परिचय
वन-क्लास सपोर्ट वेक्टर मशीन (एसवीएम) पारंपरिक एसवीएम का एक प्रकार है। इसे विशेष रूप से विसंगतियों का पता लगाने के लिए तैयार किया गया है। इसका प्राथमिक उद्देश्य ऐसे उदाहरणों का पता लगाना है जो विशेष रूप से मानक से भिन्न हैं। पारंपरिक के विपरीत मशीन लर्निंग बाइनरी या मल्टीक्लास वर्गीकरण पर केंद्रित मॉडल, वन-क्लास एसवीएम डेटासेट के भीतर बाहरी या नवीनता का पता लगाने में माहिर हैं। इस लेख में, आप सीखेंगे कि वन-क्लास सपोर्ट वेक्टर मशीन (एसवीएम) पारंपरिक एसवीएम से कैसे भिन्न है। आप यह भी सीखेंगे कि ओसी-एसवीएम कैसे काम करता है और इसे कैसे लागू किया जाए। आप इसके हाइपरपैरामीटर्स के बारे में भी जानेंगे।
सीखने के मकसद
- विसंगतियों को समझने के लिए
- वन-क्लास एसवीएम के बारे में जानें
- समझें कि यह पारंपरिक सपोर्ट वेक्टर मशीन (एसवीएम) से कैसे भिन्न है
- स्केलेरन में ओसी-एसवीएम के हाइपरपैरामीटर
- OC-SVM का उपयोग करके विसंगतियों का पता कैसे लगाएं
- वन-क्लास एसवीएम के मामलों का उपयोग करें
विषय - सूची
विसंगतियों को समझना
विसंगतियाँ ऐसे अवलोकन या उदाहरण हैं जो डेटासेट के सामान्य व्यवहार से महत्वपूर्ण रूप से भिन्न होते हैं। ये विचलन विभिन्न रूपों में प्रकट हो सकते हैं, जैसे आउटलेर, शोर, त्रुटियाँ, या अप्रत्याशित पैटर्न। विसंगतियाँ अक्सर आकर्षक होती हैं क्योंकि वे मूल्यवान अंतर्दृष्टि का प्रतिनिधित्व कर सकती हैं। वे धोखाधड़ी वाले लेनदेन की पहचान करने, उपकरण की खराबी का पता लगाने, या नई घटनाओं को उजागर करने जैसी अंतर्दृष्टि प्रदान कर सकते हैं। बाहरी और नवीनता का पता लगाना विसंगतियों और असामान्य या असामान्य टिप्पणियों की पहचान करता है।
यह भी पढ़ें: विसंगति का पता लगाने पर एक एंड-टू-एंड गाइड
वन क्लास एसवीएम
सपोर्ट वेक्टर मशीनों (एसवीएम) का परिचय
समर्थन वेक्टर मशीनें (एसवीएम) एक लोकप्रिय हैं पर्यवेक्षित शिक्षण एल्गोरिथ्म वर्गीकरण और प्रतिगमन कार्यों के लिए। एसवीएम इष्टतम हाइपरप्लेन ढूंढकर काम करते हैं जो फीचर स्पेस में विभिन्न वर्गों को अलग करते हुए उनके बीच के अंतर को अधिकतम करते हैं। यह हाइपरप्लेन प्रशिक्षण डेटा बिंदुओं के एक सबसेट पर आधारित है जिसे सपोर्ट वैक्टर कहा जाता है।
वन-क्लास एसवीएम बनाम पारंपरिक एसवीएम
- वन-क्लास एसवीएम पारंपरिक एसवीएम एल्गोरिथ्म के एक प्रकार का प्रतिनिधित्व करते हैं जो मुख्य रूप से बाहरी और नवीनता का पता लगाने के कार्यों के लिए नियोजित होता है। पारंपरिक एसवीएम के विपरीत, जो बाइनरी वर्गीकरण कार्यों को संभालते हैं, वन-क्लास एसवीएम विशेष रूप से एक ही वर्ग से डेटा बिंदुओं पर प्रशिक्षित होता है, जिसे लक्ष्य वर्ग के रूप में जाना जाता है। वन-क्लास एसवीएम का लक्ष्य एक सीमा या निर्णय फ़ंक्शन को सीखना है जो लक्ष्य वर्ग को फीचर स्पेस में समाहित करता है, डेटा के सामान्य व्यवहार को प्रभावी ढंग से मॉडलिंग करता है।
- पारंपरिक एसवीएम का लक्ष्य एक निर्णय सीमा ढूंढना है जो विभिन्न वर्गों के बीच मार्जिन को अधिकतम करता है, जिससे नए डेटा बिंदुओं के इष्टतम वर्गीकरण की अनुमति मिलती है। दूसरी ओर, वन-क्लास एसवीएम एक ऐसी सीमा ढूंढना चाहता है जो इस सीमा के बाहर आउटलेर्स या नए उदाहरणों को शामिल करने के जोखिम को कम करते हुए लक्ष्य वर्ग को घेर ले।
- पारंपरिक एसवीएम को कई वर्गों के उदाहरणों के साथ लेबल किए गए डेटा की आवश्यकता होती है, जो उन्हें पर्यवेक्षित वर्गीकरण कार्यों के लिए उपयुक्त बनाता है। इसके विपरीत, वन-क्लास एसवीएम उन परिदृश्यों में एप्लिकेशन की अनुमति देता है जहां केवल लक्ष्य वर्ग से डेटा उपलब्ध है, जो इसे बिना पर्यवेक्षित विसंगति का पता लगाने और नवीनता का पता लगाने के कार्यों के लिए उपयुक्त बनाता है।
अधिक जानें: समर्थन वेक्टर मशीनों का उपयोग करके एक-श्रेणी वर्गीकरण
वे दोनों अपने सॉफ्ट मार्जिन फॉर्मूलेशन और उनके उपयोग के तरीके में भिन्न हैं:
(एसवीएम में सॉफ्ट मार्जिन का उपयोग कुछ हद तक गलत वर्गीकरण की अनुमति देने के लिए किया जाता है)
वन-क्लास एसवीएम का लक्ष्य मैप किए गए डेटा को मूल से अलग करके फीचर स्पेस के भीतर अधिकतम मार्जिन वाले हाइपरप्लेन की खोज करना है। डेटासेट पर Dn = {x1, . . . , xn} xi ∈ X (xi एक विशेषता है) और n आयामों के साथ:
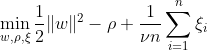
यह समीकरण OC-SVM के लिए प्रारंभिक समस्या सूत्रीकरण का प्रतिनिधित्व करता है, जहां w अलग करने वाला हाइपरप्लेन है, ρ मूल से ऑफसेट है, और ξi सुस्त चर हैं। वे नरम मार्जिन की अनुमति देते हैं लेकिन उल्लंघनों को दंडित करते हैं। एक हाइपरपैरामीटर ν ∈ (0, 1] स्लैक वेरिएबल के प्रभाव को नियंत्रित करता है और इसे आवश्यकता के अनुसार समायोजित किया जाना चाहिए। इसका उद्देश्य मार्जिन से विचलन को दंडित करते हुए w के मानदंड को कम करना है। इसके अलावा, यह डेटा के एक अंश को अनुमति देता है हाशिये के भीतर या हाइपरप्लेन के गलत पक्ष पर गिरना।
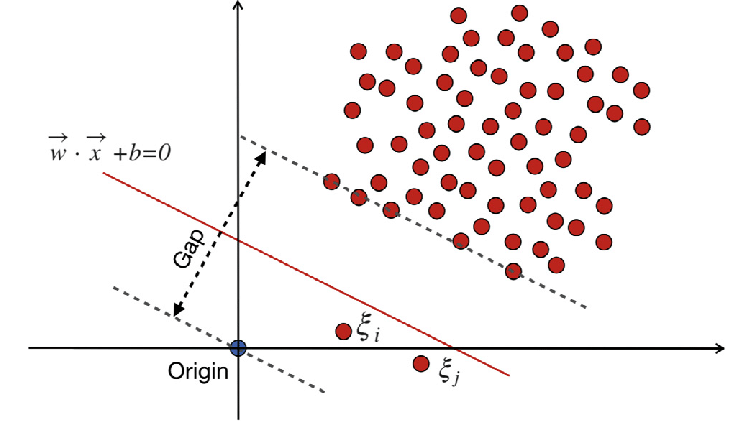
WX + b =0 निर्णय सीमा है, और सुस्त चर विचलन को दंडित करते हैं।
पारंपरिक-समर्थन वेक्टर मशीनें (एसवीएम)
पारंपरिक-समर्थन वेक्टर मशीनें (एसवीएम) गलत वर्गीकरण त्रुटियों के लिए सॉफ्ट मार्जिन फॉर्मूलेशन का उपयोग करती हैं। या वे डेटा बिंदुओं का उपयोग करते हैं जो मार्जिन के भीतर या निर्णय सीमा के गलत पक्ष पर आते हैं।
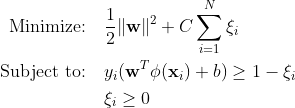
कहा पे:
w भार सदिश है।
बी पूर्वाग्रह शब्द है.
ξi सुस्त चर हैं जो नरम मार्जिन अनुकूलन की अनुमति देते हैं।
सी नियमितीकरण पैरामीटर है जो मार्जिन को अधिकतम करने और वर्गीकरण त्रुटि को कम करने के बीच व्यापार-बंद को नियंत्रित करता है।
ϕ(xi) फीचर मैपिंग फ़ंक्शन का प्रतिनिधित्व करता है।
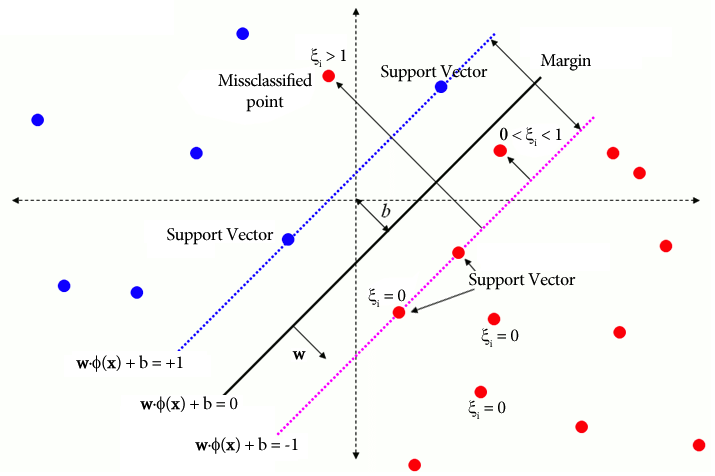
पारंपरिक एसवीएम में, एक पर्यवेक्षित शिक्षण पद्धति जो पृथक्करण के लिए वर्ग लेबल पर निर्भर करती है, एक निश्चित स्तर के गलत वर्गीकरण की अनुमति देने के लिए सुस्त चर को शामिल करती है। एसवीएम का प्राथमिक उद्देश्य निर्णय सीमा WX + b = 0 का उपयोग करके अलग-अलग वर्गों के डेटा बिंदुओं को अलग करना है। स्लैक वेरिएबल्स का मान डेटा बिंदुओं के स्थान के आधार पर भिन्न होता है: यदि डेटा बिंदु मार्जिन से परे स्थित हैं तो वे 0 पर सेट होते हैं। यदि डेटा बिंदु मार्जिन के भीतर रहता है, तो स्लैक वेरिएबल्स 0 और 1 के बीच होते हैं, 1 से अधिक होने पर विपरीत मार्जिन से आगे बढ़ते हैं।
सॉफ्ट मार्जिन फॉर्मूलेशन वाले पारंपरिक एसवीएम और वन-क्लास एसवीएम दोनों का लक्ष्य वजन वेक्टर के मानदंड को कम करना है। फिर भी, वे अपने उद्देश्यों में भिन्न हैं और वे गलत वर्गीकरण त्रुटियों या निर्णय सीमा से विचलन को कैसे संभालते हैं। पारंपरिक एसवीएम ओवरफिटिंग से बचने के लिए वर्गीकरण सटीकता को अनुकूलित करते हैं, जबकि वन-क्लास एसवीएम लक्ष्य वर्ग को मॉडलिंग करने और आउटलेर्स या उपन्यास उदाहरणों के अनुपात को नियंत्रित करने पर ध्यान केंद्रित करते हैं।
यह भी पढ़ें: वेक्टर मशीन का समर्थन करने के लिए AZ गाइड
वन-क्लास एसवीएम में महत्वपूर्ण हाइपरपैरामीटर
- एनयू: यह वन-क्लास एसवीएम में एक महत्वपूर्ण हाइपरपैरामीटर है, जो अनुमत आउटलेर्स के अनुपात को नियंत्रित करता है। यह प्रशिक्षण त्रुटियों के अंश पर ऊपरी सीमा और समर्थन वैक्टर के अंश पर निचली सीमा निर्धारित करता है। यह आम तौर पर 0 और 1 के बीच होता है, जहां कम मान एक सख्त मार्जिन दर्शाते हैं और कम आउटलेर्स को कैप्चर कर सकते हैं, जबकि उच्च मान अधिक अनुमेय होते हैं। डिफ़ॉल्ट मान 0.5 है.
- गिरी: कर्नेल फ़ंक्शन एसवीएम द्वारा उपयोग की जाने वाली निर्णय सीमा के प्रकार को निर्धारित करता है। सामान्य विकल्पों में 'रैखिक', 'आरबीएफ' (गॉसियन रेडियल आधार फ़ंक्शन), 'पॉली' (बहुपद), और 'सिग्मॉइड' शामिल हैं। 'आरबीएफ' कर्नेल का उपयोग अक्सर किया जाता है क्योंकि यह जटिल गैर-रेखीय संबंधों को प्रभावी ढंग से पकड़ सकता है।
- गामा: यह गैर-रेखीय हाइपरप्लेन के लिए एक पैरामीटर है। यह परिभाषित करता है कि एक एकल प्रशिक्षण उदाहरण का कितना प्रभाव है। गामा मान जितना बड़ा होगा, प्रभावित होने वाले अन्य उदाहरण उतने ही करीब होंगे। यह पैरामीटर आरबीएफ कर्नेल के लिए विशिष्ट है और आम तौर पर 'ऑटो' पर सेट होता है, जो डिफ़ॉल्ट रूप से 1 / n_features पर सेट होता है।
- कर्नेल पैरामीटर (डिग्री, coef0): ये पैरामीटर बहुपद और सिग्मॉइड कर्नेल के लिए हैं। 'डिग्री' बहुपद कर्नेल फ़ंक्शन की डिग्री है, और 'coef0' कर्नेल फ़ंक्शन में स्वतंत्र शब्द है। इष्टतम प्रदर्शन प्राप्त करने के लिए इन मापदंडों को ट्यून करना आवश्यक हो सकता है।
- टोल: यही रोकने की कसौटी है. जब द्वंद्व का अंतर सहनशीलता से छोटा होता है तो एल्गोरिदम रुक जाता है। यह एक पैरामीटर है जो रुकने की कसौटी के प्रति सहनशीलता को नियंत्रित करता है।
वन-क्लास एसवीएम का कार्य सिद्धांत
वन-क्लास एसवीएम में कर्नेल फ़ंक्शंस
कर्नेल फ़ंक्शंस एल्गोरिदम को परिवर्तनों की स्पष्ट रूप से गणना किए बिना उच्च-आयामी फ़ीचर स्थानों में संचालित करने की अनुमति देकर वन-क्लास एसवीएम में एक महत्वपूर्ण भूमिका निभाते हैं। वन-क्लास एसवीएम में, पारंपरिक एसवीएम की तरह, इनपुट स्पेस में डेटा बिंदुओं के जोड़े के बीच समानता को मापने के लिए कर्नेल फ़ंक्शन का उपयोग किया जाता है। वन-क्लास एसवीएम में उपयोग किए जाने वाले सामान्य कर्नेल फ़ंक्शंस में गॉसियन (आरबीएफ), बहुपद और सिग्मॉइड कर्नेल शामिल हैं। ये कर्नेल मूल इनपुट स्थान को उच्च-आयामी स्थान में मैप करते हैं, जहां डेटा बिंदु रैखिक रूप से अलग हो जाते हैं या अधिक विशिष्ट पैटर्न प्रदर्शित करते हैं, जिससे सीखने की सुविधा मिलती है। एक उपयुक्त कर्नेल फ़ंक्शन को चुनकर और उसके मापदंडों को ट्यून करके, वन-क्लास एसवीएम डेटा में जटिल संबंधों और गैर-रेखीय संरचनाओं को प्रभावी ढंग से कैप्चर कर सकता है, जिससे विसंगतियों या आउटलेर्स का पता लगाने की क्षमता में सुधार होता है।
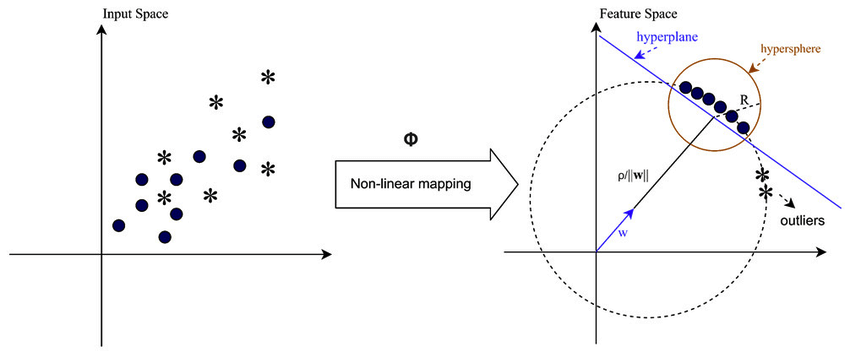
ऐसे मामलों में जहां डेटा रैखिक रूप से अलग करने योग्य नहीं है, जैसे कि जटिल या ओवरलैपिंग पैटर्न से निपटते समय, सपोर्ट वेक्टर मशीनें (एसवीएम) शेष डेटा से आउटलेर्स को प्रभावी ढंग से अलग करने के लिए रेडियल बेसिस फ़ंक्शन (आरबीएफ) कर्नेल को नियोजित कर सकती हैं। आरबीएफ कर्नेल इनपुट डेटा को उच्च-आयामी फीचर स्पेस में बदल देता है जिसे बेहतर तरीके से अलग किया जा सकता है।
मार्जिन और सपोर्ट वेक्टर
वन-क्लास एसवीएम में मार्जिन और सपोर्ट वैक्टर की अवधारणा पारंपरिक एसवीएम के समान है। मार्जिन निर्णय सीमा (हाइपरप्लेन) और प्रत्येक वर्ग के निकटतम डेटा बिंदुओं के बीच के क्षेत्र को संदर्भित करता है। वन-क्लास एसवीएम में, मार्जिन उस क्षेत्र का प्रतिनिधित्व करता है जहां लक्ष्य वर्ग से संबंधित अधिकांश डेटा बिंदु स्थित हैं। वन-क्लास एसवीएम के लिए मार्जिन को अधिकतम करना महत्वपूर्ण है क्योंकि यह नए डेटा बिंदुओं को अच्छी तरह से सामान्यीकृत करने में मदद करता है और मॉडल की मजबूती में सुधार करता है। सपोर्ट वेक्टर वे डेटा बिंदु हैं जो मार्जिन पर या उसके भीतर स्थित होते हैं और निर्णय सीमा को परिभाषित करने में योगदान करते हैं।
वन-क्लास एसवीएम में, सपोर्ट वैक्टर लक्ष्य वर्ग से निर्णय सीमा के निकटतम डेटा बिंदु हैं। ये समर्थन वैक्टर निर्णय सीमा के आकार और अभिविन्यास को निर्धारित करने में महत्वपूर्ण भूमिका निभाते हैं और इस प्रकार, वन-क्लास एसवीएम मॉडल के समग्र प्रदर्शन में महत्वपूर्ण भूमिका निभाते हैं। सपोर्ट वैक्टर की पहचान करके, वन-क्लास एसवीएम फीचर स्पेस में लक्ष्य वर्ग के प्रतिनिधित्व को प्रभावी ढंग से सीखता है और एक निर्णय सीमा का निर्माण करता है जो आउटलेर्स या नए उदाहरणों को शामिल करने के जोखिम को कम करते हुए अधिकांश डेटा बिंदुओं को समाहित करता है।
वन-क्लास एसवीएम का उपयोग करके विसंगतियों का पता कैसे लगाया जा सकता है?
नवीनता पहचान और बाहरी पहचान तकनीकों दोनों के माध्यम से वन-क्लास एसवीएम (सपोर्ट वेक्टर मशीन) का उपयोग करके विसंगतियों का पता लगाना:
बाहरी पहचान
इसमें प्रशिक्षण डेटा में उन टिप्पणियों की पहचान करना शामिल है जो बाकी हिस्सों से काफी भिन्न हैं, जिन्हें अक्सर आउटलेयर कहा जाता है। के लिए अनुमानक बाहरी पहचान इन विचलित टिप्पणियों की परवाह किए बिना, उन क्षेत्रों को फिट करने का लक्ष्य रखें जहां प्रशिक्षण डेटा सबसे अधिक केंद्रित है।
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
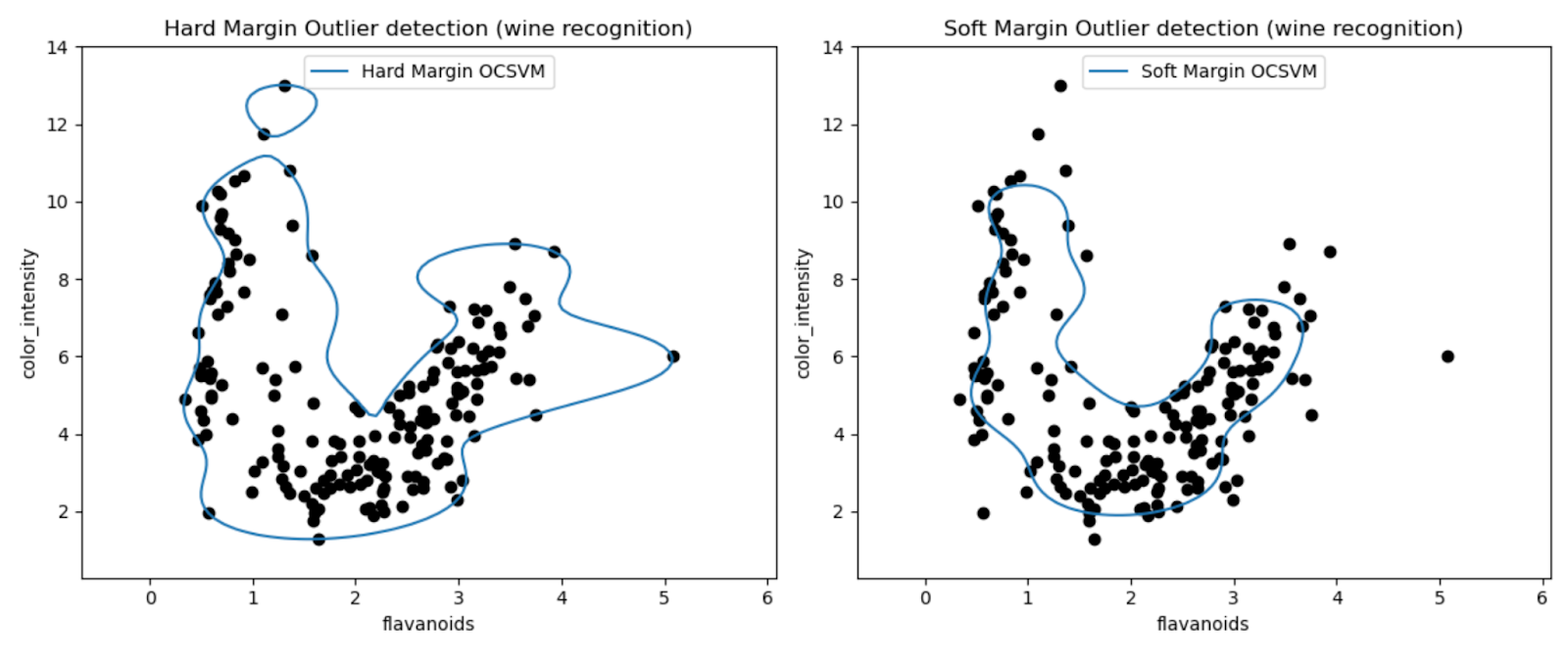
प्लॉट हमें वाइन डेटासेट में आउटलेर्स का पता लगाने में वन-क्लास एसवीएम मॉडल के प्रदर्शन का दृश्य निरीक्षण करने की अनुमति देते हैं।
हार्ड मार्जिन और सॉफ्ट मार्जिन वन-क्लास एसवीएम मॉडल के परिणामों की तुलना करके, हम देख सकते हैं कि मार्जिन सेटिंग (एनयू पैरामीटर) का विकल्प बाहरी पहचान को कैसे प्रभावित करता है।
बहुत छोटे एनयू मान (0.01) के साथ हार्ड मार्जिन मॉडल के परिणामस्वरूप अधिक रूढ़िवादी निर्णय सीमा होने की संभावना है। यह अधिकांश डेटा बिंदुओं को कसकर लपेटता है और संभावित रूप से कम बिंदुओं को आउटलेयर के रूप में वर्गीकृत करता है।
इसके विपरीत, बड़े एनयू मान (0.35) के साथ सॉफ्ट मार्जिन मॉडल के परिणामस्वरूप अधिक लचीली निर्णय सीमा होने की संभावना है। इस प्रकार व्यापक मार्जिन की अनुमति मिलती है और संभावित रूप से अधिक आउटलेर्स पर कब्जा होता है।
नवीनता का पता लगाना
दूसरी ओर, हम इसे तब लागू करते हैं जब प्रशिक्षण डेटा आउटलेर्स से मुक्त होता है, और लक्ष्य यह निर्धारित करना है कि क्या नया अवलोकन दुर्लभ है, अर्थात, ज्ञात अवलोकनों से बहुत अलग है। इस नवीनतम अवलोकन को यहाँ नवीनता कहा जाता है।
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- डेटा बिंदुओं के दो समूहों के साथ एक सिंथेटिक डेटासेट तैयार करें। ट्रेन और परीक्षण डेटा के लिए उन्हें दो अलग-अलग केंद्रों के आसपास सामान्य वितरण के साथ उत्पन्न करके ऐसा करें: (2, 2) और (-2, -2)। दोनों आयामों के साथ -4 से 4 तक के वर्ग क्षेत्र के भीतर यादृच्छिक रूप से समान रूप से बीस डेटा बिंदु उत्पन्न करें। ये डेटा बिंदु असामान्य अवलोकनों या आउटलेर्स का प्रतिनिधित्व करते हैं जो ट्रेन और परीक्षण डेटा में देखे गए सामान्य व्यवहार से महत्वपूर्ण रूप से भिन्न होते हैं।
- सीखी गई सीमा वन-क्लास एसवीएम मॉडल द्वारा सीखी गई निर्णय सीमा को संदर्भित करती है। यह सीमा फीचर स्पेस के उन क्षेत्रों को अलग करती है जहां मॉडल डेटा बिंदुओं को आउटलेर्स से सामान्य मानता है।
- आकृति में नीले से सफेद रंग का ग्रेडिएंट विश्वास या निश्चितता की अलग-अलग डिग्री का प्रतिनिधित्व करता है जो वन-क्लास एसवीएम मॉडल फीचर स्पेस में विभिन्न क्षेत्रों को प्रदान करता है, गहरे रंग डेटा बिंदुओं को 'सामान्य' के रूप में वर्गीकृत करने में उच्च आत्मविश्वास का संकेत देते हैं। गहरा नीला मॉडल के निर्णय फ़ंक्शन के अनुसार 'सामान्य' होने के मजबूत संकेत वाले क्षेत्रों को इंगित करता है। जैसे-जैसे समोच्च में रंग हल्का होता जाता है, मॉडल डेटा बिंदुओं को 'सामान्य' के रूप में वर्गीकृत करने के बारे में कम आश्वस्त होता है।
- कथानक स्पष्ट रूप से दर्शाता है कि वन-क्लास एसवीएम मॉडल नियमित और असामान्य अवलोकनों के बीच अंतर कैसे कर सकता है। सीखी गई निर्णय सीमा सामान्य और असामान्य अवलोकनों के क्षेत्रों को अलग करती है। नवीनता का पता लगाने के लिए वन-क्लास एसवीएम किसी दिए गए डेटासेट में असामान्य टिप्पणियों की पहचान करने में अपनी प्रभावशीलता साबित करता है।
nu=0.5 के लिए:
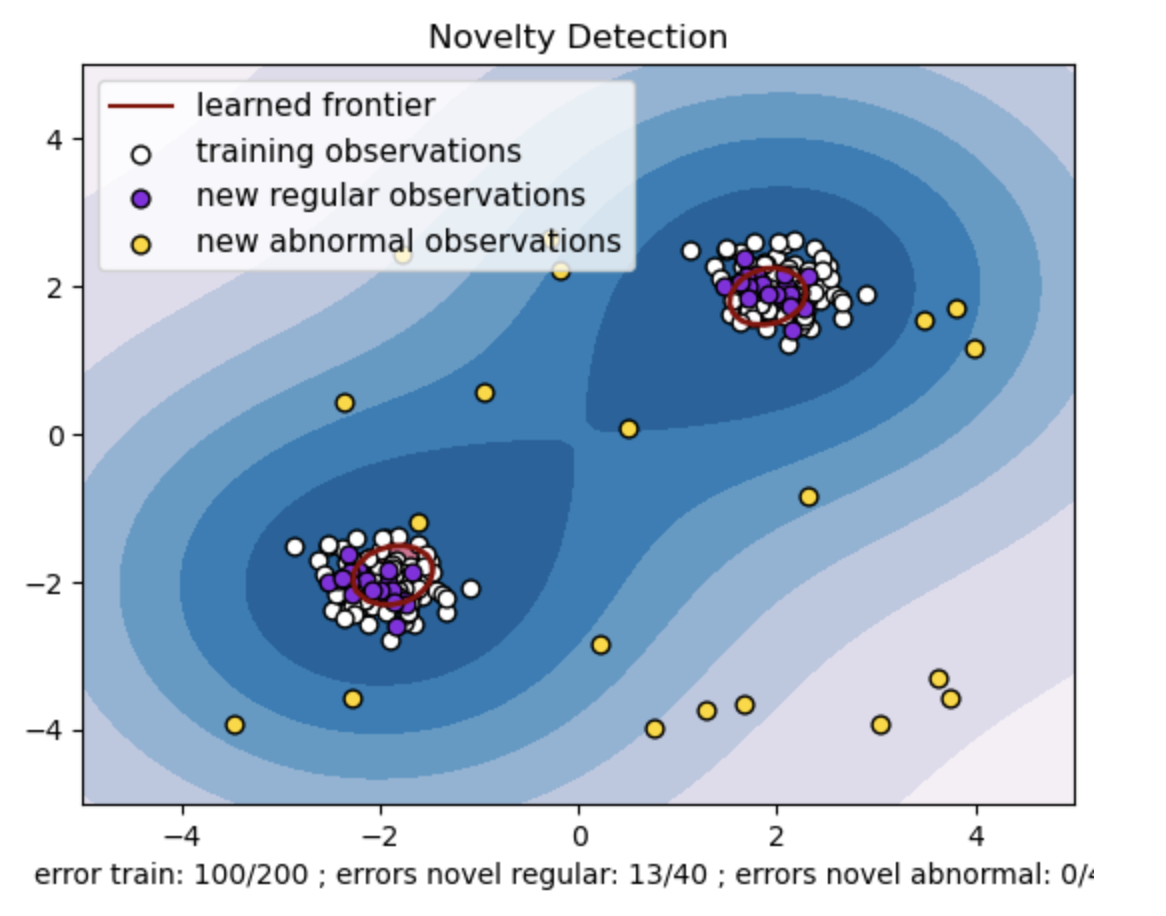
वन-क्लास एसवीएम में "एनयू" मान मॉडल द्वारा सहन किए गए आउटलेर्स के अंश को नियंत्रित करने में महत्वपूर्ण भूमिका निभाता है। यह सीधे मॉडल की विसंगतियों की पहचान करने की क्षमता को प्रभावित करता है और इस प्रकार भविष्यवाणी को प्रभावित करता है। हम देख सकते हैं कि मॉडल 100 प्रशिक्षण बिंदुओं को गलत वर्गीकृत करने की अनुमति दे रहा है। एनयू का कम मूल्य आउटलेर्स के अनुमत अंश पर एक सख्त बाधा का तात्पर्य है। एनयू का चुनाव विसंगतियों का पता लगाने में मॉडल के प्रदर्शन को प्रभावित करता है। इसमें एप्लिकेशन की विशिष्ट आवश्यकताओं और डेटासेट की विशेषताओं के आधार पर सावधानीपूर्वक ट्यूनिंग की भी आवश्यकता होती है।
गामा=0.5 और nu=0.5 के लिए
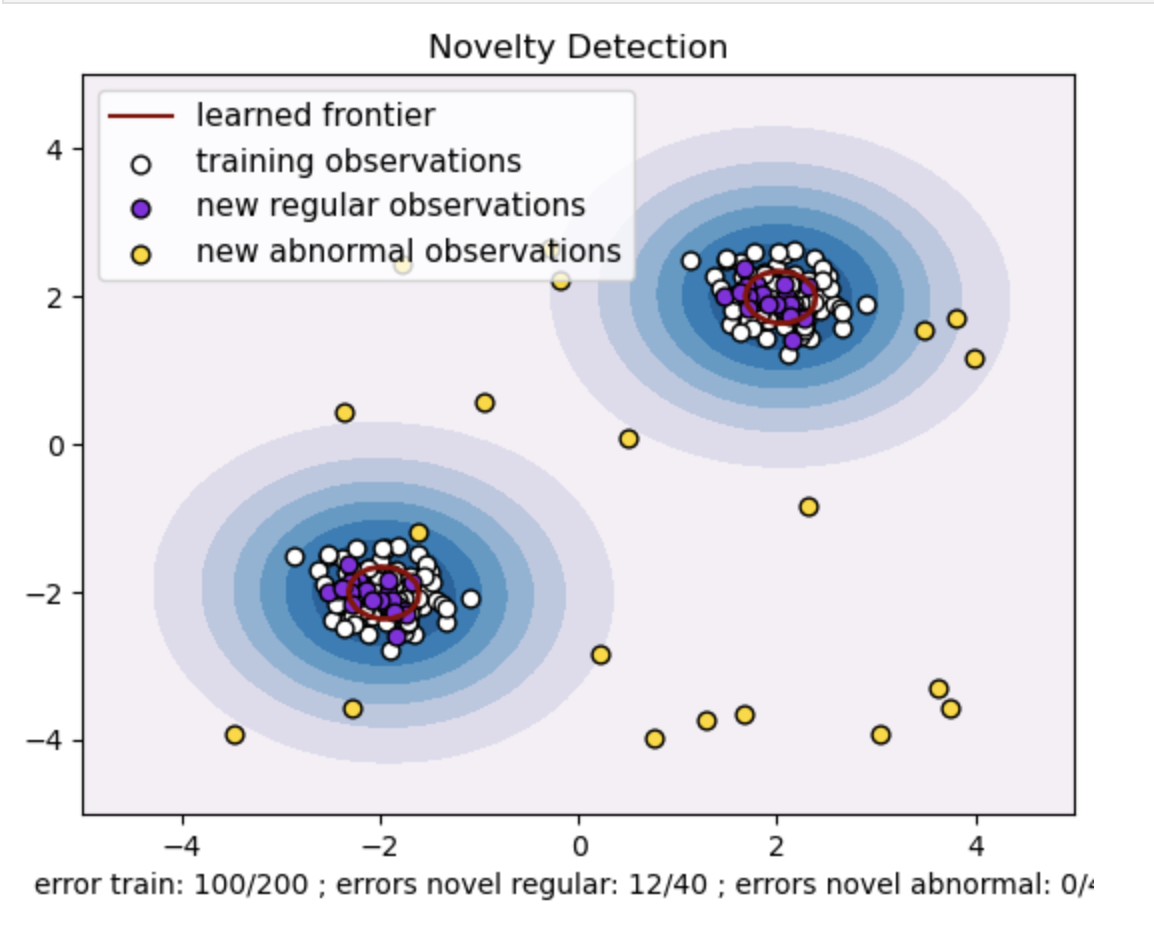
वन-क्लास एसवीएम में, गामा हाइपरपैरामीटर 'आरबीएफ' कर्नेल के लिए कर्नेल गुणांक का प्रतिनिधित्व करता है। यह हाइपरपैरामीटर निर्णय सीमा के आकार को प्रभावित करता है और परिणामस्वरूप, मॉडल के पूर्वानुमानित प्रदर्शन को प्रभावित करता है।
जब गामा उच्च होता है, तो एक एकल प्रशिक्षण उदाहरण इसके प्रभाव को इसके तत्काल आसपास तक सीमित कर देता है। यह अधिक स्थानीयकृत निर्णय सीमा बनाता है। इसलिए, एक ही वर्ग से संबंधित होने के लिए डेटा बिंदुओं को समर्थन वैक्टर के करीब होना चाहिए।
निष्कर्ष
विसंगति का पता लगाने के लिए वन-क्लास एसवीएम का उपयोग, बाह्य और नवीनता का पता लगाने का उपयोग विभिन्न डोमेन में एक मजबूत समाधान प्रदान करता है। यह उन परिदृश्यों में मदद करता है जहां लेबल किया गया विसंगति डेटा दुर्लभ या अनुपलब्ध है। इस प्रकार यह वास्तविक दुनिया के अनुप्रयोगों में विशेष रूप से मूल्यवान है जहां विसंगतियां दुर्लभ हैं और स्पष्ट रूप से परिभाषित करना चुनौतीपूर्ण है। इसके उपयोग के मामले साइबर सुरक्षा और दोष निदान जैसे विविध डोमेन तक फैले हुए हैं, जहां विसंगतियों के परिणाम होते हैं। हालाँकि, जबकि वन-क्लास एसवीएम कई लाभ प्रस्तुत करता है, बेहतर परिणाम प्राप्त करने के लिए डेटा के अनुसार हाइपरपैरामीटर सेट करना आवश्यक है, जो कभी-कभी कठिन हो सकता है।
आम सवाल-जवाब
A. वन-क्लास एसवीएम एक हाइपरप्लेन (या उच्च आयामों में हाइपरस्फेयर) का निर्माण करता है जो सामान्य डेटा बिंदुओं को समाहित करता है। यह हाइपरप्लेन सामान्य डेटा और निर्णय सीमा के बीच अंतर को अधिकतम करने के लिए स्थित है। परीक्षण या अनुमान के दौरान डेटा बिंदुओं को सामान्य (सीमा के अंदर) या विसंगतियों (सीमा के बाहर) के रूप में वर्गीकृत किया जाता है।
A. वन-क्लास एसवीएम फायदेमंद है क्योंकि इसमें प्रशिक्षण के दौरान विसंगतियों के लिए लेबल किए गए डेटा की आवश्यकता नहीं होती है। यह केवल नियमित उदाहरणों वाले डेटासेट से सीख सकता है, जिससे यह उन परिदृश्यों के लिए उपयुक्त हो जाता है जहां विसंगतियां दुर्लभ होती हैं और प्रशिक्षण के लिए लेबल किए गए उदाहरण प्राप्त करना चुनौतीपूर्ण होता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

