फाउंडेशन मॉडल (एफएम) बड़े मशीन लर्निंग (एमएल) मॉडल हैं जो बिना लेबल वाले और सामान्यीकृत डेटासेट के व्यापक स्पेक्ट्रम पर प्रशिक्षित होते हैं। एफएम, जैसा कि नाम से पता चलता है, अधिक विशिष्ट डाउनस्ट्रीम एप्लिकेशन बनाने के लिए आधार प्रदान करते हैं, और अपनी अनुकूलन क्षमता में अद्वितीय हैं। वे विभिन्न कार्यों की एक विस्तृत श्रृंखला कर सकते हैं, जैसे प्राकृतिक भाषा प्रसंस्करण, छवियों को वर्गीकृत करना, रुझानों का पूर्वानुमान लगाना, भावनाओं का विश्लेषण करना और सवालों के जवाब देना। यह पैमाना और सामान्य प्रयोजन अनुकूलन क्षमता एफएम को पारंपरिक एमएल मॉडल से अलग बनाती है। एफएम मल्टीमॉडल हैं; वे विभिन्न डेटा प्रकारों जैसे टेक्स्ट, वीडियो, ऑडियो और छवियों के साथ काम करते हैं। बड़े भाषा मॉडल (एलएलएम) एक प्रकार के एफएम हैं और बड़ी मात्रा में टेक्स्ट डेटा पर पूर्व-प्रशिक्षित होते हैं और आमतौर पर टेक्स्ट जेनरेशन, इंटेलिजेंट चैटबॉट या संक्षेपण जैसे एप्लिकेशन उपयोग होते हैं।
स्ट्रीमिंग डेटा विविध और अद्यतित जानकारी के निरंतर प्रवाह की सुविधा प्रदान करता है, जिससे मॉडल की अधिक सटीक, प्रासंगिक रूप से प्रासंगिक आउटपुट को अनुकूलित करने और उत्पन्न करने की क्षमता बढ़ जाती है। स्ट्रीमिंग डेटा का यह गतिशील एकीकरण सक्षम बनाता है जनरेटिव ए.आई. बदलती परिस्थितियों में तुरंत प्रतिक्रिया देने, उनकी अनुकूलन क्षमता और विभिन्न कार्यों में समग्र प्रदर्शन में सुधार करने के लिए एप्लिकेशन।
इसे बेहतर ढंग से समझने के लिए, एक चैटबॉट की कल्पना करें जो यात्रियों को उनकी यात्रा बुक करने में मदद करता है। इस परिदृश्य में, चैटबॉट को एयरलाइन इन्वेंट्री, उड़ान स्थिति, होटल इन्वेंट्री, नवीनतम मूल्य परिवर्तन और बहुत कुछ तक वास्तविक समय तक पहुंच की आवश्यकता होती है। यह डेटा आम तौर पर तीसरे पक्ष से आता है, और डेवलपर्स को इस डेटा को ग्रहण करने और डेटा परिवर्तन होने पर उन्हें संसाधित करने का एक तरीका खोजने की आवश्यकता होती है।
इस परिदृश्य में बैच प्रोसेसिंग सबसे उपयुक्त नहीं है। जब डेटा तेजी से बदलता है, तो इसे एक बैच में संसाधित करने से चैटबॉट द्वारा पुराने डेटा का उपयोग किया जा सकता है, जिससे ग्राहक को गलत जानकारी मिलती है, जो समग्र ग्राहक अनुभव को प्रभावित करती है। हालाँकि, स्ट्रीम प्रोसेसिंग, चैटबॉट को वास्तविक समय के डेटा तक पहुँचने और उपलब्धता और कीमत में बदलाव के अनुकूल होने में सक्षम कर सकती है, जिससे ग्राहक को सर्वोत्तम मार्गदर्शन प्रदान किया जा सकता है और ग्राहक अनुभव को बढ़ाया जा सकता है।
एक अन्य उदाहरण एआई-संचालित अवलोकन और निगरानी समाधान है जहां एफएम किसी सिस्टम के वास्तविक समय के आंतरिक मेट्रिक्स की निगरानी करते हैं और अलर्ट उत्पन्न करते हैं। जब मॉडल को कोई विसंगति या असामान्य मीट्रिक मान मिलता है, तो उसे तुरंत एक अलर्ट उत्पन्न करना चाहिए और ऑपरेटर को सूचित करना चाहिए। हालाँकि, ऐसे महत्वपूर्ण डेटा का मूल्य समय के साथ काफी कम हो जाता है। ये सूचनाएं आदर्श रूप से कुछ सेकंड के भीतर या ऐसा होते समय भी प्राप्त होनी चाहिए। यदि ऑपरेटरों को ये सूचनाएं उनके घटित होने के कुछ मिनट या घंटों बाद प्राप्त होती हैं, तो ऐसी जानकारी कार्रवाई योग्य नहीं है और संभावित रूप से इसका मूल्य खो गया है। आप खुदरा, कार विनिर्माण, ऊर्जा और वित्तीय उद्योग जैसे अन्य उद्योगों में समान उपयोग के मामले पा सकते हैं।
इस पोस्ट में, हम चर्चा करते हैं कि वास्तविक समय की प्रकृति के कारण डेटा स्ट्रीमिंग जेनरेटिव एआई अनुप्रयोगों का एक महत्वपूर्ण घटक क्यों है। हम AWS डेटा स्ट्रीमिंग सेवाओं के मूल्य पर चर्चा करते हैं जैसे Apache Kafka के लिए Amazon प्रबंधित स्ट्रीमिंग (अमेज़ॅन एमएसके), अमेज़न Kinesis डेटा स्ट्रीम, अपाचे फ्लिंक के लिए अमेज़ॅन प्रबंधित सेवा, तथा अमेज़न Kinesis डेटा Firehose जेनेरिक एआई अनुप्रयोगों के निर्माण में।
इन-कॉन्टेक्स्ट लर्निंग
एलएलएम को पॉइंट-इन-टाइम डेटा के साथ प्रशिक्षित किया जाता है और अनुमान के समय ताजा डेटा तक पहुंचने की कोई अंतर्निहित क्षमता नहीं होती है। जैसे ही नया डेटा सामने आता है, आपको मॉडल को लगातार फाइन-ट्यून करना होगा या आगे प्रशिक्षित करना होगा। यह न केवल एक महंगा ऑपरेशन है, बल्कि व्यवहार में भी बहुत सीमित है क्योंकि नए डेटा उत्पादन की दर फाइन-ट्यूनिंग की गति से कहीं अधिक है। इसके अतिरिक्त, एलएलएम में प्रासंगिक समझ की कमी होती है और वे केवल अपने प्रशिक्षण डेटा पर निर्भर होते हैं, और इसलिए मतिभ्रम का खतरा होता है। इसका मतलब है कि वे एक धाराप्रवाह, सुसंगत और वाक्यात्मक रूप से ध्वनि लेकिन तथ्यात्मक रूप से गलत प्रतिक्रिया उत्पन्न कर सकते हैं। वे प्रासंगिकता, वैयक्तिकरण और संदर्भ से भी रहित हैं।
हालाँकि, एलएलएम में मॉडल भार को संशोधित किए बिना अधिक सटीक प्रतिक्रिया देने के लिए संदर्भ से प्राप्त डेटा से सीखने की क्षमता होती है। यह कहा जाता है इन-कॉन्टेक्स्ट लर्निंग, और इसका उपयोग व्यक्तिगत उत्तर देने या संगठन की नीतियों के संदर्भ में सटीक प्रतिक्रिया प्रदान करने के लिए किया जा सकता है।
उदाहरण के लिए, एक चैटबॉट में, डेटा इवेंट उड़ानों और होटलों की सूची या मूल्य परिवर्तन से संबंधित हो सकते हैं जो लगातार स्ट्रीमिंग स्टोरेज इंजन में शामिल होते हैं। इसके अलावा, स्ट्रीम प्रोसेसर का उपयोग करके डेटा घटनाओं को फ़िल्टर किया जाता है, समृद्ध किया जाता है और उपभोग्य प्रारूप में बदल दिया जाता है। नवीनतम स्नैपशॉट को क्वेरी करके परिणाम एप्लिकेशन को उपलब्ध कराया जाता है। स्ट्रीम प्रोसेसिंग के माध्यम से स्नैपशॉट लगातार अपडेट होता रहता है; इसलिए, अद्यतन डेटा मॉडल के लिए उपयोगकर्ता संकेत के संदर्भ में प्रदान किया जाता है। यह मॉडल को कीमत और उपलब्धता में नवीनतम परिवर्तनों के अनुकूल होने की अनुमति देता है। निम्नलिखित चित्र एक बुनियादी संदर्भ-आधारित शिक्षण वर्कफ़्लो को दर्शाता है।
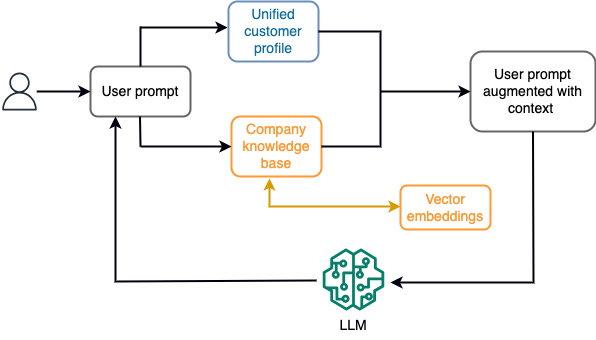
आमतौर पर इस्तेमाल किया जाने वाला संदर्भ-आधारित शिक्षण दृष्टिकोण रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) नामक तकनीक का उपयोग करना है। आरएजी में, आप प्रॉम्प्ट पर उपयोगकर्ता के प्रश्न के साथ-साथ सर्वाधिक प्रासंगिक नीति और ग्राहक रिकॉर्ड जैसी प्रासंगिक जानकारी प्रदान करते हैं। इस तरह, एलएलएम संदर्भ के रूप में प्रदान की गई अतिरिक्त जानकारी का उपयोग करके उपयोगकर्ता के प्रश्न का उत्तर तैयार करता है। आरएजी के बारे में अधिक जानने के लिए देखें अमेज़ॅन सैजमेकर जम्पस्टार्ट में फाउंडेशन मॉडल के साथ रिट्रीवल ऑगमेंटेड जेनरेशन का उपयोग करते हुए प्रश्न का उत्तर देना.
एक आरएजी-आधारित जेनेरिक एआई एप्लिकेशन केवल अपने प्रशिक्षण डेटा और ज्ञान आधार में प्रासंगिक दस्तावेजों के आधार पर सामान्य प्रतिक्रियाएं उत्पन्न कर सकता है। जब एप्लिकेशन से लगभग वास्तविक समय में वैयक्तिकृत प्रतिक्रिया की अपेक्षा की जाती है तो यह समाधान कम पड़ जाता है। उदाहरण के लिए, एक ट्रैवल चैटबॉट से उपयोगकर्ता की वर्तमान बुकिंग, उपलब्ध होटल और उड़ान सूची और बहुत कुछ पर विचार करने की अपेक्षा की जाती है। इसके अलावा, प्रासंगिक ग्राहक व्यक्तिगत डेटा (आमतौर पर के रूप में जाना जाता है एकीकृत ग्राहक प्रोफ़ाइल) आमतौर पर परिवर्तन के अधीन है। यदि जेनरेटिव एआई के उपयोगकर्ता प्रोफ़ाइल डेटाबेस को अद्यतन करने के लिए एक बैच प्रक्रिया नियोजित की जाती है, तो ग्राहक को पुराने डेटा के आधार पर असंतोषजनक प्रतिक्रियाएँ प्राप्त हो सकती हैं।
इस पोस्ट में, हम एकीकृत ग्राहक प्रोफाइल और संगठनात्मक ज्ञान आधार तक वास्तविक समय पहुंच के संदर्भ में प्रश्न उत्तर देने वाले एजेंटों के निर्माण के लिए उपयोग किए जाने वाले आरएजी समाधान को बढ़ाने के लिए स्ट्रीम प्रोसेसिंग के अनुप्रयोग पर चर्चा करते हैं।
लगभग वास्तविक समय में ग्राहक प्रोफ़ाइल अपडेट
ग्राहक रिकॉर्ड आम तौर पर एक संगठन के भीतर डेटा स्टोर में वितरित किए जाते हैं। प्रासंगिक, सटीक और अद्यतित ग्राहक प्रोफ़ाइल प्रदान करने के लिए आपके जेनरेटिव एआई एप्लिकेशन के लिए, स्ट्रीमिंग डेटा पाइपलाइन बनाना महत्वपूर्ण है जो वितरित डेटा स्टोर्स में पहचान समाधान और प्रोफ़ाइल एकत्रीकरण कर सकता है। स्ट्रीमिंग नौकरियां सिस्टम में सिंक्रनाइज़ करने के लिए लगातार नए डेटा को ग्रहण करती हैं और समय की खिड़कियों में संवर्धन, परिवर्तन, जुड़ाव और एकत्रीकरण अधिक कुशलता से कर सकती हैं। चेंज डेटा कैप्चर (सीडीसी) इवेंट में स्रोत रिकॉर्ड, अपडेट और मेटाडेटा जैसे समय, स्रोत, वर्गीकरण (सम्मिलित करें, अपडेट करें या हटाएं), और परिवर्तन के आरंभकर्ता के बारे में जानकारी होती है।
निम्नलिखित आरेख एकीकृत ग्राहक प्रोफाइल के लिए सीडीसी स्ट्रीमिंग अंतर्ग्रहण और प्रसंस्करण के लिए एक उदाहरण वर्कफ़्लो दिखाता है।

इस खंड में, हम आरएजी-आधारित जेनरेटिव एआई अनुप्रयोगों का समर्थन करने के लिए आवश्यक सीडीसी स्ट्रीमिंग पैटर्न के मुख्य घटकों पर चर्चा करते हैं।
सीडीसी स्ट्रीमिंग अंतर्ग्रहण
सीडीसी रेप्लिकेटर एक ऐसी प्रक्रिया है जो स्रोत सिस्टम से डेटा परिवर्तन एकत्र करती है (आमतौर पर लेनदेन लॉग या बिनलॉग पढ़कर) और सीडीसी घटनाओं को ठीक उसी क्रम में लिखती है जो वे स्ट्रीमिंग डेटा स्ट्रीम या विषय में हुई थीं। इसमें टूल के साथ लॉग-आधारित कैप्चर शामिल है एडब्ल्यूएस डेटाबेस प्रवासन सेवा (एडब्ल्यूएस डीएमएस) या अपाचे काफ्का कनेक्ट के लिए डेबेज़ियम जैसे ओपन सोर्स कनेक्टर। अपाचे काफ्का कनेक्ट अपाचे काफ्का पर्यावरण का हिस्सा है, जो विभिन्न स्रोतों से डेटा प्राप्त करने और विभिन्न गंतव्यों तक पहुंचाने की अनुमति देता है। आप अपना Apache Kafka कनेक्टर चालू कर सकते हैं अमेज़न एमएसके कनेक्ट अपाचे काफ्का क्लस्टर के कॉन्फ़िगरेशन, सेटअप और संचालन के बारे में चिंता किए बिना मिनटों के भीतर। आपको केवल अपने कनेक्टर का संकलित कोड अपलोड करना होगा अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस3) और अपने कनेक्टर को अपने कार्यभार के विशिष्ट कॉन्फ़िगरेशन के साथ सेट करें।
डेटा परिवर्तनों को कैप्चर करने के अन्य तरीके भी हैं। उदाहरण के लिए, अमेज़ॅन डायनेमोडीबी सीडीसी डेटा स्ट्रीमिंग के लिए एक सुविधा प्रदान करता है Amazon DynamoDB धाराएँ या किनेसिस डेटा स्ट्रीम। अमेज़ॅन S3 एक आह्वान करने के लिए एक ट्रिगर प्रदान करता है AWS लाम्बा जब कोई नया दस्तावेज़ संग्रहीत किया जाता है तो कार्य करें।
स्ट्रीमिंग भंडारण
स्ट्रीमिंग स्टोरेज सीडीसी घटनाओं को संसाधित होने से पहले संग्रहीत करने के लिए एक मध्यवर्ती बफर के रूप में कार्य करता है। स्ट्रीमिंग स्टोरेज स्ट्रीमिंग डेटा के लिए विश्वसनीय स्टोरेज प्रदान करता है। डिज़ाइन के अनुसार, यह हार्डवेयर या नोड विफलताओं के लिए अत्यधिक उपलब्ध और लचीला है और घटनाओं के लिखे जाने के क्रम को बनाए रखता है। स्ट्रीमिंग स्टोरेज डेटा ईवेंट को स्थायी रूप से या निर्धारित समय के लिए संग्रहीत कर सकता है। यह स्ट्रीम प्रोसेसर को विफलता या पुन: प्रसंस्करण की आवश्यकता होने पर स्ट्रीम के हिस्से से पढ़ने की अनुमति देता है। काइनेसिस डेटा स्ट्रीम एक सर्वर रहित स्ट्रीमिंग डेटा सेवा है जो बड़े पैमाने पर डेटा स्ट्रीम को कैप्चर करना, संसाधित करना और संग्रहीत करना आसान बनाती है। अमेज़ॅन एमएसके अपाचे काफ्का चलाने के लिए एडब्ल्यूएस द्वारा प्रदान की गई एक पूरी तरह से प्रबंधित, अत्यधिक उपलब्ध और सुरक्षित सेवा है।
स्ट्रीम प्रसंस्करण
उच्च डेटा थ्रूपुट को संभालने के लिए स्ट्रीम प्रोसेसिंग सिस्टम को समानता के लिए डिज़ाइन किया जाना चाहिए। उन्हें कई कंप्यूट नोड्स पर चल रहे कई कार्यों के बीच इनपुट स्ट्रीम को विभाजित करना चाहिए। कार्यों को नेटवर्क पर एक ऑपरेशन के परिणाम को अगले ऑपरेशन में भेजने में सक्षम होना चाहिए, जिससे जॉइन, फ़िल्टरिंग, संवर्धन और एकत्रीकरण जैसे ऑपरेशन करते समय समानांतर में डेटा को संसाधित करना संभव हो सके। स्ट्रीम प्रोसेसिंग अनुप्रयोगों को उन उपयोग के मामलों के लिए ईवेंट समय के संबंध में ईवेंट को संसाधित करने में सक्षम होना चाहिए जहां ईवेंट देर से आ सकते हैं या सही गणना सिस्टम समय के बजाय ईवेंट घटित होने के समय पर निर्भर करती है। अधिक जानकारी के लिए देखें समय की धारणाएँ: घटना समय और प्रसंस्करण समय.
स्ट्रीम प्रक्रियाएं लगातार डेटा घटनाओं के रूप में परिणाम उत्पन्न करती हैं जिन्हें लक्ष्य प्रणाली में आउटपुट करने की आवश्यकता होती है। एक लक्ष्य प्रणाली कोई भी प्रणाली हो सकती है जो सीधे प्रक्रिया के साथ या मध्यस्थ के रूप में स्ट्रीमिंग स्टोरेज के माध्यम से एकीकृत हो सकती है। स्ट्रीम प्रोसेसिंग के लिए आपके द्वारा चुने गए ढांचे के आधार पर, आपके पास उपलब्ध सिंक कनेक्टर्स के आधार पर लक्ष्य सिस्टम के लिए अलग-अलग विकल्प होंगे। यदि आप परिणामों को एक मध्यस्थ स्ट्रीमिंग स्टोरेज में लिखने का निर्णय लेते हैं, तो आप एक अलग प्रक्रिया बना सकते हैं जो घटनाओं को पढ़ती है और लक्ष्य प्रणाली में परिवर्तन लागू करती है, जैसे अपाचे काफ्का सिंक कनेक्टर चलाना। चाहे आप कोई भी विकल्प चुनें, सीडीसी डेटा को उसकी प्रकृति के कारण अतिरिक्त प्रबंधन की आवश्यकता होती है। क्योंकि सीडीसी इवेंट अपडेट या डिलीट के बारे में जानकारी रखते हैं, इसलिए यह महत्वपूर्ण है कि वे सही क्रम में लक्ष्य प्रणाली में विलय हो जाएं। यदि परिवर्तन गलत क्रम में लागू किए जाते हैं, तो लक्ष्य प्रणाली अपने स्रोत के साथ समन्वयित नहीं हो जाएगी।
अपाचे झपकी एक शक्तिशाली स्ट्रीम प्रोसेसिंग फ्रेमवर्क है जो अपनी कम विलंबता और उच्च थ्रूपुट क्षमताओं के लिए जाना जाता है। यह इवेंट टाइम प्रोसेसिंग, बिल्कुल एक बार प्रोसेसिंग सेमेन्टिक्स और उच्च दोष सहनशीलता का समर्थन करता है। इसके अतिरिक्त, यह एक विशेष संरचना के माध्यम से सीडीसी डेटा के लिए मूल समर्थन प्रदान करता है गतिशील तालिकाएँ. डायनेमिक टेबल स्रोत डेटाबेस टेबल की नकल करते हैं और स्ट्रीमिंग डेटा का एक स्तंभ प्रतिनिधित्व प्रदान करते हैं। गतिशील तालिकाओं में डेटा संसाधित होने वाली प्रत्येक घटना के साथ बदलता है। नए रिकॉर्ड किसी भी समय जोड़े, अपडेट या हटाए जा सकते हैं। डायनामिक टेबल प्रत्येक रिकॉर्ड ऑपरेशन (सम्मिलित करें, अपडेट करें, हटाएं) के लिए अलग से लागू करने के लिए आवश्यक अतिरिक्त तर्क को हटा दें। अधिक जानकारी के लिए देखें गतिशील तालिकाएँ.
- अपाचे फ्लिंक के लिए अमेज़ॅन प्रबंधित सेवा, आप Apache Flink जॉब चला सकते हैं और अन्य AWS सेवाओं के साथ एकीकृत कर सकते हैं। प्रबंधन करने के लिए कोई सर्वर और क्लस्टर नहीं हैं, और स्थापित करने के लिए कोई गणना और भंडारण बुनियादी ढांचा नहीं है।
एडब्ल्यूएस गोंद एक पूरी तरह से प्रबंधित एक्सट्रैक्ट, ट्रांसफॉर्म और लोड (ईटीएल) सेवा है, जिसका अर्थ है कि एडब्ल्यूएस आपके लिए बुनियादी ढांचे के प्रावधान, स्केलिंग और रखरखाव को संभालता है। हालाँकि यह मुख्य रूप से अपनी ETL क्षमताओं के लिए जाना जाता है, AWS ग्लू का उपयोग स्पार्क स्ट्रीमिंग अनुप्रयोगों के लिए भी किया जा सकता है। AWS ग्लू सीडीसी डेटा को संसाधित करने और बदलने के लिए किनेसिस डेटा स्ट्रीम और अमेज़ॅन एमएसके जैसी स्ट्रीमिंग डेटा सेवाओं के साथ बातचीत कर सकता है। AWS ग्लू अन्य AWS सेवाओं जैसे लैम्ब्डा, के साथ भी सहजता से एकीकृत हो सकता है। AWS स्टेप फ़ंक्शंस, और DynamoDB, आपको डेटा प्रोसेसिंग पाइपलाइनों के निर्माण और प्रबंधन के लिए एक व्यापक पारिस्थितिकी तंत्र प्रदान करता है।
एकीकृत ग्राहक प्रोफ़ाइल
विभिन्न स्रोत प्रणालियों में ग्राहक प्रोफ़ाइल के एकीकरण पर काबू पाने के लिए मजबूत डेटा पाइपलाइनों के विकास की आवश्यकता होती है। आपको डेटा पाइपलाइनों की आवश्यकता है जो सभी रिकॉर्ड को एक डेटा स्टोर में ला और सिंक्रनाइज़ कर सकें। यह डेटा स्टोर आपके संगठन को समग्र ग्राहक रिकॉर्ड दृश्य प्रदान करता है जो आरएजी-आधारित जेनरेटिव एआई अनुप्रयोगों की परिचालन दक्षता के लिए आवश्यक है। ऐसे डेटा स्टोर के निर्माण के लिए, एक असंरचित डेटा स्टोर सबसे अच्छा होगा।
एकीकृत ग्राहक प्रोफ़ाइल बनाने के लिए एक पहचान ग्राफ एक उपयोगी संरचना है क्योंकि यह विभिन्न स्रोतों से ग्राहक डेटा को समेकित और एकीकृत करता है, डेटा सटीकता और डिडुप्लीकेशन सुनिश्चित करता है, वास्तविक समय अपडेट प्रदान करता है, क्रॉस-सिस्टम अंतर्दृष्टि जोड़ता है, निजीकरण को सक्षम करता है, ग्राहक अनुभव को बढ़ाता है, और विनियामक अनुपालन का समर्थन करता है। यह एकीकृत ग्राहक प्रोफ़ाइल जेनेरिक एआई एप्लिकेशन को ग्राहकों को प्रभावी ढंग से समझने और उनके साथ जुड़ने और डेटा गोपनीयता नियमों का पालन करने, अंततः ग्राहक अनुभव को बढ़ाने और व्यवसाय विकास को बढ़ावा देने का अधिकार देता है। आप इसका उपयोग करके अपना पहचान ग्राफ़ समाधान बना सकते हैं अमेज़न नेपच्यून, एक तेज़, विश्वसनीय, पूरी तरह से प्रबंधित ग्राफ़ डेटाबेस सेवा।
AWS असंरचित कुंजी-मूल्य वस्तुओं के लिए कुछ अन्य प्रबंधित और सर्वर रहित NoSQL भंडारण सेवा प्रदान करता है। अमेज़ॅन दस्तावेज़ डीबी (MongoDB संगतता के साथ) एक तेज़, स्केलेबल, अत्यधिक उपलब्ध और पूरी तरह से प्रबंधित उद्यम है दस्तावेज़ डेटाबेस सेवा जो मूल JSON वर्कलोड का समर्थन करती है। DynamoDB एक पूरी तरह से प्रबंधित NoSQL डेटाबेस सेवा है जो निर्बाध स्केलेबिलिटी के साथ तेज़ और पूर्वानुमानित प्रदर्शन प्रदान करती है।
लगभग वास्तविक समय में संगठनात्मक ज्ञान आधार अद्यतन
ग्राहक रिकॉर्ड के समान, कंपनी की नीतियों और संगठनात्मक दस्तावेजों जैसे आंतरिक ज्ञान भंडार को भंडारण प्रणालियों में छुपाया जाता है। यह आम तौर पर असंरचित डेटा होता है और इसे गैर-वृद्धिशील तरीके से अद्यतन किया जाता है। एआई अनुप्रयोगों के लिए असंरचित डेटा का उपयोग वेक्टर एम्बेडिंग का उपयोग करके प्रभावी है, जो उच्च आयामी डेटा जैसे टेक्स्ट फ़ाइलों, छवियों और ऑडियो फ़ाइलों को बहु-आयामी संख्यात्मक के रूप में प्रस्तुत करने की एक तकनीक है।
AWS अनेक प्रदान करता है वेक्टर इंजन सेवाएँइस तरह के रूप में, Amazon OpenSearch सर्वर रहित, अमेज़ॅन केंद्र, तथा Amazon Aurora PostgreSQL-संगत संस्करण वेक्टर एम्बेडिंग को संग्रहीत करने के लिए पीजीवेक्टर एक्सटेंशन के साथ। जेनरेटिव एआई एप्लिकेशन यूजर प्रॉम्प्ट को वेक्टर में बदलकर उपयोगकर्ता अनुभव को बढ़ा सकते हैं और प्रासंगिक रूप से प्रासंगिक जानकारी प्राप्त करने के लिए वेक्टर इंजन को क्वेरी करने के लिए इसका उपयोग कर सकते हैं। अधिक सटीक और वैयक्तिकृत प्रतिक्रिया प्राप्त करने के लिए पुनर्प्राप्त किए गए संकेत और वेक्टर डेटा दोनों को एलएलएम को भेज दिया जाता है।
निम्नलिखित आरेख वेक्टर एम्बेडिंग के लिए एक उदाहरण स्ट्रीम-प्रोसेसिंग वर्कफ़्लो दिखाता है।
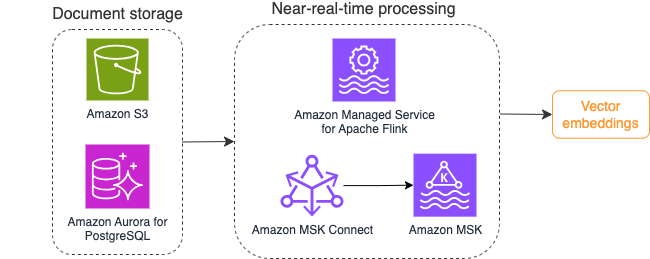
वेक्टर डेटा स्टोर में लिखे जाने से पहले ज्ञान आधार सामग्री को वेक्टर एम्बेडिंग में परिवर्तित करने की आवश्यकता होती है। अमेज़ॅन बेडरॉक or अमेज़न SageMaker आपकी पसंद के मॉडल तक पहुँचने और इस रूपांतरण के लिए एक निजी समापन बिंदु को उजागर करने में आपकी सहायता कर सकता है। इसके अलावा, आप इन एंडपॉइंट्स के साथ एकीकृत करने के लिए लैंगचेन जैसी लाइब्रेरी का उपयोग कर सकते हैं। एक बैच प्रक्रिया बनाने से आपको अपने ज्ञान आधार सामग्री को वेक्टर डेटा में बदलने और शुरुआत में इसे वेक्टर डेटाबेस में संग्रहीत करने में मदद मिल सकती है। हालाँकि, आपको अपने ज्ञान आधार सामग्री में परिवर्तन के साथ अपने वेक्टर डेटाबेस को सिंक्रनाइज़ करने के लिए दस्तावेज़ों को पुन: संसाधित करने के लिए एक अंतराल पर भरोसा करने की आवश्यकता है। बड़ी संख्या में दस्तावेज़ों के साथ, यह प्रक्रिया अक्षम हो सकती है। इन अंतरालों के बीच, आपके जेनरेटिव एआई एप्लिकेशन उपयोगकर्ताओं को पुरानी सामग्री के अनुसार उत्तर प्राप्त होंगे, या गलत उत्तर प्राप्त होगा क्योंकि नई सामग्री अभी तक वेक्टरकृत नहीं हुई है।
स्ट्रीम प्रोसेसिंग इन चुनौतियों का एक आदर्श समाधान है। यह शुरू में मौजूदा दस्तावेज़ों के अनुसार ईवेंट तैयार करता है और आगे स्रोत प्रणाली की निगरानी करता है और जैसे ही वे घटित होते हैं, दस्तावेज़ परिवर्तन ईवेंट बनाता है। इन घटनाओं को स्ट्रीमिंग स्टोरेज में संग्रहीत किया जा सकता है और स्ट्रीमिंग कार्य द्वारा संसाधित होने की प्रतीक्षा की जा सकती है। एक स्ट्रीमिंग कार्य इन घटनाओं को पढ़ता है, दस्तावेज़ की सामग्री को लोड करता है, और सामग्री को शब्दों के संबंधित टोकन की एक श्रृंखला में बदल देता है। प्रत्येक टोकन एक एम्बेडिंग एफएम पर एपीआई कॉल के माध्यम से वेक्टर डेटा में बदल जाता है। परिणाम सिंक ऑपरेटर के माध्यम से वेक्टर स्टोरेज में भंडारण के लिए भेजे जाते हैं।
यदि आप अपने दस्तावेज़ों को संग्रहीत करने के लिए अमेज़ॅन एस3 का उपयोग कर रहे हैं, तो आप लैम्ब्डा के लिए एस3 ऑब्जेक्ट परिवर्तन ट्रिगर्स के आधार पर एक इवेंट-सोर्स आर्किटेक्चर बना सकते हैं। लैम्ब्डा फ़ंक्शन वांछित प्रारूप में एक ईवेंट बना सकता है और उसे आपके स्ट्रीमिंग स्टोरेज में लिख सकता है।
स्ट्रीमिंग कार्य के रूप में चलाने के लिए आप Apache Flink का भी उपयोग कर सकते हैं। अपाचे फ़्लिंक मूल फ़ाइल सिस्टम स्रोत कनेक्टर प्रदान करता है, जो मौजूदा फ़ाइलों को खोज सकता है और शुरुआत में उनकी सामग्री को पढ़ सकता है। उसके बाद, यह नई फ़ाइलों के लिए आपके फ़ाइल सिस्टम की लगातार निगरानी कर सकता है और उनकी सामग्री को कैप्चर कर सकता है। कनेक्टर वितरित फ़ाइल सिस्टम जैसे अमेज़ॅन एस 3 या एचडीएफएस से सादे पाठ, एवरो, सीएसवी, पारक्वेट और अधिक के प्रारूप के साथ फ़ाइलों के एक सेट को पढ़ने का समर्थन करता है, और एक स्ट्रीमिंग रिकॉर्ड तैयार करता है। पूरी तरह से प्रबंधित सेवा के रूप में, Apache Flink के लिए प्रबंधित सेवा Flink नौकरियों को तैनात करने और बनाए रखने के परिचालन ओवरहेड को हटा देती है, जिससे आप अपने स्ट्रीमिंग एप्लिकेशन के निर्माण और स्केलिंग पर ध्यान केंद्रित कर सकते हैं। अमेज़ॅन एमएसके या किनेसिस डेटा स्ट्रीम जैसी एडब्ल्यूएस स्ट्रीमिंग सेवाओं में सहज एकीकरण के साथ, यह स्वचालित स्केलिंग, सुरक्षा और लचीलेपन जैसी सुविधाएं प्रदान करता है, वास्तविक समय स्ट्रीमिंग डेटा को संभालने के लिए विश्वसनीय और कुशल फ़्लिंक एप्लिकेशन प्रदान करता है।
अपनी DevOps प्राथमिकता के आधार पर, आप स्ट्रीमिंग रिकॉर्ड संग्रहीत करने के लिए किनेसिस डेटा स्ट्रीम या अमेज़ॅन MSK के बीच चयन कर सकते हैं। काइनेसिस डेटा स्ट्रीम कस्टम स्ट्रीमिंग डेटा अनुप्रयोगों के निर्माण और प्रबंधन की जटिलताओं को सरल बनाता है, जिससे आप बुनियादी ढांचे के रखरखाव के बजाय अपने डेटा से अंतर्दृष्टि प्राप्त करने पर ध्यान केंद्रित कर सकते हैं। अपाचे काफ्का का उपयोग करने वाले ग्राहक अक्सर एडब्ल्यूएस वातावरण के भीतर अपाचे काफ्का समूहों की देखरेख में इसकी सरलता, मापनीयता और निर्भरता के कारण अमेज़ॅन एमएसके का विकल्प चुनते हैं। एक पूरी तरह से प्रबंधित सेवा के रूप में, अमेज़ॅन एमएसके अपाचे काफ्का क्लस्टर को तैनात करने और बनाए रखने से जुड़ी परिचालन जटिलताओं को लेता है, जिससे आप अपने स्ट्रीमिंग अनुप्रयोगों के निर्माण और विस्तार पर ध्यान केंद्रित कर सकते हैं।
क्योंकि एक RESTful API एकीकरण इस प्रक्रिया की प्रकृति के अनुकूल है, आपको एक ऐसे ढांचे की आवश्यकता है जो विफलताओं को ट्रैक करने और विफल अनुरोध के लिए पुनः प्रयास करने के लिए RESTful API कॉल के माध्यम से एक स्टेटफुल संवर्धन पैटर्न का समर्थन करता है। अपाचे फ्लिंक फिर से एक ऐसा ढांचा है जो मेमोरी स्पीड में स्टेटफुल ऑपरेशंस कर सकता है। Apache Flink के माध्यम से API कॉल करने के सर्वोत्तम तरीकों को समझने के लिए, देखें Apache Flink के लिए Amazon Kinesis डेटा एनालिटिक्स में सामान्य स्ट्रीमिंग डेटा संवर्धन पैटर्न.
Apache Flink वेक्टर डेटास्टोर्स पर डेटा लिखने के लिए देशी सिंक कनेक्टर प्रदान करता है जैसे कि pgvector के साथ PostgreSQL के लिए Amazon Aurora या अमेज़न ओपन सर्च सर्विस वेक्टरडीबी के साथ। वैकल्पिक रूप से, आप एमएसके विषय या किनेसिस डेटा स्ट्रीम में फ्लिंक जॉब के आउटपुट (वेक्टरयुक्त डेटा) को चरणबद्ध कर सकते हैं। ओपनसर्च सेवा किनेसिस डेटा स्ट्रीम या एमएसके विषयों से मूल अंतर्ग्रहण के लिए सहायता प्रदान करती है। अधिक जानकारी के लिए देखें Amazon OpenSearch अंतर्ग्रहण के स्रोत के रूप में Amazon MSK का परिचय और अमेज़ॅन किनेसिस डेटा स्ट्रीम से स्ट्रीमिंग डेटा लोड हो रहा है.
फीडबैक विश्लेषण और फाइन-ट्यूनिंग
डेटा ऑपरेशन प्रबंधकों और एआई/एमएल डेवलपर्स के लिए जेनरेटिव एआई एप्लिकेशन और उपयोग में आने वाले एफएम के प्रदर्शन के बारे में जानकारी प्राप्त करना महत्वपूर्ण है। इसे प्राप्त करने के लिए, आपको डेटा पाइपलाइन बनाने की आवश्यकता है जो उपयोगकर्ता की प्रतिक्रिया और एप्लिकेशन लॉग और मेट्रिक्स की विविधता के आधार पर महत्वपूर्ण कुंजी प्रदर्शन संकेतक (KPI) डेटा की गणना करती है। यह जानकारी हितधारकों के लिए एफएम के प्रदर्शन, एप्लिकेशन और आपके एप्लिकेशन से प्राप्त समर्थन की गुणवत्ता के बारे में समग्र उपयोगकर्ता संतुष्टि के बारे में वास्तविक समय की जानकारी प्राप्त करने के लिए उपयोगी है। आपको डोमेन-विशिष्ट कार्यों को करने में अपनी क्षमता में सुधार करने के लिए अपने एफएम को और बेहतर बनाने के लिए वार्तालाप इतिहास को एकत्र करने और संग्रहीत करने की भी आवश्यकता है।
यह उपयोग मामला स्ट्रीमिंग एनालिटिक्स डोमेन में बहुत अच्छी तरह से फिट बैठता है। आपके एप्लिकेशन को प्रत्येक वार्तालाप को स्ट्रीमिंग स्टोरेज में संग्रहीत करना चाहिए। आपका एप्लिकेशन उपयोगकर्ताओं को प्रत्येक उत्तर की सटीकता की रेटिंग और उनकी समग्र संतुष्टि के बारे में संकेत दे सकता है। यह डेटा बाइनरी चॉइस या फ्री फॉर्म टेक्स्ट के प्रारूप में हो सकता है। इस डेटा को किनेसिस डेटा स्ट्रीम या एमएसके विषय में संग्रहीत किया जा सकता है, और वास्तविक समय में KPI उत्पन्न करने के लिए संसाधित किया जा सकता है। आप उपयोगकर्ताओं की भावनाओं के विश्लेषण के लिए एफएम को काम पर लगा सकते हैं। एफएम प्रत्येक उत्तर का विश्लेषण कर सकते हैं और उपयोगकर्ता की संतुष्टि की एक श्रेणी निर्दिष्ट कर सकते हैं।
अपाचे फ्लिंक की वास्तुकला समय की खिड़कियों पर जटिल डेटा एकत्रीकरण की अनुमति देती है। यह डेटा इवेंट की स्ट्रीम पर SQL क्वेरी के लिए भी समर्थन प्रदान करता है। इसलिए, Apache Flink का उपयोग करके, आप कच्चे उपयोगकर्ता इनपुट का त्वरित विश्लेषण कर सकते हैं और परिचित SQL क्वेरी लिखकर वास्तविक समय में KPI उत्पन्न कर सकते हैं। अधिक जानकारी के लिए देखें टेबल एपीआई और एसक्यूएल.
- अपाचे फ्लिंक स्टूडियो के लिए अमेज़ॅन प्रबंधित सेवा, आप एक इंटरैक्टिव नोटबुक में मानक SQL, Python और Scala का उपयोग करके Apache Flink स्ट्रीम प्रोसेसिंग एप्लिकेशन बना और चला सकते हैं। स्टूडियो नोटबुक Apache Zeppelin द्वारा संचालित होते हैं और स्ट्रीम प्रोसेसिंग इंजन के रूप में Apache Flink का उपयोग करते हैं। स्टूडियो नोटबुक सभी कौशल सेटों के डेवलपर्स के लिए डेटा स्ट्रीम पर उन्नत विश्लेषण को सुलभ बनाने के लिए इन तकनीकों को सहजता से संयोजित करते हैं। उपयोगकर्ता-परिभाषित फ़ंक्शंस (यूडीएफ) के समर्थन के साथ, अपाचे फ़्लिंक भावना विश्लेषण जैसे जटिल कार्यों को करने के लिए कस्टम ऑपरेटरों को एफएम जैसे बाहरी संसाधनों के साथ एकीकृत करने की अनुमति देता है। आप विभिन्न मैट्रिक्स की गणना करने या उपयोगकर्ता की भावना जैसी अतिरिक्त अंतर्दृष्टि के साथ उपयोगकर्ता प्रतिक्रिया कच्चे डेटा को समृद्ध करने के लिए यूडीएफ का उपयोग कर सकते हैं। इस पैटर्न के बारे में अधिक जानने के लिए देखें जेनएआई, फ्लिंक, अपाचे काफ्का और किनेसिस के साथ वास्तविक समय में ग्राहकों की चिंताओं को सक्रिय रूप से संबोधित करना.
अपाचे फ्लिंक स्टूडियो के लिए प्रबंधित सेवा के साथ, आप एक क्लिक के साथ अपने स्टूडियो नोटबुक को स्ट्रीमिंग कार्य के रूप में तैनात कर सकते हैं। आप आउटपुट को अपनी पसंद के स्टोरेज में भेजने या इसे किनेसिस डेटा स्ट्रीम या एमएसके विषय में स्टेज करने के लिए अपाचे फ्लिंक द्वारा प्रदान किए गए देशी सिंक कनेक्टर का उपयोग कर सकते हैं। अमेज़न रेडशिफ्ट और ओपनसर्च सेवा दोनों विश्लेषणात्मक डेटा संग्रहीत करने के लिए आदर्श हैं। दोनों इंजन विश्लेषण के लिए डेटा लेक या डेटा वेयरहाउस में एक अलग स्ट्रीमिंग पाइपलाइन के माध्यम से किनेसिस डेटा स्ट्रीम और अमेज़ॅन एमएसके से मूल अंतर्ग्रहण समर्थन प्रदान करते हैं।
अमेज़ॅन रेडशिफ्ट बड़े पैमाने पर सर्वोत्तम मूल्य-प्रदर्शन प्रदान करने के लिए AWS-डिज़ाइन किए गए हार्डवेयर और मशीन लर्निंग का उपयोग करके, डेटा वेयरहाउस और डेटा लेक में संरचित और अर्ध-संरचित डेटा का विश्लेषण करने के लिए SQL का उपयोग करता है। ओपनसर्च सेवा ओपनसर्च डैशबोर्ड और किबाना (1.5 से 7.10 संस्करण) द्वारा संचालित विज़ुअलाइज़ेशन क्षमताएं प्रदान करती है।
जरूरत पड़ने पर आप एफएम को ठीक करने के लिए यूजर प्रॉम्प्ट डेटा के साथ इस तरह के विश्लेषण के परिणाम का उपयोग कर सकते हैं। सेजमेकर आपके एफएम को बेहतर बनाने का सबसे सीधा तरीका है। सेजमेकर के साथ अमेज़ॅन एस3 का उपयोग आपके मॉडलों को बेहतर बनाने के लिए एक शक्तिशाली और निर्बाध एकीकरण प्रदान करता है। अमेज़ॅन S3 एक स्केलेबल और टिकाऊ ऑब्जेक्ट स्टोरेज समाधान के रूप में कार्य करता है, जो बड़े डेटासेट, प्रशिक्षण डेटा और मॉडल कलाकृतियों के सीधे भंडारण और पुनर्प्राप्ति को सक्षम बनाता है। सेजमेकर एक पूरी तरह से प्रबंधित एमएल सेवा है जो संपूर्ण एमएल जीवनचक्र को सरल बनाती है। SageMaker के लिए स्टोरेज बैकएंड के रूप में Amazon S3 का उपयोग करके, आप Amazon S3 की स्केलेबिलिटी, विश्वसनीयता और लागत-प्रभावशीलता से लाभ उठा सकते हैं, जबकि इसे SageMaker प्रशिक्षण और तैनाती क्षमताओं के साथ एकीकृत कर सकते हैं। यह संयोजन कुशल डेटा प्रबंधन को सक्षम बनाता है, सहयोगात्मक मॉडल विकास की सुविधा प्रदान करता है, और यह सुनिश्चित करता है कि एमएल वर्कफ़्लो सुव्यवस्थित और स्केलेबल हैं, अंततः एमएल प्रक्रिया की समग्र चपलता और प्रदर्शन को बढ़ाता है। अधिक जानकारी के लिए देखें @रिमोट डेकोरेटर के साथ अमेज़ॅन सेजमेकर पर फाल्कन 7बी और अन्य एलएलएम को फाइन-ट्यून करें.
फ़ाइल सिस्टम सिंक कनेक्टर के साथ, अपाचे फ़्लिंक जॉब्स अमेज़ॅन S3 को खुले प्रारूप (जैसे JSON, Avro, Parquet, और अधिक) फ़ाइलों में डेटा ऑब्जेक्ट के रूप में डेटा वितरित कर सकता है। यदि आप ट्रांजेक्शनल डेटा लेक फ्रेमवर्क (जैसे अपाचे हुडी, अपाचे आइसबर्ग, या डेल्टा लेक) का उपयोग करके अपने डेटा लेक को प्रबंधित करना पसंद करते हैं, तो ये सभी फ्रेमवर्क अपाचे फ्लिंक के लिए एक कस्टम कनेक्टर प्रदान करते हैं। अधिक जानकारी के लिए देखें Amazon MSK Connect, Apache Flink और Apache Hudi का उपयोग करके एक कम विलंबता स्रोत-से-डेटा झील पाइपलाइन बनाएं.
सारांश
आरएजी मॉडल पर आधारित एक जेनेरिक एआई एप्लिकेशन के लिए, आपको दो डेटा स्टोरेज सिस्टम बनाने पर विचार करने की आवश्यकता है, और आपको डेटा ऑपरेशंस बनाने की ज़रूरत है जो उन्हें सभी स्रोत सिस्टम के साथ अद्यतित रखें। पारंपरिक बैच नौकरियां आपके जेनेरिक एआई एप्लिकेशन के साथ एकीकृत करने के लिए आवश्यक डेटा के आकार और विविधता को संसाधित करने के लिए पर्याप्त नहीं हैं। स्रोत प्रणालियों में परिवर्तनों को संसाधित करने में देरी के परिणामस्वरूप गलत प्रतिक्रिया होती है और आपके जेनरेटिव एआई एप्लिकेशन की दक्षता कम हो जाती है। डेटा स्ट्रीमिंग आपको विभिन्न प्रणालियों में विभिन्न प्रकार के डेटाबेस से डेटा प्राप्त करने में सक्षम बनाती है। यह आपको वास्तविक समय में कुशलतापूर्वक कई स्रोतों में डेटा को बदलने, समृद्ध करने, जोड़ने और एकत्र करने की भी अनुमति देता है। डेटा स्ट्रीमिंग उपयोगकर्ताओं की वास्तविक समय की प्रतिक्रियाओं या एप्लिकेशन प्रतिक्रियाओं पर टिप्पणियों को इकट्ठा करने और बदलने के लिए एक सरलीकृत डेटा आर्किटेक्चर प्रदान करती है, जो आपको मॉडल फाइन-ट्यूनिंग के लिए डेटा लेक में परिणाम देने और संग्रहीत करने में मदद करती है। डेटा स्ट्रीमिंग आपको केवल परिवर्तन की घटनाओं को संसाधित करके डेटा पाइपलाइनों को अनुकूलित करने में भी मदद करती है, जिससे आप डेटा परिवर्तनों पर अधिक तेज़ी से और कुशलता से प्रतिक्रिया दे सकते हैं।
इस बारे में अधिक जानें AWS डेटा स्ट्रीमिंग सेवाएँ और अपना खुद का डेटा स्ट्रीमिंग समाधान बनाना शुरू करें।
लेखक के बारे में
 अली एलेमी AWS में स्ट्रीमिंग स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। अली एडब्ल्यूएस ग्राहकों को वास्तु सर्वोत्तम प्रथाओं के साथ सलाह देता है और उन्हें रीयल-टाइम एनालिटिक्स डेटा सिस्टम डिजाइन करने में मदद करता है जो विश्वसनीय, सुरक्षित, कुशल और लागत प्रभावी हैं। वह ग्राहक के उपयोग के मामलों से पीछे की ओर काम करता है और उनकी व्यावसायिक समस्याओं को हल करने के लिए डेटा समाधान तैयार करता है। AWS में शामिल होने से पहले, अली ने कई सार्वजनिक क्षेत्र के ग्राहकों और AWS परामर्श भागीदारों को उनकी एप्लिकेशन आधुनिकीकरण यात्रा और क्लाउड में प्रवास में समर्थन दिया।
अली एलेमी AWS में स्ट्रीमिंग स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। अली एडब्ल्यूएस ग्राहकों को वास्तु सर्वोत्तम प्रथाओं के साथ सलाह देता है और उन्हें रीयल-टाइम एनालिटिक्स डेटा सिस्टम डिजाइन करने में मदद करता है जो विश्वसनीय, सुरक्षित, कुशल और लागत प्रभावी हैं। वह ग्राहक के उपयोग के मामलों से पीछे की ओर काम करता है और उनकी व्यावसायिक समस्याओं को हल करने के लिए डेटा समाधान तैयार करता है। AWS में शामिल होने से पहले, अली ने कई सार्वजनिक क्षेत्र के ग्राहकों और AWS परामर्श भागीदारों को उनकी एप्लिकेशन आधुनिकीकरण यात्रा और क्लाउड में प्रवास में समर्थन दिया।
 इम्तियाज (ताज़) सईद AWS में एनालिटिक्स के लिए वर्ल्ड-वाइड टेक लीडर हैं। उन्हें डेटा और एनालिटिक्स जैसी सभी चीजों पर समुदाय के साथ जुड़ना अच्छा लगता है। के माध्यम से उस तक पहुंचा जा सकता है लिंक्डइन.
इम्तियाज (ताज़) सईद AWS में एनालिटिक्स के लिए वर्ल्ड-वाइड टेक लीडर हैं। उन्हें डेटा और एनालिटिक्स जैसी सभी चीजों पर समुदाय के साथ जुड़ना अच्छा लगता है। के माध्यम से उस तक पहुंचा जा सकता है लिंक्डइन.
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

