यह पोस्ट क्लाउडिया चिटू और के सहयोग से लिखी गई है ACAST से स्पिरिडॉन डॉसिस।
2014 में स्थापित है, अभिनेता का चयन दुनिया की अग्रणी स्वतंत्र पॉडकास्ट कंपनी है, जो पॉडकास्ट रचनाकारों और पॉडकास्ट विज्ञापनदाताओं को सुनने के बेहतरीन अनुभव के लिए प्रोत्साहित करती है। पॉडकास्टिंग के लिए एक स्वतंत्र और खुले पारिस्थितिकी तंत्र का समर्थन करके, अकास्ट का लक्ष्य पॉडकास्टिंग को आगे बढ़ने के लिए आवश्यक उपकरणों और मुद्रीकरण के साथ बढ़ावा देना है।
कंपनी डेटा-संचालित उत्पादों और स्केल इंजीनियरिंग सर्वोत्तम प्रथाओं के निर्माण के लिए AWS क्लाउड सेवाओं का उपयोग करती है। विकास और लाभप्रदता चरणों के बीच एक स्थायी डेटा प्लेटफ़ॉर्म सुनिश्चित करने के लिए, उनकी तकनीकी टीमों ने विकेंद्रीकृत को अपनाया डेटा जाल वास्तुकला.
इस पोस्ट में, हम चर्चा करते हैं कि कैसे Acast ने डेटा जाल की अवधारणा को नियोजित करके बड़े पैमाने पर डेटा के साथ काम करने वाली टीमों के बीच युग्मित निर्भरता की चुनौती पर काबू पाया।
समस्या
त्वरित विकास और विस्तार के साथ, अकास्ट को एक ऐसी चुनौती का सामना करना पड़ा जिसकी गूंज विश्व स्तर पर है। अकास्ट ने खुद को विविध व्यावसायिक इकाइयों और पूरे संगठन में बड़ी मात्रा में उत्पन्न डेटा के साथ पाया। मौजूदा मोनोलिथ और केंद्रीकृत वास्तुकला डेटा उपभोक्ताओं की बढ़ती मांगों को पूरा करने के लिए संघर्ष कर रही थी। डेटा इंजीनियरों को डेटा इंफ्रास्ट्रक्चर को बनाए रखना और स्केल करना अधिक चुनौतीपूर्ण लग रहा था, जिसके परिणामस्वरूप डेटा एक्सेस, डेटा साइलो और डेटा प्रबंधन में अक्षमताएं हो रही थीं। इसका मुख्य उद्देश्य व्यावसायिक आवश्यकताओं से लेकर शुरू से अंत तक उपयोगकर्ता अनुभव को बढ़ाना था।
एकॉस्ट को परिचालन पैमाने पर पहुंचने के लिए इन चुनौतियों का समाधान करने की आवश्यकता है, जिसका अर्थ है वैश्विक स्तर पर अधिकतम संख्या में लोग जो स्वतंत्र रूप से काम कर सकते हैं और मूल्य प्रदान कर सकते हैं। इस मामले में, अकास्ट ने इस मोनोलिथ संरचना की चुनौती और उत्पाद टीमों, तकनीकी टीमों, अंतिम उपभोक्ताओं के लिए मूल्य निर्धारण के उच्च समय से निपटने का प्रयास किया। यह उल्लेखनीय है कि उनके पास AWS खातों के बिना परिचालन या व्यावसायिक टीमों सहित अन्य उत्पाद और तकनीकी टीमें भी हैं।
Acast के पास अलग-अलग संख्या में उत्पाद टीमें हैं, जो मौजूदा टीमों को मर्ज करके, उन्हें विभाजित करके, नए लोगों को जोड़कर या बस नई टीमें बनाकर लगातार विकसित हो रही हैं। पिछले 2 वर्षों में, उनके पास 10-20 टीमें हो गई हैं, जिनमें से प्रत्येक में 4-10 लोग शामिल हैं। स्वामित्व के आधार पर, प्रत्येक टीम के पास कम से कम दो AWS खाते, अधिकतम 10 खाते होते हैं। इन खातों द्वारा उत्पादित अधिकांश डेटा का उपयोग बिजनेस इंटेलिजेंस (बीआई) उद्देश्यों के लिए डाउनस्ट्रीम में किया जाता है अमेज़न एथेना, प्रतिदिन सैकड़ों व्यावसायिक उपयोगकर्ताओं द्वारा।
Acast द्वारा कार्यान्वित समाधान एक डेटा जाल है, जो AWS पर तैयार किया गया है। समाधान स्पष्ट वास्तुशिल्प निर्णय के बजाय संगठनात्मक संरचना को प्रतिबिंबित करता है। इनवर्स कॉनवे मैन्युवर के अनुसार, अकास्ट की प्रौद्योगिकी वास्तुकला व्यावसायिक वास्तुकला के साथ समरूपता प्रदर्शित करती है। इस मामले में, व्यावसायिक उपयोगकर्ताओं को डेटा मेश आर्किटेक्चर के माध्यम से अंतर्दृष्टि प्राप्त करने और सीधे जानने के लिए सक्षम किया जाता है कि डोमेन-विशिष्ट मालिक कौन हैं, जिससे सहयोग में तेजी आती है। जब हम अपने AWS प्रमाणीकरण में उपयोग की जाने वाली AWS पहचान और पहुंच प्रबंधन (IAM) भूमिकाओं पर चर्चा करेंगे तो इसे और अधिक विस्तृत किया जाएगा क्योंकि भूमिकाओं में से एक व्यवसाय समूह को समर्पित है।
सफलता के मापदंड
अकास्ट एक नई टीम- और डोमेन-उन्मुख डेटा उत्पाद और इसके संबंधित बुनियादी ढांचे और सेटअप को बूटस्ट्रैपिंग और स्केल करने में सफल रहा, जिसके परिणामस्वरूप अंतर्दृष्टि एकत्र करने में कम घर्षण हुआ और उपयोगकर्ता और उपभोक्ता खुश हुए।
कार्यान्वयन की सफलता का मतलब डेटा बुनियादी ढांचे, डेटा प्रबंधन और व्यावसायिक परिणामों के विभिन्न पहलुओं का आकलन करना है। उन्होंने मेट्रिक्स और संकेतकों को निम्नलिखित श्रेणियों में वर्गीकृत किया:
- डेटा उपयोग - कौन किस डेटा स्रोत का उपभोग कर रहा है, इसकी स्पष्ट समझ, उपभोक्ताओं और उत्पादकों की मैपिंग के साथ साकार हुई। उपयोगकर्ताओं के साथ चर्चा से पता चला कि वे सरल तरीके से डेटा तक तेज़ पहुंच, अधिक संरचित डेटा संगठन और निर्माता कौन है, इसकी स्पष्ट मैपिंग पाकर अधिक खुश थे। उनकी डेटा-संचालित संस्कृति (डेटा साक्षरता, डेटा साझाकरण और व्यावसायिक इकाइयों में सहयोग) को आगे बढ़ाने के लिए बहुत प्रगति हुई है।
- सामग्री संचालन - अपने सेवा-स्तरीय ऑब्जेक्ट के साथ यह बताते हुए कि डेटा स्रोत कब उपलब्ध हैं (अन्य विवरणों के साथ), टीमों को पता है कि किसे सूचित करना है और देर से डेटा आने या डेटा के साथ अन्य समस्याएं होने पर वे कम समय में ऐसा कर सकते हैं। डेटा प्रबंधक की भूमिका के साथ, स्वामित्व मजबूत हुआ है।
- डेटा टीम उत्पादकता - इंजीनियरिंग रेट्रोस्पेक्टिव के माध्यम से, एकॉस्ट ने पाया कि उनकी टीमें अपने डेटा डोमेन के संबंध में निर्णय लेने के लिए स्वायत्तता की सराहना करती हैं।
- लागत और संसाधन दक्षता - यह एक ऐसा क्षेत्र है जहां स्केलिंग को सक्षम करते हुए सभी खातों में डेटा पढ़कर, एकैस्ट ने डेटा डुप्लिकेशन में कमी देखी, और इसलिए लागत में कमी (कुछ खातों में, डेटा की प्रतिलिपि को 100% हटा दिया गया)।
डेटा मेष सिंहावलोकन
डेटा मेश एक डोमेन-उन्मुख, स्व-सेवा डिज़ाइन (सॉफ़्टवेयर विकास परिप्रेक्ष्य में) का उपयोग करके विकेन्द्रीकृत डेटा आर्किटेक्चर बनाने के लिए एक सामाजिक-तकनीकी दृष्टिकोण है, और एरिक इवांस के डोमेन-संचालित डिज़ाइन और मैनुअल पेस और मैथ्यू स्केल्टन के सिद्धांत को उधार लेता है। टीम टोपोलॉजी का सिद्धांत. यह समझने के लिए संदर्भ स्थापित करना महत्वपूर्ण है कि डेटा जाल क्या है क्योंकि यह आने वाले तकनीकी विवरणों के लिए मंच तैयार करता है और आपको यह समझने में मदद कर सकता है कि इस पोस्ट में चर्चा की गई अवधारणाएं डेटा जाल के व्यापक ढांचे में कैसे फिट होती हैं।
Acast के कार्यान्वयन में गहराई से उतरने से पहले संक्षेप में, डेटा जाल अवधारणा निम्नलिखित सिद्धांतों पर आधारित है:
- प्रथम श्रेणी की चिंता के रूप में पाइपलाइनों के विपरीत, यह डोमेन संचालित है
- यह डेटा को एक उत्पाद के रूप में कार्य करता है
- यह एक अच्छा उत्पाद है जो उपयोगकर्ताओं को प्रसन्न करता है (डेटा भरोसेमंद है, दस्तावेज़ीकरण उपलब्ध है, और यह आसानी से उपभोग योग्य है)
- यह फ़ेडरेटेड कम्प्यूटेशनल गवर्नेंस और विकेन्द्रीकृत स्वामित्व-एक स्व-सेवा डेटा प्लेटफ़ॉर्म प्रदान करता है
डोमेन-संचालित वास्तुकला
परिचालन और विश्लेषणात्मक डेटासेट के मालिक होने के अकास्ट के दृष्टिकोण में, टीमों को डोमेन के आधार पर स्वामित्व के साथ संरचित किया जाता है, डेटा के निर्माता से सीधे पढ़ना, एपीआई के माध्यम से या अमेज़ॅन एस 3 स्टोरेज से प्रोग्रामेटिक रूप से या एथेना को एसक्यूएल क्वेरी इंजन के रूप में उपयोग करना। Acast के डोमेन के कुछ उदाहरण निम्नलिखित चित्र में प्रस्तुत किए गए हैं।
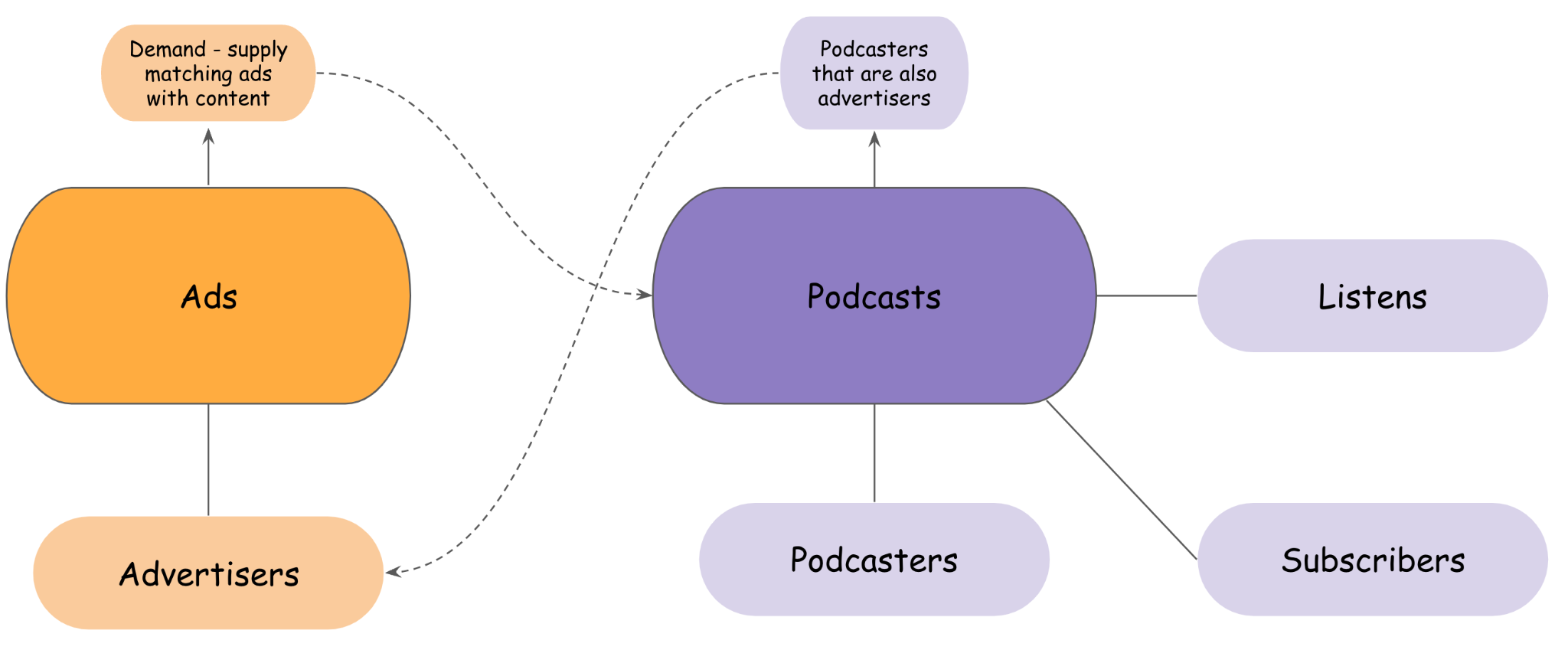
जैसा कि पिछले आंकड़े में दिखाया गया है, कुछ डोमेन एक अलग स्वामित्व के साथ अन्य डोमेन के परिचालन या विश्लेषणात्मक समापन बिंदुओं से शिथिल रूप से जुड़े हुए हैं। दूसरों के पास मजबूत निर्भरता हो सकती है, जो व्यवसाय के लिए अपेक्षित है (कुछ पॉडकास्टर विज्ञापनदाता भी हो सकते हैं, प्रायोजन क्रिएटिव बना सकते हैं और अपने स्वयं के शो के लिए अभियान चला सकते हैं, या सेवा के रूप में एकैस्ट के सॉफ़्टवेयर का उपयोग करके विज्ञापनों का लेन-देन कर सकते हैं)।
उत्पाद के रूप में डेटा
डेटा को एक उत्पाद के रूप में मानने में तीन प्रमुख घटक शामिल होते हैं: डेटा स्वयं, मेटाडेटा, और संबंधित कोड और बुनियादी ढाँचा। इस दृष्टिकोण में, डेटा उत्पन्न करने के लिए जिम्मेदार टीमों को कहा जाता है उत्पादकों. इन निर्माता टीमों के पास अपने उपभोक्ताओं के बारे में गहन ज्ञान है, वे समझते हैं कि उनके डेटा उत्पाद का उपयोग कैसे किया जाता है। डेटा उत्पादकों द्वारा नियोजित कोई भी परिवर्तन सभी उपभोक्ताओं को पहले से सूचित किया जाता है। यह सक्रिय अधिसूचना सुनिश्चित करती है कि डाउनस्ट्रीम प्रक्रियाएँ बाधित न हों। उपभोक्ताओं को अग्रिम सूचना प्रदान करने से, उनके पास सुचारू और निर्बाध कार्यप्रवाह बनाए रखते हुए, आगामी परिवर्तनों के लिए तैयारी करने और उन्हें अपनाने के लिए पर्याप्त समय होता है। निर्माता प्रारंभिक डेटासेट का एक नया संस्करण समानांतर में चलाते हैं, उपभोक्ताओं को व्यक्तिगत रूप से सूचित करते हैं, और नए संस्करण का उपभोग शुरू करने के लिए उनके साथ आवश्यक समय सीमा पर चर्चा करते हैं। जब सभी उपभोक्ता नए संस्करण का उपयोग कर रहे होते हैं, तो निर्माता प्रारंभिक संस्करण को अनुपलब्ध बना देते हैं।
टीमों के बीच फ़ाइलें साझा करने के लिए डेटा स्कीमा का अनुमान सामान्य सहमत प्रारूप से लगाया जाता है, जो कि अकास्ट के मामले में Parquet है। डेटा को फ़ाइलों, बैच किए गए या स्ट्रीम इवेंट और बहुत कुछ में साझा किया जा सकता है। प्रत्येक टीम का अपना AWS खाता होता है जो अपने स्वयं के बुनियादी ढांचे के साथ एक स्वतंत्र और स्वायत्त इकाई के रूप में कार्य करता है। ऑर्केस्ट्रेशन के लिए, वे इसका उपयोग करते हैं AWS क्लाउड डेवलपमेंट किट (AWS CDK) बुनियादी ढांचे के लिए कोड (IaC) और के रूप में एडब्ल्यूएस गोंद मेटाडेटा प्रबंधन के लिए डेटा कैटलॉग। उपयोगकर्ता उत्पादकों से डेटा प्रस्तुत करने के तरीके में सुधार करने या उच्च व्यावसायिक मूल्य उत्पन्न करने के लिए नए डेटा बिंदुओं के साथ डेटा को समृद्ध करने का अनुरोध भी कर सकते हैं।
प्रत्येक टीम के पास AWS खाता और एथेना से एक डेटा कैटलॉग आईडी होने के कारण, इसे अमेज़ॅन S3 के शीर्ष पर वितरित डेटा लेक के लेंस के माध्यम से देखना आसान है, जिसमें सभी खातों से सभी कैटलॉग को मैप करने वाला एक सामान्य कैटलॉग होता है।
साथ ही, प्रत्येक टीम अन्य कैटलॉग को अपने खाते में भी मैप कर सकती है और अपने स्वयं के डेटा का उपयोग कर सकती है, जिसे वे अन्य खातों के डेटा के साथ उत्पादित करते हैं। जब तक यह संवेदनशील डेटा न हो, डेटा को प्रोग्रामेटिक रूप से या से एक्सेस किया जा सकता है एडब्ल्यूएस प्रबंधन कंसोल डेटा इंफ्रास्ट्रक्चर इंजीनियरों पर निर्भर हुए बिना स्व-सेवा तरीके से। यह स्वयं-सेवा डेटा का एक डोमेन-अज्ञेयवादी, साझा तरीका है। उत्पाद की खोज कैटलॉग पंजीकरण के माध्यम से होती है। इंटरऑपरेबिलिटी के उद्देश्य से कंपनी में आम तौर पर सहमत और अपनाए गए केवल कुछ मानकों का उपयोग करते हुए, अकास्ट ने डेटा के आदान-प्रदान या डोमेन-अज्ञेयवादी डेटा का उपभोग करने के लिए खंडित साइलो और घर्षण को संबोधित किया।
इस सिद्धांत के साथ, टीमों को आश्वासन मिलता है कि डेटा सुरक्षित, भरोसेमंद और सटीक है, और प्रत्येक डोमेन स्तर पर उचित पहुंच नियंत्रण प्रबंधित किया जाता है। इसके अलावा, केंद्रीय खाते पर, विभिन्न प्रकार की अनुमतियों और पहुंच के उपयोग के लिए भूमिकाएं परिभाषित की जाती हैं एडब्ल्यूएस आईएएम पहचान केंद्र अनुमतियाँ. सभी डेटासेट एक ही केंद्रीय खाते से खोजे जा सकते हैं। निम्नलिखित आंकड़ा दिखाता है कि इसे कैसे उपकरणित किया जाता है, जहां दो प्रकार के उपयोगकर्ता (उपभोक्ता) समूहों द्वारा दो आईएएम भूमिकाएं ग्रहण की जाती हैं: एक जिसके पास सीमित डेटासेट तक पहुंच है, जो प्रतिबंधित डेटा है, और एक जिसके पास गैर-प्रतिबंधित डेटा तक पहुंच है। सेवा खातों के लिए इनमें से किसी भी भूमिका को ग्रहण करने का एक तरीका भी है, जैसे कि डेटा प्रोसेसिंग नौकरियों में उपयोग किया जाता है Apache Airflow के लिए Amazon प्रबंधित वर्कफ़्लो (अमेज़ॅन MWAA), उदाहरण के लिए।
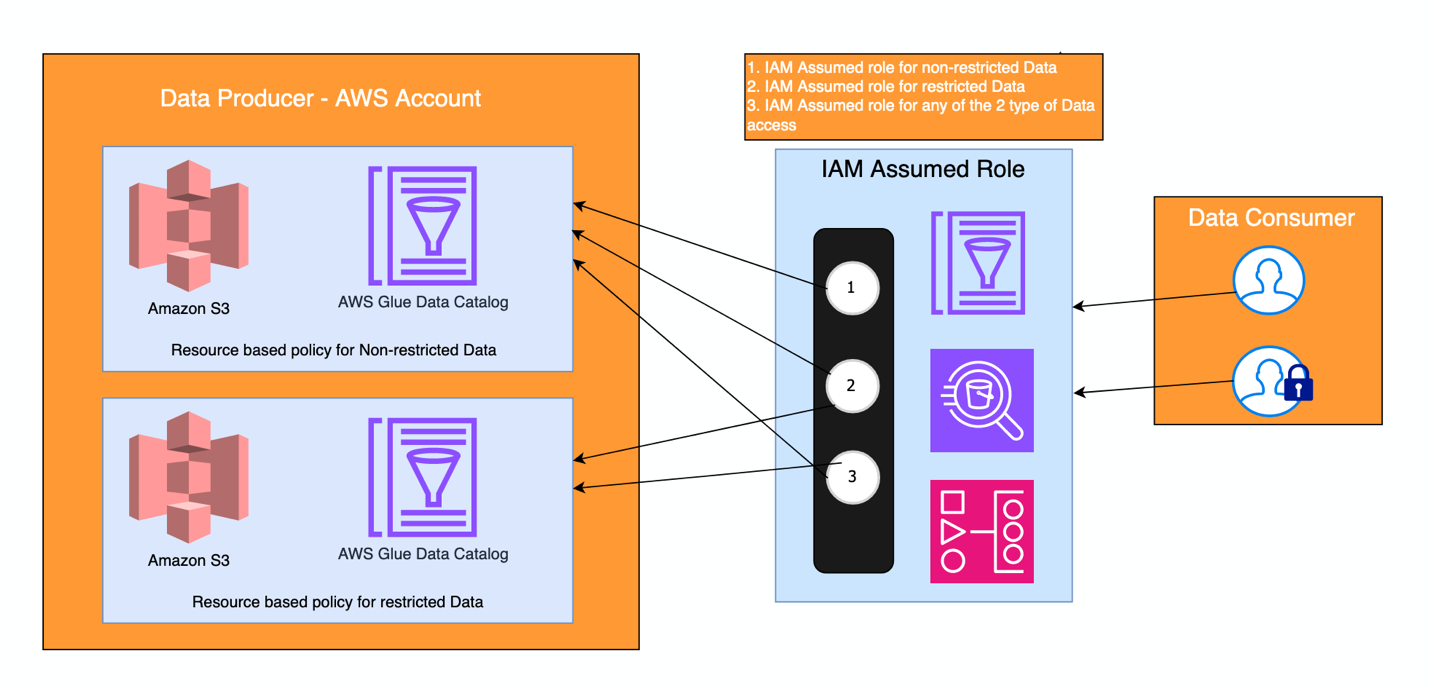
उच्च संरेखण और शिथिल युग्मित वास्तुकला के लिए अकास्ट ने कैसे समाधान निकाला
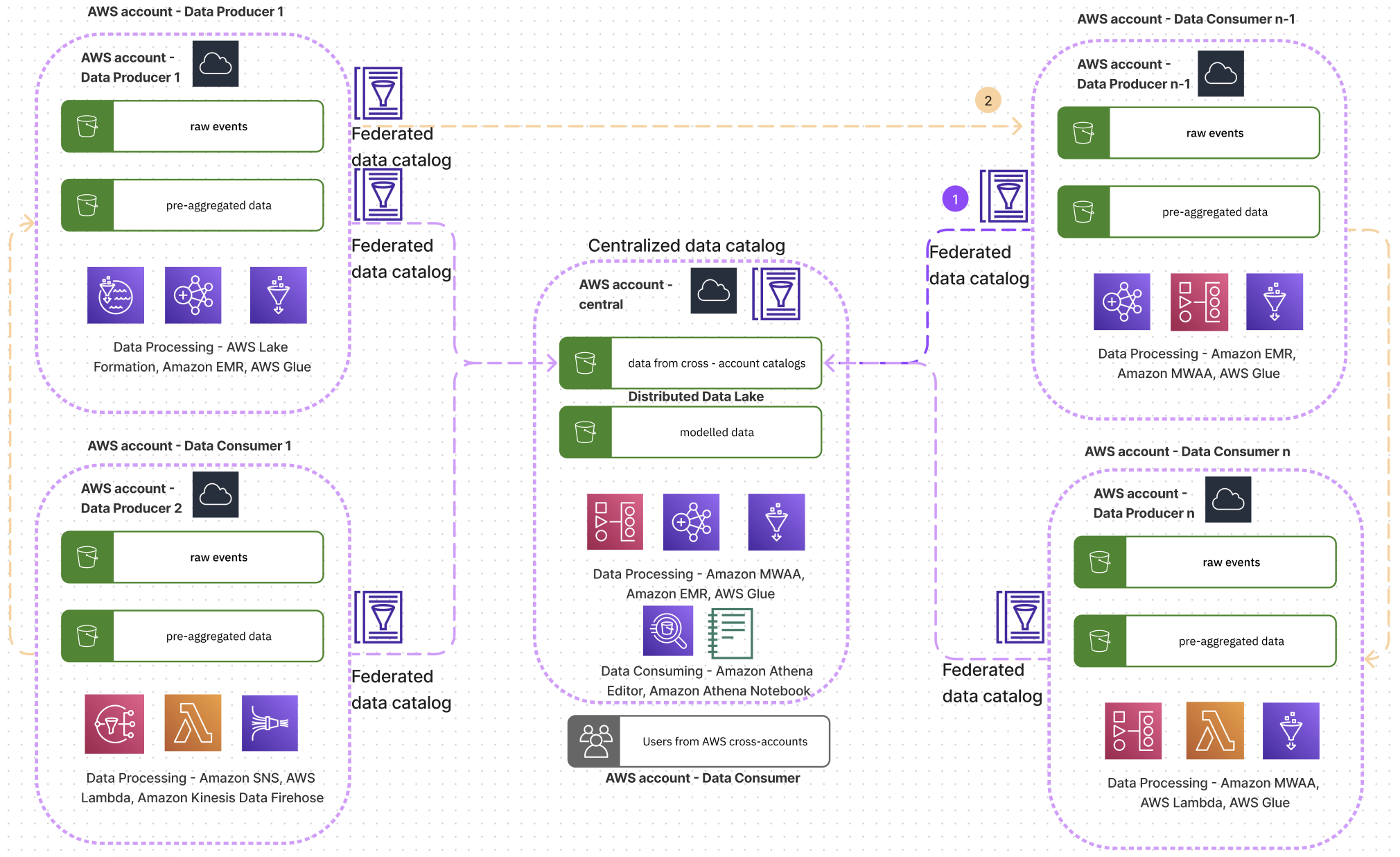
निम्नलिखित चित्र एक वैचारिक वास्तुकला को दर्शाता है कि कैसे Acast की टीमें डेटा व्यवस्थित कर रही हैं और एक दूसरे के साथ सहयोग कर रही हैं।
अकास्ट ने प्रयोग किया अच्छी तरह से तैयार की गई रूपरेखा केंद्रीय खाते के लिए क्लाउड में विश्लेषणात्मक कार्यभार चलाने के अपने अभ्यास में सुधार करना। टूल के लेंस के माध्यम से, Acast बेहतर निगरानी को संबोधित करने में सक्षम था, लागत अनुकूलन, प्रदर्शन, और सुरक्षा। इससे उन्हें उन क्षेत्रों को समझने में मदद मिली जहां वे अपने कार्यभार में सुधार कर सकते हैं और स्वचालित समाधानों के साथ सामान्य मुद्दों को कैसे संबोधित किया जाए, साथ ही केपीआई को परिभाषित करते हुए सफलता को कैसे मापा जाए। इससे उन्हें सीखने के लिए समय की बचत हुई, अन्यथा उन्हें खोजने में अधिक समय लगता। स्पिरिडॉन डॉसिस, एकॉस्ट के सूचना सुरक्षा अधिकारी, साझा करते हैं, “हमें खुशी है कि एडब्ल्यूएस हमेशा ऐसे टूल जारी करने में आगे रहता है जो मल्टी-अकाउंट सेटअप के कॉन्फ़िगरेशन, मूल्यांकन और समीक्षा को सक्षम बनाता है। विकेंद्रीकृत संगठन में काम करना हमारे लिए एक बड़ा प्लस है।" स्पिरिडॉन यह भी कहते हैं, "एक बहुत ही महत्वपूर्ण अवधारणा जिसे हम महत्व देते हैं वह है AWS सुरक्षा डिफ़ॉल्ट (उदाहरण के लिए S3 बकेट के लिए डिफ़ॉल्ट एन्क्रिप्शन)।"
आर्किटेक्चर आरेख में, हम देख सकते हैं कि प्रत्येक टीम एक डेटा निर्माता हो सकती है, केंद्रीय खाते की मालिक टीम को छोड़कर, जो केंद्रीय डेटा प्लेटफ़ॉर्म के रूप में कार्य करती है, संपूर्ण व्यावसायिक चित्र को चित्रित करने के लिए कई डोमेन से तर्क मॉडलिंग करती है। अन्य सभी टीमें डेटा उत्पादक या डेटा उपभोक्ता हो सकती हैं। वे केंद्रीय खाते से जुड़ सकते हैं और क्रॉस-अकाउंट एडब्ल्यूएस ग्लू डेटा कैटलॉग के माध्यम से डेटासेट की खोज कर सकते हैं, एथेना क्वेरी संपादक में या एथेना नोटबुक के साथ उनका विश्लेषण कर सकते हैं, या कैटलॉग को अपने स्वयं के एडब्ल्यूएस खाते में मैप कर सकते हैं। केंद्रीय एथेना कैटलॉग तक पहुंच आईएएम पहचान केंद्र के साथ कार्यान्वित की जाती है, जिसमें खुले डेटा और प्रतिबंधित डेटा एक्सेस की भूमिकाएं होती हैं।
गैर-संवेदनशील डेटा (खुले डेटा) के लिए, Acast एक टेम्पलेट का उपयोग करता है जहां डेटासेट डिफ़ॉल्ट रूप से पढ़ने के लिए पूरे संगठन के लिए खुले होते हैं, संगठन द्वारा निर्दिष्ट आईडी पैरामीटर प्रदान करने के लिए एक शर्त का उपयोग करते हुए, जैसा कि निम्नलिखित कोड स्निपेट में दिखाया गया है:
वित्तीय जैसे संवेदनशील डेटा को संभालते समय, टीमें एक सहयोगी डेटा स्टीवर्ड मॉडल का उपयोग करती हैं। डेटा प्रबंधक इच्छित उपयोग के मामले के लिए पहुंच औचित्य का मूल्यांकन करने के लिए अनुरोधकर्ता के साथ काम करता है। साथ में, वे सुरक्षा बनाए रखते हुए आवश्यकता को पूरा करने के लिए उचित पहुंच के तरीके निर्धारित करते हैं। इसमें IAM भूमिकाएँ, सेवा खाते या विशिष्ट AWS सेवाएँ शामिल हो सकती हैं। यह दृष्टिकोण तकनीकी संगठन के बाहर के व्यावसायिक उपयोगकर्ताओं को (जिसका अर्थ है कि उनके पास AWS खाता नहीं है) स्वतंत्र रूप से उन सूचनाओं तक पहुंचने और उनका विश्लेषण करने में सक्षम बनाता है जिनकी उन्हें आवश्यकता है। AWS ग्लू संसाधनों और S3 बकेट पर IAM नीतियों के माध्यम से पहुंच प्रदान करके, Acast मानव समीक्षा के माध्यम से नाजुक डेटा को नियंत्रित करते हुए स्वयं-सेवा क्षमताएं प्रदान करता है। उपयोग के मामलों को समझने, सुरक्षा जोखिमों का आकलन करने और अंततः विश्लेषणात्मक अंतर्दृष्टि के माध्यम से व्यवसाय को गति देने वाली पहुंच की सुविधा प्रदान करने के लिए डेटा प्रबंधक की भूमिका मूल्यवान रही है।
अकास्ट के उपयोग के मामले में, दानेदार पंक्ति- या स्तंभ-स्तरीय पहुंच नियंत्रण की आवश्यकता नहीं थी, इसलिए दृष्टिकोण पर्याप्त था। हालाँकि, अन्य संगठनों को संवेदनशील डेटा क्षेत्रों पर अधिक सुव्यवस्थित शासन की आवश्यकता हो सकती है। उन मामलों में, जैसे समाधान AWS झील निर्माण स्वयं-सेवा डेटा एक्सेस मॉडल प्रदान करते हुए, आवश्यक अनुमतियाँ लागू कर सकता है। अधिक जानकारी के लिए देखें AWS लेक फॉर्मेशन और AWS ग्लू का उपयोग करके डेटा मेश आर्किटेक्चर डिज़ाइन करें.
साथ ही, टीमें अन्य उत्पादकों से सीधे, अमेज़ॅन एस3 से या एपीआई के माध्यम से निर्भरता को न्यूनतम रखते हुए पढ़ सकती हैं, जो विकास और वितरण की गति को बढ़ाती है। इसलिए, एक खाता समानांतर में उत्पादक और उपभोक्ता हो सकता है। प्रत्येक टीम स्वायत्त है, और अपने स्वयं के तकनीकी स्टैक के लिए जवाबदेह है।
अतिरिक्त सीख
अकास्ट ने क्या सीखा? अब तक, हमने चर्चा की है कि वास्तुशिल्प डिजाइन संगठनात्मक संरचना का एक प्रभाव है। क्योंकि तकनीकी संगठन में कई क्रॉस-फ़ंक्शनल टीमें शामिल हैं, और डेटा जाल के सामान्य सिद्धांतों का पालन करते हुए एक नई टीम को बूटस्ट्रैप करना सीधा है, एकॉस्ट ने सीखा कि यह हर बार निर्बाध रूप से नहीं चलता है। AWS में एक पूरी तरह से नया खाता स्थापित करने के लिए, टीमें एक ही यात्रा से गुजरती हैं, लेकिन अपनी विशिष्टताओं को ध्यान में रखते हुए थोड़ी भिन्न होती हैं।
इससे कुछ मतभेद पैदा हो सकते हैं, और सभी डेटा उत्पादक टीमों को डेटा उत्पादक बनने की उच्च परिपक्वता तक पहुंचाना मुश्किल है। इसे उन क्रॉस-फंक्शनल टीमों में अलग-अलग डेटा दक्षताओं और समर्पित डेटा टीमों के न होने से समझाया जा सकता है।
विकेन्द्रीकृत समाधान को लागू करके, Acast ने अपनी टीमों को उभरती व्यावसायिक जरूरतों के अनुरूप ढालकर स्केलेबिलिटी चुनौती से प्रभावी ढंग से निपटा। यह दृष्टिकोण उच्च डिकॉउलिंग और संरेखण सुनिश्चित करता है। इसके अलावा, उन्होंने स्वामित्व को मजबूत किया, मुद्दों की पहचान करने और हल करने के लिए आवश्यक समय को काफी कम कर दिया क्योंकि अपस्ट्रीम स्रोत आसानी से ज्ञात है और निर्दिष्ट एसएलए के साथ आसानी से पहुंच योग्य है। डेटा समर्थन पूछताछ की मात्रा में 50% से अधिक की कमी देखी गई है, क्योंकि व्यावसायिक उपयोगकर्ता तेजी से जानकारी प्राप्त करने के लिए सशक्त हैं। विशेष रूप से, उन्होंने दसियों टेराबाइट्स के अनावश्यक भंडारण को सफलतापूर्वक समाप्त कर दिया, जिन्हें पहले केवल डाउनस्ट्रीम अनुरोधों को पूरा करने के लिए कॉपी किया गया था। यह उपलब्धि क्रॉस-अकाउंट रीडिंग के कार्यान्वयन के माध्यम से संभव हुई, जिससे इन पाइपलाइनों के लिए संबंधित विकास और रखरखाव लागत को हटा दिया गया।
निष्कर्ष
अकास्ट ने इनवर्स कॉनवे पैंतरेबाज़ी कानून का उपयोग किया और एडब्ल्यूएस सेवाओं को नियोजित किया जहां प्रत्येक क्रॉस-फ़ंक्शनल उत्पाद टीम के पास डेटा जाल आर्किटेक्चर बनाने के लिए अपना स्वयं का एडब्ल्यूएस खाता होता है जो स्केलेबिलिटी, उच्च स्वामित्व और स्वयं-सेवा डेटा खपत की अनुमति देता है। यह कंपनी के लिए अच्छी तरह से काम कर रहा है कि कैसे डेटा स्वामित्व और संचालन को उनके इंजीनियरिंग सिद्धांतों को पूरा करने के लिए संपर्क किया गया, जिसके परिणामस्वरूप डेटा जाल एक जानबूझकर इरादे के बजाय एक प्रभाव के रूप में हुआ। अन्य संगठनों के लिए, वांछित डेटा जाल अलग दिख सकता है और दृष्टिकोण में अन्य सीख हो सकती हैं।
निष्कर्ष निकालने के लिए, ए AWS पर आधुनिक डेटा आर्किटेक्चर आपको प्रदर्शन से समझौता किए बिना कम लागत पर डेटा उत्पादों और डेटा जाल बुनियादी ढांचे का कुशलतापूर्वक निर्माण करने की अनुमति देता है।
निम्नलिखित AWS सेवाओं के कुछ उदाहरण हैं जिनका उपयोग आप AWS पर अपना वांछित डेटा जाल डिज़ाइन करने के लिए कर सकते हैं:
लेखक के बारे में
 क्लाउडिया चितु एक डेटा रणनीतिकार और एनालिटिक्स क्षेत्र में एक प्रभावशाली नेता हैं। संगठन के समग्र रणनीतिक लक्ष्यों के साथ डेटा पहल को संरेखित करने पर ध्यान केंद्रित करते हुए, वह दीर्घकालिक योजना और सतत विकास के लिए एक मार्गदर्शक शक्ति के रूप में डेटा का उपयोग करती है।
क्लाउडिया चितु एक डेटा रणनीतिकार और एनालिटिक्स क्षेत्र में एक प्रभावशाली नेता हैं। संगठन के समग्र रणनीतिक लक्ष्यों के साथ डेटा पहल को संरेखित करने पर ध्यान केंद्रित करते हुए, वह दीर्घकालिक योजना और सतत विकास के लिए एक मार्गदर्शक शक्ति के रूप में डेटा का उपयोग करती है।
 स्पिरिडॉन डॉसिस Acast में एक सूचना सुरक्षा पेशेवर है। स्पिरिडॉन कंपनी और उपयोगकर्ताओं के डेटा की सुरक्षा करते हुए सुरक्षित तरीके से अपनी सेवाओं को डिजाइन, कार्यान्वित और संचालित करने में संगठन का समर्थन करता है।
स्पिरिडॉन डॉसिस Acast में एक सूचना सुरक्षा पेशेवर है। स्पिरिडॉन कंपनी और उपयोगकर्ताओं के डेटा की सुरक्षा करते हुए सुरक्षित तरीके से अपनी सेवाओं को डिजाइन, कार्यान्वित और संचालित करने में संगठन का समर्थन करता है।
 श्रीकांत दास अमेज़ॅन वेब सर्विसेज में एक्सेलेरेशन लैब सॉल्यूशंस आर्किटेक्ट हैं। उनके पास बिग डेटा एनालिटिक्स और डेटा इंजीनियरिंग में 13 वर्षों से अधिक का अनुभव है, जहां उन्हें विश्वसनीय, स्केलेबल और कुशल समाधान बनाने में आनंद आता है। काम के अलावा, उन्हें यात्रा करना और सोशल मीडिया पर अपने अनुभवों को ब्लॉग करना पसंद है।
श्रीकांत दास अमेज़ॅन वेब सर्विसेज में एक्सेलेरेशन लैब सॉल्यूशंस आर्किटेक्ट हैं। उनके पास बिग डेटा एनालिटिक्स और डेटा इंजीनियरिंग में 13 वर्षों से अधिक का अनुभव है, जहां उन्हें विश्वसनीय, स्केलेबल और कुशल समाधान बनाने में आनंद आता है। काम के अलावा, उन्हें यात्रा करना और सोशल मीडिया पर अपने अनुभवों को ब्लॉग करना पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/design-a-data-mesh-on-aws-that-reflects-the-envisioned-organization/

