ग्राहकों को बुनियादी ढांचे और एप्लिकेशन संसाधनों में बढ़ते सुरक्षा खतरों और कमजोरियों का सामना करना पड़ रहा है क्योंकि उनके डिजिटल पदचिह्न का विस्तार हुआ है और उन डिजिटल परिसंपत्तियों का व्यावसायिक प्रभाव बढ़ गया है। एक सामान्य साइबर सुरक्षा चुनौती दो प्रकार की रही है:
- विभिन्न प्रारूपों और स्कीमाओं में आने वाले डिजिटल संसाधनों से लॉग का उपभोग करना और उन लॉग के आधार पर खतरे के निष्कर्षों के विश्लेषण को स्वचालित करना।
- चाहे लॉग अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस), अन्य क्लाउड प्रदाताओं, ऑन-प्रिमाइसेस या एज डिवाइस से आ रहे हों, ग्राहकों को सुरक्षा डेटा को केंद्रीकृत और मानकीकृत करने की आवश्यकता है।
इसके अलावा, सुरक्षा खतरों की पहचान करने के लिए विश्लेषण को खतरे वाले अभिनेताओं, सुरक्षा वैक्टर और डिजिटल संपत्तियों के बदलते परिदृश्य को पूरा करने के लिए स्केल करने और विकसित करने में सक्षम होना चाहिए।
इस जटिल सुरक्षा विश्लेषण परिदृश्य को हल करने के लिए एक नया दृष्टिकोण सुरक्षा डेटा के अंतर्ग्रहण और भंडारण को जोड़ता है अमेज़न सुरक्षा झील और मशीन लर्निंग (एमएल) का उपयोग करके सुरक्षा डेटा का विश्लेषण करना अमेज़न SageMaker. अमेज़ॅन सिक्योरिटी लेक एक उद्देश्य-निर्मित सेवा है जो किसी संगठन के सुरक्षा डेटा को क्लाउड और ऑन-प्रिमाइसेस स्रोतों से स्वचालित रूप से आपके AWS खाते में संग्रहीत एक उद्देश्य-निर्मित डेटा लेक में केंद्रीकृत करती है। अमेज़ॅन सिक्योरिटी लेक सुरक्षा डेटा के केंद्रीय प्रबंधन को स्वचालित करता है, एकीकृत एडब्ल्यूएस सेवाओं और तृतीय-पक्ष सेवाओं से लॉग को सामान्य करता है और अनुकूलन योग्य प्रतिधारण के साथ डेटा के जीवनचक्र का प्रबंधन करता है और स्टोरेज टियरिंग को भी स्वचालित करता है। अमेज़ॅन सिक्योरिटी लेक में लॉग फ़ाइलें शामिल होती हैं साइबर सुरक्षा स्कीमा फ्रेमवर्क खोलें (OCSF) प्रारूप, सिस्को सिक्योरिटी, क्राउडस्ट्राइक, पालो ऑल्टो नेटवर्क्स और आपके AWS वातावरण के बाहर के संसाधनों से OCSF लॉग जैसे भागीदारों के लिए समर्थन के साथ। यह एकीकृत स्कीमा डाउनस्ट्रीम खपत और विश्लेषण को सुव्यवस्थित करती है क्योंकि डेटा एक मानकीकृत स्कीमा का पालन करता है और न्यूनतम डेटा पाइपलाइन परिवर्तनों के साथ नए स्रोत जोड़े जा सकते हैं। अमेज़ॅन सिक्योरिटी लेक में सुरक्षा लॉग डेटा संग्रहीत होने के बाद, सवाल यह है कि इसका विश्लेषण कैसे किया जाए। सुरक्षा लॉग डेटा का विश्लेषण करने का एक प्रभावी तरीका एमएल का उपयोग करना है; विशेष रूप से, विसंगति का पता लगाना, जो गतिविधि और ट्रैफ़िक डेटा की जांच करता है और इसकी तुलना आधार रेखा से करता है। आधार रेखा परिभाषित करती है कि उस वातावरण के लिए कौन सी गतिविधि सांख्यिकीय रूप से सामान्य है। विसंगति का पता लगाने का पैमाना एक व्यक्तिगत घटना हस्ताक्षर से परे है, और यह समय-समय पर पुनः प्रशिक्षण के साथ विकसित हो सकता है; असामान्य या विसंगतिपूर्ण के रूप में वर्गीकृत ट्रैफ़िक पर प्राथमिकता के आधार पर ध्यान और तत्परता से कार्रवाई की जा सकती है। अमेज़ॅन सेजमेकर एक पूरी तरह से प्रबंधित सेवा है जो ग्राहकों को व्यवसाय विश्लेषकों के लिए नो-कोड पेशकश सहित पूरी तरह से प्रबंधित बुनियादी ढांचे, टूल और वर्कफ़्लो के साथ किसी भी उपयोग के मामले के लिए डेटा तैयार करने और एमएल मॉडल बनाने, प्रशिक्षित करने और तैनात करने में सक्षम बनाती है। सेजमेकर दो अंतर्निहित विसंगति पहचान एल्गोरिदम का समर्थन करता है: आईपी अंतर्दृष्टि और बेतरतीब ढंग से काटा गया जंगल. आप अपना खुद का कस्टम आउटलायर डिटेक्शन मॉडल बनाने के लिए सेजमेकर का भी उपयोग कर सकते हैं एल्गोरिदम कई एमएल फ्रेमवर्क से प्राप्त।
इस पोस्ट में, आप सीखेंगे कि अमेज़ॅन सिक्योरिटी लेक से प्राप्त डेटा कैसे तैयार किया जाए, और फिर सेजमेकर में आईपी इनसाइट्स एल्गोरिदम का उपयोग करके एमएल मॉडल को प्रशिक्षित और तैनात किया जाए। यह मॉडल असामान्य नेटवर्क ट्रैफ़िक या व्यवहार की पहचान करता है जिसे बाद में एक बड़े एंड-टू-एंड सुरक्षा समाधान के हिस्से के रूप में तैयार किया जा सकता है। यदि कोई उपयोगकर्ता किसी असामान्य सर्वर से या असामान्य समय पर साइन इन कर रहा है तो ऐसा समाधान बहु-कारक प्रमाणीकरण (एमएफए) जांच को लागू कर सकता है, यदि नए आईपी पते से कोई संदिग्ध नेटवर्क स्कैन आ रहा है तो कर्मचारियों को सूचित करें, असामान्य नेटवर्क होने पर प्रशासकों को सचेत करें प्रोटोकॉल या पोर्ट का उपयोग किया जाता है, या अन्य डेटा स्रोतों जैसे आईपी अंतर्दृष्टि वर्गीकरण परिणाम को समृद्ध किया जाता है अमेज़न गार्डडूट और आईपी प्रतिष्ठा स्कोर खतरे के निष्कर्षों को रैंक करने के लिए।
समाधान अवलोकन
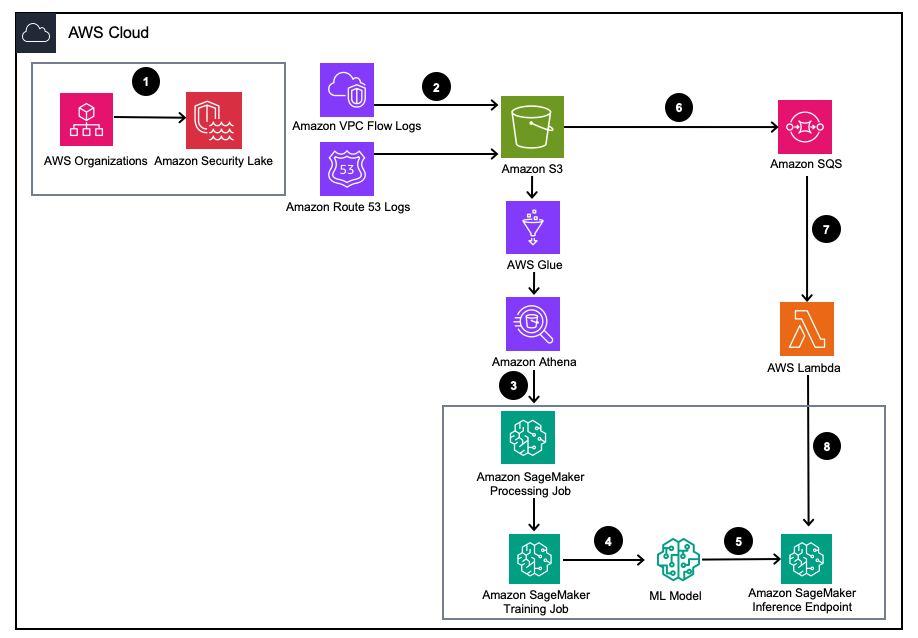
चित्र 1 - समाधान वास्तुकला
- अमेज़ॅन सिक्योरिटी लेक को सक्षम करें AWS संगठन AWS खातों, AWS क्षेत्रों और बाहरी IT परिवेशों के लिए।
- से सुरक्षा झील स्रोत स्थापित करें अमेज़न वर्चुअल प्राइवेट क्लाउड (अमेज़न VPC) प्रवाह लॉग और अमेज़न रूट53 DNS अमेज़ॅन सिक्योरिटी लेक S3 बकेट में लॉग करता है।
- सुविधाओं को इंजीनियर करने के लिए सेजमेकर प्रोसेसिंग जॉब का उपयोग करके अमेज़ॅन सिक्योरिटी लेक लॉग डेटा को प्रोसेस करें। उपयोग अमेज़न एथेना संरचित OCSF लॉग डेटा से क्वेरी करने के लिए अमेज़न सरल भंडारण सेवा (अमेज़न S3) पूज्य गुरुदेव के मार्गदर्शन से संपन्न कर सकते हैं - एडब्ल्यूएस गोंद AWS LakeFormation द्वारा प्रबंधित तालिकाएँ।
- सेजमेकर ट्रेनिंग जॉब का उपयोग करके सेजमेकर एमएल मॉडल को प्रशिक्षित करें जो संसाधित अमेज़ॅन सिक्योरिटी लेक लॉग का उपभोग करता है।
- प्रशिक्षित एमएल मॉडल को सेजमेकर अनुमान समापन बिंदु पर तैनात करें।
- नए सुरक्षा लॉग को S3 बकेट में संग्रहीत करें और इवेंट को कतार में रखें अमेज़न सरल कतार सेवा (अमेज़न SQS).
- एक सदस्यता लें AWS लाम्बा SQS कतार में कार्य करें।
- वास्तविक समय में सुरक्षा लॉग को विसंगतियों के रूप में वर्गीकृत करने के लिए लैम्ब्डा फ़ंक्शन का उपयोग करके सेजमेकर अनुमान समापन बिंदु को लागू करें।
.. पूर्वापेक्षाएँ
समाधान को तैनात करने के लिए, आपको पहले निम्नलिखित आवश्यकताएँ पूरी करनी होंगी:
- अमेज़ॅन सुरक्षा झील सक्षम करें आपके संगठन के भीतर या वीपीसी फ़्लो लॉग और रूट 53 रिज़ॉल्वर लॉग दोनों सक्षम वाले एकल खाते में।
- सुनिश्चित करें कि AWS पहचान और अभिगम प्रबंधन (IAM) नौकरियों और नोटबुक्स को संसाधित करने में सेजमेकर द्वारा उपयोग की जाने वाली भूमिका को IAM नीति प्रदान की गई है, जिसमें शामिल है अमेज़ॅन सिक्योरिटी लेक सब्सक्राइबर क्वेरी एक्सेस अनुमति प्रबंधित अमेज़ॅन सिक्योरिटी लेक डेटाबेस और AWS लेक फॉर्मेशन द्वारा प्रबंधित तालिकाओं के लिए। अनुपालन बनाए रखने के लिए इस प्रोसेसिंग कार्य को एक एनालिटिक्स या सुरक्षा टूलींग खाते के भीतर से चलाया जाना चाहिए AWS सुरक्षा संदर्भ वास्तुकला (AWS SRA).
- सुनिश्चित करें कि लैम्ब्डा फ़ंक्शन द्वारा उपयोग की जाने वाली IAM भूमिका को IAM नीति प्रदान की गई है अमेज़ॅन सिक्योरिटी लेक सब्सक्राइबर डेटा एक्सेस अनुमति.
समाधान तैनात करें
परिवेश स्थापित करने के लिए, निम्नलिखित चरणों को पूरा करें:
- लॉन्च करें सेजमेकर स्टूडियो या सेजमेकर ज्यूपिटर नोटबुक के साथ
ml.m5.largeउदाहरण। नोट: इंस्टेंस का आकार आपके द्वारा उपयोग किए जाने वाले डेटासेट पर निर्भर है। - GitHub को क्लोन करें कोष.
- िकताबेखोलो
01_ipinsights/01-01.amazon-securitylake-sagemaker-ipinsights.ipy. - लागू करें आईएएम नीति प्रदान की गई और संगत IAM ट्रस्ट नीति आपके सेजमेकर स्टूडियो नोटबुक इंस्टेंस के लिए S3, लेक फॉर्मेशन और एथेना में सभी आवश्यक डेटा तक पहुंचने के लिए।
यह ब्लॉग आपके परिवेश में तैनात होने के बाद नोटबुक के भीतर कोड के प्रासंगिक हिस्से पर चलता है।
निर्भरताएँ स्थापित करें और आवश्यक लाइब्रेरी आयात करें
निर्भरताएँ स्थापित करने, आवश्यक लाइब्रेरी आयात करने और डेटा प्रोसेसिंग और मॉडल प्रशिक्षण के लिए आवश्यक सेजमेकर S3 बकेट बनाने के लिए निम्नलिखित कोड का उपयोग करें। आवश्यक पुस्तकालयों में से एक, awswrangler, है एक पांडा डेटाफ़्रेम के लिए AWS SDK इसका उपयोग AWS ग्लू डेटा कैटलॉग के भीतर प्रासंगिक तालिकाओं को क्वेरी करने और परिणामों को स्थानीय रूप से डेटाफ़्रेम में संग्रहीत करने के लिए किया जाता है।
अमेज़ॅन सिक्योरिटी लेक वीपीसी प्रवाह लॉग तालिका को क्वेरी करें
कोड का यह भाग VPC फ़्लो लॉग से संबंधित AWS ग्लू तालिका को क्वेरी करने के लिए पांडा के लिए AWS SDK का उपयोग करता है। जैसा कि पूर्वापेक्षाओं में बताया गया है, अमेज़ॅन सिक्योरिटी लेक टेबल का प्रबंधन किया जाता है AWS झील निर्माण, इसलिए सेजमेकर नोटबुक द्वारा उपयोग की जाने वाली भूमिका के लिए सभी उचित अनुमतियाँ दी जानी चाहिए। यह क्वेरी कई दिनों के VPC फ़्लो लॉग ट्रैफ़िक को खींच लेगी। इस ब्लॉग के विकास के दौरान उपयोग किया गया डेटासेट छोटा था। आपके उपयोग के मामले के पैमाने के आधार पर, आपको पांडा के लिए AWS SDK की सीमाओं के बारे में पता होना चाहिए। टेराबाइट पैमाने पर विचार करते समय, आपको पांडा समर्थन के लिए AWS SDK पर विचार करना चाहिए मोदीन.
जब आप डेटा फ़्रेम देखते हैं, तो आपको सामान्य फ़ील्ड वाले एकल कॉलम का आउटपुट दिखाई देगा जो इसमें पाया जा सकता है नेटवर्क गतिविधि (4001) ओसीएसएफ की कक्षा।
आईपी इनसाइट्स के लिए आवश्यक प्रशिक्षण प्रारूप में अमेज़ॅन सिक्योरिटी लेक वीपीसी प्रवाह लॉग डेटा को सामान्य करें।
आईपी इनसाइट्स एल्गोरिदम के लिए आवश्यक है कि प्रशिक्षण डेटा सीएसवी प्रारूप में हो और इसमें दो कॉलम हों। पहला कॉलम एक अपारदर्शी स्ट्रिंग होना चाहिए जो किसी इकाई के विशिष्ट पहचानकर्ता से मेल खाता हो। दूसरा कॉलम दशमलव-डॉट नोटेशन में इकाई के एक्सेस इवेंट का IPv4 पता होना चाहिए। इस ब्लॉग के लिए नमूना डेटासेट में, विशिष्ट पहचानकर्ता EC2 उदाहरणों से संबंधित इंस्टेंस आईडी है instance_id के भीतर मूल्य dataframe. IPv4 पता से प्राप्त किया जाएगा src_endpoint. अमेज़ॅन एथेना क्वेरी जिस तरह से बनाई गई थी, उसके आधार पर, आईपी इनसाइट्स मॉडल के प्रशिक्षण के लिए आयातित डेटा पहले से ही सही प्रारूप में है, इसलिए किसी अतिरिक्त फीचर इंजीनियरिंग की आवश्यकता नहीं है। यदि आप क्वेरी को किसी अन्य तरीके से संशोधित करते हैं, तो आपको अतिरिक्त फीचर इंजीनियरिंग को शामिल करने की आवश्यकता हो सकती है।
अमेज़ॅन सिक्योरिटी लेक रूट 53 रिज़ॉल्वर लॉग तालिका को क्वेरी करें और सामान्य करें
जैसा कि आपने ऊपर किया, नोटबुक का अगला चरण अमेज़ॅन सिक्योरिटी लेक रूट 53 रिज़ॉल्वर तालिका के विरुद्ध एक समान क्वेरी चलाता है। चूँकि आप इस नोटबुक के भीतर सभी OCSF अनुरूप डेटा का उपयोग कर रहे होंगे, कोई भी फीचर इंजीनियरिंग कार्य रूट 53 रिज़ॉल्वर लॉग के लिए वैसे ही रहेंगे जैसे वे VPC फ़्लो लॉग के लिए थे। फिर आप दो डेटा फ़्रेमों को एक एकल डेटा फ़्रेम में संयोजित करते हैं जिसका उपयोग प्रशिक्षण के लिए किया जाता है। चूंकि अमेज़ॅन एथेना क्वेरी डेटा को स्थानीय रूप से सही प्रारूप में लोड करती है, इसलिए किसी और फीचर इंजीनियरिंग की आवश्यकता नहीं है।
आईपी इनसाइट्स प्रशिक्षण छवि प्राप्त करें और ओसीएसएफ डेटा के साथ मॉडल को प्रशिक्षित करें
नोटबुक के इस अगले भाग में, आप आईपी इनसाइट्स एल्गोरिदम के आधार पर एक एमएल मॉडल को प्रशिक्षित करते हैं और समेकित का उपयोग करते हैं dataframe विभिन्न प्रकार के लॉग से ओसीएसएफ का। आईपी इनसाइट्स हाइपरपरमेटर्स की एक सूची पाई जा सकती है यहाँ उत्पन्न करें. नीचे दिए गए उदाहरण में हमने हाइपरपैरामीटर का चयन किया है जो सबसे अच्छा प्रदर्शन करने वाला मॉडल आउटपुट करता है, उदाहरण के लिए, युग के लिए 5 और वेक्टर_डिम के लिए 128। चूँकि हमारे नमूने के लिए प्रशिक्षण डेटासेट अपेक्षाकृत छोटा था, इसलिए हमने इसका उपयोग किया ml.m5.large उदाहरण। हाइपरपैरामीटर और आपके प्रशिक्षण कॉन्फ़िगरेशन जैसे इंस्टेंस गिनती और इंस्टेंस प्रकार को आपके उद्देश्य मेट्रिक्स और आपके प्रशिक्षण डेटा आकार के आधार पर चुना जाना चाहिए। एक क्षमता जिसका उपयोग आप Amazon SageMaker के भीतर अपने मॉडल का सर्वोत्तम संस्करण खोजने के लिए कर सकते हैं, वह है Amazon SageMaker स्वचालित मॉडल ट्यूनिंग जो हाइपरपैरामीटर मानों की एक श्रृंखला में सर्वोत्तम मॉडल की खोज करता है।
प्रशिक्षित मॉडल को तैनात करें और वैध और असंगत ट्रैफ़िक के साथ परीक्षण करें
मॉडल को प्रशिक्षित करने के बाद, आप मॉडल को सेजमेकर एंडपॉइंट पर तैनात करते हैं और अपने मॉडल का परीक्षण करने के लिए अद्वितीय पहचानकर्ता और आईपीवी4 पता संयोजनों की एक श्रृंखला भेजते हैं। कोड का यह भाग मानता है कि आपके S3 बकेट में परीक्षण डेटा सहेजा गया है। परीक्षण डेटा एक .csv फ़ाइल है, जहां पहला कॉलम इंस्टेंस आईडी है और दूसरा कॉलम आईपी है। मॉडल के परिणाम देखने के लिए वैध और अमान्य डेटा का परीक्षण करने की अनुशंसा की जाती है। निम्नलिखित कोड आपके समापन बिंदु को तैनात करता है।
अब जब आपका समापन बिंदु तैनात हो गया है, तो अब आप यह पहचानने के लिए अनुमान अनुरोध सबमिट कर सकते हैं कि ट्रैफ़िक संभावित रूप से असामान्य है या नहीं। आपका स्वरूपित डेटा कैसा दिखना चाहिए इसका एक नमूना नीचे दिया गया है। इस मामले में, पहला कॉलम पहचानकर्ता एक इंस्टेंस आईडी है और दूसरा कॉलम एक संबद्ध आईपी पता है जैसा कि निम्नलिखित में दिखाया गया है:
अपना डेटा CSV प्रारूप में रखने के बाद, आप S3 बकेट से अपनी .csv फ़ाइल को पढ़कर कोड का उपयोग करके अनुमान के लिए डेटा सबमिट कर सकते हैं।
आईपी इनसाइट्स मॉडल का आउटपुट यह माप प्रदान करता है कि आईपी एड्रेस और ऑनलाइन संसाधन सांख्यिकीय रूप से कितने अपेक्षित हैं। हालाँकि, इस पते और संसाधन की सीमा असीमित है, इसलिए इस बात पर विचार हो रहा है कि आप कैसे निर्धारित करेंगे कि किसी इंस्टेंस आईडी और आईपी पते के संयोजन को असंगत माना जाना चाहिए या नहीं।
पिछले उदाहरण में, मॉडल में चार अलग-अलग पहचानकर्ता और आईपी संयोजन प्रस्तुत किए गए थे। पहले दो संयोजन वैध इंस्टेंस आईडी और आईपी एड्रेस संयोजन थे जो प्रशिक्षण सेट के आधार पर अपेक्षित हैं। तीसरे संयोजन में सही विशिष्ट पहचानकर्ता है लेकिन एक ही सबनेट के भीतर एक अलग आईपी पता है। मॉडल को यह निर्धारित करना चाहिए कि एक मामूली विसंगति है क्योंकि एम्बेडिंग प्रशिक्षण डेटा से थोड़ा अलग है। चौथे संयोजन में एक वैध विशिष्ट पहचानकर्ता है लेकिन पर्यावरण में किसी भी वीपीसी के भीतर एक गैर-मौजूद सबनेट का आईपी पता है।
नोट: सामान्य और असामान्य ट्रैफ़िक डेटा आपके विशिष्ट उपयोग के मामले के आधार पर बदल जाएगा, उदाहरण के लिए: यदि आप बाहरी और आंतरिक ट्रैफ़िक की निगरानी करना चाहते हैं तो आपको प्रत्येक आईपी पते से जुड़े एक अद्वितीय पहचानकर्ता और बाहरी पहचानकर्ताओं को उत्पन्न करने के लिए एक योजना की आवश्यकता होगी।
ज्ञात सामान्य और असामान्य ट्रैफ़िक का उपयोग करके यह निर्धारित किया जा सकता है कि ट्रैफ़िक असामान्य है या नहीं, यह निर्धारित करने के लिए आपकी सीमा क्या होनी चाहिए। इसमें बताए गए चरण यह नमूना नोटबुक इस प्रकार हैं:
- सामान्य यातायात को दर्शाने के लिए एक परीक्षण सेट का निर्माण करें।
- डेटासेट में असामान्य ट्रैफ़िक जोड़ें।
- का वितरण आलेखित करें
dot_productसामान्य ट्रैफ़िक और असामान्य ट्रैफ़िक पर मॉडल के लिए स्कोर। - एक सीमा मान चुनें जो सामान्य उपसमुच्चय को असामान्य उपसमुच्चय से अलग करता है। यह मान आपकी झूठी-सकारात्मक सहनशीलता पर आधारित है
नए वीपीसी प्रवाह लॉग ट्रैफ़िक की निरंतर निगरानी स्थापित करें।
यह प्रदर्शित करने के लिए कि इस नए एमएल मॉडल को अमेज़ॅन सिक्योरिटी लेक के साथ सक्रिय तरीके से कैसे उपयोग किया जा सकता है, हम प्रत्येक पर एक लैम्ब्डा फ़ंक्शन को कॉन्फ़िगर करेंगे। PutObject अमेज़ॅन सिक्योरिटी लेक प्रबंधित बकेट के भीतर घटना, विशेष रूप से वीपीसी प्रवाह लॉग डेटा। अमेज़ॅन सिक्योरिटी लेक के भीतर एक ग्राहक की अवधारणा है, जो अमेज़ॅन सिक्योरिटी लेक से लॉग और इवेंट का उपभोग करता है। नई घटनाओं पर प्रतिक्रिया देने वाले लैम्ब्डा फ़ंक्शन को डेटा एक्सेस सदस्यता प्रदान की जानी चाहिए। डेटा एक्सेस सब्सक्राइबर्स को एक स्रोत के लिए नए अमेज़ॅन S3 ऑब्जेक्ट के बारे में सूचित किया जाता है क्योंकि ऑब्जेक्ट सिक्योरिटी लेक बकेट में लिखे जाते हैं। सब्सक्राइबर सीधे S3 ऑब्जेक्ट तक पहुंच सकते हैं और सब्सक्रिप्शन एंडपॉइंट के माध्यम से या अमेज़ॅन SQS कतार को पोल करके नई ऑब्जेक्ट की सूचनाएं प्राप्त कर सकते हैं।
- ओपन सुरक्षा झील कंसोल.
- नेविगेशन फलक में, चुनें सभी सदस्य.
- सब्सक्राइबर्स पेज पर, चुनें ग्राहक बनाएं.
- सब्सक्राइबर विवरण के लिए, दर्ज करें
inferencelambdaएसटी सब्सक्राइबर का नाम और एक वैकल्पिक Description. - RSI क्षेत्र स्वचालित रूप से आपके वर्तमान में चयनित AWS क्षेत्र के रूप में सेट हो जाता है और इसे संशोधित नहीं किया जा सकता है।
- के लिए लॉग और ईवेंट स्रोत, चुनें विशिष्ट लॉग और ईवेंट स्रोत और चुनें वीपीसी फ्लो लॉग और रूट 53 लॉग
- के लिए डेटा एक्सेस विधि, चुनें S3.
- के लिए सब्सक्राइबर क्रेडेंशियल, उस खाते की अपनी AWS खाता आईडी प्रदान करें जहां लैम्ब्डा फ़ंक्शन रहेगा और उपयोगकर्ता द्वारा निर्दिष्ट किया जाएगा बाहरी आईडी.
नोट: यदि आप इसे किसी खाते के भीतर स्थानीय रूप से कर रहे हैं, तो आपको बाहरी आईडी की आवश्यकता नहीं है। - चुनें बनाएं.
लैम्ब्डा फ़ंक्शन बनाएं
लैम्ब्डा फ़ंक्शन को बनाने और तैनात करने के लिए आप या तो निम्नलिखित चरणों को पूरा कर सकते हैं या पूर्वनिर्मित एसएएम टेम्पलेट को तैनात कर सकते हैं 01_ipinsights/01.02-ipcheck.yaml GitHub रेपो में। एसएएम टेम्पलेट के लिए आवश्यक है कि आप एसक्यूएस एआरएन और सेजमेकर एंडपॉइंट नाम प्रदान करें।
- लैम्ब्डा कंसोल पर, चुनें फ़ंक्शन बनाएं.
- चुनें खरोंच से लेखक.
- के लिए फ़ंक्शन का नाम, दर्ज
ipcheck. - के लिए क्रम, चुनें अजगर 3.10.
- के लिए आर्किटेक्चर, चुनते हैं x86_64.
- के लिए निष्पादन भूमिका, चुनते हैं लैम्ब्डा अनुमतियों के साथ एक नई भूमिका बनाएँ.
- फ़ंक्शन बनाने के बाद, इसकी सामग्री दर्ज करें ipcheck.py GitHub रेपो से फ़ाइल।
- नेविगेशन फलक में, चुनें पर्यावरण चर.
- चुनें संपादित करें.
- चुनें पर्यावरण चर जोड़ें.
- नए पर्यावरण चर के लिए, दर्ज करें
ENDPOINT_NAMEऔर मान के लिए एंडपॉइंट एआरएन दर्ज करें जो सेजमेकर एंडपॉइंट की तैनाती के दौरान आउटपुट किया गया था। - चुनते हैं सहेजें.
- चुनें तैनाती.
- नेविगेशन फलक में, चुनें विन्यास.
- चुनते हैं ट्रिगर्स.
- चुनते हैं ट्रिगर जोड़ें.
- के अंतर्गत एक स्रोत चुनें, चुनें एसक्यूएस.
- के अंतर्गत एसक्यूएस कतार, सिक्योरिटी लेक द्वारा बनाई गई मुख्य एसक्यूएस कतार का एआरएन दर्ज करें।
- के लिए चेकबॉक्स चुनें ट्रिगर सक्रिय करें.
- चुनते हैं .
लैम्ब्डा निष्कर्षों को मान्य करें
- ओपन अमेज़न क्लाउडवॉच कंसोल.
- बाईं ओर के फलक में, चुनें लॉग समूह.
- खोज बार में, ipcheck दर्ज करें, और फिर नाम के साथ लॉग समूह का चयन करें
/aws/lambda/ipcheck. - नीचे नवीनतम लॉग स्ट्रीम का चयन करें लॉग स्ट्रीम.
- लॉग के भीतर, आपको प्रत्येक नए अमेज़ॅन सिक्योरिटी लेक लॉग के लिए निम्नलिखित जैसे परिणाम देखने चाहिए:
{'predictions': [{'dot_product': 0.018832731992006302}, {'dot_product': 0.018832731992006302}]}
यह लैम्ब्डा फ़ंक्शन अमेज़ॅन सिक्योरिटी लेक द्वारा प्राप्त किए जा रहे नेटवर्क ट्रैफ़िक का लगातार विश्लेषण करता है। यह आपको एक निर्दिष्ट सीमा का उल्लंघन होने पर अपनी सुरक्षा टीमों को सूचित करने के लिए तंत्र बनाने की अनुमति देता है, जो आपके वातावरण में असामान्य ट्रैफ़िक का संकेत देगा।
साफ - सफाई
जब आप इस समाधान के साथ प्रयोग करना समाप्त कर लें और अपने खाते पर शुल्क से बचने के लिए, S3 बकेट, सेजमेकर एंडपॉइंट को हटाकर, सेजमेकर ज्यूपिटर नोटबुक से जुड़ी गणना को बंद करके, लैम्ब्डा फ़ंक्शन को हटाकर और अमेज़ॅन सुरक्षा को अक्षम करके अपने संसाधनों को साफ करें। आपके खाते में झील.
निष्कर्ष
इस पोस्ट में आपने सीखा कि मशीन लर्निंग के लिए अमेज़ॅन सिक्योरिटी लेक से प्राप्त नेटवर्क ट्रैफ़िक डेटा कैसे तैयार किया जाए, और फिर अमेज़ॅन सेजमेकर में आईपी इनसाइट्स एल्गोरिदम का उपयोग करके एक एमएल मॉडल को प्रशिक्षित और तैनात किया जाए। ज्यूपिटर नोटबुक में उल्लिखित सभी चरणों को एंड-टू-एंड एमएल पाइपलाइन में दोहराया जा सकता है। आपने एक एडब्ल्यूएस लैम्ब्डा फ़ंक्शन भी कार्यान्वित किया है जो नए अमेज़ॅन सिक्योरिटी लेक लॉग का उपभोग करता है और प्रशिक्षित विसंगति पहचान मॉडल के आधार पर निष्कर्ष प्रस्तुत करता है। AWS लैम्ब्डा द्वारा प्राप्त एमएल मॉडल प्रतिक्रियाएँ कुछ निश्चित सीमाएँ पूरी होने पर सुरक्षा टीमों को अनियमित ट्रैफ़िक के बारे में सक्रिय रूप से सूचित कर सकती हैं। लूप समीक्षाओं में अपनी सुरक्षा टीम को शामिल करके मॉडल में निरंतर सुधार को सक्षम किया जा सकता है ताकि यह लेबल किया जा सके कि असामान्य के रूप में पहचाना गया ट्रैफ़िक गलत सकारात्मक था या नहीं। फिर इसे आपके प्रशिक्षण सेट में जोड़ा जा सकता है और आपके साथ भी जोड़ा जा सकता है साधारण अनुभवजन्य सीमा निर्धारित करते समय ट्रैफ़िक डेटासेट। यह मॉडल संभावित रूप से असामान्य नेटवर्क ट्रैफ़िक या व्यवहार की पहचान कर सकता है जिससे इसे एमएफए जांच शुरू करने के लिए एक बड़े सुरक्षा समाधान के हिस्से के रूप में शामिल किया जा सकता है यदि कोई उपयोगकर्ता असामान्य सर्वर से या असामान्य समय पर साइन इन कर रहा है, तो कोई संदिग्ध होने पर कर्मचारियों को सचेत करें नए आईपी पते से आने वाला नेटवर्क स्कैन, या खतरे के निष्कर्षों को रैंक करने के लिए आईपी अंतर्दृष्टि स्कोर को अमेज़ॅन गार्ड ड्यूटी जैसे अन्य स्रोतों के साथ संयोजित करें। यह मॉडल आपके अमेज़ॅन सिक्योरिटी लेक परिनियोजन में कस्टम स्रोतों को जोड़कर कस्टम लॉग स्रोत जैसे एज़्योर फ़्लो लॉग या ऑन-प्रिमाइसेस लॉग शामिल कर सकता है।
इस ब्लॉग पोस्ट श्रृंखला के भाग 2 में, आप सीखेंगे कि इसका उपयोग करके एक विसंगति का पता लगाने वाला मॉडल कैसे बनाया जाए बेतरतीब ढंग से काटा गया जंगल एल्गोरिदम को अतिरिक्त अमेज़ॅन सिक्योरिटी लेक स्रोतों के साथ प्रशिक्षित किया गया है जो नेटवर्क और होस्ट सुरक्षा लॉग डेटा को एकीकृत करता है और एक स्वचालित, व्यापक सुरक्षा निगरानी समाधान के हिस्से के रूप में सुरक्षा विसंगति वर्गीकरण को लागू करता है।
लेखक के बारे में
 जो मोरोट्टी अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक समाधान आर्किटेक्ट है, जो पूरे मिडवेस्ट यूएस में एंटरप्राइज़ ग्राहकों की सहायता करता है। उन्होंने तकनीकी भूमिकाओं की एक विस्तृत श्रृंखला का आयोजन किया है और ग्राहक की कला को संभव दिखाने का आनंद लेते हैं। अपने खाली समय में, वह अपने परिवार के साथ नए स्थानों की खोज करने और अपनी खेल टीम के प्रदर्शन का अधिक विश्लेषण करने के साथ गुणवत्तापूर्ण समय बिताने का आनंद लेते हैं।
जो मोरोट्टी अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक समाधान आर्किटेक्ट है, जो पूरे मिडवेस्ट यूएस में एंटरप्राइज़ ग्राहकों की सहायता करता है। उन्होंने तकनीकी भूमिकाओं की एक विस्तृत श्रृंखला का आयोजन किया है और ग्राहक की कला को संभव दिखाने का आनंद लेते हैं। अपने खाली समय में, वह अपने परिवार के साथ नए स्थानों की खोज करने और अपनी खेल टीम के प्रदर्शन का अधिक विश्लेषण करने के साथ गुणवत्तापूर्ण समय बिताने का आनंद लेते हैं।
 बिश्र तब्बा अमेज़ॅन वेब सर्विसेज में एक समाधान वास्तुकार है। बिश्र ग्राहकों को मशीन लर्निंग, सुरक्षा और अवलोकन संबंधी अनुप्रयोगों में मदद करने में माहिर है। काम के अलावा, उन्हें टेनिस खेलना, खाना बनाना और परिवार के साथ समय बिताना पसंद है।
बिश्र तब्बा अमेज़ॅन वेब सर्विसेज में एक समाधान वास्तुकार है। बिश्र ग्राहकों को मशीन लर्निंग, सुरक्षा और अवलोकन संबंधी अनुप्रयोगों में मदद करने में माहिर है। काम के अलावा, उन्हें टेनिस खेलना, खाना बनाना और परिवार के साथ समय बिताना पसंद है।
 श्रीहर्ष अदारी अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक वरिष्ठ समाधान आर्किटेक्ट हैं, जहां वे ग्राहकों को एडब्ल्यूएस पर अभिनव समाधान विकसित करने के लिए व्यावसायिक परिणामों से पीछे की ओर काम करने में मदद करते हैं। इन वर्षों में, उन्होंने उद्योग वर्टिकल में डेटा प्लेटफॉर्म ट्रांसफॉर्मेशन पर कई ग्राहकों की मदद की है। उनकी विशेषज्ञता के मुख्य क्षेत्र में प्रौद्योगिकी रणनीति, डेटा विश्लेषिकी और डेटा विज्ञान शामिल हैं। अपने खाली समय में, उन्हें टेनिस खेलना, टीवी शो देखना और तबला बजाना पसंद है।
श्रीहर्ष अदारी अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक वरिष्ठ समाधान आर्किटेक्ट हैं, जहां वे ग्राहकों को एडब्ल्यूएस पर अभिनव समाधान विकसित करने के लिए व्यावसायिक परिणामों से पीछे की ओर काम करने में मदद करते हैं। इन वर्षों में, उन्होंने उद्योग वर्टिकल में डेटा प्लेटफॉर्म ट्रांसफॉर्मेशन पर कई ग्राहकों की मदद की है। उनकी विशेषज्ञता के मुख्य क्षेत्र में प्रौद्योगिकी रणनीति, डेटा विश्लेषिकी और डेटा विज्ञान शामिल हैं। अपने खाली समय में, उन्हें टेनिस खेलना, टीवी शो देखना और तबला बजाना पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/identify-cybersecurity-anomalies-in-your-amazon-security-lake-data-using-amazon-sagemaker/

