बड़े भाषा मॉडल (एलएलएम) को आम तौर पर सार्वजनिक रूप से उपलब्ध बड़े डेटासेट पर प्रशिक्षित किया जाता है जो डोमेन अज्ञेयवादी होते हैं। उदाहरण के लिए, मेटा का लामा मॉडलों को डेटासेट जैसे पर प्रशिक्षित किया जाता है सामान्य क्रॉल, C4, विकिपीडिया, और arXiv. ये डेटासेट विषयों और डोमेन की एक विस्तृत श्रृंखला को शामिल करते हैं। यद्यपि परिणामी मॉडल सामान्य कार्यों, जैसे पाठ निर्माण और इकाई पहचान, के लिए आश्चर्यजनक रूप से अच्छे परिणाम देते हैं, इस बात के प्रमाण हैं कि डोमेन-विशिष्ट डेटासेट के साथ प्रशिक्षित मॉडल एलएलएम प्रदर्शन को और बेहतर बना सकते हैं। उदाहरण के लिए, प्रशिक्षण डेटा का उपयोग किया जाता है ब्लूमबर्ग जीपीटी 51% डोमेन-विशिष्ट दस्तावेज़ हैं, जिनमें वित्तीय समाचार, फाइलिंग और अन्य वित्तीय सामग्री शामिल हैं। वित्त-विशिष्ट कार्यों पर परीक्षण किए जाने पर परिणामी एलएलएम गैर-डोमेन-विशिष्ट डेटासेट पर प्रशिक्षित एलएलएम से बेहतर प्रदर्शन करता है। के लेखक ब्लूमबर्ग जीपीटी निष्कर्ष निकाला कि उनका मॉडल पांच वित्तीय कार्यों में से चार के लिए परीक्षण किए गए अन्य सभी मॉडलों से बेहतर प्रदर्शन करता है। जब ब्लूमबर्ग के आंतरिक वित्तीय कार्यों के लिए परीक्षण किया गया तो मॉडल ने और भी बेहतर प्रदर्शन प्रदान किया - 60 अंक बेहतर (100 में से)। हालाँकि आप व्यापक मूल्यांकन परिणामों के बारे में अधिक जान सकते हैं काग़ज़, निम्नलिखित नमूना से लिया गया ब्लूमबर्ग जीपीटी पेपर आपको वित्तीय डोमेन-विशिष्ट डेटा का उपयोग करके एलएलएम प्रशिक्षण के लाभ की एक झलक दे सकता है। जैसा कि उदाहरण में दिखाया गया है, ब्लूमबर्गजीपीटी मॉडल ने सही उत्तर प्रदान किए जबकि अन्य गैर-डोमेन-विशिष्ट मॉडल संघर्ष करते रहे:
यह पोस्ट विशेष रूप से वित्तीय क्षेत्र के लिए एलएलएम के प्रशिक्षण के लिए एक मार्गदर्शिका प्रदान करती है। हम निम्नलिखित प्रमुख क्षेत्रों को कवर करते हैं:
- डेटा संग्रह और तैयारी - प्रभावी मॉडल प्रशिक्षण के लिए प्रासंगिक वित्तीय डेटा की सोर्सिंग और क्यूरेटिंग पर मार्गदर्शन
- निरंतर पूर्व-प्रशिक्षण बनाम फ़ाइन-ट्यूनिंग - अपने एलएलएम के प्रदर्शन को अनुकूलित करने के लिए प्रत्येक तकनीक का उपयोग कब करें
- कुशल सतत पूर्व प्रशिक्षण - समय और संसाधनों की बचत करते हुए निरंतर पूर्व-प्रशिक्षण प्रक्रिया को सुव्यवस्थित करने की रणनीतियाँ
यह पोस्ट अमेज़ॅन फाइनेंस टेक्नोलॉजी के भीतर लागू विज्ञान अनुसंधान टीम और वैश्विक वित्तीय उद्योग के लिए एडब्ल्यूएस वर्ल्डवाइड विशेषज्ञ टीम की विशेषज्ञता को एक साथ लाती है। कुछ सामग्री कागज पर आधारित है डोमेन विशिष्ट बड़े भाषा मॉडल के निर्माण के लिए कुशल निरंतर पूर्व प्रशिक्षण.
वित्त डेटा एकत्र करना और तैयार करना
डोमेन निरंतर पूर्व-प्रशिक्षण के लिए बड़े पैमाने पर, उच्च-गुणवत्ता, डोमेन-विशिष्ट डेटासेट की आवश्यकता होती है। डोमेन डेटासेट क्यूरेशन के लिए मुख्य चरण निम्नलिखित हैं:
- डेटा स्रोतों की पहचान करें - डोमेन कॉर्पस के संभावित डेटा स्रोतों में ओपन वेब, विकिपीडिया, किताबें, सोशल मीडिया और आंतरिक दस्तावेज़ शामिल हैं।
- डोमेन डेटा फ़िल्टर - क्योंकि अंतिम लक्ष्य डोमेन कॉर्पस को क्यूरेट करना है, आपको लक्ष्य डोमेन के लिए अप्रासंगिक नमूनों को फ़िल्टर करने के लिए अतिरिक्त कदम उठाने की आवश्यकता हो सकती है। इससे निरंतर पूर्व-प्रशिक्षण के लिए बेकार धनराशि कम हो जाती है और प्रशिक्षण लागत कम हो जाती है।
- preprocessing - आप डेटा गुणवत्ता और प्रशिक्षण दक्षता में सुधार के लिए प्रीप्रोसेसिंग चरणों की एक श्रृंखला पर विचार कर सकते हैं। उदाहरण के लिए, कुछ डेटा स्रोतों में उचित संख्या में शोर वाले टोकन हो सकते हैं; डेटा गुणवत्ता में सुधार और प्रशिक्षण लागत को कम करने के लिए डिडुप्लीकेशन को एक उपयोगी कदम माना जाता है।
वित्तीय एलएलएम विकसित करने के लिए, आप दो महत्वपूर्ण डेटा स्रोतों का उपयोग कर सकते हैं: न्यूज़ कॉमनक्रॉल और एसईसी फाइलिंग। एसईसी फाइलिंग अमेरिकी प्रतिभूति और विनिमय आयोग (एसईसी) को प्रस्तुत एक वित्तीय विवरण या अन्य औपचारिक दस्तावेज है। सार्वजनिक रूप से सूचीबद्ध कंपनियों को नियमित रूप से विभिन्न दस्तावेज़ दाखिल करने की आवश्यकता होती है। इससे वर्षों में बड़ी संख्या में दस्तावेज़ तैयार होते हैं। न्यूज़ कॉमनक्रॉल 2016 में कॉमनक्रॉल द्वारा जारी किया गया एक डेटासेट है। इसमें दुनिया भर की समाचार साइटों के समाचार लेख शामिल हैं।
न्यूज कॉमनक्रॉल पर उपलब्ध है अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) में commoncrawl बाल्टी पर crawl-data/CC-NEWS/. आप इसका उपयोग करके फ़ाइलों की सूची प्राप्त कर सकते हैं AWS कमांड लाइन इंटरफ़ेस (एडब्ल्यूएस सीएलआई) और निम्नलिखित आदेश:
In डोमेन विशिष्ट बड़े भाषा मॉडल के निर्माण के लिए कुशल निरंतर पूर्व प्रशिक्षण, लेखक सामान्य समाचारों से वित्तीय समाचार लेखों को फ़िल्टर करने के लिए URL और कीवर्ड-आधारित दृष्टिकोण का उपयोग करते हैं। विशेष रूप से, लेखक महत्वपूर्ण वित्तीय समाचार आउटलेट्स की एक सूची और वित्तीय समाचारों से संबंधित कीवर्ड का एक सेट बनाए रखते हैं। हम किसी लेख को वित्तीय समाचार के रूप में पहचानते हैं यदि वह वित्तीय समाचार आउटलेट से आता है या यूआरएल में कोई कीवर्ड दिखाई देता है। यह सरल लेकिन प्रभावी दृष्टिकोण आपको न केवल वित्तीय समाचार आउटलेट्स बल्कि सामान्य समाचार आउटलेट्स के वित्त अनुभागों से भी वित्तीय समाचारों की पहचान करने में सक्षम बनाता है।
SEC फाइलिंग SEC के EDGAR (इलेक्ट्रॉनिक डेटा संग्रहण, विश्लेषण और पुनर्प्राप्ति) डेटाबेस के माध्यम से ऑनलाइन उपलब्ध है, जो खुली डेटा पहुंच प्रदान करता है। आप सीधे EDGAR से फाइलिंग को स्क्रैप कर सकते हैं, या एपीआई का उपयोग कर सकते हैं अमेज़न SageMaker कोड की कुछ पंक्तियों के साथ, किसी भी समयावधि के लिए और बड़ी संख्या में टिकर्स के लिए (यानी, एसईसी द्वारा निर्दिष्ट पहचानकर्ता)। अधिक जानने के लिए, देखें एसईसी फाइलिंग पुनर्प्राप्ति.
निम्न तालिका दोनों डेटा स्रोतों के मुख्य विवरणों का सारांश प्रस्तुत करती है।
| . | समाचार कॉमनक्रॉल | SEC फाइलिंग |
| व्याप्ति | 2016-2022 | 1993-2022 |
| आकार | 25.8 अरब शब्द | 5.1 अरब शब्द |
डेटा को प्रशिक्षण एल्गोरिदम में फीड करने से पहले लेखक कुछ अतिरिक्त प्रीप्रोसेसिंग चरणों से गुजरते हैं। सबसे पहले, हम देखते हैं कि एसईसी फाइलिंग में तालिकाओं और आंकड़ों को हटाने के कारण शोर वाला पाठ होता है, इसलिए लेखक छोटे वाक्यों को हटा देते हैं जिन्हें तालिका या आंकड़े लेबल माना जाता है। दूसरे, हम नए लेखों और फाइलिंग को डीडुप्लिकेट करने के लिए एक स्थानीयता संवेदनशील हैशिंग एल्गोरिदम लागू करते हैं। एसईसी फाइलिंग के लिए, हम दस्तावेज़ स्तर के बजाय अनुभाग स्तर पर डिडुप्लिकेट करते हैं। अंत में, हम दस्तावेज़ों को एक लंबी स्ट्रिंग में जोड़ते हैं, इसे टोकनाइज़ करते हैं, और टोकनाइज़ेशन को प्रशिक्षित किए जाने वाले मॉडल द्वारा समर्थित अधिकतम इनपुट लंबाई के टुकड़ों में विभाजित करते हैं। इससे निरंतर पूर्व-प्रशिक्षण के थ्रूपुट में सुधार होता है और प्रशिक्षण लागत कम हो जाती है।
निरंतर पूर्व-प्रशिक्षण बनाम फ़ाइन-ट्यूनिंग
अधिकांश उपलब्ध एलएलएम सामान्य प्रयोजन के हैं और उनमें डोमेन-विशिष्ट क्षमताओं का अभाव है। डोमेन एलएलएम ने चिकित्सा, वित्त या वैज्ञानिक क्षेत्रों में काफी प्रदर्शन दिखाया है। एलएलएम के लिए डोमेन-विशिष्ट ज्ञान प्राप्त करने के लिए, चार विधियाँ हैं: स्क्रैच से प्रशिक्षण, निरंतर पूर्व-प्रशिक्षण, डोमेन कार्यों पर अनुदेश फाइन-ट्यूनिंग, और रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी)।
पारंपरिक मॉडल में, आमतौर पर किसी डोमेन के लिए कार्य-विशिष्ट मॉडल बनाने के लिए फ़ाइन-ट्यूनिंग का उपयोग किया जाता है। इसका अर्थ है इकाई निष्कर्षण, आशय वर्गीकरण, भावना विश्लेषण, या प्रश्न उत्तर जैसे कई कार्यों के लिए कई मॉडल बनाए रखना। एलएलएम के आगमन के साथ, संदर्भ में सीखने या संकेत देने जैसी तकनीकों का उपयोग करके अलग-अलग मॉडल बनाए रखने की आवश्यकता अप्रचलित हो गई है। यह संबंधित लेकिन विशिष्ट कार्यों के लिए मॉडलों के ढेर को बनाए रखने के लिए आवश्यक प्रयास को बचाता है।
सहज रूप से, आप डोमेन-विशिष्ट डेटा के साथ एलएलएम को शुरू से ही प्रशिक्षित कर सकते हैं। हालाँकि डोमेन एलएलएम बनाने का अधिकांश काम शुरू से ही प्रशिक्षण पर केंद्रित है, लेकिन यह बेहद महंगा है। उदाहरण के लिए, GPT-4 मॉडल की लागत $ 100 लाख से अधिक प्रशिक्षित करना। इन मॉडलों को खुले डोमेन डेटा और डोमेन डेटा के मिश्रण पर प्रशिक्षित किया जाता है। निरंतर पूर्व-प्रशिक्षण मॉडलों को पूर्व-प्रशिक्षण की लागत के बिना डोमेन-विशिष्ट ज्ञान प्राप्त करने में मदद कर सकता है क्योंकि आप केवल डोमेन डेटा पर मौजूदा ओपन डोमेन एलएलएम को पूर्व-प्रशिक्षित करते हैं।
किसी कार्य पर निर्देश फाइन-ट्यूनिंग के साथ, आप मॉडल को डोमेन ज्ञान प्राप्त नहीं करा सकते क्योंकि एलएलएम केवल निर्देश फाइन-ट्यूनिंग डेटासेट में निहित डोमेन जानकारी प्राप्त करता है। जब तक निर्देश फाइन-ट्यूनिंग के लिए बहुत बड़े डेटासेट का उपयोग नहीं किया जाता है, तब तक यह डोमेन ज्ञान प्राप्त करने के लिए पर्याप्त नहीं है। उच्च-गुणवत्ता वाले अनुदेश डेटासेट की सोर्सिंग आमतौर पर चुनौतीपूर्ण होती है और यही एलएलएम को पहले स्थान पर उपयोग करने का कारण है। इसके अलावा, एक कार्य पर अनुदेश को ठीक-ठाक करने से अन्य कार्यों पर प्रदर्शन प्रभावित हो सकता है (जैसा कि इसमें देखा गया है)। इस पत्र). हालाँकि, निर्देश फाइन-ट्यूनिंग पूर्व-प्रशिक्षण विकल्पों की तुलना में अधिक लागत प्रभावी है।
निम्नलिखित आंकड़ा पारंपरिक कार्य-विशिष्ट फ़ाइन-ट्यूनिंग की तुलना करता है। बनाम एलएलएम के साथ संदर्भ में सीखने का प्रतिमान।
 किसी डोमेन पर आधारित प्रतिक्रियाएं उत्पन्न करने के लिए एलएलएम को निर्देशित करने का आरएजी सबसे प्रभावी तरीका है। यद्यपि यह सहायक जानकारी के रूप में डोमेन से तथ्य प्रदान करके प्रतिक्रियाएं उत्पन्न करने के लिए एक मॉडल का मार्गदर्शन कर सकता है, लेकिन यह डोमेन-विशिष्ट भाषा प्राप्त नहीं करता है क्योंकि एलएलएम अभी भी प्रतिक्रियाएं उत्पन्न करने के लिए गैर-डोमेन भाषा शैली पर निर्भर है।
किसी डोमेन पर आधारित प्रतिक्रियाएं उत्पन्न करने के लिए एलएलएम को निर्देशित करने का आरएजी सबसे प्रभावी तरीका है। यद्यपि यह सहायक जानकारी के रूप में डोमेन से तथ्य प्रदान करके प्रतिक्रियाएं उत्पन्न करने के लिए एक मॉडल का मार्गदर्शन कर सकता है, लेकिन यह डोमेन-विशिष्ट भाषा प्राप्त नहीं करता है क्योंकि एलएलएम अभी भी प्रतिक्रियाएं उत्पन्न करने के लिए गैर-डोमेन भाषा शैली पर निर्भर है।
डोमेन-विशिष्ट ज्ञान और शैली प्राप्त करने के लिए एक मजबूत विकल्प होने के साथ-साथ लागत के संदर्भ में निरंतर पूर्व-प्रशिक्षण पूर्व-प्रशिक्षण और अनुदेश फाइन-ट्यूनिंग के बीच का एक मध्य मार्ग है। यह एक सामान्य मॉडल प्रदान कर सकता है जिस पर सीमित निर्देश डेटा पर आगे के निर्देश को ठीक किया जा सकता है। निरंतर पूर्व-प्रशिक्षण विशेष डोमेन के लिए एक लागत प्रभावी रणनीति हो सकती है जहां डाउनस्ट्रीम कार्यों का सेट बड़ा या अज्ञात है और लेबल निर्देश ट्यूनिंग डेटा सीमित है। अन्य परिदृश्यों में, निर्देश फ़ाइन-ट्यूनिंग या RAG अधिक उपयुक्त हो सकता है।
फाइन-ट्यूनिंग, आरएजी और मॉडल प्रशिक्षण के बारे में अधिक जानने के लिए देखें फाउंडेशन मॉडल को फाइन-ट्यून करें, पुनर्प्राप्ति संवर्धित पीढ़ी (आरएजी), तथा Amazon SageMaker के साथ एक मॉडल को प्रशिक्षित करें, क्रमश। इस पद के लिए, हम कुशल निरंतर पूर्व-प्रशिक्षण पर ध्यान केंद्रित करते हैं।
कुशल निरंतर पूर्व-प्रशिक्षण की पद्धति
सतत पूर्व-प्रशिक्षण में निम्नलिखित पद्धति शामिल है:
- डोमेन-अनुकूली सतत पूर्व-प्रशिक्षण (डीएसीपी) - कागज़ पर डोमेन विशिष्ट बड़े भाषा मॉडल के निर्माण के लिए कुशल निरंतर पूर्व प्रशिक्षण, लेखक वित्तीय क्षेत्र में इसे अनुकूलित करने के लिए वित्तीय कोष पर पाइथिया भाषा मॉडल सूट को लगातार पूर्व-प्रशिक्षित करते हैं। इसका उद्देश्य संपूर्ण वित्तीय डोमेन से डेटा को एक ओपन-सोर्स मॉडल में फीड करके वित्तीय एलएलएम बनाना है। क्योंकि प्रशिक्षण कोष में डोमेन के सभी क्यूरेटेड डेटासेट शामिल हैं, परिणामी मॉडल को वित्त-विशिष्ट ज्ञान प्राप्त करना चाहिए, जिससे विभिन्न वित्तीय कार्यों के लिए एक बहुमुखी मॉडल बन सके। इसका परिणाम फिनपाइथिया मॉडल में होता है।
- कार्य-अनुकूली सतत पूर्व-प्रशिक्षण (टीएसीपी) - लेखक मॉडलों को विशिष्ट कार्यों के लिए तैयार करने के लिए उन्हें लेबल किए गए और बिना लेबल वाले कार्य डेटा पर पूर्व-प्रशिक्षित करते हैं। कुछ परिस्थितियों में, डेवलपर्स डोमेन-जेनेरिक मॉडल के बजाय इन-डोमेन कार्यों के समूह पर बेहतर प्रदर्शन देने वाले मॉडल को प्राथमिकता दे सकते हैं। टीएसीपी को निरंतर पूर्व-प्रशिक्षण के रूप में डिज़ाइन किया गया है, जिसका लक्ष्य लेबल किए गए डेटा की आवश्यकता के बिना, लक्षित कार्यों पर प्रदर्शन को बढ़ाना है। विशेष रूप से, लेखक कार्य टोकन (लेबल के बिना) पर खुले स्रोत वाले मॉडल को लगातार पूर्व-प्रशिक्षित करते हैं। प्रशिक्षण के लिए बिना लेबल वाले कार्य डेटा के एकमात्र उपयोग के कारण, टीएसीपी की प्राथमिक सीमा फाउंडेशन एलएलएम के बजाय कार्य-विशिष्ट एलएलएम के निर्माण में निहित है। हालाँकि डीएसीपी बहुत बड़े कोष का उपयोग करता है, लेकिन यह बेहद महंगा है। इन सीमाओं को संतुलित करने के लिए, लेखक दो दृष्टिकोण प्रस्तावित करते हैं जिनका लक्ष्य लक्ष्य कार्यों पर बेहतर प्रदर्शन को संरक्षित करते हुए डोमेन-विशिष्ट फाउंडेशन एलएलएम का निर्माण करना है:
- कुशल कार्य-समान डीएसीपी (ईटीएस-डीएसीपी) - लेखक वित्तीय कोष का एक सबसेट चुनने का प्रस्ताव करते हैं जो एम्बेडिंग समानता का उपयोग करके कार्य डेटा के समान है। इस उपसमुच्चय का उपयोग निरंतर पूर्व-प्रशिक्षण को और अधिक कुशल बनाने के लिए किया जाता है। विशेष रूप से, लेखक वित्तीय कोष से निकाले गए एक छोटे कोष पर ओपन सोर्स एलएलएम को लगातार पूर्व-प्रशिक्षित करते हैं जो वितरण में लक्ष्य कार्यों के करीब है। यह कार्य प्रदर्शन को बेहतर बनाने में मदद कर सकता है क्योंकि लेबल किए गए डेटा की आवश्यकता नहीं होने के बावजूद हम कार्य टोकन के वितरण के लिए मॉडल को अपनाते हैं।
- कुशल कार्य-अज्ञेयवादी डीएसीपी (ईटीए-डीएसीपी) - लेखक पर्प्लेक्सिटी और टोकन प्रकार एन्ट्रापी जैसे मेट्रिक्स का उपयोग करने का प्रस्ताव करते हैं, जिन्हें कुशल निरंतर पूर्व-प्रशिक्षण के लिए वित्तीय कोष से नमूनों का चयन करने के लिए कार्य डेटा की आवश्यकता नहीं होती है। यह दृष्टिकोण उन परिदृश्यों से निपटने के लिए डिज़ाइन किया गया है जहां कार्य डेटा अनुपलब्ध है या व्यापक डोमेन के लिए अधिक बहुमुखी डोमेन मॉडल को प्राथमिकता दी जाती है। लेखक डेटा नमूनों का चयन करने के लिए दो आयाम अपनाते हैं जो पूर्व-प्रशिक्षण डोमेन डेटा के सबसेट से डोमेन जानकारी प्राप्त करने के लिए महत्वपूर्ण हैं: नवीनता और विविधता। नवीनता, लक्ष्य मॉडल द्वारा दर्ज की गई उलझन से मापी गई, उस जानकारी को संदर्भित करती है जो एलएलएम द्वारा पहले नहीं देखी गई थी। उच्च नवीनता वाला डेटा एलएलएम के लिए नवीन ज्ञान को इंगित करता है, और ऐसे डेटा को सीखना अधिक कठिन माना जाता है। यह निरंतर पूर्व-प्रशिक्षण के दौरान गहन डोमेन ज्ञान के साथ सामान्य एलएलएम को अद्यतन करता है। दूसरी ओर, विविधता, डोमेन कॉर्पस में टोकन प्रकारों के वितरण की विविधता को पकड़ती है, जिसे भाषा मॉडलिंग पर पाठ्यक्रम सीखने के अनुसंधान में एक उपयोगी सुविधा के रूप में प्रलेखित किया गया है।
निम्नलिखित आंकड़ा ईटीएस-डीएसीपी (बाएं) बनाम ईटीए-डीएसीपी (दाएं) के उदाहरण की तुलना करता है।

हम क्यूरेटेड वित्तीय कोष से डेटा बिंदुओं को सक्रिय रूप से चुनने के लिए दो सैंपलिंग योजनाएं अपनाते हैं: हार्ड सैंपलिंग और सॉफ्ट सैंपलिंग। पहले वित्तीय कोष को संबंधित मेट्रिक्स द्वारा रैंकिंग करके और फिर शीर्ष-के नमूनों का चयन करके किया जाता है, जहां के को प्रशिक्षण बजट के अनुसार पूर्व निर्धारित किया जाता है। बाद के लिए, लेखक मीट्रिक मानों के अनुसार प्रत्येक डेटा बिंदु के लिए नमूना भार निर्दिष्ट करते हैं, और फिर प्रशिक्षण बजट को पूरा करने के लिए यादृच्छिक रूप से k डेटा बिंदुओं का नमूना लेते हैं।
परिणाम और विश्लेषण
लेखक निरंतर पूर्व-प्रशिक्षण की प्रभावकारिता की जांच करने के लिए वित्तीय कार्यों की एक श्रृंखला पर परिणामी वित्तीय एलएलएम का मूल्यांकन करते हैं:
- वित्तीय वाक्यांश बैंक - वित्तीय समाचार पर एक भावना वर्गीकरण कार्य।
- FiQA SA - वित्तीय समाचारों और सुर्खियों पर आधारित एक पहलू-आधारित भावना वर्गीकरण कार्य।
- शीर्षक - एक वित्तीय इकाई के शीर्षक में कुछ जानकारी शामिल है या नहीं, इस पर एक द्विआधारी वर्गीकरण कार्य।
- एनईआर - एसईसी रिपोर्ट के क्रेडिट जोखिम मूल्यांकन अनुभाग के आधार पर एक वित्तीय नामित इकाई निष्कर्षण कार्य। इस कार्य में शब्दों को PER, LOC, ORG, और MISC के साथ एनोटेट किया गया है।
क्योंकि वित्तीय एलएलएम निर्देश ठीक-ठाक हैं, लेखक मजबूती के लिए प्रत्येक कार्य के लिए 5-शॉट सेटिंग में मॉडल का मूल्यांकन करते हैं। औसतन, फिनपाइथिया 6.9बी चार कार्यों में पायथिया 6.9बी से 10% बेहतर प्रदर्शन करता है, जो डोमेन-विशिष्ट निरंतर पूर्व-प्रशिक्षण की प्रभावकारिता को प्रदर्शित करता है। 1बी मॉडल के लिए, सुधार कम गहरा है, लेकिन प्रदर्शन में अभी भी औसतन 2% सुधार हुआ है।
निम्नलिखित आंकड़ा दोनों मॉडलों पर डीएसीपी से पहले और बाद में प्रदर्शन अंतर को दर्शाता है।

निम्नलिखित आंकड़ा पाइथिया 6.9बी और फिनपाइथिया 6.9बी द्वारा उत्पन्न दो गुणात्मक उदाहरण दिखाता है। एक निवेशक प्रबंधक और एक वित्तीय शब्द से संबंधित दो वित्त संबंधी प्रश्नों के लिए, पाइथिया 6.9बी शब्द को नहीं समझता है या नाम को नहीं पहचानता है, जबकि फिनपाइथिया 6.9बी सही ढंग से विस्तृत उत्तर उत्पन्न करता है। गुणात्मक उदाहरण दर्शाते हैं कि निरंतर पूर्व-प्रशिक्षण एलएलएम को प्रक्रिया के दौरान डोमेन ज्ञान प्राप्त करने में सक्षम बनाता है।

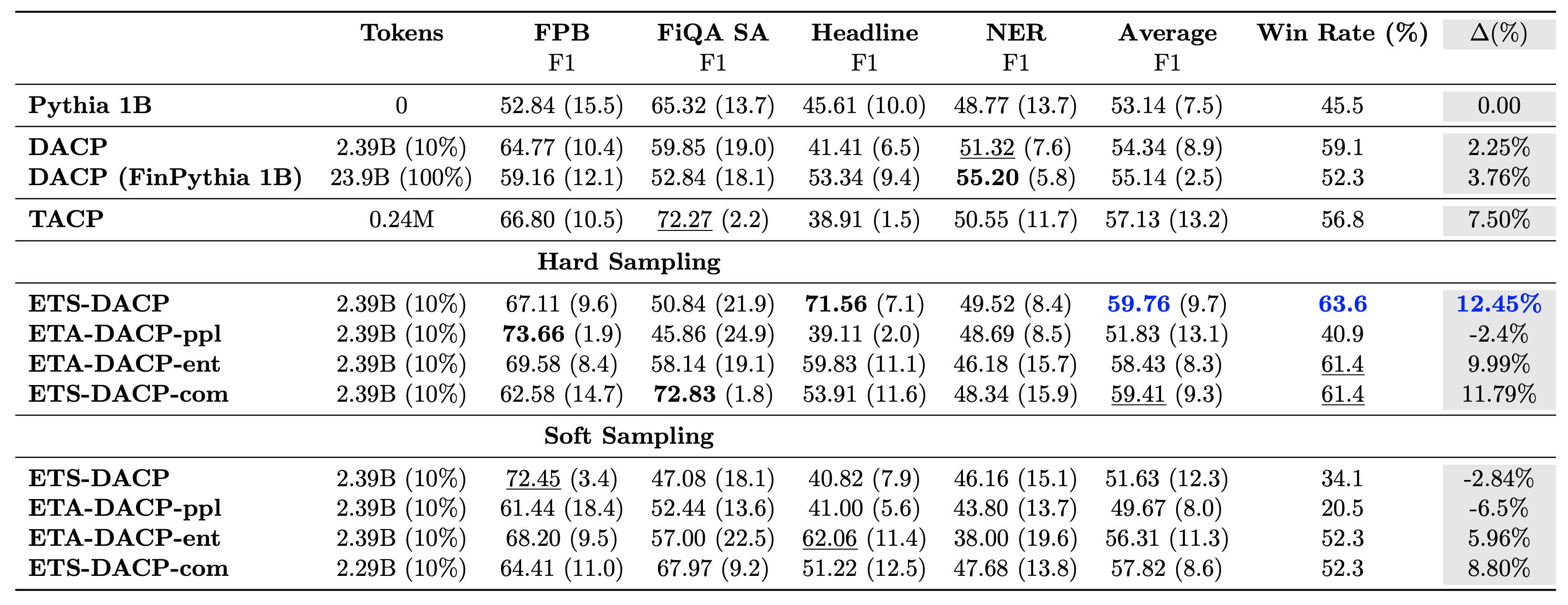
निम्न तालिका विभिन्न कुशल निरंतर पूर्व-प्रशिक्षण दृष्टिकोणों की तुलना करती है। ETA-DACP-ppl ETA-DACP है जो उलझन (नवीनता) पर आधारित है, और ETA-DACP-ent एन्ट्रापी (विविधता) पर आधारित है। ETS-DACP-com तीनों मेट्रिक्स के औसत के आधार पर डेटा चयन के साथ DACP के समान है। परिणामों से कुछ निष्कर्ष निम्नलिखित हैं:
- डेटा चयन विधियाँ कुशल हैं - वे केवल 10% प्रशिक्षण डेटा के साथ मानक निरंतर पूर्व-प्रशिक्षण से आगे निकल जाते हैं। टास्क-समान डीएसीपी (ईटीएस-डीएसीपी), एन्ट्रापी पर आधारित टास्क-एग्नॉस्टिक डीएसीपी (ईएसए-डीएसीपी-एंट) और तीनों मेट्रिक्स (ईटीएस-डीएसीपी-कॉम) पर आधारित टास्क-समान डीएसीपी सहित कुशल निरंतर पूर्व-प्रशिक्षण मानक डीएसीपी से बेहतर प्रदर्शन करता है। इस तथ्य के बावजूद कि उन्हें वित्तीय कोष के केवल 10% पर प्रशिक्षित किया जाता है।
- कार्य-जागरूक डेटा चयन छोटे भाषा मॉडल अनुसंधान के अनुरूप सबसे अच्छा काम करता है - ईटीएस-डीएसीपी सभी तरीकों के बीच सबसे अच्छा औसत प्रदर्शन रिकॉर्ड करता है और, सभी तीन मैट्रिक्स के आधार पर, दूसरा सबसे अच्छा कार्य प्रदर्शन रिकॉर्ड करता है। इससे पता चलता है कि एलएलएम के मामले में कार्य प्रदर्शन को बढ़ावा देने के लिए बिना लेबल वाले कार्य डेटा का उपयोग अभी भी एक प्रभावी तरीका है।
- कार्य-अज्ञेयवादी डेटा चयन दूसरे स्थान पर है - ईएसए-डीएसीपी-एंट कार्य-जागरूक डेटा चयन दृष्टिकोण के प्रदर्शन का अनुसरण करता है, जिसका अर्थ है कि हम अभी भी विशिष्ट कार्यों से जुड़े उच्च गुणवत्ता वाले नमूनों को सक्रिय रूप से चुनकर कार्य प्रदर्शन को बढ़ावा दे सकते हैं। यह बेहतर कार्य प्रदर्शन प्राप्त करते हुए पूरे डोमेन के लिए वित्तीय एलएलएम बनाने का मार्ग प्रशस्त करता है।
निरंतर पूर्व-प्रशिक्षण के संबंध में एक महत्वपूर्ण प्रश्न यह है कि क्या यह गैर-डोमेन कार्यों पर प्रदर्शन को नकारात्मक रूप से प्रभावित करता है। लेखक चार व्यापक रूप से उपयोग किए जाने वाले सामान्य कार्यों पर लगातार पूर्व-प्रशिक्षित मॉडल का भी मूल्यांकन करते हैं: एआरसी, एमएमएलयू, ट्रुथक्यूए, और हेलास्वैग, जो प्रश्न उत्तर देने, तर्क करने और पूरा करने की क्षमता को मापते हैं। लेखकों का मानना है कि निरंतर पूर्व-प्रशिक्षण गैर-डोमेन प्रदर्शन पर प्रतिकूल प्रभाव नहीं डालता है। अधिक जानकारी के लिए देखें डोमेन विशिष्ट बड़े भाषा मॉडल के निर्माण के लिए कुशल निरंतर पूर्व प्रशिक्षण.
निष्कर्ष
इस पोस्ट ने वित्तीय क्षेत्र के लिए एलएलएम के प्रशिक्षण के लिए डेटा संग्रह और निरंतर पूर्व-प्रशिक्षण रणनीतियों में अंतर्दृष्टि प्रदान की। आप वित्तीय कार्यों के लिए अपने स्वयं के एलएलएम का प्रशिक्षण शुरू कर सकते हैं अमेज़ॅन सेजमेकर प्रशिक्षण or अमेज़ॅन बेडरॉक आज।
लेखक के बारे में
 योंग झी अमेज़ॅन फिनटेक में एक व्यावहारिक वैज्ञानिक हैं। वह वित्त के लिए बड़े भाषा मॉडल और जेनरेटिव एआई अनुप्रयोगों को विकसित करने पर ध्यान केंद्रित करते हैं।
योंग झी अमेज़ॅन फिनटेक में एक व्यावहारिक वैज्ञानिक हैं। वह वित्त के लिए बड़े भाषा मॉडल और जेनरेटिव एआई अनुप्रयोगों को विकसित करने पर ध्यान केंद्रित करते हैं।
 करण अग्रवाल वित्त उपयोग के मामलों के लिए जेनरेटिव एआई पर ध्यान देने के साथ अमेज़ॅन फिनटेक में एक वरिष्ठ एप्लाइड वैज्ञानिक हैं। करण के पास समय-श्रृंखला विश्लेषण और एनएलपी में व्यापक अनुभव है, सीमित लेबल वाले डेटा से सीखने में उनकी विशेष रुचि है
करण अग्रवाल वित्त उपयोग के मामलों के लिए जेनरेटिव एआई पर ध्यान देने के साथ अमेज़ॅन फिनटेक में एक वरिष्ठ एप्लाइड वैज्ञानिक हैं। करण के पास समय-श्रृंखला विश्लेषण और एनएलपी में व्यापक अनुभव है, सीमित लेबल वाले डेटा से सीखने में उनकी विशेष रुचि है
 ऐतज़ाज़ अहमद अमेज़ॅन में एक एप्लाइड साइंस मैनेजर हैं जहां वह वित्त में मशीन लर्निंग और जेनरेटिव एआई के विभिन्न अनुप्रयोगों का निर्माण करने वाले वैज्ञानिकों की एक टीम का नेतृत्व करते हैं। उनकी शोध रुचि एनएलपी, जेनरेटिव एआई और एलएलएम एजेंटों में है। उन्होंने टेक्सास ए एंड एम यूनिवर्सिटी से इलेक्ट्रिकल इंजीनियरिंग में पीएचडी प्राप्त की।
ऐतज़ाज़ अहमद अमेज़ॅन में एक एप्लाइड साइंस मैनेजर हैं जहां वह वित्त में मशीन लर्निंग और जेनरेटिव एआई के विभिन्न अनुप्रयोगों का निर्माण करने वाले वैज्ञानिकों की एक टीम का नेतृत्व करते हैं। उनकी शोध रुचि एनएलपी, जेनरेटिव एआई और एलएलएम एजेंटों में है। उन्होंने टेक्सास ए एंड एम यूनिवर्सिटी से इलेक्ट्रिकल इंजीनियरिंग में पीएचडी प्राप्त की।
 किंगवेई ली अमेज़ॅन वेब सर्विसेज में मशीन लर्निंग विशेषज्ञ हैं। उन्होंने अपनी पीएच.डी. प्राप्त की। अपने सलाहकार के अनुसंधान अनुदान खाते को तोड़ने और अपने वादे के अनुसार नोबेल पुरस्कार देने में विफल रहने के बाद ऑपरेशन रिसर्च में। वर्तमान में वह वित्तीय सेवा में ग्राहकों को AWS पर मशीन लर्निंग समाधान बनाने में मदद करते हैं।
किंगवेई ली अमेज़ॅन वेब सर्विसेज में मशीन लर्निंग विशेषज्ञ हैं। उन्होंने अपनी पीएच.डी. प्राप्त की। अपने सलाहकार के अनुसंधान अनुदान खाते को तोड़ने और अपने वादे के अनुसार नोबेल पुरस्कार देने में विफल रहने के बाद ऑपरेशन रिसर्च में। वर्तमान में वह वित्तीय सेवा में ग्राहकों को AWS पर मशीन लर्निंग समाधान बनाने में मदद करते हैं।
 राघवेंद्र अरनी AWS इंडस्ट्रीज के भीतर ग्राहक त्वरण टीम (CAT) का नेतृत्व करता है। कैट ग्राहक-सामना करने वाले क्लाउड आर्किटेक्ट, सॉफ्टवेयर इंजीनियरों, डेटा वैज्ञानिकों और एआई/एमएल विशेषज्ञों और डिजाइनरों की एक वैश्विक क्रॉस-फंक्शनल टीम है जो उन्नत प्रोटोटाइप के माध्यम से नवाचार को बढ़ावा देती है, और विशेष तकनीकी विशेषज्ञता के माध्यम से क्लाउड परिचालन उत्कृष्टता को बढ़ावा देती है।
राघवेंद्र अरनी AWS इंडस्ट्रीज के भीतर ग्राहक त्वरण टीम (CAT) का नेतृत्व करता है। कैट ग्राहक-सामना करने वाले क्लाउड आर्किटेक्ट, सॉफ्टवेयर इंजीनियरों, डेटा वैज्ञानिकों और एआई/एमएल विशेषज्ञों और डिजाइनरों की एक वैश्विक क्रॉस-फंक्शनल टीम है जो उन्नत प्रोटोटाइप के माध्यम से नवाचार को बढ़ावा देती है, और विशेष तकनीकी विशेषज्ञता के माध्यम से क्लाउड परिचालन उत्कृष्टता को बढ़ावा देती है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

