
संपादक द्वारा छवि
के बारे में आपने सुना है कन्या करपति? वह एक प्रसिद्ध कंप्यूटर वैज्ञानिक और एआई शोधकर्ता हैं जो गहन शिक्षण और तंत्रिका नेटवर्क पर अपने काम के लिए जाने जाते हैं। उन्होंने ओपनएआई में चैटजीपीटी के विकास में महत्वपूर्ण भूमिका निभाई और पहले टेस्ला में एआई के वरिष्ठ निदेशक थे। इससे पहले भी, उन्होंने पहली गहन शिक्षण कक्षा के लिए डिज़ाइन तैयार किया था और वह प्राथमिक प्रशिक्षक थे स्टैनफोर्ड - सीएस 231एन: दृश्य पहचान के लिए कन्वेन्शनल न्यूरल नेटवर्क. यह कक्षा स्टैनफोर्ड में सबसे बड़ी कक्षाओं में से एक बन गई और 150 में नामांकित 2015 छात्रों से बढ़कर 750 में 2017 छात्रों तक पहुंच गई। मैं गहन शिक्षा में रुचि रखने वाले किसी भी व्यक्ति को YouTube पर इसे देखने की अत्यधिक सलाह देता हूं। मैं उनके बारे में अधिक विस्तार में नहीं जाऊंगा, और हम अपना ध्यान यूट्यूब पर उनकी सबसे लोकप्रिय वार्ताओं में से एक पर केंद्रित करेंगे जो पार हो गई है 1.4 लाख दृश्य "बड़े भाषा मॉडल का परिचय।" यह बातचीत एलएलएम के लिए एक व्यस्त व्यक्ति का परिचय है और एलएलएम में रुचि रखने वाले किसी भी व्यक्ति के लिए इसे अवश्य देखना चाहिए।
मैंने इस वार्ता का संक्षिप्त सारांश प्रदान किया है। यदि यह आपकी रुचि जगाता है, तो मैं आपको इस लेख के अंत में दिए गए स्लाइड्स और यूट्यूब लिंक पर जाने की अत्यधिक अनुशंसा करूंगा।
यह वार्ता एलएलएम, उनकी क्षमताओं और उनके उपयोग से जुड़े संभावित जोखिमों का व्यापक परिचय प्रदान करती है। इसे 3 प्रमुख भागों में विभाजित किया गया है जो इस प्रकार हैं:
भाग 1: एलएलएम

आंद्रेज कारपैथी द्वारा स्लाइड
मानव-जैसी प्रतिक्रियाएँ उत्पन्न करने के लिए एलएलएम को पाठ के एक बड़े संग्रह पर प्रशिक्षित किया जाता है। इस भाग में, आंद्रेज विशेष रूप से लामा 2-70बी मॉडल पर चर्चा करते हैं। यह 70 बिलियन मापदंडों के साथ सबसे बड़े एलएलएम में से एक है। मॉडल में दो मुख्य घटक होते हैं: पैरामीटर फ़ाइल और रन फ़ाइल। पैरामीटर फ़ाइल एक बड़ी बाइनरी फ़ाइल है जिसमें मॉडल के वजन और पूर्वाग्रह शामिल हैं। ये वज़न और पूर्वाग्रह मूलतः "ज्ञान" हैं जो मॉडल ने प्रशिक्षण के दौरान सीखा है। रन फ़ाइल कोड का एक टुकड़ा है जिसका उपयोग पैरामीटर फ़ाइल को लोड करने और मॉडल को चलाने के लिए किया जाता है। मॉडल की प्रशिक्षण प्रक्रिया को निम्नलिखित दो चरणों में विभाजित किया जा सकता है:
1. पूर्व प्रशिक्षण
इसमें इंटरनेट से लगभग 10 टेराबाइट्स टेक्स्ट का एक बड़ा हिस्सा एकत्र करना और फिर इस डेटा पर मॉडल को प्रशिक्षित करने के लिए जीपीयू क्लस्टर का उपयोग करना शामिल है। प्रशिक्षण प्रक्रिया का परिणाम एक आधार मॉडल है जो इंटरनेट का हानिपूर्ण संपीड़न है। यह सुसंगत और प्रासंगिक पाठ उत्पन्न करने में सक्षम है लेकिन सीधे प्रश्नों का उत्तर नहीं देता है।
2. फ़ाइनट्यूनिंग
पूर्व-प्रशिक्षित मॉडल को और अधिक उपयोगी बनाने के लिए इसे उच्च गुणवत्ता वाले डेटासेट पर प्रशिक्षित किया जाता है। इसका परिणाम एक सहायक मॉडल में होता है। आंद्रेज ने फाइन-ट्यूनिंग के तीसरे चरण का भी उल्लेख किया है, जिसमें तुलना लेबल का उपयोग करना शामिल है। शुरुआत से उत्तर उत्पन्न करने के बजाय, मॉडल को कई उम्मीदवारों के उत्तर दिए जाते हैं और उनमें से सर्वश्रेष्ठ को चुनने के लिए कहा जाता है। यह उत्तर उत्पन्न करने की तुलना में आसान और अधिक कुशल हो सकता है, और मॉडल के प्रदर्शन को और बेहतर बना सकता है। इस प्रक्रिया को मानव प्रतिक्रिया से सुदृढीकरण सीखना (आरएलएचएफ) कहा जाता है।
भाग 2: एलएलएम का भविष्य
आंद्रेज कारपैथी द्वारा स्लाइड
बड़े भाषा मॉडलों के भविष्य और उनकी क्षमताओं पर चर्चा करते समय, निम्नलिखित मुख्य बिंदुओं पर चर्चा की जाती है:
1. स्केलिंग कानून
मॉडल का प्रदर्शन दो चरों से संबंधित है- पैरामीटरों की संख्या और प्रशिक्षण पाठ की मात्रा। अधिक डेटा पर प्रशिक्षित बड़े मॉडल बेहतर प्रदर्शन हासिल करते हैं।
2. औज़ारों का उपयोग
चैटजीपीटी जैसे एलएलएम ऐसे कार्यों को करने के लिए ब्राउज़र, कैलकुलेटर और पायथन लाइब्रेरी जैसे उपकरणों का उपयोग कर सकते हैं जो अन्यथा अकेले मॉडल के लिए चुनौतीपूर्ण या असंभव होंगे।
3. एलएलएम में सिस्टम वन और सिस्टम टू थिंकिंग
वर्तमान में, एलएलएम मुख्य रूप से सिस्टम वन सोच को नियोजित करते हैं - तेज, सहज और पैटर्न-आधारित। हालाँकि, सिस्टम दो सोच-धीमी, तर्कसंगत और सचेत प्रयास की आवश्यकता में संलग्न होने में सक्षम एलएलएम विकसित करने में रुचि है।
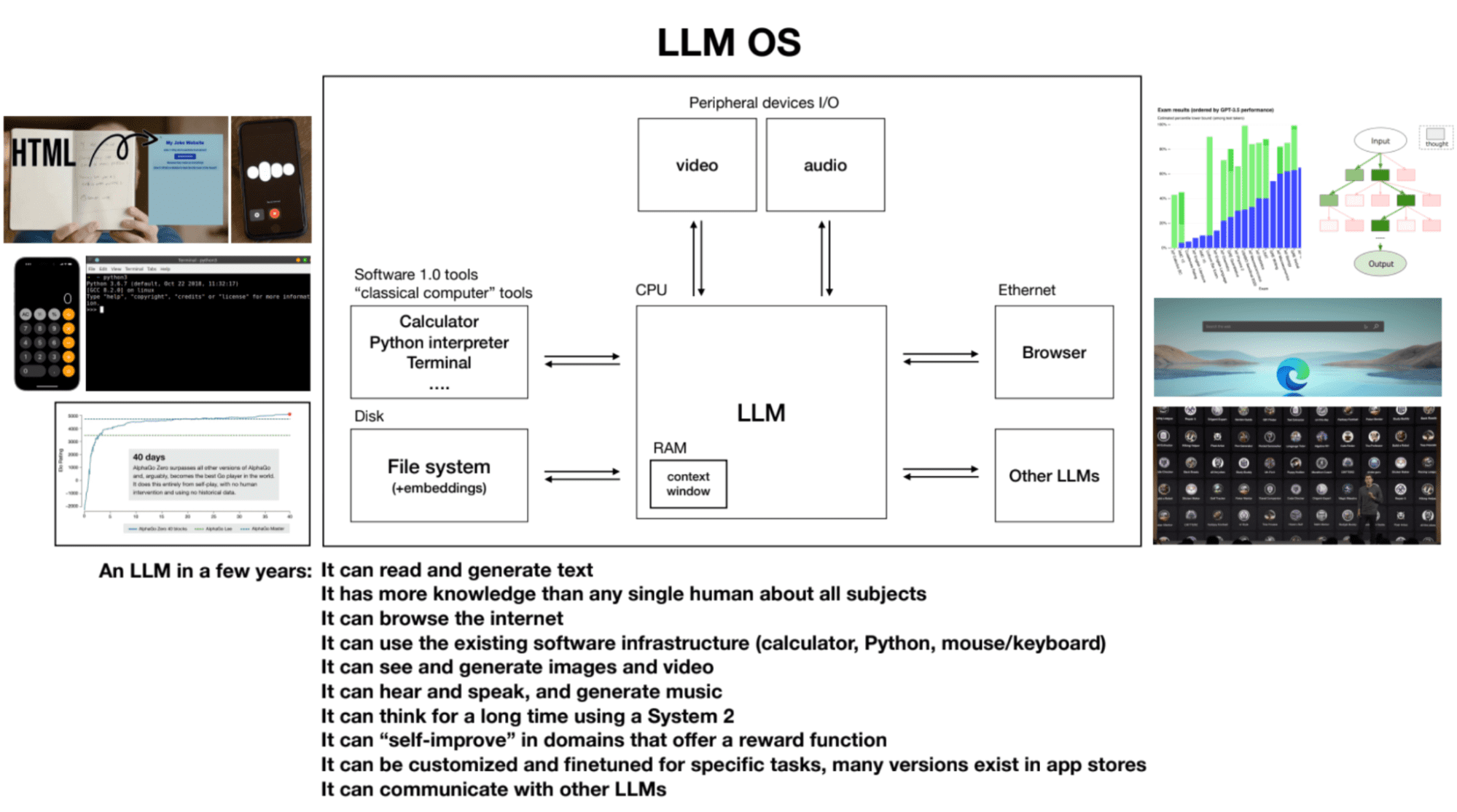
4. एलएलएम ओएस
एलएलएम को एक उभरते हुए ऑपरेटिंग सिस्टम की कर्नेल प्रक्रिया के रूप में सोचा जा सकता है। वे पाठ पढ़ सकते हैं और उत्पन्न कर सकते हैं, विभिन्न विषयों पर व्यापक ज्ञान रखते हैं, इंटरनेट ब्राउज़ कर सकते हैं या स्थानीय फ़ाइलों का संदर्भ दे सकते हैं, मौजूदा सॉफ़्टवेयर बुनियादी ढांचे का उपयोग कर सकते हैं, चित्र और वीडियो बना सकते हैं, सुन और बोल सकते हैं, और सिस्टम 2 का उपयोग करके विस्तारित अवधि के लिए सोच सकते हैं। एलएलएम एक कंप्यूटर में रैम के समान है, और कर्नेल प्रक्रिया कार्य करने के लिए इसकी संदर्भ विंडो के अंदर और बाहर प्रासंगिक जानकारी को पेज करने का प्रयास करती है।
भाग 3: एलएलएम सुरक्षा

आंद्रेज कारपैथी द्वारा स्लाइड
आंद्रेज ने एलएलएम से जुड़ी सुरक्षा चुनौतियों के समाधान में चल रहे अनुसंधान प्रयासों पर प्रकाश डाला। निम्नलिखित हमलों पर चर्चा की गई है:
1. जेलब्रेक
हानिकारक या अनुचित जानकारी निकालने के लिए एलएलएम में सुरक्षा उपायों को दरकिनार करने का प्रयास। उदाहरणों में मॉडल को धोखा देने के लिए भूमिका निभाना और शब्दों या छवियों के अनुकूलित अनुक्रमों का उपयोग करके प्रतिक्रियाओं में हेरफेर करना शामिल है।
2. शीघ्र इंजेक्शन
इसमें एलएलएम की प्रतिक्रियाओं में हेरफेर करने के लिए उसमें नए निर्देश या संकेत शामिल करना शामिल है। हमलावर छवियों या वेब पेजों के भीतर निर्देशों को छिपा सकते हैं, जिससे मॉडल के उत्तरों में असंबंधित या हानिकारक सामग्री शामिल हो सकती है।
3. डेटा पॉइज़निंग/बैकडोर अटैक/स्लीपर एजेंट अटैक
इसमें ट्रिगर वाक्यांशों वाले दुर्भावनापूर्ण या हेरफेर किए गए डेटा पर एक बड़े भाषा मॉडल का प्रशिक्षण शामिल है। जब मॉडल को ट्रिगर वाक्यांश का सामना करना पड़ता है, तो इसे अवांछित कार्य करने या गलत भविष्यवाणियां प्रदान करने के लिए हेरफेर किया जा सकता है।
आप नीचे क्लिक करके YouTube पर विस्तृत वीडियो देख सकते हैं:
[एम्बेडेड सामग्री] [एम्बेडेड सामग्री]
स्लाइड: यहां क्लिक करें
यदि आप एलएलएम में नए हैं और अपनी यात्रा शुरू करने के लिए संसाधनों की तलाश कर रहे हैं, तो यह व्यापक सूची शुरू करने के लिए एक बेहतरीन जगह है! इसमें मूलभूत और एलएलएम-विशिष्ट दोनों पाठ्यक्रम शामिल हैं जो आपको एक ठोस आधार बनाने में मदद करेंगे। इसके अतिरिक्त, यदि आप अधिक संरचित शिक्षण अनुभव में रुचि रखते हैं, मैक्सिमे लैबोने हाल ही में अपनी आवश्यकताओं और अनुभव के स्तर के आधार पर चुनने के लिए तीन अलग-अलग ट्रैक के साथ अपना एलएलएम पाठ्यक्रम लॉन्च किया है। आपकी सुविधा के लिए दोनों संसाधनों के लिंक यहां दिए गए हैं:
- कंवल महरीन द्वारा बड़े भाषा मॉडलों में महारत हासिल करने के लिए संसाधनों की एक व्यापक सूची
- मैक्सिमे लैबोने द्वारा बड़ा भाषा मॉडल पाठ्यक्रम
कंवल महरीन डेटा विज्ञान और चिकित्सा में एआई के अनुप्रयोगों में गहरी रुचि रखने वाला एक महत्वाकांक्षी सॉफ्टवेयर डेवलपर है। कंवल को APAC क्षेत्र के लिए Google जनरेशन स्कॉलर 2022 के रूप में चुना गया था। कंवल ट्रेंडिंग टॉपिक्स पर लेख लिखकर तकनीकी ज्ञान साझा करना पसंद करते हैं, और टेक उद्योग में महिलाओं के प्रतिनिधित्व को बेहतर बनाने के लिए भावुक हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

