आप अंतर्दृष्टि प्राप्त करने के लिए कई इंटरनेट ऑफ थिंग्स (IoT) सेंसर से डेटा प्राप्त और एकीकृत कर सकते हैं। हालाँकि, आपको सामान्य डेटा तत्वों के आधार पर सभी सेंसरों से उपकरण स्वास्थ्य जानकारी जैसे विश्लेषण प्राप्त करने के लिए कई IoT सेंसर उपकरणों से डेटा को एकीकृत करना पड़ सकता है। इनमें से प्रत्येक सेंसर डिवाइस अद्वितीय स्कीमा और विभिन्न विशेषताओं के साथ डेटा संचारित कर सकता है।
आप अपने सभी IoT सेंसर से किसी केंद्रीय स्थान पर डेटा प्राप्त कर सकते हैं अमेज़न सरल भंडारण सेवा (अमेज़न S3)। स्कीमा विकास एक ऐसी सुविधा है जहां डेटाबेस तालिका की स्कीमा अंतर्ग्रहण की जा रही फ़ाइलों की विशेषताओं में परिवर्तन को समायोजित करने के लिए विकसित हो सकती है। स्कीमा इवोल्यूशन कार्यक्षमता के साथ उपलब्ध है एडब्ल्यूएस गोंद, अमेज़न रेडशिफ्ट स्पेक्ट्रम जब नई विशेषताएँ जोड़ी जाती हैं या मौजूदा विशेषताएँ हटा दी जाती हैं तो स्कीमा परिवर्तनों को स्वचालित रूप से संभाल सकता है। यह S3 फ़ाइल संरचनाओं के आधार पर स्कीमा परिवर्तनों को पढ़कर AWS ग्लू क्रॉलर के साथ प्राप्त किया जाता है। क्रॉलर एक हाइब्रिड स्कीमा बनाता है जो पुराने और नए दोनों डेटासेट के साथ काम करता है। आप एकल के माध्यम से अलग-अलग स्कीमा के साथ निर्दिष्ट अमेज़ॅन एस 3 स्थान पर सभी अंतर्ग्रहण डेटा फ़ाइलों को पढ़ सकते हैं अमेज़न रेडशिफ्ट स्पेक्ट्रम AWS ग्लू मेटाडेटा कैटलॉग का हवाला देकर तालिका।
इस पोस्ट में, हम प्रदर्शित करते हैं कि एक ही अमेज़ॅन S3 स्थान में संग्रहीत विभिन्न स्कीमा के साथ एकाधिक JSON स्वरूपित फ़ाइलों को पढ़ने के लिए AWS ग्लू स्कीमा विकास सुविधा का उपयोग कैसे करें। हम यह भी दिखाते हैं कि स्कीमा को फिर से परिभाषित किए बिना या डेटा को रेडशिफ्ट तालिकाओं में लोड किए बिना रेडशिफ्ट स्पेक्ट्रम के साथ अमेज़ॅन एस 3 में इस डेटा को कैसे क्वेरी किया जाए।
समाधान अवलोकन
समाधान में निम्नलिखित चरण होते हैं:
- एक बनाएं अमेज़ॅन डेटा फ़ायरहोज़ अपने गंतव्य के रूप में Amazon S3 के साथ डिलीवरी स्ट्रीम।
- से नमूना स्ट्रीम डेटा उत्पन्न करें अमेज़ॅन किनेसिस डेटा जेनरेटर (केडीजी) गंतव्य के रूप में फायरहोज डिलीवरी स्ट्रीम के साथ।
- प्रारंभिक डेटा फ़ाइलों को Amazon S3 स्थान पर अपलोड करें।
- अमेज़ॅन S3 से डेटा फ़ाइलों को पढ़कर बाहरी तालिका परिभाषा के साथ डेटा कैटलॉग को पॉप्युलेट करने के लिए AWS ग्लू क्रॉलर बनाएं और चलाएं।
- नामक बाह्य स्कीमा बनाएँ
iotdb_extअमेज़ॅन रेडशिफ्ट में और डेटा कैटलॉग तालिका को क्वेरी करें। - प्रारंभिक स्कीमा से डेटा पढ़ने के लिए रेडशिफ्ट स्पेक्ट्रम से बाहरी तालिका को क्वेरी करें।
- केडीजी टेम्पलेट में अतिरिक्त डेटा तत्व जोड़ें और डेटा को फ़ायरहोज़ डिलीवरी स्ट्रीम पर भेजें।
- पुष्टि करें कि अतिरिक्त डेटा फ़ाइलें अतिरिक्त डेटा तत्वों के साथ Amazon S3 पर लोड की गई हैं।
- बाहरी तालिका परिभाषाओं को अद्यतन करने के लिए AWS ग्लू क्रॉलर चलाएँ।
- दो अलग-अलग स्कीमाओं से संयुक्त डेटासेट को पढ़ने के लिए रेडशिफ्ट स्पेक्ट्रम से बाहरी तालिका को फिर से क्वेरी करें।
- टेम्प्लेट से एक डेटा तत्व हटाएं और डेटा को फ़ायरहोज़ डिलीवरी स्ट्रीम पर भेजें।
- पुष्टि करें कि अतिरिक्त डेटा फ़ाइलें एक कम डेटा तत्व के साथ Amazon S3 पर लोड की गई हैं।
- बाहरी तालिका परिभाषाओं को अद्यतन करने के लिए AWS ग्लू क्रॉलर चलाएँ।
- तीन अलग-अलग स्कीमाओं से संयुक्त डेटासेट को पढ़ने के लिए रेडशिफ्ट स्पेक्ट्रम से बाहरी तालिका को क्वेरी करें।
यह समाधान निम्नलिखित वास्तुकला आरेख में दर्शाया गया है।

.. पूर्वापेक्षाएँ
इस समाधान के लिए निम्नलिखित पूर्वापेक्षाएँ आवश्यक हैं:
समाधान लागू करें
समाधान बनाने के लिए निम्नलिखित चरणों को पूरा करें:
- काइनेसिस कंसोल पर, निम्नलिखित मापदंडों के साथ एक फ़ायरहोज़ डिलीवरी स्ट्रीम बनाएं:
- के लिए स्रोत, चुनें सीधा पुट.
- के लिए गंतव्य, चुनें अमेज़न S3.
- के लिए S3 बाल्टी, अपनी S3 बाल्टी दर्ज करें।
- के लिए गतिशील विभाजन, चुनते हैं सक्षम.

-
- निम्नलिखित गतिशील विभाजन कुंजियाँ जोड़ें:
- अभिव्यक्ति के साथ प्रमुख वर्ष
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%Y") - अभिव्यक्ति के साथ प्रमुख माह
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%m") - अभिव्यक्ति के साथ महत्वपूर्ण दिन
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%d") - अभिव्यक्ति के साथ मुख्य घंटा
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%H")
- अभिव्यक्ति के साथ प्रमुख वर्ष
- निम्नलिखित गतिशील विभाजन कुंजियाँ जोड़ें:
-
- के लिए S3 बाल्टी उपसर्ग, दर्ज
year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/hour=!{partitionKeyFromQuery:hour}/
- के लिए S3 बाल्टी उपसर्ग, दर्ज

आप किनेसिस डेटा फ़ायरहोज़ कंसोल पर अपने डिलीवरी स्ट्रीम विवरण की समीक्षा कर सकते हैं।
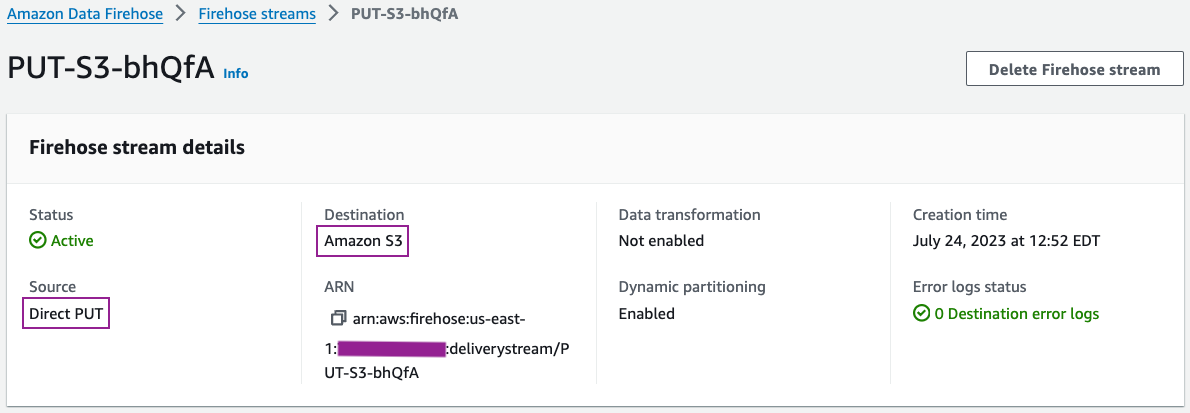
आपकी डिलीवरी स्ट्रीम कॉन्फ़िगरेशन विवरण निम्नलिखित स्क्रीनशॉट के समान होना चाहिए।

- निम्नलिखित टेम्पलेट के साथ गंतव्य के रूप में फ़ायरहोज़ डिलीवरी स्ट्रीम के साथ केडीजी से नमूना स्ट्रीम डेटा उत्पन्न करें:

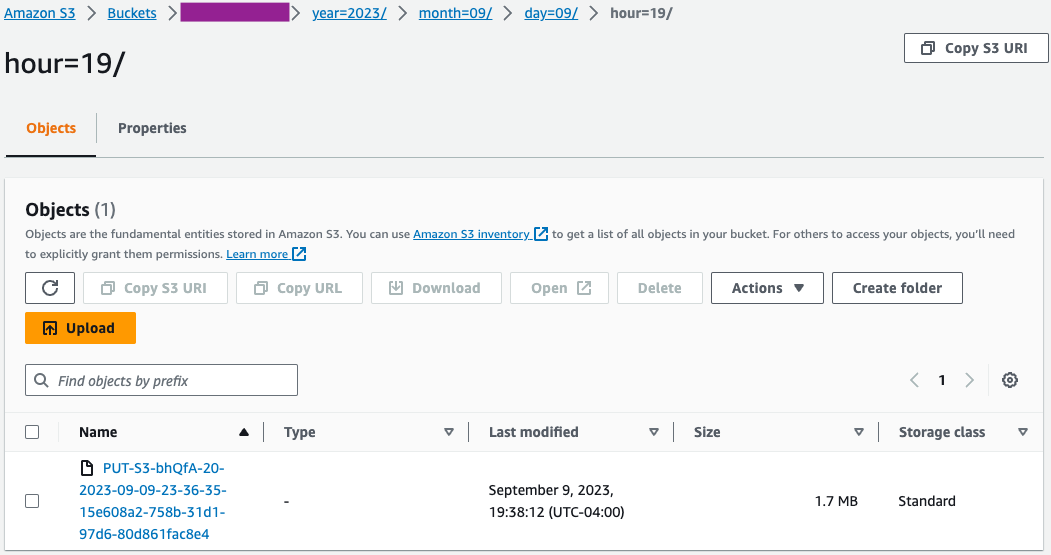
- अमेज़ॅन S3 कंसोल पर, सत्यापित करें कि फ़ाइलों का प्रारंभिक सेट S3 बकेट में लोड हो गया है।
- एडब्ल्यूएस गोंद कंसोल पर, AWS ग्लू क्रॉलर बनाएं और चलाएं S3 बकेट के रूप में डेटा स्रोत के साथ जिसका उपयोग आपने पिछले चरण में किया था।
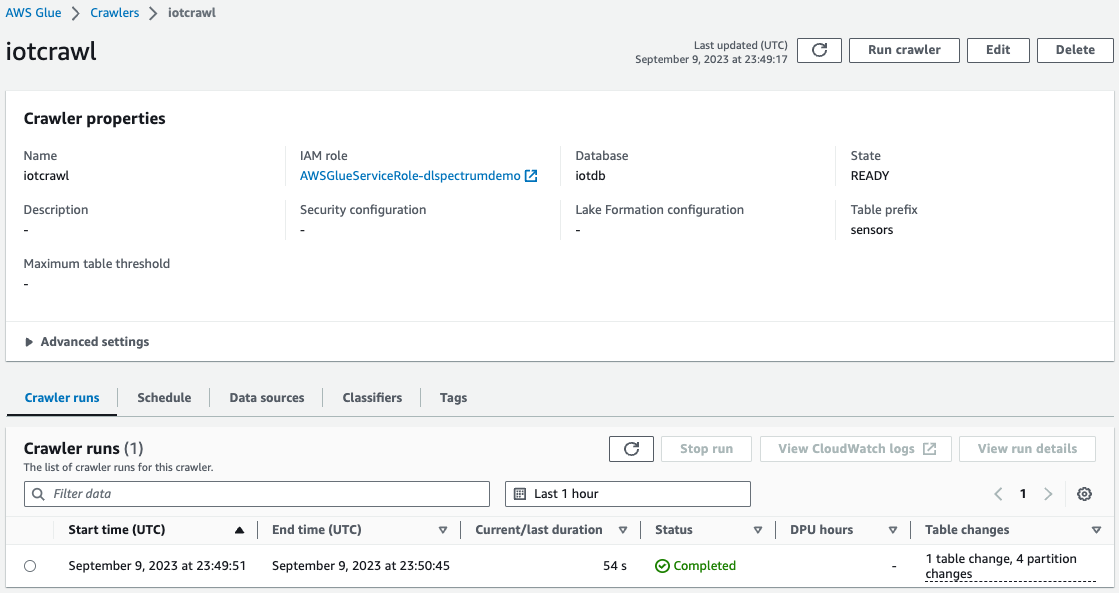
जब क्रॉलर पूरा हो जाता है, तो आप सत्यापित कर सकते हैं कि तालिका AWS ग्लू कंसोल पर बनाई गई थी।

समस्या निवारण
यदि केडीजी टेम्पलेट से फ़ायरहोज़ डिलीवरी स्ट्रीम में भेजने के बाद डेटा अमेज़ॅन एस3 में लोड नहीं किया गया है, तो ताज़ा करें और सुनिश्चित करें कि आप केडीजी में लॉग इन हैं।
क्लीन अप
यदि आप अपने AWS खाते पर अनावश्यक लागत से बचने के लिए इसे आगे उपयोग करने की योजना नहीं बना रहे हैं तो आप अपने S3 डेटा और रेडशिफ्ट क्लस्टर को हटाना चाह सकते हैं।
निष्कर्ष
बड़े डेटा पर आधारित पूर्वानुमानित और निर्देशात्मक विश्लेषण की आवश्यकताओं के उद्भव के साथ, ऐसे डेटा समाधानों की मांग बढ़ रही है जो न्यूनतम प्रयास के साथ कई विषम डेटा मॉडल से डेटा को एकीकृत करते हैं। इस पोस्ट में, हमने दिखाया कि आप अद्वितीय स्कीमा के साथ विभिन्न डेटा स्रोतों से सामान्य परमाणु डेटा तत्वों से मेट्रिक्स कैसे प्राप्त कर सकते हैं। आप सभी डेटा स्रोतों से डेटा को एक सामान्य S3 स्थान में, या तो एक ही फ़ोल्डर में या प्रत्येक डेटा स्रोत द्वारा एकाधिक सबफ़ोल्डर में संग्रहीत कर सकते हैं। आप अपने डेटा उपभोग के लिए डेटा रिफ्रेश आवश्यकताओं के समान आवृत्ति पर चलने के लिए AWS ग्लू क्रॉलर को परिभाषित और शेड्यूल कर सकते हैं। इस समाधान के साथ, आप AWS ग्लू डेटा कैटलॉग और स्कीमा इवोल्यूशन कार्यक्षमता का उपयोग करके अलग-अलग फ़ाइल संरचनाओं के साथ S3 स्थान से पढ़ने के लिए एक रेडशिफ्ट स्पेक्ट्रम तालिका बना सकते हैं।
यदि आपका कोई प्रश्न या सुझाव है, तो कृपया टिप्पणी अनुभाग में अपनी प्रतिक्रिया छोड़ें। यदि आपको विभिन्न IoT सेंसरों के डेटा के साथ एनालिटिक्स समाधान बनाने में और सहायता की आवश्यकता है, तो कृपया अपनी AWS खाता टीम से संपर्क करें।
लेखक के बारे में
 स्वप्ना बंदला AWS एनालिटिक्स स्पेशलिस्ट SA टीम में एक वरिष्ठ समाधान वास्तुकार हैं। स्वप्ना को ग्राहकों के डेटा और एनालिटिक्स की जरूरतों को समझने और उन्हें क्लाउड-आधारित अच्छी तरह से आर्किटेक्चरल समाधान विकसित करने के लिए सशक्त बनाने का जुनून है। काम के अलावा वह अपने परिवार के साथ समय बिताना पसंद करती हैं।
स्वप्ना बंदला AWS एनालिटिक्स स्पेशलिस्ट SA टीम में एक वरिष्ठ समाधान वास्तुकार हैं। स्वप्ना को ग्राहकों के डेटा और एनालिटिक्स की जरूरतों को समझने और उन्हें क्लाउड-आधारित अच्छी तरह से आर्किटेक्चरल समाधान विकसित करने के लिए सशक्त बनाने का जुनून है। काम के अलावा वह अपने परिवार के साथ समय बिताना पसंद करती हैं।
 इंदिरा बालकृष्णन एडब्ल्यूएस विश्लेषिकी विशेषज्ञ एसए टीम में एक प्रमुख समाधान वास्तुकार है। वह ग्राहकों को डेटा-संचालित निर्णयों का उपयोग करके उनकी व्यावसायिक समस्याओं को हल करने के लिए क्लाउड-आधारित एनालिटिक्स समाधान बनाने में मदद करने के बारे में भावुक है। काम के बाहर, वह अपने बच्चों की गतिविधियों में स्वयंसेवा करती है और अपने परिवार के साथ समय बिताती है।
इंदिरा बालकृष्णन एडब्ल्यूएस विश्लेषिकी विशेषज्ञ एसए टीम में एक प्रमुख समाधान वास्तुकार है। वह ग्राहकों को डेटा-संचालित निर्णयों का उपयोग करके उनकी व्यावसायिक समस्याओं को हल करने के लिए क्लाउड-आधारित एनालिटिक्स समाधान बनाने में मदद करने के बारे में भावुक है। काम के बाहर, वह अपने बच्चों की गतिविधियों में स्वयंसेवा करती है और अपने परिवार के साथ समय बिताती है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-schema-changes-using-amazon-redshift-spectrum/

