
लेखक द्वारा छवि
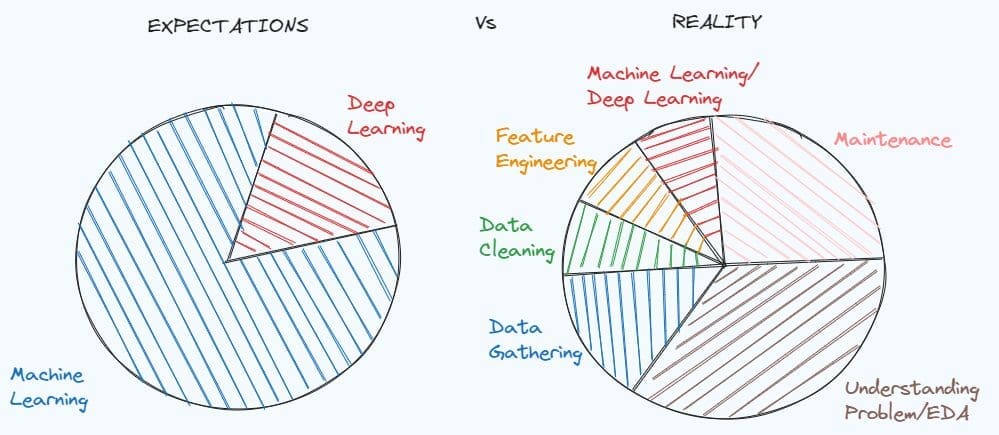
डेटा सूचित निर्णय लेने और आर्टिफिशियल इंटेलिजेंस आधारित अनुप्रयोगों को सक्षम करने में महत्वपूर्ण भूमिका निभाता है। परिणामस्वरूप, विभिन्न उद्योगों में कुशल डेटा पेशेवरों की मांग बढ़ रही है। यदि आप डेटा विज्ञान में नए हैं, तो गाइडों का यह व्यापक संग्रह आपको विशाल मात्रा में डेटा से अंतर्दृष्टि निकालने के लिए आवश्यक आवश्यक कौशल विकसित करने में मदद करने के लिए डिज़ाइन किया गया है।
लिंक: डेटा साइंस के लिए SQL में महारत हासिल करने के लिए 7 कदम

यह एसक्यूएल में महारत हासिल करने के लिए एक चरण-दर-चरण दृष्टिकोण है, जिसमें एसक्यूएल कमांड, एग्रीगेशन, ग्रुपिंग, सॉर्टिंग, जॉइन, सबक्वेरीज़ और विंडो फ़ंक्शंस की मूल बातें शामिल हैं।
गाइड तकनीकी विश्लेषणों में आवश्यकताओं का अनुवाद करके वास्तविक दुनिया की व्यावसायिक समस्याओं को हल करने के लिए एसक्यूएल का उपयोग करने के महत्व पर भी प्रकाश डालता है। डेटा विज्ञान साक्षात्कार के अभ्यास और तैयारी के लिए, यह हैकररैंक और पीजीएक्सरसाइज जैसे ऑनलाइन प्लेटफार्मों के माध्यम से एसक्यूएल का अभ्यास करने की सिफारिश करता है।
लिंक: डेटा साइंस के लिए पायथन में महारत हासिल करने के 7 कदम

यह मार्गदर्शिका पायथन प्रोग्रामिंग सीखने और डेटा साइंस और एनालिटिक्स में करियर के लिए आवश्यक कौशल विकसित करने के लिए चरण-दर-चरण रोडमैप प्रदान करती है। इसकी शुरुआत ऑनलाइन पाठ्यक्रमों और कोडिंग चुनौतियों के माध्यम से पायथन के बुनियादी सिद्धांतों को सीखने से होती है। फिर, यह डेटा विश्लेषण, मशीन लर्निंग और वेब स्क्रैपिंग के लिए पायथन लाइब्रेरी को कवर करता है।
करियर गाइड परियोजनाओं के माध्यम से कोडिंग का अभ्यास करने और अपने कौशल को प्रदर्शित करने के लिए एक ऑनलाइन पोर्टफोलियो बनाने के महत्व पर प्रकाश डालता है। यह प्रत्येक चरण के लिए निःशुल्क और सशुल्क संसाधन अनुशंसाएँ भी प्रदान करता है।
लिंक: डेटा सफ़ाई और प्रीप्रोसेसिंग तकनीकों में महारत हासिल करने के लिए 7 कदम
डेटा सफाई और प्रीप्रोसेसिंग तकनीकों में महारत हासिल करने के लिए चरण-दर-चरण मार्गदर्शिका, जो किसी भी डेटा विज्ञान परियोजनाओं का एक अनिवार्य हिस्सा है। गाइड में विभिन्न विषयों को शामिल किया गया है, जिसमें खोजपूर्ण डेटा विश्लेषण, लापता मूल्यों को संभालना, डुप्लिकेट और आउटलेर से निपटना, श्रेणीबद्ध विशेषताओं को एन्कोड करना, डेटा को प्रशिक्षण और परीक्षण सेट में विभाजित करना, फीचर स्केलिंग और वर्गीकरण समस्याओं में असंतुलित डेटा को संबोधित करना शामिल है।
आप पांडा और स्किकिट-लर्न जैसे पायथन पुस्तकालयों का उपयोग करके विभिन्न प्रीप्रोसेसिंग कार्यों के लिए उदाहरण कोड की सहायता से समस्या कथन और डेटा को समझने के महत्व को सीखेंगे।
लिंक: पांडा और पायथन के साथ डेटा विवाद में महारत हासिल करने के लिए 7 कदम

यह पांडा के साथ डेटा तकरार में महारत हासिल करने के लिए एक व्यापक शिक्षण पथ है। गाइड में पायथन फंडामेंटल्स, एसक्यूएल और वेब स्क्रैपिंग सीखने जैसी पूर्वापेक्षाएँ शामिल हैं, इसके बाद विभिन्न स्रोतों से डेटा लोड करने, डेटाफ़्रेम का चयन और फ़िल्टर करने, डेटासेट का पता लगाने और साफ़ करने, परिवर्तन और एकत्रीकरण करने, डेटाफ़्रेम में शामिल होने और पिवट टेबल बनाने के चरण शामिल हैं। अंत में, यह डेटा विश्लेषण कौशल दिखाने और परियोजनाओं का एक पोर्टफोलियो बनाने के लिए स्ट्रीमलिट का उपयोग करके एक इंटरैक्टिव डेटा डैशबोर्ड बनाने का सुझाव देता है, जो नौकरी के अवसरों की तलाश करने वाले इच्छुक डेटा विश्लेषकों के लिए आवश्यक है।
लिंक: खोजपूर्ण डेटा विश्लेषण में महारत हासिल करने के लिए 7 कदम
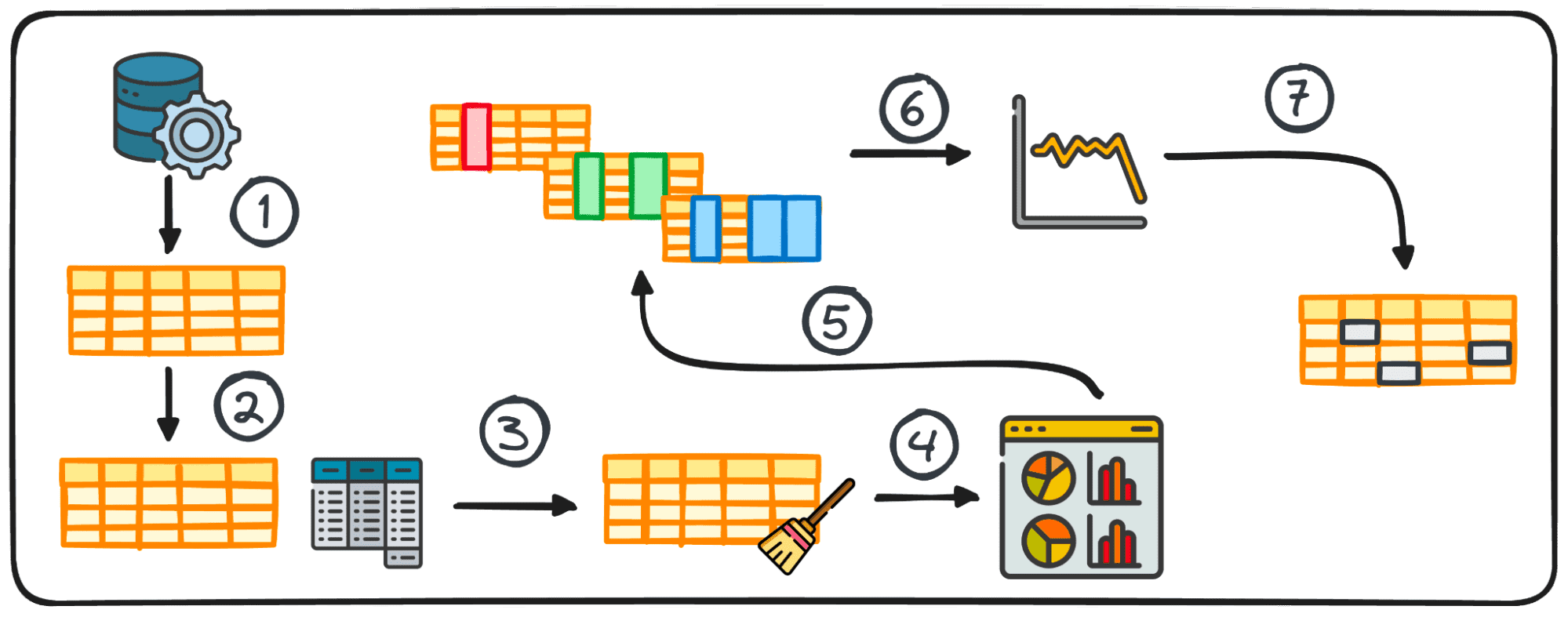
गाइड पायथन का उपयोग करके प्रभावी खोजपूर्ण डेटा विश्लेषण (ईडीए) करने के लिए 7 प्रमुख चरणों की रूपरेखा तैयार करता है। इन चरणों में डेटा संग्रह, सांख्यिकीय सारांश तैयार करना, सफाई और परिवर्तनों के माध्यम से डेटा तैयार करना, पैटर्न और आउटलेर्स की पहचान करने के लिए डेटा को विज़ुअलाइज़ करना, वेरिएबल्स का यूनीवेरिएट, बाइवेरिएट और मल्टीवेरिएट विश्लेषण करना, समय श्रृंखला डेटा का विश्लेषण करना और लापता मानों और आउटलेर्स से निपटना शामिल है। ईडीए डेटा विश्लेषण में एक महत्वपूर्ण चरण है, जो पेशेवरों को डेटा की गुणवत्ता, संरचना और संबंधों को समझने में सक्षम बनाता है, जिससे बाद के चरणों में सटीक और व्यावहारिक विश्लेषण सुनिश्चित होता है।
डेटा विज्ञान में अपनी यात्रा शुरू करने के लिए, SQL में महारत हासिल करने के साथ शुरुआत करने की अनुशंसा की जाती है। यह आपको डेटाबेस के साथ कुशलतापूर्वक काम करने की अनुमति देगा। एक बार जब आप SQL के साथ सहज हो जाते हैं, तो आप Python प्रोग्रामिंग में उतर सकते हैं, जो डेटा विश्लेषण के लिए शक्तिशाली लाइब्रेरी के साथ आता है। डेटा सफ़ाई जैसी आवश्यक तकनीकों को सीखना महत्वपूर्ण है, क्योंकि इससे आपको उच्च-गुणवत्ता वाले डेटासेट बनाए रखने में मदद मिलेगी।
फिर, अपने डेटा को नया आकार देने और तैयार करने के लिए पांडा के साथ डेटा तकरार में विशेषज्ञता हासिल करें। सबसे महत्वपूर्ण बात यह है कि डेटासेट को पूरी तरह से समझने और अंतर्दृष्टि को उजागर करने के लिए खोजपूर्ण डेटा विश्लेषण में महारत हासिल करें।
इन दिशानिर्देशों का पालन करने के बाद, अगला कदम किसी प्रोजेक्ट पर काम करना और अनुभव हासिल करना है। आप एक साधारण प्रोजेक्ट से शुरुआत कर सकते हैं और फिर अधिक जटिल प्रोजेक्ट पर आगे बढ़ सकते हैं। इसके बारे में मीडियम पर लिखें और अपने कौशल को बेहतर बनाने के लिए नवीनतम तकनीकों के बारे में जानें।
आबिद अली अवनी (@1अबिदलियावान) एक प्रमाणित डेटा वैज्ञानिक पेशेवर है जिसे मशीन लर्निंग मॉडल बनाना पसंद है। वर्तमान में, वह सामग्री निर्माण और मशीन लर्निंग और डेटा विज्ञान प्रौद्योगिकियों पर तकनीकी ब्लॉग लिखने पर ध्यान केंद्रित कर रहे हैं। आबिद के पास प्रौद्योगिकी प्रबंधन में मास्टर डिग्री और दूरसंचार इंजीनियरिंग में स्नातक की डिग्री है। उनका दृष्टिकोण मानसिक बीमारी से जूझ रहे छात्रों के लिए ग्राफ न्यूरल नेटवर्क का उपयोग करके एआई उत्पाद बनाना है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/collection-of-guides-on-mastering-sql-python-data-cleaning-data-wrangling-and-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=collection-of-guides-on-mastering-sql-python-data-cleaning-data-wrangling-and-exploratory-data-analysis

