परिचय
एक हलचल भरे हवाई अड्डे की कल्पना करें जहाँ हर मिनट उड़ानें उड़ान भर रही हों और उतर रही हों। जिस तरह हवाई यातायात नियंत्रक तात्कालिकता के आधार पर उड़ानों को प्राथमिकता देते हैं, हीप्स हमें विशिष्ट मानदंडों के आधार पर डेटा को प्रबंधित और संसाधित करने में मदद करते हैं, यह सुनिश्चित करते हुए कि डेटा का सबसे "तत्काल" या "महत्वपूर्ण" टुकड़ा हमेशा शीर्ष पर पहुंच योग्य है।
इस गाइड में, हम जमीन से ऊपर तक ढेर को समझने की यात्रा शुरू करेंगे। हम ढेर क्या हैं और उनके अंतर्निहित गुणों को स्पष्ट करके शुरुआत करेंगे। वहां से, हम पाइथॉन के हीप्स कार्यान्वयन के बारे में गहराई से जानेंगे
heapqमॉड्यूल, और इसकी कार्यक्षमताओं के समृद्ध सेट का पता लगाएं। इसलिए, यदि आपने कभी सोचा है कि डेटा के गतिशील सेट को कुशलतापूर्वक कैसे प्रबंधित किया जाए जहां उच्चतम (या निम्नतम) प्राथमिकता तत्व की अक्सर आवश्यकता होती है, तो आप एक उपहार के लिए हैं।
ढेर क्या है?
ढेरों के उपयोग पर विचार करने से पहले पहली बात जो आप समझना चाहेंगे वह है ढेर क्या है. एक ढेर डेटा संरचनाओं की दुनिया में पेड़-आधारित पावरहाउस के रूप में खड़ा है, विशेष रूप से कुशल व्यवस्था और पदानुक्रम बनाए रखना. हालांकि अप्रशिक्षित आंखों के लिए यह एक द्विआधारी वृक्ष जैसा हो सकता है, लेकिन इसकी संरचना और संचालन नियमों की बारीकियां इसे स्पष्ट रूप से अलग करती हैं।
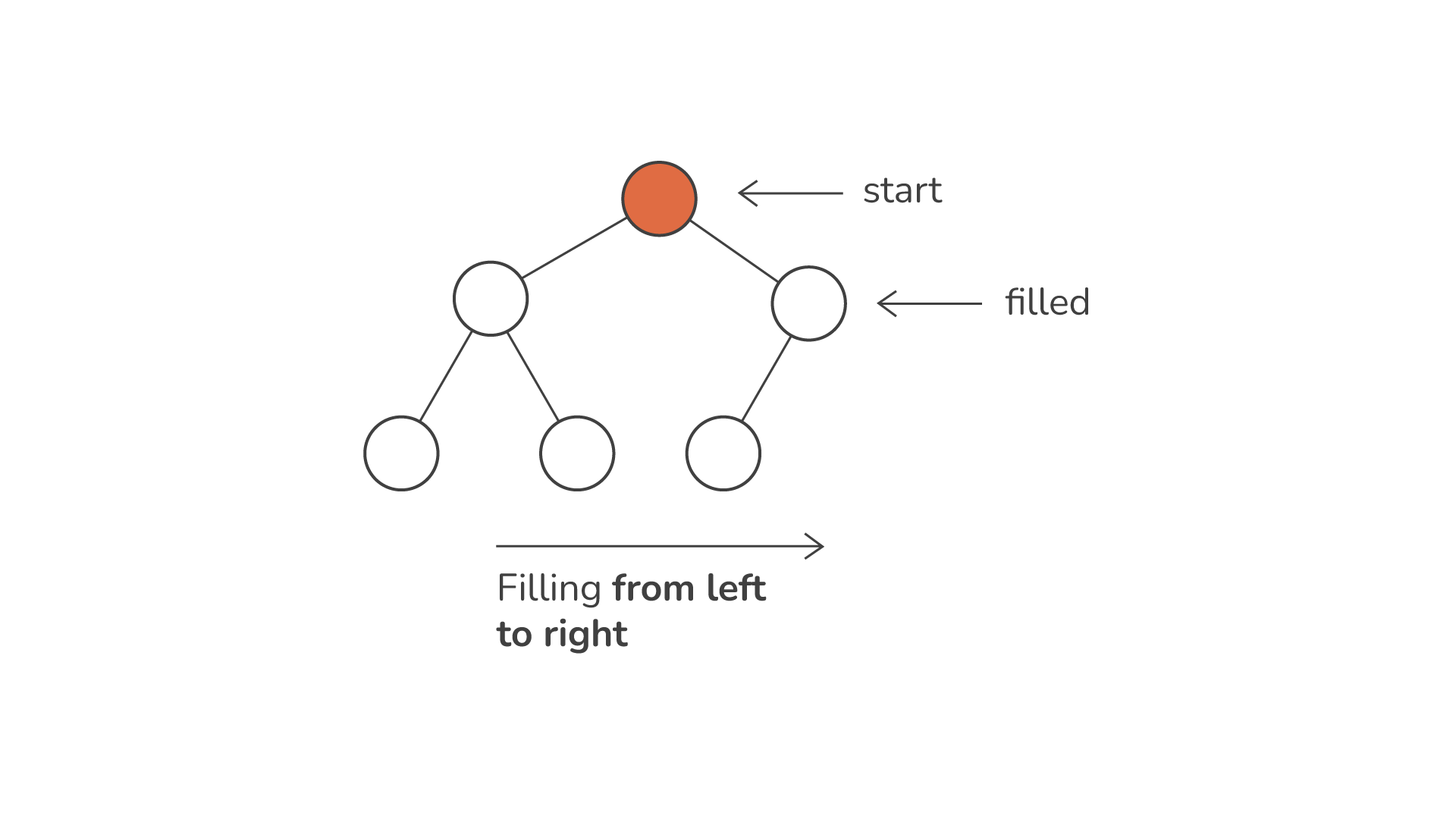
ढेर की परिभाषित विशेषताओं में से एक इसकी प्रकृति है पूरा बाइनरी ट्री. इसका मतलब यह है कि पेड़ का हर स्तर, शायद आखिरी को छोड़कर, पूरी तरह से भर गया है। इस अंतिम स्तर के भीतर, नोड्स बाएँ से दाएँ बढ़ते हैं। ऐसी संरचना यह सुनिश्चित करती है कि ढेरों को सरणियों या सूचियों का उपयोग करके कुशलतापूर्वक दर्शाया और हेरफेर किया जा सकता है, साथ ही सरणी में प्रत्येक तत्व की स्थिति पेड़ में उसके स्थान को प्रतिबिंबित करती है।
हालाँकि, ढेर का असली सार उसमें निहित है आदेश। में अधिकतम ढेर, किसी भी नोड का मान उसके बच्चों के मान से अधिक या उसके बराबर होता है, जो सबसे बड़े तत्व को ठीक जड़ में रखता है। दूसरी ओर, ए न्यूनतम ढेर विपरीत सिद्धांत पर कार्य करता है: किसी भी नोड का मान या तो उसके बच्चों के मान से कम या उसके बराबर होता है, जिससे यह सुनिश्चित होता है कि सबसे छोटा तत्व जड़ पर बैठता है।
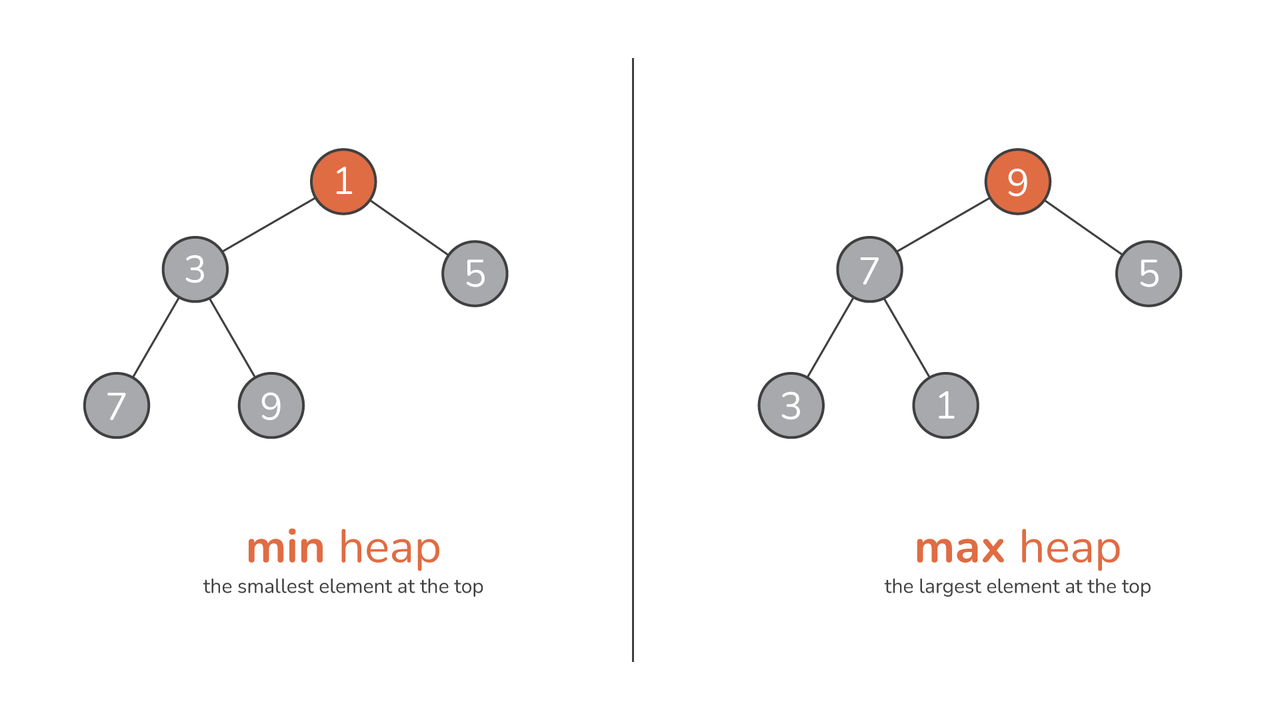
सलाह: आप एक ढेर की कल्पना इस प्रकार कर सकते हैं संख्याओं का पिरामिड. अधिकतम ढेर के लिए, जैसे-जैसे आप आधार से शिखर तक चढ़ते हैं, संख्याएँ बढ़ती हैं, शिखर पर अधिकतम मूल्य में परिणत होती हैं। इसके विपरीत, एक न्यूनतम ढेर अपने चरम पर न्यूनतम मूल्य के साथ शुरू होता है, जैसे-जैसे आप नीचे की ओर बढ़ते हैं, संख्या बढ़ती जाती है।
जैसे-जैसे हम आगे बढ़ेंगे, हम गहराई से जानेंगे कि कैसे हीप्स के ये अंतर्निहित गुण कुशल संचालन को सक्षम बनाते हैं और कैसे पायथन heapq मॉड्यूल हमारे कोडिंग प्रयासों में ढेरों को सहजता से एकीकृत करता है।
ढेर के लक्षण एवं गुण
हीप्स, अपनी अनूठी संरचना और ऑर्डरिंग सिद्धांतों के साथ, विशिष्ट विशेषताओं और गुणों का एक सेट सामने लाते हैं जो उन्हें विभिन्न कम्प्यूटेशनल परिदृश्यों में अमूल्य बनाते हैं।
सबसे पहले और सबसे महत्वपूर्ण, ढेर हैं स्वाभाविक रूप से कुशल. उनकी वृक्ष-आधारित संरचना, विशेष रूप से पूर्ण बाइनरी ट्री प्रारूप, यह सुनिश्चित करती है कि प्राथमिकता वाले तत्वों (अधिकतम या न्यूनतम) के सम्मिलन और निष्कर्षण जैसे संचालन आमतौर पर लॉगरिदमिक समय में किए जा सकते हैं O (लॉग एन). यह दक्षता उन एल्गोरिदम और अनुप्रयोगों के लिए एक वरदान है जिन्हें प्राथमिकता वाले तत्वों तक लगातार पहुंच की आवश्यकता होती है।
ढेर की एक और उल्लेखनीय संपत्ति उनकी है स्मृति दक्षता. चूँकि चाइल्ड या पैरेंट नोड्स के लिए स्पष्ट पॉइंटर्स की आवश्यकता के बिना ढेरों को सरणियों या सूचियों का उपयोग करके दर्शाया जा सकता है, वे स्थान-बचत कर रहे हैं। सरणी में प्रत्येक तत्व की स्थिति पेड़ में उसके स्थान से मेल खाती है, जो पूर्वानुमानित और सीधे ट्रैवर्सल और हेरफेर की अनुमति देती है।
ढेर की ऑर्डरिंग संपत्ति, चाहे अधिकतम ढेर या न्यूनतम ढेर के रूप में, यह सुनिश्चित करती है जड़ हमेशा सर्वोच्च प्राथमिकता का तत्व रखती है. यह सुसंगत क्रम संपूर्ण संरचना में खोज किए बिना शीर्ष-प्राथमिकता वाले तत्व तक त्वरित पहुंच की अनुमति देता है।
इसके अलावा, ढेर हैं बहुमुखी. जबकि बाइनरी हीप्स (जहां प्रत्येक माता-पिता के अधिकतम दो बच्चे होते हैं) सबसे आम हैं, हीप्स को दो से अधिक बच्चों के लिए सामान्यीकृत किया जा सकता है, जिन्हें इस रूप में जाना जाता है डी-एरी ढेर. यह लचीलापन विशिष्ट उपयोग के मामलों और प्रदर्शन आवश्यकताओं के आधार पर फ़ाइन-ट्यूनिंग की अनुमति देता है।
अंततः, ढेर हैं आत्म समायोजन. जब भी तत्वों को जोड़ा या हटाया जाता है, तो संरचना अपने गुणों को बनाए रखने के लिए खुद को पुनर्व्यवस्थित करती है। यह गतिशील संतुलन यह सुनिश्चित करता है कि ढेर हर समय अपने मुख्य संचालन के लिए अनुकूलित रहे।
सलाह: इन गुणों ने हीप डेटा संरचना को एक कुशल सॉर्टिंग एल्गोरिदम - हीप सॉर्ट के लिए उपयुक्त बना दिया। पायथन में हीप सॉर्ट के बारे में अधिक जानने के लिए, हमारा पढ़ें "पायथन में ढेर सॉर्ट करें" लेख.
जैसे-जैसे हम पायथन के कार्यान्वयन और व्यावहारिक अनुप्रयोगों में गहराई से उतरेंगे, ढेर की वास्तविक क्षमता हमारे सामने प्रकट होगी।
ढेर के प्रकार
सभी ढेर समान नहीं बनाए गए हैं. उनके क्रम और संरचनात्मक गुणों के आधार पर, ढेर को विभिन्न प्रकारों में वर्गीकृत किया जा सकता है, प्रत्येक के अपने अनुप्रयोगों और फायदों के साथ। दो मुख्य श्रेणियां हैं अधिकतम ढेर और न्यूनतम ढेर.
ए की सबसे विशिष्ट विशेषता अधिकतम ढेर यह है कि किसी दिए गए नोड का मान उसके बच्चों के मान से अधिक या उसके बराबर है। यह सुनिश्चित करता है कि ढेर में सबसे बड़ा तत्व हमेशा जड़ में रहता है। ऐसी संरचना विशेष रूप से तब उपयोगी होती है जब अधिकतम तत्व तक बार-बार पहुंचने की आवश्यकता होती है, जैसा कि कुछ प्राथमिकता कतार कार्यान्वयन में होता है।
अधिकतम ढेर का समकक्ष, ए न्यूनतम ढेर यह सुनिश्चित करता है कि किसी दिए गए नोड का मान उसके बच्चों के मान से कम या उसके बराबर है। यह ढेर के सबसे छोटे तत्व को जड़ में स्थित करता है। न्यूनतम ढेर उन परिदृश्यों में अमूल्य हैं जहां कम से कम तत्व प्रमुख महत्व का है, जैसे कि एल्गोरिदम में जो वास्तविक समय डेटा प्रोसेसिंग से निपटते हैं।
इन प्राथमिक श्रेणियों के अलावा, ढेरों को उनके शाखा कारक के आधार पर भी अलग किया जा सकता है:
जबकि बाइनरी हीप्स सबसे आम हैं, प्रत्येक माता-पिता के अधिकतम दो बच्चे होते हैं, हीप्स की अवधारणा को दो से अधिक बच्चों वाले नोड्स तक बढ़ाया जा सकता है। में एक डी-एरी ढेर, प्रत्येक नोड में अधिकतम है d बच्चे। इस भिन्नता को विशिष्ट परिदृश्यों के लिए अनुकूलित किया जा सकता है, जैसे कुछ कार्यों को तेज करने के लिए पेड़ की ऊंचाई कम करना।
द्विपद ढेर द्विपद वृक्षों का एक समूह है जिसे पुनरावर्ती रूप से परिभाषित किया गया है। द्विपद हीप्स का उपयोग प्राथमिकता कतार कार्यान्वयन में किया जाता है और कुशल मर्ज संचालन प्रदान करता है।
प्रसिद्ध फाइबोनैचि अनुक्रम के नाम पर, फाइबोनैचि ढेर बाइनरी या बाइनोमियल हीप्स की तुलना में कई परिचालनों के लिए बेहतर-परिशोधित रनिंग समय प्रदान करता है। वे नेटवर्क अनुकूलन एल्गोरिदम में विशेष रूप से उपयोगी हैं।
पायथन का ढेर कार्यान्वयन - द heapq मॉड्यूल
पायथन हीप संचालन के लिए एक अंतर्निहित मॉड्यूल प्रदान करता है - heapq मापांक। यह मॉड्यूल ढेर-संबंधित कार्यों का एक संग्रह प्रदान करता है जो डेवलपर्स को सूचियों को ढेर में बदलने और कस्टम कार्यान्वयन की आवश्यकता के बिना विभिन्न ढेर संचालन करने की अनुमति देता है। आइए इस मॉड्यूल की बारीकियों के बारे में जानें और यह कैसे आपके लिए ढेरों की शक्ति लाता है।
RSI heapq मॉड्यूल एक अलग हीप डेटा प्रकार प्रदान नहीं करता है। इसके बजाय, यह ऐसे फ़ंक्शंस प्रदान करता है जो नियमित पायथन सूचियों पर काम करते हैं, उन्हें बदलते हैं और उनके साथ व्यवहार करते हैं बाइनरी ढेर.
यह दृष्टिकोण मेमोरी-कुशल दोनों है और पायथन की मौजूदा डेटा संरचनाओं के साथ सहजता से एकीकृत होता है।
इसका मतलब है कि ढेरों को सूचियों के रूप में दर्शाया जाता है in heapq. इस प्रतिनिधित्व की सुंदरता इसकी सादगी है - शून्य-आधारित सूची सूचकांक प्रणाली एक अंतर्निहित बाइनरी ट्री के रूप में कार्य करती है। स्थिति में किसी दिए गए तत्व के लिए i, इसका:
- बायाँ बच्चा स्थान पर है
2*i + 1 - राइट चाइल्ड पोजीशन पर है
2*i + 2 - पैरेंट नोड स्थिति पर है
(i-1)//2
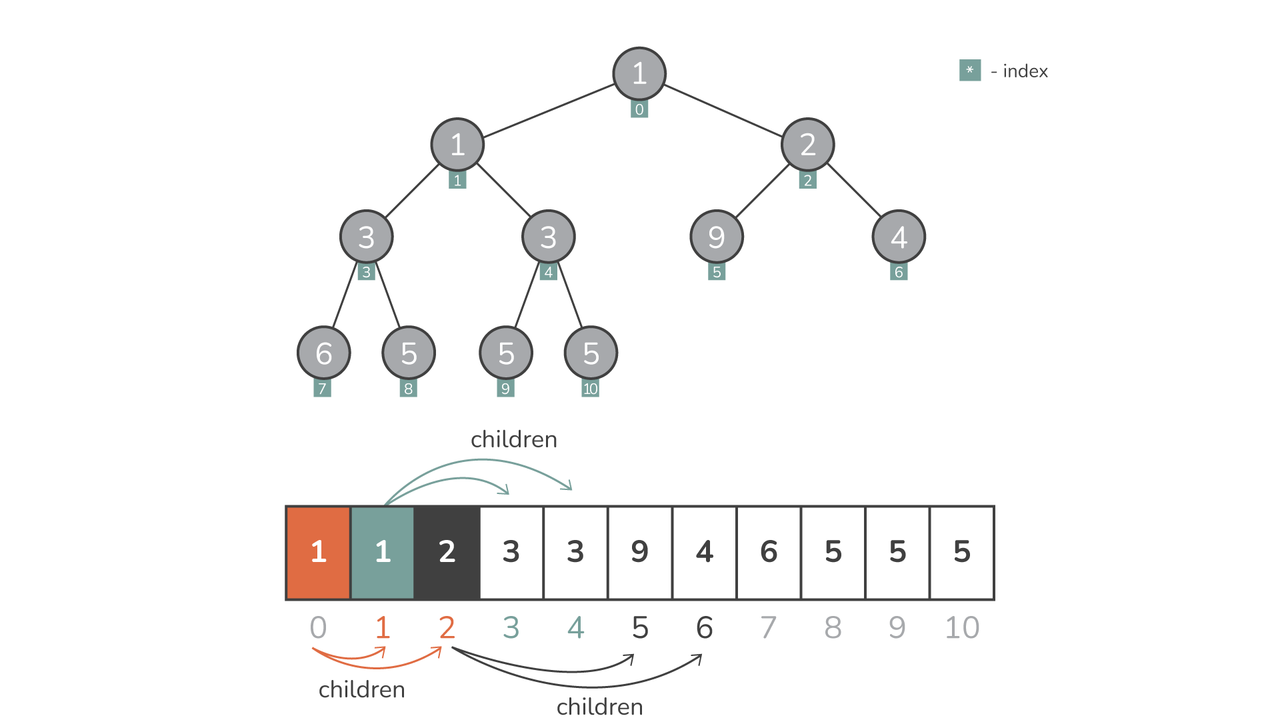
यह अंतर्निहित संरचना सुनिश्चित करती है कि अलग नोड-आधारित बाइनरी ट्री प्रतिनिधित्व की कोई आवश्यकता नहीं है, जिससे संचालन सरल हो जाता है और मेमोरी का उपयोग न्यूनतम हो जाता है।
अंतरिक्ष जटिलता: हीप्स को आमतौर पर बाइनरी ट्री के रूप में कार्यान्वित किया जाता है लेकिन चाइल्ड नोड्स के लिए स्पष्ट पॉइंटर्स के भंडारण की आवश्यकता नहीं होती है। यह उन्हें अंतरिक्ष जटिलता के साथ अंतरिक्ष-कुशल बनाता है पर) n तत्वों को संग्रहीत करने के लिए।
यह ध्यान रखना आवश्यक है कि heapq मॉड्यूल डिफ़ॉल्ट रूप से न्यूनतम ढेर बनाता है. इसका मतलब यह है कि सबसे छोटा तत्व हमेशा मूल (या सूची में पहले स्थान) पर होता है। यदि आपको अधिकतम ढेर की आवश्यकता है, तो आपको तत्वों को गुणा करके क्रम को उलटना होगा -1 या कस्टम तुलना फ़ंक्शन का उपयोग करें.
पायथन के heapq मॉड्यूल फ़ंक्शंस का एक सूट प्रदान करता है जो डेवलपर्स को सूचियों पर विभिन्न ढेर संचालन करने की अनुमति देता है।
नोट: का उपयोग करने के लिए heapq आपके एप्लिकेशन में मॉड्यूल, आपको इसे सरल का उपयोग करके आयात करना होगा import heapq.
निम्नलिखित अनुभागों में, हम इनमें से प्रत्येक मूलभूत संचालन में गहराई से उतरेंगे, उनके यांत्रिकी और उपयोग के मामलों की खोज करेंगे।
किसी सूची को ढेर में कैसे बदलें
RSI heapify() फ़ंक्शन हीप से संबंधित कई कार्यों के लिए प्रारंभिक बिंदु है। यह एक पुनरावर्तनीय (आमतौर पर एक सूची) लेता है और न्यूनतम ढेर के गुणों को संतुष्ट करने के लिए इसके तत्वों को पुन: व्यवस्थित करता है:
सर्वोत्तम प्रथाओं, उद्योग-स्वीकृत मानकों और शामिल चीट शीट के साथ, Git सीखने के लिए व्यावहारिक मार्गदर्शिका देखें। Googling Git कमांड को रोकें और वास्तव में सीखना यह!
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
heapq.heapify(data)
print(data)
यह एक पुन: व्यवस्थित सूची आउटपुट करेगा जो वैध न्यूनतम ढेर का प्रतिनिधित्व करता है:
[1, 1, 2, 3, 3, 9, 4, 6, 5, 5, 5]
समय जटिलता: का उपयोग करके एक अव्यवस्थित सूची को ढेर में परिवर्तित करना heapify फ़ंक्शन एक है पर) संचालन। यह उल्टा लग सकता है, जैसा कि कोई उम्मीद कर सकता है ओ (nlogn), लेकिन वृक्ष संरचना के गुणों के कारण, इसे रैखिक समय में प्राप्त किया जा सकता है।
ढेर में एक तत्व कैसे जोड़ें
RSI heappush() फ़ंक्शन आपको ढेर के गुणों को बनाए रखते हुए ढेर में एक नया तत्व डालने की अनुमति देता है:
import heapq heap = []
heapq.heappush(heap, 5)
heapq.heappush(heap, 3)
heapq.heappush(heap, 7)
print(heap)
कोड चलाने से आपको न्यूनतम ढेर संपत्ति को बनाए रखने वाले तत्वों की एक सूची मिलेगी:
[3, 5, 7]
समय जटिलता: ढेर में सम्मिलन ऑपरेशन, जिसमें ढेर की संपत्ति को बनाए रखते हुए ढेर में एक नया तत्व रखना शामिल है, में समय की जटिलता होती है ओ (logn). ऐसा इसलिए है, क्योंकि सबसे खराब स्थिति में, तत्व को पत्ती से जड़ तक यात्रा करनी पड़ सकती है।
ढेर से सबसे छोटे तत्व को कैसे निकालें और वापस कैसे करें
RSI heappop() फ़ंक्शन ढेर से सबसे छोटा तत्व निकालता है और लौटाता है (एक न्यूनतम ढेर में जड़)। हटाने के बाद, यह सुनिश्चित करता है कि सूची वैध ढेर बनी रहे:
import heapq heap = [1, 3, 5, 7, 9]
print(heapq.heappop(heap))
print(heap)
नोट: RSI heappop() उन एल्गोरिदम में अमूल्य है जिनके लिए तत्वों को आरोही क्रम में संसाधित करने की आवश्यकता होती है, जैसे हीप सॉर्ट एल्गोरिदम, या प्राथमिकता कतारों को लागू करते समय जहां कार्यों को उनकी तात्कालिकता के आधार पर निष्पादित किया जाता है।
यह सबसे छोटे तत्व और शेष सूची को आउटपुट करेगा:
1
[3, 7, 5, 9]
यहाँ, 1 से सबसे छोटा तत्व है heap, और शेष सूची ने हमारे हटाए जाने के बाद भी ढेर संपत्ति को बनाए रखा है 1.
समय जटिलता: मूल तत्व को हटाना (जो न्यूनतम ढेर में सबसे छोटा या अधिकतम ढेर में सबसे बड़ा है) और ढेर को पुनर्गठित करना भी आवश्यक है ओ (logn) समय है.
किसी नए आइटम को कैसे पुश करें और सबसे छोटे आइटम को कैसे पॉप करें
RSI heappushpop() फ़ंक्शन एक संयुक्त ऑपरेशन है जो एक नई वस्तु को ढेर पर धकेलता है और फिर ढेर से सबसे छोटी वस्तु को पॉप और लौटाता है:
import heapq heap = [3, 5, 7, 9]
print(heapq.heappushpop(heap, 4)) print(heap)
यह आउटपुट करेगा 3, सबसे छोटा तत्व, और नया प्रिंट करें heap सूची जिसमें अब शामिल है 4 ढेर संपत्ति को बनाए रखते समय:
3
[4, 5, 7, 9]
नोट: ऊपर दिए heappushpop() फ़ंक्शन किसी नए तत्व को पुश करने और सबसे छोटे तत्व को अलग से पॉप करने के संचालन की तुलना में अधिक कुशल है।
सबसे छोटी वस्तु को कैसे बदलें और एक नई वस्तु कैसे डालें
RSI heapreplace() फ़ंक्शन सबसे छोटे तत्व को पॉप करता है और एक नए तत्व को ढेर पर धकेलता है, यह सब एक कुशल ऑपरेशन में:
import heapq heap = [1, 5, 7, 9]
print(heapq.heapreplace(heap, 4))
print(heap)
यह प्रिंट 1, सबसे छोटा तत्व, और सूची में अब 4 शामिल हैं और ढेर गुण बनाए रखता है:
1
[4, 5, 7, 9]
नोट: heapreplace() स्ट्रीमिंग परिदृश्यों में फायदेमंद है जहां आप वर्तमान सबसे छोटे तत्व को एक नए मान के साथ बदलना चाहते हैं, जैसे रोलिंग विंडो संचालन या रीयल-टाइम डेटा प्रोसेसिंग कार्यों में।
पायथन के ढेर में एकाधिक चरम सीमाएँ ढूँढना
nlargest(n, iterable[, key]) और nsmallest(n, iterable[, key]) फ़ंक्शंस को पुनरावर्तनीय से कई सबसे बड़े या सबसे छोटे तत्वों को पुनः प्राप्त करने के लिए डिज़ाइन किया गया है। जब आपको केवल कुछ चरम मूल्यों की आवश्यकता होती है तो वे संपूर्ण पुनरावर्तनीय को क्रमबद्ध करने से अधिक कुशल हो सकते हैं। उदाहरण के लिए, मान लें कि आपके पास निम्नलिखित सूची है और आप सूची में तीन सबसे छोटे और तीन सबसे बड़े मान ढूंढना चाहते हैं:
data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
यहाँ, nlargest() और nsmallest() फ़ंक्शन काम आ सकते हैं:
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
print(heapq.nlargest(3, data)) print(heapq.nsmallest(3, data)) इससे आपको दो सूचियाँ मिलेंगी - एक में तीन सबसे बड़े मान होंगे और दूसरे में तीन सबसे छोटे मान होंगे data सूची:
[9, 6, 5]
[1, 1, 2]
अपना कस्टम ढेर कैसे बनाएं
जबकि पाइथॉन का heapq मॉड्यूल ढेर के साथ काम करने के लिए उपकरणों का एक मजबूत सेट प्रदान करता है, ऐसे परिदृश्य हैं जहां डिफ़ॉल्ट न्यूनतम ढेर व्यवहार पर्याप्त नहीं हो सकता है। चाहे आप एक अधिकतम हीप लागू करना चाह रहे हों या एक ऐसे हीप की आवश्यकता हो जो कस्टम तुलना कार्यों के आधार पर संचालित हो, एक कस्टम हीप बनाना इसका उत्तर हो सकता है। आइए जानें कि ढेरों को विशिष्ट आवश्यकताओं के अनुरूप कैसे तैयार किया जाए।
का उपयोग करके मैक्स हीप को कार्यान्वित करना heapq
डिफ़ॉल्ट रूप से, heapq बनाता है न्यूनतम ढेर. हालाँकि, एक सरल तरकीब से, आप इसका उपयोग अधिकतम ढेर लागू करने के लिए कर सकते हैं। विचार यह है कि तत्वों को गुणा करके उनके क्रम को उलटा किया जाए -1 उन्हें ढेर में जोड़ने से पहले:
import heapq class MaxHeap: def __init__(self): self.heap = [] def push(self, val): heapq.heappush(self.heap, -val) def pop(self): return -heapq.heappop(self.heap) def peek(self): return -self.heap[0]
इस दृष्टिकोण के साथ, सबसे बड़ी संख्या (निरपेक्ष मूल्य के संदर्भ में) सबसे छोटी हो जाती है, जिससे अनुमति मिलती है heapq अधिकतम ढेर संरचना को बनाए रखने के लिए कार्य करता है।
कस्टम तुलना कार्यों के साथ ढेर
कभी-कभी, आपको ऐसे ढेर की आवश्यकता हो सकती है जो केवल तत्वों के प्राकृतिक क्रम के आधार पर तुलना न करे। उदाहरण के लिए, यदि आप जटिल वस्तुओं के साथ काम कर रहे हैं या आपके पास विशिष्ट सॉर्टिंग मानदंड हैं, तो एक कस्टम तुलना फ़ंक्शन आवश्यक हो जाता है।
इसे प्राप्त करने के लिए, आप तत्वों को एक सहायक वर्ग में लपेट सकते हैं जो तुलना ऑपरेटरों को ओवरराइड करता है:
import heapq class CustomElement: def __init__(self, obj, comparator): self.obj = obj self.comparator = comparator def __lt__(self, other): return self.comparator(self.obj, other.obj) def custom_heappush(heap, obj, comparator=lambda x, y: x < y): heapq.heappush(heap, CustomElement(obj, comparator)) def custom_heappop(heap): return heapq.heappop(heap).obj
इस सेटअप के साथ, आप किसी भी कस्टम तुलनित्र फ़ंक्शन को परिभाषित कर सकते हैं और इसे हीप के साथ उपयोग कर सकते हैं।
निष्कर्ष
हीप्स कई परिचालनों के लिए पूर्वानुमानित प्रदर्शन प्रदान करता है, जिससे वे प्राथमिकता-आधारित कार्यों के लिए एक विश्वसनीय विकल्प बन जाते हैं। हालाँकि, मौजूदा एप्लिकेशन की विशिष्ट आवश्यकताओं और विशेषताओं पर विचार करना आवश्यक है। कुछ मामलों में, हीप के कार्यान्वयन में बदलाव या यहां तक कि वैकल्पिक डेटा संरचनाओं को चुनने से वास्तविक दुनिया में बेहतर प्रदर्शन मिल सकता है।
हीप्स, जैसा कि हमने यात्रा की है, केवल एक अन्य डेटा संरचना से कहीं अधिक है। वे दक्षता, संरचना और अनुकूलनशीलता के संगम का प्रतिनिधित्व करते हैं। उनके मूलभूत गुणों से लेकर पायथन में उनके कार्यान्वयन तक heapq मॉड्यूल, हीप्स असंख्य कम्प्यूटेशनल चुनौतियों के लिए एक मजबूत समाधान प्रदान करता है, विशेष रूप से प्राथमिकता के आसपास केंद्रित।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://stackabuse.com/guide-to-heaps-in-python/

