता है कि स्वतंत्र चर में परिवर्तन आश्रित चर को कैसे प्रभावित करते हैं। यह भविष्यवाणी के लिए एक शक्तिशाली उपकरण है और कई अन्य जटिल सांख्यिकीय मॉडलों के लिए मूलभूत है। दो चरों के बीच संबंधों का विश्लेषण करके, हम इस बारे में सूचित पूर्वानुमान लगा सकते हैं कि वे कैसे बातचीत करेंगे।
सरल रैखिक प्रतिगमन स्वतंत्र चर (व्याख्यात्मक चर) और आश्रित चर के बीच एक रैखिक संबंध मानता है। यदि इन दो चरों के बीच संबंध रैखिक नहीं है, तो सरल रैखिक प्रतिगमन की धारणाओं का उल्लंघन हो सकता है, जिससे संभावित रूप से गलत भविष्यवाणियां या व्याख्याएं हो सकती हैं। इस प्रकार, सरल रैखिक प्रतिगमन लागू करने से पहले डेटा में एक रैखिक संबंध को सत्यापित करना आवश्यक है।
11. एकाधिक रैखिक प्रतिगमन
एकाधिक रैखिक प्रतिगमन को सरल रैखिक प्रतिगमन के विस्तार के रूप में सोचें। फिर भी, चमकदार कवच (भविष्यवक्ता) में एक शूरवीर के साथ परिणाम की भविष्यवाणी करने की कोशिश करने के बजाय, आपके पास एक पूरी टीम है। यह एक-पर-एक बास्केटबॉल गेम से पूरी टीम के प्रयास में अपग्रेड करने जैसा है, जहां प्रत्येक खिलाड़ी (भविष्यवक्ता) अद्वितीय कौशल लाता है। विचार यह देखना है कि कितने चर मिलकर एक परिणाम को प्रभावित करते हैं।
हालाँकि, एक बड़ी टीम के साथ रिश्तों को प्रबंधित करने की चुनौती आती है, जिसे मल्टीकोलिनैरिटी के रूप में जाना जाता है। ऐसा तब होता है जब भविष्यवक्ता एक-दूसरे के बहुत करीब होते हैं और समान जानकारी साझा करते हैं। कल्पना कीजिए कि दो बास्केटबॉल खिलाड़ी लगातार एक ही शॉट लेने की कोशिश कर रहे हैं; वे एक-दूसरे के रास्ते में आ सकते हैं। प्रतिगमन प्रत्येक भविष्यवक्ता के अद्वितीय योगदान को देखना कठिन बना सकता है, संभावित रूप से हमारी समझ को ख़राब कर सकता है कि कौन से चर महत्वपूर्ण हैं।
12. लॉजिस्टिक रिग्रेशन
जबकि रैखिक प्रतिगमन निरंतर परिणामों (जैसे तापमान या कीमतें) की भविष्यवाणी करता है, रसद प्रतिगमन इसका उपयोग तब किया जाता है जब परिणाम निश्चित हो (जैसे हां/नहीं, जीत/हार)। कल्पना कीजिए कि विभिन्न कारकों के आधार पर यह अनुमान लगाने की कोशिश की जा रही है कि कोई टीम जीतेगी या हारेगी; लॉजिस्टिक रिग्रेशन आपकी पसंदीदा रणनीति है।
यह रैखिक समीकरण को बदल देता है ताकि इसका आउटपुट 0 और 1 के बीच आ जाए, जो किसी विशेष श्रेणी से संबंधित होने की संभावना को दर्शाता है। यह एक जादुई लेंस की तरह है जो निरंतर स्कोर को स्पष्ट "यह या वह" दृश्य में परिवर्तित करता है, जिससे हमें स्पष्ट परिणामों की भविष्यवाणी करने की अनुमति मिलती है।
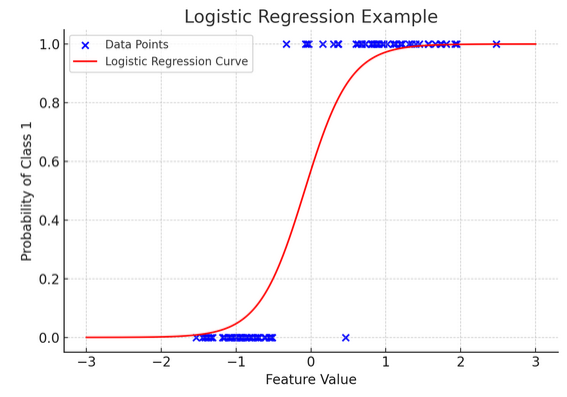
ग्राफिकल प्रतिनिधित्व सिंथेटिक बाइनरी वर्गीकरण डेटासेट पर लागू लॉजिस्टिक रिग्रेशन का एक उदाहरण दिखाता है। नीले बिंदु डेटा बिंदुओं का प्रतिनिधित्व करते हैं, एक्स-अक्ष के साथ उनकी स्थिति फीचर मान को दर्शाती है और वाई-अक्ष श्रेणी (0 या 1) को दर्शाती है। लाल वक्र विभिन्न फीचर मानों के लिए कक्षा 1 (उदाहरण के लिए, "जीत") से संबंधित होने की संभावना की लॉजिस्टिक रिग्रेशन मॉडल की भविष्यवाणी का प्रतिनिधित्व करता है। जैसा कि आप देख सकते हैं, वक्र वर्ग 0 की संभाव्यता से वर्ग 1 तक सुचारू रूप से परिवर्तित होता है, जो एक अंतर्निहित निरंतर सुविधा के आधार पर श्रेणीबद्ध परिणामों की भविष्यवाणी करने की मॉडल की क्षमता को प्रदर्शित करता है।
लॉजिस्टिक रिग्रेशन का सूत्र इस प्रकार दिया गया है:

यह सूत्र रैखिक समीकरण के आउटपुट को 0 और 1 के बीच की संभावना में बदलने के लिए लॉजिस्टिक फ़ंक्शन का उपयोग करता है। यह परिवर्तन हमें स्वतंत्र चर xx के मूल्य के आधार पर आउटपुट को किसी विशेष श्रेणी से संबंधित संभावनाओं के रूप में व्याख्या करने की अनुमति देता है।
13. एनोवा और ची-स्क्वायर परीक्षण
एनोवा (विचरण का विश्लेषण) और ची-स्क्वायर परीक्षण सांख्यिकी की दुनिया में जासूसों की तरह हैं, जो हमें विभिन्न रहस्यों को सुलझाने में मदद करते हैं। मैंt यह हमें यह देखने के लिए कई समूहों के माध्यों की तुलना करने की अनुमति देता है कि क्या कम से कम एक सांख्यिकीय रूप से भिन्न है। इसे यह निर्धारित करने के लिए कुकीज़ के कई बैचों से चखने वाले नमूनों के रूप में सोचें कि क्या किसी बैच का स्वाद काफी अलग है।
दूसरी ओर, ची-स्क्वायर परीक्षण का उपयोग श्रेणीबद्ध डेटा के लिए किया जाता है। इससे हमें यह समझने में मदद मिलती है कि क्या दो श्रेणीगत चरों के बीच कोई महत्वपूर्ण संबंध है। उदाहरण के लिए, क्या किसी व्यक्ति की पसंदीदा संगीत शैली और उनके आयु समूह के बीच कोई संबंध है? ची-स्क्वायर परीक्षण ऐसे प्रश्नों का उत्तर देने में मदद करता है।
14. केंद्रीय सीमा प्रमेय और डेटा विज्ञान में इसका महत्व
RSI केंद्रीय सीमा प्रमेय (सीएलटी) एक मौलिक सांख्यिकीय सिद्धांत है जो लगभग जादुई लगता है। यह हमें बताता है कि यदि आप किसी जनसंख्या से पर्याप्त नमूने लेते हैं और उनके साधनों की गणना करते हैं, तो जनसंख्या के मूल वितरण की परवाह किए बिना, वे साधन एक सामान्य वितरण (घंटी वक्र) बनाएंगे। यह अविश्वसनीय रूप से शक्तिशाली है क्योंकि यह हमें आबादी के बारे में अनुमान लगाने की अनुमति देता है, तब भी जब हम उनके सटीक वितरण को नहीं जानते हैं।
डेटा विज्ञान में, सीएलटी कई तकनीकों को रेखांकित करता है, जो हमें सामान्य रूप से वितरित डेटा के लिए डिज़ाइन किए गए टूल का उपयोग करने में सक्षम बनाता है, तब भी जब हमारा डेटा शुरू में उन मानदंडों को पूरा नहीं करता है। यह सांख्यिकीय विधियों के लिए एक सार्वभौमिक एडाप्टर ढूंढने जैसा है, जिससे कई शक्तिशाली उपकरण अधिक स्थितियों में लागू हो जाते हैं।
15. बायस-वेरिएंस ट्रेडऑफ़
In भविष्य कहनेवाला मॉडलिंग और यंत्र अधिगम, पूर्वाग्रह-विचरण व्यापारऑफ़ एक महत्वपूर्ण अवधारणा है जो दो मुख्य प्रकार की त्रुटियों के बीच तनाव को उजागर करती है जो हमारे मॉडल को गड़बड़ा सकती है। पूर्वाग्रह अत्यधिक सरलीकृत मॉडलों की त्रुटियों को संदर्भित करता है जो अंतर्निहित रुझानों को अच्छी तरह से पकड़ नहीं पाते हैं। एक घुमावदार सड़क के माध्यम से एक सीधी रेखा फिट करने की कोशिश करने की कल्पना करें; आप निशान से चूक जायेंगे. इसके विपरीत, बहुत जटिल मॉडल के वेरिएंस डेटा में शोर को ऐसे पकड़ते हैं जैसे कि यह एक वास्तविक पैटर्न हो - जैसे कि हर मोड़ का पता लगाना और एक ऊबड़-खाबड़ रास्ते पर मुड़ना, यह सोचना कि यह आगे का रास्ता है।
कला कुल त्रुटि को कम करने के लिए इन दोनों को संतुलित करने में निहित है, उस मधुर स्थान को ढूंढना जहां आपका मॉडल बिल्कुल सही है - सटीक पैटर्न को पकड़ने के लिए पर्याप्त जटिल लेकिन यादृच्छिक शोर को अनदेखा करने के लिए पर्याप्त सरल। यह गिटार ट्यून करने जैसा है; यदि यह बहुत तंग या ढीला है तो यह ठीक नहीं लगेगा। पूर्वाग्रह-विचरण व्यापारऑफ़ इन दोनों के बीच सही संतुलन खोजने के बारे में है। परिणामों की सटीक भविष्यवाणी करने में अपना सर्वश्रेष्ठ प्रदर्शन करने के लिए पूर्वाग्रह-विचरण ट्रेडऑफ़ हमारे सांख्यिकीय मॉडल को ट्यून करने का सार है।
निष्कर्ष
सांख्यिकीय नमूने से लेकर पूर्वाग्रह-विचरण व्यापार तक, ये सिद्धांत केवल अकादमिक धारणाएं नहीं हैं बल्कि व्यावहारिक डेटा विश्लेषण के लिए आवश्यक उपकरण हैं। वे महत्वाकांक्षी डेटा वैज्ञानिकों को विशाल डेटा को कार्रवाई योग्य अंतर्दृष्टि में बदलने के कौशल से लैस करते हैं, डिजिटल युग में डेटा-संचालित निर्णय लेने और नवाचार की रीढ़ के रूप में आंकड़ों पर जोर देते हैं।
क्या हम सांख्यिकी की कोई बुनियादी अवधारणा भूल गए हैं? चलो हम नीचे टिप्पणी अनुभाग में पता करते हैं।
हमारे अन्वेषण शुरू से अंत तक सांख्यिकी गाइड डेटा विज्ञान विषय के बारे में जानने के लिए!
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

