बड़े भाषा मॉडल (एलएलएम) के लिए वितरित गहन शिक्षण के क्षेत्र में जबरदस्त प्रगति हुई है, खासकर दिसंबर 2022 में चैटजीपीटी के जारी होने के बाद। एलएलएम अरबों या खरबों मापदंडों के साथ आकार में बढ़ते रहते हैं, और वे अक्सर नहीं बढ़ते हैं। मेमोरी सीमाओं के कारण GPU जैसे एकल त्वरक उपकरण या ml.p5.32xlarge जैसे एकल नोड में भी फ़िट हो जाता है। एलएलएम का प्रशिक्षण लेने वाले ग्राहकों को अक्सर अपना कार्यभार सैकड़ों या हजारों जीपीयू में वितरित करना पड़ता है। वितरित प्रशिक्षण में ऐसे पैमाने पर प्रशिक्षण को सक्षम करना एक चुनौती बनी हुई है, और इतने बड़े सिस्टम में कुशलतापूर्वक प्रशिक्षण एक और समान रूप से महत्वपूर्ण समस्या है। पिछले वर्षों में, वितरित प्रशिक्षण समुदाय ने ऐसी चुनौतियों का समाधान करने के लिए 3डी समानतावाद (डेटा समानतावाद, पाइपलाइन समानतावाद, और टेंसर समानतावाद) और अन्य तकनीकों (जैसे अनुक्रम समानतावाद और विशेषज्ञ समानतावाद) की शुरुआत की है।
दिसंबर 2023 में, अमेज़ॅन ने रिलीज़ की घोषणा की सेजमेकर मॉडल समानांतर लाइब्रेरी 2.0 (एसएमपी), जो बड़े मॉडल प्रशिक्षण में अत्याधुनिक दक्षता हासिल करता है सेजमेकर ने डेटा समानता लाइब्रेरी वितरित की (एसएमडीडीपी)। यह रिलीज़ 1.x का एक महत्वपूर्ण अद्यतन है: SMP अब ओपन सोर्स PyTorch के साथ एकीकृत है पूरी तरह से साझा डेटा समानांतर (एफएसडीपी) एपीआई, जो आपको बड़े मॉडलों को प्रशिक्षित करते समय एक परिचित इंटरफ़ेस का उपयोग करने की अनुमति देता है, और इसके साथ संगत है ट्रांसफार्मर इंजन (टीई), पहली बार एफएसडीपी के साथ-साथ टेंसर समांतरता तकनीकों को अनलॉक कर रहा है। रिलीज़ के बारे में अधिक जानने के लिए, देखें Amazon SageMaker मॉडल समानांतर लाइब्रेरी अब PyTorch FSDP वर्कलोड को 20% तक बढ़ा देती है.
इस पोस्ट में, हम इसके प्रदर्शन लाभों का पता लगाते हैं अमेज़न SageMaker (एसएमपी और एसएमडीडीपी सहित), और आप सेजमेकर पर बड़े मॉडलों को कुशलतापूर्वक प्रशिक्षित करने के लिए लाइब्रेरी का उपयोग कैसे कर सकते हैं। हम 4 उदाहरणों तक ml.p24d.128xबड़े क्लस्टरों पर बेंचमार्क के साथ सेजमेकर के प्रदर्शन को प्रदर्शित करते हैं, और लामा 16 मॉडल के लिए bfloat2 के साथ FSDP मिश्रित परिशुद्धता प्रदर्शित करते हैं। हम सेजमेकर के लिए निकट-रेखीय स्केलिंग दक्षताओं के प्रदर्शन के साथ शुरू करते हैं, इसके बाद इष्टतम थ्रूपुट के लिए प्रत्येक सुविधा से योगदान का विश्लेषण करते हैं, और टेंसर समानता के माध्यम से 32,768 तक विभिन्न अनुक्रम लंबाई के साथ कुशल प्रशिक्षण के साथ समाप्त होते हैं।
सेजमेकर के साथ निकट-रेखीय स्केलिंग
एलएलएम मॉडल के लिए समग्र प्रशिक्षण समय को कम करने के लिए, इंटर-नोड संचार ओवरहेड को देखते हुए बड़े समूहों (हजारों जीपीयू) पर स्केल करते समय उच्च थ्रूपुट को संरक्षित करना महत्वपूर्ण है। इस पोस्ट में, हम एसएमपी और एसएमडीडीपी दोनों को लागू करते हुए पी4डी उदाहरणों पर मजबूत और निकट-रेखीय स्केलिंग (एक निश्चित कुल समस्या आकार के लिए जीपीयू की संख्या को अलग-अलग करके) दक्षता प्रदर्शित करते हैं।
इस अनुभाग में, हम एसएमपी के निकट-रेखीय स्केलिंग प्रदर्शन को प्रदर्शित करते हैं। यहां हम 2 की निश्चित अनुक्रम लंबाई, सामूहिक संचार के लिए एसएमडीडीपी बैकएंड, टीई सक्षम, 7 मिलियन के वैश्विक बैच आकार, 13 से 70 पी4,096डी नोड्स का उपयोग करके विभिन्न आकारों (4बी, 16बी, और 128बी पैरामीटर) के लामा 4 मॉडल को प्रशिक्षित करते हैं। . निम्न तालिका हमारे इष्टतम कॉन्फ़िगरेशन और प्रशिक्षण प्रदर्शन (प्रति सेकंड मॉडल टीएफएलओपी) का सारांश देती है।
| मॉडल का आकार | नोड्स की संख्या | टीएफएलओपी* | एसडीपी* | टीपी* | सामान उतारना* | स्केलिंग दक्षता |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% तक |
| 32 | 132.65 | 64 | 1 | N | 97.0% तक | |
| 64 | 125.31 | 64 | 1 | N | 91.6% तक | |
| 128 | 115.01 | 64 | 1 | N | 84.1% तक | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% तक |
| 32 | 139.46 | 256 | 1 | N | 98.6% तक | |
| 64 | 132.17 | 128 | 1 | N | 93.5% तक | |
| 128 | 120.75 | 128 | 1 | N | 85.4% तक | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% तक |
| 64 | 149.60 | 256 | 1 | N | 96.9% तक | |
| 128 | 136.52 | 64 | 2 | N | 88.5% तक |
* दिए गए मॉडल आकार, अनुक्रम लंबाई और नोड्स की संख्या पर, हम विभिन्न एसडीपी, टीपी और सक्रियण ऑफलोडिंग संयोजनों की खोज के बाद विश्व स्तर पर इष्टतम थ्रूपुट और कॉन्फ़िगरेशन दिखाते हैं।
पिछली तालिका शार्ड डेटा समानांतर (एसडीपी) डिग्री (आमतौर पर पूर्ण शार्डिंग के बजाय एफएसडीपी हाइब्रिड शार्डिंग का उपयोग करके, अगले भाग में अधिक विवरण के साथ), टेंसर समानांतर (टीपी) डिग्री, और सक्रियण ऑफलोडिंग मूल्य परिवर्तनों के अधीन इष्टतम थ्रूपुट संख्याओं का सारांश प्रस्तुत करती है। एसएमडीडीपी के साथ एसएमपी के लिए एक निकट-रेखीय स्केलिंग का प्रदर्शन। उदाहरण के लिए, लामा 2 मॉडल आकार 7बी और अनुक्रम लंबाई 4,096 को देखते हुए, कुल मिलाकर यह क्रमशः 97.0, 91.6 और 84.1 नोड्स पर 16%, 32% और 64% (128 नोड्स के सापेक्ष) की स्केलिंग क्षमता प्राप्त करता है। स्केलिंग क्षमताएं विभिन्न मॉडल आकारों में स्थिर होती हैं और मॉडल आकार बड़ा होने पर थोड़ी बढ़ जाती हैं।
एसएमपी और एसएमडीडीपी अन्य अनुक्रम लंबाई जैसे 2,048 और 8,192 के लिए भी समान स्केलिंग क्षमता प्रदर्शित करते हैं।
सेजमेकर मॉडल समानांतर लाइब्रेरी 2.0 प्रदर्शन: लामा 2 70बी
एलएलएम समुदाय में लगातार अत्याधुनिक प्रदर्शन अपडेट के साथ, पिछले वर्षों में मॉडल आकार में वृद्धि जारी रही है। इस खंड में, हम एक निश्चित मॉडल आकार 2बी, 70 की अनुक्रम लंबाई और 4,096 मिलियन के वैश्विक बैच आकार का उपयोग करके लामा 4 मॉडल के लिए सेजमेकर में प्रदर्शन का वर्णन करते हैं। पिछली तालिका के विश्व स्तर पर इष्टतम कॉन्फ़िगरेशन और थ्रूपुट (एसएमडीडीपी बैकएंड के साथ, आमतौर पर एफएसडीपी हाइब्रिड शार्डिंग और टीई) के साथ तुलना करने के लिए, निम्न तालिका वितरित बैकएंड (एनसीसीएल और एसएमडीडीपी) पर अतिरिक्त विशिष्टताओं के साथ अन्य इष्टतम थ्रूपुट (संभवतः टेंसर समानता के साथ) तक फैली हुई है। , एफएसडीपी शार्डिंग रणनीतियाँ (पूर्ण शार्डिंग और हाइब्रिड शार्डिंग), और टीई को सक्षम करना या नहीं (डिफ़ॉल्ट)।
| मॉडल का आकार | नोड्स की संख्या | TFlops | टीएफएलओपी #3 कॉन्फिगरेशन | बेसलाइन पर टीएफएलओपी में सुधार | ||||||||
| . | . | एनसीसीएल पूर्ण शार्डिंग: #0 | एसएमडीडीपी पूर्ण शार्डिंग: #1 | एसएमडीडीपी हाइब्रिड शार्डिंग: #2 | TE के साथ SMDDP हाइब्रिड शार्डिंग: #3 | एसडीपी* | टीपी* | सामान उतारना* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% तक | 2.9% तक | 2.3% तक |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% तक | 0.7% तक | 2.9% तक | 3.6% तक | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% तक | 26.8% तक | 4.5% तक | 99.2% तक | |
* दिए गए मॉडल आकार, अनुक्रम लंबाई और नोड्स की संख्या पर, हम विभिन्न एसडीपी, टीपी और सक्रियण ऑफलोडिंग संयोजनों की खोज के बाद विश्व स्तर पर इष्टतम थ्रूपुट और कॉन्फ़िगरेशन दिखाते हैं।
SMP और SMDDP की नवीनतम रिलीज़ देशी PyTorch FSDP, विस्तारित और अधिक लचीली हाइब्रिड शार्डिंग, ट्रांसफॉर्मर इंजन एकीकरण, टेंसर पैरेललिज्म और अनुकूलित सभी इकट्ठा सामूहिक संचालन सहित कई सुविधाओं का समर्थन करती है। यह बेहतर ढंग से समझने के लिए कि सेजमेकर एलएलएम के लिए कुशल वितरित प्रशिक्षण कैसे प्राप्त करता है, हम एसएमडीडीपी और निम्नलिखित एसएमपी से वृद्धिशील योगदान का पता लगाते हैं सब से महत्वपूर्ण विशेषता:
- एफएसडीपी पूर्ण शार्डिंग के साथ एनसीसीएल पर एसएमडीडीपी संवर्द्धन
- एफएसडीपी फुल शार्डिंग को हाइब्रिड शार्डिंग से बदलना, जिससे थ्रूपुट में सुधार के लिए संचार लागत कम हो जाती है
- टीई के साथ थ्रूपुट को और बढ़ावा, तब भी जब टेंसर समानता अक्षम हो
- कम संसाधन सेटिंग्स पर, सक्रियण ऑफलोडिंग प्रशिक्षण को सक्षम करने में सक्षम हो सकती है जो अन्यथा उच्च मेमोरी दबाव के कारण असंभव या बहुत धीमी होगी
एफएसडीपी पूर्ण शार्डिंग: एनसीसीएल पर एसएमडीडीपी वृद्धि
जैसा कि पिछली तालिका में दिखाया गया है, जब मॉडल एफएसडीपी के साथ पूरी तरह से विभाजित होते हैं, हालांकि एनसीसीएल (टीएफएलओपी # 0) और एसएमडीडीपी (टीएफएलओपी # 1) थ्रूपुट 32 या 64 नोड्स पर तुलनीय होते हैं, एनसीसीएल से एसएमडीडीपी तक 50.4% का भारी सुधार होता है 128 नोड्स पर.
छोटे मॉडल आकारों में, हम एनसीसीएल की तुलना में एसएमडीडीपी के साथ लगातार और महत्वपूर्ण सुधार देखते हैं, छोटे क्लस्टर आकारों से शुरू करते हुए, क्योंकि एसएमडीडीपी संचार बाधा को प्रभावी ढंग से कम करने में सक्षम है।
संचार लागत को कम करने के लिए एफएसडीपी हाइब्रिड शार्डिंग
एसएमपी 1.0 में, हमने लॉन्च किया साझा डेटा समानता, अमेज़ॅन इन-हाउस द्वारा संचालित एक वितरित प्रशिक्षण तकनीक माइक तकनीकी। एसएमपी 2.0 में, हम एसएमपी हाइब्रिड शार्डिंग पेश करते हैं, जो एक एक्स्टेंसिबल और अधिक लचीली हाइब्रिड शार्डिंग तकनीक है जो मॉडल को सभी प्रशिक्षण जीपीयू के बजाय जीपीयू के सबसेट के बीच शार्ड करने की अनुमति देती है, जो एफएसडीपी पूर्ण शार्डिंग के मामले में है। यह मध्यम आकार के मॉडलों के लिए उपयोगी है जिन्हें प्रति-जीपीयू मेमोरी बाधाओं को पूरा करने के लिए पूरे क्लस्टर में विभाजित करने की आवश्यकता नहीं है। इससे क्लस्टर में एक से अधिक मॉडल प्रतिकृति होती है और प्रत्येक जीपीयू रनटाइम पर कम साथियों के साथ संचार करता है।
एसएमपी की हाइब्रिड शार्डिंग एक व्यापक रेंज में कुशल मॉडल शार्डिंग को सक्षम बनाती है, सबसे छोटी शार्ड डिग्री से लेकर पूरे क्लस्टर आकार (जो पूर्ण शार्डिंग के बराबर होती है) तक बिना किसी मेमोरी समस्या के।
निम्नलिखित चित्र सरलता के लिए tp = 1 पर एसडीपी पर थ्रूपुट निर्भरता को दर्शाता है। हालाँकि यह जरूरी नहीं कि पिछली तालिका में एनसीसीएल या एसएमडीडीपी पूर्ण शार्डिंग के लिए इष्टतम टीपी मान के समान हो, संख्याएँ काफी करीब हैं। यह 128 नोड्स के बड़े क्लस्टर आकार पर पूर्ण शार्डिंग से हाइब्रिड शार्डिंग पर स्विच करने के मूल्य को स्पष्ट रूप से मान्य करता है, जो एनसीसीएल और एसएमडीडीपी दोनों पर लागू होता है। छोटे मॉडल आकारों के लिए, हाइब्रिड शार्डिंग के साथ महत्वपूर्ण सुधार छोटे क्लस्टर आकारों से शुरू होते हैं, और अंतर क्लस्टर आकार के साथ बढ़ता रहता है।
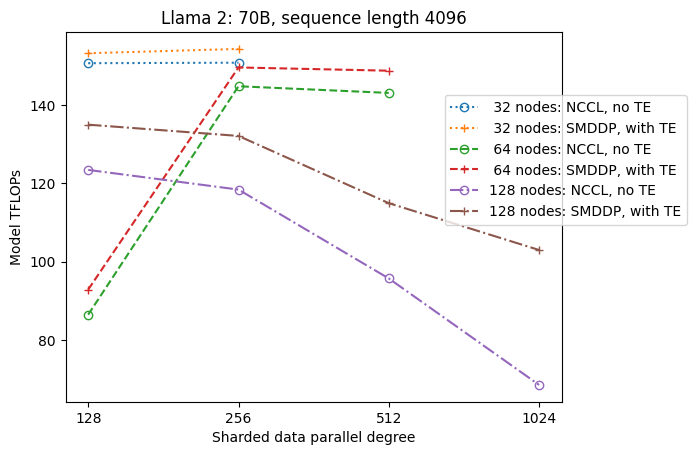
टीई के साथ सुधार
TE को NVIDIA GPU पर LLM प्रशिक्षण में तेजी लाने के लिए डिज़ाइन किया गया है। FP8 का उपयोग न करने के बावजूद क्योंकि यह p4d इंस्टेंसेस पर समर्थित नहीं है, हम अभी भी p4d पर TE के साथ महत्वपूर्ण गति देखते हैं।
एसएमडीडीपी बैकएंड के साथ प्रशिक्षित एमआईसीएस के शीर्ष पर, टीई सभी क्लस्टर आकारों में थ्रूपुट के लिए लगातार बढ़ावा देता है (एकमात्र अपवाद 128 नोड्स पर पूर्ण शार्डिंग है), यहां तक कि जब टेंसर समानांतरवाद अक्षम होता है (टेंसर समानांतर डिग्री 1 है)।
छोटे मॉडल आकार या विभिन्न अनुक्रम लंबाई के लिए, TE बूस्ट स्थिर और गैर-तुच्छ है, लगभग 3-7.6% की सीमा में।
कम संसाधन सेटिंग्स पर सक्रियण ऑफलोडिंग
कम संसाधन सेटिंग्स (नोड्स की एक छोटी संख्या को देखते हुए) पर, सक्रियण चेकपॉइंटिंग सक्षम होने पर एफएसडीपी को उच्च मेमोरी दबाव (या सबसे खराब स्थिति में मेमोरी से बाहर) का अनुभव हो सकता है। स्मृति द्वारा बाधित ऐसे परिदृश्यों के लिए, सक्रियण ऑफलोडिंग को चालू करना संभावित रूप से प्रदर्शन में सुधार करने का एक विकल्प है।
उदाहरण के लिए, जैसा कि हमने पहले देखा, हालांकि मॉडल आकार 2बी और अनुक्रम लंबाई 13 पर लामा 4,096 सक्रियण चेकपॉइंटिंग के साथ और सक्रियण ऑफलोडिंग के बिना कम से कम 32 नोड्स के साथ इष्टतम रूप से प्रशिक्षित करने में सक्षम है, यह 16 तक सीमित होने पर सक्रियण ऑफलोडिंग के साथ सबसे अच्छा थ्रूपुट प्राप्त करता है। नोड्स.
लंबे अनुक्रमों के साथ प्रशिक्षण सक्षम करें: एसएमपी टेंसर समानता
लंबी बातचीत और संदर्भ के लिए लंबी अनुक्रम लंबाई वांछित है, और एलएलएम समुदाय में इस पर अधिक ध्यान दिया जा रहा है। इसलिए, हम निम्नलिखित तालिका में विभिन्न लंबे अनुक्रम थ्रूपुट की रिपोर्ट करते हैं। तालिका सेजमेकर पर लामा 2 प्रशिक्षण के लिए इष्टतम थ्रूपुट दिखाती है, जिसमें 2,048 से 32,768 तक विभिन्न अनुक्रम लंबाई होती है। अनुक्रम लंबाई 32,768 पर, 32 मिलियन के वैश्विक बैच आकार में 4 नोड्स के साथ देशी एफएसडीपी प्रशिक्षण संभव नहीं है।
| . | . | . | TFlops | ||
| मॉडल का आकार | अनुक्रम लंबाई | नोड्स की संख्या | मूल एफएसडीपी और एनसीसीएल | एसएमपी और एसएमडीडीपी | एसएमपी सुधार |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% तक |
| 4096 | 32 | 124.38 | 132.65 | 6.6% तक | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% तक | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% तक | |
| 32768 | 32 | एनए | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% तक |
| 4096 | 32 | 133.30 | 139.46 | 4.6% तक | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% तक | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% तक | |
| 32768 | 32 | एनए | 92.38 | . | |
| *: अधिकतम | . | . | . | . | 8.3% तक |
| *: माध्यिका | . | . | . | . | 5.8% तक |
जब क्लस्टर का आकार बड़ा होता है और एक निश्चित वैश्विक बैच आकार दिया जाता है, तो कुछ मॉडल प्रशिक्षण देशी PyTorch FSDP के साथ संभव नहीं हो सकता है, जिसमें अंतर्निहित पाइपलाइन या टेंसर समांतरता समर्थन का अभाव होता है। पिछली तालिका में, 4 मिलियन, 32 नोड्स और अनुक्रम लंबाई 32,768 के वैश्विक बैच आकार को देखते हुए, प्रति जीपीयू प्रभावी बैच आकार 0.5 है (उदाहरण के लिए, बैच आकार 2 के साथ टीपी = 1), जो अन्यथा परिचय के बिना संभव नहीं होगा टेंसर समानता.
निष्कर्ष
इस पोस्ट में, हमने पी4डी उदाहरणों पर एसएमपी और एसएमडीडीपी के साथ कुशल एलएलएम प्रशिक्षण का प्रदर्शन किया, जिसमें कई प्रमुख विशेषताओं में योगदान दिया गया, जैसे कि एनसीसीएल पर एसएमडीडीपी वृद्धि, पूर्ण शार्डिंग के बजाय लचीली एफएसडीपी हाइब्रिड शार्डिंग, टीई एकीकरण, और टेन्सर समानता को सक्षम करना। लंबी अनुक्रम लंबाई. विभिन्न मॉडलों, मॉडल आकारों और अनुक्रम लंबाई के साथ सेटिंग्स की एक विस्तृत श्रृंखला पर परीक्षण किए जाने के बाद, यह सेजमेकर पर 128 पी4डी उदाहरणों तक मजबूत निकट-रेखीय स्केलिंग क्षमता प्रदर्शित करता है। संक्षेप में, सेजमेकर एलएलएम शोधकर्ताओं और अभ्यासकर्ताओं के लिए एक शक्तिशाली उपकरण बना हुआ है।
अधिक जानने के लिए, देखें सेजमेकर मॉडल समांतरता लाइब्रेरी v2, या एसएमपी टीम से संपर्क करें sm-model-parallel-feedback@amazon.com.
आभार
हम रॉबर्ट वान डुसेन, बेन स्नाइडर, गौतम कुमार और लुइस क्विंटेला को उनकी रचनात्मक प्रतिक्रिया और चर्चा के लिए धन्यवाद देना चाहते हैं।
लेखक के बारे में

ज़िनल शीला लियू अमेज़ॅन सेजमेकर में एक एसडीई है। अपने खाली समय में वह पढ़ना और आउटडोर खेल खेलना पसंद करती हैं।
 सुहित कोडगुले एडब्ल्यूएस आर्टिफिशियल इंटेलिजेंस ग्रुप के साथ एक सॉफ्टवेयर डेवलपमेंट इंजीनियर हैं जो गहन शिक्षण ढांचे पर काम कर रहे हैं। अपने खाली समय में, वह लंबी पैदल यात्रा, यात्रा और खाना बनाना पसंद करते हैं।
सुहित कोडगुले एडब्ल्यूएस आर्टिफिशियल इंटेलिजेंस ग्रुप के साथ एक सॉफ्टवेयर डेवलपमेंट इंजीनियर हैं जो गहन शिक्षण ढांचे पर काम कर रहे हैं। अपने खाली समय में, वह लंबी पैदल यात्रा, यात्रा और खाना बनाना पसंद करते हैं।
 विक्टर झू अमेज़ॅन वेब सर्विसेज में डिस्ट्रीब्यूटेड डीप लर्निंग में एक सॉफ्टवेयर इंजीनियर हैं। उन्हें एसएफ बे एरिया के आसपास लंबी पैदल यात्रा और बोर्ड गेम का आनंद लेते हुए पाया जा सकता है।
विक्टर झू अमेज़ॅन वेब सर्विसेज में डिस्ट्रीब्यूटेड डीप लर्निंग में एक सॉफ्टवेयर इंजीनियर हैं। उन्हें एसएफ बे एरिया के आसपास लंबी पैदल यात्रा और बोर्ड गेम का आनंद लेते हुए पाया जा सकता है।
 दरिया कावड़ AWS में एक सॉफ्टवेयर इंजीनियर के रूप में काम करता है। उनकी रुचियों में गहन शिक्षण और वितरित प्रशिक्षण अनुकूलन शामिल हैं।
दरिया कावड़ AWS में एक सॉफ्टवेयर इंजीनियर के रूप में काम करता है। उनकी रुचियों में गहन शिक्षण और वितरित प्रशिक्षण अनुकूलन शामिल हैं।
 टेंग जू AWS AI में वितरित प्रशिक्षण समूह में एक सॉफ्टवेयर डेवलपमेंट इंजीनियर है। उसे पढ़ने में आनंद आता है।
टेंग जू AWS AI में वितरित प्रशिक्षण समूह में एक सॉफ्टवेयर डेवलपमेंट इंजीनियर है। उसे पढ़ने में आनंद आता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

