परिचय
महत्व निर्धारित करने के लिए एक विश्वसनीय सांख्यिकीय तकनीक विचरण (एनोवा) का विश्लेषण है, खासकर जब दो से अधिक नमूना औसत की तुलना की जाती है। यद्यपि टी-वितरण दो नमूनों के साधनों की तुलना करने के लिए पर्याप्त है, एक बार में तीन या अधिक नमूनों के साथ काम करते समय एक एनोवा की आवश्यकता होती है ताकि यह निर्धारित किया जा सके कि उनके साधन समान हैं या नहीं क्योंकि वे एक ही अंतर्निहित आबादी से आते हैं।
उदाहरण के लिए, एनोवा का उपयोग यह निर्धारित करने के लिए किया जा सकता है कि क्या विभिन्न उर्वरकों का अलग-अलग भूखंडों में गेहूं के उत्पादन पर अलग-अलग प्रभाव पड़ता है और क्या ये उपचार एक ही आबादी से सांख्यिकीय रूप से भिन्न परिणाम प्रदान करते हैं।

प्रोफेसर आरए फिशर ने 1920 में कृषि संबंधी डेटा के विश्लेषण में समस्या से निपटने के दौरान 'एनालिसिस ऑफ वेरिएंस' शब्द की शुरुआत की। परिवर्तनशीलता प्राकृतिक घटनाओं की एक मूलभूत विशेषता है। किसी भी डेटासेट में समग्र भिन्नता कई स्रोतों से उत्पन्न होती है, जिसे मोटे तौर पर निर्दिष्ट और आकस्मिक कारणों के रूप में वर्गीकृत किया जा सकता है।
निर्दिष्ट कारणों के कारण भिन्नता का पता लगाया और मापा जा सकता है जबकि आकस्मिक कारणों के कारण भिन्नता मानव हाथ के नियंत्रण से परे है और इसे अलग से इलाज नहीं किया जा सकता है।
आरए फिशर के अनुसार, वेरिएंस का विश्लेषण (एनोवा) "कारणों के एक समूह के लिए जिम्मेदार भिन्नता को दूसरे समूह के लिए जिम्मेदार भिन्नता से अलग करना" है।
सीखने के मकसद
- वेरिएंस के विश्लेषण (एनोवा) की अवधारणा और सांख्यिकीय विश्लेषण में इसके महत्व को समझें, खासकर जब कई नमूना औसत की तुलना करते हैं।
- एनोवा परीक्षण आयोजित करने और चिकित्सा, शिक्षा, विपणन, विनिर्माण, मनोविज्ञान और कृषि जैसे विभिन्न क्षेत्रों में इसके अनुप्रयोग के लिए आवश्यक मान्यताओं को जानें।
- एक-तरफ़ा एनोवा निष्पादित करने की चरण-दर-चरण प्रक्रिया का अन्वेषण करें, जिसमें शून्य और वैकल्पिक परिकल्पना स्थापित करना, डेटा संग्रह और संगठन, समूह आंकड़ों की गणना, वर्गों के योग का निर्धारण, स्वतंत्रता की डिग्री की गणना, औसत वर्गों की गणना शामिल है। , एफ-सांख्यिकी की गणना, महत्वपूर्ण मूल्य का निर्धारण और निर्णय लेना।
- scipy.stats लाइब्रेरी का उपयोग करके पायथन में एक-तरफ़ा एनोवा परीक्षण लागू करने में व्यावहारिक अंतर्दृष्टि प्राप्त करें।
- एनोवा के संदर्भ में एफ-सांख्यिकी और पी-मूल्य के महत्व स्तर और व्याख्या को समझें।
- समूहों के बीच महत्वपूर्ण अंतरों के आगे के विश्लेषण के लिए तुकी के ईमानदारी से महत्वपूर्ण अंतर (एचएसडी) जैसी पोस्ट-हॉक विश्लेषण विधियों के बारे में जानें।
विषय - सूची
एनोवा परीक्षण के लिए मान्यताएँ
एनोवा परीक्षण परीक्षण सांख्यिकी एफ पर आधारित है।
एनोवा में एफ-परीक्षण की वैधता के संबंध में की गई धारणाओं में निम्नलिखित शामिल हैं:
- अवलोकन स्वतंत्र हैं.
- मूल जनसंख्या जिससे अवलोकन लिया गया है वह सामान्य है।
- विभिन्न उपचार और पर्यावरणीय प्रभाव प्रकृति में योगात्मक हैं।
वन-वे एनोवा
एक तरह से एनोवा है सांख्यिकीय परीक्षण यह निर्धारित करने के लिए उपयोग किया जाता है कि क्या एक ही कारक (स्वतंत्र चर) के लिए तीन या अधिक समूहों के साधनों में सांख्यिकीय रूप से महत्वपूर्ण अंतर हैं। यह समूहों के बीच भिन्नता की तुलना समूहों के भीतर भिन्नता से करता है ताकि यह आकलन किया जा सके कि क्या ये अंतर यादृच्छिक अवसर या कारक के व्यवस्थित प्रभाव के कारण हैं।
विभिन्न डोमेन से एक-तरफ़ा एनोवा के कई उपयोग मामले हैं:
- चिकित्सा: किसी विशेष चिकित्सीय स्थिति पर विभिन्न उपचारों की प्रभावशीलता की तुलना करने के लिए वन-वे एनोवा का उपयोग किया जा सकता है। उदाहरण के लिए, इसका उपयोग यह निर्धारित करने के लिए किया जा सकता है कि क्या तीन अलग-अलग दवाओं का रक्तचाप को कम करने पर महत्वपूर्ण रूप से अलग-अलग प्रभाव पड़ता है।
- शिक्षा: एक-तरफ़ा एनोवा का उपयोग यह विश्लेषण करने के लिए किया जा सकता है कि क्या विभिन्न शिक्षण विधियों का उपयोग करके पढ़ाए गए छात्रों के बीच परीक्षण स्कोर में महत्वपूर्ण अंतर हैं।
- विपणन: विभिन्न ब्रांडों के उत्पादों के बीच ग्राहक संतुष्टि के स्तर में महत्वपूर्ण अंतर हैं या नहीं, इसका आकलन करने के लिए एक-तरफ़ा एनोवा को नियोजित किया जा सकता है।
- विनिर्माण: एक-तरफ़ा एनोवा का उपयोग यह विश्लेषण करने के लिए किया जा सकता है कि विभिन्न विनिर्माण प्रक्रियाओं द्वारा उत्पादित सामग्रियों की ताकत में महत्वपूर्ण अंतर हैं या नहीं।
- मनोविज्ञान: एक-तरफ़ा एनोवा का उपयोग यह जांचने के लिए किया जा सकता है कि विभिन्न तनावों के संपर्क में आने वाले प्रतिभागियों के बीच चिंता के स्तर में महत्वपूर्ण अंतर हैं या नहीं।
- कृषि: एक-तरफ़ा एनोवा का उपयोग यह निर्धारित करने के लिए किया जा सकता है कि खेती के प्रयोगों में विभिन्न उर्वरकों के कारण फसल की पैदावार में काफी भिन्नता होती है या नहीं।
आइए इसे कृषि उदाहरण से विस्तार से समझें:
कृषि अनुसंधान में, एक-तरफ़ा एनोवा का उपयोग यह आकलन करने के लिए किया जा सकता है कि क्या विभिन्न उर्वरकों से फसल की पैदावार में काफी भिन्नता होती है।
पौधों की वृद्धि पर उर्वरक का प्रभाव
कल्पना कीजिए कि आप पौधों की वृद्धि पर विभिन्न उर्वरकों के प्रभाव पर शोध कर रहे हैं। आप पौधों के अलग-अलग समूहों में तीन प्रकार के उर्वरक (ए, बी और सी) लागू करते हैं। एक निर्धारित अवधि के बाद, आप प्रत्येक समूह में पौधों की औसत ऊंचाई मापते हैं। आप यह जांचने के लिए एक-तरफ़ा एनोवा का उपयोग कर सकते हैं कि विभिन्न उर्वरकों के साथ उगाए गए पौधों की औसत ऊंचाई में कोई महत्वपूर्ण अंतर है या नहीं।
चरण 1: शून्य और वैकल्पिक परिकल्पनाएँ
पहला कदम शून्य और वैकल्पिक परिकल्पनाओं को आगे बढ़ाना है:
- शून्य परिकल्पना(H0): सभी समूहों के साधन समान हैं (उर्वरक प्रकार के कारण पौधों की वृद्धि में कोई महत्वपूर्ण अंतर नहीं है)
- वैकल्पिक परिकल्पना (H1): कम से कम एक समूह का माध्य दूसरों से भिन्न है (उर्वरक प्रकार का पौधों की वृद्धि पर महत्वपूर्ण प्रभाव पड़ता है)।
चरण 2: डेटा संग्रह और डेटा संगठन
एक निर्धारित विकास अवधि के बाद, तीनों समूहों में प्रत्येक पौधे की अंतिम ऊंचाई को सावधानीपूर्वक मापें। अब अपना डेटा व्यवस्थित करें. प्रत्येक स्तंभ एक उर्वरक प्रकार (ए, बी, सी) का प्रतिनिधित्व करता है और प्रत्येक पंक्ति उस समूह के भीतर एक व्यक्तिगत पौधे की ऊंचाई रखती है।
चरण 3: समूह सांख्यिकी की गणना करें
- प्रत्येक उर्वरक समूह (ए, बी और सी) में पौधों के लिए औसत अंतिम ऊंचाई की गणना करें।
- सभी समूहों में देखे गए पौधों की कुल संख्या (एन) की गणना करें।
- हमारे मामले में समूहों (K) की कुल संख्या निर्धारित करें, k=3(A, B, C)
चरण 4: वर्ग के योग की गणना करें
तो वर्ग का कुल योग, समूह के बीच वर्ग का योग, समूह के भीतर वर्ग का योग की गणना की जाएगी।
यहां, वर्ग का कुल योग सभी पौधों की अंतिम ऊंचाई में कुल भिन्नता को दर्शाता है।
वर्ग के बीच-समूह का योग तीन उर्वरक समूहों की औसत ऊंचाई के बीच देखी गई भिन्नता को दर्शाता है। और वर्ग के भीतर-समूह का योग प्रत्येक उर्वरक समूह के भीतर अंतिम ऊंचाइयों में भिन्नता को दर्शाता है।
चरण5: स्वतंत्रता की डिग्री की गणना करें
स्वतंत्रता की डिग्री जनसंख्या पैरामीटर का अनुमान लगाने के लिए उपयोग की जाने वाली जानकारी के स्वतंत्र टुकड़ों की संख्या को परिभाषित करती है।
- समूह के बीच स्वतंत्रता की डिग्री: k-1 (समूहों की संख्या घटा 1) तो, यहाँ यह 3-1 =2 होगा
- समूह के भीतर स्वतंत्रता की डिग्री: एनके (अवलोकनों की कुल संख्या घटा समूहों की संख्या)
चरण 6: माध्य वर्गों की गणना करें
माध्य वर्ग वर्गों के संबंधित योग को स्वतंत्रता की डिग्री से विभाजित करके प्राप्त किया जाता है।
- इनके बीच का माध्य वर्ग: बीच-समूह के बीच वर्ग/स्वतंत्रता की डिग्री का समूह योग
- भीतर का माध्य वर्ग: समूह के भीतर समूह के भीतर स्वतंत्रता के वर्ग/डिग्री का योग
चरण7: एफ-सांख्यिकी की गणना करें
एफ-सांख्यिकी एक परीक्षण आँकड़ा है जिसका उपयोग समूहों के बीच भिन्नता की तुलना समूहों के भीतर भिन्नता से करने के लिए किया जाता है। एक उच्च एफ-आँकड़ा पौधों की वृद्धि पर उर्वरक प्रकार के संभावित रूप से मजबूत प्रभाव का सुझाव देता है।
वन-वे एनोवा के लिए एफ-सांख्यिकी की गणना इस सूत्र का उपयोग करके की जाती है:
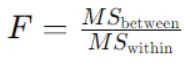
यहाँ,
MSbetween समूहों के बीच का माध्य वर्ग है, जिसकी गणना समूहों के बीच वर्गों के योग को समूहों के बीच स्वतंत्रता की डिग्री से विभाजित करके की जाती है।
MSwithin समूहों के भीतर औसत वर्ग है, जिसकी गणना समूहों के भीतर वर्गों के योग को समूहों के भीतर स्वतंत्रता की डिग्री से विभाजित करके की जाती है।
- समूहों के बीच स्वतंत्रता की डिग्री(dof_between): dof_between = k-1
जहाँ k स्वतंत्र चर के समूहों (स्तरों) की संख्या है।
- समूहों के भीतर स्वतंत्रता की डिग्री (dof_within): dof_within = Nk
जहां N अवलोकनों की संख्या है और k स्वतंत्र चर के समूहों (स्तरों) की संख्या है।
एक-तरफ़ा एनोवा के लिए, स्वतंत्रता की कुल डिग्री समूहों के बीच और समूहों के भीतर स्वतंत्रता की डिग्री का योग है:
dof_total= dof_between+dof_within
चरण8: महत्वपूर्ण मूल्य और निर्णय निर्धारित करें
विश्लेषण के लिए एक महत्व स्तर (अल्फा) चुनें, आमतौर पर 0.05 चुना जाता है
चुने गए अल्फ़ा स्तर पर महत्वपूर्ण एफ-मान देखें और एफ-वितरण तालिका का उपयोग करके समूह के बीच स्वतंत्रता की डिग्री और समूह के भीतर स्वतंत्रता की डिग्री की गणना करें।
परिकलित एफ-सांख्यिकी की तुलना महत्वपूर्ण एफ-मूल्य से करें
- यदि गणना की गई एफ-सांख्यिकी महत्वपूर्ण एफ-मूल्य से अधिक है, तो शून्य परिकल्पना (एच0) को अस्वीकार करें। यह तीन उर्वरक समूहों के बीच औसत पौधों की ऊंचाई में सांख्यिकीय रूप से महत्वपूर्ण अंतर को इंगित करता है।
- यदि परिकलित एफ-सांख्यिकी महत्वपूर्ण एफ-वैल से कम या उसके बराबर है, तो शून्य परिकल्पना (एच0) को अस्वीकार करने में विफल रहें। आप इस डेटा के आधार पर कोई महत्वपूर्ण अंतर नहीं निकाल सकते।
चरण 9: पोस्ट-हॉक विश्लेषण (यदि आवश्यक हो)
अगर शून्य परिकल्पना अस्वीकार कर दिया गया है, जो एक महत्वपूर्ण समग्र अंतर को दर्शाता है, हो सकता है कि आप गहराई में जाना चाहें। तुकी के ईमानदारी से महत्वपूर्ण अंतर (एचएसडी) जैसे पोस्ट-हॉक यह पहचानने में मदद कर सकते हैं कि कौन से विशिष्ट उर्वरक समूहों में सांख्यिकीय रूप से भिन्न औसत पौधे की ऊंचाई है।
पायथन में कार्यान्वयन:
import scipy.stats as stats
# Sample plant height data for each fertilizer type
plant_heights_A = [25, 28, 23, 27, 26]
plant_heights_B = [20, 22, 19, 21, 24]
plant_heights_C = [18, 20, 17, 19, 21]
# Perform one-way ANOVA
f_value, p_value = stats.f_oneway(plant_heights_A, plant_heights_B, plant_heights_C)
# Interpretation
print("F-statistic:", f_value)
print("p-value:", p_value)
# Significance level (alpha) - typically set at 0.05
alpha = 0.05
if p_value < alpha:
print("Reject H0: There is a significant difference in plant growth between the fertilizer groups.")
else:
print("Fail to reject H0: We cannot conclude a significant difference based on this sample.")
आउटपुट:

के बीच स्वतंत्रता की डिग्री K-1 = 3-1 =2 है, जहां k उर्वरक समूहों की संख्या को दर्शाता है। भीतर स्वतंत्रता की डिग्री Nk = 15-3 = 12 है, जहां N डेटा बिंदुओं की कुल संख्या का प्रतिनिधित्व करता है।
डीओएफ(2,12) पर एफ-क्रिटिकल की गणना की जा सकती है एफ-वितरण तालिका महत्व के 0.05 स्तर पर।
एफ-क्रिटिकल = 9.42
चूंकि एफ-क्रिटिकल <एफ-सांख्यिकी इसलिए, हम शून्य परिकल्पना को अस्वीकार करते हैं जो निष्कर्ष निकालती है कि उर्वरक समूहों के बीच पौधों की वृद्धि में महत्वपूर्ण अंतर है।
0.05 से नीचे पी-मान के साथ, हमारा निष्कर्ष सुसंगत रहता है: हम शून्य परिकल्पना को अस्वीकार करते हैं, जो उर्वरक समूहों के बीच पौधों की वृद्धि में महत्वपूर्ण अंतर का संकेत देता है।
दो तरफा एनोवा
एक-तरफ़ा एनोवा केवल एक कारक के लिए उपयुक्त है, लेकिन क्या होगा यदि आपके प्रयोग को प्रभावित करने वाले दो कारक हों? फिर दो-तरफ़ा एनोवा का उपयोग किया जाता है जो आपको एक ही आश्रित चर पर दो स्वतंत्र चर के प्रभावों का विश्लेषण करने की अनुमति देता है।
चरण 1: परिकल्पनाएँ स्थापित करना
- शून्य परिकल्पना (H0): उर्वरक प्रकार (ए, बी, सी) या रोपण समय (जल्दी, देर से) या उनकी परस्पर क्रिया के कारण औसत अंतिम पौधे की ऊंचाई में कोई महत्वपूर्ण अंतर नहीं है।
- वैकल्पिक परिकल्पना (H1): कम से कम एक निम्नलिखित सत्य है:
- उर्वरक के प्रकार का औसत अंतिम ऊंचाई पर महत्वपूर्ण प्रभाव पड़ता है।
- रोपण का समय औसत अंतिम ऊंचाई पर महत्वपूर्ण प्रभाव डालता है।
- उर्वरक के प्रकार और रोपण के समय के बीच एक महत्वपूर्ण परस्पर क्रिया प्रभाव होता है। इसका मतलब है कि एक कारक (उर्वरक) का प्रभाव दूसरे कारक (रोपण समय) के स्तर पर निर्भर करता है।
चरण 2: डेटा संग्रह और संगठन
- अंतिम पौधे की ऊँचाई मापें।
- अपने डेटा को अलग-अलग पौधों और स्तंभों का प्रतिनिधित्व करने वाली पंक्तियों के साथ एक तालिका में व्यवस्थित करें:
- उर्वरक प्रकार (ए, बी, सी)
- रोपण का समय (जल्दी, देर से)
- अंतिम ऊंचाई (सेमी)
यहाँ तालिका है:

चरण 3: वर्ग के योग की गणना करें
वन-वे एनोवा के समान, आपको अंतिम ऊंचाई में भिन्नता का आकलन करने के लिए वर्गों के विभिन्न योगों की गणना करनी होगी:
- वर्ग का कुल योग (एसएसटी): सभी पौधों में कुल भिन्नता का प्रतिनिधित्व करता है। वर्ग का मुख्य प्रभाव योग:
- बीच-उर्वरक प्रकार (SSB_F): उर्वरक प्रकार में अंतर के कारण भिन्नता को दर्शाता है (रोपण के समय में औसत)
- बीच-प्लेटिंग टाइम्स (SSB_T): रोपण समय (उर्वरक प्रकारों में औसत) में अंतर के कारण भिन्नता को दर्शाता है।
- वर्ग का इंटरेक्शन योग (एसएसआई): उर्वरक के प्रकार और रोपण के समय के बीच परस्पर क्रिया के कारण होने वाले बदलाव को दर्शाता है।
- वर्गों के भीतर-समूह योग (एसएसडब्ल्यू): प्रत्येक उर्वरक-रोपण समय संयोजन के भीतर अंतिम ऊंचाई में भिन्नता का प्रतिनिधित्व करता है।
चरण 4: स्वतंत्रता की डिग्री की गणना करें (डीएफ):
स्वतंत्रता की डिग्री प्रत्येक प्रभाव के लिए सूचना के स्वतंत्र टुकड़ों की संख्या को परिभाषित करती है।
- dfकुल: एन-1 (कुल अवलोकन घटा 1)
- डीएफउर्वरक: उर्वरकों के प्रकारों की संख्या-1
- dfरोपण का समय: रोपण समय की संख्या -1
- dfइंटरैक्शन: (उर्वरकों की संख्या -1) * (रोपण के समय की संख्या -1)
- डीएफभीतर: dfTotal-dfउर्वरक-dfप्लांटिंग-dfइंटरेक्शन
चरण 5: माध्य वर्गों की गणना करें
वर्ग के प्रत्येक योग को उसकी स्वतंत्रता की संगत डिग्री से विभाजित करें।
- एमएस_उर्वरक: एसएसबी_एफ/डीएफउर्वरक
- MS_रोपण का समय: एसएसबी_टी/डीएफप्लांटिंग
- एमएस_इंटरैक्शन: एसएसआई/डीएफइंटरेक्शन
- MS_भीतर: एसएसडब्ल्यू/डीएफभीतर
चरण6: एफ-सांख्यिकी की गणना करें
उर्वरक प्रकार, रोपण समय और अंतःक्रिया प्रभाव के लिए अलग-अलग एफ-आँकड़ों की गणना करें:
- F_उर्वरक: एमएस_उर्वरक/एमएस_भीतर
- F_रोपण का समय: MS_रोपण का समय/ MS_भीतर
- F_इंटरैक्शन: MS_इंटीएक्शन/MS_भीतर
- F_रोपण का समय: MS_रोपण का समय/MS_भीतर
- F_इंटरैक्शन: MS_इंटरैक्शन/ MS_भीतर
चरण 7: महत्वपूर्ण मूल्य और निर्णय निर्धारित करें:
अपने विश्लेषण के लिए एक महत्व स्तर (अल्फा) चुनें, आमतौर पर हम 0.05 लेते हैं
एफ-वितरण तालिका या सांख्यिकीय सॉफ्टवेयर का उपयोग करके चुने हुए अल्फा स्तर पर प्रत्येक प्रभाव (उर्वरक, रोपण समय, इंटरैक्शन) के लिए महत्वपूर्ण एफ-मान और उनकी स्वतंत्रता की संबंधित डिग्री देखें।
प्रत्येक प्रभाव के लिए अपने परिकलित एफ-आँकड़ों की महत्वपूर्ण एफ-मानों से तुलना करें:
- यदि एफ-सांख्यिकी महत्वपूर्ण एफ-मूल्य से अधिक है, तो उस प्रभाव के लिए शून्य परिकल्पना (एच0) को अस्वीकार करें। यह सांख्यिकीय रूप से महत्वपूर्ण अंतर दर्शाता है।
- यदि एफ-सांख्यिकी महत्वपूर्ण एफ-मूल्य से कम या उसके बराबर है तो उस प्रभाव के लिए एच0 को अस्वीकार करने में विफल रहें। यह सांख्यिकीय रूप से नगण्य अंतर को दर्शाता है।
चरण 8: पोस्ट-हॉक विश्लेषण (यदि आवश्यक हो)
यदि शून्य परिकल्पना को अस्वीकार कर दिया जाता है, जो एक महत्वपूर्ण समग्र अंतर को दर्शाता है, तो आप अधिक गहराई में जाना चाहेंगे। तुकी के ईमानदारी से महत्वपूर्ण अंतर (एचएसडी) जैसे पोस्ट-हॉक यह पहचानने में मदद कर सकते हैं कि कौन से विशिष्ट उर्वरक समूहों में सांख्यिकीय रूप से भिन्न औसत पौधे की ऊंचाई है।
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
# Create a DataFrame from the dictionary
plant_heights = {
'Treatment': ['A', 'A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C', 'C'],
'Time': ['Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late'],
'Height': [25, 28, 23, 27, 26, 24,
20, 22, 19, 21, 24, 22,
18, 20, 17, 19, 21, 20]
}
df = pd.DataFrame(plant_heights)
# Fit the ANOVA model
model = ols('Height ~ C(Treatment) + C(Time) + C(Treatment):C(Time)', data=df).fit()
# Perform ANOVA
anova_table = sm.stats.anova_lm(model, typ=2)
# Print the ANOVA table
print(anova_table)
# Interpret the results
alpha = 0.05 # Significance level
if anova_table['PR(>F)'][0] < alpha:
print("nReject null hypothesis for Treatment factor.")
else:
print("nFail to reject null hypothesis for Treatment factor.")
if anova_table['PR(>F)'][1] < alpha:
print("Reject null hypothesis for Time factor.")
else:
print("Fail to reject null hypothesis for Time factor.")
if anova_table['PR(>F)'][2] < alpha:
print("Reject null hypothesis for Interaction between Treatment and Time.")
else:
print("Fail to reject null hypothesis for Interaction between Treatment and Time.")
आउटपुट:
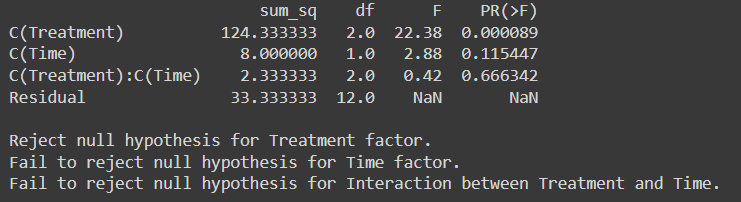
स्वतंत्रता की डिग्री पर उपचार के लिए एफ-महत्वपूर्ण मूल्य (2,12) से महत्व के 0.05 स्तर पर एफ-वितरण तालिका 9.42 है
1,12 महत्व के स्तर पर स्वतंत्रता की डिग्री (0.05) पर समय के लिए एफ-महत्वपूर्ण मान 61.22 है
एफ- स्वतंत्रता की डिग्री (0.05) पर महत्व के 2,12 स्तर पर उपचार और समय के बीच बातचीत के लिए महत्वपूर्ण मूल्य 9.42 है
चूंकि एफ-क्रिटिकल <एफ-सांख्यिकी इसलिए, हम उपचार कारक के लिए शून्य परिकल्पना को अस्वीकार करते हैं।
लेकिन समय कारक और उपचार और समय कारक के बीच बातचीत के लिए हम शून्य परिकल्पना को एफ-सांख्यिकी मूल्य> एफ-महत्वपूर्ण मूल्य के रूप में अस्वीकार करने में विफल रहे।
0.05 से नीचे पी-वैल्यू के साथ, हमारा निष्कर्ष सुसंगत रहता है: हम उपचार कारक के लिए शून्य परिकल्पना को अस्वीकार करते हैं जबकि 0.05 से ऊपर पी-वैल्यू के साथ हम समय कारक और उपचार और समय कारक के बीच बातचीत के लिए शून्य परिकल्पना को अस्वीकार करने में विफल रहते हैं।
वन-वे एनोवा और टू-वे एनोवा के बीच अंतर
वन-वे एनोवा और टू-वे एनोवा दोनों सांख्यिकीय तकनीकें हैं जिनका उपयोग समूहों के बीच अंतर का विश्लेषण करने के लिए किया जाता है, लेकिन वे स्वतंत्र चर की संख्या और प्रयोगात्मक डिजाइन की जटिलता के संदर्भ में भिन्न होते हैं।
यहां एक-तरफ़ा एनोवा और दो-तरफ़ा एनोवा के बीच मुख्य अंतर दिए गए हैं:
| पहलू | वन-वे एनोवा | दो तरफा एनोवा |
|---|---|---|
| चरों की संख्या | एक सतत आश्रित चर पर एक स्वतंत्र चर (कारक) का विश्लेषण करता है | एक सतत आश्रित चर पर दो स्वतंत्र चर (कारकों) का विश्लेषण करता है |
| प्रयोगात्मक डिजाइन | कई स्तरों (समूहों) के साथ एक श्रेणीगत स्वतंत्र चर | दो श्रेणीबद्ध स्वतंत्र चर (कारक), जिन्हें अक्सर कई स्तरों के साथ ए और बी के रूप में लेबल किया जाता है। मुख्य प्रभावों और अंतःक्रिया प्रभावों की जांच की अनुमति देता है |
| व्याख्या | समूह साधनों के बीच महत्वपूर्ण अंतर दर्शाता है | कारकों (ए और बी) के मुख्य प्रभावों और उनकी परस्पर क्रिया के बारे में जानकारी प्रदान करता है। कारक स्तरों और अन्योन्याश्रितता के बीच अंतर का आकलन करने में मदद करता है |
| जटिलता | अपेक्षाकृत सरल और व्याख्या करने में आसान | अधिक जटिल, दो कारकों के मुख्य प्रभावों और उनकी परस्पर क्रिया का विश्लेषण। कारक संबंधों पर सावधानीपूर्वक विचार करने की आवश्यकता है |
निष्कर्ष
एनोवा समूह साधनों के बीच अंतर का विश्लेषण करने के लिए एक शक्तिशाली उपकरण है, जो दो से अधिक नमूना औसत की तुलना करते समय आवश्यक है। एक-तरफ़ा एनोवा निरंतर परिणाम पर एक कारक के प्रभाव का आकलन करता है, जबकि दो-तरफ़ा एनोवा दो कारकों और उनके परस्पर प्रभाव पर विचार करने के लिए इस विश्लेषण का विस्तार करता है। इन अंतरों को समझने से शोधकर्ता अपने प्रयोगात्मक डिजाइन और शोध प्रश्नों के लिए सबसे उपयुक्त विश्लेषणात्मक दृष्टिकोण चुनने में सक्षम हो जाते हैं।
आम सवाल-जवाब
A. एनोवा का मतलब है एनालिसिस ऑफ वेरिएंस, एक सांख्यिकीय पद्धति जिसका उपयोग समूह साधनों के बीच अंतर का विश्लेषण करने के लिए किया जाता है। इसका उपयोग तीन या अधिक समूहों में साधनों की तुलना करते समय यह निर्धारित करने के लिए किया जाता है कि क्या महत्वपूर्ण अंतर हैं।
A. वन-वे एनोवा का उपयोग तब किया जाता है जब आपके पास कई स्तरों वाला एक श्रेणीगत स्वतंत्र चर (कारक) होता है और आप इन स्तरों के साधनों की तुलना करना चाहते हैं। उदाहरण के लिए, एक ही परिणाम पर विभिन्न उपचारों की प्रभावशीलता की तुलना करना।
उ. दो-तरफा एनोवा का उपयोग तब किया जाता है जब आपके पास दो श्रेणीगत स्वतंत्र चर (कारक) होते हैं और आप एक निरंतर निर्भर चर पर उनके प्रभावों का विश्लेषण करना चाहते हैं, साथ ही दोनों कारकों के बीच बातचीत का भी विश्लेषण करना चाहते हैं। यह किसी परिणाम पर दो कारकों के संयुक्त प्रभावों का अध्ययन करने के लिए उपयोगी है।
A. एनोवा में पी-वैल्यू डेटा के अवलोकन की संभावना को इंगित करता है यदि शून्य परिकल्पना (समूह साधनों के बीच कोई महत्वपूर्ण अंतर नहीं) सत्य थी। कम पी-मान (<0.05) बताता है कि शून्य परिकल्पना को अस्वीकार करने और यह निष्कर्ष निकालने के लिए महत्वपूर्ण सबूत हैं कि समूहों के बीच मतभेद हैं।)
ए. एनोवा में एफ-सांख्यिकी समूहों के बीच भिन्नता और समूहों के भीतर भिन्नता के अनुपात को मापती है। एक उच्च एफ-सांख्यिकी इंगित करती है कि समूहों के बीच भिन्नता समूहों के भीतर भिन्नता के सापेक्ष बड़ी है, जो समूह के साधनों के बीच एक महत्वपूर्ण अंतर का सुझाव देती है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/04/one-way-and-two-way-analysis-of-variance-anova/

