आज, सभी उद्योगों के ग्राहक - चाहे वह वित्तीय सेवाएँ, स्वास्थ्य सेवा और जीवन विज्ञान, यात्रा और आतिथ्य, मीडिया और मनोरंजन, दूरसंचार, एक सेवा के रूप में सॉफ्टवेयर (SaaS), और यहां तक कि मालिकाना मॉडल प्रदाता हों - बड़े भाषा मॉडल (एलएलएम) का उपयोग कर रहे हैं। प्रश्न और उत्तर (क्यूएनए) चैटबॉट, खोज इंजन और ज्ञानकोष जैसे एप्लिकेशन बनाएं। इन जनरेटिव ए.आई. एप्लिकेशन का उपयोग न केवल मौजूदा व्यावसायिक प्रक्रियाओं को स्वचालित करने के लिए किया जाता है, बल्कि इन एप्लिकेशन का उपयोग करने वाले ग्राहकों के अनुभव को बदलने की क्षमता भी है। एलएलएम जैसे विषयों में हो रही प्रगति के साथ मिक्सट्रल-8x7बी निर्देश, जैसे आर्किटेक्चर का व्युत्पन्न विशेषज्ञों का मिश्रण (एमओई), ग्राहक लगातार जेनेरिक एआई अनुप्रयोगों के प्रदर्शन और सटीकता में सुधार करने के तरीकों की तलाश कर रहे हैं, साथ ही उन्हें बंद और खुले स्रोत मॉडल की व्यापक रेंज का प्रभावी ढंग से उपयोग करने की अनुमति भी दे रहे हैं।
एलएलएम के आउटपुट की सटीकता और प्रदर्शन को बेहतर बनाने के लिए आमतौर पर कई तकनीकों का उपयोग किया जाता है, जैसे कि फाइन-ट्यूनिंग पैरामीटर कुशल फ़ाइन-ट्यूनिंग (PEFT), मानव प्रतिक्रिया से सुदृढीकरण सीखना (आरएलएचएफ), और प्रदर्शन कर रहे हैं ज्ञान आसवन. हालाँकि, जेनेरिक एआई अनुप्रयोगों का निर्माण करते समय, आप एक वैकल्पिक समाधान का उपयोग कर सकते हैं जो बाहरी ज्ञान के गतिशील समावेश की अनुमति देता है और आपको अपने मौजूदा मूलभूत मॉडल को ठीक करने की आवश्यकता के बिना पीढ़ी के लिए उपयोग की जाने वाली जानकारी को नियंत्रित करने की अनुमति देता है। यह वह जगह है जहां रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) आता है, विशेष रूप से जेनेरिक एआई अनुप्रयोगों के लिए, जैसा कि हमारे द्वारा चर्चा किए गए अधिक महंगे और मजबूत फाइन-ट्यूनिंग विकल्पों के विपरीत है। यदि आप अपने दैनिक कार्यों में जटिल आरएजी अनुप्रयोगों को लागू कर रहे हैं, तो आपको अपने आरएजी सिस्टम के साथ सामान्य चुनौतियों का सामना करना पड़ सकता है जैसे कि गलत पुनर्प्राप्ति, दस्तावेजों का बढ़ता आकार और जटिलता, और संदर्भ का अतिप्रवाह, जो उत्पन्न उत्तरों की गुणवत्ता और विश्वसनीयता को महत्वपूर्ण रूप से प्रभावित कर सकता है। .
यह पोस्ट प्रासंगिक संपीड़न जैसी तकनीकों के अलावा लैंगचेन और पैरेंट दस्तावेज़ रिट्रीवर जैसे उपकरणों का उपयोग करके प्रतिक्रिया सटीकता में सुधार करने के लिए आरएजी पैटर्न पर चर्चा करती है ताकि डेवलपर्स को मौजूदा जेनरेटिव एआई अनुप्रयोगों में सुधार करने में सक्षम बनाया जा सके।
समाधान अवलोकन
इस पोस्ट में, हम मूल दस्तावेज़ रिट्रीवर टूल और प्रासंगिक संपीड़न तकनीक का उपयोग करके अमेज़ॅन सेजमेकर नोटबुक पर RAG QnA सिस्टम का कुशलतापूर्वक निर्माण करने के लिए BGE लार्ज एन एम्बेडिंग मॉडल के साथ संयुक्त मिक्सट्रल-8x7B इंस्ट्रक्ट टेक्स्ट जेनरेशन के उपयोग को प्रदर्शित करते हैं। निम्नलिखित चित्र इस समाधान की वास्तुकला को दर्शाता है।
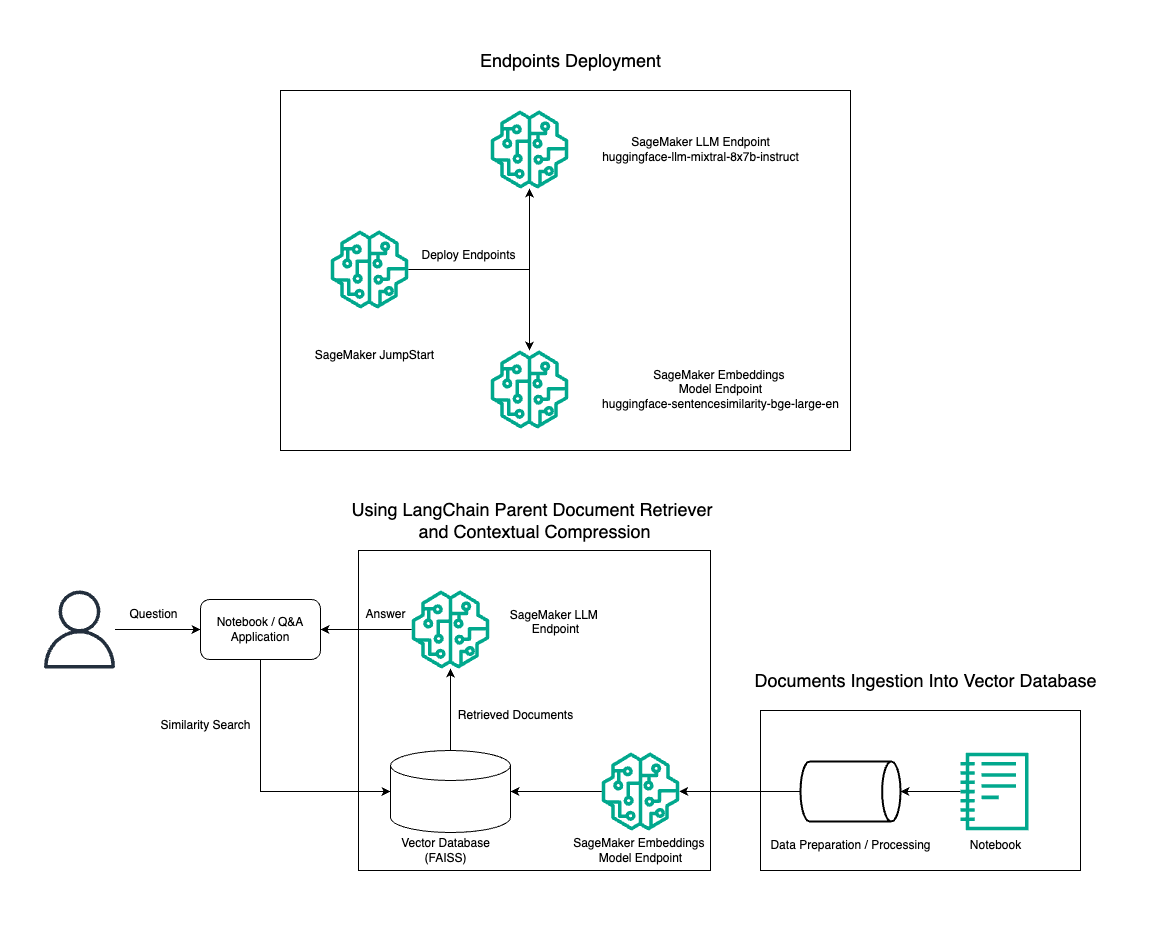
आप बस कुछ ही क्लिक के साथ इस समाधान को तैनात कर सकते हैं अमेज़न SageMaker जम्पस्टार्ट, एक पूरी तरह से प्रबंधित मंच जो सामग्री लेखन, कोड निर्माण, प्रश्न उत्तर, कॉपी राइटिंग, संक्षेपण, वर्गीकरण और सूचना पुनर्प्राप्ति जैसे विभिन्न उपयोग के मामलों के लिए अत्याधुनिक फाउंडेशन मॉडल प्रदान करता है। यह पूर्व-प्रशिक्षित मॉडलों का एक संग्रह प्रदान करता है जिन्हें आप मशीन लर्निंग (एमएल) अनुप्रयोगों के विकास और तैनाती में तेजी लाते हुए जल्दी और आसानी से तैनात कर सकते हैं। सेजमेकर जंपस्टार्ट के प्रमुख घटकों में से एक मॉडल हब है, जो विभिन्न कार्यों के लिए मिक्सट्राल-8x7बी जैसे पूर्व-प्रशिक्षित मॉडल की एक विशाल सूची प्रदान करता है।
मिक्सट्रल-8x7B एक MoE आर्किटेक्चर का उपयोग करता है। यह आर्किटेक्चर तंत्रिका नेटवर्क के विभिन्न हिस्सों को विभिन्न कार्यों में विशेषज्ञता प्रदान करता है, जिससे कार्यभार को कई विशेषज्ञों के बीच प्रभावी ढंग से विभाजित किया जा सकता है। यह दृष्टिकोण पारंपरिक वास्तुकला की तुलना में बड़े मॉडलों के कुशल प्रशिक्षण और तैनाती को सक्षम बनाता है।
MoE आर्किटेक्चर का एक मुख्य लाभ इसकी स्केलेबिलिटी है। कार्यभार को कई विशेषज्ञों के बीच वितरित करके, MoE मॉडल को बड़े डेटासेट पर प्रशिक्षित किया जा सकता है और समान आकार के पारंपरिक मॉडल की तुलना में बेहतर प्रदर्शन प्राप्त किया जा सकता है। इसके अतिरिक्त, MoE मॉडल अनुमान के दौरान अधिक कुशल हो सकते हैं क्योंकि किसी दिए गए इनपुट के लिए केवल विशेषज्ञों के एक सबसेट को सक्रिय करने की आवश्यकता होती है।
AWS पर Mixtral-8x7B इंस्ट्रक्शन के बारे में अधिक जानकारी के लिए देखें मिक्सट्रल-8x7B अब अमेज़न सेजमेकर जम्पस्टार्ट पर उपलब्ध है. मिक्सट्रल-8x7B मॉडल को बिना किसी प्रतिबंध के उपयोग के लिए अनुमेय अपाचे 2.0 लाइसेंस के तहत उपलब्ध कराया गया है।
इस पोस्ट में, हम चर्चा करते हैं कि आप इसका उपयोग कैसे कर सकते हैं लैंगचैन प्रभावी और अधिक कुशल RAG अनुप्रयोग बनाने के लिए। लैंगचेन एक खुला स्रोत पायथन लाइब्रेरी है जिसे एलएलएम के साथ एप्लिकेशन बनाने के लिए डिज़ाइन किया गया है। यह शक्तिशाली और अनुकूलन योग्य एप्लिकेशन बनाने के लिए एलएलएम को अन्य घटकों, जैसे ज्ञान आधार, पुनर्प्राप्ति प्रणाली और अन्य एआई टूल के साथ संयोजित करने के लिए एक मॉड्यूलर और लचीला ढांचा प्रदान करता है।
हम मिक्सट्रल-8x7बी के साथ सेजमेकर पर एक आरएजी पाइपलाइन का निर्माण कर रहे हैं। हम सेजमेकर नोटबुक पर RAG का उपयोग करके एक कुशल QnA सिस्टम बनाने के लिए BGE लार्ज एन एम्बेडिंग मॉडल के साथ मिक्सट्रल-8x7B इंस्ट्रक्ट टेक्स्ट जेनरेशन मॉडल का उपयोग करते हैं। हम सेजमेकर जम्पस्टार्ट के माध्यम से एलएलएम की तैनाती को प्रदर्शित करने के लिए ml.t3.medium उदाहरण का उपयोग करते हैं, जिसे सेजमेकर-जनरेटेड एपीआई एंडपॉइंट के माध्यम से एक्सेस किया जा सकता है। यह सेटअप लैंगचेन के साथ उन्नत आरएजी तकनीकों की खोज, प्रयोग और अनुकूलन की अनुमति देता है। हम RAG वर्कफ़्लो में FAISS एंबेडिंग स्टोर के एकीकरण का भी वर्णन करते हैं, सिस्टम के प्रदर्शन को बढ़ाने के लिए एंबेडिंग को संग्रहीत करने और पुनर्प्राप्त करने में इसकी भूमिका पर प्रकाश डालते हैं।
हम सेजमेकर नोटबुक का एक संक्षिप्त अवलोकन करते हैं। अधिक विस्तृत और चरण-दर-चरण निर्देशों के लिए, देखें सेजमेकर जम्पस्टार्ट गिटहब रेपो पर मिक्सट्रल के साथ उन्नत आरएजी पैटर्न.
उन्नत RAG पैटर्न की आवश्यकता
उन्नत आरएजी पैटर्न मानव-जैसे पाठ को संसाधित करने, समझने और उत्पन्न करने में एलएलएम की वर्तमान क्षमताओं में सुधार करने के लिए आवश्यक हैं। जैसे-जैसे दस्तावेज़ों का आकार और जटिलता बढ़ती है, दस्तावेज़ के कई पहलुओं को एक ही एम्बेडिंग में प्रस्तुत करने से विशिष्टता का नुकसान हो सकता है। हालाँकि किसी दस्तावेज़ के सामान्य सार को पकड़ना आवश्यक है, लेकिन इसके भीतर के विभिन्न उप-संदर्भों को पहचानना और उनका प्रतिनिधित्व करना भी उतना ही महत्वपूर्ण है। यह एक चुनौती है जिसका सामना आपको बड़े दस्तावेज़ों के साथ काम करते समय अक्सर करना पड़ता है। आरएजी के साथ एक और चुनौती यह है कि पुनर्प्राप्ति के साथ, आप उन विशिष्ट प्रश्नों से अवगत नहीं होते हैं जिन्हें आपका दस्तावेज़ भंडारण सिस्टम अंतर्ग्रहण पर निपटेगा। इससे किसी क्वेरी के लिए सर्वाधिक प्रासंगिक जानकारी पाठ (संदर्भ अतिप्रवाह) के नीचे दब सकती है। विफलता को कम करने और मौजूदा आरएजी आर्किटेक्चर में सुधार करने के लिए, आप पुनर्प्राप्ति त्रुटियों को कम करने, उत्तर की गुणवत्ता बढ़ाने और जटिल प्रश्न प्रबंधन को सक्षम करने के लिए उन्नत आरएजी पैटर्न (मूल दस्तावेज़ पुनर्प्राप्ति और प्रासंगिक संपीड़न) का उपयोग कर सकते हैं।
इस पोस्ट में चर्चा की गई तकनीकों के साथ, आप बाहरी ज्ञान पुनर्प्राप्ति और एकीकरण से जुड़ी प्रमुख चुनौतियों का समाधान कर सकते हैं, जिससे आपका एप्लिकेशन अधिक सटीक और प्रासंगिक रूप से जागरूक प्रतिक्रिया देने में सक्षम हो जाएगा।
निम्नलिखित अनुभागों में, हम पता लगाते हैं कि कैसे मूल दस्तावेज़ पुनःप्राप्तकर्ता और प्रासंगिक संपीड़न हमारे द्वारा चर्चा की गई कुछ समस्याओं से निपटने में आपको मदद मिल सकती है।
मूल दस्तावेज़ पुनःप्राप्तकर्ता
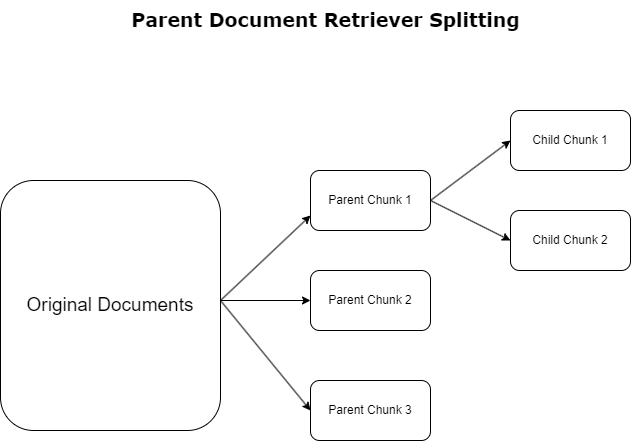
पिछले अनुभाग में, हमने व्यापक दस्तावेजों से निपटने के दौरान आरएजी अनुप्रयोगों के सामने आने वाली चुनौतियों पर प्रकाश डाला। इन चुनौतियों से निपटने के लिए, मूल दस्तावेज़ पुनःप्राप्तकर्ता आने वाले दस्तावेज़ों को इस प्रकार वर्गीकृत और नामित करें मूल दस्तावेज़. ये दस्तावेज़ अपनी व्यापक प्रकृति के लिए पहचाने जाते हैं लेकिन इन्हें एम्बेडिंग के लिए सीधे उनके मूल रूप में उपयोग नहीं किया जाता है। संपूर्ण दस्तावेज़ को एक एम्बेडिंग में संपीड़ित करने के बजाय, मूल दस्तावेज़ पुनर्प्राप्तकर्ता इन मूल दस्तावेज़ों को विच्छेदित करते हैं बाल दस्तावेज़. प्रत्येक चाइल्ड दस्तावेज़ व्यापक मूल दस्तावेज़ से अलग-अलग पहलुओं या विषयों को कैप्चर करता है। इन चाइल्ड सेगमेंट की पहचान के बाद, उनके विशिष्ट विषयगत सार को कैप्चर करते हुए, प्रत्येक को व्यक्तिगत एम्बेडिंग सौंपी जाती है (निम्नलिखित चित्र देखें)। पुनर्प्राप्ति के दौरान, मूल दस्तावेज़ लागू किया जाता है। यह तकनीक एलएलएम को व्यापक परिप्रेक्ष्य प्रदान करते हुए लक्षित लेकिन व्यापक खोज क्षमताएं प्रदान करती है। मूल दस्तावेज़ पुनर्प्राप्तिकर्ता एलएलएम को दोहरा लाभ प्रदान करते हैं: सटीक और प्रासंगिक जानकारी पुनर्प्राप्ति के लिए बाल दस्तावेज़ एम्बेडिंग की विशिष्टता, प्रतिक्रिया पीढ़ी के लिए मूल दस्तावेज़ों के आह्वान के साथ मिलकर, जो एलएलएम के आउटपुट को एक स्तरित और संपूर्ण संदर्भ के साथ समृद्ध करता है।
प्रासंगिक संपीड़न
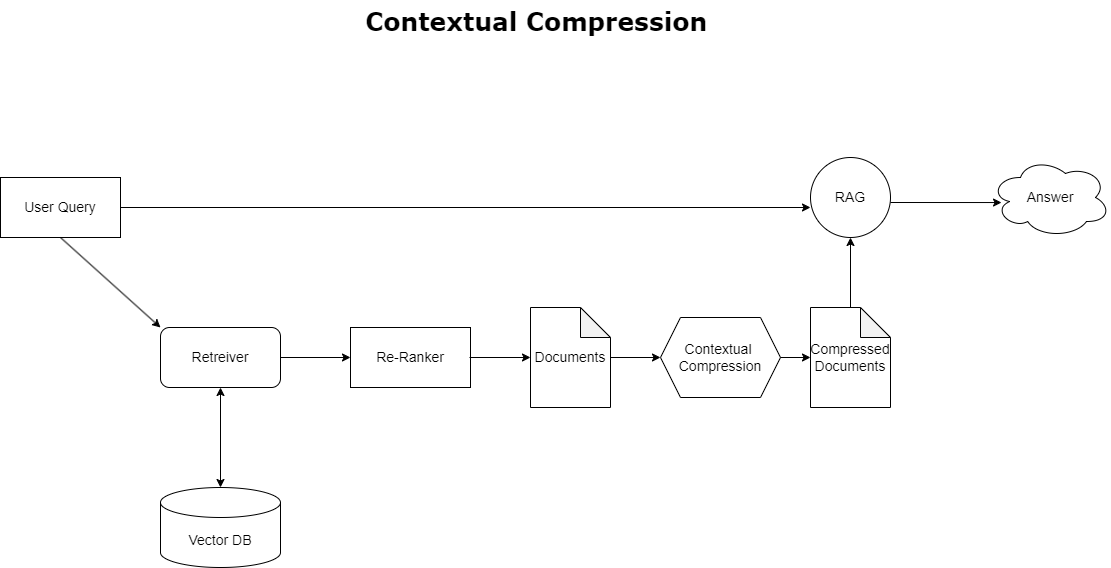
पहले चर्चा की गई संदर्भ अतिप्रवाह की समस्या का समाधान करने के लिए, आप इसका उपयोग कर सकते हैं प्रासंगिक संपीड़न क्वेरी के संदर्भ के अनुरूप पुनर्प्राप्त दस्तावेज़ों को संपीड़ित और फ़िल्टर करने के लिए, ताकि केवल प्रासंगिक जानकारी ही रखी और संसाधित की जा सके। इसे आरंभिक दस्तावेज़ लाने के लिए एक बेस रिट्रीवर और इन दस्तावेज़ों की सामग्री को कम करके या प्रासंगिकता के आधार पर उन्हें पूरी तरह से बाहर करके परिष्कृत करने के लिए एक दस्तावेज़ कंप्रेसर के संयोजन के माध्यम से प्राप्त किया जाता है, जैसा कि निम्नलिखित चित्र में दिखाया गया है। यह सुव्यवस्थित दृष्टिकोण, प्रासंगिक संपीड़न पुनर्प्राप्ति द्वारा सुगम, जानकारी के एक समूह से केवल आवश्यक चीज़ों को निकालने और उपयोग करने की एक विधि प्रदान करके आरएजी अनुप्रयोग दक्षता को बढ़ाता है। यह सूचना अधिभार और अप्रासंगिक डेटा प्रोसेसिंग के मुद्दे से निपटता है, जिससे बेहतर प्रतिक्रिया गुणवत्ता, अधिक लागत प्रभावी एलएलएम संचालन और एक चिकनी समग्र पुनर्प्राप्ति प्रक्रिया होती है। अनिवार्य रूप से, यह एक फ़िल्टर है जो जानकारी को मौजूदा क्वेरी के अनुरूप बनाता है, जिससे यह बेहतर प्रदर्शन और उपयोगकर्ता संतुष्टि के लिए अपने आरएजी अनुप्रयोगों को अनुकूलित करने का लक्ष्य रखने वाले डेवलपर्स के लिए एक बहुत जरूरी उपकरण बन जाता है।
.. पूर्वापेक्षाएँ
यदि आप सेजमेकर में नए हैं, तो देखें अमेज़ॅन सेजमेकर डेवलपमेंट गाइड.
इससे पहले कि आप समाधान के साथ शुरुआत करें, एक AWS खाता बनाएँ. जब आप एक एडब्ल्यूएस खाता बनाते हैं, तो आपको एक एकल साइन-ऑन (एसएसओ) पहचान मिलती है, जिसकी खाते में सभी एडब्ल्यूएस सेवाओं और संसाधनों तक पूरी पहुंच होती है। इस पहचान को AWS खाता कहा जाता है रूट उपयोगकर्ता.
में साइन इन करना एडब्ल्यूएस प्रबंधन कंसोल खाता बनाने के लिए आपके द्वारा उपयोग किए गए ईमेल पते और पासवर्ड का उपयोग करने से आपको अपने खाते के सभी AWS संसाधनों तक पूर्ण पहुंच प्राप्त होती है। हम दृढ़तापूर्वक अनुशंसा करते हैं कि आप रोजमर्रा के कार्यों, यहां तक कि प्रशासनिक कार्यों के लिए भी रूट उपयोगकर्ता का उपयोग न करें।
इसके बजाय, का पालन करें सुरक्षा सर्वोत्तम अभ्यास in AWS पहचान और अभिगम प्रबंधन (आईएएम), और एक प्रशासनिक उपयोगकर्ता और समूह बनाएँ. फिर रूट उपयोगकर्ता क्रेडेंशियल को सुरक्षित रूप से लॉक करें और उनका उपयोग केवल कुछ खाता और सेवा प्रबंधन कार्यों को करने के लिए करें।
मिक्सट्रल-8x7b मॉडल के लिए ml.g5.48xlarge उदाहरण की आवश्यकता होती है। सेजमेकर जंपस्टार्ट 100 से अधिक विभिन्न ओपन सोर्स और थर्ड-पार्टी फाउंडेशन मॉडल तक पहुंचने और तैनात करने का एक सरल तरीका प्रदान करता है। के लिए सेजमेकर जम्पस्टार्ट से मिक्सट्रल-8x7बी को होस्ट करने के लिए एक एंडपॉइंट लॉन्च करें, आपको एंडपॉइंट उपयोग के लिए ml.g5.48xlarge इंस्टेंस तक पहुंचने के लिए सेवा कोटा बढ़ाने का अनुरोध करने की आवश्यकता हो सकती है। तुम कर सकते हो अनुरोध सेवा कोटा बढ़ता है कंसोल के माध्यम से, AWS कमांड लाइन इंटरफ़ेस (एडब्ल्यूएस सीएलआई), या एपीआई उन अतिरिक्त संसाधनों तक पहुंच की अनुमति देने के लिए।
सेजमेकर नोटबुक इंस्टेंस सेट करें और निर्भरताएँ स्थापित करें
आरंभ करने के लिए, एक सेजमेकर नोटबुक इंस्टेंस बनाएं और आवश्यक निर्भरताएँ स्थापित करें। को देखें गीथहब रेपो एक सफल सेटअप सुनिश्चित करने के लिए. नोटबुक इंस्टेंस सेट करने के बाद, आप मॉडल को तैनात कर सकते हैं।
आप नोटबुक को अपने पसंदीदा एकीकृत विकास परिवेश (आईडीई) पर स्थानीय रूप से भी चला सकते हैं। सुनिश्चित करें कि आपके पास ज्यूपिटर नोटबुक लैब स्थापित है।
मॉडल तैनात करें
सेजमेकर जम्पस्टार्ट पर मिक्सट्रल-8X7B इंस्ट्रक्ट एलएलएम मॉडल तैनात करें:
सेजमेकर जम्पस्टार्ट पर बीजीई लार्ज एन एम्बेडिंग मॉडल तैनात करें:
लैंगचेन स्थापित करें
सभी आवश्यक लाइब्रेरी आयात करने और मिक्सट्रल-8x7B मॉडल और BGE लार्ज एन एम्बेडिंग मॉडल को तैनात करने के बाद, अब आप लैंगचेन सेट कर सकते हैं। चरण-दर-चरण निर्देशों के लिए, देखें गीथहब रेपो.
डेटा तैयारी
इस पोस्ट में, हम क्यूएनए निष्पादित करने के लिए टेक्स्ट कॉर्पस के रूप में शेयरधारकों को अमेज़ॅन के कई वर्षों के पत्रों का उपयोग करते हैं। डेटा तैयार करने के अधिक विस्तृत चरणों के लिए, देखें गीथहब रेपो.
सवाल जवाब
एक बार डेटा तैयार हो जाने के बाद, आप लैंगचेन द्वारा प्रदान किए गए रैपर का उपयोग कर सकते हैं, जो वेक्टर स्टोर के चारों ओर लपेटता है और एलएलएम के लिए इनपुट लेता है। यह रैपर निम्नलिखित चरण निष्पादित करता है:
- इनपुट प्रश्न लें.
- एक प्रश्न एम्बेडिंग बनाएं.
- प्रासंगिक दस्तावेज़ लाएँ.
- दस्तावेज़ों और प्रश्न को एक संकेत में शामिल करें।
- प्रॉम्प्ट के साथ मॉडल का आह्वान करें और पठनीय तरीके से उत्तर तैयार करें।
अब जब वेक्टर स्टोर स्थापित हो गया है, तो आप प्रश्न पूछना शुरू कर सकते हैं:
नियमित रिट्रीवर श्रृंखला
पिछले परिदृश्य में, हमने आपके प्रश्न का संदर्भ-जागरूक उत्तर प्राप्त करने का त्वरित और सीधा तरीका खोजा। अब आइए RetrievalQA की मदद से एक अधिक अनुकूलन योग्य विकल्प देखें, जहां आप अनुकूलित कर सकते हैं कि कैसे लाए गए दस्तावेज़ों को चेन_टाइप पैरामीटर का उपयोग करके प्रॉम्प्ट में जोड़ा जाना चाहिए। साथ ही, यह नियंत्रित करने के लिए कि कितने प्रासंगिक दस्तावेज़ पुनर्प्राप्त किए जाने चाहिए, आप विभिन्न आउटपुट देखने के लिए निम्नलिखित कोड में k पैरामीटर को बदल सकते हैं। कई परिदृश्यों में, आप जानना चाहेंगे कि उत्तर उत्पन्न करने के लिए एलएलएम ने किस स्रोत दस्तावेज़ का उपयोग किया था। आप उन दस्तावेज़ों का उपयोग करके आउटपुट में प्राप्त कर सकते हैं return_source_documents, जो एलएलएम प्रॉम्प्ट के संदर्भ में जोड़े गए दस्तावेज़ लौटाता है। पुनर्प्राप्तिQA आपको एक कस्टम प्रॉम्प्ट टेम्पलेट प्रदान करने की भी अनुमति देता है जो मॉडल के लिए विशिष्ट हो सकता है।
आइए एक प्रश्न पूछें:
मूल दस्तावेज़ पुनर्प्राप्ति श्रृंखला
आइए इसकी सहायता से अधिक उन्नत RAG विकल्प देखें ParentDocumentRetriever. दस्तावेज़ पुनर्प्राप्ति के साथ काम करते समय, आपको सटीक एम्बेडिंग के लिए दस्तावेज़ के छोटे हिस्सों को संग्रहीत करने और अधिक संदर्भ को संरक्षित करने के लिए बड़े दस्तावेज़ों के बीच व्यापार-बंद का सामना करना पड़ सकता है। मूल दस्तावेज़ रिट्रीवर डेटा के छोटे टुकड़ों को विभाजित और संग्रहीत करके उस संतुलन को बनाता है।
हम एक का उपयोग करें parent_splitter मूल दस्तावेज़ों को बड़े टुकड़ों में विभाजित करना, जिन्हें मूल दस्तावेज़ कहा जाता है और a child_splitter मूल दस्तावेज़ों से छोटे बच्चों के दस्तावेज़ बनाने के लिए:
फिर चाइल्ड दस्तावेज़ों को एम्बेडिंग का उपयोग करके एक वेक्टर स्टोर में अनुक्रमित किया जाता है। यह समानता के आधार पर प्रासंगिक बाल दस्तावेजों की कुशल पुनर्प्राप्ति को सक्षम बनाता है। प्रासंगिक जानकारी प्राप्त करने के लिए, मूल दस्तावेज़ पुनर्प्राप्ति पहले वेक्टर स्टोर से चाइल्ड दस्तावेज़ प्राप्त करता है। इसके बाद यह उन चाइल्ड दस्तावेज़ों के लिए मूल आईडी खोजता है और संबंधित बड़े मूल दस्तावेज़ लौटाता है।
आइए एक प्रश्न पूछें:
प्रासंगिक संपीड़न श्रृंखला
आइए एक और उन्नत RAG विकल्प देखें जिसे कहा जाता है प्रासंगिक संपीड़न. पुनर्प्राप्ति के साथ एक चुनौती यह है कि आमतौर पर हम यह नहीं जानते हैं कि जब आप सिस्टम में डेटा अंतर्ग्रहण करेंगे तो आपके दस्तावेज़ भंडारण सिस्टम को किन विशिष्ट प्रश्नों का सामना करना पड़ेगा। इसका मतलब यह है कि किसी क्वेरी के लिए सबसे अधिक प्रासंगिक जानकारी बहुत सारे अप्रासंगिक पाठ वाले दस्तावेज़ में छिपी हो सकती है। आपके आवेदन के माध्यम से उस पूर्ण दस्तावेज़ को पारित करने से अधिक महंगी एलएलएम कॉल और खराब प्रतिक्रियाएँ हो सकती हैं।
प्रासंगिक संपीड़न रिट्रीवर दस्तावेज़ भंडारण प्रणाली से प्रासंगिक जानकारी पुनर्प्राप्त करने की चुनौती को संबोधित करता है, जहां प्रासंगिक डेटा बहुत सारे पाठ वाले दस्तावेज़ों के भीतर छिपा हो सकता है। दिए गए क्वेरी संदर्भ के आधार पर पुनर्प्राप्त दस्तावेज़ों को संपीड़ित और फ़िल्टर करके, केवल सबसे प्रासंगिक जानकारी वापस की जाती है।
प्रासंगिक संपीड़न रिट्रीवर का उपयोग करने के लिए, आपको इसकी आवश्यकता होगी:
- एक बेस रिट्रीवर - यह प्रारंभिक रिट्रीवर है जो क्वेरी के आधार पर स्टोरेज सिस्टम से दस्तावेज़ लाता है
- एक दस्तावेज़ कंप्रेसर - यह घटक प्रारंभिक रूप से पुनर्प्राप्त दस्तावेज़ों को लेता है और प्रासंगिकता निर्धारित करने के लिए क्वेरी संदर्भ का उपयोग करके व्यक्तिगत दस्तावेज़ों की सामग्री को कम करके या अप्रासंगिक दस्तावेज़ों को पूरी तरह से हटाकर उन्हें छोटा कर देता है।
एलएलएम चेन एक्सट्रैक्टर के साथ प्रासंगिक संपीड़न जोड़ना
सबसे पहले, अपने बेस रिट्रीवर को एक से लपेटें ContextualCompressionRetriever. आप एक जोड़ देंगे एलएलएमचेनएक्सट्रैक्टर, जो प्रारंभ में लौटाए गए दस्तावेज़ों पर पुनरावृति करेगा और प्रत्येक से केवल वही सामग्री निकालेगा जो क्वेरी के लिए प्रासंगिक है।
का उपयोग करके श्रृंखला आरंभ करें ContextualCompressionRetriever के साथ एक LLMChainExtractor और प्रॉम्प्ट को इसके माध्यम से पास करें chain_type_kwargs तर्क।
आइए एक प्रश्न पूछें:
एलएलएम श्रृंखला फ़िल्टर के साथ दस्तावेज़ फ़िल्टर करें
RSI एलएलएमचेनफ़िल्टर थोड़ा सरल लेकिन अधिक मजबूत कंप्रेसर है जो एलएलएम श्रृंखला का उपयोग यह तय करने के लिए करता है कि दस्तावेज़ सामग्री में हेरफेर किए बिना, प्रारंभ में पुनर्प्राप्त किए गए दस्तावेज़ों में से कौन सा फ़िल्टर करना है और कौन सा वापस करना है:
का उपयोग करके श्रृंखला आरंभ करें ContextualCompressionRetriever के साथ एक LLMChainFilter और प्रॉम्प्ट को इसके माध्यम से पास करें chain_type_kwargs तर्क।
आइए एक प्रश्न पूछें:
परिणामों की तुलना करें
निम्न तालिका तकनीक के आधार पर विभिन्न प्रश्नों के परिणामों की तुलना करती है।
| तकनीक | प्रश्न 1 | प्रश्न 2 | तुलना |
| AWS का विकास कैसे हुआ? | अमेज़न सफल क्यों है? | ||
| रेगुलर रिट्रीवर चेन आउटपुट | AWS (अमेज़ॅन वेब सर्विसेज) शुरू में लाभहीन निवेश से $85B वार्षिक राजस्व रन रेट वाले व्यवसाय में मजबूत लाभप्रदता के साथ विकसित हुई, जो सेवाओं और सुविधाओं की एक विस्तृत श्रृंखला की पेशकश करती है, और अमेज़ॅन के पोर्टफोलियो का एक महत्वपूर्ण हिस्सा बन गई है। संदेह और अल्पकालिक बाधाओं का सामना करने के बावजूद, AWS ने चपलता, नवीनता, लागत-दक्षता और सुरक्षा जैसे लाभ प्रदान करते हुए नवाचार करना, नए ग्राहकों को आकर्षित करना और सक्रिय ग्राहकों को स्थानांतरित करना जारी रखा। AWS ने नई क्षमताएं प्रदान करने और अपने ग्राहकों के लिए जो संभव है उसे बदलने के लिए चिप विकास सहित अपने दीर्घकालिक निवेश का भी विस्तार किया। | अमेज़ॅन अपने निरंतर नवाचार और नए क्षेत्रों जैसे प्रौद्योगिकी अवसंरचना सेवाओं, डिजिटल रीडिंग डिवाइस, आवाज-संचालित व्यक्तिगत सहायक और तीसरे पक्ष के बाज़ार जैसे नए व्यवसाय मॉडल में विस्तार के कारण सफल है। संचालन को तेजी से बढ़ाने की इसकी क्षमता, जैसा कि इसकी पूर्ति और परिवहन नेटवर्क के तेजी से विस्तार में देखा जाता है, भी इसकी सफलता में योगदान देती है। इसके अतिरिक्त, अमेज़ॅन द्वारा अपनी प्रक्रियाओं में अनुकूलन और दक्षता हासिल करने पर ध्यान देने से उत्पादकता में सुधार और लागत में कमी आई है। अमेज़ॅन बिजनेस का उदाहरण विभिन्न क्षेत्रों में अपनी ई-कॉमर्स और लॉजिस्टिक्स ताकत का लाभ उठाने की कंपनी की क्षमता को उजागर करता है। | नियमित रिट्रीवर श्रृंखला की प्रतिक्रियाओं के आधार पर, हमने देखा कि यद्यपि यह लंबे उत्तर प्रदान करता है, यह संदर्भ अतिप्रवाह से ग्रस्त है और प्रदान की गई क्वेरी का जवाब देने के संबंध में कॉर्पस से किसी भी महत्वपूर्ण विवरण का उल्लेख करने में विफल रहता है। नियमित पुनर्प्राप्ति श्रृंखला गहराई या प्रासंगिक अंतर्दृष्टि के साथ बारीकियों को पकड़ने में सक्षम नहीं है, संभवतः दस्तावेज़ के महत्वपूर्ण पहलू गायब हैं। |
| मूल दस्तावेज़ पुनर्प्राप्ति आउटपुट | AWS (अमेज़ॅन वेब सर्विसेज) की शुरुआत 2 में इलास्टिक कंप्यूट क्लाउड (EC2006) सेवा के फीचर-खराब प्रारंभिक लॉन्च के साथ हुई, जो दुनिया के एक क्षेत्र में, केवल लिनक्स ऑपरेटिंग सिस्टम इंस्टेंस के साथ, एक डेटा सेंटर में केवल एक इंस्टेंस आकार प्रदान करता था। , और निगरानी, लोड संतुलन, ऑटो-स्केलिंग, या लगातार भंडारण जैसी कई प्रमुख सुविधाओं के बिना। हालाँकि, AWS की सफलता ने उन्हें तेजी से पुनरावृत्ति करने और गायब क्षमताओं को जोड़ने की अनुमति दी, अंततः विभिन्न स्वादों, आकारों और गणना, भंडारण और नेटवर्किंग के अनुकूलन की पेशकश करने के लिए विस्तार किया, साथ ही कीमत और प्रदर्शन को आगे बढ़ाने के लिए अपने स्वयं के चिप्स (ग्रेविटॉन) विकसित किए। . AWS की पुनरावृत्तीय नवाचार प्रक्रिया के लिए ग्राहकों की जरूरतों को पूरा करने और शेयरधारकों के लिए दीर्घकालिक ग्राहक अनुभव, वफादारी और रिटर्न में सुधार करने के लिए, 20 वर्षों में वित्तीय और लोगों के संसाधनों में महत्वपूर्ण निवेश की आवश्यकता होती है, जो अक्सर भुगतान करने के समय से काफी पहले होता है। | अमेज़न लगातार नवप्रवर्तन करने, बदलती बाज़ार स्थितियों के अनुकूल ढलने और विभिन्न बाज़ार क्षेत्रों में ग्राहकों की ज़रूरतों को पूरा करने की अपनी क्षमता के कारण सफल है। यह अमेज़ॅन बिजनेस की सफलता में स्पष्ट है, जो व्यावसायिक ग्राहकों को चयन, मूल्य और सुविधा प्रदान करके वार्षिक सकल बिक्री में लगभग $35B तक बढ़ गया है। ईकॉमर्स और लॉजिस्टिक्स क्षमताओं में अमेज़ॅन के निवेश ने प्राइम के साथ खरीदें जैसी सेवाओं के निर्माण को भी सक्षम किया है, जो प्रत्यक्ष-से-उपभोक्ता वेबसाइट वाले व्यापारियों को विचारों से खरीदारी तक रूपांतरण चलाने में मदद करता है। | मूल दस्तावेज़ रिट्रीवर AWS की विकास रणनीति की विशिष्टताओं पर गहराई से प्रकाश डालता है, जिसमें ग्राहकों की प्रतिक्रिया के आधार पर नई सुविधाओं को जोड़ने की पुनरावृत्तीय प्रक्रिया और फीचर-खराब प्रारंभिक लॉन्च से एक प्रमुख बाजार स्थिति तक की विस्तृत यात्रा शामिल है, जबकि एक संदर्भ-समृद्ध प्रतिक्रिया प्रदान की जाती है। . प्रतिक्रियाएँ तकनीकी नवाचारों और बाज़ार रणनीति से लेकर संगठनात्मक दक्षता और ग्राहक फोकस तक पहलुओं की एक विस्तृत श्रृंखला को कवर करती हैं, जो उदाहरणों के साथ सफलता में योगदान देने वाले कारकों का समग्र दृष्टिकोण प्रदान करती हैं। इसका श्रेय मूल दस्तावेज़ पुनर्प्राप्तकर्ता की लक्षित लेकिन व्यापक खोज क्षमताओं को दिया जा सकता है। |
| एलएलएम चेन एक्सट्रैक्टर: प्रासंगिक संपीड़न आउटपुट | AWS अमेज़ॅन के अंदर एक छोटी परियोजना के रूप में शुरू करके विकसित हुई, जिसमें महत्वपूर्ण पूंजी निवेश की आवश्यकता थी और कंपनी के अंदर और बाहर दोनों तरफ से संदेह का सामना करना पड़ा। हालाँकि, AWS ने संभावित प्रतिस्पर्धियों पर बढ़त बना ली थी और उसे विश्वास था कि यह ग्राहकों और अमेज़ॅन के लिए मूल्य ला सकता है। AWS ने निवेश जारी रखने के लिए दीर्घकालिक प्रतिबद्धता जताई, जिसके परिणामस्वरूप 3,300 में 2022 से अधिक नई सुविधाएँ और सेवाएँ लॉन्च की गईं। AWS ने ग्राहकों के अपने प्रौद्योगिकी बुनियादी ढांचे का प्रबंधन करने के तरीके को बदल दिया है और मजबूत लाभप्रदता के साथ $85B वार्षिक राजस्व रन रेट वाला व्यवसाय बन गया है। AWS ने अपनी पेशकशों में भी लगातार सुधार किया है, जैसे कि शुरुआती लॉन्च के बाद अतिरिक्त सुविधाओं और सेवाओं के साथ EC2 को बढ़ाना। | दिए गए संदर्भ के आधार पर, अमेज़ॅन की सफलता को एक पुस्तक-विक्रय मंच से एक जीवंत तृतीय-पक्ष विक्रेता पारिस्थितिकी तंत्र के साथ वैश्विक बाज़ार तक इसके रणनीतिक विस्तार, AWS में शुरुआती निवेश, किंडल और एलेक्सा को पेश करने में नवाचार और पर्याप्त वृद्धि के लिए जिम्मेदार ठहराया जा सकता है। 2019 से 2022 तक वार्षिक राजस्व में। इस वृद्धि से पूर्ति केंद्र पदचिह्न का विस्तार हुआ, अंतिम-मील परिवहन नेटवर्क का निर्माण हुआ, और एक नए सॉर्टेशन सेंटर नेटवर्क का निर्माण हुआ, जो उत्पादकता और लागत में कटौती के लिए अनुकूलित थे। | एलएलएम चेन एक्सट्रैक्टर मुख्य बिंदुओं को व्यापक रूप से कवर करने और अनावश्यक गहराई से बचने के बीच संतुलन बनाए रखता है। यह गतिशील रूप से क्वेरी के संदर्भ में समायोजित हो जाता है, इसलिए आउटपुट सीधे प्रासंगिक और व्यापक होता है। |
| एलएलएम चेन फ़िल्टर: प्रासंगिक संपीड़न आउटपुट | AWS (अमेज़ॅन वेब सर्विसेज) शुरू में फीचर-खराब लेकिन आवश्यक क्षमताओं को जोड़ने के लिए ग्राहकों की प्रतिक्रिया के आधार पर तेजी से लॉन्च करके विकसित हुई। इस दृष्टिकोण ने AWS को 2 में सीमित सुविधाओं के साथ EC2006 लॉन्च करने और फिर अतिरिक्त इंस्टेंस आकार, डेटा केंद्र, क्षेत्र, ऑपरेटिंग सिस्टम विकल्प, निगरानी उपकरण, लोड संतुलन, ऑटो-स्केलिंग और लगातार स्टोरेज जैसी नई कार्यक्षमताएं जोड़ने की अनुमति दी। समय के साथ, ग्राहकों की जरूरतों, चपलता, नवाचार, लागत-दक्षता और सुरक्षा पर ध्यान केंद्रित करके AWS एक फीचर-खराब सेवा से बहु-अरब डॉलर के व्यवसाय में बदल गया। AWS की अब वार्षिक राजस्व दर $85B है और यह प्रत्येक वर्ष 3,300 से अधिक नई सुविधाएँ और सेवाएँ प्रदान करता है, जो स्टार्ट-अप से लेकर बहुराष्ट्रीय कंपनियों और सार्वजनिक क्षेत्र के संगठनों तक के ग्राहकों की एक विस्तृत श्रृंखला को पूरा करता है। | अमेज़ॅन अपने नवोन्मेषी बिजनेस मॉडल, निरंतर तकनीकी प्रगति और रणनीतिक संगठनात्मक परिवर्तनों के कारण सफल है। कंपनी ने नए विचारों को पेश करके पारंपरिक उद्योगों को लगातार बाधित किया है, जैसे कि विभिन्न उत्पादों और सेवाओं के लिए एक ईकॉमर्स प्लेटफॉर्म, एक तृतीय-पक्ष बाज़ार, क्लाउड इंफ्रास्ट्रक्चर सेवाएं (एडब्ल्यूएस), किंडल ई-रीडर और एलेक्सा वॉयस-संचालित व्यक्तिगत सहायक। . इसके अतिरिक्त, अमेज़ॅन ने अपनी दक्षता में सुधार करने के लिए संरचनात्मक परिवर्तन किए हैं, जैसे कि लागत और डिलीवरी समय को कम करने के लिए अपने अमेरिकी पूर्ति नेटवर्क को पुनर्गठित करना, जिससे इसकी सफलता में और योगदान मिला है। | एलएलएम चेन एक्सट्रैक्टर के समान, एलएलएम चेन फ़िल्टर यह सुनिश्चित करता है कि यद्यपि मुख्य बिंदु कवर किए गए हैं, आउटपुट संक्षिप्त और प्रासंगिक उत्तरों की तलाश करने वाले ग्राहकों के लिए कुशल है। |
इन विभिन्न तकनीकों की तुलना करने पर, हम देख सकते हैं कि AWS के एक साधारण सेवा से एक जटिल, बहु-अरब डॉलर की इकाई में परिवर्तन का विवरण देने या अमेज़ॅन की रणनीतिक सफलताओं की व्याख्या करने जैसे संदर्भों में, नियमित रिट्रीवर श्रृंखला में अधिक परिष्कृत तकनीकों की पेशकश की सटीकता का अभाव है, जिससे कम लक्षित जानकारी प्राप्त होती है। हालाँकि चर्चा की गई उन्नत तकनीकों के बीच बहुत कम अंतर दिखाई देते हैं, वे नियमित रिट्रीवर श्रृंखलाओं की तुलना में कहीं अधिक जानकारीपूर्ण हैं।
स्वास्थ्य देखभाल, दूरसंचार और वित्तीय सेवाओं जैसे उद्योगों में ग्राहकों के लिए जो अपने अनुप्रयोगों में आरएजी को लागू करना चाहते हैं, सटीकता प्रदान करने, अतिरेक से बचने और जानकारी को प्रभावी ढंग से संपीड़ित करने में नियमित रिट्रीवर श्रृंखला की सीमाएं इन जरूरतों को पूरा करने की तुलना में इसे कम अनुकूल बनाती हैं। अधिक उन्नत मूल दस्तावेज़ पुनर्प्राप्ति और प्रासंगिक संपीड़न तकनीकों के लिए। ये तकनीकें मूल्य-प्रदर्शन को बेहतर बनाने में मदद करते हुए बड़ी मात्रा में जानकारी को केंद्रित, प्रभावशाली अंतर्दृष्टि में परिवर्तित करने में सक्षम हैं जिनकी आपको आवश्यकता है।
क्लीन अप
जब आप नोटबुक चलाना समाप्त कर लें, तो उपयोग में आने वाले संसाधनों के लिए शुल्क के संचय से बचने के लिए अपने द्वारा बनाए गए संसाधनों को हटा दें:
निष्कर्ष
इस पोस्ट में, हमने एक समाधान प्रस्तुत किया है जो आपको जानकारी को संसाधित करने और उत्पन्न करने के लिए एलएलएम की क्षमता को बढ़ाने के लिए मूल दस्तावेज़ पुनर्प्राप्ति और प्रासंगिक संपीड़न श्रृंखला तकनीकों को लागू करने की अनुमति देता है। हमने सेजमेकर जम्पस्टार्ट के साथ उपलब्ध मिक्सट्राल-8x7बी इंस्ट्रक्ट और बीजीई लार्ज एन मॉडल के साथ इन उन्नत आरएजी तकनीकों का परीक्षण किया। हमने एम्बेडिंग और दस्तावेज़ खंडों के लिए सतत भंडारण का उपयोग करने और एंटरप्राइज़ डेटा स्टोर के साथ एकीकरण का भी पता लगाया।
हमने जिन तकनीकों का प्रदर्शन किया, वे न केवल एलएलएम मॉडल के बाहरी ज्ञान तक पहुंचने और उसे शामिल करने के तरीके को परिष्कृत करती हैं, बल्कि उनके आउटपुट की गुणवत्ता, प्रासंगिकता और दक्षता में भी उल्लेखनीय सुधार करती हैं। बड़े टेक्स्ट कॉर्पोरा से पुनर्प्राप्ति को भाषा निर्माण क्षमताओं के साथ जोड़कर, ये उन्नत आरएजी तकनीकें एलएलएम को अधिक तथ्यात्मक, सुसंगत और संदर्भ-उपयुक्त प्रतिक्रियाएं उत्पन्न करने में सक्षम बनाती हैं, जिससे विभिन्न प्राकृतिक भाषा प्रसंस्करण कार्यों में उनका प्रदर्शन बढ़ता है।
सेजमेकर जम्पस्टार्ट इस समाधान के केंद्र में है। सेजमेकर जम्पस्टार्ट के साथ, आप खुले और बंद स्रोत मॉडल के व्यापक वर्गीकरण तक पहुंच प्राप्त करते हैं, एमएल के साथ शुरुआत करने की प्रक्रिया को सुव्यवस्थित करते हैं और तेजी से प्रयोग और तैनाती को सक्षम करते हैं। इस समाधान का परिनियोजन आरंभ करने के लिए, नोटबुक में नेविगेट करें गीथहब रेपो.
लेखक के बारे में
 निथियं विजयेश्वरन AWS में सॉल्यूशन आर्किटेक्ट हैं। उनका फोकस क्षेत्र जेनरेटिव एआई और एडब्ल्यूएस एआई एक्सेलेरेटर है। उनके पास कंप्यूटर विज्ञान और जैव सूचना विज्ञान में स्नातक की डिग्री है। Niithiyn AWS ग्राहकों को कई मोर्चों पर सक्षम बनाने और जेनरेटिव AI को अपनाने में तेजी लाने के लिए जेनरेटिव AI GTM टीम के साथ मिलकर काम करता है। वह डलास मावेरिक्स का शौक़ीन प्रशंसक है और उसे स्नीकर्स इकट्ठा करने में मज़ा आता है।
निथियं विजयेश्वरन AWS में सॉल्यूशन आर्किटेक्ट हैं। उनका फोकस क्षेत्र जेनरेटिव एआई और एडब्ल्यूएस एआई एक्सेलेरेटर है। उनके पास कंप्यूटर विज्ञान और जैव सूचना विज्ञान में स्नातक की डिग्री है। Niithiyn AWS ग्राहकों को कई मोर्चों पर सक्षम बनाने और जेनरेटिव AI को अपनाने में तेजी लाने के लिए जेनरेटिव AI GTM टीम के साथ मिलकर काम करता है। वह डलास मावेरिक्स का शौक़ीन प्रशंसक है और उसे स्नीकर्स इकट्ठा करने में मज़ा आता है।
 सेबस्टियन बुस्टिलो AWS में सॉल्यूशन आर्किटेक्ट हैं। वह जेनरेटिव एआई और कंप्यूट एक्सेलेरेटर के प्रति गहन जुनून के साथ एआई/एमएल प्रौद्योगिकियों पर ध्यान केंद्रित करता है। AWS में, वह ग्राहकों को जेनरेटिव AI के माध्यम से व्यावसायिक मूल्य अनलॉक करने में मदद करता है। जब वह काम पर नहीं होता है, तो वह एक बेहतरीन कप विशेष कॉफी बनाने और अपनी पत्नी के साथ दुनिया की खोज करने का आनंद लेता है।
सेबस्टियन बुस्टिलो AWS में सॉल्यूशन आर्किटेक्ट हैं। वह जेनरेटिव एआई और कंप्यूट एक्सेलेरेटर के प्रति गहन जुनून के साथ एआई/एमएल प्रौद्योगिकियों पर ध्यान केंद्रित करता है। AWS में, वह ग्राहकों को जेनरेटिव AI के माध्यम से व्यावसायिक मूल्य अनलॉक करने में मदद करता है। जब वह काम पर नहीं होता है, तो वह एक बेहतरीन कप विशेष कॉफी बनाने और अपनी पत्नी के साथ दुनिया की खोज करने का आनंद लेता है।
 अरमांडो डियाज़ AWS में सॉल्यूशन आर्किटेक्ट हैं। वह जेनरेटिव एआई, एआई/एमएल और डेटा एनालिटिक्स पर ध्यान केंद्रित करता है। AWS में, आर्मंडो ग्राहकों को अपने सिस्टम में अत्याधुनिक जेनरेटिव AI क्षमताओं को एकीकृत करने, नवाचार और प्रतिस्पर्धी लाभ को बढ़ावा देने में मदद करता है। जब वह काम पर नहीं होता है, तो वह अपनी पत्नी और परिवार के साथ समय बिताना, लंबी पैदल यात्रा करना और दुनिया भर की यात्रा करना पसंद करता है।
अरमांडो डियाज़ AWS में सॉल्यूशन आर्किटेक्ट हैं। वह जेनरेटिव एआई, एआई/एमएल और डेटा एनालिटिक्स पर ध्यान केंद्रित करता है। AWS में, आर्मंडो ग्राहकों को अपने सिस्टम में अत्याधुनिक जेनरेटिव AI क्षमताओं को एकीकृत करने, नवाचार और प्रतिस्पर्धी लाभ को बढ़ावा देने में मदद करता है। जब वह काम पर नहीं होता है, तो वह अपनी पत्नी और परिवार के साथ समय बिताना, लंबी पैदल यात्रा करना और दुनिया भर की यात्रा करना पसंद करता है।
 डॉ फारूक साबिर AWS में एक वरिष्ठ आर्टिफिशियल इंटेलिजेंस और मशीन लर्निंग स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। उनके पास ऑस्टिन में टेक्सास विश्वविद्यालय से इलेक्ट्रिकल इंजीनियरिंग में पीएचडी और एमएस की डिग्री है और जॉर्जिया इंस्टीट्यूट ऑफ टेक्नोलॉजी से कंप्यूटर साइंस में एमएस है। उनके पास 15 साल से अधिक का कार्य अनुभव है और वह कॉलेज के छात्रों को पढ़ाना और सलाह देना भी पसंद करते हैं। AWS में, वह ग्राहकों को डेटा साइंस, मशीन लर्निंग, कंप्यूटर विज़न, आर्टिफिशियल इंटेलिजेंस, न्यूमेरिकल ऑप्टिमाइज़ेशन और संबंधित डोमेन में उनकी व्यावसायिक समस्याओं को तैयार करने और हल करने में मदद करता है। डलास, टेक्सास में स्थित, वह और उसका परिवार यात्रा करना और लंबी सड़क यात्राओं पर जाना पसंद करते हैं।
डॉ फारूक साबिर AWS में एक वरिष्ठ आर्टिफिशियल इंटेलिजेंस और मशीन लर्निंग स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। उनके पास ऑस्टिन में टेक्सास विश्वविद्यालय से इलेक्ट्रिकल इंजीनियरिंग में पीएचडी और एमएस की डिग्री है और जॉर्जिया इंस्टीट्यूट ऑफ टेक्नोलॉजी से कंप्यूटर साइंस में एमएस है। उनके पास 15 साल से अधिक का कार्य अनुभव है और वह कॉलेज के छात्रों को पढ़ाना और सलाह देना भी पसंद करते हैं। AWS में, वह ग्राहकों को डेटा साइंस, मशीन लर्निंग, कंप्यूटर विज़न, आर्टिफिशियल इंटेलिजेंस, न्यूमेरिकल ऑप्टिमाइज़ेशन और संबंधित डोमेन में उनकी व्यावसायिक समस्याओं को तैयार करने और हल करने में मदद करता है। डलास, टेक्सास में स्थित, वह और उसका परिवार यात्रा करना और लंबी सड़क यात्राओं पर जाना पसंद करते हैं।
 मार्को पूनियो एक सॉल्यूशन आर्किटेक्ट है जो जेनरेटिव एआई रणनीति, एप्लाइड एआई समाधानों और एडब्ल्यूएस पर ग्राहकों को हाइपर-स्केल में मदद करने के लिए अनुसंधान करने पर केंद्रित है। मार्को एक डिजिटल नेटिव क्लाउड सलाहकार है जिसके पास फिनटेक, हेल्थकेयर और लाइफ साइंसेज, सॉफ्टवेयर-ए-ए-सर्विस और हाल ही में दूरसंचार उद्योगों में अनुभव है। वह मशीन लर्निंग, आर्टिफिशियल इंटेलिजेंस और विलय एवं अधिग्रहण के जुनून के साथ एक योग्य प्रौद्योगिकीविद् हैं। मार्को सिएटल, वाशिंगटन में स्थित है और अपने खाली समय में लिखना, पढ़ना, व्यायाम करना और एप्लिकेशन बनाना पसंद करता है।
मार्को पूनियो एक सॉल्यूशन आर्किटेक्ट है जो जेनरेटिव एआई रणनीति, एप्लाइड एआई समाधानों और एडब्ल्यूएस पर ग्राहकों को हाइपर-स्केल में मदद करने के लिए अनुसंधान करने पर केंद्रित है। मार्को एक डिजिटल नेटिव क्लाउड सलाहकार है जिसके पास फिनटेक, हेल्थकेयर और लाइफ साइंसेज, सॉफ्टवेयर-ए-ए-सर्विस और हाल ही में दूरसंचार उद्योगों में अनुभव है। वह मशीन लर्निंग, आर्टिफिशियल इंटेलिजेंस और विलय एवं अधिग्रहण के जुनून के साथ एक योग्य प्रौद्योगिकीविद् हैं। मार्को सिएटल, वाशिंगटन में स्थित है और अपने खाली समय में लिखना, पढ़ना, व्यायाम करना और एप्लिकेशन बनाना पसंद करता है।
 ए जे धीमिन AWS में सॉल्यूशन आर्किटेक्ट हैं। वह जेनरेटिव एआई, सर्वरलेस कंप्यूटिंग और डेटा एनालिटिक्स में माहिर हैं। वह मशीन लर्निंग टेक्निकल फील्ड कम्युनिटी में एक सक्रिय सदस्य/संरक्षक हैं और उन्होंने विभिन्न एआई/एमएल विषयों पर कई वैज्ञानिक पत्र प्रकाशित किए हैं। वह AWSome जेनरेटिव AI समाधान विकसित करने के लिए स्टार्ट-अप से लेकर उद्यमों तक के ग्राहकों के साथ काम करता है। वह विशेष रूप से उन्नत डेटा विश्लेषण के लिए बड़े भाषा मॉडल का लाभ उठाने और वास्तविक दुनिया की चुनौतियों का समाधान करने वाले व्यावहारिक अनुप्रयोगों की खोज करने के बारे में भावुक हैं। काम के अलावा, एजे को यात्रा करना पसंद है, और वर्तमान में वह दुनिया के हर देश का दौरा करने के लक्ष्य के साथ 53 देशों में है।
ए जे धीमिन AWS में सॉल्यूशन आर्किटेक्ट हैं। वह जेनरेटिव एआई, सर्वरलेस कंप्यूटिंग और डेटा एनालिटिक्स में माहिर हैं। वह मशीन लर्निंग टेक्निकल फील्ड कम्युनिटी में एक सक्रिय सदस्य/संरक्षक हैं और उन्होंने विभिन्न एआई/एमएल विषयों पर कई वैज्ञानिक पत्र प्रकाशित किए हैं। वह AWSome जेनरेटिव AI समाधान विकसित करने के लिए स्टार्ट-अप से लेकर उद्यमों तक के ग्राहकों के साथ काम करता है। वह विशेष रूप से उन्नत डेटा विश्लेषण के लिए बड़े भाषा मॉडल का लाभ उठाने और वास्तविक दुनिया की चुनौतियों का समाधान करने वाले व्यावहारिक अनुप्रयोगों की खोज करने के बारे में भावुक हैं। काम के अलावा, एजे को यात्रा करना पसंद है, और वर्तमान में वह दुनिया के हर देश का दौरा करने के लक्ष्य के साथ 53 देशों में है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

