यह पोस्ट विप्रो के AWS AI/ML प्रैक्टिस के भजनदीप सिंह और अजय विश्वकर्मा के सहयोग से लिखा गया था।
कई संगठन मशीन लर्निंग (एमएल) मॉडल बनाने और प्रबंधित करने के लिए ऑन-प्रिमाइसेस और ओपन सोर्स डेटा साइंस समाधानों के संयोजन का उपयोग कर रहे हैं।
डेटा विज्ञान और DevOps टीमों को इन पृथक टूल स्टैक और सिस्टम को प्रबंधित करने में चुनौतियों का सामना करना पड़ सकता है। एक कॉम्पैक्ट समाधान बनाने के लिए एकाधिक टूल स्टैक को एकीकृत करने में कस्टम कनेक्टर या वर्कफ़्लो का निर्माण शामिल हो सकता है। प्रत्येक स्टैक के वर्तमान संस्करण के आधार पर विभिन्न निर्भरताओं को प्रबंधित करना और प्रत्येक स्टैक के नए अपडेट जारी करने के साथ उन निर्भरताओं को बनाए रखना समाधान को जटिल बनाता है। इससे बुनियादी ढांचे के रखरखाव की लागत बढ़ जाती है और उत्पादकता में बाधा आती है।
आर्टिफिशियल इंटेलिजेंस (एआई) और मशीन लर्निंग (एमएल) की पेशकश अमेज़ॅन वेब सेवा (एडब्ल्यूएस)एकीकृत निगरानी और अधिसूचना सेवाओं के साथ, संगठनों को इष्टतम लागत पर स्वचालन, स्केलेबिलिटी और मॉडल गुणवत्ता के आवश्यक स्तर प्राप्त करने में सहायता मिलती है। AWS डेटा विज्ञान और DevOps टीमों को समग्र मॉडल जीवनचक्र प्रक्रिया को सहयोग करने और सुव्यवस्थित करने में भी मदद करता है।
एमएल सेवाओं के एडब्ल्यूएस पोर्टफोलियो में सेवाओं का एक मजबूत सेट शामिल है जिसका उपयोग आप मशीन लर्निंग अनुप्रयोगों के विकास, प्रशिक्षण और तैनाती में तेजी लाने के लिए कर सकते हैं। सेवाओं के सुइट का उपयोग एमएल मॉडल की निगरानी और पुनः प्रशिक्षण सहित संपूर्ण मॉडल जीवनचक्र का समर्थन करने के लिए किया जा सकता है।
इस पोस्ट में, हम विप्रो के उपयोग करने वाले ग्राहकों में से एक के लिए मॉडल विकास और एमएलओपीएस फ्रेमवर्क कार्यान्वयन पर चर्चा करते हैं अमेज़न SageMaker और अन्य AWS सेवाएँ।
विप्रो एक है AWS प्रीमियर टियर सर्विसेज पार्टनर और प्रबंधित सेवा प्रदाता (एमएसपी)। इसका एआई/एमएल समाधान अपने कई उद्यम ग्राहकों के लिए परिचालन दक्षता, उत्पादकता और ग्राहक अनुभव को बढ़ाया।
वर्तमान चुनौतियां
आइए सबसे पहले ग्राहक के डेटा विज्ञान और DevOps टीमों को उनके वर्तमान सेटअप के साथ सामना की जाने वाली कुछ चुनौतियों को समझें। फिर हम जांच कर सकते हैं कि एकीकृत सेजमेकर एआई/एमएल पेशकश ने उन चुनौतियों को हल करने में कैसे मदद की।
- सहयोग - डेटा वैज्ञानिकों में से प्रत्येक ने एमएल मॉडल बनाने और प्रशिक्षित करने के लिए अपने स्वयं के स्थानीय ज्यूपिटर नोटबुक पर काम किया। उनके पास अन्य डेटा वैज्ञानिकों के साथ साझा करने और सहयोग करने के लिए एक प्रभावी तरीके का अभाव था।
- स्केलेबिलिटी - एमएल मॉडल के प्रशिक्षण और पुन: प्रशिक्षण में अधिक से अधिक समय लग रहा था क्योंकि मॉडल अधिक जटिल हो गए थे जबकि आवंटित बुनियादी ढांचा क्षमता स्थिर बनी हुई थी।
- एमएलओपीएस - मॉडल निगरानी और चल रहे शासन को एमएल मॉडल के साथ कसकर एकीकृत और स्वचालित नहीं किया गया था। एमएलओपीएस पाइपलाइन में तृतीय-पक्ष टूल को एकीकृत करने में निर्भरताएं और जटिलताएं हैं।
- पुन: प्रयोज्यता - पुन: प्रयोज्य एमएलओपीएस ढांचे के बिना, प्रत्येक मॉडल को अलग से विकसित और नियंत्रित किया जाना चाहिए, जो समग्र प्रयास को बढ़ाता है और मॉडल के संचालन में देरी करता है।
यह आरेख चुनौतियों का सारांश देता है और कैसे सेजमेकर पर विप्रो के कार्यान्वयन ने अंतर्निहित सेजमेकर सेवाओं और पेशकशों के साथ उन्हें संबोधित किया।
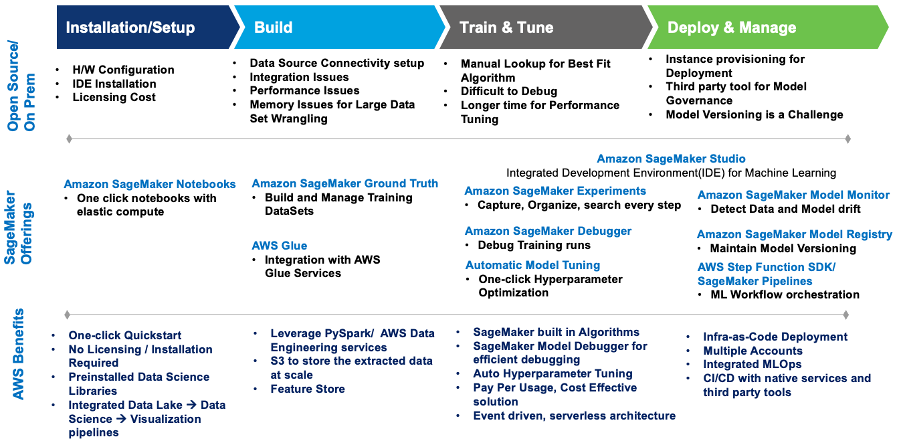
चित्र 1 - एमएल वर्कलोड माइग्रेशन के लिए सेजमेकर की पेशकश
विप्रो ने एक ऐसे आर्किटेक्चर को परिभाषित किया है जो लागत-अनुकूलित और पूरी तरह से स्वचालित तरीके से चुनौतियों का समाधान करता है।
समाधान बनाने के लिए उपयोग किया जाने वाला उपयोग मामला और मॉडल निम्नलिखित है:
- उदाहरण: प्रयुक्त कार डेटासेट के आधार पर कीमत का पूर्वानुमान
- समस्या का प्रकार: प्रतीपगमन
- प्रयुक्त मॉडल: XGBoost और लीनियर लर्नर (सेजमेकर अंतर्निर्मित एल्गोरिदम)
समाधान वास्तुकला
विप्रो सलाहकारों ने वर्तमान परिवेश के साथ-साथ AWS पर आधुनिक समाधान के लिए उनकी आवश्यकताओं और अपेक्षाओं को समझने के लिए ग्राहक के डेटा विज्ञान, DevOps और डेटा इंजीनियरिंग टीमों के साथ एक गहन खोज कार्यशाला का आयोजन किया। परामर्श कार्य के अंत तक, टीम ने निम्नलिखित आर्किटेक्चर को लागू किया था जो ग्राहक टीम की मुख्य आवश्यकताओं को प्रभावी ढंग से संबोधित करता था, जिसमें शामिल हैं:
कूट साझा - सेजमेकर नोटबुक डेटा वैज्ञानिकों को टीम के अन्य सदस्यों के साथ प्रयोग करने और कोड साझा करने में सक्षम बनाती है। विप्रो ने फीचर इंजीनियरिंग, मॉडल प्रशिक्षण, मॉडल परिनियोजन और पाइपलाइन निर्माण में तेजी लाने के लिए विप्रो के कोड एक्सेलेरेटर और स्निपेट को लागू करके अपनी एमएल मॉडल यात्रा को और तेज कर दिया।
सतत एकीकरण और सतत वितरण (सीआई/सीडी) पाइपलाइन - जब भी कोड के नए संस्करण प्रतिबद्ध होते हैं तो पाइपलाइन परिनियोजन लॉन्च करने के लिए ग्राहक के GitHub रिपॉजिटरी सक्षम कोड संस्करण और स्वचालित स्क्रिप्ट का उपयोग करना।
एमएलओपीएस - आर्किटेक्चर परिभाषित शेड्यूल के अनुसार डेटा और मॉडल ड्रिफ्ट को मान्य करके निरंतर मॉडल गुणवत्ता प्रशासन के लिए एक सेजमेकर मॉडल मॉनिटरिंग पाइपलाइन लागू करता है। जब भी बहाव का पता चलता है, तो संबंधित टीमों को कार्रवाई करने या मॉडल पुनः प्रशिक्षण शुरू करने के लिए सूचित करने के लिए एक कार्यक्रम शुरू किया जाता है।
घटना संचालित वास्तुकला - मॉडल प्रशिक्षण, मॉडल परिनियोजन और मॉडल निगरानी के लिए पाइपलाइन उपयोग द्वारा अच्छी तरह से एकीकृत हैं अमेज़न EventBridge, एक सर्वर रहित इवेंट बस। जब परिभाषित घटनाएँ घटित होती हैं, तो इवेंटब्रिज प्रतिक्रिया में चलने के लिए एक पाइपलाइन का आह्वान कर सकता है। यह पाइपलाइनों का एक ढीला-युग्मित सेट प्रदान करता है जो पर्यावरण की प्रतिक्रिया में आवश्यकतानुसार चल सकता है।
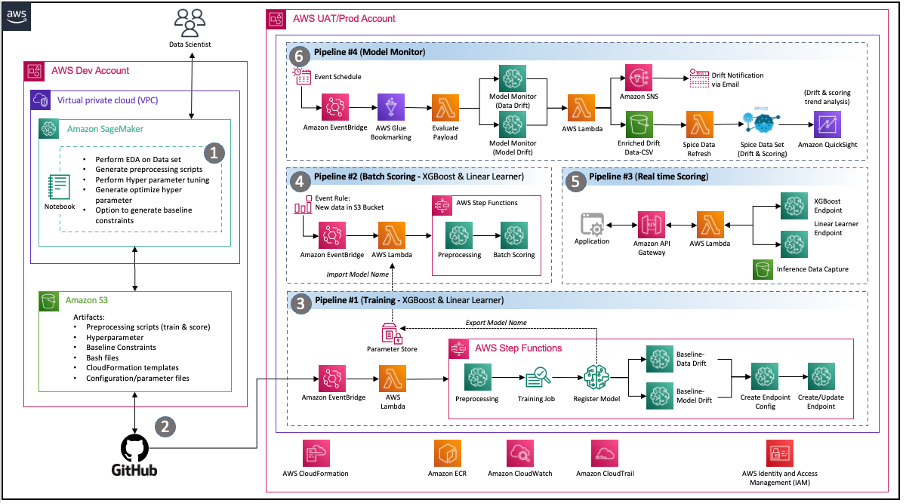
चित्र 2 - सेजमेकर के साथ इवेंट संचालित एमएलओपीएस आर्किटेक्चर
समाधान घटक
यह खंड वास्तुकला के विभिन्न समाधान घटकों का वर्णन करता है।
प्रयोग नोटबुक
- उद्देश्य: ग्राहक की डेटा विज्ञान टीम इष्टतम सुविधाओं के साथ आने के लिए विभिन्न डेटासेट और कई मॉडलों के साथ प्रयोग करना चाहती थी, जिनका उपयोग स्वचालित पाइपलाइन में आगे के इनपुट के रूप में किया जाता था।
- उपाय: विप्रो ने प्रत्येक पुन: प्रयोज्य चरण के लिए कोड स्निपेट के साथ सेजमेकर प्रयोग नोटबुक बनाई, जैसे डेटा पढ़ना और लिखना, मॉडल फीचर इंजीनियरिंग, मॉडल प्रशिक्षण और हाइपरपैरामीटर ट्यूनिंग। फ़ीचर इंजीनियरिंग कार्य डेटा रैंगलर में भी तैयार किए जा सकते हैं, लेकिन क्लाइंट ने विशेष रूप से सेजमेकर प्रसंस्करण नौकरियों के लिए कहा है AWS स्टेप फ़ंक्शंस क्योंकि वे उन तकनीकों का उपयोग करने में अधिक सहज थे। हमने पाइपलाइनों के लिए अच्छी तरह से परिभाषित इनपुट को सक्षम करने के लिए सीधे नोटबुक इंस्टेंस से प्रवाह परीक्षण के लिए एक स्टेप फ़ंक्शन बनाने के लिए एडब्ल्यूएस स्टेप फ़ंक्शन डेटा साइंस एसडीके का उपयोग किया। इससे डेटा वैज्ञानिक टीम को बहुत तेज गति से पाइपलाइन बनाने और परीक्षण करने में मदद मिली है।
स्वचालित प्रशिक्षण पाइपलाइन
- उद्देश्य: इंस्टेंस प्रकार, हाइपरपैरामीटर और एक जैसे कॉन्फ़िगर करने योग्य पैरामीटर के साथ एक स्वचालित प्रशिक्षण और पुन: प्रशिक्षण पाइपलाइन को सक्षम करने के लिए अमेज़न सरल भंडारण सेवा (अमेज़न S3) बाल्टी स्थान. पाइपलाइन को डेटा पुश इवेंट द्वारा S3 पर भी लॉन्च किया जाना चाहिए।
- उपाय: विप्रो ने स्टेप फंक्शंस एसडीके, सेजमेकर प्रोसेसिंग, ट्रेनिंग जॉब्स, बेसलाइन जेनरेशन के लिए सेजमेकर मॉडल मॉनिटर कंटेनर का उपयोग करके एक पुन: प्रयोज्य प्रशिक्षण पाइपलाइन लागू की। AWS लाम्बा, और इवेंटब्रिज सेवाएं। एडब्ल्यूएस इवेंट-संचालित आर्किटेक्चर का उपयोग करके, पाइपलाइन को मैप किए गए एस3 बकेट में पुश किए जा रहे नए डेटा इवेंट के आधार पर स्वचालित रूप से लॉन्च करने के लिए कॉन्फ़िगर किया गया है। सूचनाएं निर्धारित ईमेल पते पर भेजने के लिए कॉन्फ़िगर की गई हैं। उच्च स्तर पर, प्रशिक्षण प्रवाह निम्नलिखित चित्र जैसा दिखता है:
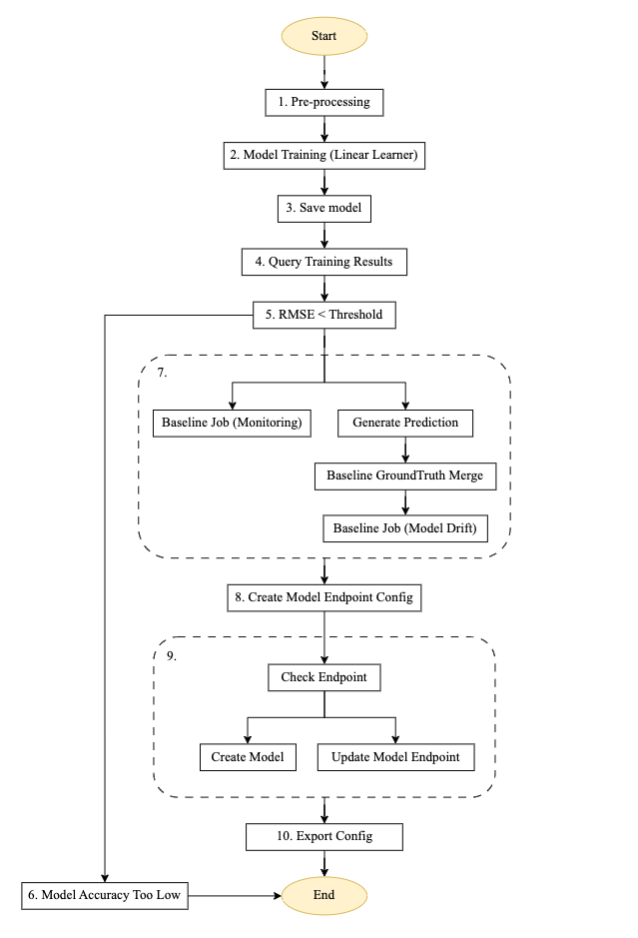
चित्र 3 - प्रशिक्षण पाइपलाइन स्टेप मशीन।
स्वचालित प्रशिक्षण पाइपलाइन के लिए प्रवाह विवरण
उपरोक्त आरेख स्टेप फ़ंक्शंस, लैम्ब्डा और सेजमेकर का उपयोग करके निर्मित एक स्वचालित प्रशिक्षण पाइपलाइन है। यह स्वचालित मॉडल प्रशिक्षण स्थापित करने, भविष्यवाणियां उत्पन्न करने, मॉडल निगरानी और डेटा निगरानी के लिए आधार रेखा बनाने और पिछले मॉडल सीमा मूल्य के आधार पर एंडपॉइंट बनाने और अपडेट करने के लिए एक पुन: प्रयोज्य पाइपलाइन है।
- पूर्व प्रसंस्करण: यह चरण अमेज़ॅन S3 स्थान से डेटा को इनपुट के रूप में लेता है और आवश्यक फीचर इंजीनियरिंग और डेटा प्री-प्रोसेसिंग कार्यों, जैसे ट्रेन, परीक्षण और मान्य विभाजन को करने के लिए सेजमेकर SKLearn कंटेनर का उपयोग करता है।
- मॉडल प्रशिक्षण: सेजमेकर एसडीके का उपयोग करते हुए, यह चरण संबंधित मॉडल छवि के साथ प्रशिक्षण कोड चलाता है और प्रशिक्षित मॉडल कलाकृतियों को उत्पन्न करते हुए प्री-प्रोसेसिंग स्क्रिप्ट से डेटासेट को प्रशिक्षित करता है।
- मॉडल सहेजें: यह चरण प्रशिक्षित मॉडल कलाकृतियों से एक मॉडल बनाता है। मॉडल का नाम किसी अन्य पाइपलाइन में संदर्भ के लिए संग्रहीत किया जाता है एडब्ल्यूएस सिस्टम मैनेजर पैरामीटर स्टोर.
- क्वेरी प्रशिक्षण परिणाम: यह चरण पिछले मॉडल प्रशिक्षण चरण से पूर्ण किए गए प्रशिक्षण कार्य के मेट्रिक्स लाने के लिए लैम्ब्डा फ़ंक्शन को कॉल करता है।
- आरएमएसई सीमा: यह चरण एक परिभाषित सीमा के विरुद्ध प्रशिक्षित मॉडल मीट्रिक (आरएमएसई) को सत्यापित करता है ताकि यह तय किया जा सके कि एंडपॉइंट परिनियोजन की ओर आगे बढ़ना है या इस मॉडल को अस्वीकार करना है।
- मॉडल सटीकता बहुत कम: इस चरण में मॉडल की सटीकता की जांच पिछले सर्वश्रेष्ठ मॉडल के मुकाबले की जाती है। यदि मॉडल मीट्रिक सत्यापन में विफल रहता है, तो अधिसूचना लैम्ब्डा फ़ंक्शन द्वारा पंजीकृत लक्ष्य विषय पर भेजी जाती है अमेज़न सरल अधिसूचना सेवा (अमेज़न SNS). यदि यह जाँच विफल हो जाती है, तो प्रवाह बाहर निकल जाता है क्योंकि नया प्रशिक्षित मॉडल परिभाषित सीमा को पूरा नहीं करता है।
- बेसलाइन नौकरी डेटा बहाव: यदि प्रशिक्षित मॉडल सत्यापन चरणों को पार कर जाता है, तो निगरानी को सक्षम करने के लिए इस प्रशिक्षित मॉडल संस्करण के लिए बेसलाइन आँकड़े तैयार किए जाते हैं और मॉडल गुणवत्ता जांच के लिए बेसलाइन उत्पन्न करने के लिए समानांतर शाखा चरण चलाए जाते हैं।
- मॉडल एंडपॉइंट कॉन्फ़िगरेशन बनाएं: यह चरण पिछले चरण में मूल्यांकन किए गए मॉडल के लिए एंडपॉइंट कॉन्फ़िगरेशन बनाता है डेटा कैप्चर सक्षम करें विन्यास।
- समापन बिंदु की जाँच करें: यह चरण जाँचता है कि क्या समापन बिंदु मौजूद है या बनाने की आवश्यकता है। आउटपुट के आधार पर, अगला चरण एंडपॉइंट बनाना या अपडेट करना है।
- निर्यात कॉन्फ़िगरेशन: यह चरण पैरामीटर के मॉडल नाम, एंडपॉइंट नाम और एंडपॉइंट कॉन्फ़िगरेशन को निर्यात करता है एडब्ल्यूएस सिस्टम मैनेजर पैरामीटर स्टोर.
राज्य मशीन स्थिति परिवर्तन की विफलता या सफलता पर अलर्ट और सूचनाएं कॉन्फ़िगर किए गए एसएनएस विषय ईमेल पर भेजे जाने के लिए कॉन्फ़िगर की गई हैं। XGBoost मॉडल के लिए समान पाइपलाइन कॉन्फ़िगरेशन का पुन: उपयोग किया जाता है।
स्वचालित बैच स्कोरिंग पाइपलाइन
- उद्देश्य: जैसे ही संबंधित अमेज़न S3 स्थान पर स्कोरिंग इनपुट बैच डेटा उपलब्ध हो, बैच स्कोरिंग लॉन्च करें। बैच स्कोरिंग को स्कोरिंग करने के लिए नवीनतम पंजीकृत मॉडल का उपयोग करना चाहिए।
- उपाय: विप्रो ने स्टेप फंक्शंस एसडीके, सेजमेकर बैच ट्रांसफॉर्मेशन जॉब्स, लैम्ब्डा और इवेंटब्रिज का उपयोग करके एक पुन: प्रयोज्य स्कोरिंग पाइपलाइन लागू की। संबंधित S3 स्थान पर नए स्कोरिंग बैच डेटा की उपलब्धता के आधार पर पाइपलाइन स्वचालित रूप से चालू हो जाती है।
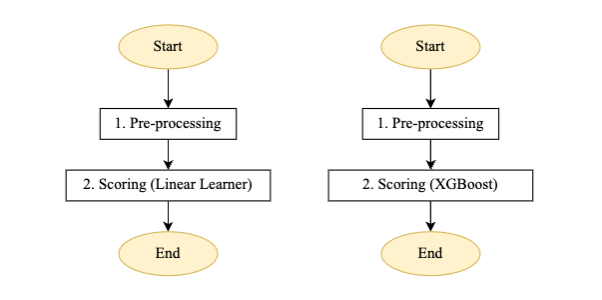
चित्र 4 - लीनियर लर्नर और XGBoost मॉडल के लिए स्कोरिंग पाइपलाइन स्टेप मशीन
स्वचालित बैच स्कोरिंग पाइपलाइन के लिए प्रवाह विवरण:
- पूर्व प्रसंस्करण: इस चरण के लिए इनपुट संबंधित S3 स्थान से एक डेटा फ़ाइल है, और SageMaker बैच परिवर्तन कार्य को कॉल करने से पहले आवश्यक प्री-प्रोसेसिंग करता है।
- स्कोरिंग: यह चरण अनुमान उत्पन्न करने के लिए बैच ट्रांसफ़ॉर्मेशन कार्य चलाता है, पंजीकृत मॉडल के नवीनतम संस्करण को कॉल करता है और स्कोरिंग आउटपुट को S3 बकेट में संग्रहीत करता है। विप्रो ने सेजमेकर बैच ट्रांसफ़ॉर्मेशन एपीआई के इनपुट फ़िल्टर और जॉइन कार्यक्षमता का उपयोग किया है। इससे बेहतर निर्णय लेने के लिए स्कोरिंग डेटा को समृद्ध करने में मदद मिली।
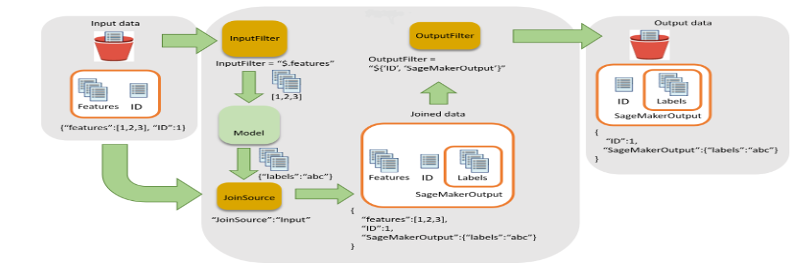
चित्र 5 - बैच परिवर्तन के लिए इनपुट फ़िल्टर और जॉइन फ़्लो
- इस चरण में, राज्य मशीन पाइपलाइन को S3 बकेट में एक नई डेटा फ़ाइल द्वारा लॉन्च किया जाता है।
अधिसूचना को राज्य मशीन स्थिति परिवर्तन की विफलता/सफलता पर कॉन्फ़िगर किए गए एसएनएस विषय ईमेल पर भेजने के लिए कॉन्फ़िगर किया गया है।
वास्तविक समय अनुमान पाइपलाइन
- उद्देश्य: दोनों मॉडलों (लीनियर लर्नर और XGBoost) एंडपॉइंट्स से वास्तविक समय के अनुमानों को सक्षम करने के लिए और एप्लिकेशन पर वापस लौटने के लिए अधिकतम अनुमानित मूल्य प्राप्त करें (या किसी अन्य कस्टम तर्क का उपयोग करके जिसे लैम्ब्डा फ़ंक्शन के रूप में लिखा जा सकता है)।
- उपाय: विप्रो टीम ने पुन: प्रयोज्य आर्किटेक्चर का उपयोग करके कार्यान्वित किया है अमेज़ॅन एपीआई गेटवे, लैम्ब्डा, और सेजमेकर एंडपॉइंट जैसा कि चित्र 6 में दिखाया गया है:

चित्र 6 - वास्तविक समय अनुमान पाइपलाइन
वास्तविक समय अनुमान पाइपलाइन के लिए प्रवाह विवरण चित्र 6 में दिखाया गया है:
- पेलोड को एप्लिकेशन से अमेज़ॅन एपीआई गेटवे पर भेजा जाता है, जो इसे संबंधित लैम्ब्डा फ़ंक्शन पर रूट करता है।
- एक लैम्ब्डा फ़ंक्शन (एक एकीकृत सेजमेकर कस्टम लेयर के साथ) आवश्यक प्री-प्रोसेसिंग, JSON या CSV पेलोड फ़ॉर्मेटिंग करता है, और संबंधित एंडपॉइंट्स को आमंत्रित करता है।
- प्रतिक्रिया लैम्ब्डा को लौटा दी जाती है और एपीआई गेटवे के माध्यम से एप्लिकेशन को वापस भेज दी जाती है।
ग्राहक ने इस पाइपलाइन का उपयोग छोटे और मध्यम स्तर के मॉडल के लिए किया, जिसमें विभिन्न प्रकार के ओपन-सोर्स एल्गोरिदम का उपयोग शामिल था। सेजमेकर के प्रमुख लाभों में से एक यह है कि विभिन्न प्रकार के एल्गोरिदम को सेजमेकर में लाया जा सकता है और अपना खुद का कंटेनर लाओ (बीवाईओसी) तकनीक का उपयोग करके तैनात किया जा सकता है। BYOC में एल्गोरिदम को कंटेनरीकृत करना और छवि को पंजीकृत करना शामिल है अमेज़ॅन इलास्टिक कंटेनर रजिस्ट्री (अमेज़ॅन ईसीआर), और फिर प्रशिक्षण और अनुमान लगाने के लिए एक कंटेनर बनाने के लिए उसी छवि का उपयोग करें।
मशीन लर्निंग चक्र में स्केलिंग सबसे बड़े मुद्दों में से एक है। सेजमेकर अनुमान के दौरान किसी मॉडल को स्केल करने के लिए आवश्यक टूल के साथ आता है। पूर्ववर्ती आर्किटेक्चर में, उपयोगकर्ताओं को सेजमेकर की ऑटो-स्केलिंग को सक्षम करने की आवश्यकता होती है, जो अंततः कार्यभार को संभालती है। ऑटो-स्केलिंग को सक्षम करने के लिए, उपयोगकर्ताओं को एक ऑटो-स्केलिंग नीति प्रदान करनी होगी जो प्रति इंस्टेंस और अधिकतम और न्यूनतम इंस्टेंस के थ्रूपुट के बारे में पूछती है। मौजूदा नीति के तहत, सेजमेकर स्वचालित रूप से वास्तविक समय के समापन बिंदुओं के लिए कार्यभार को संभालता है और जरूरत पड़ने पर उदाहरणों के बीच स्विच करता है।
कस्टम मॉडल मॉनिटर पाइपलाइन
- उद्देश्य: ग्राहक टीम डेटा बहाव और मॉडल बहाव दोनों को पकड़ने के लिए स्वचालित मॉडल निगरानी रखना चाहती थी। विप्रो टीम ने वास्तविक समय अनुमान और बैच परिवर्तन के लिए पुन: प्रयोज्य पाइपलाइन के साथ डेटा बहाव और मॉडल बहाव दोनों को सक्षम करने के लिए सेजमेकर मॉडल मॉनिटरिंग का उपयोग किया। ध्यान दें कि इस समाधान के विकास के दौरान, सेजमेकर मॉडल मॉनिटरिंग ने डेटा का पता लगाने या बैच परिवर्तन के लिए मॉडल बहाव। हमने बैच ट्रांसफॉर्मेशन पेलोड के लिए मॉडल मॉनिटर कंटेनर का उपयोग करने के लिए अनुकूलन लागू किया है।
- उपाय: विप्रो टीम ने वास्तविक समय और बैच अनुमान पेलोड के लिए एक पुन: प्रयोज्य मॉडल-मॉनिटरिंग पाइपलाइन लागू की एडब्ल्यूएस गोंद वृद्धिशील पेलोड को पकड़ने और निर्धारित कार्यक्रम के अनुसार मॉडल निगरानी कार्य शुरू करने के लिए।

चित्र 7 - मॉडल मॉनिटर स्टेप मशीन
कस्टम मॉडल मॉनिटर पाइपलाइन के लिए प्रवाह विवरण:
पाइपलाइन इवेंटब्रिज के माध्यम से कॉन्फ़िगर किए गए निर्धारित शेड्यूल के अनुसार चलती है।
- सीएसवी समेकन - यह वास्तविक समय डेटा कैप्चर और प्रतिक्रिया और बैच डेटा प्रतिक्रिया की परिभाषित S3 बाल्टी में वृद्धिशील पेलोड की उपस्थिति का पता लगाने के लिए AWS ग्लू बुकमार्क सुविधा का उपयोग करता है। इसके बाद यह उस डेटा को आगे की प्रक्रिया के लिए एकत्रित करता है।
- पेलोड का मूल्यांकन करें - यदि वर्तमान रन के लिए वृद्धिशील डेटा या पेलोड मौजूद है, तो यह निगरानी शाखा को आमंत्रित करता है। अन्यथा, यह बिना प्रसंस्करण के बायपास हो जाता है और कार्य से बाहर निकल जाता है।
- प्रोसेसिंग के बाद - मॉनिटरिंग शाखा को दो समानांतर उप शाखाओं के लिए डिज़ाइन किया गया है - एक डेटा बहाव के लिए और दूसरा मॉडल बहाव के लिए।
- निगरानी (डेटा बहाव) - जब भी कोई पेलोड मौजूद होता है तो डेटा बहाव शाखा चलती है। यह डेटा सुविधाओं के लिए प्रशिक्षण पाइपलाइन के माध्यम से उत्पन्न नवीनतम प्रशिक्षित मॉडल बेसलाइन बाधाओं और सांख्यिकी फ़ाइलों का उपयोग करता है और मॉडल निगरानी कार्य चलाता है।
- निगरानी (मॉडल बहाव) - मॉडल ड्रिफ्ट शाखा तभी चलती है जब अनुमान पेलोड के साथ जमीनी सच्चाई डेटा की आपूर्ति की जाती है। यह मॉडल गुणवत्ता सुविधाओं के लिए प्रशिक्षण पाइपलाइन के माध्यम से उत्पन्न प्रशिक्षित मॉडल बेसलाइन बाधाओं और सांख्यिकी फ़ाइलों का उपयोग करता है और मॉडल निगरानी कार्य चलाता है।
- बहाव का मूल्यांकन करें - डेटा और मॉडल बहाव दोनों का परिणाम एक बाधा उल्लंघन फ़ाइल है जिसका मूल्यांकन मूल्यांकन बहाव लैम्ब्डा फ़ंक्शन द्वारा किया जाता है जो बहाव के विवरण के साथ संबंधित अमेज़ॅन एसएनएस विषयों को अधिसूचना भेजता है। रिपोर्टिंग उद्देश्यों के लिए विशेषताओं को जोड़ने के साथ बहाव डेटा को और अधिक समृद्ध किया गया है। बहाव अधिसूचना ईमेल चित्र 8 में दिए गए उदाहरणों के समान दिखेंगे।

चित्र 8 - डेटा और मॉडल ड्रिफ्ट अधिसूचना संदेश

चित्र 9 - डेटा और मॉडल ड्रिफ्ट अधिसूचना संदेश
अमेज़ॅन क्विकसाइट विज़ुअलाइज़ेशन के साथ अंतर्दृष्टि:
- उद्देश्य: ग्राहक डेटा और मॉडल बहाव के बारे में अंतर्दृष्टि प्राप्त करना चाहता था, बहाव डेटा को संबंधित मॉडल निगरानी नौकरियों से जोड़ना चाहता था, और हस्तक्षेप डेटा रुझानों की प्रकृति को समझने के लिए अनुमान डेटा रुझानों का पता लगाना चाहता था।
- उपाय: विप्रो टीम ने इनपुट डेटा को ड्रिफ्ट परिणाम के साथ जोड़कर ड्रिफ्ट डेटा को समृद्ध किया, जो ड्रिफ्ट से लेकर निगरानी और संबंधित स्कोरिंग डेटा तक ट्राइएज को सक्षम बनाता है। विज़ुअलाइज़ेशन और डैशबोर्ड का उपयोग करके बनाया गया था अमेज़न क्विकसाइट साथ में अमेज़न एथेना डेटा स्रोत के रूप में (अमेज़ॅन S3 CSV स्कोरिंग और ड्रिफ्ट डेटा का उपयोग करके)।
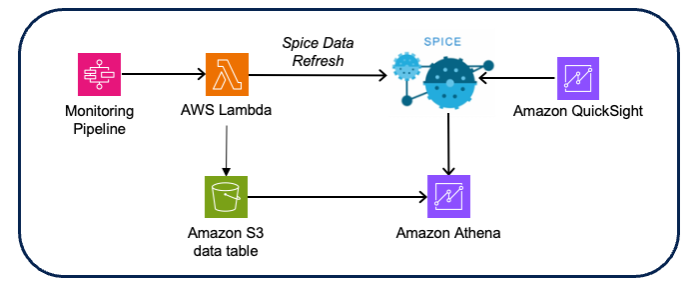
चित्र 10 - मॉडल मॉनिटरिंग विज़ुअलाइज़ेशन आर्किटेक्चर
रचना विवेचन:
- बेहतर इन-मेमोरी प्रदर्शन के लिए क्विकसाइट स्पाइस डेटासेट का उपयोग करें।
- स्पाइस डेटा रिफ्रेश को स्वचालित करने के लिए क्विकसाइट रिफ्रेश डेटासेट एपीआई का उपयोग करें।
- डैशबोर्ड और विश्लेषण पहुंच नियंत्रण के लिए समूह-आधारित सुरक्षा लागू करें।
- सभी खातों में, निर्यात और आयात डेटासेट, डेटा स्रोत और क्विकसाइट द्वारा प्रदान किए गए विश्लेषण एपीआई कॉल का उपयोग करके तैनाती को स्वचालित करें।
मॉडल मॉनिटरिंग डैशबोर्ड:
मॉडल निगरानी नौकरियों के प्रभावी परिणाम और सार्थक अंतर्दृष्टि को सक्षम करने के लिए, मॉडल निगरानी डेटा के लिए कस्टम डैशबोर्ड बनाए गए थे। मॉडल मॉनिटरिंग द्वारा प्रकट रुझानों का एक दृश्य बनाने के लिए इनपुट डेटा बिंदुओं को अनुमान अनुरोध डेटा, जॉब डेटा और मॉनिटरिंग आउटपुट के समानांतर जोड़ा जाता है।
इससे वास्तव में ग्राहक टीम को अनुमान अनुरोधों के प्रत्येक बैच के अनुमानित परिणाम के साथ-साथ विभिन्न डेटा सुविधाओं के पहलुओं की कल्पना करने में मदद मिली है।
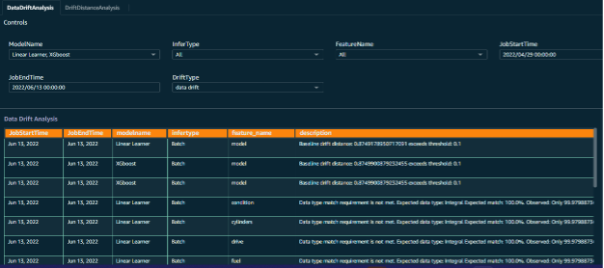
चित्र 11 - चयन संकेतों के साथ मॉडल मॉनिटर डैशबोर्ड

चित्र 12 - मॉडल मॉनिटर बहाव विश्लेषण
निष्कर्ष
इस पोस्ट में बताए गए कार्यान्वयन ने विप्रो को अपने ऑन-प्रिमाइसेस मॉडल को प्रभावी ढंग से AWS में स्थानांतरित करने और एक स्केलेबल, स्वचालित मॉडल विकास ढांचे का निर्माण करने में सक्षम बनाया।
पुन: प्रयोज्य फ्रेमवर्क घटकों का उपयोग डेटा विज्ञान टीम को अपने काम को तैनाती योग्य AWS स्टेप फ़ंक्शंस JSON घटकों के रूप में प्रभावी ढंग से पैकेज करने के लिए सशक्त बनाता है। इसके साथ ही, DevOps टीमों ने उच्च वातावरण में मॉडलों के निर्बाध प्रचार और पुनः प्रशिक्षण की सुविधा के लिए स्वचालित CI/CD पाइपलाइन का उपयोग और संवर्द्धन किया।
मॉडल मॉनिटरिंग घटक ने मॉडल प्रदर्शन की निरंतर निगरानी को सक्षम किया है, और जब भी डेटा या मॉडल बहाव का पता चलता है तो उपयोगकर्ताओं को अलर्ट और सूचनाएं प्राप्त होती हैं।
ग्राहक की टीम इस एमएलओपीएस ढांचे का उपयोग अधिक मॉडलों को स्थानांतरित करने या विकसित करने और उनके सेजमेकर अपनाने को बढ़ाने के लिए कर रही है।
हमारे सावधानीपूर्वक डिज़ाइन किए गए आर्किटेक्चर के साथ सेजमेकर सेवाओं के व्यापक सूट का उपयोग करके, ग्राहक कई मॉडलों को निर्बाध रूप से ऑनबोर्ड कर सकते हैं, तैनाती के समय को काफी कम कर सकते हैं और कोड साझाकरण से जुड़ी जटिलताओं को कम कर सकते हैं। इसके अलावा, हमारा आर्किटेक्चर एक सुव्यवस्थित विकास प्रक्रिया सुनिश्चित करते हुए, कोड संस्करण रखरखाव को सरल बनाता है।
यह आर्किटेक्चर पूरे मशीन लर्निंग चक्र को संभालता है, जिसमें स्वचालित मॉडल प्रशिक्षण, वास्तविक समय और बैच अनुमान, सक्रिय मॉडल निगरानी और बहाव विश्लेषण शामिल है। यह एंड-टू-एंड समाधान ग्राहकों को निरंतर सटीकता और विश्वसनीयता सुनिश्चित करने के लिए कठोर निगरानी और विश्लेषण क्षमताओं को बनाए रखते हुए इष्टतम मॉडल प्रदर्शन प्राप्त करने में सक्षम बनाता है।
इस वास्तुकला को बनाने के लिए, जैसे आवश्यक संसाधन बनाकर शुरुआत करें अमेज़न वर्चुअल प्राइवेट क्लाउड (अमेज़न VPC), सेजमेकर नोटबुक और लैम्ब्डा फ़ंक्शन। उचित सेटअप करना सुनिश्चित करें AWS पहचान और अभिगम प्रबंधन (IAM) इन संसाधनों के लिए नीतियां।
इसके बाद, सेजमेकर स्टूडियो या ज्यूपिटर नोटबुक के भीतर आर्किटेक्चर के घटकों - जैसे प्रशिक्षण और प्रीप्रोसेसिंग स्क्रिप्ट - के निर्माण पर ध्यान केंद्रित करें। इस चरण में वांछित कार्यक्षमताओं को सक्षम करने के लिए आवश्यक कोड और कॉन्फ़िगरेशन विकसित करना शामिल है।
आर्किटेक्चर के घटकों को परिभाषित करने के बाद, आप डेटा पर अनुमान उत्पन्न करने या पोस्ट-प्रोसेसिंग चरणों को निष्पादित करने के लिए लैम्ब्डा फ़ंक्शन के निर्माण के साथ आगे बढ़ सकते हैं।
अंत में, घटकों को जोड़ने और एक सुचारू वर्कफ़्लो स्थापित करने के लिए स्टेप फ़ंक्शंस का उपयोग करें जो प्रत्येक चरण के संचालन का समन्वय करता है।
लेखक के बारे में
 स्टीफन रैंडोल्फ अमेज़न वेब सर्विसेज (AWS) में सीनियर पार्टनर सॉल्यूशंस आर्किटेक्ट हैं। वह नवीनतम एडब्ल्यूएस तकनीक पर ग्लोबल सिस्टम इंटीग्रेटर (जीएसआई) भागीदारों को सक्षम और समर्थन करता है क्योंकि वे व्यावसायिक चुनौतियों को हल करने के लिए उद्योग समाधान विकसित करते हैं। स्टीफ़न को विशेष रूप से सुरक्षा और जेनरेटिव एआई का शौक है, और वह ग्राहकों और साझेदारों को AWS पर सुरक्षित, कुशल और नवीन समाधान तैयार करने में मदद करता है।
स्टीफन रैंडोल्फ अमेज़न वेब सर्विसेज (AWS) में सीनियर पार्टनर सॉल्यूशंस आर्किटेक्ट हैं। वह नवीनतम एडब्ल्यूएस तकनीक पर ग्लोबल सिस्टम इंटीग्रेटर (जीएसआई) भागीदारों को सक्षम और समर्थन करता है क्योंकि वे व्यावसायिक चुनौतियों को हल करने के लिए उद्योग समाधान विकसित करते हैं। स्टीफ़न को विशेष रूप से सुरक्षा और जेनरेटिव एआई का शौक है, और वह ग्राहकों और साझेदारों को AWS पर सुरक्षित, कुशल और नवीन समाधान तैयार करने में मदद करता है।
 भजनदीप सिंह विप्रो टेक्नोलॉजीज में AWS AI/ML सेंटर ऑफ एक्सीलेंस हेड के रूप में कार्य किया है, जो डेटा एनालिटिक्स और AI समाधान प्रदान करने के लिए ग्राहक सहभागिता का नेतृत्व करता है। उनके पास AWS AI/ML स्पेशलिटी सर्टिफिकेशन है और वे AI/ML सेवाओं और समाधानों पर तकनीकी ब्लॉग लिखते हैं। सभी उद्योगों में अग्रणी एडब्ल्यूएस एआई/एमएल समाधानों के अनुभव के साथ, भजनदीप ने ग्राहकों को अपनी विशेषज्ञता और नेतृत्व के माध्यम से एडब्ल्यूएस एआई/एमएल सेवाओं के मूल्य को अधिकतम करने में सक्षम बनाया है।
भजनदीप सिंह विप्रो टेक्नोलॉजीज में AWS AI/ML सेंटर ऑफ एक्सीलेंस हेड के रूप में कार्य किया है, जो डेटा एनालिटिक्स और AI समाधान प्रदान करने के लिए ग्राहक सहभागिता का नेतृत्व करता है। उनके पास AWS AI/ML स्पेशलिटी सर्टिफिकेशन है और वे AI/ML सेवाओं और समाधानों पर तकनीकी ब्लॉग लिखते हैं। सभी उद्योगों में अग्रणी एडब्ल्यूएस एआई/एमएल समाधानों के अनुभव के साथ, भजनदीप ने ग्राहकों को अपनी विशेषज्ञता और नेतृत्व के माध्यम से एडब्ल्यूएस एआई/एमएल सेवाओं के मूल्य को अधिकतम करने में सक्षम बनाया है।
 अजय विश्वकर्मा विप्रो के एआई समाधान अभ्यास के एडब्ल्यूएस विंग के लिए एक एमएल इंजीनियर है। उन्हें सेजमेकर में कस्टम एल्गोरिदम के लिए BYOM समाधान बनाने, एंड टू एंड ईटीएल पाइपलाइन परिनियोजन, लेक्स का उपयोग करके चैटबॉट बनाने, क्रॉस अकाउंट क्विकसाइट संसाधन साझा करने और परिनियोजन के लिए क्लाउडफॉर्मेशन टेम्पलेट बनाने का अच्छा अनुभव है। वह ग्राहकों की हर समस्या को एक चुनौती के रूप में लेते हुए AWS की खोज करना पसंद करते हैं ताकि अधिक से अधिक खोज की जा सके और उन्हें समाधान प्रदान किया जा सके।
अजय विश्वकर्मा विप्रो के एआई समाधान अभ्यास के एडब्ल्यूएस विंग के लिए एक एमएल इंजीनियर है। उन्हें सेजमेकर में कस्टम एल्गोरिदम के लिए BYOM समाधान बनाने, एंड टू एंड ईटीएल पाइपलाइन परिनियोजन, लेक्स का उपयोग करके चैटबॉट बनाने, क्रॉस अकाउंट क्विकसाइट संसाधन साझा करने और परिनियोजन के लिए क्लाउडफॉर्मेशन टेम्पलेट बनाने का अच्छा अनुभव है। वह ग्राहकों की हर समस्या को एक चुनौती के रूप में लेते हुए AWS की खोज करना पसंद करते हैं ताकि अधिक से अधिक खोज की जा सके और उन्हें समाधान प्रदान किया जा सके।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/modernizing-data-science-lifecycle-management-with-aws-and-wipro/

