गेमिंग, खुदरा और वित्त से लेकर विनिर्माण, स्वास्थ्य सेवा और यात्रा तक वैश्विक स्तर पर उत्पन्न डेटा की मात्रा में वृद्धि जारी है। संगठन अपने व्यवसायों और ग्राहकों के लिए नवाचार करने के लिए डेटा के निरंतर प्रवाह का त्वरित उपयोग करने के और तरीके तलाश रहे हैं। उन्हें वास्तविक समय में डेटा को विश्वसनीय रूप से कैप्चर करना, संसाधित करना, विश्लेषण करना और असंख्य डेटा स्टोर में लोड करना होगा।
अपाचे काफ्का इन वास्तविक समय की स्ट्रीमिंग आवश्यकताओं के लिए एक लोकप्रिय विकल्प है। हालाँकि, अन्य डेटा प्रोसेसिंग घटकों के साथ काफ्का क्लस्टर स्थापित करना चुनौतीपूर्ण हो सकता है जो आपके एप्लिकेशन की आवश्यकताओं के आधार पर स्वचालित रूप से स्केल करते हैं। आप चरम ट्रैफ़िक के लिए कम प्रावधान करने का जोखिम उठाते हैं, जिससे डाउनटाइम हो सकता है, या बेस लोड के लिए अधिक प्रावधान हो सकता है, जिससे बर्बादी हो सकती है। AWS कई सर्वर रहित सेवाएँ प्रदान करता है जैसे Apache Kafka के लिए Amazon प्रबंधित स्ट्रीमिंग (अमेज़ॅन एमएसके), अमेज़ॅन डेटा फ़ायरहोज़, अमेज़ॅन डायनेमोडीबी, तथा AWS लाम्बा वह पैमाना आपकी आवश्यकताओं के आधार पर स्वचालित रूप से होता है।
इस पोस्ट में, हम बताते हैं कि आप इनमें से कुछ सेवाओं का उपयोग कैसे कर सकते हैं एमएसके सर्वर रहित, आपकी वास्तविक समय की जरूरतों को पूरा करने के लिए एक सर्वर रहित डेटा प्लेटफ़ॉर्म बनाने के लिए।
समाधान अवलोकन
आइए एक परिदृश्य की कल्पना करें. आप कई भौगोलिक क्षेत्रों में तैनात एक इंटरनेट सेवा प्रदाता के लिए हजारों मॉडेम के प्रबंधन के लिए जिम्मेदार हैं। आप मॉडेम कनेक्टिविटी गुणवत्ता की निगरानी करना चाहते हैं जिसका ग्राहक उत्पादकता और संतुष्टि पर महत्वपूर्ण प्रभाव पड़ता है। आपकी तैनाती में विभिन्न मॉडेम शामिल हैं जिन्हें न्यूनतम डाउनटाइम सुनिश्चित करने के लिए निगरानी और रखरखाव की आवश्यकता होती है। प्रत्येक डिवाइस हर सेकंड हजारों 1 केबी रिकॉर्ड प्रसारित करता है, जैसे सीपीयू उपयोग, मेमोरी उपयोग, अलार्म और कनेक्शन स्थिति। आप इस डेटा तक वास्तविक समय में पहुंच चाहते हैं ताकि आप वास्तविक समय में प्रदर्शन की निगरानी कर सकें, और समस्याओं का तुरंत पता लगा सकें और उन्हें कम कर सकें। पूर्वानुमानित रखरखाव मूल्यांकन चलाने, अनुकूलन के अवसर खोजने और मांग का पूर्वानुमान लगाने के लिए आपको मशीन लर्निंग (एमएल) मॉडल के लिए इस डेटा तक दीर्घकालिक पहुंच की भी आवश्यकता है।
आपके ग्राहक जो डेटा ऑनसाइट एकत्र करते हैं, वे पायथन में लिखे गए हैं, और वे सभी डेटा को अपाचे काफ्का विषयों के रूप में अमेज़ॅन एमएसके को भेज सकते हैं। अपने एप्लिकेशन की कम-विलंबता और वास्तविक समय डेटा पहुंच के लिए, आप इसका उपयोग कर सकते हैं लैम्ब्डा और डायनेमोडीबी. लंबी अवधि के डेटा भंडारण के लिए, आप प्रबंधित सर्वर रहित कनेक्टर सेवा का उपयोग कर सकते हैं अमेज़ॅन डेटा फ़ायरहोज़ अपने डेटा लेक में डेटा भेजने के लिए।
निम्नलिखित चित्र दिखाता है कि आप इस एंड-टू-एंड सर्वर रहित एप्लिकेशन को कैसे बना सकते हैं।
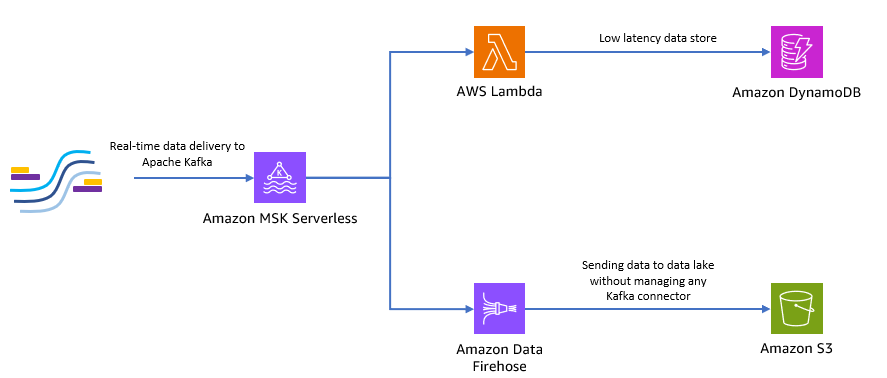
आइए इस आर्किटेक्चर को लागू करने के लिए निम्नलिखित अनुभागों में दिए गए चरणों का पालन करें।
Amazon MSK पर सर्वर रहित काफ्का क्लस्टर बनाएं
हम मॉडेम से वास्तविक समय टेलीमेट्री डेटा प्राप्त करने के लिए अमेज़ॅन एमएसके का उपयोग करते हैं। Amazon MSK पर सर्वर रहित काफ्का क्लस्टर बनाना सीधा है। इसका उपयोग करने में केवल कुछ मिनट लगते हैं एडब्ल्यूएस प्रबंधन कंसोल या एडब्ल्यूएस एसडीके। कंसोल का उपयोग करने के लिए, देखें MSK सर्वर रहित क्लस्टर का उपयोग करना प्रारंभ करना. आप एक सर्वर रहित क्लस्टर बनाते हैं, AWS पहचान और अभिगम प्रबंधन (IAM) भूमिका, और क्लाइंट मशीन।
पायथन का उपयोग करके एक काफ्का विषय बनाएं
जब आपका क्लस्टर और क्लाइंट मशीन तैयार हो जाए, तो अपने क्लाइंट मशीन पर एसएसएच करें और पायथन के लिए काफ्का पायथन और एमएसके आईएएम लाइब्रेरी स्थापित करें।
- काफ्का पायथन और स्थापित करने के लिए निम्नलिखित कमांड चलाएँ एमएसके आईएएम लाइब्रेरी:
- नामक एक नई फ़ाइल बनाएँ
createTopic.py. - इस फ़ाइल में निम्न कोड को प्रतिस्थापित करते हुए कॉपी करें
bootstrap_serversऔरregionआपके क्लस्टर के विवरण के साथ जानकारी। पुनः प्राप्त करने के निर्देशों के लिएbootstrap_serversआपके MSK क्लस्टर के लिए जानकारी, देखें Amazon MSK क्लस्टर के लिए बूटस्ट्रैप ब्रोकर प्राप्त करना.
- चलाएं
createTopic.pyएक नया काफ्का विषय बनाने के लिए स्क्रिप्ट कहा जाता हैmytopicआपके सर्वर रहित क्लस्टर पर:
पायथन का उपयोग करके रिकॉर्ड तैयार करें
आइए कुछ नमूना मॉडेम टेलीमेट्री डेटा उत्पन्न करें।
- नामक एक नई फ़ाइल बनाएँ
kafkaDataGen.py. - अद्यतन करते हुए, निम्न कोड को इस फ़ाइल में कॉपी करें
BROKERSऔरregionआपके क्लस्टर के विवरण सहित जानकारी:
- चलाएं
kafkaDataGen.pyलगातार यादृच्छिक डेटा उत्पन्न करने और इसे निर्दिष्ट काफ्का विषय पर प्रकाशित करने के लिए:
Amazon S3 में इवेंट स्टोर करें
अब आप सभी कच्चे ईवेंट डेटा को एक में संग्रहीत करते हैं अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) एनालिटिक्स के लिए डेटा लेक। आप एमएल मॉडल को प्रशिक्षित करने के लिए उसी डेटा का उपयोग कर सकते हैं। अमेज़ॅन डेटा फ़ायरहोज़ के साथ एकीकरण अमेज़ॅन MSK को आपके अपाचे काफ्का क्लस्टर से डेटा को S3 डेटा लेक में निर्बाध रूप से लोड करने की अनुमति देता है। अपने स्वयं के कनेक्टर एप्लिकेशन बनाने या प्रबंधित करने की आवश्यकता को समाप्त करते हुए, काफ्का से अमेज़ॅन S3 तक डेटा को लगातार स्ट्रीम करने के लिए निम्नलिखित चरणों को पूरा करें:
- Amazon S3 कंसोल पर, एक नई बकेट बनाएं। आप मौजूदा बाल्टी का भी उपयोग कर सकते हैं।
- अपने S3 बकेट में एक नया फ़ोल्डर बनाएँ जिसे कहा जाता है
streamingDataLake. - Amazon MSK कंसोल पर, अपना MSK सर्वर रहित क्लस्टर चुनें।
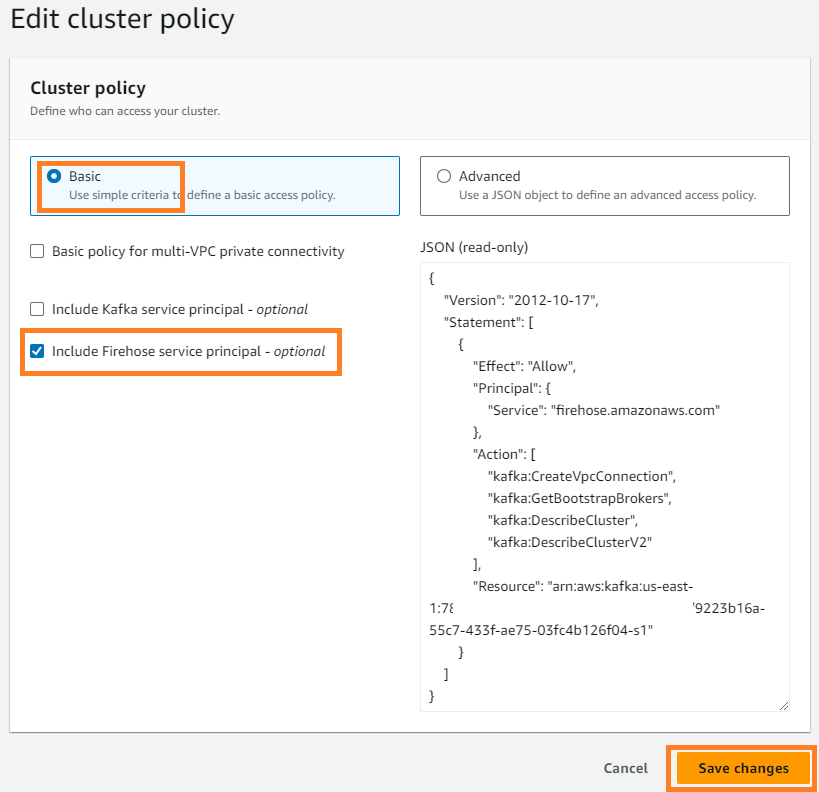
- पर क्रियाएँ मेनू, चुनें क्लस्टर नीति संपादित करें.

- चुनते हैं फ़ायरहोज़ सेवा प्रिंसिपल शामिल करें और चुनें परिवर्तन सहेजें.
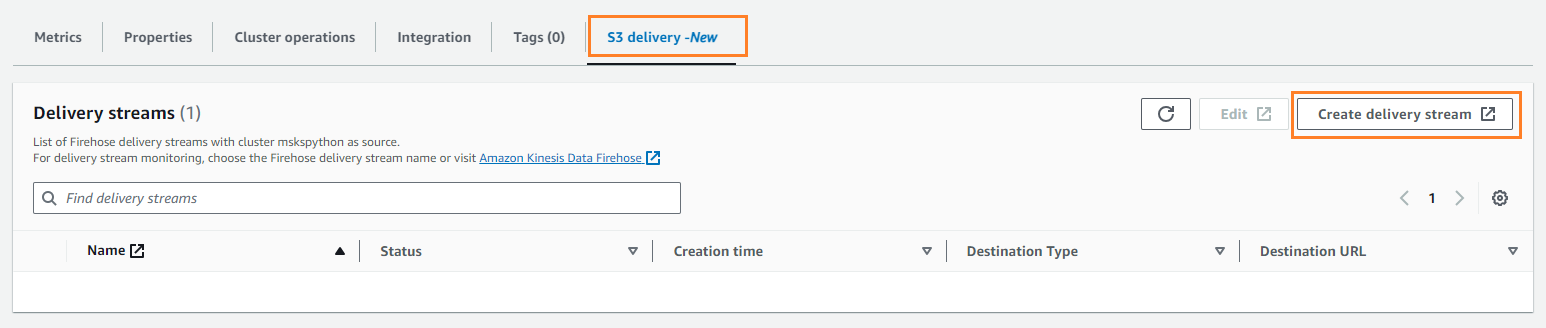
- पर S3 डिलिवरी टैब चुनें वितरण स्ट्रीम बनाएं.
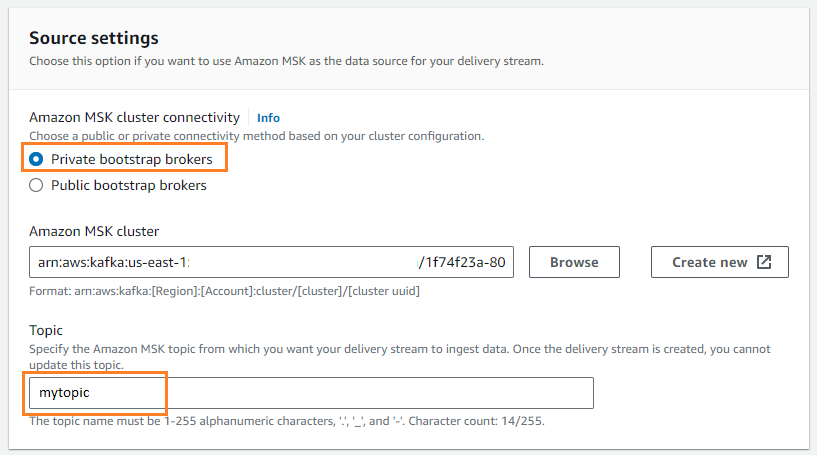
- के लिए स्रोत, चुनें अमेज़ॅन एमएसके.
- के लिए गंतव्य, चुनें अमेज़न S3.

- के लिए अमेज़ॅन एमएसके क्लस्टर कनेक्टिविटी, चुनते हैं निजी बूटस्ट्रैप दलाल.
- के लिए विषय, विषय का नाम दर्ज करें (इस पोस्ट के लिए,
mytopic).
- के लिए S3 बाल्टी, चुनें ब्राउज और अपनी S3 बाल्टी चुनें।
- दर्ज
streamingDataLakeआपके S3 बकेट उपसर्ग के रूप में। - दर्ज
streamingDataLakeErrआपके S3 बकेट त्रुटि आउटपुट उपसर्ग के रूप में।

- चुनें वितरण स्ट्रीम बनाएं.
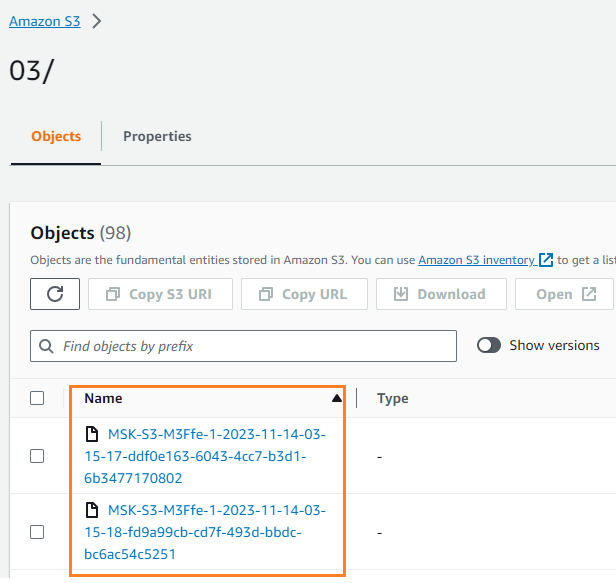
आप सत्यापित कर सकते हैं कि डेटा आपके S3 बकेट में लिखा गया था। आपको यह देखना चाहिए कि streamingDataLake निर्देशिका बनाई गई थी और फ़ाइलें विभाजन में संग्रहीत हैं।
DynamoDB में ईवेंट संग्रहीत करें
अंतिम चरण के लिए, आप नवीनतम मॉडेम डेटा को DynamoDB में संग्रहीत करते हैं। यह क्लाइंट एप्लिकेशन को मॉडेम स्थिति तक पहुंचने और कम विलंबता और उच्च उपलब्धता के साथ कहीं से भी मॉडेम के साथ बातचीत करने की अनुमति देता है। लैम्ब्डा अमेज़ॅन एमएसके के साथ सहजता से काम करता है. लैम्ब्डा आंतरिक रूप से इवेंट स्रोत से नए संदेशों के लिए सर्वेक्षण करता है और फिर समकालिक रूप से लक्ष्य लैम्ब्डा फ़ंक्शन को आमंत्रित करता है। लैम्ब्डा संदेशों को बैचों में पढ़ता है और इन्हें आपके फ़ंक्शन को इवेंट पेलोड के रूप में प्रदान करता है।
आइए सबसे पहले DynamoDB में एक तालिका बनाएं। को देखें DynamoDB API अनुमतियाँ: क्रियाएँ, संसाधन और शर्तें संदर्भ यह सत्यापित करने के लिए कि आपकी क्लाइंट मशीन के पास आवश्यक अनुमतियाँ हैं।
- नामक एक नई फ़ाइल बनाएँ
createTable.py. - अद्यतन करते हुए, निम्न कोड को फ़ाइल में कॉपी करें
regionजानकारी:
- चलाएं
createTable.pyतालिका बनाने के लिए स्क्रिप्ट कहा जाता हैdevice_statusडायनेमोडीबी में:
अब लैम्ब्डा फ़ंक्शन को कॉन्फ़िगर करते हैं।
- लैम्ब्डा कंसोल पर, चुनें कार्य नेविगेशन फलक में
- चुनें फ़ंक्शन बनाएं.
- चुनते हैं खरोंच से लेखक.
- के लिए कार्य का नामएक नाम दर्ज करें (उदाहरण के लिए,
my-notification-kafka). - के लिए क्रम, चुनें अजगर 3.11.
- के लिए अनुमतियाँ, चुनते हैं किसी मौजूदा भूमिका का उपयोग करें और एक भूमिका चुनें आपके क्लस्टर से पढ़ने की अनुमति.
- फ़ंक्शन बनाएं.
लैम्ब्डा फ़ंक्शन कॉन्फ़िगरेशन पृष्ठ पर, अब आप स्रोतों, गंतव्यों और अपने एप्लिकेशन कोड को कॉन्फ़िगर कर सकते हैं।
- चुनें ट्रिगर जोड़ें.
- के लिए ट्रिगर कॉन्फ़िगरेशन, दर्ज
MSKलैम्ब्डा स्रोत फ़ंक्शन के लिए ट्रिगर के रूप में अमेज़ॅन एमएसके को कॉन्फ़िगर करने के लिए। - के लिए एमएसके क्लस्टर, दर्ज
myCluster. - अचयनित ट्रिगर सक्रिय करें, क्योंकि आपने अभी तक अपना लैम्ब्डा फ़ंक्शन कॉन्फ़िगर नहीं किया है।
- के लिए बैच का आकार, दर्ज
100. - के लिए शुरुआत का स्थान, चुनें Latest.
- के लिए विषय का नामएक नाम दर्ज करें (उदाहरण के लिए,
mytopic). - चुनें .
- लैम्ब्डा फ़ंक्शन विवरण पृष्ठ पर, पर कोड टैब, निम्नलिखित कोड दर्ज करें:
- लैम्ब्डा फ़ंक्शन तैनात करें।
- पर विन्यास टैब चुनें संपादित करें ट्रिगर को संपादित करने के लिए.
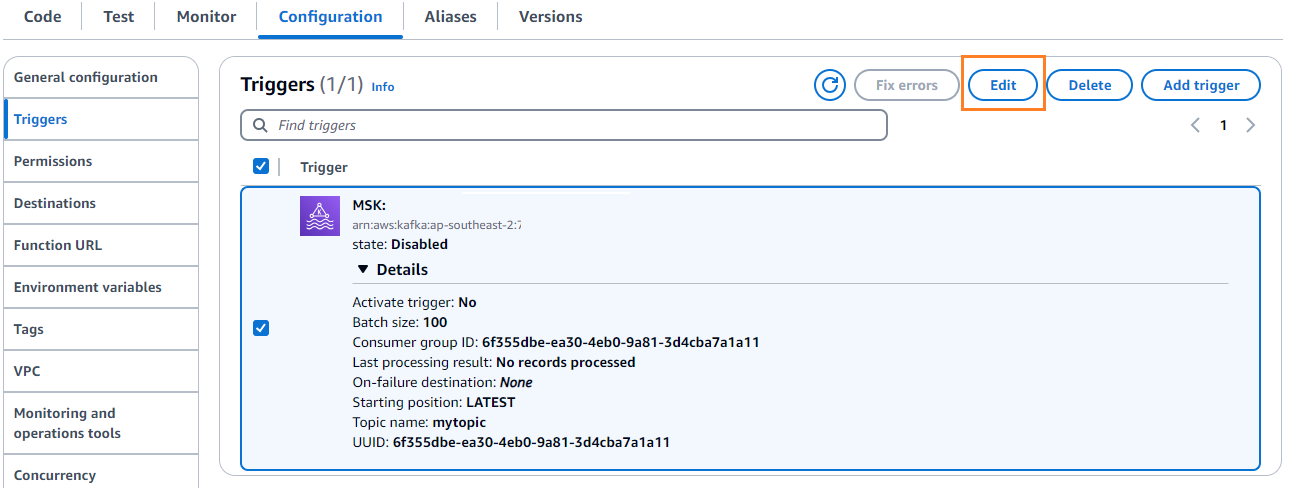
- ट्रिगर चुनें, फिर चुनें सहेजें.
- डायनॉम्बीडी कंसोल पर, चुनें वस्तुओं का अन्वेषण करें नेविगेशन फलक में
- तालिका का चयन करें
device_status.
आप देखेंगे कि लैम्ब्डा काफ्का विषय में उत्पन्न घटनाओं को DynamoDB पर लिख रहा है।

सारांश
वास्तविक समय के अनुप्रयोगों के निर्माण के लिए स्ट्रीमिंग डेटा पाइपलाइन महत्वपूर्ण हैं। हालाँकि, बुनियादी ढांचे की स्थापना और प्रबंधन कठिन हो सकता है। इस पोस्ट में, हमने Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose और अन्य सेवाओं का उपयोग करके AWS पर सर्वर रहित स्ट्रीमिंग पाइपलाइन बनाने का तरीका बताया। मुख्य लाभ प्रबंधन के लिए कोई सर्वर नहीं होना, बुनियादी ढांचे की स्वचालित स्केलेबिलिटी और पूरी तरह से प्रबंधित सेवाओं का उपयोग करते हुए भुगतान करने वाला मॉडल है।
क्या आप अपनी स्वयं की रीयल-टाइम पाइपलाइन बनाने के लिए तैयार हैं? निःशुल्क AWS खाते के साथ आज ही शुरुआत करें। सर्वर रहित की शक्ति के साथ, आप अपने एप्लिकेशन लॉजिक पर ध्यान केंद्रित कर सकते हैं जबकि AWS अविभाजित भारी भारोत्तोलन को संभालता है। आइए AWS पर कुछ अद्भुत बनाएं!
लेखक के बारे में
 मसूदुर रहमान सईम AWS में एक स्ट्रीमिंग डेटा आर्किटेक्ट है। वह वास्तविक दुनिया की व्यावसायिक समस्याओं को हल करने के लिए डेटा स्ट्रीमिंग आर्किटेक्चर के डिजाइन और निर्माण के लिए विश्व स्तर पर AWS ग्राहकों के साथ काम करता है। वह स्ट्रीमिंग डेटा सेवाओं और NoSQL का उपयोग करने वाले समाधानों को अनुकूलित करने में माहिर हैं। सईम डिस्ट्रीब्यूटेड कंप्यूटिंग को लेकर बहुत जुनूनी है।
मसूदुर रहमान सईम AWS में एक स्ट्रीमिंग डेटा आर्किटेक्ट है। वह वास्तविक दुनिया की व्यावसायिक समस्याओं को हल करने के लिए डेटा स्ट्रीमिंग आर्किटेक्चर के डिजाइन और निर्माण के लिए विश्व स्तर पर AWS ग्राहकों के साथ काम करता है। वह स्ट्रीमिंग डेटा सेवाओं और NoSQL का उपयोग करने वाले समाधानों को अनुकूलित करने में माहिर हैं। सईम डिस्ट्रीब्यूटेड कंप्यूटिंग को लेकर बहुत जुनूनी है।
 माइकल ओगुइके अमेज़न MSK के लिए उत्पाद प्रबंधक हैं। उन्हें कार्रवाई को प्रेरित करने वाली अंतर्दृष्टि को उजागर करने के लिए डेटा का उपयोग करने का शौक है। उन्हें डेटा स्ट्रीमिंग का उपयोग करके विभिन्न प्रकार के उद्योगों के ग्राहकों को उनके व्यवसाय को बेहतर बनाने में मदद करने में आनंद आता है। माइकल को किताबों और पॉडकास्ट से व्यवहार विज्ञान और मनोविज्ञान के बारे में सीखना भी पसंद है।
माइकल ओगुइके अमेज़न MSK के लिए उत्पाद प्रबंधक हैं। उन्हें कार्रवाई को प्रेरित करने वाली अंतर्दृष्टि को उजागर करने के लिए डेटा का उपयोग करने का शौक है। उन्हें डेटा स्ट्रीमिंग का उपयोग करके विभिन्न प्रकार के उद्योगों के ग्राहकों को उनके व्यवसाय को बेहतर बनाने में मदद करने में आनंद आता है। माइकल को किताबों और पॉडकास्ट से व्यवहार विज्ञान और मनोविज्ञान के बारे में सीखना भी पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

