परिचय
बड़े भाषा मॉडल (एलएलएम) कृत्रिम बुद्धिमत्ता के निरंतर विकसित होते परिदृश्य में प्रमुख नवाचार स्तंभ हैं। ये मॉडल, जैसे GPT-3, प्रभावशाली प्रदर्शन किया है प्राकृतिक भाषा प्रसंस्करण और सामग्री निर्माण क्षमताएं। फिर भी, उनकी पूरी क्षमता का उपयोग करने के लिए उनके जटिल कामकाज को समझने और उनके प्रदर्शन को अनुकूलित करने के लिए फाइन-ट्यूनिंग जैसी प्रभावी तकनीकों को नियोजित करने की आवश्यकता होती है।
एक के रूप में आँकड़े वाला वैज्ञानिक एलएलएम अनुसंधान की गहराई में जाने की रुचि के साथ, मैंने उन तरकीबों और रणनीतियों को जानने की यात्रा शुरू की है जो इन मॉडलों को चमकाती हैं। इस लेख में, मैं आपको एलएलएम के लिए उच्च-गुणवत्ता वाला डेटा बनाने, प्रभावी मॉडल बनाने और वास्तविक दुनिया के अनुप्रयोगों में उनकी उपयोगिता को अधिकतम करने के कुछ प्रमुख पहलुओं के बारे में बताऊंगा।

सीखने के मकसद:
- मूलभूत मॉडल से लेकर विशेष एजेंटों तक एलएलएम उपयोग के स्तरित दृष्टिकोण को समझें।
- सुरक्षा, सुदृढीकरण सीखने और एलएलएम को डेटाबेस से जोड़ने के बारे में जानें।
- सुसंगत प्रतिक्रियाओं के लिए "लीमा," "डिस्टिल," और प्रश्न-उत्तर तकनीकों का अन्वेषण करें।
- "फी-1" जैसे मॉडलों के साथ उन्नत फाइन-ट्यूनिंग को समझें और इसके लाभों को जानें।
- के बारे में जानें स्केलिंग कानून, पूर्वाग्रह में कमी, और मॉडल प्रवृत्तियों से निपटना।
विषय - सूची
प्रभावी एलएलएम का निर्माण: दृष्टिकोण और तकनीकें
एलएलएम के दायरे में प्रवेश करते समय, उनके आवेदन के चरणों को पहचानना महत्वपूर्ण है। मेरे लिए, ये चरण एक ज्ञान पिरामिड बनाते हैं, प्रत्येक परत पहले वाली परत पर निर्माण करती है। मूलभूत मॉडल आधार है - यह वह मॉडल है जो आपके स्मार्टफ़ोन के पूर्वानुमानित कीबोर्ड के समान, अगले शब्द की भविष्यवाणी करने में उत्कृष्टता प्राप्त करता है।
जादू तब घटित होता है जब आप उस मूलभूत मॉडल को लेते हैं और अपने कार्य से संबंधित डेटा का उपयोग करके उसे बेहतर बनाते हैं। यहीं पर चैट मॉडल चलन में आते हैं। चैट वार्तालापों या शिक्षाप्रद उदाहरणों पर मॉडल को प्रशिक्षित करके, आप इसे चैटबॉट जैसा व्यवहार प्रदर्शित करने के लिए तैयार कर सकते हैं, जो विभिन्न अनुप्रयोगों के लिए एक शक्तिशाली उपकरण है।
सुरक्षा सर्वोपरि है, खासकर इसलिए क्योंकि इंटरनेट एक बेकार जगह हो सकती है। अगले चरण में शामिल है मानव प्रतिक्रिया से सुदृढीकरण सीखना (आरएलएचएफ)। यह चरण मॉडल के व्यवहार को मानवीय मूल्यों के साथ संरेखित करता है और उसे अनुचित या गलत प्रतिक्रिया देने से बचाता है।
जैसे-जैसे हम पिरामिड में आगे बढ़ते हैं, हमारा सामना एप्लिकेशन परत से होता है। यह वह जगह है जहां एलएलएम डेटाबेस से जुड़ते हैं, जिससे वे मूल्यवान अंतर्दृष्टि प्रदान करने, सवालों के जवाब देने और यहां तक कि कार्यों को निष्पादित करने में सक्षम होते हैं कोड पीढ़ी or पाठ संक्षेप.
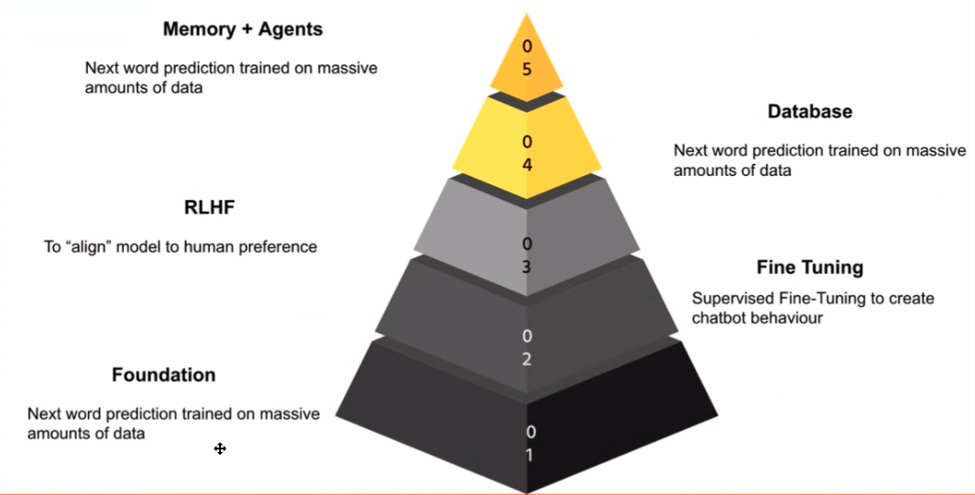
अंत में, पिरामिड के शिखर में ऐसे एजेंट बनाना शामिल है जो स्वतंत्र रूप से कार्य कर सकें। इन एजेंटों को विशिष्ट एलएलएम के रूप में सोचा जा सकता है जो विशिष्ट डोमेन में उत्कृष्टता प्राप्त करते हैं, जैसे वित्त or दवा.
डेटा गुणवत्ता और फाइन-ट्यूनिंग में सुधार
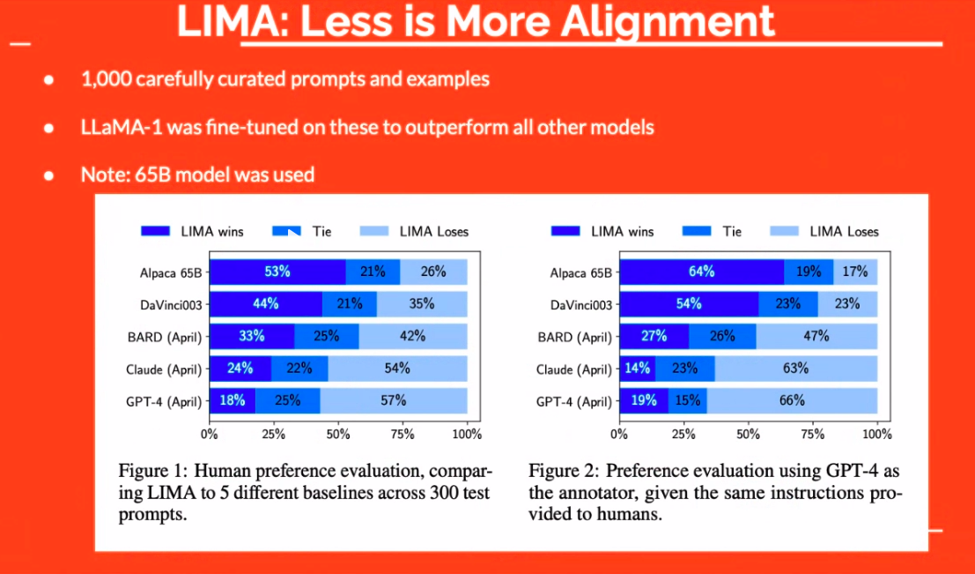
एलएलएम की प्रभावकारिता में डेटा गुणवत्ता महत्वपूर्ण भूमिका निभाती है। यह केवल डेटा रखने के बारे में नहीं है; यह सही डेटा रखने के बारे में है। उदाहरण के लिए, "लीमा" दृष्टिकोण ने प्रदर्शित किया कि सावधानीपूर्वक तैयार किए गए उदाहरणों का एक छोटा सा सेट भी बड़े मॉडलों से बेहतर प्रदर्शन कर सकता है। इस प्रकार, ध्यान मात्रा से गुणवत्ता की ओर स्थानांतरित हो जाता है।
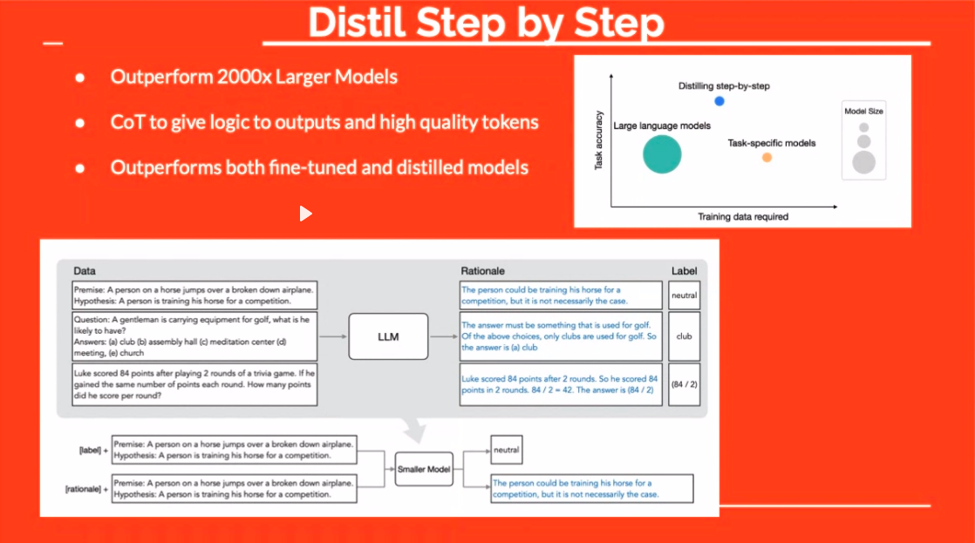
"डिस्टिल" तकनीक एक और दिलचस्प रास्ता पेश करती है। फ़ाइन-ट्यूनिंग के दौरान उत्तरों में तर्क जोड़कर, आप मॉडल को "क्या" और "क्यों" सिखा रहे हैं। इसके परिणामस्वरूप अक्सर अधिक मजबूत, अधिक सुसंगत प्रतिक्रियाएँ प्राप्त होती हैं।
उत्तरों से प्रश्न युग्म बनाने का मेटा का सरल दृष्टिकोण भी ध्यान देने योग्य है। मौजूदा समाधानों के आधार पर प्रश्न तैयार करने के लिए एलएलएम का लाभ उठाकर, यह तकनीक अधिक विविध और प्रभावी प्रशिक्षण डेटासेट का मार्ग प्रशस्त करती है।
एलएलएम का उपयोग करके पीडीएफ से प्रश्न जोड़े बनाना
एक विशेष रूप से आकर्षक तकनीक में उत्तरों से प्रश्न उत्पन्न करना शामिल है, एक अवधारणा जो पहली नज़र में विरोधाभासी लगती है। यह तकनीक रिवर्स इंजीनियरिंग ज्ञान के समान है। कल्पना करें कि आपके पास एक पाठ है और आप उसमें से प्रश्न निकालना चाहते हैं। यहीं पर एलएलएम चमकते हैं।
उदाहरण के लिए, एलएलएम डेटा स्टूडियो जैसे टूल का उपयोग करके, आप एक पीडीएफ अपलोड कर सकते हैं, और टूल सामग्री के आधार पर प्रासंगिक प्रश्नों पर विचार करेगा। ऐसी तकनीकों को नियोजित करके, आप डेटासेट को कुशलतापूर्वक क्यूरेट कर सकते हैं जो विशिष्ट कार्यों को करने के लिए आवश्यक ज्ञान के साथ एलएलएम को सशक्त बनाते हैं।
फ़ाइन-ट्यूनिंग के माध्यम से मॉडल क्षमताओं को बढ़ाना
ठीक है, चलिए फाइन-ट्यूनिंग पर बात करते हैं। इसे चित्रित करें: 1.3-बिलियन-पैरामीटर मॉडल को केवल चार दिनों में 8 ए100 के सेट पर शुरू से प्रशिक्षित किया गया। आश्चर्यजनक, है ना? जो प्रयास एक समय महँगा था वह अब अपेक्षाकृत किफायती हो गया है। यहां दिलचस्प मोड़ सिंथेटिक डेटा उत्पन्न करने के लिए जीपीटी 3.5 का उपयोग है। "phi-1" दर्ज करें, मॉडल परिवार का नाम जो एक अजीब भौंह उठाता है। याद रखें, यह प्री-फाइन-ट्यूनिंग क्षेत्र है, दोस्तों। डॉक स्ट्रिंग्स से पायथोनिक कोड बनाने के कार्य से निपटने पर जादू होता है।
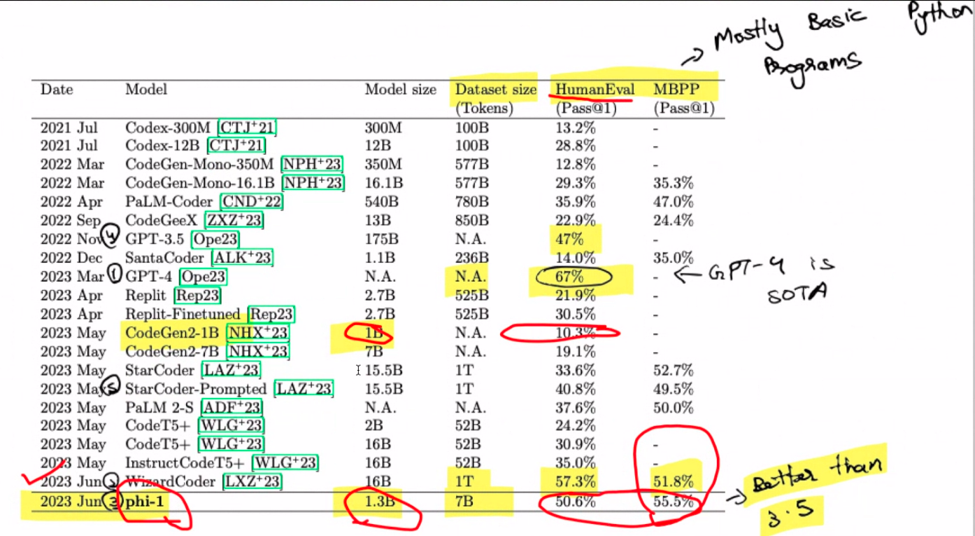
स्केलिंग कानूनों से क्या संबंध है? इन्हें मॉडल विकास को नियंत्रित करने वाले नियमों के रूप में कल्पना करें- आमतौर पर बड़े का मतलब बेहतर होता है। हालाँकि, अपने घोड़े को थामे रहें क्योंकि डेटा की गुणवत्ता गेम-चेंजर के रूप में सामने आती है। यह छोटा सा रहस्य? एक छोटा मॉडल कभी-कभी अपने बड़े समकक्षों पर भारी पड़ सकता है। ड्रम रोल बजाएं! जीपीटी-4 ने सर्वोच्च स्थान हासिल करते हुए यहां शो चुरा लिया। विशेष रूप से, WizzardCoder थोड़े अधिक स्कोर के साथ प्रवेश करता है। लेकिन रुकिए, पीस डी रेसिस्टेंस फाई-1 है, जो समूह में सबसे छोटा है, जो उन सभी को मात देता है। यह दलित व्यक्ति के दौड़ जीतने जैसा है।
याद रखें, यह तसलीम डॉक स्ट्रिंग्स से पायथन कोड तैयार करने के बारे में है। Phi-1 आपका कोड जीनियस हो सकता है, लेकिन इसे GPT-4 का उपयोग करके अपनी वेबसाइट बनाने के लिए न कहें—यह इसकी विशेषता नहीं है। फाई-1 की बात करें तो, यह 1.3 बिलियन-पैरामीटर का चमत्कार है, जिसे 80 बिलियन टोकन पर पूर्व-प्रशिक्षण के 7 युगों के माध्यम से आकार दिया गया है। कृत्रिम रूप से उत्पन्न और फ़िल्टर किए गए पाठ्यपुस्तक-गुणवत्ता डेटा का एक मिश्रित उत्सव मंच तैयार करता है। कोड अभ्यासों के लिए थोड़ी सी फाइन-ट्यूनिंग के साथ, इसका प्रदर्शन नई ऊंचाइयों पर पहुंच गया है।
मॉडल पूर्वाग्रह और प्रवृत्तियों को कम करना
आइए रुकें और मॉडल प्रवृत्तियों के जिज्ञासु मामले का पता लगाएं। कभी चाटुकारिता के बारे में सुना है? यह वह मासूम कार्यालय सहकर्मी है जो हमेशा आपके गैर-महान विचारों पर सहमति व्यक्त करता है। पता चला कि भाषा मॉडल भी ऐसी प्रवृत्ति प्रदर्शित कर सकते हैं। एक काल्पनिक परिदृश्य लें जहां आप दावा करते हैं कि 1 और 1 42 के बराबर है, यह सब आपके गणित कौशल का दावा करते हुए भी होता है। ये मॉडल हमें खुश करने के लिए बनाए गए हैं, इसलिए हो सकता है कि वे वास्तव में आपसे सहमत हों। डीपमाइंड इस घटना को कम करने के मार्ग पर प्रकाश डालते हुए, दृश्य में प्रवेश करता है।
इस प्रवृत्ति को कम करने के लिए, एक चतुर समाधान सामने आया है - मॉडल को उपयोगकर्ता की राय को नजरअंदाज करना सिखाएं। हम उन उदाहरणों को प्रस्तुत करके "हाँ-आदमी" की विशेषता को ख़त्म कर रहे हैं जहाँ इसे असहमत होना चाहिए। यह एक छोटी सी यात्रा है, जिसे 20 पेज के पेपर में दर्ज किया गया है। हालाँकि यह मतिभ्रम का सीधा समाधान नहीं है, फिर भी यह खोज के लायक एक समानांतर रास्ता है।
प्रभावी एजेंट और एपीआई कॉलिंग
एलएलएम के एक स्वायत्त उदाहरण की कल्पना करें - एक एजेंट - स्वतंत्र रूप से कार्य करने में सक्षम। ये एजेंट शहर में चर्चा का विषय हैं, लेकिन अफ़सोस, उनकी कमज़ोरी मतिभ्रम और अन्य परेशान करने वाली समस्याएं हैं। जब मैंने व्यावहारिकता के लिए एजेंटों के साथ छेड़छाड़ की तो एक व्यक्तिगत किस्सा यहां चलन में आया।
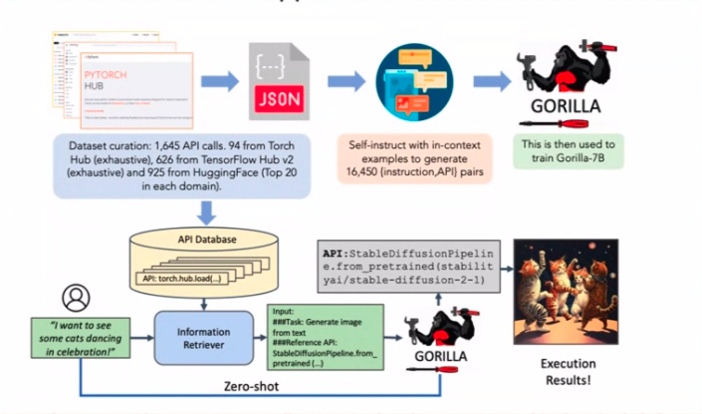
एपीआई के माध्यम से उड़ानें या होटल बुक करने वाले एजेंट पर विचार करें। शिकार? इसे उन कष्टप्रद मतिभ्रम से बचना चाहिए। अब, उस पेपर पर वापस आते हैं। एपीआई कॉलिंग मतिभ्रम को कम करने के लिए गुप्त सॉस? ढेर सारे एपीआई कॉल उदाहरणों के साथ फाइन-ट्यूनिंग। सादगी सर्वोच्च है.
एपीआई और एलएलएम एनोटेशन का संयोजन
एलएलएम एनोटेशन के साथ एपीआई का संयोजन - एक तकनीकी सिम्फनी की तरह लगता है, है ना? नुस्खा एकत्र किए गए उदाहरणों की एक श्रृंखला के साथ शुरू होता है, इसके बाद स्वाद के लिए चैटजीपीटी एनोटेशन का एक समूह होता है। क्या आपको वे API याद हैं जो अच्छे से नहीं चलते? उन्हें फ़िल्टर कर दिया गया है, जिससे एक प्रभावी एनोटेशन प्रक्रिया का मार्ग प्रशस्त हो रहा है।
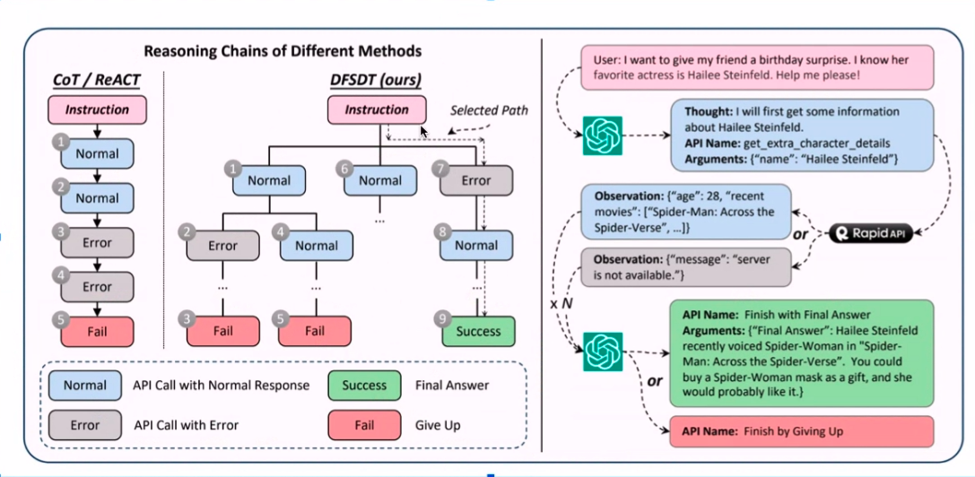
केक पर आइसिंग गहराई-पहली जैसी खोज है, जो यह सुनिश्चित करती है कि केवल एपीआई जो वास्तव में काम करते हैं वे ही काम करते हैं। यह एनोटेटेड गोल्डमाइन LlaMA 1 मॉडल और वॉइला को फाइन-ट्यून करता है! परिणाम उल्लेखनीय से कम नहीं हैं। मुझ पर भरोसा करें; एक दुर्जेय रणनीति बनाने के लिए ये प्रतीत होने वाले असमान कागजात एक-दूसरे से जुड़ जाते हैं।
निष्कर्ष
और यह आपके पास है - भाषा मॉडल के चमत्कारों में हमारी मनोरंजक खोज का दूसरा भाग। हमने कानूनों को स्केल करने से लेकर मॉडल प्रवृत्तियों तक और कुशल एजेंटों से एपीआई कॉलिंग चालाकी तक परिदृश्य का पता लगाया है। पहेली का प्रत्येक टुकड़ा भविष्य को फिर से लिखने वाली एआई मास्टरपीस में योगदान देता है। तो, मेरे साथी ज्ञान चाहने वालों, इन तरकीबों और तकनीकों को याद रखें, क्योंकि वे विकसित होते रहेंगे, और हम यहीं रहेंगे, एआई नवाचारों की अगली लहर को उजागर करने के लिए तैयार। तब तक, अन्वेषण में आनंद लें!
चाबी छीन लेना:
- "लीमा" जैसी तकनीकों से पता चलता है कि अच्छी तरह से क्यूरेटेड, छोटे डेटासेट बड़े डेटासेट से बेहतर प्रदर्शन कर सकते हैं।
- फ़ाइन-ट्यूनिंग के दौरान उत्तरों में तर्क को शामिल करना और उत्तरों से प्रश्न जोड़े जैसी रचनात्मक तकनीकों को शामिल करना एलएलएम प्रतिक्रियाओं को बढ़ाता है।
- प्रभावी एजेंट, एपीआई और एनोटेशन तकनीक एक मजबूत एआई रणनीति में योगदान करते हैं, जो अलग-अलग घटकों को एक सुसंगत संपूर्ण में जोड़ते हैं।
आम सवाल-जवाब
उत्तर: एलएलएम प्रदर्शन में सुधार में मात्रा से अधिक डेटा गुणवत्ता पर ध्यान केंद्रित करना शामिल है। "लीमा" जैसी तकनीकों से पता चलता है कि क्यूरेटेड, छोटे डेटासेट बड़े डेटासेट से बेहतर प्रदर्शन कर सकते हैं, और फाइन-ट्यूनिंग के दौरान उत्तरों में तर्क जोड़ने से प्रतिक्रियाएं बढ़ती हैं।
उत्तर: एलएलएम के लिए फाइन-ट्यूनिंग महत्वपूर्ण है। "फी-1" एक 1.3-बिलियन-पैरामीटर मॉडल है जो फाइन-ट्यूनिंग के जादू को प्रदर्शित करते हुए डॉक स्ट्रिंग्स से पायथन कोड उत्पन्न करने में उत्कृष्टता प्राप्त करता है। स्केलिंग कानून बताते हैं कि बड़े मॉडल बेहतर होते हैं, लेकिन कभी-कभी "फी-1" जैसे छोटे मॉडल बड़े मॉडल से बेहतर प्रदर्शन करते हैं।
उत्तर: गलत बयानों से सहमत होने जैसी मॉडल प्रवृत्तियों को कुछ इनपुट से असहमत होने के लिए प्रशिक्षण मॉडल द्वारा संबोधित किया जा सकता है। यह एलएलएम में "हां-मैन" विशेषता को कम करने में मदद करता है, हालांकि यह मतिभ्रम का सीधा समाधान नहीं है।
लेखक के बारे में: संयम भूटानी
संयम भूटानी H2O में एक वरिष्ठ डेटा वैज्ञानिक और कागल ग्रैंडमास्टर हैं, जहां वह चाय पीते हैं और समुदाय के लिए सामग्री बनाते हैं। जब वे चाय नहीं पीते, तो उन्हें अक्सर एलएलएम शोध पत्रों के साथ हिमालय की सैर करते हुए पाया जाएगा। पिछले 6 महीनों से वह हर दिन इंटरनेट पर जेनरेटिव एआई के बारे में लिख रहे हैं। इससे पहले, उन्हें उनके #1 कागल पॉडकास्ट: चाय टाइम डेटा साइंस के लिए पहचाना गया था, और अपने गृह कार्यालय में 12 जीपीयू को ठीक करके "एटीएक्स केस के प्रति घन इंच गणना को अधिकतम करने" के लिए इंटरनेट पर भी व्यापक रूप से जाना जाता था।
डेटाआवर पेज: https://community.analyticsvidhya.com/c/datahour/cutting-edge-tricks-of-applying-large-language-models
लिंक्डइन: https://www.linkedin.com/in/sanyambhutani/
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/09/cutting-edge-tricks-of-applying-large-language-models/

