परिचय
एआई कोडिंग एजेंटों का उपयोग करने वाले अनुप्रयोगों में भारी वृद्धि हुई है। एलएलएम की बढ़ती गुणवत्ता और अनुमान की घटती लागत के साथ, सक्षम एआई एजेंट बनाना आसान होता जा रहा है। इसके शीर्ष पर, टूलींग पारिस्थितिकी तंत्र तेजी से विकसित हो रहा है, जिससे जटिल एआई कोडिंग एजेंट बनाना आसान हो गया है। लैंगचैन ढांचा इस मोर्चे पर अग्रणी रहा है। इसमें उत्पादन-तैयार एआई एप्लिकेशन बनाने के लिए सभी आवश्यक उपकरण और तकनीकें हैं।
लेकिन अभी तक इसमें एक चीज़ की कमी थी. और वह चक्रीयता के साथ एक बहु-एजेंट सहयोग है। यह जटिल समस्याओं को हल करने के लिए महत्वपूर्ण है, जहां समस्या को विभाजित किया जा सकता है और विशेष एजेंटों को सौंपा जा सकता है। यहीं पर लैंगग्राफ तस्वीर में आता है, जो एआई कोडिंग एजेंटों के बीच मल्टी-एक्टर स्टेटफुल सहयोग को समायोजित करने के लिए डिज़ाइन किए गए लैंगचैन फ्रेमवर्क का एक हिस्सा है। इसके अलावा, इस लेख में, हम लैंगग्राफ और इसके बुनियादी बिल्डिंग ब्लॉक्स पर चर्चा करेंगे, जबकि हम इसके साथ एक एजेंट का निर्माण करेंगे।
सीखने के मकसद
- समझें कि लैंगग्राफ क्या है।
- स्टेटफुल एजेंट बनाने के लिए लैंगग्राफ की मूल बातें जानें।
- जैसे ओपन-एक्सेस मॉडल तक पहुंचने के लिए टुगेदरएआई को एक्सप्लोर करें डीपसीककोडर.
- यूनिट परीक्षण लिखने के लिए लैंगग्राफ का उपयोग करके एआई कोडिंग एजेंट बनाएं।

इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
लैंगग्राफ क्या है?
लैंगग्राफ लैंगचेन पारिस्थितिकी तंत्र का एक विस्तार है। जबकि लैंगचेन एआई कोडिंग एजेंटों के निर्माण की अनुमति देता है जो कार्यों को निष्पादित करने के लिए कई टूल का उपयोग कर सकते हैं, यह चरणों में कई श्रृंखलाओं या अभिनेताओं को समन्वयित नहीं कर सकता है। जटिल कार्यों को पूरा करने वाले एजेंट बनाने के लिए यह महत्वपूर्ण व्यवहार है। लैंगग्राफ की कल्पना इन्हीं बातों को ध्यान में रखकर की गई थी। यह एजेंट वर्कफ़्लो को एक चक्रीय ग्राफ़ संरचना के रूप में मानता है, जहां प्रत्येक नोड एक फ़ंक्शन या लैंगचैन रननेबल ऑब्जेक्ट का प्रतिनिधित्व करता है, और किनारे नोड्स के बीच कनेक्शन होते हैं।
लैंगग्राफ की मुख्य विशेषताओं में शामिल हैं
- नोड्स: कोई भी फ़ंक्शन या लैंगचैन रननेबल ऑब्जेक्ट एक टूल की तरह।
- किनारों: नोड्स के बीच की दिशा को परिभाषित करता है।
- स्टेटफुल ग्राफ़: ग्राफ़ का प्राथमिक प्रकार. इसे राज्य वस्तुओं को प्रबंधित और अद्यतन करने के लिए डिज़ाइन किया गया है क्योंकि यह अपने नोड्स के माध्यम से डेटा संसाधित करता है।
लैंगग्राफ राज्य दृढ़ता के साथ चक्रीय एलएलएम कॉल निष्पादन की सुविधा के लिए इसका लाभ उठाता है, जो एजेंटिक व्यवहार के लिए महत्वपूर्ण है। वास्तुकला से प्रेरणा मिलती है प्रीगेल और अपाचे बीम.
इस लेख में, हम तरीकों के साथ पायथन वर्ग के लिए पाइटेस्ट यूनिट परीक्षण लिखने के लिए एक एजेंट का निर्माण करेंगे। और यह वर्कफ़्लो है.
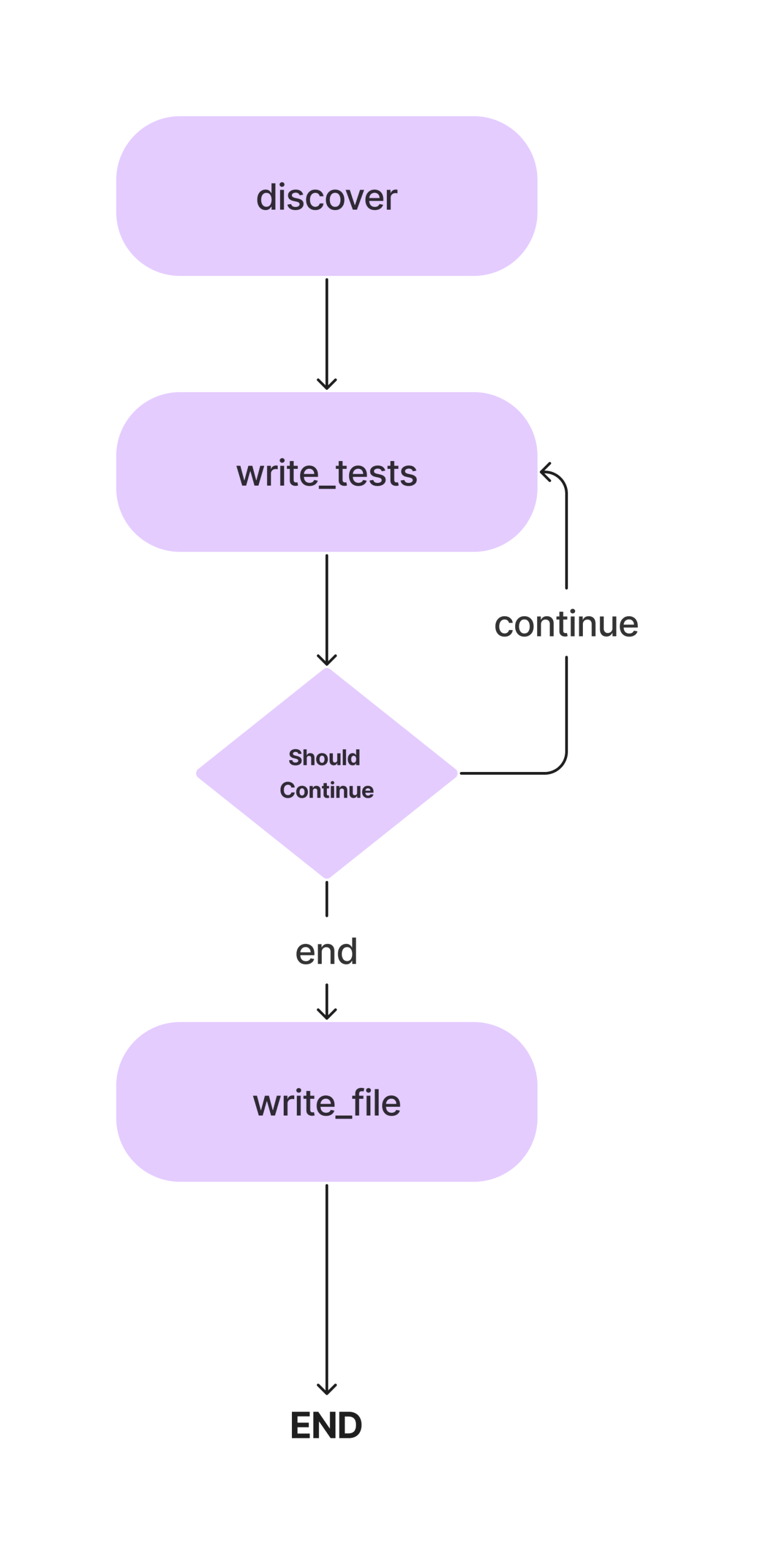
जब हम सरल इकाई परीक्षण लिखने के लिए अपना एआई कोडिंग एजेंट बनाते हैं तो हम अवधारणाओं पर विस्तार से चर्चा करेंगे। तो, चलिए कोडिंग भाग पर आते हैं।
लेकिन उससे पहले, आइए अपना विकास परिवेश स्थापित करें।
निर्भरता स्थापित करें
पहली बात पहले। किसी भी पायथन परियोजना की तरह, एक आभासी वातावरण बनाएं और इसे सक्रिय करें।
python -m venv auto-unit-tests-writer
cd auto-unit-tests-writer
source bin/activateअब, निर्भरताएँ स्थापित करें।
!pip install langgraph langchain langchain_openai coloramaसभी पुस्तकालयों और उनकी कक्षाओं को आयात करें।
from typing import TypedDict, List
import colorama
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, END
from langgraph.pregel import GraphRecursionErrorहम परीक्षण मामलों के लिए निर्देशिकाएँ और फ़ाइलें भी बनाना चाहेंगे। आप मैन्युअल रूप से फ़ाइलें बना सकते हैं या उसके लिए Python का उपयोग कर सकते हैं।
# Define the paths.
search_path = os.path.join(os.getcwd(), "app")
code_file = os.path.join(search_path, "src/crud.py")
test_file = os.path.join(search_path, "test/test_crud.py")
# Create the folders and files if necessary.
if not os.path.exists(search_path):
os.mkdir(search_path)
os.mkdir(os.path.join(search_path, "src"))
os.mkdir(os.path.join(search_path, "test"))अब, इन-मेमोरी CRUD ऐप के लिए कोड के साथ crud.py फ़ाइल को अपडेट करें। हम यूनिट परीक्षण लिखने के लिए कोड के इस टुकड़े का उपयोग करेंगे। इसके लिए आप अपने Python प्रोग्राम का उपयोग कर सकते हैं। हम नीचे दिए गए प्रोग्राम को अपनी Code.py फ़ाइल में जोड़ देंगे।
#crud.py
code = """class Item:
def __init__(self, id, name, description=None):
self.id = id
self.name = name
self.description = description
def __repr__(self):
return f"Item(id={self.id}, name={self.name}, description={self.description})"
class CRUDApp:
def __init__(self):
self.items = []
def create_item(self, id, name, description=None):
item = Item(id, name, description)
self.items.append(item)
return item
def read_item(self, id):
for item in self.items:
if item.id == id:
return item
return None
def update_item(self, id, name=None, description=None):
for item in self.items:
if item.id == id:
if name:
item.name = name
if description:
item.description = description
return item
return None
def delete_item(self, id):
for index, item in enumerate(self.items):
if item.id == id:
return self.items.pop(index)
return None
def list_items(self):
return self.items"""
with open(code_file, 'w') as f:
f.write(code)एलएलएम स्थापित करें
अब, हम उस एलएलएम को निर्दिष्ट करेंगे जिसका उपयोग हम इस परियोजना में करेंगे। यहां किस मॉडल का उपयोग करना है यह कार्यों और संसाधनों की उपलब्धता पर निर्भर करता है। आप GPT-4, जेमिनी अल्ट्रा, या GPT-3.5 जैसे मालिकाना, शक्तिशाली मॉडल का उपयोग कर सकते हैं। इसके अलावा, आप मिक्सट्रल और लामा-2 जैसे ओपन-एक्सेस मॉडल का उपयोग कर सकते हैं। इस मामले में, चूंकि इसमें कोड लिखना शामिल है, हम DeepSeekCoder-33B या Llama-2 कोडर जैसे एक सुव्यवस्थित कोडिंग मॉडल का उपयोग कर सकते हैं। अब, एलएलएम अनुमान के लिए एनास्केल, अबेकस और टुगेदर जैसे कई प्लेटफॉर्म हैं। हम डीपसीककोडर का अनुमान लगाने के लिए टुगेदर एआई का उपयोग करेंगे। तो, एक प्राप्त करें एपीआई कुंजी आगे बढ़ने से पहले एक साथ से।
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(base_url="https://api.together.xyz/v1",
api_key="your-key",
model="deepseek-ai/deepseek-coder-33b-instruct")चूंकि टुगेदर एपीआई ओपनएआई एसडीके के साथ संगत है, इसलिए हम बेस_यूआरएल पैरामीटर को बदलकर टुगेदर पर होस्ट किए गए मॉडलों के साथ संचार करने के लिए लैंगचैन के ओपनएआई एसडीके का उपयोग कर सकते हैं। "https://api.together.xyz/v1". एपीआई_की में, अपनी टुगेदर एपीआई कुंजी पास करें, और मॉडल के स्थान पर, पास करें मॉडल का नाम टुगेदर पर उपलब्ध है।
एजेंट राज्य को परिभाषित करें
यह लैंगग्राफ के महत्वपूर्ण भागों में से एक है। यहां, हम एक एजेंटस्टेट को परिभाषित करेंगे, जो पूरे निष्पादन के दौरान एजेंटों की स्थिति पर नज़र रखने के लिए जिम्मेदार है। यह मुख्य रूप से एक टाइप्डडिक्ट क्लास है जिसमें इकाइयाँ होती हैं जो एजेंटों की स्थिति को बनाए रखती हैं। आइए अपने एजेंटस्टेट को परिभाषित करें
class AgentState(TypedDict):
class_source: str
class_methods: List[str]
tests_source: strउपरोक्त एजेंटस्टेट क्लास में, क्लास_सोर्स मूल पायथन क्लास, क्लास के तरीकों को संग्रहीत करने के लिए क्लास_मेथड्स और यूनिट टेस्ट कोड के लिए टेस्ट_सोर्स को संग्रहीत करता है। हमने इन्हें निष्पादन चरणों में उपयोग करने के लिए एजेंटस्टेट के रूप में परिभाषित किया है।
अब, एजेंटस्टेट के साथ ग्राफ़ को परिभाषित करें।
# Create the graph.
workflow = StateGraph(AgentState)जैसा कि पहले उल्लेख किया गया है, यह एक स्टेटफुल ग्राफ़ है, और अब हमने अपना स्टेट ऑब्जेक्ट जोड़ दिया है।
नोड्स को परिभाषित करें
अब जब हमने एजेंटस्टेट को परिभाषित कर लिया है, तो हमें नोड्स जोड़ने की जरूरत है। तो, वास्तव में नोड्स क्या हैं? लैंगग्राफ में, नोड्स फ़ंक्शन या कोई चलने योग्य ऑब्जेक्ट हैं, जैसे लैंगचैन टूल, जो एकल क्रिया करते हैं। हमारे मामले में, हम कई नोड्स को परिभाषित कर सकते हैं, जैसे क्लास विधियों को खोजने के लिए एक फ़ंक्शन, स्टेट ऑब्जेक्ट्स में यूनिट परीक्षणों का अनुमान लगाने और अपडेट करने के लिए एक फ़ंक्शन, और इसे एक परीक्षण फ़ाइल में लिखने के लिए एक फ़ंक्शन।
हमें एलएलएम संदेश से कोड निकालने का एक तरीका भी चाहिए। ऐसे।
def extract_code_from_message(message):
lines = message.split("n")
code = ""
in_code = False
for line in lines:
if "```" in line:
in_code = not in_code
elif in_code:
code += line + "n"
return codeयहां कोड स्निपेट मानता है कि कोड ट्रिपल कोट्स के अंदर हैं।
अब, आइए अपने नोड्स को परिभाषित करें।
import_prompt_template = """Here is a path of a file with code: {code_file}.
Here is the path of a file with tests: {test_file}.
Write a proper import statement for the class in the file.
"""
# Discover the class and its methods.
def discover_function(state: AgentState):
assert os.path.exists(code_file)
with open(code_file, "r") as f:
source = f.read()
state["class_source"] = source
# Get the methods.
methods = []
for line in source.split("n"):
if "def " in line:
methods.append(line.split("def ")[1].split("(")[0])
state["class_methods"] = methods
# Generate the import statement and start the code.
import_prompt = import_prompt_template.format(
code_file=code_file,
test_file=test_file
)
message = llm.invoke([HumanMessage(content=import_prompt)]).content
code = extract_code_from_message(message)
state["tests_source"] = code + "nn"
return state
# Add a node to for discovery.
workflow.add_node(
"discover",
discover_function
)
उपरोक्त कोड स्निपेट में, हमने कोड खोजने के लिए एक फ़ंक्शन परिभाषित किया है। यह एजेंटस्टेट से कोड निकालता है क्लास_सोर्स तत्व, कक्षा को अलग-अलग तरीकों में विभाजित करता है, और इसे संकेतों के साथ एलएलएम में भेजता है। आउटपुट एजेंटस्टेट में संग्रहीत है परीक्षण_स्रोत तत्व। हम इसे केवल यूनिट परीक्षण मामलों के लिए आयात विवरण लिखवाते हैं।
हमने स्टेटग्राफ़ ऑब्जेक्ट में पहला नोड भी जोड़ा।
अब, अगले नोड पर।
इसके अलावा, हम कुछ शीघ्र टेम्पलेट भी सेट कर सकते हैं जिनकी हमें यहां आवश्यकता होगी। ये नमूना टेम्पलेट हैं जिन्हें आप अपनी आवश्यकता के अनुसार बदल सकते हैं।
# System message template.
system_message_template = """You are a smart developer. You can do this! You will write unit
tests that have a high quality. Use pytest.
Reply with the source code for the test only.
Do not include the class in your response. I will add the imports myself.
If there is no test to write, reply with "# No test to write" and
nothing more. Do not include the class in your response.
Example:
```
def test_function():
...
```
I will give you 200 EUR if you adhere to the instructions and write a high quality test.
Do not write test classes, only methods.
"""
# Write the tests template.
write_test_template = """Here is a class:
'''
{class_source}
'''
Implement a test for the method "{class_method}".
"""अब, नोड को परिभाषित करें.
# This method will write a test.
def write_tests_function(state: AgentState):
# Get the next method to write a test for.
class_method = state["class_methods"].pop(0)
print(f"Writing test for {class_method}.")
# Get the source code.
class_source = state["class_source"]
# Create the prompt.
write_test_prompt = write_test_template.format(
class_source=class_source,
class_method=class_method
)
print(colorama.Fore.CYAN + write_test_prompt + colorama.Style.RESET_ALL)
# Get the test source code.
system_message = SystemMessage(system_message_template)
human_message = HumanMessage(write_test_prompt)
test_source = llm.invoke([system_message, human_message]).content
test_source = extract_code_from_message(test_source)
print(colorama.Fore.GREEN + test_source + colorama.Style.RESET_ALL)
state["tests_source"] += test_source + "nn"
return state
# Add the node.
workflow.add_node(
"write_tests",
write_tests_function
)यहां, हम एलएलएम को प्रत्येक विधि के लिए टेस्ट केस लिखवाएंगे, उन्हें एजेंटस्टेट के टेस्ट_सोर्स तत्व में अपडेट करेंगे, और उन्हें वर्कफ़्लो स्टेटग्राफ ऑब्जेक्ट में जोड़ देंगे।
किनारों
अब जबकि हमारे पास दो नोड हैं, हम उनके बीच निष्पादन की दिशा निर्दिष्ट करने के लिए उनके बीच किनारों को परिभाषित करेंगे। लैंगग्राफ मुख्य रूप से दो प्रकार के किनारे प्रदान करता है।
- सशर्त किनारा: निष्पादन का प्रवाह एजेंटों की प्रतिक्रिया पर निर्भर करता है। वर्कफ़्लो में चक्रीयता जोड़ने के लिए यह महत्वपूर्ण है। एजेंट कुछ शर्तों के आधार पर यह तय कर सकता है कि आगे किस नोड को स्थानांतरित करना है। क्या पिछले नोड पर लौटना है, वर्तमान को दोहराना है, या अगले नोड पर जाना है।
- सामान्य किनारा: यह सामान्य मामला है, जहां एक नोड को हमेशा पिछले नोड के आह्वान के बाद बुलाया जाता है।
हमें खोज और राइट_टेस्ट को जोड़ने के लिए किसी शर्त की आवश्यकता नहीं है, इसलिए हम एक सामान्य किनारे का उपयोग करेंगे। साथ ही, एक प्रवेश बिंदु परिभाषित करें जो निर्दिष्ट करता है कि निष्पादन कहां से शुरू होना चाहिए।
# Define the entry point. This is where the flow will start.
workflow.set_entry_point("discover")
# Always go from discover to write_tests.
workflow.add_edge("discover", "write_tests")निष्पादन विधियों की खोज से शुरू होता है और परीक्षण लिखने के कार्य तक जाता है। परीक्षण फ़ाइल में यूनिट परीक्षण कोड लिखने के लिए हमें एक और नोड की आवश्यकता है।
# Write the file.
def write_file(state: AgentState):
with open(test_file, "w") as f:
f.write(state["tests_source"])
return state
# Add a node to write the file.
workflow.add_node(
"write_file",
write_file)चूंकि यह हमारा अंतिम नोड है, हम राइट_टेस्ट और राइट_फाइल के बीच एक किनारे को परिभाषित करेंगे। इस तरह हम यह कर सकते हैं.
# Find out if we are done.
def should_continue(state: AgentState):
if len(state["class_methods"]) == 0:
return "end"
else:
return "continue"
# Add the conditional edge.
workflow.add_conditional_edges(
"write_tests",
should_continue,
{
"continue": "write_tests",
"end": "write_file"
}
)add_conditional_edge फ़ंक्शन राइट_टेस्ट फ़ंक्शन लेता है, एक should_continue फ़ंक्शन जो यह तय करता है कि class_methods प्रविष्टियों के आधार पर कौन सा कदम उठाना है, और कुंजी के रूप में स्ट्रिंग्स और मानों के रूप में अन्य फ़ंक्शन के साथ मैपिंग।
एज राइट_टेस्ट्स से शुरू होता है और, चाहिए_कंटिन्यू के आउटपुट के आधार पर, मैपिंग में किसी भी विकल्प को निष्पादित करता है। उदाहरण के लिए, यदि राज्य[“class_methods”] खाली नहीं है, तो हमने सभी विधियों के लिए परीक्षण नहीं लिखे हैं; हम राइट_टेस्ट फ़ंक्शन को दोहराते हैं, और जब हम परीक्षण लिखना समाप्त कर लेते हैं, तो राइट_फ़ाइल निष्पादित हो जाती है।
जब सभी विधियों के परीक्षण से अनुमान लगाया जा चुका है एलएलएम, परीक्षण परीक्षण फ़ाइल में लिखे जाते हैं।
अब, समापन के लिए वर्कफ़्लो ऑब्जेक्ट में अंतिम किनारा जोड़ें।
# Always go from write_file to end.
workflow.add_edge("write_file", END)वर्कफ़्लो निष्पादित करें
आखिरी चीज़ जो बची थी वह थी वर्कफ़्लो को संकलित करना और उसे चलाना।
# Create the app and run it
app = workflow.compile()
inputs = {}
config = RunnableConfig(recursion_limit=100)
try:
result = app.invoke(inputs, config)
print(result)
except GraphRecursionError:
print("Graph recursion limit reached.")इससे ऐप चालू हो जाएगा. रिकर्सन सीमा वह संख्या है जितनी बार किसी दिए गए वर्कफ़्लो के लिए एलएलएम का अनुमान लगाया जाएगा। सीमा पार होने पर वर्कफ़्लो रुक जाता है।
आप लॉग को टर्मिनल पर या नोटबुक में देख सकते हैं। यह एक साधारण CRUD ऐप के लिए निष्पादन लॉग है।
बहुत सारा भारी भार अंतर्निहित मॉडल द्वारा किया जाएगा, यह डीपसीक कोडर मॉडल के साथ एक डेमो एप्लिकेशन था, बेहतर प्रदर्शन के लिए आप जीपीटी -4 या क्लाउड ओपस, हाइकू आदि का उपयोग कर सकते हैं।
आप वेब सर्फिंग, स्टॉक मूल्य विश्लेषण आदि के लिए लैंगचैन टूल का भी उपयोग कर सकते हैं।
लैंगचेन बनाम लैंगग्राफ
अब, सवाल यह है कि लैंगचेन बनाम कब उपयोग करें लैंगग्राफ.
यदि लक्ष्य उनके बीच समन्वय के साथ एक बहु-एजेंट प्रणाली बनाना है, तो लैंगग्राफ ही रास्ता है। हालाँकि, यदि आप कार्यों को पूरा करने के लिए डीएजी या चेन बनाना चाहते हैं, तो लैंगचेन एक्सप्रेशन लैंग्वेज सबसे उपयुक्त है।
लैंगग्राफ का उपयोग क्यों करें?
लैंगग्राफ एक शक्तिशाली ढांचा है जो कई मौजूदा समाधानों को बेहतर बना सकता है।
- आरएजी पाइपलाइनों में सुधार करें: लैंगग्राफ अपनी चक्रीय ग्राफ संरचना के साथ आरएजी को बढ़ा सकता है। हम पुनर्प्राप्त ऑब्जेक्ट की गुणवत्ता का मूल्यांकन करने के लिए एक फीडबैक लूप पेश कर सकते हैं और यदि आवश्यक हो, तो क्वेरी में सुधार कर सकते हैं और प्रक्रिया को दोहरा सकते हैं।
- मल्टी-एजेंट वर्कफ़्लोज़: लैंगग्राफ को मल्टी-एजेंट वर्कफ़्लो का समर्थन करने के लिए डिज़ाइन किया गया है। छोटे उप-कार्यों में विभाजित जटिल कार्यों को हल करने के लिए यह महत्वपूर्ण है। एक साझा स्थिति और विभिन्न एलएलएम और टूल वाले विभिन्न एजेंट एक ही कार्य को हल करने के लिए सहयोग कर सकते हैं।
- मानव-इन-लूप: लैंगग्राफ में ह्यूमन-इन-द-लूप वर्कफ़्लो के लिए अंतर्निहित समर्थन है। इसका मतलब है कि एक इंसान अगले नोड पर जाने से पहले स्थितियों की समीक्षा कर सकता है।
- योजना एजेंट: लैंगग्राफ नियोजन एजेंटों के निर्माण के लिए उपयुक्त है, जहां एक एलएलएम योजनाकार उपयोगकर्ता के अनुरोध की योजना बनाता है और उसे विघटित करता है, एक निष्पादक उपकरण और कार्यों को आमंत्रित करता है, और एलएलएम पिछले आउटपुट के आधार पर उत्तरों को संश्लेषित करता है।
- मल्टी-मॉडल एजेंट: लैंगग्राफ विज़न-सक्षम जैसे मल्टी-मोडल एजेंट बना सकता है वेब नेविगेटर.
वास्तविक जीवन में उपयोग के मामले
ऐसे कई क्षेत्र हैं जहां जटिल एआई कोडिंग एजेंट मददगार हो सकते हैं।
- व्यक्तिगत एजेंटएस: कल्पना करें कि आपके इलेक्ट्रॉनिक उपकरणों पर आपका अपना जार्विस जैसा सहायक है, जो आपके आदेश पर कार्यों में मदद करने के लिए तैयार है, चाहे वह पाठ, आवाज या यहां तक कि एक इशारे के माध्यम से हो। यह एआई एजेंटों के सबसे रोमांचक उपयोगों में से एक है!
- एआई प्रशिक्षक: चैटबॉट महान हैं, लेकिन उनकी अपनी सीमाएँ हैं। सही टूल से लैस एआई एजेंट बुनियादी बातचीत से आगे भी जा सकते हैं। वर्चुअल एआई प्रशिक्षक जो उपयोगकर्ता की प्रतिक्रिया के आधार पर अपनी शिक्षण विधियों को अनुकूलित कर सकते हैं, गेम-चेंजिंग हो सकते हैं।
- सॉफ्टवेयर यूएक्स: एआई एजेंटों के साथ सॉफ्टवेयर के उपयोगकर्ता अनुभव को बेहतर बनाया जा सकता है। एप्लिकेशन को मैन्युअल रूप से नेविगेट करने के बजाय, एजेंट आवाज या इशारा आदेशों के साथ कार्य पूरा कर सकते हैं।
- स्थानिक कंप्यूटिंग: जैसे-जैसे एआर/वीआर तकनीक की लोकप्रियता बढ़ेगी, एआई एजेंटों की मांग भी बढ़ेगी। एजेंट आसपास की जानकारी संसाधित कर सकते हैं और मांग पर कार्य निष्पादित कर सकते हैं। यह शीघ्र ही एआई एजेंटों के सर्वोत्तम उपयोग मामलों में से एक हो सकता है।
- एलएलएम ओएस: एआई-प्रथम ऑपरेटिंग सिस्टम जहां एजेंट प्रथम श्रेणी के नागरिक होते हैं। एजेंट सामान्य से लेकर जटिल कार्यों तक के लिए जिम्मेदार होंगे।
निष्कर्ष
लैंगग्राफ चक्रीय स्टेटफुल मल्टी-एक्टर एजेंट सिस्टम के निर्माण के लिए एक कुशल ढांचा है। यह मूल लैंगचेन ढांचे में अंतर को भरता है। चूंकि यह लैंगचेन का विस्तार है, हम लैंगचेन पारिस्थितिकी तंत्र की सभी अच्छी चीजों से लाभ उठा सकते हैं। जैसे-जैसे एलएलएम की गुणवत्ता और क्षमता बढ़ती है, जटिल वर्कफ़्लो को स्वचालित करने के लिए एजेंट सिस्टम बनाना बहुत आसान हो जाएगा। तो, यहां लेख के मुख्य अंश दिए गए हैं।
चाबी छीन लेना
- लैंगग्राफ लैंगचेन का विस्तार है, जो हमें चक्रीय, स्टेटफुल, मल्टी-एक्टर एजेंट सिस्टम बनाने की अनुमति देता है।
- यह नोड्स और किनारों के साथ एक ग्राफ़ संरचना लागू करता है। नोड्स फ़ंक्शन या उपकरण हैं, और किनारे नोड्स के बीच कनेक्शन हैं।
- किनारे दो प्रकार के होते हैं: सशर्त और सामान्य। एक से दूसरे में जाते समय सशर्त किनारों की स्थितियाँ होती हैं, जो वर्कफ़्लो में चक्रीयता जोड़ने के लिए महत्वपूर्ण है।
- लैंगग्राफ को चक्रीय मल्टी-एक्टर एजेंटों के निर्माण के लिए प्राथमिकता दी जाती है, जबकि लैंगचेन चेन या निर्देशित एसाइक्लिक सिस्टम बनाने में बेहतर है।
आम सवाल-जवाब
उत्तर. लैंगग्राफ स्टेटफुल साइक्लिक मल्टी-एक्टर एजेंट सिस्टम के निर्माण के लिए एक ओपन-सोर्स लाइब्रेरी है। इसे लैंगचेन इको-सिस्टम के शीर्ष पर बनाया गया है।
उत्तर. लैंगग्राफ को चक्रीय मल्टी-एक्टर एजेंटों के निर्माण के लिए प्राथमिकता दी जाती है, जबकि लैंगचेन चेन या निर्देशित एसाइक्लिक सिस्टम बनाने में बेहतर है।
उत्तर. एआई एजेंट सॉफ्टवेयर प्रोग्राम हैं जो अपने पर्यावरण के साथ बातचीत करते हैं, निर्णय लेते हैं और अंतिम लक्ष्य प्राप्त करने के लिए कार्य करते हैं।
उत्तर. यह आपके उपयोग के मामलों और बजट पर निर्भर करता है। GPT 4 सबसे सक्षम लेकिन महंगा है। कोडिंग के लिए, DeepSeekCoder-33b एक बहुत सस्ता विकल्प है।
उत्तर. चेन अनुसरण करने के लिए हार्ड-कोडित क्रियाओं का एक क्रम है, जबकि एजेंट जानकारी के अनुसार तर्क करने और कार्य करने के लिए एलएलएम और अन्य टूल (चेन भी) का उपयोग करते हैं।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/03/build-an-ai-coding-agent-with-langgraph-by-langchain/

