बड़ी मात्रा में पाठ से सटीक और व्यावहारिक उत्तरों को अनलॉक करना बड़े भाषा मॉडल (एलएलएम) द्वारा सक्षम एक रोमांचक क्षमता है। एलएलएम अनुप्रयोगों का निर्माण करते समय, मॉडल को प्रासंगिक संदर्भ प्रदान करने के लिए बाहरी डेटा स्रोतों को कनेक्ट करना और क्वेरी करना अक्सर आवश्यक होता है। एक लोकप्रिय दृष्टिकोण क्यू एंड ए सिस्टम बनाने के लिए रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) का उपयोग करना है जो जटिल जानकारी को समझता है और प्रश्नों के लिए प्राकृतिक प्रतिक्रिया प्रदान करता है। आरएजी मॉडलों को विशाल ज्ञान आधारों का उपयोग करने और चैटबॉट्स और एंटरप्राइज सर्च असिस्टेंट जैसे अनुप्रयोगों के लिए मानव-जैसे संवाद प्रदान करने की अनुमति देता है।
इस पोस्ट में, हम यह पता लगाएंगे कि शक्ति का उपयोग कैसे किया जाए लामाइंडेक्स, लामा 2-70बी-चैट, तथा लैंगचैन शक्तिशाली Q&A एप्लिकेशन बनाने के लिए। इन अत्याधुनिक प्रौद्योगिकियों के साथ, आप टेक्स्ट कॉर्पोरा को ग्रहण कर सकते हैं, महत्वपूर्ण ज्ञान को अनुक्रमित कर सकते हैं और ऐसे टेक्स्ट उत्पन्न कर सकते हैं जो उपयोगकर्ताओं के प्रश्नों का सटीक और स्पष्ट रूप से उत्तर देता है।
लामा 2-70बी-चैट
लामा 2-70बी-चैट एक शक्तिशाली एलएलएम है जो अग्रणी मॉडलों के साथ प्रतिस्पर्धा करता है। यह दो ट्रिलियन टेक्स्ट टोकन पर पूर्व-प्रशिक्षित है, और मेटा द्वारा उपयोगकर्ताओं को चैट सहायता के लिए उपयोग करने का इरादा है। प्री-ट्रेनिंग डेटा सार्वजनिक रूप से उपलब्ध डेटा से प्राप्त किया जाता है और सितंबर 2022 तक समाप्त होता है, और फाइन-ट्यूनिंग डेटा जुलाई 2023 तक समाप्त होता है। मॉडल की प्रशिक्षण प्रक्रिया, सुरक्षा विचारों, सीखने और इच्छित उपयोगों के बारे में अधिक जानकारी के लिए, पेपर देखें लामा 2: ओपन फाउंडेशन और फाइन-ट्यून्ड चैट मॉडल. लामा 2 मॉडल उपलब्ध हैं अमेज़न SageMaker जम्पस्टार्ट त्वरित और सीधी तैनाती के लिए.
लामाइंडेक्स
लामाइंडेक्स एक डेटा फ्रेमवर्क है जो एलएलएम एप्लिकेशन बनाने में सक्षम बनाता है। यह उपकरण प्रदान करता है जो आपके मौजूदा डेटा को विभिन्न स्रोतों और प्रारूपों (पीडीएफ, दस्तावेज़, एपीआई, एसक्यूएल, और अधिक) के साथ अंतर्ग्रहण करने के लिए डेटा कनेक्टर प्रदान करता है। चाहे आपके पास डेटाबेस में या पीडीएफ में संग्रहीत डेटा हो, LlamaIndex उस डेटा को एलएलएम के लिए उपयोग में लाना आसान बनाता है। जैसा कि हम इस पोस्ट में प्रदर्शित करते हैं, LlamaIndex API डेटा एक्सेस को आसान बनाता है और आपको शक्तिशाली कस्टम LLM एप्लिकेशन और वर्कफ़्लो बनाने में सक्षम बनाता है।
यदि आप एलएलएम के साथ प्रयोग और निर्माण कर रहे हैं, तो आप संभवतः लैंगचेन से परिचित हैं, जो एलएलएम-संचालित अनुप्रयोगों के विकास और तैनाती को सरल बनाते हुए एक मजबूत ढांचा प्रदान करता है। लैंगचेन के समान, LlamaIndex कई टूल प्रदान करता है, जिसमें डेटा कनेक्टर, डेटा इंडेक्स, इंजन और डेटा एजेंट, साथ ही टूल और अवलोकन, ट्रेसिंग और मूल्यांकन जैसे एप्लिकेशन एकीकरण शामिल हैं। LlamaIndex डेटा और शक्तिशाली एलएलएम के बीच अंतर को पाटने, उपयोगकर्ता के अनुकूल सुविधाओं के साथ डेटा कार्यों को सुव्यवस्थित करने पर केंद्रित है। LlamaIndex को विशेष रूप से RAG जैसे खोज और पुनर्प्राप्ति अनुप्रयोगों के निर्माण के लिए डिज़ाइन और अनुकूलित किया गया है, क्योंकि यह LLM को क्वेरी करने और प्रासंगिक दस्तावेज़ों को पुनर्प्राप्त करने के लिए एक सरल इंटरफ़ेस प्रदान करता है।
समाधान अवलोकन
इस पोस्ट में, हम प्रदर्शित करते हैं कि LlamaIndex और LLM का उपयोग करके RAG-आधारित एप्लिकेशन कैसे बनाया जाए। निम्नलिखित आरेख निम्नलिखित अनुभागों में उल्लिखित इस समाधान की चरण-दर-चरण वास्तुकला को दर्शाता है।
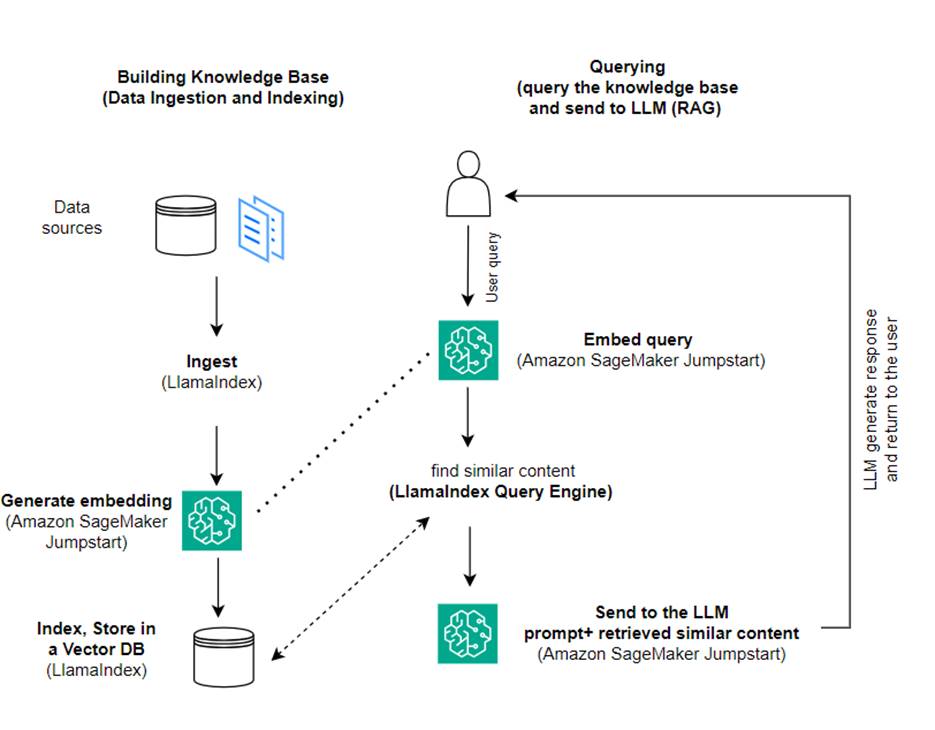
RAG अधिक व्यावहारिक प्रतिक्रियाएँ उत्पन्न करने के लिए सूचना पुनर्प्राप्ति को प्राकृतिक भाषा निर्माण के साथ जोड़ता है। संकेत मिलने पर, RAG सबसे पहले इनपुट के लिए सबसे प्रासंगिक उदाहरण प्राप्त करने के लिए टेक्स्ट कॉर्पोरा की खोज करता है। प्रतिक्रिया निर्माण के दौरान, मॉडल अपनी क्षमताओं को बढ़ाने के लिए इन उदाहरणों पर विचार करता है। प्रासंगिक पुनर्प्राप्त अंशों को शामिल करके, आरएजी प्रतिक्रियाएं बुनियादी जेनरेटर मॉडल की तुलना में अधिक तथ्यात्मक, सुसंगत और संदर्भ के अनुरूप होती हैं। यह पुनर्प्राप्ति-उत्पन्न ढांचा पुनर्प्राप्ति और पीढ़ी दोनों की ताकत का लाभ उठाता है, पुनरावृत्ति और संदर्भ की कमी जैसे मुद्दों को संबोधित करने में मदद करता है जो शुद्ध ऑटोरेग्रेसिव वार्तालाप मॉडल से उत्पन्न हो सकते हैं। आरएजी प्रासंगिक, उच्च-गुणवत्ता वाली प्रतिक्रियाओं के साथ संवादी एजेंटों और एआई सहायकों के निर्माण के लिए एक प्रभावी दृष्टिकोण पेश करता है।
समाधान के निर्माण में निम्नलिखित चरण शामिल हैं:
- सेट अप अमेज़ॅन सैजमेकर स्टूडियो विकास परिवेश के रूप में और आवश्यक निर्भरताएँ स्थापित करें।
- अमेज़ॅन सेजमेकर जम्पस्टार्ट हब से एक एम्बेडिंग मॉडल तैनात करें।
- हमारे बाहरी ज्ञान आधार के रूप में उपयोग करने के लिए प्रेस विज्ञप्तियाँ डाउनलोड करें।
- क्वेरी करने और प्रॉम्प्ट में अतिरिक्त संदर्भ जोड़ने में सक्षम होने के लिए प्रेस विज्ञप्तियों से एक इंडेक्स बनाएं।
- ज्ञान आधार पर प्रश्न पूछें.
- LlamaIndex और LangChain एजेंटों का उपयोग करके एक प्रश्नोत्तर एप्लिकेशन बनाएं।
इस पोस्ट में सभी कोड उपलब्ध हैं गीथहब रेपो.
.. पूर्वापेक्षाएँ
इस उदाहरण के लिए, आपको SageMaker डोमेन और उपयुक्त AWS खाते की आवश्यकता है AWS पहचान और अभिगम प्रबंधन (आईएएम) अनुमतियाँ। खाता सेटअप निर्देशों के लिए, देखें एडब्ल्यूएस खाता बनाएं. यदि आपके पास पहले से सेजमेकर डोमेन नहीं है, तो देखें अमेज़ॅन सेजमेकर डोमेन एक बनाने के लिए अवलोकन. इस पोस्ट में, हम इसका उपयोग करते हैं AmazonSageMakerFullAccess भूमिका। यह अनुशंसित नहीं है कि आप इस क्रेडेंशियल का उपयोग उत्पादन परिवेश में करें। इसके बजाय, आपको कम से कम विशेषाधिकार वाली अनुमतियों वाली भूमिका बनानी और उसका उपयोग करना चाहिए। आप यह भी पता लगा सकते हैं कि आप इसका उपयोग कैसे कर सकते हैं अमेज़न सैजमेकर रोल मैनेजर सेजमेकर कंसोल के माध्यम से सीधे सामान्य मशीन सीखने की जरूरतों के लिए व्यक्तित्व-आधारित आईएएम भूमिकाएं बनाना और प्रबंधित करना।
इसके अतिरिक्त, आपको कम से कम निम्नलिखित इंस्टेंस आकारों तक पहुंच की आवश्यकता है:
- एमएल.g5.2xबड़ा तैनात करते समय समापन बिंदु उपयोग के लिए गले मिलता हुआ चेहरा जीपीटी-जे टेक्स्ट एम्बेडिंग मॉडल
- एमएल.g5.48xबड़ा लामा 2-चैट मॉडल एंडपॉइंट को तैनात करते समय एंडपॉइंट उपयोग के लिए
अपना कोटा बढ़ाने के लिए, देखें कोटा बढ़ाने की मांग.
सेजमेकर जम्पस्टार्ट का उपयोग करके GPT-J एम्बेडिंग मॉडल तैनात करें
सेजमेकर जम्पस्टार्ट मॉडल को तैनात करते समय यह अनुभाग आपको दो विकल्प देता है। आप दिए गए कोड का उपयोग करके कोड-आधारित परिनियोजन का उपयोग कर सकते हैं, या सेजमेकर जम्पस्टार्ट यूजर इंटरफेस (यूआई) का उपयोग कर सकते हैं।
सेजमेकर पायथन एसडीके के साथ परिनियोजन करें
आप एलएलएम को तैनात करने के लिए सेजमेकर पायथन एसडीके का उपयोग कर सकते हैं, जैसा कि इसमें दिखाया गया है कोड भंडार में उपलब्ध है. निम्नलिखित चरणों को पूरा करें:
- उस इंस्टेंस आकार को सेट करें जिसका उपयोग एम्बेडिंग मॉडल की तैनाती के लिए किया जाना है
instance_type = "ml.g5.2xlarge" - एम्बेडिंग के लिए उपयोग किए जाने वाले मॉडल की आईडी का पता लगाएं। सेजमेकर जम्पस्टार्ट में, इसकी पहचान इस प्रकार की जाती है
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - पूर्व-प्रशिक्षित मॉडल कंटेनर को पुनः प्राप्त करें और इसे अनुमान के लिए तैनात करें।
एम्बेडिंग मॉडल सफलतापूर्वक तैनात होने पर सेजमेकर मॉडल एंडपॉइंट का नाम और निम्नलिखित संदेश लौटाएगा:
सेजमेकर स्टूडियो में सेजमेकर जम्पस्टार्ट के साथ परिनियोजन
स्टूडियो में सेजमेकर जम्पस्टार्ट का उपयोग करके मॉडल को तैनात करने के लिए, निम्नलिखित चरणों को पूरा करें:
- सेजमेकर स्टूडियो कंसोल पर, नेविगेशन फलक में जम्पस्टार्ट चुनें।

- GPT-J 6B एम्बेडिंग FP16 मॉडल खोजें और चुनें।
- परिनियोजन चुनें और परिनियोजन कॉन्फ़िगरेशन को अनुकूलित करें।

- इस उदाहरण के लिए, हमें एक ml.g5.2xlarge इंस्टेंस की आवश्यकता है, जो सेजमेकर जम्पस्टार्ट द्वारा सुझाया गया डिफ़ॉल्ट इंस्टेंस है।
- समापन बिंदु बनाने के लिए फिर से परिनियोजन चुनें।
समापन बिंदु को सेवा में आने में लगभग 5-10 मिनट लगेंगे।

एम्बेडिंग मॉडल को तैनात करने के बाद, सेजमेकर एपीआई के साथ लैंगचेन एकीकरण का उपयोग करने के लिए, आपको इनपुट (कच्चा पाठ) को संभालने और मॉडल का उपयोग करके उन्हें एम्बेडिंग में बदलने के लिए एक फ़ंक्शन बनाने की आवश्यकता है। आप नामक क्लास बनाकर ऐसा करते हैं ContentHandler, जो इनपुट डेटा का JSON लेता है, और टेक्स्ट एम्बेडिंग का JSON लौटाता है: class ContentHandler(EmbeddingsContentHandler).
मॉडल समापन बिंदु नाम को पास करें ContentHandler पाठ को परिवर्तित करने और एम्बेडिंग वापस करने का कार्य:
आप एसडीके के आउटपुट में या सेजमेकर जम्पस्टार्ट यूआई में तैनाती विवरण में एंडपॉइंट नाम का पता लगा सकते हैं।
आप इसका परीक्षण कर सकते हैं ContentHandler फ़ंक्शन और एंडपॉइंट कुछ कच्चे पाठ को इनपुट करके और चलाकर अपेक्षा के अनुरूप काम कर रहे हैं embeddings.embed_query(text) समारोह। आप दिए गए उदाहरण का उपयोग कर सकते हैं text = "Hi! It's time for the beach" या अपना स्वयं का पाठ आज़माएँ.
सेजमेकर जम्पस्टार्ट का उपयोग करके लामा 2-चैट को तैनात और परीक्षण करें
अब आप उस मॉडल को तैनात कर सकते हैं जो आपके उपयोगकर्ताओं के साथ इंटरैक्टिव बातचीत करने में सक्षम है। इस उदाहरण में, हम लामा 2-चैट मॉडल में से एक को चुनते हैं, जिसे इसके माध्यम से पहचाना जाता है
मॉडल को वास्तविक समय के समापन बिंदु पर तैनात करने की आवश्यकता है predictor = my_model.deploy(). सेजमेकर मॉडल का समापन बिंदु नाम लौटाएगा, जिसका उपयोग आप कर सकते हैं endpoint_name बाद में संदर्भ के लिए परिवर्तनीय।
आप परिभाषित करें ए print_dialogue चैट मॉडल पर इनपुट भेजने और उसकी आउटपुट प्रतिक्रिया प्राप्त करने का कार्य। पेलोड में मॉडल के लिए हाइपरपैरामीटर शामिल हैं, जिनमें निम्नलिखित शामिल हैं:
- max_new_tokens - टोकन की अधिकतम संख्या को संदर्भित करता है जो मॉडल अपने आउटपुट में उत्पन्न कर सकता है।
- शीर्ष_पी - टोकन की संचयी संभावना को संदर्भित करता है जिसे मॉडल द्वारा अपने आउटपुट उत्पन्न करते समय बनाए रखा जा सकता है
- तापमान - मॉडल द्वारा उत्पन्न आउटपुट की यादृच्छिकता को संदर्भित करता है। 0 से अधिक या 1 के बराबर तापमान यादृच्छिकता के स्तर को बढ़ाता है, जबकि 0 का तापमान सबसे अधिक संभावित टोकन उत्पन्न करेगा।
आपको अपने उपयोग के मामले के आधार पर अपने हाइपरपैरामीटर का चयन करना चाहिए और उनका उचित परीक्षण करना चाहिए। लामा परिवार जैसे मॉडलों के लिए आपको एक अतिरिक्त पैरामीटर शामिल करने की आवश्यकता होती है जो दर्शाता है कि आपने अंतिम उपयोगकर्ता लाइसेंस अनुबंध (ईयूएलए) को पढ़ और स्वीकार कर लिया है:
मॉडल का परीक्षण करने के लिए, इनपुट पेलोड के सामग्री अनुभाग को बदलें: "content": "what is the recipe of mayonnaise?". आप अपने स्वयं के टेक्स्ट मानों का उपयोग कर सकते हैं और उन्हें बेहतर ढंग से समझने के लिए हाइपरपैरामीटर को अपडेट कर सकते हैं।
एम्बेडिंग मॉडल की तैनाती के समान, आप सेजमेकर जम्पस्टार्ट यूआई का उपयोग करके लामा-70बी-चैट को तैनात कर सकते हैं:
- सेजमेकर स्टूडियो कंसोल पर, चुनें कूदना शुरू करो नेविगेशन फलक में
- खोजें और चुनें
Llama-2-70b-Chat model - EULA स्वीकार करें और चुनें तैनाती, डिफ़ॉल्ट उदाहरण का फिर से उपयोग करना
एम्बेडिंग मॉडल के समान, आप अपने चैट मॉडल के इनपुट और आउटपुट के लिए एक कंटेंट हैंडलर टेम्पलेट बनाकर लैंगचेन एकीकरण का उपयोग कर सकते हैं। इस मामले में, आप इनपुट को उपयोगकर्ता से आने वाले इनपुट के रूप में परिभाषित करते हैं, और इंगित करते हैं कि वे इसके द्वारा नियंत्रित होते हैं system prompt। system prompt किसी विशेष उपयोग के मामले में उपयोगकर्ता की सहायता करने में मॉडल को उसकी भूमिका के बारे में सूचित करता है।
उपरोक्त हाइपरपैरामीटर और कस्टम विशेषताओं (ईयूएलए स्वीकृति) के अलावा, मॉडल को लागू करते समय इस सामग्री हैंडलर को पारित किया जाता है। आप निम्नलिखित कोड का उपयोग करके इन सभी विशेषताओं को पार्स करते हैं:
जब समापन बिंदु उपलब्ध हो, तो आप परीक्षण कर सकते हैं कि यह अपेक्षा के अनुरूप काम कर रहा है। आप अपडेट कर सकते हैं llm("what is amazon sagemaker?") अपने स्वयं के पाठ के साथ. आपको विशिष्ट को परिभाषित करने की भी आवश्यकता है ContentHandler लैंगचेन का उपयोग करके एलएलएम शुरू करना, जैसा कि इसमें दिखाया गया है कोड और निम्नलिखित कोड स्निपेट:
RAG बनाने के लिए LlamaIndex का उपयोग करें
जारी रखने के लिए, RAG एप्लिकेशन बनाने के लिए LlamaIndex इंस्टॉल करें। आप पाइप का उपयोग करके LlamaIndex इंस्टॉल कर सकते हैं: pip install llama_index
अनुक्रमण के लिए आपको सबसे पहले अपना डेटा (ज्ञान आधार) LlamaIndex पर लोड करना होगा। इसमें कुछ चरण शामिल हैं:
- डेटा लोडर चुनें:
LlamaIndex कई डेटा कनेक्टर उपलब्ध कराता है लामाहब सामान्य डेटा प्रकारों जैसे JSON, CSV और टेक्स्ट फ़ाइलों के साथ-साथ अन्य डेटा स्रोतों के लिए, जो आपको विभिन्न प्रकार के डेटासेट को समाहित करने की अनुमति देता है। इस पोस्ट में हम प्रयोग करते हैं SimpleDirectoryReader जैसा कि कोड में दिखाया गया है, कुछ पीडीएफ फाइलों को अंतर्ग्रहण करने के लिए। हमारा डेटा नमूना पीडीएफ संस्करण में दो अमेज़ॅन प्रेस विज्ञप्तियां हैं प्रेस विज्ञप्ति हमारे कोड भंडार में फ़ोल्डर। पीडीएफ़ लोड करने के बाद, आप देख सकते हैं कि उन्हें 11 तत्वों की सूची में बदल दिया गया है।
दस्तावेज़ों को सीधे लोड करने के बजाय, आप उन्हें गुप्त भी कर सकते हैं Document में आपत्ति Node वस्तुओं को सूचकांक में भेजने से पहले। संपूर्ण भेजने के बीच चयन Document सूचकांक पर आपत्ति करना या दस्तावेज़ को इसमें परिवर्तित करना Node अनुक्रमण से पहले ऑब्जेक्ट आपके विशिष्ट उपयोग के मामले और आपके डेटा की संरचना पर निर्भर करता है। नोड्स दृष्टिकोण आम तौर पर लंबे दस्तावेज़ों के लिए एक अच्छा विकल्प है, जहां आप पूरे दस्तावेज़ के बजाय दस्तावेज़ के विशिष्ट हिस्सों को तोड़ना और पुनः प्राप्त करना चाहते हैं। अधिक जानकारी के लिए देखें दस्तावेज़/नोड्स.
- लोडर को इंस्टेंट करें और दस्तावेज़ लोड करें:
यह चरण लोडर वर्ग और किसी भी आवश्यक कॉन्फ़िगरेशन को आरंभ करता है, जैसे कि छिपी हुई फ़ाइलों को अनदेखा करना है या नहीं। अधिक जानकारी के लिए देखें SimpleDirectoryReader.
- लोडर को बुलाओ
load_dataआपकी स्रोत फ़ाइलों और डेटा को पार्स करने और उन्हें LlamaIndex दस्तावेज़ ऑब्जेक्ट में परिवर्तित करने की विधि, जो अनुक्रमण और क्वेरी के लिए तैयार है। आप LlamaIndex की अनुक्रमणिका और पुनर्प्राप्ति क्षमताओं का उपयोग करके डेटा अंतर्ग्रहण और पूर्ण-पाठ खोज की तैयारी को पूरा करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
- सूचकांक बनाएं:
LlamaIndex की मुख्य विशेषता डेटा पर संगठित इंडेक्स बनाने की क्षमता है, जिसे दस्तावेज़ या नोड्स के रूप में दर्शाया जाता है। अनुक्रमण डेटा पर कुशल पूछताछ की सुविधा प्रदान करता है। हम अपना इंडेक्स डिफ़ॉल्ट इन-मेमोरी वेक्टर स्टोर और अपनी परिभाषित सेटिंग कॉन्फ़िगरेशन के साथ बनाते हैं। लामाइंडेक्स सेटिंग एक कॉन्फ़िगरेशन ऑब्जेक्ट है जो LlamaIndex एप्लिकेशन में अनुक्रमण और क्वेरी संचालन के लिए आमतौर पर उपयोग किए जाने वाले संसाधन और सेटिंग्स प्रदान करता है। यह एक सिंगलटन ऑब्जेक्ट के रूप में कार्य करता है, जिससे यह आपको वैश्विक कॉन्फ़िगरेशन सेट करने की अनुमति देता है, साथ ही आपको विशिष्ट घटकों को सीधे उन इंटरफेस (जैसे एलएलएम, एम्बेडिंग मॉडल) में पास करके स्थानीय रूप से ओवरराइड करने की अनुमति देता है जो उनका उपयोग करते हैं। जब कोई विशेष घटक स्पष्ट रूप से प्रदान नहीं किया जाता है, तो LlamaIndex फ्रेमवर्क परिभाषित सेटिंग्स पर वापस आ जाता है Settings वैश्विक डिफ़ॉल्ट के रूप में ऑब्जेक्ट। लैंगचेन के साथ हमारे एम्बेडिंग और एलएलएम मॉडल का उपयोग करने और कॉन्फ़िगर करने के लिए Settings हमें इंस्टॉल करना होगा llama_index.embeddings.langchain और llama_index.llms.langchain. हम कॉन्फ़िगर कर सकते हैं Settings निम्नलिखित कोड के अनुसार ऑब्जेक्ट करें:
डिफ़ॉल्ट रूप से, VectorStoreIndex इन-मेमोरी का उपयोग करता है SimpleVectorStore इसे डिफ़ॉल्ट संग्रहण संदर्भ के भाग के रूप में प्रारंभ किया गया है। वास्तविक जीवन के उपयोग के मामलों में, आपको अक्सर बाहरी वेक्टर स्टोर जैसे कि कनेक्ट करने की आवश्यकता होती है अमेज़न ओपन सर्च सर्विस. अधिक विवरण के लिए, देखें अमेज़ॅन ओपनसर्च सर्वरलेस के लिए वेक्टर इंजन.
अब आप इसका उपयोग करके अपने दस्तावेज़ों पर प्रश्नोत्तर चला सकते हैं query_engine LlamaIndex से. ऐसा करने के लिए, प्रश्नों के लिए आपके द्वारा पहले बनाए गए इंडेक्स को पास करें और अपना प्रश्न पूछें। क्वेरी इंजन डेटा क्वेरी के लिए एक सामान्य इंटरफ़ेस है। यह इनपुट के रूप में एक प्राकृतिक भाषा क्वेरी लेता है और एक समृद्ध प्रतिक्रिया देता है। क्वेरी इंजन आम तौर पर एक या अधिक के ऊपर बनाया जाता है अनुक्रमणिका का उपयोग retrievers.
आप देख सकते हैं कि RAG समाधान प्रदान किए गए दस्तावेज़ों से सही उत्तर प्राप्त करने में सक्षम है:
लैंगचेन टूल्स और एजेंटों का उपयोग करें
Loader कक्षा। लोडर को डेटा को LlamaIndex में या बाद में एक टूल के रूप में लोड करने के लिए डिज़ाइन किया गया है लैंगचेन एजेंट. यह आपको इसे अपने एप्लिकेशन के हिस्से के रूप में उपयोग करने के लिए अधिक शक्ति और लचीलापन देता है। आप अपनी परिभाषा से शुरुआत करें साधन लैंगचेन एजेंट वर्ग से। आप अपने टूल पर जो फ़ंक्शन पास करते हैं, वह LlamaIndex का उपयोग करके आपके दस्तावेज़ों पर बनाए गए इंडेक्स पर सवाल उठाता है।
फिर आप सही प्रकार के एजेंट का चयन करें जिसे आप अपने आरएजी कार्यान्वयन के लिए उपयोग करना चाहते हैं। इस स्थिति में, आप इसका उपयोग करते हैं chat-zero-shot-react-description प्रतिनिधि। इस एजेंट के साथ, एलएलएम प्रतिक्रिया प्रदान करने के लिए उपलब्ध टूल (इस परिदृश्य में, ज्ञान आधार पर आरएजी) का उपयोग करेगा। फिर आप अपना टूल, एलएलएम और एजेंट प्रकार पास करके एजेंट को प्रारंभ करते हैं:
आप एजेंट को वहां से गुजरते हुए देख सकते हैं thoughts, actions, तथा observation , टूल का उपयोग करें (इस परिदृश्य में, अपने अनुक्रमित दस्तावेज़ों को क्वेरी करना); और एक परिणाम लौटाएँ:
आप शुरू से अंत तक कार्यान्वयन कोड संलग्न में पा सकते हैं गीथहब रेपो.
क्लीन अप
अनावश्यक लागतों से बचने के लिए, आप अपने संसाधनों को निम्नलिखित कोड स्निपेट या अमेज़ॅन जंपस्टार्ट यूआई के माध्यम से साफ़ कर सकते हैं।
Boto3 SDK का उपयोग करने के लिए, टेक्स्ट एम्बेडिंग मॉडल एंडपॉइंट और टेक्स्ट जेनरेशन मॉडल एंडपॉइंट, साथ ही एंडपॉइंट कॉन्फ़िगरेशन को हटाने के लिए निम्नलिखित कोड का उपयोग करें:
सेजमेकर कंसोल का उपयोग करने के लिए, निम्नलिखित चरणों को पूरा करें:
- सेजमेकर कंसोल पर, नेविगेशन फलक में अनुमान के अंतर्गत, एंडपॉइंट चुनें
- एम्बेडिंग और टेक्स्ट जेनरेशन एंडपॉइंट खोजें।
- अंतिमबिंदु विवरण पृष्ठ पर, हटाएँ चुनें।
- पुष्टि करने के लिए फिर से हटाएँ चुनें।
निष्कर्ष
खोज और पुनर्प्राप्ति पर केंद्रित उपयोग के मामलों के लिए, LlamaIndex लचीली क्षमताएं प्रदान करता है। यह एलएलएम के लिए अनुक्रमण और पुनर्प्राप्ति में उत्कृष्टता प्राप्त करता है, जिससे यह डेटा की गहन खोज के लिए एक शक्तिशाली उपकरण बन जाता है। LlamaIndex आपको संगठित डेटा इंडेक्स बनाने, विविध एलएलएम का उपयोग करने, बेहतर एलएलएम प्रदर्शन के लिए डेटा बढ़ाने और प्राकृतिक भाषा के साथ डेटा क्वेरी करने में सक्षम बनाता है।
इस पोस्ट ने कुछ प्रमुख LlamaIndex अवधारणाओं और क्षमताओं का प्रदर्शन किया। हमने एम्बेडिंग के लिए GPT-J और RAG एप्लिकेशन बनाने के लिए LLM के रूप में Llama 2-Chat का उपयोग किया, लेकिन आप इसके बजाय किसी भी उपयुक्त मॉडल का उपयोग कर सकते हैं। आप सेजमेकर जम्पस्टार्ट पर उपलब्ध मॉडलों की व्यापक रेंज का पता लगा सकते हैं।
हमने यह भी दिखाया कि कैसे LlamaIndex लैंगचेन जैसे अन्य फ्रेमवर्क के साथ डेटा को कनेक्ट करने, इंडेक्स करने, पुनर्प्राप्त करने और एकीकृत करने के लिए शक्तिशाली, लचीले उपकरण प्रदान कर सकता है। LlamaIndex एकीकरण और लैंगचेन के साथ, आप अधिक शक्तिशाली, बहुमुखी और व्यावहारिक एलएलएम एप्लिकेशन बना सकते हैं।
लेखक के बारे में
 डॉ. रोमिना शरीफपुर अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक वरिष्ठ मशीन लर्निंग और आर्टिफिशियल इंटेलिजेंस सॉल्यूशंस आर्किटेक्ट हैं। उन्होंने एमएल और एआई में प्रगति द्वारा सक्षम नवीन एंड-टू-एंड समाधानों के डिजाइन और कार्यान्वयन का नेतृत्व करते हुए 10 साल से अधिक समय बिताया है। रोमिना की रुचि के क्षेत्र प्राकृतिक भाषा प्रसंस्करण, बड़े भाषा मॉडल और एमएलओपीएस हैं।
डॉ. रोमिना शरीफपुर अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक वरिष्ठ मशीन लर्निंग और आर्टिफिशियल इंटेलिजेंस सॉल्यूशंस आर्किटेक्ट हैं। उन्होंने एमएल और एआई में प्रगति द्वारा सक्षम नवीन एंड-टू-एंड समाधानों के डिजाइन और कार्यान्वयन का नेतृत्व करते हुए 10 साल से अधिक समय बिताया है। रोमिना की रुचि के क्षेत्र प्राकृतिक भाषा प्रसंस्करण, बड़े भाषा मॉडल और एमएलओपीएस हैं।
 निकोल पिंटो सिडनी, ऑस्ट्रेलिया में स्थित एक एआई/एमएल स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट है। स्वास्थ्य देखभाल और वित्तीय सेवाओं में उनकी पृष्ठभूमि उन्हें ग्राहकों की समस्याओं को हल करने में एक अद्वितीय दृष्टिकोण प्रदान करती है। वह मशीन लर्निंग के माध्यम से ग्राहकों को सक्षम बनाने और एसटीईएम में महिलाओं की अगली पीढ़ी को सशक्त बनाने को लेकर उत्साहित हैं।
निकोल पिंटो सिडनी, ऑस्ट्रेलिया में स्थित एक एआई/एमएल स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट है। स्वास्थ्य देखभाल और वित्तीय सेवाओं में उनकी पृष्ठभूमि उन्हें ग्राहकों की समस्याओं को हल करने में एक अद्वितीय दृष्टिकोण प्रदान करती है। वह मशीन लर्निंग के माध्यम से ग्राहकों को सक्षम बनाने और एसटीईएम में महिलाओं की अगली पीढ़ी को सशक्त बनाने को लेकर उत्साहित हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

