विनिर्माण के उभरते परिदृश्य में, एआई और मशीन लर्निंग (एमएल) की परिवर्तनकारी शक्ति स्पष्ट है, जो एक डिजिटल क्रांति लाती है जो संचालन को सुव्यवस्थित करती है और उत्पादकता को बढ़ाती है। हालाँकि, यह प्रगति डेटा-संचालित समाधानों को नेविगेट करने वाले उद्यमों के लिए अद्वितीय चुनौतियाँ पेश करती है। औद्योगिक सुविधाएं बड़ी मात्रा में असंरचित डेटा से जूझती हैं, जो सेंसर, टेलीमेट्री सिस्टम और उत्पादन लाइनों में फैले उपकरणों से प्राप्त होती हैं। पूर्वानुमानित रखरखाव और विसंगति का पता लगाने जैसे अनुप्रयोगों के लिए वास्तविक समय डेटा महत्वपूर्ण है, फिर भी ऐसे समय श्रृंखला डेटा के साथ प्रत्येक औद्योगिक उपयोग के मामले के लिए कस्टम एमएल मॉडल विकसित करने के लिए डेटा वैज्ञानिकों से काफी समय और संसाधनों की आवश्यकता होती है, जिससे व्यापक रूप से अपनाने में बाधा आती है।
जनरेटिव एआई जैसे बड़े पूर्व-प्रशिक्षित फाउंडेशन मॉडल (एफएम) का उपयोग करना क्लाउड सरल पाठ संकेतों के आधार पर वार्तालाप पाठ से लेकर कंप्यूटर कोड तक विभिन्न प्रकार की सामग्री तेजी से उत्पन्न कर सकता है, जिसे कहा जाता है शून्य-शॉट संकेत. यह प्रत्येक उपयोग के मामले के लिए डेटा वैज्ञानिकों को मैन्युअल रूप से विशिष्ट एमएल मॉडल विकसित करने की आवश्यकता को समाप्त करता है, और इसलिए एआई पहुंच को लोकतांत्रिक बनाता है, जिससे छोटे निर्माताओं को भी लाभ होता है। कर्मचारी एआई-जनित अंतर्दृष्टि के माध्यम से उत्पादकता प्राप्त करते हैं, इंजीनियर सक्रिय रूप से विसंगतियों का पता लगा सकते हैं, आपूर्ति श्रृंखला प्रबंधक इन्वेंट्री का अनुकूलन कर सकते हैं, और संयंत्र नेतृत्व सूचित, डेटा-संचालित निर्णय लेता है।
फिर भी, स्टैंडअलोन एफएम को संदर्भ आकार की बाधाओं (आमतौर पर) के साथ जटिल औद्योगिक डेटा को संभालने में सीमाओं का सामना करना पड़ता है 200,000 से कम टोकन), जो चुनौतियां खड़ी करता है। इसे संबोधित करने के लिए, आप प्राकृतिक भाषा प्रश्नों (एनएलक्यू) के जवाब में कोड उत्पन्न करने की एफएम की क्षमता का उपयोग कर सकते हैं। एजेंटों को पसंद है पांडासाई इस कोड को उच्च-रिज़ॉल्यूशन समय श्रृंखला डेटा पर चलाना और एफएम का उपयोग करके त्रुटियों को संभालना, चलन में आता है। पांडासएआई एक पायथन लाइब्रेरी है जो लोकप्रिय डेटा विश्लेषण और हेरफेर उपकरण पांडा में जेनरेटिव एआई क्षमताओं को जोड़ती है।
हालाँकि, जटिल एनएलक्यू, जैसे समय श्रृंखला डेटा प्रोसेसिंग, बहु-स्तरीय एकत्रीकरण, और धुरी या संयुक्त तालिका संचालन, शून्य-शॉट प्रॉम्प्ट के साथ असंगत पायथन स्क्रिप्ट सटीकता उत्पन्न कर सकते हैं।
कोड जनरेशन सटीकता को बढ़ाने के लिए, हम गतिशील रूप से निर्माण का प्रस्ताव करते हैं मल्टी-शॉट संकेत एनएलक्यू के लिए. मल्टी-शॉट प्रॉम्प्टिंग, सटीकता और स्थिरता को बढ़ावा देते हुए, समान संकेतों के लिए वांछित आउटपुट के कई उदाहरण दिखाकर एफएम को अतिरिक्त संदर्भ प्रदान करता है। इस पोस्ट में, मल्टी-शॉट प्रॉम्प्ट को एक समान डेटा प्रकार (उदाहरण के लिए, इंटरनेट ऑफ थिंग्स उपकरणों से उच्च-रिज़ॉल्यूशन समय श्रृंखला डेटा) पर चलने वाले सफल पायथन कोड वाले एम्बेडिंग से पुनर्प्राप्त किया जाता है। गतिशील रूप से निर्मित मल्टी-शॉट प्रॉम्प्ट एफएम को सबसे प्रासंगिक संदर्भ प्रदान करता है, और उन्नत गणित गणना, समय श्रृंखला डेटा प्रोसेसिंग और डेटा संक्षिप्त समझ में एफएम की क्षमता को बढ़ाता है। यह बेहतर प्रतिक्रिया उद्यम श्रमिकों और परिचालन टीमों को डेटा के साथ जुड़ने, व्यापक डेटा विज्ञान कौशल की आवश्यकता के बिना अंतर्दृष्टि प्राप्त करने की सुविधा प्रदान करती है।
समय श्रृंखला डेटा विश्लेषण से परे, एफएम विभिन्न औद्योगिक अनुप्रयोगों में मूल्यवान साबित होते हैं। रखरखाव टीमें संपत्ति के स्वास्थ्य का आकलन करती हैं, तस्वीरें खींचती हैं अमेज़ॅन रेकग्निशन-आधारित कार्यक्षमता सारांश, और बुद्धिमान खोजों का उपयोग करके विसंगति मूल कारण विश्लेषण पुनर्प्राप्ति संवर्धित पीढ़ी (आरएजी)। इन वर्कफ़्लो को सरल बनाने के लिए, AWS ने शुरुआत की है अमेज़ॅन बेडरॉक, आपको अत्याधुनिक पूर्व-प्रशिक्षित एफएम जैसे जेनेरिक एआई अनुप्रयोगों को बनाने और स्केल करने में सक्षम बनाता है क्लाउड v2. साथ अमेज़ॅन बेडरॉक के लिए ज्ञानकोष, आप संयंत्र श्रमिकों के लिए अधिक सटीक विसंगति मूल कारण विश्लेषण प्रदान करने के लिए आरएजी विकास प्रक्रिया को सरल बना सकते हैं। हमारी पोस्ट अमेज़ॅन बेडरॉक द्वारा संचालित औद्योगिक उपयोग के मामलों के लिए एक बुद्धिमान सहायक को प्रदर्शित करती है, जो एनएलक्यू चुनौतियों का समाधान करती है, छवियों से आंशिक सारांश तैयार करती है, और आरएजी दृष्टिकोण के माध्यम से उपकरण निदान के लिए एफएम प्रतिक्रियाओं को बढ़ाती है।
समाधान अवलोकन
निम्नलिखित चित्र समाधान वास्तुकला को दर्शाता है।

वर्कफ़्लो में तीन अलग-अलग उपयोग के मामले शामिल हैं:
केस 1 का उपयोग करें: समय श्रृंखला डेटा के साथ एनएलक्यू
समय श्रृंखला डेटा के साथ एनएलक्यू के वर्कफ़्लो में निम्नलिखित चरण शामिल हैं:
- हम विसंगति का पता लगाने के लिए एमएल क्षमताओं के साथ एक स्थिति निगरानी प्रणाली का उपयोग करते हैं, जैसे अमेज़न मोनिट्रोन, औद्योगिक उपकरणों के स्वास्थ्य की निगरानी करना। अमेज़ॅन मोनिट्रॉन उपकरण के कंपन और तापमान माप से संभावित उपकरण विफलताओं का पता लगाने में सक्षम है।
- हम प्रसंस्करण द्वारा समय श्रृंखला डेटा एकत्र करते हैं अमेज़न मोनिट्रोन के माध्यम से डेटा अमेज़न Kinesis डेटा स्ट्रीम और अमेज़ॅन डेटा फ़ायरहोज़, इसे सारणीबद्ध सीएसवी प्रारूप में परिवर्तित करना और इसे एक में सहेजना अमेज़न सरल भंडारण सेवा (अमेज़न S3) बाल्टी।
- अंतिम-उपयोगकर्ता स्ट्रीमलिट ऐप पर प्राकृतिक भाषा क्वेरी भेजकर अमेज़ॅन एस 3 में अपने समय श्रृंखला डेटा के साथ चैट करना शुरू कर सकता है।
- स्ट्रीमलिट ऐप उपयोगकर्ता के प्रश्नों को अग्रेषित करता है अमेज़ॅन बेडरॉक टाइटन टेक्स्ट एम्बेडिंग मॉडल इस क्वेरी को एम्बेड करने के लिए, और एक के भीतर एक समानता खोज करता है अमेज़न ओपन सर्च सर्विस सूचकांक, जिसमें पूर्व एनएलक्यू और उदाहरण कोड शामिल हैं।
- समानता खोज के बाद, एनएलक्यू प्रश्न, डेटा स्कीमा और पायथन कोड सहित शीर्ष समान उदाहरण, एक कस्टम प्रॉम्प्ट में डाले जाते हैं।
- PandasAI इस कस्टम प्रॉम्प्ट को अमेज़न बेडरॉक क्लाउड v2 मॉडल पर भेजता है।
- ऐप Amazon बेडरॉक क्लाउड v2 मॉडल के साथ इंटरैक्ट करने के लिए PandasAI एजेंट का उपयोग करता है, जो Amazon Monitron डेटा विश्लेषण और NLQ प्रतिक्रियाओं के लिए पायथन कोड तैयार करता है।
- अमेज़ॅन बेडरॉक क्लाउड v2 मॉडल द्वारा पायथन कोड लौटाने के बाद, PandasAI ऐप से अपलोड किए गए अमेज़ॅन मोनिट्रॉन डेटा पर पायथन क्वेरी चलाता है, कोड आउटपुट एकत्र करता है और असफल रन के लिए किसी भी आवश्यक पुनर्प्रयास को संबोधित करता है।
- स्ट्रीमलिट ऐप PandasAI के माध्यम से प्रतिक्रिया एकत्र करता है, और उपयोगकर्ताओं को आउटपुट प्रदान करता है। यदि आउटपुट संतोषजनक है, तो उपयोगकर्ता ओपनसर्च सेवा में एनएलक्यू और क्लाउड-जनरेटेड पायथन कोड को सहेजकर इसे सहायक के रूप में चिह्नित कर सकता है।
केस 2 का उपयोग करें: ख़राब हिस्सों का सारांश जनरेशन
हमारे सारांश पीढ़ी उपयोग मामले में निम्नलिखित चरण शामिल हैं:
- उपयोगकर्ता को यह पता चलने के बाद कि कौन सी औद्योगिक संपत्ति असामान्य व्यवहार दिखाती है, वे इसकी तकनीकी विशिष्टता और संचालन स्थिति के अनुसार यह पहचानने के लिए खराबी वाले हिस्से की छवियां अपलोड कर सकते हैं कि इस हिस्से में शारीरिक रूप से कुछ गड़बड़ है या नहीं।
- उपयोगकर्ता का उपयोग कर सकते हैं अमेज़ॅन रिकॉग्निशन डिटेक्टटेक्स्ट एपीआई इन छवियों से टेक्स्ट डेटा निकालने के लिए।
- निकाले गए टेक्स्ट डेटा को अमेज़ॅन बेडरॉक क्लाउड v2 मॉडल के प्रॉम्प्ट में शामिल किया गया है, जो मॉडल को खराबी वाले भाग का 200-शब्द सारांश उत्पन्न करने में सक्षम बनाता है। उपयोगकर्ता इस जानकारी का उपयोग भाग का आगे निरीक्षण करने के लिए कर सकता है।
केस 3 का उपयोग करें: मूल कारण निदान
हमारे मूल कारण निदान उपयोग मामले में निम्नलिखित चरण शामिल हैं:
- उपयोगकर्ता खराब परिसंपत्तियों से संबंधित विभिन्न दस्तावेज़ प्रारूपों (पीडीएफ, TXT, और इसी तरह) में एंटरप्राइज़ डेटा प्राप्त करता है, और उन्हें S3 बकेट में अपलोड करता है।
- इन फ़ाइलों का एक ज्ञान आधार अमेज़ॅन बेडरॉक में टाइटन टेक्स्ट एम्बेडिंग मॉडल और एक डिफ़ॉल्ट ओपनसर्च सर्विस वेक्टर स्टोर के साथ तैयार किया जाता है।
- उपयोगकर्ता खराब उपकरणों के मूल कारण निदान से संबंधित प्रश्न पूछता है। उत्तर RAG दृष्टिकोण के साथ अमेज़ॅन बेडरॉक नॉलेज बेस के माध्यम से तैयार किए जाते हैं।
.. पूर्वापेक्षाएँ
इस पोस्ट का अनुसरण करने के लिए, आपको निम्नलिखित शर्तें पूरी करनी होंगी:
समाधान अवसंरचना परिनियोजित करें
अपने समाधान संसाधन स्थापित करने के लिए, निम्नलिखित चरणों को पूरा करें:
- तैनात करें एडब्ल्यूएस CloudFormation टेम्पलेट opensearchsagemaker.yml, जो एक ओपनसर्च सेवा संग्रह और सूचकांक बनाता है, अमेज़न SageMaker नोटबुक उदाहरण, और S3 बाल्टी। आप इस AWS CloudFormation स्टैक को इस प्रकार नाम दे सकते हैं:
genai-sagemaker. - JupyterLab में SageMaker नोटबुक इंस्टेंस खोलें। आपको निम्नलिखित मिलेगा गीथहब रेपो इस उदाहरण पर पहले ही डाउनलोड किया जा चुका है: औद्योगिक-संचालन-में-उत्पादक-एआई-की-क्षमता को अनलॉक करना.
- इस रिपॉजिटरी में निम्नलिखित निर्देशिका से नोटबुक चलाएँ: औद्योगिक-संचालन/SagemakerNotebook/nlq-vector-rag-embedding.ipynb-में-जनरेटिव-एआई-की-क्षमता को अनलॉक करना. यह नोटबुक की-वैल्यू जोड़े को स्टोर करने के लिए सेजमेकर नोटबुक का उपयोग करके ओपनसर्च सर्विस इंडेक्स को लोड करेगा मौजूदा 23 एनएलक्यू उदाहरण.
- डेटा फ़ोल्डर से दस्तावेज़ अपलोड करें एसेटपार्टडॉक GitHub रिपॉजिटरी में CloudFormation स्टैक आउटपुट में सूचीबद्ध S3 बकेट में।

इसके बाद, आप Amazon S3 में दस्तावेज़ों के लिए ज्ञान आधार बनाते हैं।
- अमेज़ॅन बेडरॉक कंसोल पर, चुनें नॉलेज बेस नेविगेशन फलक में
- चुनें ज्ञान का आधार बनाएं.
- के लिए ज्ञान आधार नाम, नाम डालें।
- के लिए रनटाइम भूमिका, चुनते हैं एक नई सेवा भूमिका बनाएं और उसका उपयोग करें.
- के लिए डेटा स्रोत का नाम, अपने डेटा स्रोत का नाम दर्ज करें।
- के लिए एस३ यूआरआई, बकेट का S3 पथ दर्ज करें जहां आपने मूल कारण दस्तावेज़ अपलोड किए हैं।
- चुनें अगला.
 टाइटन एंबेडिंग मॉडल स्वचालित रूप से चुना जाता है।
टाइटन एंबेडिंग मॉडल स्वचालित रूप से चुना जाता है। - चुनते हैं शीघ्रता से एक नया वेक्टर स्टोर बनाएं.
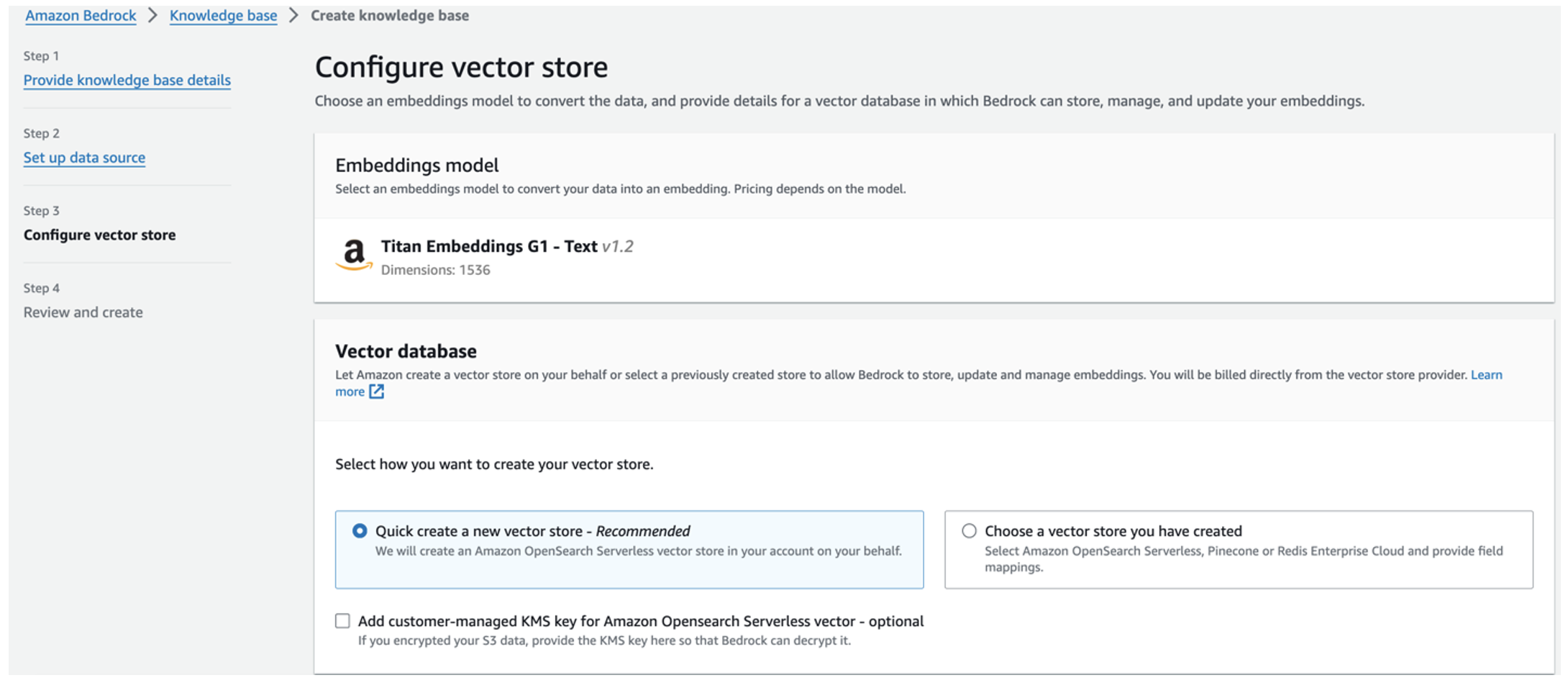
- अपनी सेटिंग्स की समीक्षा करें और चयन करके ज्ञान का आधार बनाएं ज्ञान का आधार बनाएं.
- ज्ञानकोष सफलतापूर्वक बन जाने के बाद, चुनें सिंक S3 बकेट को नॉलेज बेस के साथ सिंक करने के लिए।

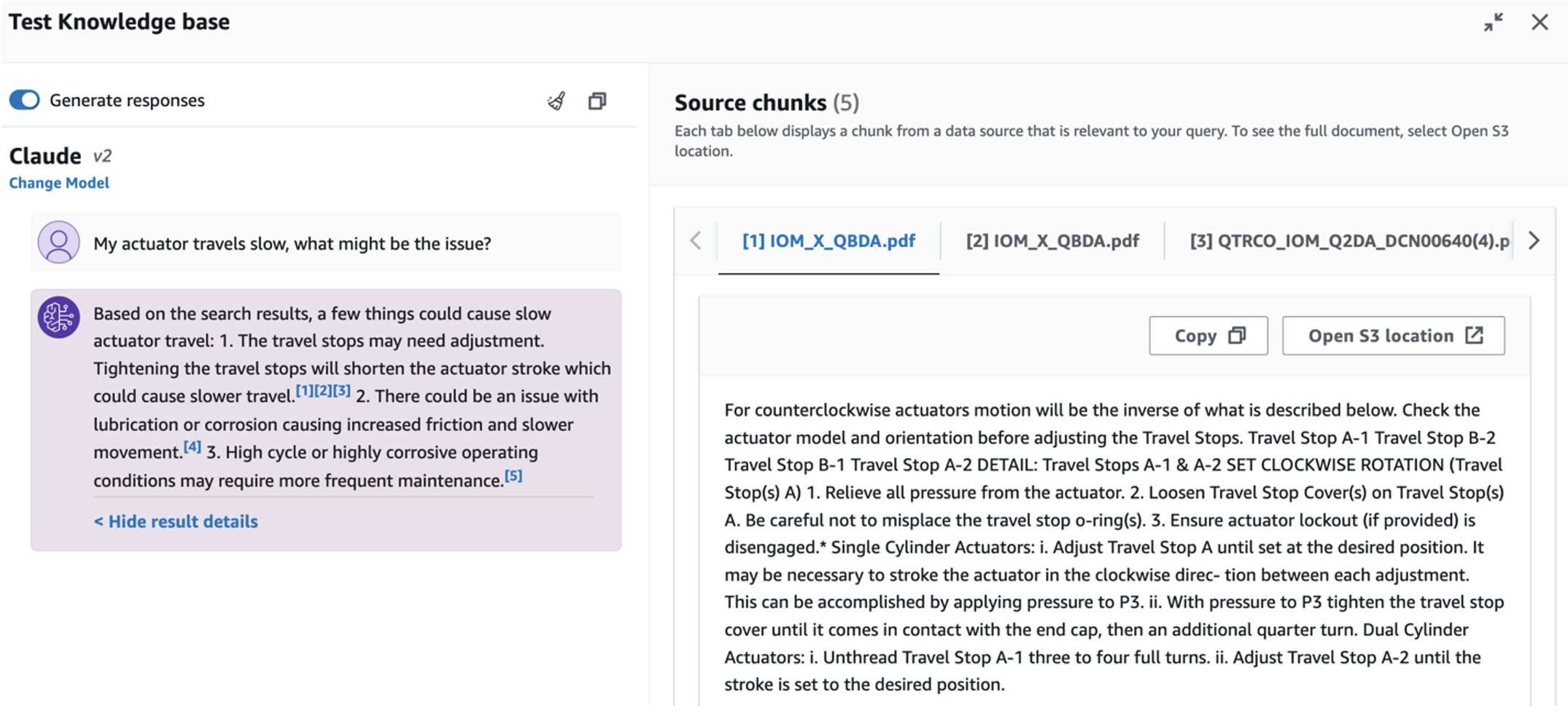
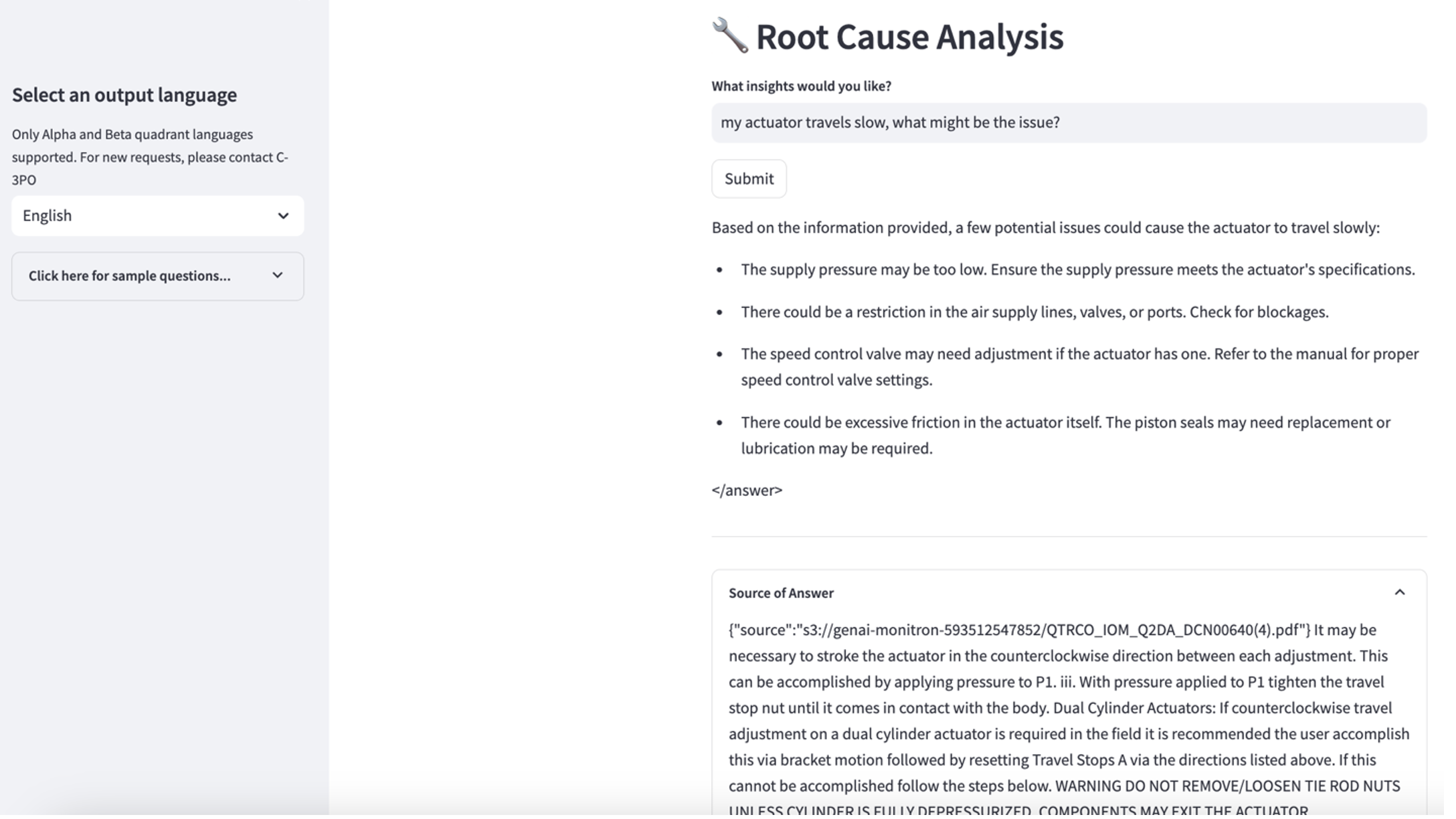
- ज्ञान आधार स्थापित करने के बाद, आप "मेरा एक्चुएटर धीमी गति से यात्रा करता है, समस्या क्या हो सकती है?" जैसे प्रश्न पूछकर मूल कारण निदान के लिए आरएजी दृष्टिकोण का परीक्षण कर सकते हैं।
अगला कदम आपके पीसी या ईसी2 इंस्टेंस (उबंटू सर्वर 22.04 एलटीएस) पर आवश्यक लाइब्रेरी पैकेज के साथ ऐप को तैनात करना है।
- अपने AWS क्रेडेंशियल सेट करें अपने स्थानीय पीसी पर AWS CLI के साथ। सरलता के लिए, आप उसी व्यवस्थापक भूमिका का उपयोग कर सकते हैं जिसका उपयोग आपने क्लाउडफ़ॉर्मेशन स्टैक को तैनात करने के लिए किया था। यदि आप Amazon EC2 का उपयोग कर रहे हैं, उदाहरण के लिए एक उपयुक्त IAM भूमिका संलग्न करें.
- क्लोन गीथहब रेपो:
- निर्देशिका को इसमें बदलें
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcऔर चलाने के लिएsetup.shलैंगचेन और पांडाएआई सहित आवश्यक पैकेज स्थापित करने के लिए इस फ़ोल्डर में स्क्रिप्ट:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - निम्न आदेश के साथ स्ट्रीमलिट ऐप चलाएँ:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
पिछले चरण में अमेज़ॅन बेडरॉक में आपके द्वारा बनाया गया ओपनसर्च सेवा संग्रह एआरएन प्रदान करें।
अपने परिसंपत्ति स्वास्थ्य सहायक से चैट करें
एंड-टू-एंड परिनियोजन पूरा करने के बाद, आप पोर्ट 8501 पर लोकलहोस्ट के माध्यम से ऐप तक पहुंच सकते हैं, जो वेब इंटरफ़ेस के साथ एक ब्राउज़र विंडो खोलता है। यदि आपने ऐप को EC2 इंस्टेंस पर तैनात किया है, सुरक्षा समूह इनबाउंड नियम के माध्यम से पोर्ट 8501 तक पहुंच की अनुमति दें. आप विभिन्न उपयोग मामलों के लिए अलग-अलग टैब पर नेविगेट कर सकते हैं।
उपयोग केस 1 का अन्वेषण करें
पहले उपयोग के मामले का पता लगाने के लिए, चुनें डेटा इनसाइट और चार्ट. अपना समय श्रृंखला डेटा अपलोड करके प्रारंभ करें। यदि आपके पास उपयोग करने के लिए मौजूदा समय श्रृंखला डेटा फ़ाइल नहीं है, तो आप निम्नलिखित अपलोड कर सकते हैं नमूना सीएसवी फ़ाइल अनाम Amazon Monitron प्रोजेक्ट डेटा के साथ। यदि आपके पास पहले से ही अमेज़ॅन मोनिट्रॉन प्रोजेक्ट है, तो देखें Amazon Monitron और Amazon Kinesis के साथ पूर्वानुमानित रखरखाव प्रबंधन के लिए कार्रवाई योग्य अंतर्दृष्टि उत्पन्न करें अपने Amazon Monitron डेटा को Amazon S3 पर स्ट्रीम करने और इस एप्लिकेशन के साथ अपने डेटा का उपयोग करने के लिए।
जब अपलोड पूरा हो जाए, तो अपने डेटा के साथ बातचीत शुरू करने के लिए एक क्वेरी दर्ज करें। बायां साइडबार आपकी सुविधा के लिए उदाहरण प्रश्नों की एक श्रृंखला प्रदान करता है। निम्नलिखित स्क्रीनशॉट एक प्रश्न इनपुट करते समय एफएम द्वारा उत्पन्न प्रतिक्रिया और पायथन कोड को दर्शाते हैं जैसे "मुझे क्रमशः चेतावनी या अलार्म के रूप में दिखाए गए प्रत्येक साइट के लिए सेंसर की अद्वितीय संख्या बताएं?" (एक कठिन स्तर का प्रश्न) या "सेंसर के लिए तापमान संकेत को स्वस्थ नहीं दिखाया गया है, क्या आप असामान्य कंपन संकेत दिखाने वाले प्रत्येक सेंसर के लिए दिनों में समय अवधि की गणना कर सकते हैं?" (एक चुनौती स्तर का प्रश्न)। ऐप आपके प्रश्न का उत्तर देगा, और ऐसे परिणाम उत्पन्न करने के लिए किए गए डेटा विश्लेषण की पायथन स्क्रिप्ट भी दिखाएगा।


यदि आप उत्तर से संतुष्ट हैं, तो आप इसे इस रूप में चिह्नित कर सकते हैं सहायक, एनएलक्यू और क्लाउड-जनरेटेड पायथन कोड को ओपनसर्च सर्विस इंडेक्स में सहेजना।

उपयोग केस 2 का अन्वेषण करें
दूसरे उपयोग के मामले का पता लगाने के लिए, चुनें कैप्चर की गई छवि सारांश स्ट्रीमलिट ऐप में टैब। आप अपनी औद्योगिक संपत्ति की एक छवि अपलोड कर सकते हैं, और एप्लिकेशन छवि जानकारी के आधार पर इसके तकनीकी विनिर्देश और संचालन की स्थिति का 200 शब्दों का सारांश तैयार करेगा। निम्नलिखित स्क्रीनशॉट बेल्ट मोटर ड्राइव की छवि से उत्पन्न सारांश दिखाता है। इस सुविधा का परीक्षण करने के लिए, यदि आपके पास उपयुक्त छवि नहीं है, तो आप निम्नलिखित का उपयोग कर सकते हैं उदाहरण छवि.
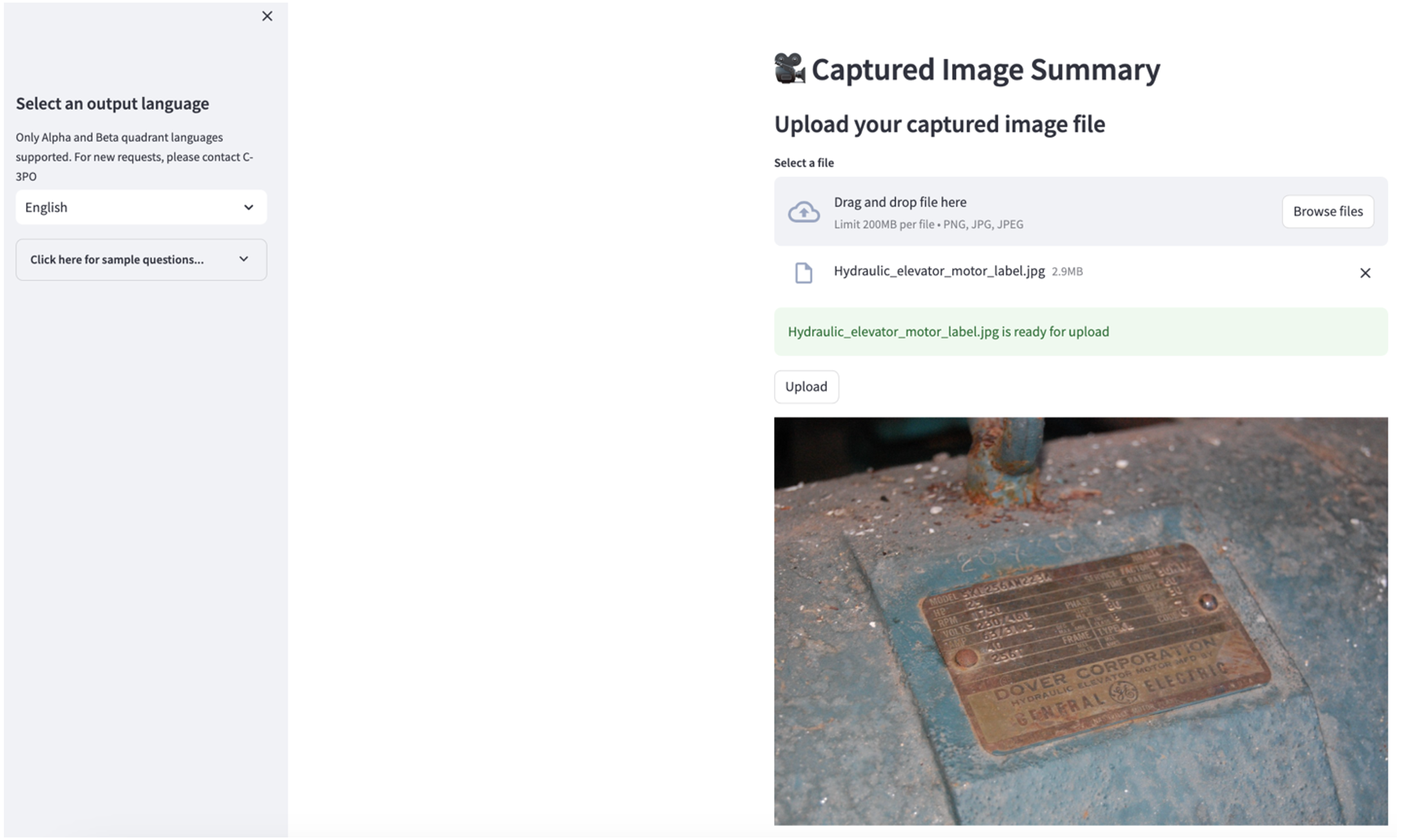
हाइड्रोलिक लिफ्ट मोटर लेबलक्लेरेंस रिशर के तहत लाइसेंस प्राप्त है सीसी द्वारा एसए 2.0.

उपयोग केस 3 का अन्वेषण करें
तीसरे उपयोग के मामले का पता लगाने के लिए, चुनें मूल कारण निदान टैब. अपनी टूटी हुई औद्योगिक संपत्ति से संबंधित एक प्रश्न इनपुट करें, जैसे, "मेरा एक्चुएटर धीमी गति से चलता है, क्या समस्या हो सकती है?" जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है, एप्लिकेशन उत्तर उत्पन्न करने के लिए उपयोग किए गए स्रोत दस्तावेज़ अंश के साथ प्रतिक्रिया देता है।
केस 1 का उपयोग करें: डिज़ाइन विवरण
इस अनुभाग में, हम पहले उपयोग के मामले के लिए एप्लिकेशन वर्कफ़्लो के डिज़ाइन विवरण पर चर्चा करते हैं।
कस्टम प्रॉम्प्ट बिल्डिंग
उपयोगकर्ता की प्राकृतिक भाषा क्वेरी विभिन्न कठिन स्तरों के साथ आती है: आसान, कठिन और चुनौती।
सीधे प्रश्नों में निम्नलिखित अनुरोध शामिल हो सकते हैं:
- अद्वितीय मान चुनें
- कुल संख्याएँ गिनें
- मानों को क्रमबद्ध करें
इन सवालों के लिए, प्रोसेसिंग के लिए पायथन स्क्रिप्ट तैयार करने के लिए PandasAI सीधे एफएम के साथ बातचीत कर सकता है।
कठिन प्रश्नों के लिए बुनियादी एकत्रीकरण संचालन या समय श्रृंखला विश्लेषण की आवश्यकता होती है, जैसे कि निम्नलिखित:
- पहले मान चुनें और परिणामों को श्रेणीबद्ध तरीके से समूहित करें
- प्रारंभिक रिकॉर्ड चयन के बाद आँकड़े निष्पादित करें
- टाइमस्टैम्प गिनती (उदाहरण के लिए, न्यूनतम और अधिकतम)
कठिन प्रश्नों के लिए, विस्तृत चरण-दर-चरण निर्देशों वाला एक त्वरित टेम्पलेट एफएम को सटीक प्रतिक्रिया प्रदान करने में सहायता करता है।
चुनौती-स्तर के प्रश्नों के लिए उन्नत गणित गणना और समय श्रृंखला प्रसंस्करण की आवश्यकता होती है, जैसे कि निम्नलिखित:
- प्रत्येक सेंसर के लिए विसंगति अवधि की गणना करें
- मासिक आधार पर साइट के लिए विसंगति सेंसर की गणना करें
- सामान्य संचालन और असामान्य परिस्थितियों में सेंसर रीडिंग की तुलना करें
इन प्रश्नों के लिए, आप प्रतिक्रिया सटीकता बढ़ाने के लिए कस्टम प्रॉम्प्ट में मल्टी-शॉट्स का उपयोग कर सकते हैं। ऐसे मल्टी-शॉट्स उन्नत समय श्रृंखला प्रसंस्करण और गणित गणना के उदाहरण दिखाते हैं, और एफएम को समान विश्लेषण पर प्रासंगिक अनुमान लगाने के लिए संदर्भ प्रदान करेंगे। एनएलक्यू प्रश्न बैंक से सबसे प्रासंगिक उदाहरणों को गतिशील रूप से प्रॉम्प्ट में सम्मिलित करना एक चुनौती हो सकती है। एक समाधान मौजूदा एनएलक्यू प्रश्न नमूनों से एम्बेडिंग का निर्माण करना और इन एम्बेडिंग को ओपनसर्च सर्विस जैसे वेक्टर स्टोर में सहेजना है। जब कोई प्रश्न स्ट्रीमलिट ऐप पर भेजा जाता है, तो प्रश्न को वेक्टरकृत किया जाएगा बेडरॉकएम्बेडिंग्स. उस प्रश्न के लिए शीर्ष एन सबसे प्रासंगिक एम्बेडिंग का उपयोग करके पुनर्प्राप्त किया जाता है opensearch_vector_search.similarity_search और मल्टी-शॉट प्रॉम्प्ट के रूप में प्रॉम्प्ट टेम्पलेट में डाला गया।
निम्न आरेख इस वर्कफ़्लो को दिखाता है।
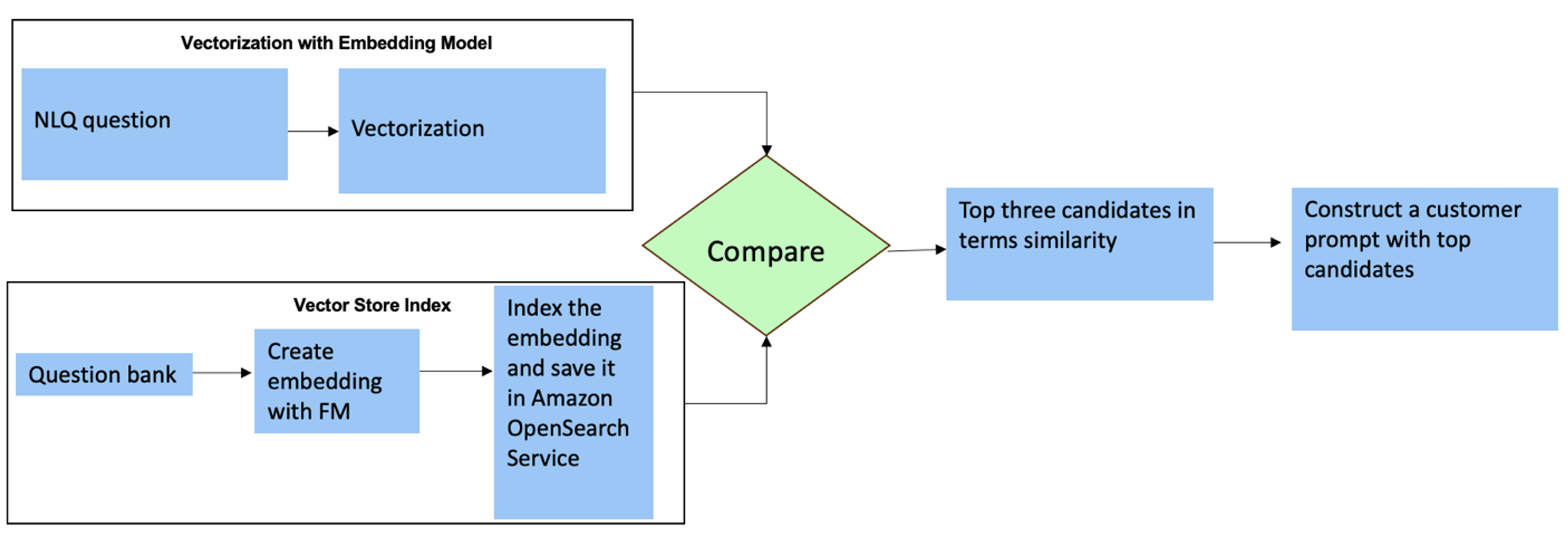
एम्बेडिंग परत का निर्माण तीन प्रमुख उपकरणों का उपयोग करके किया जाता है:
- एंबेडिंग मॉडल - हम अमेज़ॅन बेडरॉक के माध्यम से उपलब्ध अमेज़ॅन टाइटन एंबेडिंग का उपयोग करते हैं (amazon.titan-embed-text-v1) पाठ्य दस्तावेजों का संख्यात्मक प्रतिनिधित्व उत्पन्न करना।
- वेक्टर स्टोर - हमारे वेक्टर स्टोर के लिए, हम इस नोटबुक में एनएलक्यू उदाहरणों से उत्पन्न एम्बेडिंग के भंडारण को सुव्यवस्थित करते हुए, लैंगचेन फ्रेमवर्क के माध्यम से ओपनसर्च सेवा का उपयोग करते हैं।
- सूची - ओपनसर्च सर्विस इंडेक्स इनपुट एम्बेडिंग की तुलना दस्तावेज़ एम्बेडिंग से करने और प्रासंगिक दस्तावेज़ों की पुनर्प्राप्ति को सुविधाजनक बनाने में महत्वपूर्ण भूमिका निभाता है। चूँकि Python उदाहरण कोड JSON फ़ाइल के रूप में सहेजे गए थे, उन्हें OpenSearch सेवा में वैक्टर के माध्यम से अनुक्रमित किया गया था OpenSearchVevtorSearch.fromtexts एपीआई कॉल।
स्ट्रीमलिट के माध्यम से मानव-लेखापरीक्षित उदाहरणों का निरंतर संग्रह
ऐप विकास की शुरुआत में, हमने ओपनसर्च सर्विस इंडेक्स में एम्बेडिंग के रूप में केवल 23 सहेजे गए उदाहरणों के साथ शुरुआत की। जैसे ही ऐप फ़ील्ड में लाइव होता है, उपयोगकर्ता ऐप के माध्यम से अपने एनएलक्यू इनपुट करना शुरू कर देते हैं। हालाँकि, टेम्प्लेट में उपलब्ध सीमित उदाहरणों के कारण, कुछ एनएलक्यू को समान संकेत नहीं मिल सकते हैं। इन एम्बेडिंग को लगातार समृद्ध करने और अधिक प्रासंगिक उपयोगकर्ता संकेत प्रदान करने के लिए, आप मानव-लेखापरीक्षित उदाहरण एकत्र करने के लिए स्ट्रीमलिट ऐप का उपयोग कर सकते हैं।
ऐप के भीतर, निम्नलिखित फ़ंक्शन इस उद्देश्य को पूरा करता है। जब अंतिम उपयोगकर्ताओं को आउटपुट उपयोगी लगे और चयन करें सहायक, एप्लिकेशन इन चरणों का पालन करता है:
- पायथन स्क्रिप्ट एकत्र करने के लिए PandasAI से कॉलबैक विधि का उपयोग करें।
- पायथन स्क्रिप्ट, इनपुट प्रश्न और सीएसवी मेटाडेटा को एक स्ट्रिंग में पुन: स्वरूपित करें।
- जांचें कि क्या यह एनएलक्यू उदाहरण मौजूदा ओपनसर्च सर्विस इंडेक्स में पहले से मौजूद है opensearch_vector_search.similarity_search_with_score.
- यदि कोई समान उदाहरण नहीं है, तो इस एनएलक्यू को ओपनसर्च सर्विस इंडेक्स का उपयोग करके जोड़ा जाता है opensearch_vector_search.add_texts.
उस स्थिति में जब कोई उपयोगकर्ता चयन करता है अनुपयोगी, कोई कार्यवाही नहीं की जाती। यह पुनरावृत्तीय प्रक्रिया यह सुनिश्चित करती है कि उपयोगकर्ता द्वारा योगदान किए गए उदाहरणों को शामिल करके सिस्टम में लगातार सुधार होता रहे।
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
मानव ऑडिटिंग को शामिल करने से, जैसे-जैसे ऐप का उपयोग बढ़ता है, त्वरित एम्बेडिंग के लिए ओपनसर्च सेवा में उपलब्ध उदाहरणों की मात्रा बढ़ती जाती है। इस विस्तारित एम्बेडिंग डेटासेट के परिणामस्वरूप समय के साथ खोज सटीकता में वृद्धि हुई है। विशेष रूप से, चुनौतीपूर्ण एनएलक्यू के लिए, प्रत्येक एनएलक्यू प्रश्न के लिए कस्टम संकेत बनाने के लिए गतिशील रूप से समान उदाहरण डालने पर एफएम की प्रतिक्रिया सटीकता लगभग 90% तक पहुंच जाती है। यह मल्टी-शॉट संकेतों के बिना परिदृश्यों की तुलना में उल्लेखनीय 28% वृद्धि दर्शाता है।
केस 2 का उपयोग करें: डिज़ाइन विवरण
स्ट्रीमलिट ऐप पर कैप्चर की गई छवि सारांश टैब, आप सीधे एक छवि फ़ाइल अपलोड कर सकते हैं। यह अमेज़ॅन रिकॉग्निशन एपीआई आरंभ करता है (डिटेक्ट_टेक्स्ट एपीआई), मशीन विनिर्देशों का विवरण देने वाली छवि लेबल से पाठ निकालना। इसके बाद, निकाले गए टेक्स्ट डेटा को प्रॉम्प्ट के संदर्भ के रूप में अमेज़ॅन बेडरॉक क्लाउड मॉडल पर भेजा जाता है, जिसके परिणामस्वरूप 200 शब्दों का सारांश मिलता है।
उपयोगकर्ता अनुभव के नजरिए से, पाठ सारांशीकरण कार्य के लिए स्ट्रीमिंग कार्यक्षमता को सक्षम करना सर्वोपरि है, जिससे उपयोगकर्ता पूरे आउटपुट की प्रतीक्षा करने के बजाय एफएम-जनरेटेड सारांश को छोटे टुकड़ों में पढ़ सकते हैं। अमेज़ॅन बेडरॉक अपने एपीआई के माध्यम से स्ट्रीमिंग की सुविधा प्रदान करता है (बेडरॉक_रनटाइम.इनवोक_मॉडल_विथ_रेस्पॉन्स_स्ट्रीम).
केस 3 का उपयोग करें: डिज़ाइन विवरण
इस परिदृश्य में, हमने RAG दृष्टिकोण को नियोजित करते हुए मूल कारण विश्लेषण पर केंद्रित एक चैटबॉट एप्लिकेशन विकसित किया है। यह चैटबॉट मूल कारण विश्लेषण की सुविधा के लिए असर उपकरण से संबंधित कई दस्तावेज़ों का उपयोग करता है। यह आरएजी-आधारित मूल कारण विश्लेषण चैटबॉट वेक्टर टेक्स्ट अभ्यावेदन, या एम्बेडिंग उत्पन्न करने के लिए ज्ञान आधार का उपयोग करता है। अमेज़ॅन बेडरॉक के लिए नॉलेज बेस एक पूरी तरह से प्रबंधित क्षमता है जो आपको डेटा स्रोतों में कस्टम एकीकरण बनाने या डेटा प्रवाह और आरएजी कार्यान्वयन विवरण प्रबंधित किए बिना, अंतर्ग्रहण से पुनर्प्राप्ति और त्वरित वृद्धि तक संपूर्ण आरएजी वर्कफ़्लो को लागू करने में मदद करता है।
जब आप अमेज़ॅन बेडरॉक से नॉलेज बेस प्रतिक्रिया से संतुष्ट हो जाते हैं, तो आप नॉलेज बेस से मूल कारण प्रतिक्रिया को स्ट्रीमलिट ऐप में एकीकृत कर सकते हैं।
क्लीन अप
लागत बचाने के लिए, इस पोस्ट में आपके द्वारा बनाए गए संसाधनों को हटा दें:
- अमेज़ॅन बेडरॉक से ज्ञानकोष हटाएं।
- ओपनसर्च सर्विस इंडेक्स हटाएं।
- जेनाई-सेजमेकर क्लाउडफॉर्मेशन स्टैक हटाएं।
- यदि आपने स्ट्रीमलिट ऐप चलाने के लिए EC2 इंस्टेंस का उपयोग किया है तो EC2 इंस्टेंस को रोकें।
निष्कर्ष
जनरेटिव एआई अनुप्रयोगों ने पहले ही विभिन्न व्यावसायिक प्रक्रियाओं को बदल दिया है, श्रमिक उत्पादकता और कौशल सेट को बढ़ाया है। हालाँकि, समय श्रृंखला डेटा विश्लेषण को संभालने में एफएम की सीमाओं ने औद्योगिक ग्राहकों द्वारा उनके पूर्ण उपयोग में बाधा उत्पन्न की है। इस बाधा ने दैनिक रूप से संसाधित होने वाले प्रमुख डेटा प्रकार के लिए जेनरेटिव एआई के अनुप्रयोग को बाधित कर दिया है।
इस पोस्ट में, हमने औद्योगिक उपयोगकर्ताओं के लिए इस चुनौती को कम करने के लिए डिज़ाइन किया गया एक जेनरेटिव एआई एप्लिकेशन समाधान पेश किया है। यह एप्लिकेशन एफएम की समय श्रृंखला विश्लेषण क्षमता को मजबूत करने के लिए एक ओपन सोर्स एजेंट, पांडाएआई का उपयोग करता है। समय श्रृंखला डेटा को सीधे एफएम पर भेजने के बजाय, ऐप असंरचित समय श्रृंखला डेटा के विश्लेषण के लिए पायथन कोड उत्पन्न करने के लिए पांडाएआई का उपयोग करता है। पायथन कोड जेनरेशन की सटीकता बढ़ाने के लिए, मानव ऑडिटिंग के साथ एक कस्टम प्रॉम्प्ट जेनरेशन वर्कफ़्लो लागू किया गया है।
अपनी संपत्ति के स्वास्थ्य के बारे में अंतर्दृष्टि से सशक्त होकर, औद्योगिक श्रमिक मूल कारण निदान और आंशिक प्रतिस्थापन योजना सहित विभिन्न उपयोग के मामलों में जेनेरिक एआई की क्षमता का पूरी तरह से उपयोग कर सकते हैं। अमेज़ॅन बेडरॉक के लिए नॉलेज बेस के साथ, डेवलपर्स के लिए आरएजी समाधान बनाना और प्रबंधित करना सीधा है।
एंटरप्राइज़ डेटा प्रबंधन और संचालन का प्रक्षेप पथ परिचालन स्वास्थ्य में व्यापक अंतर्दृष्टि के लिए जेनरेटर एआई के साथ गहन एकीकरण की ओर बढ़ रहा है। अमेज़ॅन बेडरॉक के नेतृत्व में यह बदलाव, एलएलएम की बढ़ती मजबूती और क्षमता से काफी बढ़ गया है अमेज़न बेडरॉक क्लाउड 3 समाधानों को और उन्नत करने के लिए। अधिक जानने के लिए, परामर्श पर जाएँ अमेज़ॅन बेडरॉक दस्तावेज़ीकरण, और इससे रूबरू हों अमेज़ॅन बेडरॉक कार्यशाला.
लेखक के बारे में
 जूलिया हू अमेज़ॅन वेब सर्विसेज में एक सीनियर एआई/एमएल सॉल्यूशंस आर्किटेक्ट हैं। वह जेनरेटिव एआई, एप्लाइड डेटा साइंस और आईओटी आर्किटेक्चर में विशेषज्ञता रखती हैं। वर्तमान में वह अमेज़ॅन क्यू टीम का हिस्सा हैं, और मशीन लर्निंग टेक्निकल फील्ड कम्युनिटी में एक सक्रिय सदस्य/संरक्षक हैं। वह AWSome जेनरेटिव AI समाधान विकसित करने के लिए स्टार्ट-अप से लेकर उद्यमों तक के ग्राहकों के साथ काम करती है। वह विशेष रूप से उन्नत डेटा विश्लेषण के लिए बड़े भाषा मॉडल का लाभ उठाने और वास्तविक दुनिया की चुनौतियों का समाधान करने वाले व्यावहारिक अनुप्रयोगों की खोज करने को लेकर उत्साहित हैं।
जूलिया हू अमेज़ॅन वेब सर्विसेज में एक सीनियर एआई/एमएल सॉल्यूशंस आर्किटेक्ट हैं। वह जेनरेटिव एआई, एप्लाइड डेटा साइंस और आईओटी आर्किटेक्चर में विशेषज्ञता रखती हैं। वर्तमान में वह अमेज़ॅन क्यू टीम का हिस्सा हैं, और मशीन लर्निंग टेक्निकल फील्ड कम्युनिटी में एक सक्रिय सदस्य/संरक्षक हैं। वह AWSome जेनरेटिव AI समाधान विकसित करने के लिए स्टार्ट-अप से लेकर उद्यमों तक के ग्राहकों के साथ काम करती है। वह विशेष रूप से उन्नत डेटा विश्लेषण के लिए बड़े भाषा मॉडल का लाभ उठाने और वास्तविक दुनिया की चुनौतियों का समाधान करने वाले व्यावहारिक अनुप्रयोगों की खोज करने को लेकर उत्साहित हैं।
 सुदेश शशिधरन ऊर्जा टीम के भीतर, AWS में एक वरिष्ठ समाधान वास्तुकार हैं। सुदेश को नई तकनीकों के साथ प्रयोग करना और जटिल व्यावसायिक चुनौतियों का समाधान करने वाले नवीन समाधान बनाना पसंद है। जब वह समाधान डिज़ाइन नहीं कर रहा होता है या नवीनतम तकनीकों के साथ छेड़छाड़ नहीं कर रहा होता है, तो आप उसे टेनिस कोर्ट पर अपने बैकहैंड पर काम करते हुए पा सकते हैं।
सुदेश शशिधरन ऊर्जा टीम के भीतर, AWS में एक वरिष्ठ समाधान वास्तुकार हैं। सुदेश को नई तकनीकों के साथ प्रयोग करना और जटिल व्यावसायिक चुनौतियों का समाधान करने वाले नवीन समाधान बनाना पसंद है। जब वह समाधान डिज़ाइन नहीं कर रहा होता है या नवीनतम तकनीकों के साथ छेड़छाड़ नहीं कर रहा होता है, तो आप उसे टेनिस कोर्ट पर अपने बैकहैंड पर काम करते हुए पा सकते हैं।
 नील देसाई आर्टिफिशियल इंटेलिजेंस (एआई), डेटा साइंस, सॉफ्टवेयर इंजीनियरिंग और एंटरप्राइज आर्किटेक्चर में 20 से अधिक वर्षों के अनुभव के साथ एक प्रौद्योगिकी कार्यकारी है। AWS में, वह विश्वव्यापी AI सेवा विशेषज्ञ समाधान आर्किटेक्ट्स की एक टीम का नेतृत्व करते हैं जो ग्राहकों को नवीन जेनरेटिव AI-संचालित समाधान बनाने, ग्राहकों के साथ सर्वोत्तम प्रथाओं को साझा करने और उत्पाद रोडमैप चलाने में मदद करते हैं। वेस्टास, हनीवेल और क्वेस्ट डायग्नोस्टिक्स में अपनी पिछली भूमिकाओं में, नील ने नवीन उत्पादों और सेवाओं को विकसित करने और लॉन्च करने में नेतृत्वकारी भूमिकाएँ निभाई हैं, जिससे कंपनियों को अपने संचालन में सुधार करने, लागत कम करने और राजस्व बढ़ाने में मदद मिली है। उन्हें वास्तविक दुनिया की समस्याओं को हल करने के लिए प्रौद्योगिकी का उपयोग करने का शौक है और वह सफलता के सिद्ध ट्रैक रिकॉर्ड वाले एक रणनीतिक विचारक हैं।
नील देसाई आर्टिफिशियल इंटेलिजेंस (एआई), डेटा साइंस, सॉफ्टवेयर इंजीनियरिंग और एंटरप्राइज आर्किटेक्चर में 20 से अधिक वर्षों के अनुभव के साथ एक प्रौद्योगिकी कार्यकारी है। AWS में, वह विश्वव्यापी AI सेवा विशेषज्ञ समाधान आर्किटेक्ट्स की एक टीम का नेतृत्व करते हैं जो ग्राहकों को नवीन जेनरेटिव AI-संचालित समाधान बनाने, ग्राहकों के साथ सर्वोत्तम प्रथाओं को साझा करने और उत्पाद रोडमैप चलाने में मदद करते हैं। वेस्टास, हनीवेल और क्वेस्ट डायग्नोस्टिक्स में अपनी पिछली भूमिकाओं में, नील ने नवीन उत्पादों और सेवाओं को विकसित करने और लॉन्च करने में नेतृत्वकारी भूमिकाएँ निभाई हैं, जिससे कंपनियों को अपने संचालन में सुधार करने, लागत कम करने और राजस्व बढ़ाने में मदद मिली है। उन्हें वास्तविक दुनिया की समस्याओं को हल करने के लिए प्रौद्योगिकी का उपयोग करने का शौक है और वह सफलता के सिद्ध ट्रैक रिकॉर्ड वाले एक रणनीतिक विचारक हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

