परिचय
कृत्रिम बुद्धिमत्ता के क्षेत्र में हाल के वर्षों में उल्लेखनीय प्रगति देखी गई है, विशेषकर बड़े भाषा मॉडल के क्षेत्र में। एलएलएम मानव-जैसा पाठ उत्पन्न कर सकते हैं, दस्तावेज़ों को सारांशित कर सकते हैं और सॉफ़्टवेयर कोड लिख सकते हैं। मिस्ट्रल-7बी हाल के बड़े भाषा मॉडलों में से एक है जो अंग्रेजी पाठ और कोड पीढ़ी क्षमताओं का समर्थन करता है, और इसका उपयोग विभिन्न कार्यों के लिए किया जा सकता है जैसे पाठ संक्षेप, वर्गीकरण, पाठ पूर्णता, और कोड पूर्णता।

जो बात मिस्ट्रल-7बी-इंस्ट्रक्ट को अलग करती है, वह कम मापदंडों के बावजूद शानदार प्रदर्शन देने की इसकी क्षमता है, जो इसे एक उच्च-प्रदर्शन और लागत प्रभावी समाधान बनाती है। मॉडल ने हाल ही में लोकप्रियता हासिल की है जब बेंचमार्क नतीजों से पता चला है कि यह न केवल एमटी-बेंच पर सभी 7बी मॉडल से बेहतर प्रदर्शन करता है बल्कि 13बी चैट मॉडल के साथ भी अनुकूल प्रतिस्पर्धा करता है। इस ब्लॉग में, हम मिस्ट्रल 7बी की विशेषताओं और क्षमताओं का पता लगाएंगे, जिसमें इसके उपयोग के मामले, प्रदर्शन और मॉडल को ठीक करने के लिए एक व्यावहारिक मार्गदर्शिका शामिल है।
सीखने के मकसद
- समझें कि बड़े भाषा मॉडल और मिस्ट्रल 7बी कैसे काम करते हैं
- मिस्ट्रल 7बी की वास्तुकला और बेंचमार्क
- मिस्ट्रल 7बी के मामलों का उपयोग करें और यह कैसे कार्य करता है
- अनुमान और फ़ाइन-ट्यूनिंग के लिए कोड में गहराई से उतरें
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
बड़े भाषा मॉडल क्या हैं?
बड़े भाषा मॉडल'आर्किटेक्चर ट्रांसफॉर्मर के साथ बनता है, जो डेटा में लंबी दूरी की निर्भरता को पकड़ने के लिए ध्यान तंत्र का उपयोग करता है, जहां ट्रांसफॉर्मर ब्लॉक की कई परतों में मल्टी-हेड सेल्फ-अटेंशन और फीड-फॉरवर्ड न्यूरल नेटवर्क होते हैं। ये मॉडल टेक्स्ट डेटा पर पूर्व-प्रशिक्षित होते हैं, एक क्रम में अगले शब्द की भविष्यवाणी करना सीखते हैं, इस प्रकार भाषाओं में पैटर्न को कैप्चर करते हैं। विशिष्ट कार्यों पर पूर्व-प्रशिक्षण भार को ठीक किया जा सकता है। हम विशेष रूप से मिस्ट्रल 7बी एलएलएम की वास्तुकला को देखेंगे, और क्या चीज़ इसे विशिष्ट बनाती है।
मिस्ट्रल 7बी आर्किटेक्चर
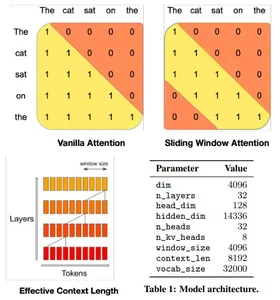
मिस्ट्रल 7बी मॉडल ट्रांसफॉर्मर आर्किटेक्चर कुशलतापूर्वक मेमोरी उपयोग के साथ उच्च प्रदर्शन को संतुलित करता है, गति और गुणवत्ता में बड़े मॉडलों से बेहतर प्रदर्शन करने के लिए ध्यान तंत्र और कैशिंग रणनीतियों का उपयोग करता है। यह 4096-विंडो स्लाइडिंग विंडो अटेंशन (एसडब्ल्यूए) का उपयोग करता है, जो प्रत्येक टोकन को पूर्ववर्ती टोकन के सबसेट में भाग लेने की अनुमति देकर लंबे अनुक्रमों पर ध्यान को अधिकतम करता है, जो लंबे अनुक्रमों पर ध्यान को अनुकूलित करता है।
एक दी गई छिपी हुई परत विंडो आकार और परत की गहराई द्वारा निर्धारित दूरी पर इनपुट परतों से टोकन तक पहुंच सकती है। मॉडल फ्लैश अटेंशन और एक्सफॉर्मर्स में संशोधनों को एकीकृत करता है, जिससे पारंपरिक ध्यान तंत्र की तुलना में गति दोगुनी हो जाती है। इसके अतिरिक्त, एक रोलिंग बफ़र कैश तंत्र कुशल मेमोरी उपयोग के लिए एक निश्चित कैश आकार बनाए रखता है।
Google Colab में मिस्ट्रल 7बी
आइए कोड में गहराई से उतरें और Google Colab में मिस्ट्रल 7बी मॉडल के साथ चल रहे अनुमानों को देखें। हम एकल T4 GPU के साथ मुफ़्त संस्करण का उपयोग करेंगे और मॉडल को लोड करेंगे आलिंगन करता हुआ चेहरा.
1. Colab में ctransformers लाइब्रेरी स्थापित करें और आयात करें।
#intsall ctransformers
pip install ctransformers[cuda] #import
from ctransformers import AutoModelForCausalLM2. हगिंग फेस से मॉडल ऑब्जेक्ट को प्रारंभ करें और आवश्यक पैरामीटर सेट करें। हम मॉडल के एक अलग संस्करण का उपयोग करेंगे क्योंकि मिस्ट्रल एआई के मूल मॉडल में पूरे मॉडल को Google Colab पर मेमोरी में लोड करने में समस्या हो सकती है।
#load the model from huggingface with 50 gpu layers
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf", model_type = "mistral", gpu_layers = 50)3. Google Colab में परिणामों को लंबवत रूप से प्रिंट करने के लिए एक फ़ंक्शन परिभाषित करें। यदि यह चरण किसी भिन्न परिवेश में चलाया जा रहा है तो इसे छोड़ा या संशोधित किया जा सकता है।
#function to print the model output in colab in a readable manner
def colab_print(text, max_width = 120): words = text.split() line = "" for word in words: if len(line) + len(word) + 1 > max_width: print(line) line = "" line += word + " " print (line)4. मॉडल का उपयोग करके टेक्स्ट जेनरेट करें और परिणाम देखें। जेनरेट किए गए टेक्स्ट की गुणवत्ता बदलने के लिए पैरामीटर्स को संशोधित करें।
#generate text
colab_print(llm('''Give me a well-written paragraph in 5 sentences about a Senior Data Scientist (name - Suvojit) who writes blogs on LLMs on Analytics Vidhya. He studied Masters in AIML in BITS Pilani and works at AZ Company, with a total of 4 years of experience. Start the sentence with - Suvojit is a''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))मॉडल प्रतिक्रिया: सुवोजीत एक वरिष्ठ डेटा वैज्ञानिक हैं, जो अपनी टीम के हिस्से के रूप में AZ कंपनी में 4 साल से काम कर रहे हैं, जो लिमिटेड मेमोरी मशीन लर्निंग तकनीकों का उपयोग करके अपने ग्राहकों के ब्रांडों और व्यावसायिक लाइनों में उपभोक्ता व्यवहार पूर्वानुमान मॉडल के डिजाइन, कार्यान्वयन और सुधार पर ध्यान केंद्रित कर रहे हैं। वह एनालिटिक्स विद्या पर एलएलएम के बारे में लिखते हैं जो उन्हें डेटा साइंस में नवीनतम रुझानों के साथ अपडेट रहने में मदद करता है। उनके पास बिट्स पिलानी से एआईएमएल में मास्टर डिग्री है, जहां उन्होंने मशीन लर्निंग एल्गोरिदम और उनके अनुप्रयोगों का अध्ययन किया। सुवोजित व्यवसायों को बेहतर निर्णय लेने और उनके प्रदर्शन में सुधार करने में मदद करने के लिए डेटा विज्ञान के अपने ज्ञान का उपयोग करने के लिए उत्साहित हैं।
बक्सों का इस्तेमाल करें
आइए मिस्ट्रल 7बी के कुछ उपयोग मामलों को अधिक विस्तार से देखें।
अनुवाद करें
मिस्ट्रल 7बी अनुवाद के लिए कई भाषाओं का समर्थन करता है। आइए अंग्रेजी से फ्रेंच और स्पेनिश अनुवाद देखें और सटीकता की जांच करें।
#translate English to French
colab_print(llm('''Translate this text from English to French: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))मॉडल प्रतिक्रिया: अनुवाद होगा: "सुवोजीत इस्ट अन साइंटिफिक डेस डोनीज़ सीनियर क्वि एक्रिट डेस ब्लॉग्स सुर एनालिटिक्स विद्या।"
#tranlsate English to Spanish
colab_print(llm('''Translate this text from English to Spanish: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))मॉडल प्रतिक्रिया: अनुवाद होगा: "सुवोजित एक वरिष्ठ डेटा वैज्ञानिक है जो एनालिटिक्स विद्या में ब्लॉग लिखता है।"
संक्षिप्तीकरण
उपयुक्त सारांश निर्देशों का उपयोग करके दस्तावेज़ों को छोटे संस्करण में सारांशित करने के लिए मिस्ट्रल 7बी का उपयोग करें।
#Define the prompt with instructions
prompt = '''[INST] You are a helpful code assistant. Your task is to summarize text into exactly two short sentences: Transformers have revolutionized the field of large language models with their ability to capture long-range dependencies and intricate patterns in text. Originating from the paper "Attention Is All You Need" by Vaswani et al. in 2017, transformers introduced the self-attention mechanism, which weighs input tokens differently based on their relevance to a given token. This mechanism enables transformers to process
information more flexibly than traditional RNNs or LSTMs. Consequently, models like GPT, BERT, and their subsequent iterations have been built on the transformer architecture, leading to breakthroughs in numerous natural language processing tasks. Their parallel processing capabilities further make them conducive to training on vast amounts of data. However, as these models grow in size, concerns about their environmental impact and computational demands also emerge. Despite these challenges, the transformative power of transformers in language models remains undeniable. Just summarize the text in exactly 2 short sentences without explanations:
[/INST]''' #Summarize
colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))मॉडल प्रतिक्रिया: ट्रांसफॉर्मर ने लंबी दूरी की निर्भरता और जटिल पैटर्न को पकड़कर बड़े भाषा मॉडल में क्रांति ला दी है, एक आत्म-ध्यान तंत्र पेश किया है जो उन्हें जानकारी को लचीले ढंग से संसाधित करता है और बाद के कार्यान्वयन में जीपीटी और बीईआरटी जैसी सफलताएं शामिल हैं। हालाँकि, जैसे-जैसे ये मॉडल आकार में बढ़ते हैं, उनके पर्यावरणीय प्रभाव और कम्प्यूटेशनल माँगों के बारे में चिंताएँ पैदा होती हैं, इन चुनौतियों के बावजूद वे भाषा मॉडलिंग में निर्विवाद रूप से परिवर्तनकारी बने रहते हैं।
कस्टम निर्देश
हम मॉडल से एक विशेष प्रतिक्रिया प्राप्त करने के लिए उपयोगकर्ता इनपुट को संशोधित करने के लिए [INST] टैग का उपयोग कर सकते हैं। उदाहरण के लिए, हम टेक्स्ट विवरण के आधार पर JSON उत्पन्न कर सकते हैं।
prompt = '''[INST] You are a helpful code assistant. Your task is to generate a valid JSON object based on the given information: My name is Suvojit Hore, working in company AB and my address is AZ Street NY. Just generate the JSON object without explanations:
[/INST] ''' colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))मॉडल प्रतिक्रिया: “`json {“नाम”: “सुवोजीत होरे”, “कंपनी”: “AB”, “पता”: “AZ स्ट्रीट NY” } “`
मिस्ट्रल 7बी को फाइन-ट्यूनिंग
आइए देखें कि हम Google Colab पर एकल GPU का उपयोग करके मॉडल को कैसे बेहतर बना सकते हैं। हम एक डेटासेट का उपयोग करेंगे जो छवियों के बारे में कुछ शब्दों के विवरण को विस्तृत और अत्यधिक वर्णनात्मक पाठ में परिवर्तित करता है। इन परिणामों का उपयोग विशिष्ट छवि उत्पन्न करने के लिए मिडजर्नी में किया जा सकता है। लक्ष्य एलएलएम को छवि निर्माण के लिए एक त्वरित इंजीनियर के रूप में कार्य करने के लिए प्रशिक्षित करना है।
पर्यावरण सेटअप करें और Google Colab में आवश्यक लाइब्रेरी आयात करें:
# Install the necessary libraries
!pip install pandas autotrain-advanced -q
!autotrain setup --update-torch
!pip install -q peft accelerate bitsandbytes safetensors #import the necesary libraries
import pandas as pd
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
from huggingface_hub import notebook_loginब्राउज़र से हगिंग फेस में लॉग इन करें और एक्सेस टोकन को कॉपी करें। नोटबुक में हगिंग फेस में लॉग इन करने के लिए इस टोकन का उपयोग करें।
notebook_login()
डेटासेट को Colab सत्र संग्रहण पर अपलोड करें। हम मिडजर्नी डेटासेट का उपयोग करेंगे।
df = pd.read_csv("prompt_engineering.csv")
df.head(5)
उपयुक्त मापदंडों के साथ ऑटोट्रेन का उपयोग करके मॉडल को प्रशिक्षित करें। अपने स्वयं के हगिन फेस रेपो और उपयोगकर्ता एक्सेस टोकन के लिए इसे चलाने के लिए नीचे दिए गए कमांड को संशोधित करें।
!autotrain llm --train --project_name mistral-7b-sh-finetuned --model username/Mistral-7B-Instruct-v0.1-sharded --token hf_yiguyfTFtufTFYUTUfuytfuys --data_path . --use_peft --use_int4 --learning_rate 2e-4 --train_batch_size 12 --num_train_epochs 3 --trainer sft --target_modules q_proj,v_proj --push_to_hub --repo_id username/mistral-7b-sh-finetunedआइए अब अनुमान इंजन को चलाने और छवियों के कुछ विस्तृत विवरण उत्पन्न करने के लिए परिष्कृत मॉडल का उपयोग करें।
#adapter and model
adapters_name = "suvz47/mistral-7b-sh-finetuned"
model_name = "bn22/Mistral-7B-Instruct-v0.1-sharded" device = "cuda" #set the config
bnb_config = transformers.BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
) #initialize the model
model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, torch_dtype=torch.bfloat16, quantization_config=bnb_config, device_map='auto'
)परिष्कृत मॉडल और टोकनाइज़र लोड करें।
#load the model and tokenizer
model = PeftModel.from_pretrained(model, adapters_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.bos_token_id = 1 stop_token_ids = [0]केवल कुछ शब्दों के साथ एक विस्तृत और वर्णनात्मक मिडजर्नी प्रॉम्प्ट तैयार करें।
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A computer with an emotional chip [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])मॉडल प्रतिक्रिया: जैसे ही भावनात्मक चिप वाला कंप्यूटर अपनी भावनाओं को संसाधित करना शुरू करता है, यह अपने अस्तित्व और उद्देश्य पर सवाल उठाना शुरू कर देता है, जिससे आत्म-खोज और आत्म-सुधार की यात्रा शुरू हो जाती है।
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A rainbow chasing its colors [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])मॉडल प्रतिक्रिया: रंगों का पीछा करता हुआ इंद्रधनुष खुद को एक रेगिस्तान में पाता है जहां आकाश अंतहीन नीले रंग का समुद्र है, और इंद्रधनुष के रंग रेत में बिखरे हुए हैं।
निष्कर्ष
मिस्ट्रल 7बी बड़े भाषा मॉडल के क्षेत्र में एक महत्वपूर्ण प्रगति साबित हुआ है। इसकी कुशल वास्तुकला, इसके बेहतर प्रदर्शन के साथ, भविष्य में विभिन्न एनएलपी कार्यों के लिए प्रमुख बनने की इसकी क्षमता को दर्शाती है। यह ब्लॉग मॉडल की वास्तुकला, उसके अनुप्रयोग और अन्य अनुप्रयोगों के लिए अनुवाद, सारांश और फाइन-ट्यूनिंग जैसे विशिष्ट कार्यों के लिए इसकी शक्ति का उपयोग कैसे कर सकता है, इस बारे में अंतर्दृष्टि प्रदान करता है। सही मार्गदर्शन और प्रयोग के साथ, मिस्ट्रल 7बी एलएलएम के साथ जो संभव है उसकी सीमाओं को फिर से परिभाषित कर सकता है।
चाबी छीन लेना
- मिस्ट्रल-7बी-कम मापदंडों के बावजूद प्रदर्शन में उत्कृष्टता का निर्देश देता है।
- यह लंबे अनुक्रम अनुकूलन के लिए स्लाइडिंग विंडो अटेंशन का उपयोग करता है।
- फ़्लैश अटेंशन और xFormers जैसे फ़ीचर इसकी गति को दोगुना कर देते हैं।
- रोलिंग बफ़र कैश कुशल मेमोरी प्रबंधन सुनिश्चित करता है।
- बहुमुखी: अनुवाद, सारांशीकरण, संरचित डेटा निर्माण, पाठ निर्माण और पाठ समापन को संभालता है।
- कस्टम निर्देश जोड़ने के लिए प्रॉम्प्ट इंजीनियरिंग मॉडल को क्वेरी को बेहतर ढंग से समझने और कई जटिल भाषा कार्यों को करने में मदद कर सकती है।
- फाइनट्यून मिस्ट्रल 7बी किसी भी विशिष्ट भाषा कार्य जैसे एक त्वरित इंजीनियर के रूप में कार्य करने के लिए।
आम सवाल-जवाब
A. मिस्ट्रल-7बी को दक्षता और प्रदर्शन के लिए डिज़ाइन किया गया है। हालांकि इसमें कुछ अन्य मॉडलों की तुलना में कम पैरामीटर हैं, लेकिन इसकी वास्तुशिल्प प्रगति, जैसे कि स्लाइडिंग विंडो अटेंशन, इसे उत्कृष्ट परिणाम देने की अनुमति देती है, यहां तक कि विशिष्ट कार्यों में बड़े मॉडलों से भी बेहतर प्रदर्शन करती है।
उ. हां, मिस्ट्रल-7बी को विभिन्न कार्यों के लिए ठीक किया जा सकता है। गाइड छवि निर्माण के लिए संक्षिप्त पाठ विवरण को विस्तृत संकेतों में परिवर्तित करने के लिए मॉडल को ठीक करने का एक उदाहरण प्रदान करता है।
A. स्लाइडिंग विंडो अटेंशन (SWA) मॉडल को लंबे अनुक्रमों को कुशलतापूर्वक संभालने की अनुमति देता है। 4096 के विंडो आकार के साथ, एसडब्ल्यूए ध्यान संचालन को अनुकूलित करता है, जिससे मिस्ट्रल-7बी गति या सटीकता से समझौता किए बिना लंबे पाठों को संसाधित करने में सक्षम होता है।
उ. हां, मिस्ट्रल-7बी इनफरेंस चलाते समय, हम ctransformers लाइब्रेरी का उपयोग करने की सलाह देते हैं, खासकर Google Colab के भीतर काम करते समय। अतिरिक्त सुविधा के लिए आप मॉडल को हगिंग फेस से भी लोड कर सकते हैं
उ. इनपुट प्रॉम्प्ट में विस्तृत निर्देश तैयार करना महत्वपूर्ण है। मिस्ट्रल-7बी की बहुमुखी प्रतिभा इसे इन विस्तृत निर्देशों को समझने और उनका पालन करने में सक्षम बनाती है, जिससे सटीक और वांछित आउटपुट सुनिश्चित होते हैं। उचित त्वरित इंजीनियरिंग मॉडल के प्रदर्शन को महत्वपूर्ण रूप से बढ़ा सकती है।
संदर्भ
- थंबनेल - स्थिर प्रसार का उपयोग करके उत्पन्न किया गया
- आर्किटेक्चर - काग़ज़
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/11/from-gpt-to-mistral-7b-the-exciting-leap-forward-in-ai-conversations/

