यह एक्सफ़ूड एबी द्वारा लिखित एक अतिथि पोस्ट है।
इस पोस्ट में, हम साझा करते हैं कि कैसे एक बड़े स्वीडिश खाद्य खुदरा विक्रेता, एक्सफ़ूड ने AWS विशेषज्ञों के साथ निकट सहयोग में प्रोटोटाइप द्वारा अपने मौजूदा कृत्रिम बुद्धिमत्ता (एआई) और मशीन लर्निंग (एमएल) संचालन के संचालन और स्केलेबिलिटी में सुधार किया। अमेज़न SageMaker.
एक्सफ़ूड 13,000 से अधिक कर्मचारियों और 300 से अधिक स्टोरों के साथ स्वीडन का दूसरा सबसे बड़ा खाद्य खुदरा विक्रेता है। एक्सफ़ूड में जिम्मेदारी के विभिन्न क्षेत्रों के साथ कई विकेन्द्रीकृत डेटा विज्ञान टीमों के साथ एक संरचना है। एक केंद्रीय डेटा प्लेटफ़ॉर्म टीम के साथ, डेटा विज्ञान टीमें संगठन में एआई और एमएल समाधानों के माध्यम से नवाचार और डिजिटल परिवर्तन लाती हैं। एक्सफूड एमएल का उपयोग करके अपने डेटा को विकसित करने के लिए अमेज़ॅन सेजमेकर का उपयोग कर रहा है और कई वर्षों से उत्पादन में मॉडल हैं। हाल ही में, परिष्कार का स्तर और उत्पादन में मॉडलों की विशाल संख्या तेजी से बढ़ रही है। हालाँकि, नवाचार की गति अधिक होने के बावजूद, विभिन्न टीमों ने काम करने के अपने तरीके विकसित किए थे और नए एमएलओपीएस सर्वोत्तम अभ्यास की तलाश में थे।
हमारी चुनौती
क्लाउड सेवाओं और एआई/एमएल के मामले में प्रतिस्पर्धी बने रहने के लिए, एक्सफ़ूड ने AWS के साथ साझेदारी करना चुना और कई वर्षों से उनके साथ सहयोग कर रहा है।
AWS के साथ हमारे आवर्ती विचार-मंथन सत्रों में से एक के दौरान, हम चर्चा कर रहे थे कि डेटा विज्ञान और एमएल चिकित्सकों की नवाचार और दक्षता की गति को बढ़ाने के लिए टीमों में सर्वोत्तम सहयोग कैसे किया जाए। हमने एमएलओपीएस के लिए सर्वोत्तम अभ्यास पर एक प्रोटोटाइप बनाने के लिए संयुक्त प्रयास करने का निर्णय लिया। प्रोटोटाइप का उद्देश्य स्केलेबल और कुशल एमएल मॉडल बनाने के लिए सभी डेटा विज्ञान टीमों के लिए एक मॉडल टेम्पलेट बनाना था - एक्सफूड के लिए एआई और एमएल प्लेटफार्मों की एक नई पीढ़ी की नींव। टेम्पलेट को AWS ML विशेषज्ञों और कंपनी-विशिष्ट सर्वोत्तम अभ्यास मॉडल - दोनों दुनिया के सर्वोत्तम - से सर्वोत्तम प्रथाओं को जोड़ना और संयोजित करना चाहिए।
हमने एक्सफ़ूड के वर्तमान में सबसे विकसित एमएल मॉडल में से एक से एक प्रोटोटाइप बनाने का निर्णय लिया: दुकानों में बिक्री का पूर्वानुमान लगाना. अधिक विशेष रूप से, खाद्य खुदरा दुकानों के लिए आगामी अभियानों के फलों और सब्जियों का पूर्वानुमान। सटीक दैनिक पूर्वानुमान दुकानों के लिए ऑर्डर देने की प्रक्रिया का समर्थन करता है, स्टोर में आवश्यक स्टॉक स्तरों की सटीक भविष्यवाणी करके बिक्री को अनुकूलित करने के परिणामस्वरूप भोजन की बर्बादी को कम करके स्थिरता बढ़ाता है। यह हमारे प्रोटोटाइप के लिए शुरुआत करने के लिए एकदम सही जगह थी - न केवल एक्सफूड को एक नया एआई/एमएल प्लेटफॉर्म मिलेगा, बल्कि हमें अपनी एमएल क्षमताओं को बेंचमार्क करने और प्रमुख एडब्ल्यूएस विशेषज्ञों से सीखने का भी मौका मिलेगा।
हमारा समाधान: अमेज़ॅन सेजमेकर स्टूडियो पर एक नया एमएल टेम्पलेट
एक वास्तविक व्यावसायिक मामले के लिए डिज़ाइन की गई पूर्ण एमएल पाइपलाइन का निर्माण चुनौतीपूर्ण हो सकता है। इस मामले में, हम एक पूर्वानुमान मॉडल विकसित कर रहे हैं, इसलिए इसे पूरा करने के लिए दो मुख्य चरण हैं:
- ऐतिहासिक डेटा का उपयोग करके पूर्वानुमान लगाने के लिए मॉडल को प्रशिक्षित करें।
- भविष्य की घटनाओं की भविष्यवाणी करने के लिए प्रशिक्षित मॉडल लागू करें।
एक्सफ़ूड के मामले में, इस उद्देश्य के लिए एक अच्छी तरह से काम करने वाली पाइपलाइन पहले से ही सेजमेकर नोटबुक का उपयोग करके स्थापित की गई थी और तीसरे पक्ष के वर्कफ़्लो प्रबंधन प्लेटफ़ॉर्म एयरफ़्लो द्वारा व्यवस्थित की गई थी। हालाँकि, हमारे एमएल प्लेटफॉर्म को आधुनिक बनाने और आगे बढ़ने के कई स्पष्ट लाभ हैं अमेज़ॅन सैजमेकर स्टूडियो और अमेज़न SageMaker पाइपलाइन. सेजमेकर स्टूडियो में जाने से कई पूर्वनिर्धारित आउट-ऑफ़-द-बॉक्स सुविधाएँ मिलती हैं:
- मॉडल और डेटा गुणवत्ता के साथ-साथ मॉडल व्याख्या की निगरानी करना
- डिबगिंग जैसे अंतर्निहित एकीकृत विकास वातावरण (आईडीई) उपकरण
- लागत/प्रदर्शन की निगरानी
- मॉडल स्वीकृति ढाँचा
- मॉडल रजिस्ट्री
हालाँकि, एक्सफ़ूड के लिए सबसे महत्वपूर्ण प्रोत्साहन कस्टम प्रोजेक्ट टेम्प्लेट बनाने की क्षमता है अमेज़ॅन सेजमेकर प्रोजेक्ट्स सभी डेटा विज्ञान टीमों और एमएल चिकित्सकों के लिए एक ब्लूप्रिंट के रूप में उपयोग किया जाएगा। एक्सफ़ूड टीम के पास पहले से ही एमएल मॉडलिंग का एक मजबूत और परिपक्व स्तर था, इसलिए मुख्य ध्यान नई वास्तुकला के निर्माण पर था।
समाधान अवलोकन
एक्सफूड का प्रस्तावित नया एमएल ढांचा दो मुख्य पाइपलाइनों के आसपास संरचित है: मॉडल बिल्ड पाइपलाइन और बैच इंफ़ेक्शन पाइपलाइन:
- इन पाइपलाइनों को दो अलग-अलग Git रिपॉजिटरी में संस्करणित किया गया है: एक बिल्ड रिपॉजिटरी और एक परिनियोजन (अनुमान) रिपॉजिटरी। साथ में, वे फलों और सब्जियों के पूर्वानुमान के लिए एक मजबूत पाइपलाइन बनाते हैं।
- पाइपलाइनों को निरंतर एकीकरण और निरंतर तैनाती (सीआई/सीडी) घटकों के लिए तीसरे पक्ष के गिट रिपॉजिटरी (बिटबकेट) और बिटबकेट पाइपलाइनों के साथ एकीकरण में सेजमेकर प्रोजेक्ट्स का उपयोग करके एक कस्टम प्रोजेक्ट टेम्पलेट में पैक किया गया है।
- सेजमेकर प्रोजेक्ट टेम्पलेट में पाइपलाइनों के निर्माण और तैनाती के प्रत्येक चरण के अनुरूप बीज कोड शामिल है (हम इस पोस्ट में बाद में इन चरणों पर अधिक विस्तार से चर्चा करते हैं) साथ ही पाइपलाइन परिभाषा-चरणों को कैसे चलाया जाना चाहिए इसके लिए नुस्खा शामिल है।
- टेम्पलेट के आधार पर नई परियोजनाओं के निर्माण के स्वचालन को सुव्यवस्थित किया गया है AWS सेवा सूची, जहां एक पोर्टफोलियो बनाया जाता है, जो कई उत्पादों के लिए एक सार के रूप में कार्य करता है।
- प्रत्येक उत्पाद एक में तब्दील हो जाता है एडब्ल्यूएस CloudFormation टेम्प्लेट, जिसे तब तैनात किया जाता है जब एक डेटा वैज्ञानिक नींव के रूप में हमारे एमएलओपीएस ब्लूप्रिंट के साथ एक नया सेजमेकर प्रोजेक्ट बनाता है। यह एक को सक्रिय करता है AWS लाम्बा फ़ंक्शन जो दो रिपॉजिटरी-मॉडल बिल्ड और मॉडल परिनियोजन-के साथ एक बिटबकेट प्रोजेक्ट बनाता है जिसमें बीज कोड होता है।
निम्नलिखित चित्र समाधान वास्तुकला को दर्शाता है। वर्कफ़्लो ए दो मॉडल पाइपलाइनों-निर्माण और अनुमान के बीच जटिल प्रवाह को दर्शाता है। वर्कफ़्लो बी एक नया एमएल प्रोजेक्ट बनाने के लिए प्रवाह दिखाता है।

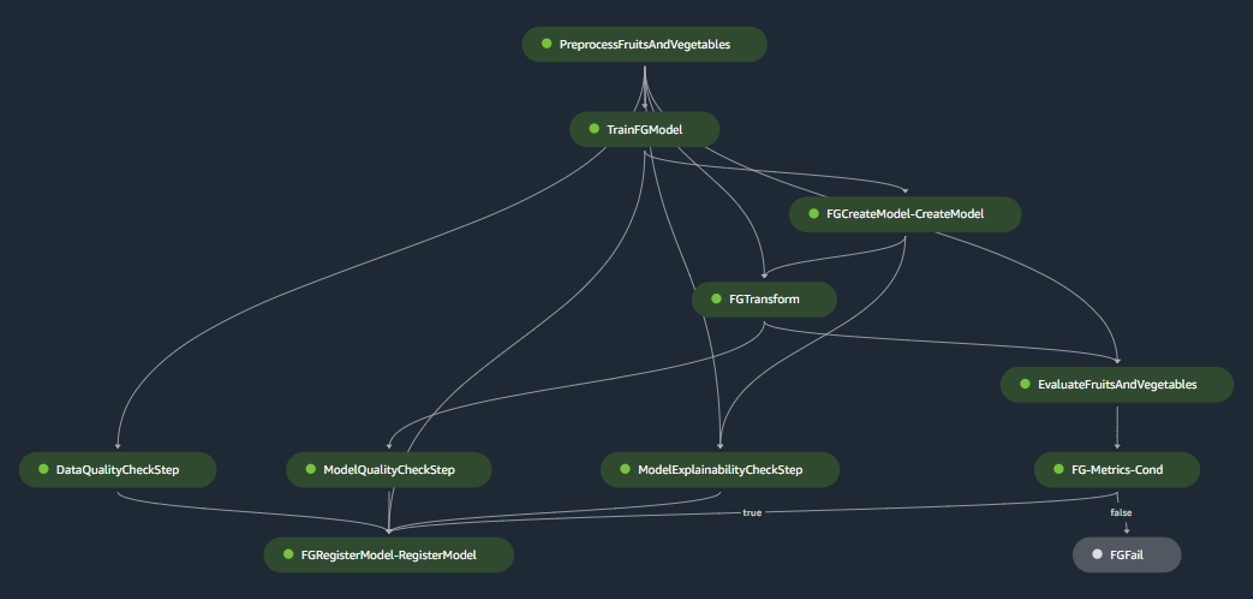
मॉडल निर्माण पाइपलाइन
मॉडल बिल्ड पाइपलाइन मॉडल के जीवनचक्र को व्यवस्थित करती है, जो प्रीप्रोसेसिंग से शुरू होती है, प्रशिक्षण के माध्यम से आगे बढ़ती है, और मॉडल रजिस्ट्री में पंजीकृत होने पर समाप्त होती है:
- preprocessing - यहाँ, सेजमेकर
ScriptProcessorक्लास को फीचर इंजीनियरिंग के लिए नियोजित किया जाता है, जिसके परिणामस्वरूप डेटासेट पर मॉडल को प्रशिक्षित किया जाएगा। - प्रशिक्षण और बैच परिवर्तन - सेजमेकर के कस्टम प्रशिक्षण और अनुमान कंटेनरों का उपयोग ऐतिहासिक डेटा पर मॉडल को प्रशिक्षित करने और संबंधित कार्यों के लिए सेजमेकर एस्टिमेटर और ट्रांसफार्मर का उपयोग करके मूल्यांकन डेटा पर पूर्वानुमान बनाने के लिए किया जाता है।
- मूल्यांकन - प्रशिक्षित मॉडल मूल्यांकन डेटा पर उत्पन्न भविष्यवाणियों की तुलना जमीनी सच्चाई से करके मूल्यांकन करता है
ScriptProcessor. - आधारभूत नौकरियाँ - पाइपलाइन इनपुट डेटा में आंकड़ों के आधार पर बेसलाइन बनाती है। ये डेटा और मॉडल गुणवत्ता के साथ-साथ फीचर एट्रिब्यूशन की निगरानी के लिए आवश्यक हैं।
- मॉडल रजिस्ट्री - प्रशिक्षित मॉडल को भविष्य में उपयोग के लिए पंजीकृत किया गया है। उत्पादन में उपयोग के लिए मॉडल को तैनात करने के लिए नामित डेटा वैज्ञानिकों द्वारा मॉडल को मंजूरी दी जाएगी।
उत्पादन परिवेश के लिए, डेटा अंतर्ग्रहण और ट्रिगर तंत्र को प्राथमिक एयरफ़्लो ऑर्केस्ट्रेशन के माध्यम से प्रबंधित किया जाता है। इस बीच, विकास के दौरान, जब भी मॉडल बिल्ड बिटबकेट रिपॉजिटरी में एक नई प्रतिबद्धता पेश की जाती है तो पाइपलाइन सक्रिय हो जाती है। निम्नलिखित चित्र मॉडल बिल्ड पाइपलाइन की कल्पना करता है।
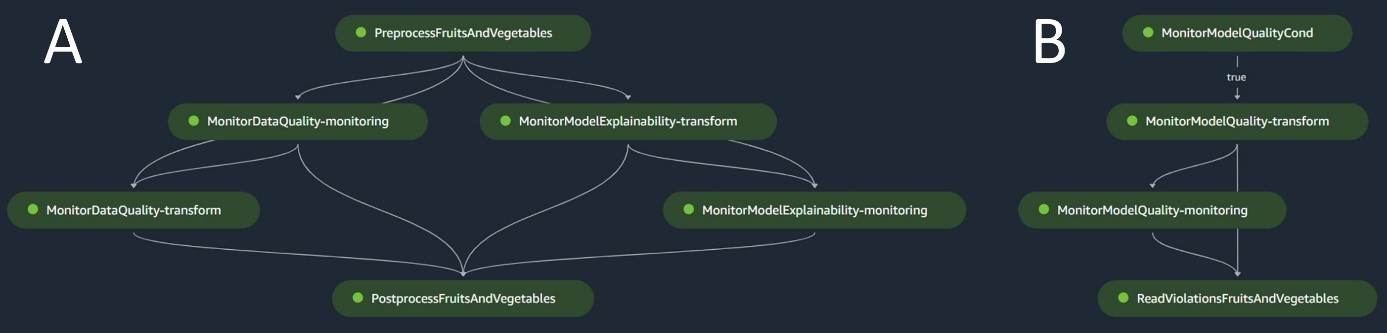
बैच अनुमान पाइपलाइन
बैच अनुमान पाइपलाइन अनुमान चरण को संभालती है, जिसमें निम्नलिखित चरण होते हैं:
- preprocessing - डेटा का उपयोग करके प्रीप्रोसेस किया जाता है
ScriptProcessor. - बैच परिवर्तन - मॉडल सेजमेकर ट्रांसफार्मर के साथ कस्टम इंट्रेंस कंटेनर का उपयोग करता है और इनपुट प्रीप्रोसेस्ड डेटा को देखते हुए भविष्यवाणियां उत्पन्न करता है। उपयोग किया गया मॉडल मॉडल रजिस्ट्री में नवीनतम अनुमोदित प्रशिक्षित मॉडल है।
- प्रोसेसिंग के बाद - भविष्यवाणियाँ पोस्टप्रोसेसिंग चरणों की एक श्रृंखला का उपयोग करके गुजरती हैं
ScriptProcessor. - निगरानी - सतत निगरानी डेटा गुणवत्ता, मॉडल गुणवत्ता और फीचर एट्रिब्यूशन से संबंधित बदलावों की जांच पूरी करती है।
यदि विसंगतियां उत्पन्न होती हैं, तो पोस्टप्रोसेसिंग स्क्रिप्ट के भीतर एक व्यावसायिक तर्क यह आकलन करता है कि मॉडल को फिर से प्रशिक्षित करना आवश्यक है या नहीं। पाइपलाइन नियमित अंतराल पर चलने के लिए निर्धारित है।
निम्नलिखित चित्र बैच अनुमान पाइपलाइन को दर्शाता है। वर्कफ़्लो ए प्रीप्रोसेसिंग, डेटा गुणवत्ता और फीचर एट्रिब्यूशन ड्रिफ्ट जांच, अनुमान और पोस्टप्रोसेसिंग से मेल खाता है। वर्कफ़्लो बी मॉडल गुणवत्ता बहाव जांच से मेल खाता है। इन पाइपलाइनों को विभाजित किया गया है क्योंकि मॉडल गुणवत्ता बहाव जांच केवल तभी चलेगी जब नया जमीनी सच्चाई डेटा उपलब्ध होगा।
SageMaker मॉडल मॉनिटर
- अमेज़ॅन सैजमेकर मॉडल मॉनिटर एकीकृत, पाइपलाइनों को निम्नलिखित पर वास्तविक समय की निगरानी से लाभ होता है:
- आँकड़े की गुणवत्ता - डेटा में किसी भी बहाव या विसंगतियों पर नज़र रखता है
- मॉडल की गुणवत्ता - मॉडल के प्रदर्शन में किसी भी उतार-चढ़ाव पर नजर रखता है
- फ़ीचर एट्रिब्यूशन - फ़ीचर एट्रिब्यूशन में बहाव की जाँच करता है
मॉडल गुणवत्ता की निगरानी के लिए जमीनी सच्चाई डेटा तक पहुंच की आवश्यकता होती है। यद्यपि जमीनी सच्चाई प्राप्त करना कभी-कभी चुनौतीपूर्ण हो सकता है, डेटा या फीचर एट्रिब्यूशन ड्रिफ्ट मॉनिटरिंग का उपयोग मॉडल गुणवत्ता के लिए एक सक्षम प्रॉक्सी के रूप में कार्य करता है।
विशेष रूप से, डेटा गुणवत्ता विचलन के मामले में, सिस्टम निम्नलिखित पर ध्यान देता है:
- संकल्पना बहाव - यह इनपुट और आउटपुट के बीच सहसंबंध में बदलाव से संबंधित है, जिसके लिए जमीनी सच्चाई की आवश्यकता होती है
- सहसंयोजक बदलाव - यहां, स्वतंत्र इनपुट चर के वितरण में परिवर्तन पर जोर दिया गया है
सेजमेकर मॉडल मॉनिटर की डेटा ड्रिफ्ट कार्यक्षमता इनपुट डेटा को सावधानीपूर्वक कैप्चर और जांचती है, नियमों और सांख्यिकीय जांचों को तैनात करती है। जब भी विसंगतियों का पता चलता है तो अलर्ट जारी कर दिया जाता है।
मॉडल गिरावट की निगरानी के लिए प्रॉक्सी के रूप में डेटा गुणवत्ता बहाव जांच का उपयोग करने के समानांतर, सिस्टम सामान्यीकृत डिस्काउंटेड संचयी लाभ (एनडीसीजी) स्कोर का उपयोग करके फीचर एट्रिब्यूशन बहाव की भी निगरानी करता है। यह स्कोर फीचर एट्रिब्यूशन रैंकिंग क्रम में बदलाव के साथ-साथ फीचर के कच्चे एट्रिब्यूशन स्कोर दोनों के प्रति संवेदनशील है। व्यक्तिगत विशेषताओं और उनके सापेक्ष महत्व के लिए एट्रिब्यूशन में बहाव की निगरानी करके, मॉडल की गुणवत्ता में गिरावट का पता लगाना आसान है।
मॉडल की व्याख्या
मॉडल व्याख्याशीलता एमएल परिनियोजन का एक महत्वपूर्ण हिस्सा है, क्योंकि यह भविष्यवाणियों में पारदर्शिता सुनिश्चित करता है। विस्तृत समझ के लिए, हम उपयोग करते हैं अमेज़न SageMaker स्पष्ट करें.
यह शेपली मूल्य अवधारणा पर आधारित मॉडल-अज्ञेयवादी फीचर एट्रिब्यूशन तकनीक के माध्यम से वैश्विक और स्थानीय दोनों मॉडल स्पष्टीकरण प्रदान करता है। इसका उपयोग यह जानने के लिए किया जाता है कि अनुमान के दौरान कोई विशेष भविष्यवाणी क्यों की गई थी। ऐसी व्याख्याएँ, जो स्वाभाविक रूप से विरोधाभासी हैं, विभिन्न आधार रेखाओं के आधार पर भिन्न हो सकती हैं। सेजमेकर क्लैरिफाई इनपुट डेटासेट में के-मीन्स या के-प्रोटोटाइप का उपयोग करके इस बेसलाइन को निर्धारित करने में सहायता करता है, जिसे बाद में मॉडल बिल्ड पाइपलाइन में जोड़ा जाता है। यह कार्यक्षमता हमें मॉडल कैसे काम करती है इसकी समझ बढ़ाने के लिए भविष्य में जेनरेटिव एआई एप्लिकेशन बनाने में सक्षम बनाती है।
औद्योगीकरण: प्रोटोटाइप से उत्पादन तक
एमएलओपीएस प्रोजेक्ट में उच्च स्तर का स्वचालन शामिल है और यह समान उपयोग के मामलों के लिए ब्लूप्रिंट के रूप में काम कर सकता है:
- बुनियादी ढांचे का पूरी तरह से पुन: उपयोग किया जा सकता है, जबकि बीज कोड को प्रत्येक कार्य के लिए अनुकूलित किया जा सकता है, अधिकांश परिवर्तन पाइपलाइन परिभाषा और प्रीप्रोसेसिंग, प्रशिक्षण, अनुमान और पोस्टप्रोसेसिंग के लिए व्यावसायिक तर्क तक सीमित हैं।
- प्रशिक्षण और अनुमान स्क्रिप्ट को सेजमेकर कस्टम कंटेनरों का उपयोग करके होस्ट किया जाता है, इसलिए जब तक डेटा सारणीबद्ध प्रारूप में है, तब तक विभिन्न मॉडलों को डेटा और मॉडल निगरानी या मॉडल व्याख्यात्मक चरणों में बदलाव किए बिना समायोजित किया जा सकता है।
प्रोटोटाइप पर काम खत्म करने के बाद, हमने इस बात पर ध्यान दिया कि हमें इसे उत्पादन में कैसे उपयोग करना चाहिए। ऐसा करने के लिए, हमें MLOps टेम्पलेट में कुछ अतिरिक्त समायोजन करने की आवश्यकता महसूस हुई:
- टेम्पलेट के प्रोटोटाइप में उपयोग किए गए मूल बीज कोड में कोर एमएल चरणों (प्रशिक्षण और अनुमान) से पहले और बाद में चलने वाले प्रीप्रोसेसिंग और पोस्टप्रोसेसिंग चरण शामिल थे। हालाँकि, जब उत्पादन में एकाधिक उपयोग के मामलों के लिए टेम्पलेट का उपयोग बढ़ाया जाता है, तो अंतर्निहित प्रीप्रोसेसिंग और पोस्टप्रोसेसिंग चरणों से कोड की व्यापकता और पुनरुत्पादन में कमी आ सकती है।
- व्यापकता में सुधार लाने और दोहराव वाले कोड को कम करने के लिए, हमने पाइपलाइनों को और भी कम करने का निर्णय लिया। एमएल पाइपलाइन के हिस्से के रूप में प्रीप्रोसेसिंग और पोस्टप्रोसेसिंग चरणों को चलाने के बजाय, हम इन्हें एमएल पाइपलाइन को ट्रिगर करने से पहले और बाद में प्राथमिक एयरफ्लो ऑर्केस्ट्रेशन के हिस्से के रूप में चलाते हैं।
- इस तरह, उपयोग के मामले-विशिष्ट प्रसंस्करण कार्यों को टेम्पलेट से अलग कर दिया जाता है, और जो बचा है वह एक कोर एमएल पाइपलाइन है जो कोड की न्यूनतम पुनरावृत्ति के साथ कई उपयोग के मामलों में सामान्य कार्य करता है। उपयोग के मामलों के बीच भिन्न पैरामीटर प्राथमिक एयरफ्लो ऑर्केस्ट्रेशन से एमएल पाइपलाइन में इनपुट के रूप में आपूर्ति किए जाते हैं।
परिणाम: मॉडल निर्माण और परिनियोजन के लिए एक तेज़ और कुशल दृष्टिकोण
AWS के सहयोग से प्रोटोटाइप के परिणामस्वरूप वर्तमान सर्वोत्तम प्रथाओं का पालन करते हुए एक MLOps टेम्पलेट तैयार हुआ है जो अब Axfood की सभी डेटा विज्ञान टीमों के उपयोग के लिए उपलब्ध है। सेजमेकर स्टूडियो के भीतर एक नया सेजमेकर प्रोजेक्ट बनाकर, डेटा वैज्ञानिक नई एमएल परियोजनाओं पर जल्दी और निर्बाध रूप से उत्पादन शुरू कर सकते हैं, जिससे अधिक कुशल समय प्रबंधन की अनुमति मिलती है। यह टेम्पलेट के भाग के रूप में थकाऊ, दोहराए जाने वाले एमएलओपीएस कार्यों को स्वचालित करके संभव बनाया गया है।
इसके अलावा, हमारे एमएल सेटअप में स्वचालित तरीके से कई नई कार्यक्षमताएँ जोड़ी गई हैं। इन लाभों में शामिल हैं:
- मॉडल की निगरानी - हम मॉडल और डेटा गुणवत्ता के साथ-साथ मॉडल की व्याख्या के लिए ड्रिफ्ट जांच कर सकते हैं
- मॉडल और डेटा वंश - अब यह पता लगाना संभव है कि किस मॉडल के लिए कौन सा डेटा उपयोग किया गया है
- मॉडल रजिस्ट्री - यह हमें उत्पादन के लिए मॉडलों को सूचीबद्ध करने और मॉडल संस्करणों को प्रबंधित करने में मदद करता है
निष्कर्ष
इस पोस्ट में, हमने चर्चा की कि कैसे Axfood ने AWS विशेषज्ञों के सहयोग से और SageMaker और इसके संबंधित उत्पादों का उपयोग करके हमारे मौजूदा AI और ML संचालन के संचालन और स्केलेबिलिटी में सुधार किया।
इन सुधारों से एक्सफ़ूड की डेटा विज्ञान टीमों को अधिक मानकीकृत तरीके से एमएल वर्कफ़्लो बनाने में मदद मिलेगी और उत्पादन में मॉडलों के विश्लेषण और निगरानी को बहुत सरल बनाया जाएगा - हमारी टीमों द्वारा निर्मित और रखरखाव किए गए एमएल मॉडल की गुणवत्ता सुनिश्चित होगी।
कृपया टिप्पणी अनुभाग में कोई प्रतिक्रिया या प्रश्न छोड़ें।
लेखक के बारे में
 डॉ. ब्योर्न ब्लोमक्विस्ट एक्सफूड एबी में एआई रणनीति के प्रमुख हैं। एक्सफ़ूड एबी में शामिल होने से पहले उन्होंने एक्सफ़ूड के एक भाग, डागाब में डेटा वैज्ञानिकों की एक टीम का नेतृत्व किया, जो पूरे स्वीडन में लोगों को अच्छा और टिकाऊ भोजन प्रदान करने के मिशन के साथ नवीन मशीन लर्निंग समाधान का निर्माण कर रही थी। स्वीडन के उत्तर में जन्मे और पले-बढ़े ब्योर्न अपने खाली समय में बर्फीले पहाड़ों और खुले समुद्रों में जाते हैं।
डॉ. ब्योर्न ब्लोमक्विस्ट एक्सफूड एबी में एआई रणनीति के प्रमुख हैं। एक्सफ़ूड एबी में शामिल होने से पहले उन्होंने एक्सफ़ूड के एक भाग, डागाब में डेटा वैज्ञानिकों की एक टीम का नेतृत्व किया, जो पूरे स्वीडन में लोगों को अच्छा और टिकाऊ भोजन प्रदान करने के मिशन के साथ नवीन मशीन लर्निंग समाधान का निर्माण कर रही थी। स्वीडन के उत्तर में जन्मे और पले-बढ़े ब्योर्न अपने खाली समय में बर्फीले पहाड़ों और खुले समुद्रों में जाते हैं।
 ऑस्कर क्लैंग दगाब में एनालिटिक्स विभाग में एक वरिष्ठ डेटा वैज्ञानिक हैं, जहां उन्हें एनालिटिक्स और मशीन लर्निंग के साथ काम करने में मजा आता है, उदाहरण के लिए आपूर्ति श्रृंखला संचालन का अनुकूलन, पूर्वानुमान मॉडल का निर्माण और हाल ही में, जेनएआई एप्लिकेशन। वह अधिक सुव्यवस्थित मशीन लर्निंग पाइपलाइन बनाने, दक्षता और स्केलेबिलिटी बढ़ाने के लिए प्रतिबद्ध है।
ऑस्कर क्लैंग दगाब में एनालिटिक्स विभाग में एक वरिष्ठ डेटा वैज्ञानिक हैं, जहां उन्हें एनालिटिक्स और मशीन लर्निंग के साथ काम करने में मजा आता है, उदाहरण के लिए आपूर्ति श्रृंखला संचालन का अनुकूलन, पूर्वानुमान मॉडल का निर्माण और हाल ही में, जेनएआई एप्लिकेशन। वह अधिक सुव्यवस्थित मशीन लर्निंग पाइपलाइन बनाने, दक्षता और स्केलेबिलिटी बढ़ाने के लिए प्रतिबद्ध है।
 पावेल मैस्लोव एनालिटिक प्लेटफ़ॉर्म टीम में एक वरिष्ठ DevOps और ML इंजीनियर हैं। पावेल के पास AWS प्लेटफॉर्म पर DevOps और ML/AI के डोमेन में फ्रेमवर्क, बुनियादी ढांचे और टूल के विकास का व्यापक अनुभव है। पावेल, एक्सफ़ूड में एमएल के भीतर मूलभूत क्षमता के निर्माण में प्रमुख खिलाड़ियों में से एक रहा है।
पावेल मैस्लोव एनालिटिक प्लेटफ़ॉर्म टीम में एक वरिष्ठ DevOps और ML इंजीनियर हैं। पावेल के पास AWS प्लेटफॉर्म पर DevOps और ML/AI के डोमेन में फ्रेमवर्क, बुनियादी ढांचे और टूल के विकास का व्यापक अनुभव है। पावेल, एक्सफ़ूड में एमएल के भीतर मूलभूत क्षमता के निर्माण में प्रमुख खिलाड़ियों में से एक रहा है।
 जोकिम बर्ग स्टॉकहोम स्वीडन में स्थित टीम लीड और प्रोडक्ट ओनर एनालिटिक प्लेटफॉर्म है। वह डेटा प्लेटफ़ॉर्म एंड DevOps/MLOps इंजीनियरों की एक टीम का नेतृत्व कर रहे हैं जो डेटा साइंस टीमों के लिए डेटा और एमएल प्लेटफ़ॉर्म प्रदान करता है। जोकिम के पास विभिन्न उद्योगों की वरिष्ठ विकास और वास्तुकला टीमों का नेतृत्व करने का कई वर्षों का अनुभव है।
जोकिम बर्ग स्टॉकहोम स्वीडन में स्थित टीम लीड और प्रोडक्ट ओनर एनालिटिक प्लेटफॉर्म है। वह डेटा प्लेटफ़ॉर्म एंड DevOps/MLOps इंजीनियरों की एक टीम का नेतृत्व कर रहे हैं जो डेटा साइंस टीमों के लिए डेटा और एमएल प्लेटफ़ॉर्म प्रदान करता है। जोकिम के पास विभिन्न उद्योगों की वरिष्ठ विकास और वास्तुकला टीमों का नेतृत्व करने का कई वर्षों का अनुभव है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/how-axfood-enables-accelerated-machine-learning-throughout-the-organization-using-amazon-sagemaker/

