किसी भी जेनेरिक एआई एप्लिकेशन के निर्माण के लिए, बड़े भाषा मॉडल (एलएलएम) को नए डेटा के साथ समृद्ध करना अनिवार्य है। यहीं पर रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) तकनीक आती है। आरएजी एक मशीन लर्निंग (एमएल) आर्किटेक्चर है जो अपने ज्ञान को बढ़ाने और ज्ञान-गहन कार्यों पर अत्याधुनिक परिणाम प्राप्त करने के लिए बाहरी दस्तावेजों (जैसे विकिपीडिया) का उपयोग करता है। . इन बाहरी डेटा स्रोतों को अंतर्ग्रहण करने के लिए, वेक्टर डेटाबेस विकसित हुए हैं, जो डेटा स्रोत के वेक्टर एम्बेडिंग को संग्रहीत कर सकते हैं और समानता खोजों की अनुमति दे सकते हैं।
इस पोस्ट में, हम दिखाते हैं कि बड़ी मात्रा में डेटा को अंतर्ग्रहण करने के लिए RAG एक्स्ट्रैक्ट, ट्रांसफॉर्म और लोड (ETL) इंजेसन पाइपलाइन कैसे बनाई जाए। अमेज़न ओपन सर्च सर्विस क्लस्टर और उपयोग PostgreSQL के लिए Amazon रिलेशनल डेटाबेस सर्विस (Amazon RDS) वेक्टर डेटा स्टोर के रूप में पीजीवेक्टर एक्सटेंशन के साथ। प्रत्येक सेवा समानता की गणना करने के लिए के-निकटतम पड़ोसी (के-एनएन) या अनुमानित निकटतम पड़ोसी (एएनएन) एल्गोरिदम और दूरी मेट्रिक्स लागू करती है। हम के एकीकरण का परिचय देते हैं रे RAG प्रासंगिक दस्तावेज़ पुनर्प्राप्ति तंत्र में। रे एक खुला स्रोत, पायथन, सामान्य प्रयोजन, वितरित कंप्यूटिंग लाइब्रेरी है। यह कई जीपीयू में समानांतर रूप से बड़ी मात्रा में डेटा के लिए एम्बेडिंग उत्पन्न करने और संग्रहीत करने के लिए वितरित डेटा प्रोसेसिंग की अनुमति देता है। हम प्रत्येक सेवा के लिए समानांतर इंजेस्ट और क्वेरी चलाने के लिए इन जीपीयू के साथ एक रे क्लस्टर का उपयोग करते हैं।
इस प्रयोग में, हम ओपनसर्च सेवा और अमेज़ॅन आरडीएस पर पीजीवेक्टर एक्सटेंशन के लिए निम्नलिखित पहलुओं का विश्लेषण करने का प्रयास करते हैं:
- एक वेक्टर स्टोर के रूप में, RAG के लिए लाखों रिकॉर्ड वाले बड़े डेटासेट को स्केल करने और संभालने की क्षमता
- RAG के लिए अंतर्ग्रहण पाइपलाइन में संभावित बाधाएँ
- ओपनसर्च सेवा और अमेज़ॅन आरडीएस के लिए अंतर्ग्रहण और क्वेरी पुनर्प्राप्ति समय में इष्टतम प्रदर्शन कैसे प्राप्त करें
वेक्टर डेटा स्टोर और जेनेरिक एआई अनुप्रयोगों के निर्माण में उनकी भूमिका के बारे में अधिक समझने के लिए, देखें जेनरेटिव एआई अनुप्रयोगों में वेक्टर डेटास्टोर्स की भूमिका.
ओपनसर्च सेवा का अवलोकन
ओपनसर्च सेवा व्यवसाय और परिचालन डेटा के सुरक्षित विश्लेषण, खोज और अनुक्रमण के लिए एक प्रबंधित सेवा है। ओपनसर्च सेवा टेक्स्ट और वेक्टर डेटा पर कई इंडेक्स बनाने की क्षमता के साथ पेटाबाइट-स्केल डेटा का समर्थन करती है। अनुकूलित कॉन्फ़िगरेशन के साथ, इसका लक्ष्य प्रश्नों के लिए उच्च रिकॉल करना है। ओपनसर्च सेवा एएनएन के साथ-साथ सटीक के-एनएन खोज का भी समर्थन करती है। ओपनसर्च सेवा एल्गोरिदम के चयन का समर्थन करती है एनएमएसएलआईबी, FAISS, तथा ल्यूसिने के-एनएन खोज को सशक्त बनाने के लिए पुस्तकालय। हमने Hierarchical Navigable Small World (HNSW) एल्गोरिदम के साथ OpenSearch के लिए ANN इंडेक्स बनाया क्योंकि इसे बड़े डेटासेट के लिए एक बेहतर खोज विधि माना जाता है। इंडेक्स एल्गोरिथम के चयन के बारे में अधिक जानकारी के लिए देखें OpenSearch के साथ अपने अरब-पैमाने के उपयोग के मामले के लिए k-NN एल्गोरिथम चुनें.
पीजीवेक्टर के साथ PostgreSQL के लिए अमेज़ॅन आरडीएस का अवलोकन
पीजीवेक्टर एक्सटेंशन PostgreSQL में एक ओपन सोर्स वेक्टर समानता खोज जोड़ता है। पीजीवेक्टर एक्सटेंशन का उपयोग करके, पोस्टग्रेएसक्यूएल वेक्टर एम्बेडिंग पर समानता खोज कर सकता है, जिससे व्यवसायों को त्वरित और कुशल समाधान प्रदान किया जा सकता है। पीजीवेक्टर दो प्रकार की वेक्टर समानता खोज प्रदान करता है: सटीक निकटतम पड़ोसी, जिसके परिणामस्वरूप 100% रिकॉल होता है, और अनुमानित निकटतम पड़ोसी (एएनएन), जो रिकॉल पर ट्रेड-ऑफ के साथ सटीक खोज की तुलना में बेहतर प्रदर्शन प्रदान करता है। किसी सूचकांक पर खोज के लिए, आप चुन सकते हैं कि खोज में कितने केंद्रों का उपयोग करना है, अधिक केंद्र प्रदर्शन के साथ बेहतर रिकॉल प्रदान करते हैं।
समाधान अवलोकन
निम्नलिखित चित्र समाधान वास्तुकला को दर्शाता है।

आइए प्रमुख घटकों को अधिक विस्तार से देखें।
डेटासेट
हम नमूना प्रश्न प्रदान करने के लिए OSCAR डेटा को अपने कोष और SQUAD डेटासेट के रूप में उपयोग करते हैं। इन डेटासेट को पहले Parquet फ़ाइलों में परिवर्तित किया जाता है। फिर हम Parquet डेटा को एम्बेडिंग में बदलने के लिए रे क्लस्टर का उपयोग करते हैं। निर्मित एंबेडिंग्स को पीजीवेक्टर के साथ ओपनसर्च सर्विस और अमेज़ॅन आरडीएस में शामिल किया जाता है।
OSCAR (ओपन सुपर-लार्ज क्रॉल्ड एग्रीगेटेड कॉर्पस) भाषा वर्गीकरण और फ़िल्टरिंग द्वारा प्राप्त एक विशाल बहुभाषी कॉर्पस है। आम क्रॉल कॉर्पस का उपयोग करना असभ्य वास्तुकला। डेटा को मूल और डुप्लिकेट दोनों रूपों में भाषा द्वारा वितरित किया जाता है। ऑस्कर कॉर्पस डेटासेट लगभग 609 मिलियन रिकॉर्ड है और कच्ची JSONL फ़ाइलों के रूप में लगभग 4.5 टीबी लेता है। फिर JSONL फ़ाइलों को Parquet प्रारूप में परिवर्तित कर दिया जाता है, जिससे कुल आकार 1.8 TB तक कम हो जाता है। हमने अंतर्ग्रहण के दौरान समय बचाने के लिए डेटासेट को 25 मिलियन रिकॉर्ड तक कम कर दिया है।
SQuAD (स्टैनफोर्ड क्वेश्चन आंसरिंग डेटासेट) एक रीडिंग कॉम्प्रिहेंशन डेटासेट है जिसमें विकिपीडिया लेखों के एक सेट पर भीड़ कार्यकर्ताओं द्वारा पूछे गए प्रश्न शामिल हैं, जहां प्रत्येक प्रश्न का उत्तर पाठ का एक खंड है, या विस्तार, संबंधित पाठ्यांश से, अन्यथा प्रश्न अनुत्तरित हो सकता है। हम उपयोग करते हैं दस्ते, के रूप में लाइसेंस प्राप्त है CC-BY-SA 4.0, नमूना प्रश्न प्रदान करने के लिए। इसमें लगभग 100,000 प्रश्न हैं जिनमें 50,000 से अधिक ऐसे प्रश्न हैं जो उत्तर देने योग्य प्रश्नों के समान दिखने के लिए भीड़ कार्यकर्ताओं द्वारा लिखे गए हैं।
अंतर्ग्रहण और वेक्टर एम्बेडिंग बनाने के लिए रे क्लस्टर
हमारे परीक्षण में, हमने पाया कि एम्बेडिंग बनाते समय GPU प्रदर्शन पर सबसे बड़ा प्रभाव डालता है। इसलिए, हमने अपने कच्चे पाठ को परिवर्तित करने और एम्बेडिंग बनाने के लिए रे क्लस्टर का उपयोग करने का निर्णय लिया। रे एक खुला स्रोत एकीकृत कंप्यूट ढांचा है जो एमएल इंजीनियरों और पायथन डेवलपर्स को पायथन अनुप्रयोगों को स्केल करने और एमएल वर्कलोड में तेजी लाने में सक्षम बनाता है। हमारे क्लस्टर में 5 g4dn.12xlarge शामिल है अमेज़ॅन इलास्टिक कम्प्यूट क्लाउड (अमेज़ॅन EC2) उदाहरण। प्रत्येक इंस्टेंस को 4 NVIDIA T4 Tensor Core GPU, 48 vCPU और 192 GiB मेमोरी के साथ कॉन्फ़िगर किया गया था। हमारे टेक्स्ट रिकॉर्ड के लिए, हमने प्रत्येक को 1,000-खंड ओवरलैप के साथ 100 टुकड़ों में विभाजित किया। यह प्रति रिकॉर्ड लगभग 200 तक पहुँच जाता है। एम्बेडिंग बनाने के लिए उपयोग किए जाने वाले मॉडल के लिए, हमने निर्णय लिया ऑल-एमपीनेट-बेस-वी2 768-आयामी वेक्टर स्थान बनाने के लिए।
इंफ्रास्ट्रक्चर सेटअप
हमने अपना बुनियादी ढांचा स्थापित करने के लिए निम्नलिखित आरडीएस इंस्टेंस प्रकार और ओपनसर्च सेवा क्लस्टर कॉन्फ़िगरेशन का उपयोग किया।
हमारे आरडीएस इंस्टेंस प्रकार के गुण निम्नलिखित हैं:
- उदाहरण प्रकार: db.r7g.12xlarge
- आवंटित भंडारण: 20 टीबी
- मल्टी-एज़: सच है
- भंडारण एन्क्रिप्टेड: सत्य
- प्रदर्शन अंतर्दृष्टि सक्षम करें: सत्य
- प्रदर्शन अंतर्दृष्टि प्रतिधारण: 7 दिन
- भंडारण प्रकार: gp3
- प्रावधानित आईओपीएस: 64,000
- सूचकांक प्रकार: आईवीएफ
- सूचियों की संख्या: 5,000
- दूरी फ़ंक्शन: L2
हमारी ओपनसर्च सेवा क्लस्टर गुण निम्नलिखित हैं:
- संस्करण: 2.5
- डेटा नोड्स: 10
- डेटा नोड इंस्टेंस प्रकार: r6g.4xlarge
- प्राथमिक नोड्स: 3
- प्राथमिक नोड उदाहरण प्रकार: r6g.xlarge
- सूचकांक: HNSW इंजन:
nmslib - ताज़ा अंतराल: 30 सेकंड
ef_construction: 256- मी: 16
- दूरी फ़ंक्शन: L2
हमने किसी भी प्रदर्शन बाधा से बचने के लिए ओपनसर्च सर्विस क्लस्टर और आरडीएस इंस्टेंसेस दोनों के लिए बड़े कॉन्फ़िगरेशन का उपयोग किया।
हम एक का उपयोग करके समाधान तैनात करते हैं AWS क्लाउड डेवलपमेंट किट (एडब्ल्यूएस सीडीके) धुआँरा, जैसा कि निम्नलिखित अनुभाग में बताया गया है।
एडब्ल्यूएस सीडीके ढेर तैनात करें
AWS CDK स्टैक हमें डेटा प्राप्त करने के लिए OpenSearch सेवा या Amazon RDS चुनने की अनुमति देता है।
पूर्व आवश्यकताएँ
इंस्टॉलेशन के साथ आगे बढ़ने से पहले, सीडीके, बिन, src.tc के तहत, अपनी पसंद के आधार पर अमेज़ॅन आरडीएस और ओपनसर्च सेवा के लिए बूलियन मानों को सही या गलत में बदलें।
आपको एक सेवा-लिंक्ड की भी आवश्यकता है AWS पहचान और अभिगम प्रबंधन ओपनसर्च सेवा डोमेन के लिए (IAM) भूमिका। अधिक जानकारी के लिए देखें अमेज़ॅन ओपनसर्च सर्विस कंस्ट्रक्ट लाइब्रेरी. भूमिका बनाने के लिए आप निम्न कमांड भी चला सकते हैं:
यह AWS CDK स्टैक निम्नलिखित बुनियादी ढांचे को तैनात करेगा:
- एक वीपीसी
- एक जंप होस्ट (VPC के अंदर)
- एक ओपनसर्च सेवा क्लस्टर (यदि अंतर्ग्रहण के लिए ओपनसर्च सेवा का उपयोग कर रहे हैं)
- एक आरडीएस उदाहरण (यदि अंतर्ग्रहण के लिए अमेज़न आरडीएस का उपयोग कर रहे हैं)
- An एडब्ल्यूएस सिस्टम मैनेजर रे क्लस्टर को तैनात करने के लिए दस्तावेज़
- An अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) बकेट
- An एडब्ल्यूएस गोंद OSCAR डेटासेट JSONL फ़ाइलों को Parquet फ़ाइलों में परिवर्तित करने का कार्य
- अमेज़ॅन क्लाउडवॉच डैशबोर्ड
डेटा डाउनलोड करें
जंप होस्ट से निम्नलिखित कमांड चलाएँ:
गिट रेपो को क्लोन करने से पहले, सुनिश्चित करें कि आपके पास हगिंग फेस प्रोफ़ाइल और OSCAR डेटा कॉर्पस तक पहुंच है। OSCAR डेटा की क्लोनिंग के लिए आपको उपयोगकर्ता नाम और पासवर्ड का उपयोग करना होगा:
JSONL फ़ाइलों को Parquet में कनवर्ट करें
AWS CDK स्टैक ने AWS ग्लू ETL जॉब बनाई oscar-jsonl-parquet OSCAR डेटा को JSONL से Parquet प्रारूप में परिवर्तित करने के लिए।
चलाने के बाद oscar-jsonl-parquet नौकरी, Parquet प्रारूप में फ़ाइलें S3 बकेट में Parquet फ़ोल्डर के अंतर्गत उपलब्ध होनी चाहिए।
प्रश्न डाउनलोड करें
अपने जंप होस्ट से, प्रश्न डेटा डाउनलोड करें और इसे अपने S3 बकेट पर अपलोड करें:
रे क्लस्टर स्थापित करें
AWS CDK स्टैक परिनियोजन के भाग के रूप में, हमने एक सिस्टम मैनेजर दस्तावेज़ बनाया, जिसे कहा जाता है CreateRayCluster.
दस्तावेज़ चलाने के लिए, निम्नलिखित चरणों को पूरा करें:
- सिस्टम मैनेजर कंसोल पर, के अंतर्गत दस्तावेज़ नेविगेशन फलक में, चुनें मेरे स्वामित्व में.
- ओपन
CreateRayClusterदस्तावेज़. - चुनें रन.
रन कमांड पेज में क्लस्टर के लिए डिफ़ॉल्ट मान पॉप्युलेट होंगे।
डिफ़ॉल्ट कॉन्फ़िगरेशन 5 g4dn.12xlarge का अनुरोध करता है। सुनिश्चित करें कि आपके खाते में इसका समर्थन करने की सीमाएँ हैं। प्रासंगिक सेवा सीमा ऑन-डिमांड जी और वीटी इंस्टेंसेस चलाना है। इसके लिए डिफ़ॉल्ट 64 है, लेकिन इस कॉन्फ़िगरेशन के लिए 240 सीपीयूएस की आवश्यकता है।
- क्लस्टर कॉन्फ़िगरेशन की समीक्षा करने के बाद, रन कमांड के लक्ष्य के रूप में जंप होस्ट का चयन करें।
यह आदेश निम्नलिखित चरण निष्पादित करेगा:
- रे क्लस्टर फ़ाइलों की प्रतिलिपि बनाएँ
- रे क्लस्टर स्थापित करें
- OpenSearch सेवा अनुक्रमणिका सेट करें
- आरडीएस टेबल सेट करें
आप सिस्टम मैनेजर कंसोल पर कमांड के आउटपुट की निगरानी कर सकते हैं। इस प्रक्रिया को शुरुआती लॉन्च में 10-15 मिनट का समय लगेगा।
अंतर्ग्रहण चलाएँ
जंप होस्ट से, रे क्लस्टर से कनेक्ट करें:
पहली बार होस्ट से कनेक्ट होने पर, आवश्यकताएँ स्थापित करें। ये फ़ाइलें पहले से ही हेड नोड पर मौजूद होनी चाहिए.
किसी भी अंतर्ग्रहण विधि के लिए, यदि आपको निम्न जैसी कोई त्रुटि मिलती है, तो यह समाप्त हो चुके क्रेडेंशियल से संबंधित है। वर्तमान समाधान (इस लेखन के समय) क्रेडेंशियल फ़ाइलों को रे हेड नोड में रखना है। सुरक्षा जोखिमों से बचने के लिए, उद्देश्य-निर्मित सॉफ़्टवेयर विकसित करते समय या वास्तविक डेटा के साथ काम करते समय प्रमाणीकरण के लिए IAM उपयोगकर्ताओं का उपयोग न करें। इसके बजाय, किसी पहचान प्रदाता जैसे फ़ेडरेशन का उपयोग करें AWS IAM पहचान केंद्र (AWS सिंगल साइन-ऑन का उत्तराधिकारी).
आमतौर पर, क्रेडेंशियल फ़ाइल में संग्रहीत होते हैं ~/.aws/credentials Linux और macOS सिस्टम पर, और %USERPROFILE%.awscredentials विंडोज़ पर, लेकिन ये सत्र टोकन के साथ अल्पकालिक क्रेडेंशियल हैं। आप डिफ़ॉल्ट क्रेडेंशियल फ़ाइल को ओवरराइड भी नहीं कर सकते हैं, और इसलिए आपको नए IAM उपयोगकर्ता का उपयोग करके सत्र टोकन के बिना दीर्घकालिक क्रेडेंशियल बनाने की आवश्यकता है।
दीर्घकालिक क्रेडेंशियल बनाने के लिए, आपको एक AWS एक्सेस कुंजी और AWS गुप्त एक्सेस कुंजी उत्पन्न करने की आवश्यकता है। आप ऐसा IAM कंसोल से कर सकते हैं. निर्देशों के लिए, देखें IAM उपयोगकर्ता क्रेडेंशियल्स के साथ प्रमाणित करें.
कुंजियाँ बनाने के बाद, जंप होस्ट का उपयोग करके कनेक्ट करें सत्र प्रबंधक, सिस्टम मैनेजर की एक क्षमता, और निम्नलिखित कमांड चलाएँ:
अब आप अंतर्ग्रहण चरणों को पुन: चला सकते हैं.
ओपनसर्च सेवा में डेटा डालें
यदि आप ओपनसर्च सेवा का उपयोग कर रहे हैं, तो फ़ाइलें अंतर्ग्रहण करने के लिए निम्नलिखित स्क्रिप्ट चलाएँ:
जब यह पूरा हो जाए, तो वह स्क्रिप्ट चलाएँ जो सिम्युलेटेड क्वेरीज़ चलाती है:
अमेज़ॅन आरडीएस में डेटा डालें
यदि आप अमेज़ॅन आरडीएस का उपयोग कर रहे हैं, तो फ़ाइलों को अंतर्ग्रहण करने के लिए निम्नलिखित स्क्रिप्ट चलाएँ:
जब यह पूरा हो जाए, तो आरडीएस इंस्टेंस पर पूर्ण वैक्यूम चलाना सुनिश्चित करें।
फिर सिम्युलेटेड क्वेरी चलाने के लिए निम्नलिखित स्क्रिप्ट चलाएँ:
रे डैशबोर्ड सेट करें
रे डैशबोर्ड सेट करने से पहले, आपको इंस्टॉल करना चाहिए AWS कमांड लाइन इंटरफ़ेस (एडब्ल्यूएस सीएलआई) आपकी स्थानीय मशीन पर। निर्देशों के लिए, देखें AWS CLI का नवीनतम संस्करण स्थापित या अद्यतन करें.
डैशबोर्ड सेट करने के लिए निम्नलिखित चरणों को पूरा करें:
- स्थापित करें सत्र प्रबंधक प्लगइन एडब्ल्यूएस सीएलआई के लिए.
- Isengard खाते में, bash/zsh के लिए अस्थायी क्रेडेंशियल कॉपी करें और अपने स्थानीय टर्मिनल में चलाएं।
- अपनी मशीन में एक session.sh फ़ाइल बनाएं और निम्नलिखित सामग्री को फ़ाइल में कॉपी करें:
- उस निर्देशिका को बदलें जहाँ यह session.sh फ़ाइल संग्रहीत है।
- कमांड चलाएं
Chmod +xफ़ाइल को निष्पादन योग्य अनुमति देने के लिए। - निम्न कमांड चलाएं:
उदाहरण के लिए:
आपको निम्न जैसा एक संदेश दिखाई देगा:
अपने ब्राउज़र में एक नया टैब खोलें और लोकलहोस्ट:8265 दर्ज करें।
आप रे डैशबोर्ड और चल रही नौकरियों और क्लस्टर के आँकड़े देखेंगे। आप यहां से मेट्रिक्स को ट्रैक कर सकते हैं।
उदाहरण के लिए, आप क्लस्टर पर लोड देखने के लिए रे डैशबोर्ड का उपयोग कर सकते हैं। जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है, अंतर्ग्रहण के दौरान, GPU 100% उपयोग के करीब चल रहा है।
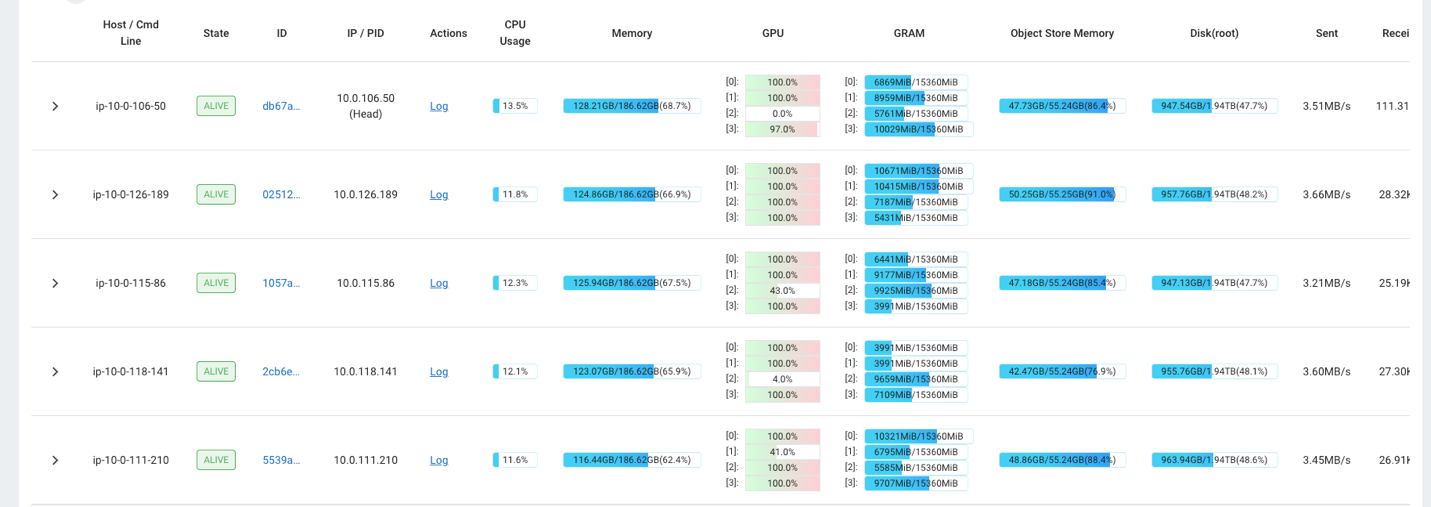
तुम भी उपयोग कर सकते हैं RAG_Benchmarks अंतर्ग्रहण दर और क्वेरी प्रतिक्रिया समय देखने के लिए क्लाउडवॉच डैशबोर्ड।
समाधान की व्यापकता
आप इस समाधान को अन्य AWS या तृतीय-पक्ष वेक्टर स्टोर में प्लग इन करने के लिए बढ़ा सकते हैं। प्रत्येक नए वेक्टर स्टोर के लिए, आपको डेटा स्टोर को कॉन्फ़िगर करने के साथ-साथ डेटा अंतर्ग्रहण के लिए स्क्रिप्ट बनाने की आवश्यकता होगी। आवश्यकतानुसार शेष पाइपलाइन का पुन: उपयोग किया जा सकता है।
निष्कर्ष
इस पोस्ट में, हमने एक ईटीएल पाइपलाइन साझा की है जिसका उपयोग आप वेक्टर डेटास्टोर के रूप में पीजीवेक्टर एक्सटेंशन के साथ ओपनसर्च सर्विस और अमेज़ॅन आरडीएस दोनों में वेक्टरकृत आरएजी डेटा डालने के लिए कर सकते हैं। समाधान ने बड़े डेटा कॉर्पस को ग्रहण करने के लिए आवश्यक समानता प्रदान करने के लिए रे क्लस्टर का उपयोग किया। आप RAG पाइपलाइन बनाने के लिए अपनी पसंद के किसी भी वेक्टर डेटाबेस को एकीकृत करने के लिए इस पद्धति का उपयोग कर सकते हैं।
लेखक के बारे में
 रैंडी डेफॉउ AWS में वरिष्ठ प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं। उनके पास मिशिगन विश्वविद्यालय से एमएसईई है, जहां उन्होंने स्वायत्त वाहनों के लिए कंप्यूटर विज़न पर काम किया। उन्होंने कोलोराडो स्टेट यूनिवर्सिटी से एमबीए भी किया है। रैंडी ने प्रौद्योगिकी क्षेत्र में सॉफ्टवेयर इंजीनियरिंग से लेकर उत्पाद प्रबंधन तक विभिन्न पदों पर कार्य किया है। उन्होंने 2013 में बड़े डेटा क्षेत्र में प्रवेश किया और उस क्षेत्र का पता लगाना जारी रखा। वह एमएल क्षेत्र में परियोजनाओं पर सक्रिय रूप से काम कर रहे हैं और उन्होंने स्ट्रेटा और ग्लूकॉन सहित कई सम्मेलनों में प्रस्तुति दी है।
रैंडी डेफॉउ AWS में वरिष्ठ प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं। उनके पास मिशिगन विश्वविद्यालय से एमएसईई है, जहां उन्होंने स्वायत्त वाहनों के लिए कंप्यूटर विज़न पर काम किया। उन्होंने कोलोराडो स्टेट यूनिवर्सिटी से एमबीए भी किया है। रैंडी ने प्रौद्योगिकी क्षेत्र में सॉफ्टवेयर इंजीनियरिंग से लेकर उत्पाद प्रबंधन तक विभिन्न पदों पर कार्य किया है। उन्होंने 2013 में बड़े डेटा क्षेत्र में प्रवेश किया और उस क्षेत्र का पता लगाना जारी रखा। वह एमएल क्षेत्र में परियोजनाओं पर सक्रिय रूप से काम कर रहे हैं और उन्होंने स्ट्रेटा और ग्लूकॉन सहित कई सम्मेलनों में प्रस्तुति दी है।
 डेविड ईसाई दक्षिणी कैलिफ़ोर्निया में स्थित एक प्रमुख समाधान वास्तुकार है। उनके पास सूचना सुरक्षा में स्नातक की डिग्री है और स्वचालन का शौक है। उनका फोकस क्षेत्र DevOps संस्कृति और परिवर्तन, कोड के रूप में बुनियादी ढाँचा और लचीलापन हैं। AWS में शामिल होने से पहले, उन्होंने सुरक्षा, DevOps और सिस्टम इंजीनियरिंग, बड़े पैमाने पर निजी और सार्वजनिक क्लाउड वातावरण के प्रबंधन में भूमिकाएँ निभाईं।
डेविड ईसाई दक्षिणी कैलिफ़ोर्निया में स्थित एक प्रमुख समाधान वास्तुकार है। उनके पास सूचना सुरक्षा में स्नातक की डिग्री है और स्वचालन का शौक है। उनका फोकस क्षेत्र DevOps संस्कृति और परिवर्तन, कोड के रूप में बुनियादी ढाँचा और लचीलापन हैं। AWS में शामिल होने से पहले, उन्होंने सुरक्षा, DevOps और सिस्टम इंजीनियरिंग, बड़े पैमाने पर निजी और सार्वजनिक क्लाउड वातावरण के प्रबंधन में भूमिकाएँ निभाईं।
 प्राची कुलकर्णी AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनकी विशेषज्ञता मशीन लर्निंग है, और वह विभिन्न एडब्ल्यूएस एमएल, बिग डेटा और एनालिटिक्स पेशकशों का उपयोग करके समाधान डिजाइन करने पर सक्रिय रूप से काम कर रही हैं। प्राची के पास स्वास्थ्य सेवा, लाभ, खुदरा और शिक्षा सहित कई क्षेत्रों में अनुभव है, और उन्होंने उत्पाद इंजीनियरिंग और वास्तुकला, प्रबंधन और ग्राहक सफलता में कई पदों पर काम किया है।
प्राची कुलकर्णी AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनकी विशेषज्ञता मशीन लर्निंग है, और वह विभिन्न एडब्ल्यूएस एमएल, बिग डेटा और एनालिटिक्स पेशकशों का उपयोग करके समाधान डिजाइन करने पर सक्रिय रूप से काम कर रही हैं। प्राची के पास स्वास्थ्य सेवा, लाभ, खुदरा और शिक्षा सहित कई क्षेत्रों में अनुभव है, और उन्होंने उत्पाद इंजीनियरिंग और वास्तुकला, प्रबंधन और ग्राहक सफलता में कई पदों पर काम किया है।
 ऋचा गुप्ता AWS में सॉल्यूशन आर्किटेक्ट हैं। वह ग्राहकों के लिए संपूर्ण समाधान तैयार करने में रुचि रखती है। उनकी विशेषज्ञता मशीन लर्निंग है और इसका उपयोग नए समाधान बनाने के लिए कैसे किया जा सकता है जो परिचालन उत्कृष्टता की ओर ले जाता है और व्यावसायिक राजस्व को बढ़ाता है। AWS में शामिल होने से पहले, उन्होंने एक सॉफ्टवेयर इंजीनियर और सॉल्यूशंस आर्किटेक्ट के रूप में बड़े टेलीकॉम ऑपरेटरों के लिए समाधान बनाने का काम किया। काम के अलावा, वह नई जगहों की खोज करना पसंद करती है और साहसिक गतिविधियाँ पसंद करती है।
ऋचा गुप्ता AWS में सॉल्यूशन आर्किटेक्ट हैं। वह ग्राहकों के लिए संपूर्ण समाधान तैयार करने में रुचि रखती है। उनकी विशेषज्ञता मशीन लर्निंग है और इसका उपयोग नए समाधान बनाने के लिए कैसे किया जा सकता है जो परिचालन उत्कृष्टता की ओर ले जाता है और व्यावसायिक राजस्व को बढ़ाता है। AWS में शामिल होने से पहले, उन्होंने एक सॉफ्टवेयर इंजीनियर और सॉल्यूशंस आर्किटेक्ट के रूप में बड़े टेलीकॉम ऑपरेटरों के लिए समाधान बनाने का काम किया। काम के अलावा, वह नई जगहों की खोज करना पसंद करती है और साहसिक गतिविधियाँ पसंद करती है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

