यह पोस्ट FedML के चाओयांग हे, अल नेवारेज़ और सलमान अवेस्टिमेहर के साथ सह-लिखित है।
कई संगठन स्वचालन और बड़े वितरित डेटासेट के उपयोग के माध्यम से अपने व्यावसायिक निर्णय लेने को बढ़ाने के लिए मशीन लर्निंग (एमएल) लागू कर रहे हैं। डेटा तक बढ़ती पहुंच के साथ, एमएल में अद्वितीय व्यावसायिक अंतर्दृष्टि और अवसर प्रदान करने की क्षमता है। हालाँकि, विभिन्न स्थानों पर कच्ची, गैर-स्वच्छता वाली संवेदनशील जानकारी साझा करने से महत्वपूर्ण सुरक्षा और गोपनीयता जोखिम पैदा होता है, खासकर स्वास्थ्य देखभाल जैसे विनियमित उद्योगों में।
इस मुद्दे को हल करने के लिए, फ़ेडरेटेड लर्निंग (एफएल) एक विकेन्द्रीकृत और सहयोगी एमएल प्रशिक्षण तकनीक है जो सटीकता और निष्ठा बनाए रखते हुए डेटा गोपनीयता प्रदान करती है। पारंपरिक एमएल प्रशिक्षण के विपरीत, एफएल प्रशिक्षण एक स्वतंत्र सुरक्षित सत्र का उपयोग करके एक अलग ग्राहक स्थान के भीतर होता है। क्लाइंट केवल अपने आउटपुट मॉडल मापदंडों को एक केंद्रीकृत सर्वर के साथ साझा करता है, जिसे प्रशिक्षण समन्वयक या एकत्रीकरण सर्वर के रूप में जाना जाता है, न कि मॉडल को प्रशिक्षित करने के लिए उपयोग किया जाने वाला वास्तविक डेटा। यह दृष्टिकोण मॉडल प्रशिक्षण पर प्रभावी सहयोग को सक्षम करते हुए कई डेटा गोपनीयता चिंताओं को कम करता है।
हालाँकि FL बेहतर डेटा गोपनीयता और सुरक्षा प्राप्त करने की दिशा में एक कदम है, लेकिन यह कोई गारंटीकृत समाधान नहीं है। पहुंच नियंत्रण और एन्क्रिप्शन की कमी वाले असुरक्षित नेटवर्क अभी भी हमलावरों के लिए संवेदनशील जानकारी उजागर कर सकते हैं। इसके अतिरिक्त, स्थानीय रूप से प्रशिक्षित जानकारी अगर एक अनुमान हमले के माध्यम से पुनर्निर्माण की जाती है तो निजी डेटा को उजागर कर सकती है। इन जोखिमों को कम करने के लिए, एफएल मॉडल प्रशिक्षण समन्वयक के साथ जानकारी साझा करने से पहले व्यक्तिगत प्रशिक्षण एल्गोरिदम और प्रभावी मास्किंग और पैरामीटराइजेशन का उपयोग करता है। स्थानीय और केंद्रीकृत स्थानों पर मजबूत नेटवर्क नियंत्रण अनुमान और घुसपैठ के जोखिमों को और कम कर सकता है।
इस पोस्ट में, हम एक FL दृष्टिकोण का उपयोग करते हुए साझा करते हैं फेडएमएल, अमेज़ॅन इलास्टिक कुबेरनेट्स सेवा (अमेज़ॅन ईकेएस), और अमेज़न SageMaker डेटा गोपनीयता और सुरक्षा चिंताओं को संबोधित करते हुए रोगी परिणामों में सुधार करना।
स्वास्थ्य देखभाल में संघीय शिक्षा की आवश्यकता
रोगी देखभाल के बारे में सटीक पूर्वानुमान और आकलन करने के लिए हेल्थकेयर वितरित डेटा स्रोतों पर बहुत अधिक निर्भर करता है। गोपनीयता की रक्षा के लिए उपलब्ध डेटा स्रोतों को सीमित करने से परिणाम सटीकता और अंततः, रोगी देखभाल की गुणवत्ता पर नकारात्मक प्रभाव पड़ता है। इसलिए, एमएल एडब्ल्यूएस ग्राहकों के लिए चुनौतियां पैदा करता है जिन्हें रोगी परिणामों से समझौता किए बिना वितरित संस्थाओं में गोपनीयता और सुरक्षा सुनिश्चित करने की आवश्यकता होती है।
एफएल समाधान लागू करते समय स्वास्थ्य देखभाल संगठनों को संयुक्त राज्य अमेरिका में स्वास्थ्य बीमा पोर्टेबिलिटी और जवाबदेही अधिनियम (एचआईपीएए) जैसे सख्त अनुपालन नियमों का पालन करना चाहिए। डेटा गोपनीयता, सुरक्षा और अनुपालन सुनिश्चित करना स्वास्थ्य सेवा में और भी महत्वपूर्ण हो जाता है, जिसके लिए मजबूत एन्क्रिप्शन, एक्सेस नियंत्रण, ऑडिटिंग तंत्र और सुरक्षित संचार प्रोटोकॉल की आवश्यकता होती है। इसके अतिरिक्त, हेल्थकेयर डेटासेट में अक्सर जटिल और विषम डेटा प्रकार होते हैं, जिससे डेटा मानकीकरण और इंटरऑपरेबिलिटी एफएल सेटिंग्स में एक चुनौती बन जाती है।
केस अवलोकन का उपयोग करें
इस पोस्ट में उल्लिखित उपयोग का मामला विभिन्न संगठनों में हृदय रोग डेटा का है, जिस पर एक एमएल मॉडल रोगी में हृदय रोग की भविष्यवाणी करने के लिए वर्गीकरण एल्गोरिदम चलाएगा। चूँकि यह डेटा विभिन्न संगठनों का है, इसलिए हम निष्कर्षों को एकत्रित करने के लिए फ़ेडरेटेड लर्निंग का उपयोग करते हैं।
RSI हृदय रोग डेटासेट कैलिफ़ोर्निया विश्वविद्यालय से इरविन की मशीन लर्निंग रिपॉजिटरी हृदय संबंधी अनुसंधान और पूर्वानुमानित मॉडलिंग के लिए व्यापक रूप से उपयोग किया जाने वाला डेटासेट है। इसमें 303 नमूने शामिल हैं, जिनमें से प्रत्येक एक मरीज का प्रतिनिधित्व करता है, और इसमें नैदानिक और जनसांख्यिकीय विशेषताओं के साथ-साथ हृदय रोग की उपस्थिति या अनुपस्थिति का संयोजन शामिल है।
इस बहुभिन्नरूपी डेटासेट में रोगी की जानकारी में 76 विशेषताएं हैं, जिनमें से 14 विशेषताओं का उपयोग आमतौर पर दिए गए गुणों के आधार पर हृदय रोग की उपस्थिति की भविष्यवाणी करने के लिए एमएल एल्गोरिदम के विकास और मूल्यांकन के लिए किया जाता है।
फेडएमएल ढांचा
FL फ्रेमवर्क का एक विस्तृत चयन है, लेकिन हमने इसका उपयोग करने का निर्णय लिया फेडएमएल ढांचा इस उपयोग के मामले के लिए क्योंकि यह खुला स्रोत है और कई FL प्रतिमानों का समर्थन करता है। FedML FL के लिए एक लोकप्रिय ओपन सोर्स लाइब्रेरी, MLOps प्लेटफ़ॉर्म और एप्लिकेशन इकोसिस्टम प्रदान करता है। ये FL समाधानों के विकास और तैनाती की सुविधा प्रदान करते हैं। यह टूल, लाइब्रेरी और एल्गोरिदम का एक व्यापक सूट प्रदान करता है जो शोधकर्ताओं और चिकित्सकों को वितरित वातावरण में एफएल एल्गोरिदम को लागू करने और प्रयोग करने में सक्षम बनाता है। FedML उपयोगकर्ता के अनुकूल इंटरफ़ेस और अनुकूलन योग्य घटकों की पेशकश करके FL में डेटा गोपनीयता, संचार और मॉडल एकत्रीकरण की चुनौतियों का समाधान करता है। सहयोग और ज्ञान साझा करने पर अपने फोकस के साथ, फेडएमएल का लक्ष्य एफएल को अपनाने में तेजी लाना और इस उभरते क्षेत्र में नवाचार को बढ़ावा देना है। फेडएमएल ढांचा मॉडल अज्ञेयवादी है, जिसमें बड़े भाषा मॉडल (एलएलएम) के लिए हाल ही में जोड़ा गया समर्थन शामिल है। अधिक जानकारी के लिए देखें फेडएलएलएम जारी करना: फेडएमएल प्लेटफॉर्म का उपयोग करके मालिकाना डेटा पर अपने खुद के बड़े भाषा मॉडल बनाएं.
फेडएमएल ऑक्टोपस
सिस्टम पदानुक्रम और विविधता वास्तविक जीवन के FL उपयोग मामलों में एक प्रमुख चुनौती है, जहां विभिन्न डेटा साइलो में सीपीयू और जीपीयू के साथ अलग-अलग बुनियादी ढांचे हो सकते हैं। ऐसे परिदृश्यों में, आप उपयोग कर सकते हैं फेडएमएल ऑक्टोपस.
फेडएमएल ऑक्टोपस क्रॉस-संगठन और क्रॉस-अकाउंट प्रशिक्षण के लिए क्रॉस-साइलो एफएल का औद्योगिक-ग्रेड प्लेटफॉर्म है। FedML MLOps के साथ मिलकर, यह डेवलपर्स या संगठनों को सुरक्षित तरीके से किसी भी पैमाने पर कहीं से भी खुला सहयोग करने में सक्षम बनाता है। फेडएमएल ऑक्टोपस प्रत्येक डेटा साइलो के अंदर एक वितरित प्रशिक्षण प्रतिमान चलाता है और सिंक्रोनस या एसिंक्रोनस प्रशिक्षण का उपयोग करता है।
फेडएमएल एमएलओप्स
FedML MLOps कोड के स्थानीय विकास को सक्षम बनाता है जिसे बाद में FedML फ्रेमवर्क का उपयोग करके कहीं भी तैनात किया जा सकता है। प्रशिक्षण शुरू करने से पहले, आपको एक FedML खाता बनाना होगा, साथ ही FedML ऑक्टोपस में सर्वर और क्लाइंट पैकेज बनाना और अपलोड करना होगा। अधिक जानकारी के लिए देखें कदम और फेडएमएल ऑक्टोपस का परिचय: सरलीकृत एमएलओपीएस के साथ फ़ेडरेटेड लर्निंग को उत्पादन में बढ़ाना.
समाधान अवलोकन
हम प्रयोग ट्रैकिंग के लिए सेजमेकर के साथ एकीकृत कई ईकेएस क्लस्टरों में फेडएमएल को तैनात करते हैं। हम उपयोग करते हैं टेराफॉर्म के लिए अमेज़न ईकेएस ब्लूप्रिंट आवश्यक बुनियादी ढाँचे को तैनात करना। ईकेएस ब्लूप्रिंट संपूर्ण ईकेएस क्लस्टर बनाने में मदद करता है जो वर्कलोड को तैनात करने और संचालित करने के लिए आवश्यक परिचालन सॉफ़्टवेयर के साथ पूरी तरह से बूटस्ट्रैप्ड हैं। ईकेएस ब्लूप्रिंट के साथ, ईकेएस पर्यावरण की वांछित स्थिति के लिए कॉन्फ़िगरेशन, जैसे कि नियंत्रण विमान, वर्कर नोड्स और कुबेरनेट्स ऐड-ऑन, को कोड (आईएसी) ब्लूप्रिंट के रूप में एक बुनियादी ढांचे के रूप में वर्णित किया गया है। ब्लूप्रिंट कॉन्फ़िगर होने के बाद, इसका उपयोग निरंतर परिनियोजन स्वचालन का उपयोग करके कई AWS खातों और क्षेत्रों में सुसंगत वातावरण बनाने के लिए किया जा सकता है।
इस पोस्ट में साझा की गई सामग्री वास्तविक जीवन की स्थितियों और अनुभवों को दर्शाती है, लेकिन यह ध्यान रखना महत्वपूर्ण है कि विभिन्न स्थानों पर इन स्थितियों की तैनाती भिन्न हो सकती है। हालाँकि हम अलग-अलग वीपीसी के साथ एक ही AWS खाते का उपयोग करते हैं, लेकिन यह समझना महत्वपूर्ण है कि अलग-अलग परिस्थितियाँ और कॉन्फ़िगरेशन भिन्न हो सकते हैं। इसलिए, प्रदान की गई जानकारी को एक सामान्य मार्गदर्शिका के रूप में उपयोग किया जाना चाहिए और विशिष्ट आवश्यकताओं और स्थानीय परिस्थितियों के आधार पर अनुकूलन की आवश्यकता हो सकती है।
निम्नलिखित चित्र हमारे समाधान वास्तुकला को दर्शाता है।
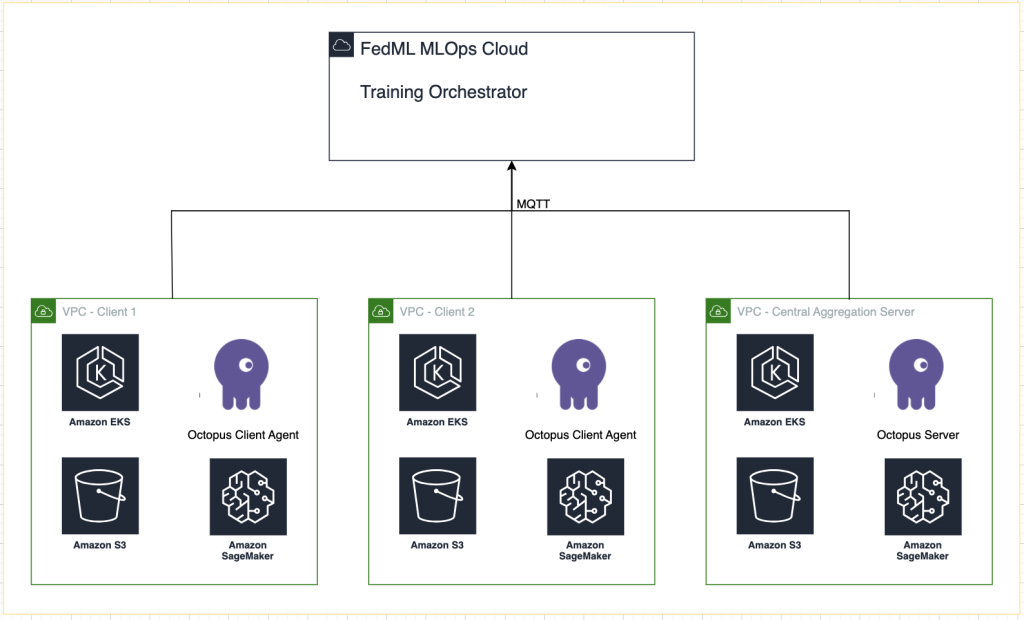
प्रत्येक प्रशिक्षण रन के लिए FedML MLOps द्वारा प्रदान की गई ट्रैकिंग के अलावा, हम इसका उपयोग करते हैं अमेज़न SageMaker प्रयोग प्रत्येक क्लाइंट मॉडल और केंद्रीकृत (एग्रीगेटर) मॉडल के प्रदर्शन को ट्रैक करने के लिए।
सेजमेकर एक्सपेरिमेंट्स सेजमेकर की एक क्षमता है जो आपको अपने एमएल प्रयोगों को बनाने, प्रबंधित करने, विश्लेषण करने और तुलना करने की सुविधा देती है। प्रयोग के विवरण, मापदंडों और परिणामों को रिकॉर्ड करके, शोधकर्ता अपने काम को सटीक रूप से पुन: पेश और मान्य कर सकते हैं। यह विभिन्न दृष्टिकोणों की प्रभावी तुलना और विश्लेषण की अनुमति देता है, जिससे सूचित निर्णय लेने में मदद मिलती है। इसके अतिरिक्त, ट्रैकिंग प्रयोग मॉडल की प्रगति में अंतर्दृष्टि प्रदान करके और शोधकर्ताओं को पिछले पुनरावृत्तियों से सीखने में सक्षम बनाकर पुनरावृत्तीय सुधार की सुविधा प्रदान करते हैं, जिससे अंततः अधिक प्रभावी समाधानों के विकास में तेजी आती है।
हम प्रत्येक रन के लिए सेजमेकर एक्सपेरिमेंट्स को निम्नलिखित भेजते हैं:
- मॉडल मूल्यांकन मेट्रिक्स - प्रशिक्षण हानि और वक्र के अंतर्गत क्षेत्र (एयूसी)
- हाइपरपैरामीटर - युग, सीखने की दर, बैच का आकार, अनुकूलक, और वजन में कमी
.. पूर्वापेक्षाएँ
इस पोस्ट के साथ अनुसरण करने के लिए, आपके पास निम्नलिखित पूर्वापेक्षाएँ होनी चाहिए:
समाधान तैनात करें
आरंभ करने के लिए, स्थानीय रूप से नमूना कोड होस्ट करने वाले रिपॉजिटरी को क्लोन करें:
फिर निम्नलिखित आदेशों का उपयोग करके उपयोग के मामले के बुनियादी ढांचे को तैनात करें:
टेराफॉर्म टेम्पलेट को पूरी तरह से तैनात होने में 20-30 मिनट लग सकते हैं। इसे तैनात करने के बाद, FL एप्लिकेशन को चलाने के लिए अगले अनुभागों में दिए गए चरणों का पालन करें।
एक MLOps परिनियोजन पैकेज बनाएँ
FedML दस्तावेज़ीकरण के एक भाग के रूप में, हमें क्लाइंट और सर्वर पैकेज बनाने की आवश्यकता है, जिसे MLOps प्लेटफ़ॉर्म प्रशिक्षण शुरू करने के लिए सर्वर और क्लाइंट को वितरित करेगा।
इन पैकेजों को बनाने के लिए, रूट निर्देशिका में पाई गई निम्न स्क्रिप्ट चलाएँ:
यह प्रोजेक्ट की रूट निर्देशिका में निम्नलिखित निर्देशिका में संबंधित पैकेज बनाएगा:
पैकेजों को FedML MLOps प्लेटफ़ॉर्म पर अपलोड करें
पैकेज अपलोड करने के लिए निम्नलिखित चरणों को पूरा करें:
- फेडएमएल यूआई पर, चुनें मेरे अनुप्रयोग नेविगेशन फलक में
- चुनें नया आवेदन.
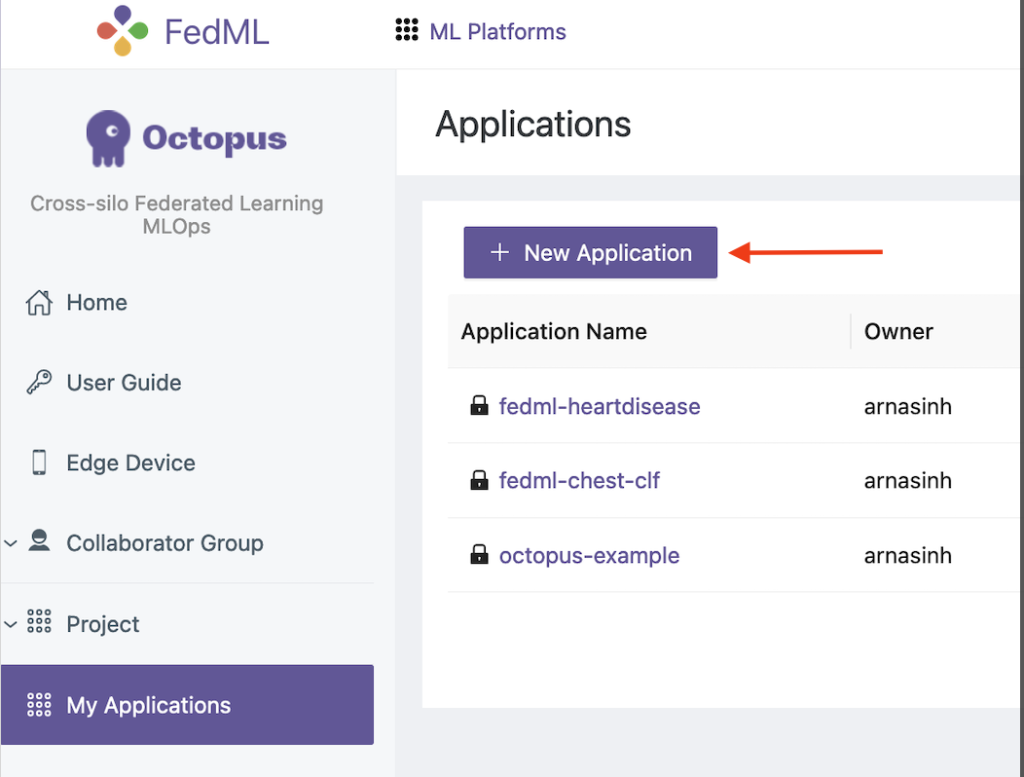
- अपने वर्कस्टेशन से क्लाइंट और सर्वर पैकेज अपलोड करें।
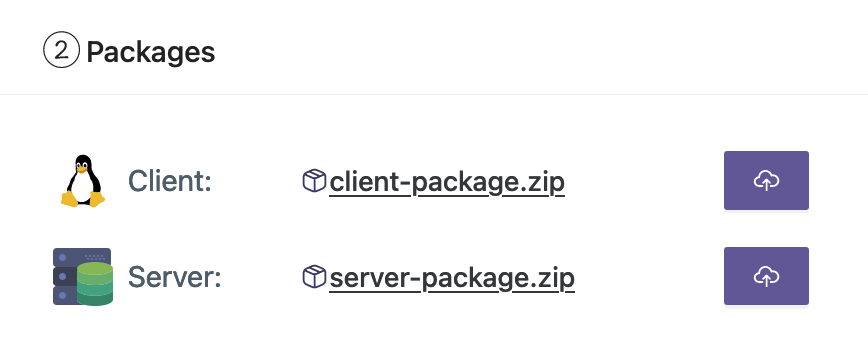
- आप हाइपरपैरामीटर को समायोजित भी कर सकते हैं या नए बना सकते हैं।

ट्रिगर फ़ेडरेटेड प्रशिक्षण
फ़ेडरेटेड प्रशिक्षण चलाने के लिए, निम्नलिखित चरणों को पूरा करें:
- फेडएमएल यूआई पर, चुनें प्रोजेक्ट सूची नेविगेशन फलक में
- चुनें एक नया प्रोजेक्ट बनाएं.
- समूह का नाम और प्रोजेक्ट का नाम दर्ज करें, फिर चुनें OK.

- नव निर्मित प्रोजेक्ट चुनें और चुनें नया रन बनाएं एक प्रशिक्षण रन को ट्रिगर करने के लिए।
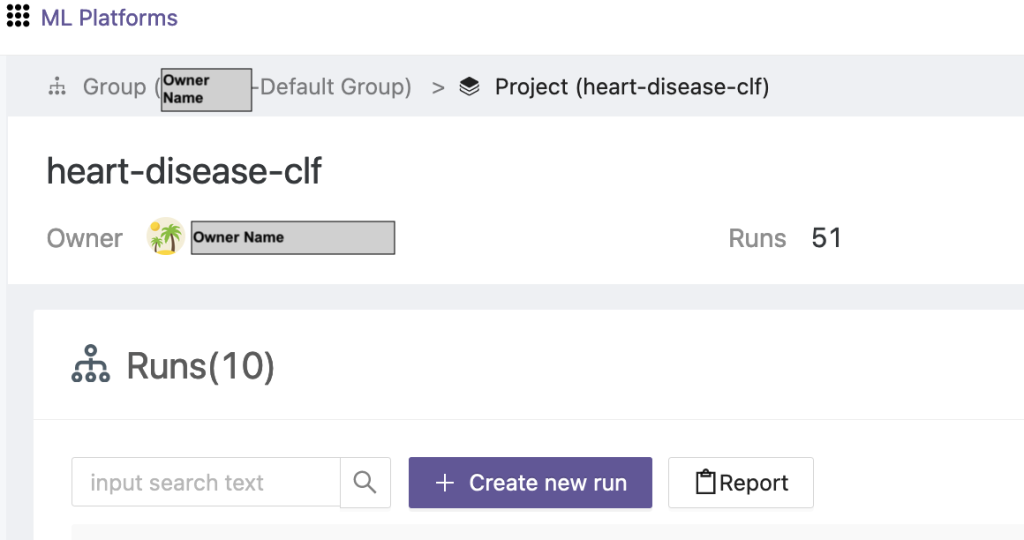
- इस ट्रेनिंग रन के लिए एज क्लाइंट डिवाइस और सेंट्रल एग्रीगेटर सर्वर का चयन करें।
- वह एप्लिकेशन चुनें जिसे आपने पिछले चरणों में बनाया था।

- किसी भी हाइपरपैरामीटर को अपडेट करें या डिफ़ॉल्ट सेटिंग्स का उपयोग करें।
- चुनें प्रारंभ प्रशिक्षण शुरू करना।

- चुनना प्रशिक्षण की स्थिति टैब खोलें और प्रशिक्षण पूरा होने तक प्रतीक्षा करें। आप उपलब्ध टैब पर भी नेविगेट कर सकते हैं.
- जब प्रशिक्षण पूरा हो जाए, तो चुनें प्रणाली अपने एज सर्वर और एकत्रीकरण ईवेंट पर प्रशिक्षण समय अवधि देखने के लिए टैब।
परिणाम और प्रयोग विवरण देखें
जब प्रशिक्षण पूरा हो जाए, तो आप FedML और SageMaker का उपयोग करके परिणाम देख सकते हैं।
FedML UI पर, पर मॉडल टैब पर, आप एग्रीगेटर और क्लाइंट मॉडल देख सकते हैं। आप इन मॉडलों को वेबसाइट से भी डाउनलोड कर सकते हैं।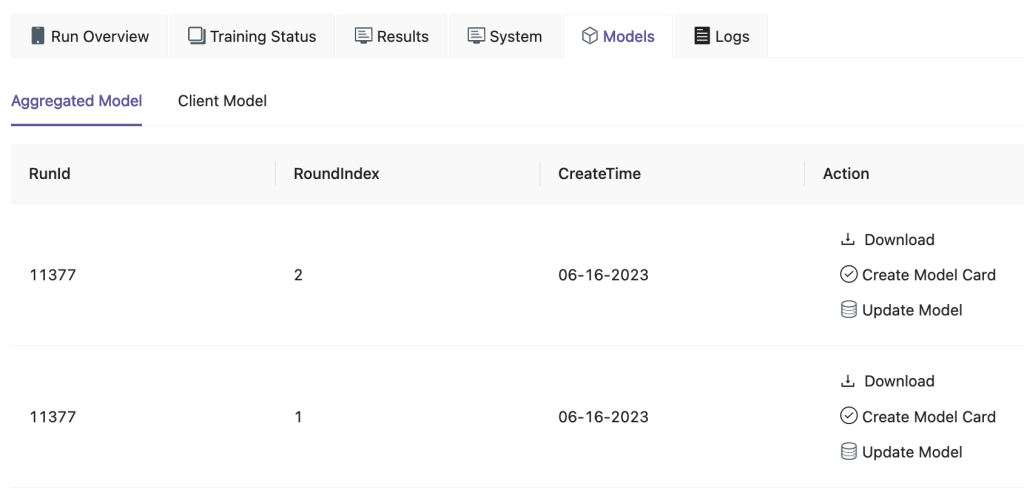
आप इसमें लॉग इन भी कर सकते हैं अमेज़ॅन सैजमेकर स्टूडियो और चुनें प्रयोगों नेविगेशन फलक में
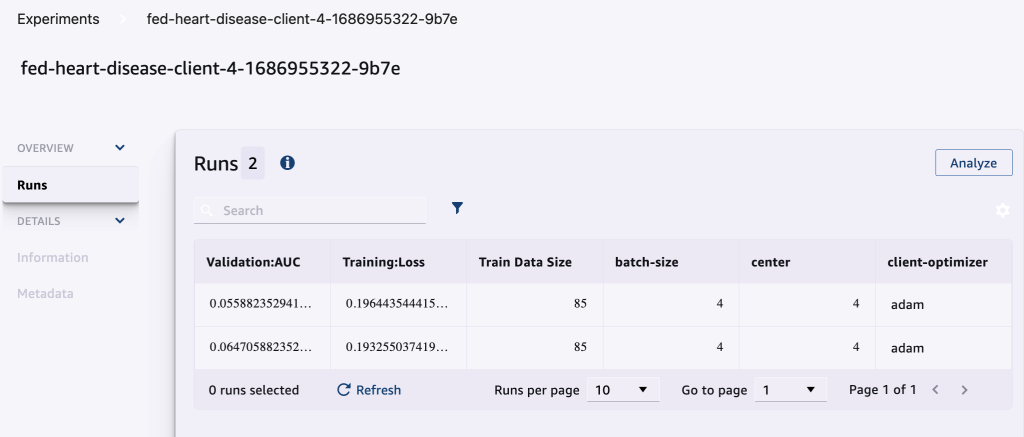
निम्नलिखित स्क्रीनशॉट लॉग किए गए प्रयोगों को दिखाता है।
प्रयोग ट्रैकिंग कोड
इस अनुभाग में, हम उस कोड का पता लगाते हैं जो सेजमेकर प्रयोग ट्रैकिंग को FL फ्रेमवर्क प्रशिक्षण के साथ एकीकृत करता है।
अपनी पसंद के संपादक में, प्रशिक्षण के एक भाग के रूप में सेजमेकर प्रयोग ट्रैकिंग कोड को इंजेक्ट करने के लिए कोड में संपादन देखने के लिए निम्नलिखित फ़ोल्डर खोलें:
प्रशिक्षण पर नज़र रखने के लिए, हम एक सेजमेकर प्रयोग बनाएं का उपयोग करके लॉग किए गए पैरामीटर और मेट्रिक्स के साथ log_parameter और log_metric निम्नलिखित कोड नमूने में उल्लिखित कमांड।
में एक प्रविष्टि config/fedml_config.yaml फ़ाइल प्रयोग उपसर्ग की घोषणा करती है, जिसे अद्वितीय प्रयोग नाम बनाने के लिए कोड में संदर्भित किया गया है: sm_experiment_name: "fed-heart-disease". आप इसे अपनी पसंद के किसी भी मूल्य पर अपडेट कर सकते हैं।
उदाहरण के लिए, निम्न कोड देखें heart_disease_trainer.py, जिसका उपयोग प्रत्येक ग्राहक द्वारा अपने डेटासेट पर मॉडल को प्रशिक्षित करने के लिए किया जाता है:
प्रत्येक क्लाइंट रन के लिए, प्रयोग विवरण को heart_disease_trainer.py में निम्नलिखित कोड का उपयोग करके ट्रैक किया जाता है:
इसी तरह, आप कोड का उपयोग कर सकते हैं heart_disease_aggregator.py मॉडल भार को अद्यतन करने के बाद स्थानीय डेटा पर परीक्षण चलाने के लिए। ग्राहकों के साथ प्रत्येक संचार के बाद विवरण लॉग किया जाता है।
क्लीन अप
जब आप समाधान पूरा कर लें, तो कुशल संसाधन उपयोग और लागत प्रबंधन सुनिश्चित करने के लिए उपयोग किए गए संसाधनों को साफ़ करना सुनिश्चित करें, और अनावश्यक खर्चों और संसाधन अपव्यय से बचें। पर्यावरण को सक्रिय रूप से व्यवस्थित करना, जैसे अप्रयुक्त उदाहरणों को हटाना, अनावश्यक सेवाओं को रोकना और अस्थायी डेटा को हटाना, एक स्वच्छ और संगठित बुनियादी ढांचे में योगदान देता है। आप अपने संसाधनों को साफ़ करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
सारांश
अमेज़ॅन ईकेएस को बुनियादी ढांचे के रूप में और फेडएमएल को एफएल के लिए ढांचे के रूप में उपयोग करके, हम डेटा गोपनीयता का सम्मान करते हुए साझा मॉडलों को प्रशिक्षण और तैनात करने के लिए एक स्केलेबल और प्रबंधित वातावरण प्रदान करने में सक्षम हैं। एफएल की विकेंद्रीकृत प्रकृति के साथ, संगठन सुरक्षित रूप से सहयोग कर सकते हैं, वितरित डेटा की क्षमता को अनलॉक कर सकते हैं और डेटा गोपनीयता से समझौता किए बिना एमएल मॉडल में सुधार कर सकते हैं।
हमेशा की तरह, AWS आपकी प्रतिक्रिया का स्वागत करता है। कृपया अपने विचार और प्रश्न टिप्पणी अनुभाग में छोड़ें।
लेखक के बारे में
 रैंडी डेफॉउ AWS में वरिष्ठ प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं। उनके पास मिशिगन विश्वविद्यालय से एमएसईई है, जहां उन्होंने स्वायत्त वाहनों के लिए कंप्यूटर विज़न पर काम किया। उन्होंने कोलोराडो स्टेट यूनिवर्सिटी से एमबीए भी किया है। रैंडी ने प्रौद्योगिकी क्षेत्र में सॉफ्टवेयर इंजीनियरिंग से लेकर उत्पाद प्रबंधन तक विभिन्न पदों पर कार्य किया है। उन्होंने 2013 में बड़े डेटा क्षेत्र में प्रवेश किया और उस क्षेत्र का पता लगाना जारी रखा। वह एमएल क्षेत्र में परियोजनाओं पर सक्रिय रूप से काम कर रहे हैं और उन्होंने स्ट्रेटा और ग्लूकॉन सहित कई सम्मेलनों में प्रस्तुति दी है।
रैंडी डेफॉउ AWS में वरिष्ठ प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं। उनके पास मिशिगन विश्वविद्यालय से एमएसईई है, जहां उन्होंने स्वायत्त वाहनों के लिए कंप्यूटर विज़न पर काम किया। उन्होंने कोलोराडो स्टेट यूनिवर्सिटी से एमबीए भी किया है। रैंडी ने प्रौद्योगिकी क्षेत्र में सॉफ्टवेयर इंजीनियरिंग से लेकर उत्पाद प्रबंधन तक विभिन्न पदों पर कार्य किया है। उन्होंने 2013 में बड़े डेटा क्षेत्र में प्रवेश किया और उस क्षेत्र का पता लगाना जारी रखा। वह एमएल क्षेत्र में परियोजनाओं पर सक्रिय रूप से काम कर रहे हैं और उन्होंने स्ट्रेटा और ग्लूकॉन सहित कई सम्मेलनों में प्रस्तुति दी है।
 अर्नब सिन्हा AWS के लिए एक वरिष्ठ समाधान वास्तुकार है, जो संगठनों को डेटा सेंटर माइग्रेशन, डिजिटल परिवर्तन और एप्लिकेशन आधुनिकीकरण, बड़े डेटा और मशीन लर्निंग में व्यावसायिक परिणामों का समर्थन करने वाले स्केलेबल समाधान डिजाइन और निर्माण करने में मदद करने के लिए फील्ड सीटीओ के रूप में कार्य करता है। उन्होंने ऊर्जा, खुदरा, विनिर्माण, स्वास्थ्य सेवा और जीवन विज्ञान सहित विभिन्न उद्योगों में ग्राहकों का समर्थन किया है। अर्नब के पास एमएल स्पेशलिटी सर्टिफिकेशन सहित सभी AWS सर्टिफिकेशन हैं। AWS में शामिल होने से पहले, अर्नब एक प्रौद्योगिकी नेता थे और पहले आर्किटेक्ट और इंजीनियरिंग नेतृत्व की भूमिका निभा चुके थे।
अर्नब सिन्हा AWS के लिए एक वरिष्ठ समाधान वास्तुकार है, जो संगठनों को डेटा सेंटर माइग्रेशन, डिजिटल परिवर्तन और एप्लिकेशन आधुनिकीकरण, बड़े डेटा और मशीन लर्निंग में व्यावसायिक परिणामों का समर्थन करने वाले स्केलेबल समाधान डिजाइन और निर्माण करने में मदद करने के लिए फील्ड सीटीओ के रूप में कार्य करता है। उन्होंने ऊर्जा, खुदरा, विनिर्माण, स्वास्थ्य सेवा और जीवन विज्ञान सहित विभिन्न उद्योगों में ग्राहकों का समर्थन किया है। अर्नब के पास एमएल स्पेशलिटी सर्टिफिकेशन सहित सभी AWS सर्टिफिकेशन हैं। AWS में शामिल होने से पहले, अर्नब एक प्रौद्योगिकी नेता थे और पहले आर्किटेक्ट और इंजीनियरिंग नेतृत्व की भूमिका निभा चुके थे।
 प्राची कुलकर्णी AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनकी विशेषज्ञता मशीन लर्निंग है, और वह विभिन्न एडब्ल्यूएस एमएल, बिग डेटा और एनालिटिक्स पेशकशों का उपयोग करके समाधान डिजाइन करने पर सक्रिय रूप से काम कर रही हैं। प्राची के पास स्वास्थ्य सेवा, लाभ, खुदरा और शिक्षा सहित कई क्षेत्रों में अनुभव है, और उन्होंने उत्पाद इंजीनियरिंग और वास्तुकला, प्रबंधन और ग्राहक सफलता में कई पदों पर काम किया है।
प्राची कुलकर्णी AWS में एक वरिष्ठ समाधान वास्तुकार हैं। उनकी विशेषज्ञता मशीन लर्निंग है, और वह विभिन्न एडब्ल्यूएस एमएल, बिग डेटा और एनालिटिक्स पेशकशों का उपयोग करके समाधान डिजाइन करने पर सक्रिय रूप से काम कर रही हैं। प्राची के पास स्वास्थ्य सेवा, लाभ, खुदरा और शिक्षा सहित कई क्षेत्रों में अनुभव है, और उन्होंने उत्पाद इंजीनियरिंग और वास्तुकला, प्रबंधन और ग्राहक सफलता में कई पदों पर काम किया है।
 टैमर शेरिफ प्रौद्योगिकी और उद्यम परामर्श सेवाओं के क्षेत्र में विविध पृष्ठभूमि के साथ, AWS में एक प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं, जिन्होंने सॉल्यूशन आर्किटेक्ट के रूप में 17 वर्षों से अधिक समय बिताया है। बुनियादी ढांचे पर ध्यान देने के साथ, टैमर की विशेषज्ञता वाणिज्यिक, स्वास्थ्य सेवा, ऑटोमोटिव, सार्वजनिक क्षेत्र, विनिर्माण, तेल और गैस, मीडिया सेवाओं और अन्य सहित उद्योग कार्यक्षेत्रों के व्यापक स्पेक्ट्रम को कवर करती है। उनकी दक्षता क्लाउड आर्किटेक्चर, एज कंप्यूटिंग, नेटवर्किंग, स्टोरेज, वर्चुअलाइजेशन, व्यावसायिक उत्पादकता और तकनीकी नेतृत्व जैसे विभिन्न डोमेन तक फैली हुई है।
टैमर शेरिफ प्रौद्योगिकी और उद्यम परामर्श सेवाओं के क्षेत्र में विविध पृष्ठभूमि के साथ, AWS में एक प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं, जिन्होंने सॉल्यूशन आर्किटेक्ट के रूप में 17 वर्षों से अधिक समय बिताया है। बुनियादी ढांचे पर ध्यान देने के साथ, टैमर की विशेषज्ञता वाणिज्यिक, स्वास्थ्य सेवा, ऑटोमोटिव, सार्वजनिक क्षेत्र, विनिर्माण, तेल और गैस, मीडिया सेवाओं और अन्य सहित उद्योग कार्यक्षेत्रों के व्यापक स्पेक्ट्रम को कवर करती है। उनकी दक्षता क्लाउड आर्किटेक्चर, एज कंप्यूटिंग, नेटवर्किंग, स्टोरेज, वर्चुअलाइजेशन, व्यावसायिक उत्पादकता और तकनीकी नेतृत्व जैसे विभिन्न डोमेन तक फैली हुई है।
 हंस नेस्बिट दक्षिणी कैलिफ़ोर्निया स्थित AWS में एक वरिष्ठ समाधान वास्तुकार हैं। वह अत्यधिक स्केलेबल, लचीले और लचीले क्लाउड आर्किटेक्चर तैयार करने के लिए पश्चिमी अमेरिका में ग्राहकों के साथ काम करता है। अपने खाली समय में, वह अपने परिवार के साथ समय बिताना, खाना बनाना और गिटार बजाना पसंद करते हैं।
हंस नेस्बिट दक्षिणी कैलिफ़ोर्निया स्थित AWS में एक वरिष्ठ समाधान वास्तुकार हैं। वह अत्यधिक स्केलेबल, लचीले और लचीले क्लाउड आर्किटेक्चर तैयार करने के लिए पश्चिमी अमेरिका में ग्राहकों के साथ काम करता है। अपने खाली समय में, वह अपने परिवार के साथ समय बिताना, खाना बनाना और गिटार बजाना पसंद करते हैं।
 चाओयांग हे फेडएमएल, इंक. के सह-संस्थापक और सीटीओ हैं, जो किसी भी पैमाने पर कहीं से भी खुले और सहयोगी एआई के सामुदायिक निर्माण के लिए चलने वाला एक स्टार्टअप है। उनका शोध वितरित और फ़ेडरेटेड मशीन लर्निंग एल्गोरिदम, सिस्टम और अनुप्रयोगों पर केंद्रित है। उन्होंने दक्षिणी कैलिफोर्निया विश्वविद्यालय से कंप्यूटर विज्ञान में पीएचडी प्राप्त की।
चाओयांग हे फेडएमएल, इंक. के सह-संस्थापक और सीटीओ हैं, जो किसी भी पैमाने पर कहीं से भी खुले और सहयोगी एआई के सामुदायिक निर्माण के लिए चलने वाला एक स्टार्टअप है। उनका शोध वितरित और फ़ेडरेटेड मशीन लर्निंग एल्गोरिदम, सिस्टम और अनुप्रयोगों पर केंद्रित है। उन्होंने दक्षिणी कैलिफोर्निया विश्वविद्यालय से कंप्यूटर विज्ञान में पीएचडी प्राप्त की।
 अल नेवारेज़ FedML में उत्पाद प्रबंधन के निदेशक हैं। फेडएमएल से पहले, वह Google में समूह उत्पाद प्रबंधक और लिंक्डइन में डेटा विज्ञान के वरिष्ठ प्रबंधक थे। उनके पास डेटा उत्पाद से संबंधित कई पेटेंट हैं, और उन्होंने स्टैनफोर्ड विश्वविद्यालय में इंजीनियरिंग की पढ़ाई की है।
अल नेवारेज़ FedML में उत्पाद प्रबंधन के निदेशक हैं। फेडएमएल से पहले, वह Google में समूह उत्पाद प्रबंधक और लिंक्डइन में डेटा विज्ञान के वरिष्ठ प्रबंधक थे। उनके पास डेटा उत्पाद से संबंधित कई पेटेंट हैं, और उन्होंने स्टैनफोर्ड विश्वविद्यालय में इंजीनियरिंग की पढ़ाई की है।
 सलमान एवेस्टीमर फेडएमएल के सह-संस्थापक और सीईओ हैं। वह यूएससी में डीन के प्रोफेसर, भरोसेमंद एआई पर यूएससी-अमेज़ॅन सेंटर के निदेशक और एलेक्सा एआई में अमेज़ॅन स्कॉलर रहे हैं। वह फ़ेडरेटेड और विकेन्द्रीकृत मशीन लर्निंग, सूचना सिद्धांत, सुरक्षा और गोपनीयता के विशेषज्ञ हैं। वह आईईईई के फेलो हैं और उन्होंने यूसी बर्कले से ईईसीएस में पीएचडी प्राप्त की है।
सलमान एवेस्टीमर फेडएमएल के सह-संस्थापक और सीईओ हैं। वह यूएससी में डीन के प्रोफेसर, भरोसेमंद एआई पर यूएससी-अमेज़ॅन सेंटर के निदेशक और एलेक्सा एआई में अमेज़ॅन स्कॉलर रहे हैं। वह फ़ेडरेटेड और विकेन्द्रीकृत मशीन लर्निंग, सूचना सिद्धांत, सुरक्षा और गोपनीयता के विशेषज्ञ हैं। वह आईईईई के फेलो हैं और उन्होंने यूसी बर्कले से ईईसीएस में पीएचडी प्राप्त की है।
 समीर लाड AWS के साथ एक निपुण एंटरप्राइज़ टेक्नोलॉजिस्ट है जो ग्राहकों के C-स्तर के अधिकारियों के साथ मिलकर काम करता है। एक पूर्व सी-सूट कार्यकारी के रूप में, जिन्होंने कई फॉर्च्यून 100 कंपनियों में परिवर्तन किए हैं, समीर अपने ग्राहकों को उनकी परिवर्तन यात्रा में सफल होने में मदद करने के लिए अपने अमूल्य अनुभव साझा करते हैं।
समीर लाड AWS के साथ एक निपुण एंटरप्राइज़ टेक्नोलॉजिस्ट है जो ग्राहकों के C-स्तर के अधिकारियों के साथ मिलकर काम करता है। एक पूर्व सी-सूट कार्यकारी के रूप में, जिन्होंने कई फॉर्च्यून 100 कंपनियों में परिवर्तन किए हैं, समीर अपने ग्राहकों को उनकी परिवर्तन यात्रा में सफल होने में मदद करने के लिए अपने अमूल्य अनुभव साझा करते हैं।
 स्टीफन क्रेमर AWS में एक बोर्ड और CxO सलाहकार और पूर्व कार्यकारी हैं। स्टीफन सफलता की नींव के रूप में संस्कृति और नेतृत्व की वकालत करते हैं। वह अत्यधिक प्रतिस्पर्धी, डेटा-संचालित संगठनों को सक्षम करने वाले क्लाउड परिवर्तन के चालकों में सुरक्षा और नवाचार का दावा करते हैं।
स्टीफन क्रेमर AWS में एक बोर्ड और CxO सलाहकार और पूर्व कार्यकारी हैं। स्टीफन सफलता की नींव के रूप में संस्कृति और नेतृत्व की वकालत करते हैं। वह अत्यधिक प्रतिस्पर्धी, डेटा-संचालित संगठनों को सक्षम करने वाले क्लाउड परिवर्तन के चालकों में सुरक्षा और नवाचार का दावा करते हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

