प्रासंगिक और अर्थ संबंधी खोज के उदय ने ईकॉमर्स और खुदरा व्यवसायों को अपने उपभोक्ताओं के लिए खोज को सरल बना दिया है। जेनरेटिव एआई द्वारा संचालित खोज इंजन और अनुशंसा प्रणालियां प्राकृतिक भाषा के प्रश्नों को समझकर और अधिक सटीक परिणाम देकर उत्पाद खोज अनुभव को तेजी से बेहतर बना सकती हैं। यह समग्र उपयोगकर्ता अनुभव को बढ़ाता है, जिससे ग्राहकों को वही ढूंढने में मदद मिलती है जो वे खोज रहे हैं।
अमेज़न ओपन सर्च सर्विस अब का समर्थन करता है cosine समानता के-एनएन इंडेक्स के लिए मीट्रिक। कोज्या समानता दो सदिशों के बीच कोण के कोसाइन को मापती है, जहां एक छोटा कोज्या कोण सदिशों के बीच उच्च समानता को दर्शाता है। कोसाइन समानता के साथ, आप दो सदिशों के बीच अभिविन्यास को माप सकते हैं, जो इसे कुछ विशिष्ट सिमेंटिक खोज अनुप्रयोगों के लिए एक अच्छा विकल्प बनाता है।
इस पोस्ट में, हम दिखाते हैं कि उत्पाद अनुशंसाओं के लिए एक प्रासंगिक पाठ और छवि खोज इंजन का उपयोग कैसे करें अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल, में उपलब्ध अमेज़ॅन बेडरॉक, साथ में Amazon OpenSearch सर्वर रहित.
एक मल्टीमॉडल एम्बेडिंग मॉडल को पाठ, चित्र और ऑडियो जैसे विभिन्न तौर-तरीकों के संयुक्त प्रतिनिधित्व को सीखने के लिए डिज़ाइन किया गया है। छवियों और उनके संबंधित कैप्शन वाले बड़े पैमाने के डेटासेट पर प्रशिक्षण करके, एक मल्टीमॉडल एम्बेडिंग मॉडल छवियों और टेक्स्ट को एक साझा अव्यक्त स्थान में एम्बेड करना सीखता है। यह संकल्पनात्मक रूप से कैसे काम करता है इसका एक उच्च-स्तरीय अवलोकन निम्नलिखित है:
- अलग एनकोडर - इन मॉडलों में प्रत्येक मोडेलिटी के लिए अलग एनकोडर होते हैं - टेक्स्ट के लिए एक टेक्स्ट एनकोडर (उदाहरण के लिए, BERT या RoBERTa), छवियों के लिए छवि एनकोडर (उदाहरण के लिए, छवियों के लिए CNN), और ऑडियो के लिए ऑडियो एनकोडर (उदाहरण के लिए, Wav2Vec जैसे मॉडल) . प्रत्येक एनकोडर अपने संबंधित तौर-तरीकों की अर्थ संबंधी विशेषताओं को कैप्चर करते हुए एम्बेडिंग उत्पन्न करता है
- तौर-तरीके का संलयन - यूनी-मोडल एनकोडर से एम्बेडिंग को अतिरिक्त तंत्रिका नेटवर्क परतों का उपयोग करके संयोजित किया जाता है। लक्ष्य तौर-तरीकों के बीच अंतःक्रिया और सहसंबंध सीखना है। सामान्य संलयन दृष्टिकोण में संयोजन, तत्व-वार संचालन, पूलिंग और ध्यान तंत्र शामिल हैं।
- साझा प्रतिनिधित्व स्थान - फ़्यूज़न परतें व्यक्तिगत तौर-तरीकों को एक साझा प्रतिनिधित्व स्थान में प्रोजेक्ट करने में मदद करती हैं। मल्टीमॉडल डेटासेट पर प्रशिक्षण द्वारा, मॉडल एक सामान्य एम्बेडिंग स्थान सीखता है जहां प्रत्येक मोडेलिटी से एम्बेडिंग जो समान अंतर्निहित सिमेंटिक सामग्री का प्रतिनिधित्व करती है, एक साथ करीब होती है।
- डाउनस्ट्रीम कार्य - उत्पन्न संयुक्त मल्टीमॉडल एम्बेडिंग का उपयोग मल्टीमॉडल पुनर्प्राप्ति, वर्गीकरण या अनुवाद जैसे विभिन्न डाउनस्ट्रीम कार्यों के लिए किया जा सकता है। मॉडल व्यक्तिगत मोडल एम्बेडिंग की तुलना में इन कार्यों पर प्रदर्शन को बेहतर बनाने के लिए तौर-तरीकों में सहसंबंध का उपयोग करता है। मुख्य लाभ संयुक्त मॉडलिंग के माध्यम से पाठ, छवियों और ऑडियो जैसे तौर-तरीकों के बीच बातचीत और शब्दार्थ को समझने की क्षमता है।
समाधान अवलोकन
समाधान पाठ या छवि प्रश्नों के आधार पर उत्पादों को पुनः प्राप्त करने और अनुशंसा करने के लिए एक बड़े भाषा मॉडल (एलएलएम) संचालित खोज इंजन प्रोटोटाइप के निर्माण के लिए एक कार्यान्वयन प्रदान करता है। हम इसका उपयोग करने के चरणों का विवरण देते हैं अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग छवियों और पाठ को एम्बेडिंग में एन्कोड करने के लिए मॉडल, ओपनसर्च सेवा इंडेक्स में एम्बेडिंग को शामिल करना, और ओपनसर्च सेवा का उपयोग करके इंडेक्स को क्वेरी करना के-निकटतम पड़ोसी (के-एनएन) कार्यक्षमता.
इस समाधान में निम्नलिखित घटक शामिल हैं:
- अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल - यह फाउंडेशन मॉडल (एफएम) इस पोस्ट में प्रयुक्त उत्पाद छवियों की एम्बेडिंग उत्पन्न करता है। अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग के साथ, आप अपनी सामग्री के लिए एम्बेडिंग उत्पन्न कर सकते हैं और उन्हें वेक्टर डेटाबेस में संग्रहीत कर सकते हैं। जब कोई अंतिम उपयोगकर्ता पाठ और छवि के किसी भी संयोजन को खोज क्वेरी के रूप में सबमिट करता है, तो मॉडल खोज क्वेरी के लिए एम्बेडिंग उत्पन्न करता है और अंतिम उपयोगकर्ताओं को प्रासंगिक खोज और अनुशंसा परिणाम प्रदान करने के लिए संग्रहीत एम्बेडिंग से उनका मिलान करता है। आप अपनी अनूठी सामग्री की समझ को बढ़ाने के लिए मॉडल को और अधिक अनुकूलित कर सकते हैं और फ़ाइन-ट्यूनिंग के लिए छवि-पाठ जोड़े का उपयोग करके अधिक सार्थक परिणाम प्रदान कर सकते हैं। डिफ़ॉल्ट रूप से, मॉडल 1,024 आयामों के वैक्टर (एम्बेडिंग) उत्पन्न करता है, और अमेज़ॅन बेडरॉक के माध्यम से एक्सेस किया जाता है। आप गति और प्रदर्शन को अनुकूलित करने के लिए छोटे आयाम भी उत्पन्न कर सकते हैं
- Amazon OpenSearch सर्वर रहित - यह ओपनसर्च सेवा के लिए ऑन-डिमांड सर्वर रहित कॉन्फ़िगरेशन है। हम अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल द्वारा उत्पन्न एम्बेडिंग को संग्रहीत करने के लिए एक वेक्टर डेटाबेस के रूप में अमेज़ॅन ओपनसर्च सर्वरलेस का उपयोग करते हैं। अमेज़ॅन ओपनसर्च सर्वरलेस कलेक्शन में बनाया गया एक इंडेक्स हमारे रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) समाधान के लिए वेक्टर स्टोर के रूप में कार्य करता है।
- अमेज़ॅन सैजमेकर स्टूडियो - यह मशीन लर्निंग (एमएल) के लिए एक एकीकृत विकास वातावरण (आईडीई) है। एमएल व्यवसायी आपके डेटा को तैयार करने से लेकर एमएल मॉडल के निर्माण, प्रशिक्षण और तैनाती तक सभी एमएल विकास चरण निष्पादित कर सकते हैं।
समाधान डिज़ाइन में दो भाग होते हैं: डेटा अनुक्रमण और प्रासंगिक खोज। डेटा अनुक्रमण के दौरान, आप इन छवियों के लिए एम्बेडिंग उत्पन्न करने के लिए उत्पाद छवियों को संसाधित करते हैं और फिर वेक्टर डेटा स्टोर को पॉप्युलेट करते हैं। ये चरण उपयोगकर्ता इंटरैक्शन चरणों से पहले पूरे किए जाते हैं।
प्रासंगिक खोज चरण में, उपयोगकर्ता की एक खोज क्वेरी (पाठ या छवि) को एम्बेडिंग में परिवर्तित किया जाता है और समानता खोज के आधार पर समान उत्पाद छवियों को खोजने के लिए वेक्टर डेटाबेस पर एक समानता खोज चलाई जाती है। फिर आप शीर्ष समान परिणाम प्रदर्शित करते हैं। इस पोस्ट के लिए सभी कोड उपलब्ध हैं गीथहब रेपो.
निम्नलिखित चित्र समाधान वास्तुकला को दर्शाता है।
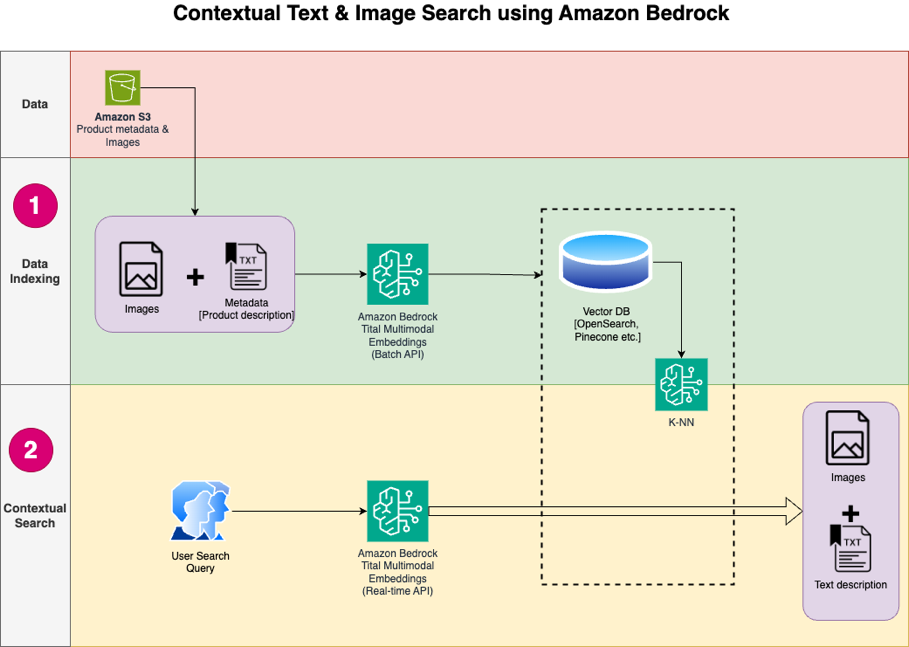
समाधान वर्कफ़्लो चरण निम्नलिखित हैं:
- जनता से उत्पाद विवरण पाठ और चित्र डाउनलोड करें अमेज़न सरल भंडारण सेवा (अमेज़न S3) बाल्टी।
- डेटासेट की समीक्षा करें और तैयार करें।
- अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल (amazon.titan-embed-image-v1) का उपयोग करके उत्पाद छवियों के लिए एम्बेडिंग उत्पन्न करें। यदि आपके पास बड़ी संख्या में चित्र और विवरण हैं, तो आप वैकल्पिक रूप से इसका उपयोग कर सकते हैं अमेज़ॅन बेडरॉक के लिए बैच अनुमान.
- एम्बेडिंग को इसमें स्टोर करें Amazon OpenSearch सर्वर रहित खोज इंजन के रूप में.
- अंत में, उपयोगकर्ता क्वेरी को प्राकृतिक भाषा में प्राप्त करें, इसे अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल का उपयोग करके एम्बेडिंग में परिवर्तित करें, और प्रासंगिक खोज परिणाम प्राप्त करने के लिए के-एनएन खोज करें।
हम समाधान विकसित करने के लिए आईडीई के रूप में सेजमेकर स्टूडियो (आरेख में नहीं दिखाया गया) का उपयोग करते हैं।
इन चरणों पर निम्नलिखित अनुभागों में विस्तार से चर्चा की गई है। हम आउटपुट के स्क्रीनशॉट और विवरण भी शामिल करते हैं।
.. पूर्वापेक्षाएँ
इस पोस्ट में दिए गए समाधान को लागू करने के लिए, आपके पास निम्नलिखित होना चाहिए:
- An AWS खाता और एफएम, अमेज़ॅन बेडरॉक से परिचित होना, अमेज़न SageMaker, और ओपनसर्च सेवा।
- अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल अमेज़ॅन बेडरॉक में सक्षम है। आप पुष्टि कर सकते हैं कि यह सक्षम है मॉडल पहुंच अमेज़ॅन बेडरॉक कंसोल का पृष्ठ। यदि अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग सक्षम है, तो एक्सेस स्थिति इस प्रकार दिखाई देगी प्रवेश करने की अनुमति है, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।

यदि मॉडल उपलब्ध नहीं है, तो चुनकर मॉडल तक पहुंच सक्षम करें मॉडल पहुंच प्रबंधित करें, चयन करना अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग G1, और चुनने मॉडल पहुंच का अनुरोध करें. मॉडल तुरंत उपयोग के लिए सक्षम है.

समाधान स्थापित करें
जब आवश्यक चरण पूरे हो जाएं, तो आप समाधान स्थापित करने के लिए तैयार हैं:
- अपने AWS खाते में, SageMaker कंसोल खोलें और चुनें स्टूडियो नेविगेशन फलक में
- अपना डोमेन और उपयोगकर्ता प्रोफ़ाइल चुनें, फिर चुनें स्टूडियो खोलें.
आपका डोमेन और उपयोगकर्ता प्रोफ़ाइल नाम भिन्न हो सकता है.

- चुनें सिस्टम टर्मिनल के अंतर्गत उपयोगिताएँ और फ़ाइलें.
- क्लोन करने के लिए निम्न कमांड चलाएँ गीथहब रेपो सेजमेकर स्टूडियो उदाहरण के लिए:
- पर नेविगेट करें
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2eफ़ोल्डर. - ओपन
titan_mm_embed_search_blog.ipynbस्मरण पुस्तक।
समाधान चलाएँ
फ़ाइल खोलें titan_mm_embed_search_blog.ipynb और डेटा साइंस पायथन 3 कर्नेल का उपयोग करें। पर रन मेनू, चुनें सभी सेल चलाएं इस नोटबुक में कोड चलाने के लिए.
यह नोटबुक निम्नलिखित चरण निष्पादित करती है:
- इस समाधान के लिए आवश्यक पैकेज और लाइब्रेरी स्थापित करें।
- सार्वजनिक रूप से उपलब्ध लोड करें अमेज़न बर्कले ऑब्जेक्ट डेटासेट और पांडा डेटा फ़्रेम में मेटाडेटा।
डेटासेट बहुभाषी मेटाडेटा और 147,702 अद्वितीय कैटलॉग छवियों के साथ 398,212 उत्पाद लिस्टिंग का एक संग्रह है। इस पोस्ट के लिए, आप केवल यूएस अंग्रेजी में आइटम छवियों और आइटम नामों का उपयोग करें। आप लगभग 1,600 उत्पादों का उपयोग करते हैं।

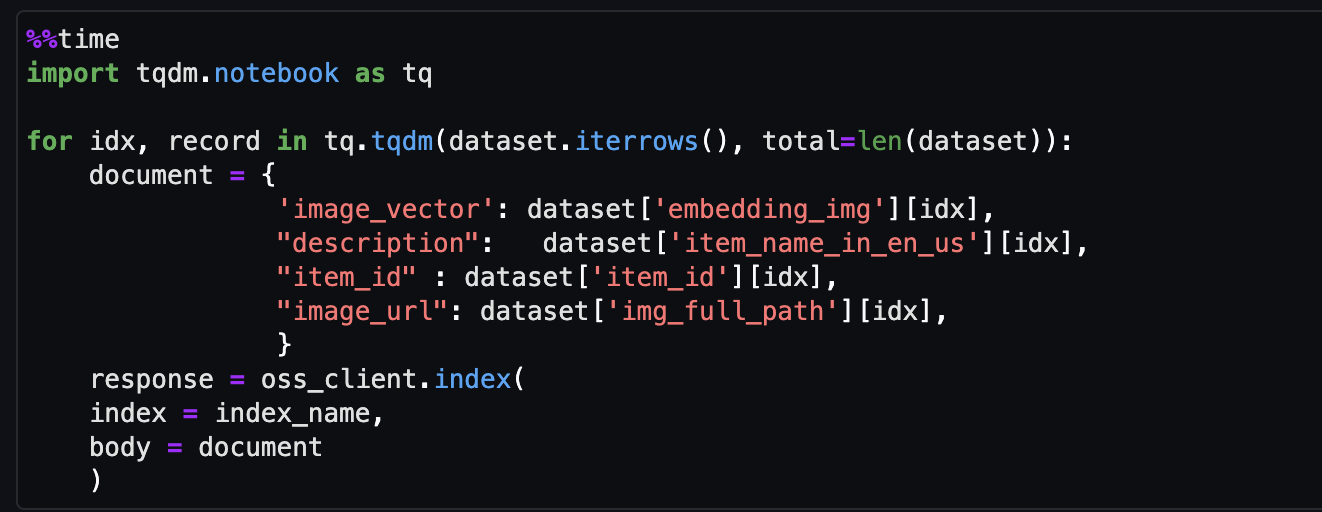
- अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल का उपयोग करके आइटम छवियों के लिए एम्बेडिंग उत्पन्न करें
get_titan_multomodal_embedding()समारोह। अमूर्तता के लिए, हमने इस नोटबुक में उपयोग किए गए सभी महत्वपूर्ण कार्यों को परिभाषित किया हैutils.pyफ़ाइल.

इसके बाद, आप एक Amazon OpenSearch सर्वर रहित वेक्टर स्टोर (संग्रह और अनुक्रमणिका) बनाएं और सेट करें।
- नया वेक्टर खोज संग्रह और इंडेक्स बनाने से पहले, आपको पहले तीन संबद्ध ओपनसर्च सेवा नीतियां बनानी होंगी: एन्क्रिप्शन सुरक्षा नीति, नेटवर्क सुरक्षा नीति और डेटा एक्सेस नीति।

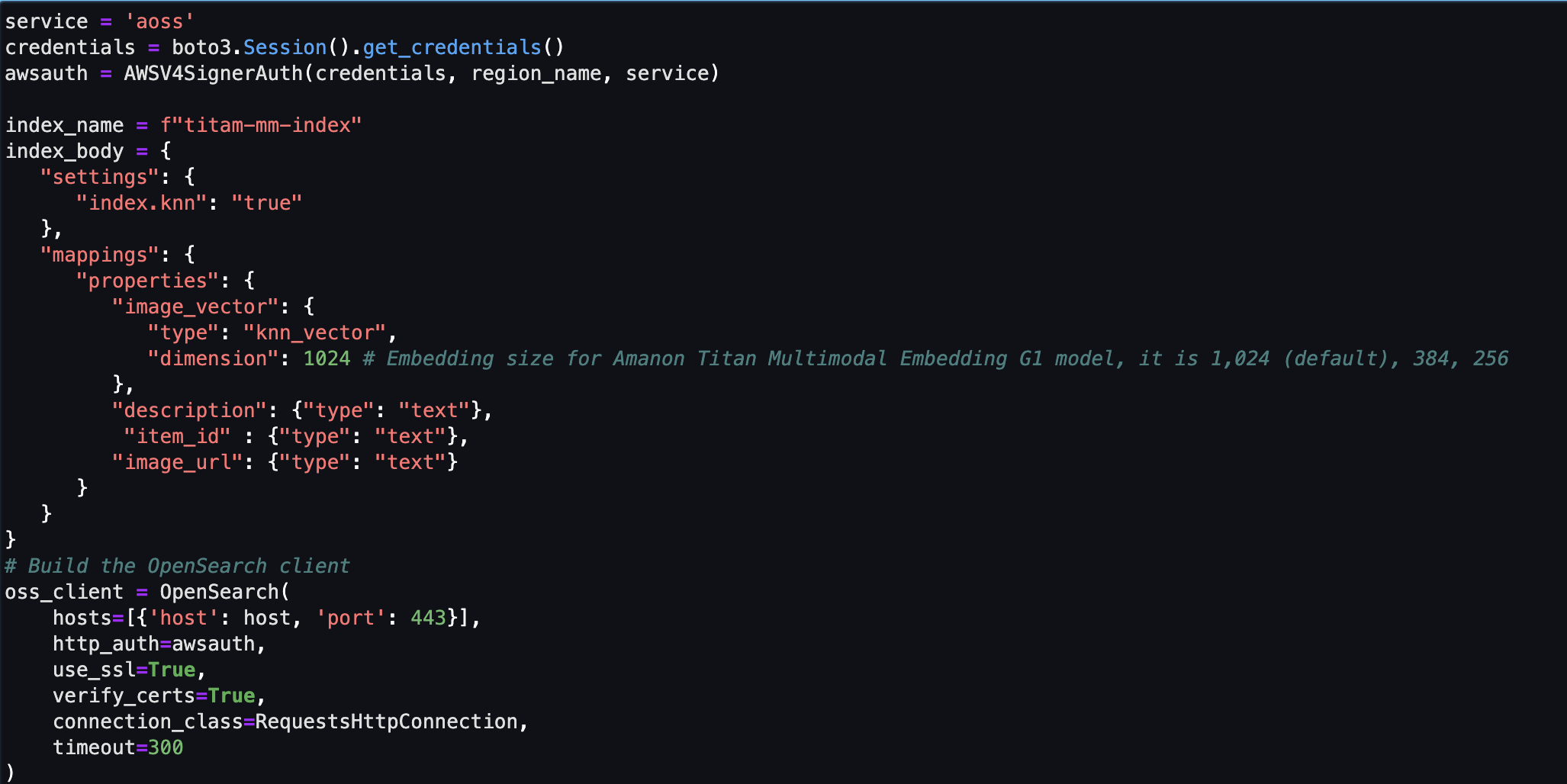
- अंत में, छवि को वेक्टर इंडेक्स में एम्बेड करें।
अब आप वास्तविक समय में मल्टीमॉडल खोज कर सकते हैं।
एक प्रासंगिक खोज चलाएँ
इस अनुभाग में, हम पाठ या छवि क्वेरी के आधार पर प्रासंगिक खोज के परिणाम दिखाते हैं।
सबसे पहले, आइए टेक्स्ट इनपुट के आधार पर एक छवि खोज करें। निम्नलिखित उदाहरण में, हम टेक्स्ट इनपुट "ड्रिंकवेयर ग्लास" का उपयोग करते हैं और समान आइटम खोजने के लिए इसे खोज इंजन पर भेजते हैं।
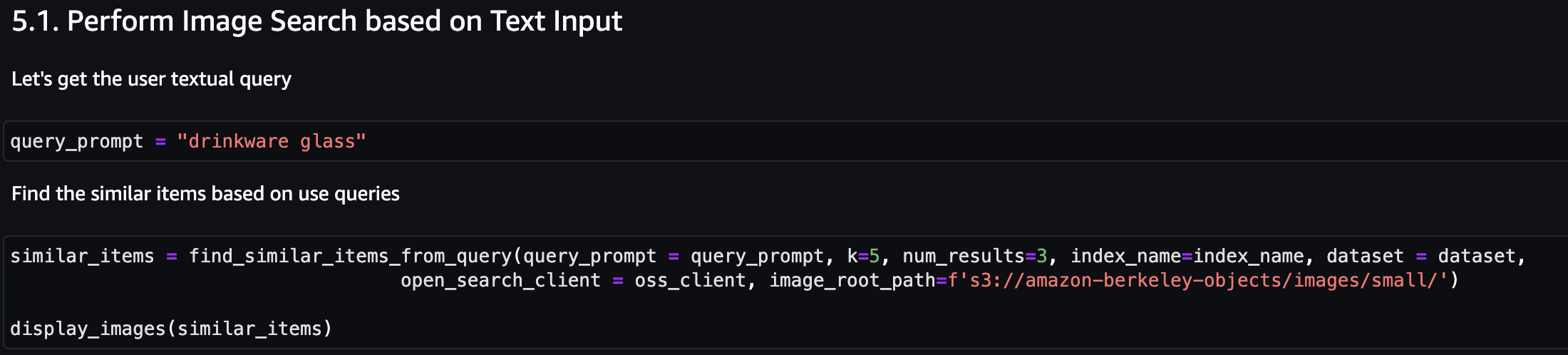
निम्न स्क्रीनशॉट परिणाम दिखाता है।

आइए अब एक साधारण छवि के आधार पर परिणामों को देखें। इनपुट छवि वेक्टर एम्बेडिंग में परिवर्तित हो जाती है और, समानता खोज के आधार पर, मॉडल परिणाम लौटाता है।
आप किसी भी छवि का उपयोग कर सकते हैं, लेकिन निम्नलिखित उदाहरण के लिए, हम आइटम आईडी के आधार पर डेटासेट से एक यादृच्छिक छवि का उपयोग करते हैं (उदाहरण के लिए, item_id = "B07JCDQWM6"), और फिर समान आइटम खोजने के लिए इस छवि को खोज इंजन पर भेजें।

निम्न स्क्रीनशॉट परिणाम दिखाता है।

क्लीन अप
भविष्य में शुल्क लगने से बचने के लिए, इस समाधान में उपयोग किए गए संसाधनों को हटा दें। आप नोटबुक का क्लीनअप अनुभाग चलाकर ऐसा कर सकते हैं।

निष्कर्ष
इस पोस्ट ने शक्तिशाली प्रासंगिक खोज अनुप्रयोगों के निर्माण के लिए अमेज़ॅन बेडरॉक में अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल का उपयोग करने का एक पूर्वाभ्यास प्रस्तुत किया। विशेष रूप से, हमने उत्पाद सूची खोज एप्लिकेशन का एक उदाहरण प्रदर्शित किया। हमने देखा कि कैसे एम्बेडिंग मॉडल छवियों और पाठ्य डेटा से जानकारी की कुशल और सटीक खोज को सक्षम बनाता है, जिससे प्रासंगिक वस्तुओं की खोज करते समय उपयोगकर्ता के अनुभव में वृद्धि होती है।
अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग आपको अंतिम-उपयोगकर्ताओं के लिए अधिक सटीक और प्रासंगिक रूप से प्रासंगिक मल्टीमॉडल खोज, अनुशंसा और वैयक्तिकरण अनुभव प्रदान करने में मदद करती है। उदाहरण के लिए, करोड़ों छवियों वाली एक स्टॉक फ़ोटोग्राफ़ी कंपनी अपनी खोज कार्यक्षमता को सशक्त बनाने के लिए मॉडल का उपयोग कर सकती है, ताकि उपयोगकर्ता किसी वाक्यांश, छवि या छवि और पाठ के संयोजन का उपयोग करके छवियों को खोज सकें।
अमेज़ॅन बेडरॉक में अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल अब यूएस ईस्ट (एन वर्जीनिया) और यूएस वेस्ट (ओरेगन) एडब्ल्यूएस क्षेत्रों में उपलब्ध है। अधिक जानने के लिए, देखें अमेज़ॅन टाइटन इमेज जेनरेटर, मल्टीमॉडल एंबेडिंग और टेक्स्ट मॉडल अब अमेज़ॅन बेडरॉक में उपलब्ध हैं, अमेज़ॅन टाइटन उत्पाद पृष्ठ, और अमेज़न बेडरॉक यूजर गाइड. अमेज़ॅन बेडरॉक में अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग के साथ शुरुआत करने के लिए, यहां जाएं अमेज़ॅन बेडरॉक कंसोल.
अमेज़ॅन टाइटन मल्टीमॉडल एंबेडिंग मॉडल के साथ निर्माण शुरू करें अमेज़ॅन बेडरॉक आज।
लेखक के बारे में
 संदीप सिंह ने गु अमेज़ॅन वेब सर्विसेज में एक वरिष्ठ जेनेरेटिव एआई डेटा वैज्ञानिक हैं, जो व्यवसायों को जेनेरेटिव एआई के साथ नवाचार करने में मदद करते हैं। वह जेनरेटिव एआई, आर्टिफिशियल इंटेलिजेंस, मशीन लर्निंग और सिस्टम डिजाइन में माहिर हैं। उन्हें विभिन्न उद्योगों के लिए जटिल व्यावसायिक समस्याओं को हल करने, दक्षता और स्केलेबिलिटी को अनुकूलित करने के लिए अत्याधुनिक एआई/एमएल-संचालित समाधान विकसित करने का शौक है।
संदीप सिंह ने गु अमेज़ॅन वेब सर्विसेज में एक वरिष्ठ जेनेरेटिव एआई डेटा वैज्ञानिक हैं, जो व्यवसायों को जेनेरेटिव एआई के साथ नवाचार करने में मदद करते हैं। वह जेनरेटिव एआई, आर्टिफिशियल इंटेलिजेंस, मशीन लर्निंग और सिस्टम डिजाइन में माहिर हैं। उन्हें विभिन्न उद्योगों के लिए जटिल व्यावसायिक समस्याओं को हल करने, दक्षता और स्केलेबिलिटी को अनुकूलित करने के लिए अत्याधुनिक एआई/एमएल-संचालित समाधान विकसित करने का शौक है।
 मणि खानूजा एक टेक लीड - जेनेरेटिव एआई स्पेशलिस्ट, एडब्ल्यूएस पर एप्लाइड मशीन लर्निंग एंड हाई परफॉर्मेंस कंप्यूटिंग पुस्तक की लेखिका और मैन्युफैक्चरिंग एजुकेशन फाउंडेशन बोर्ड में महिलाओं के लिए निदेशक मंडल की सदस्य हैं। वह कंप्यूटर विज़न, प्राकृतिक भाषा प्रसंस्करण और जेनरेटिव एआई जैसे विभिन्न डोमेन में मशीन लर्निंग प्रोजेक्ट्स का नेतृत्व करती हैं। वह आंतरिक और बाहरी सम्मेलनों जैसे एडब्ल्यूएस री:इन्वेंट, वीमेन इन मैन्युफैक्चरिंग वेस्ट, यूट्यूब वेबिनार और जीएचसी 23 में बोलती हैं। अपने खाली समय में, वह समुद्र तट के किनारे लंबी सैर करना पसंद करती हैं।
मणि खानूजा एक टेक लीड - जेनेरेटिव एआई स्पेशलिस्ट, एडब्ल्यूएस पर एप्लाइड मशीन लर्निंग एंड हाई परफॉर्मेंस कंप्यूटिंग पुस्तक की लेखिका और मैन्युफैक्चरिंग एजुकेशन फाउंडेशन बोर्ड में महिलाओं के लिए निदेशक मंडल की सदस्य हैं। वह कंप्यूटर विज़न, प्राकृतिक भाषा प्रसंस्करण और जेनरेटिव एआई जैसे विभिन्न डोमेन में मशीन लर्निंग प्रोजेक्ट्स का नेतृत्व करती हैं। वह आंतरिक और बाहरी सम्मेलनों जैसे एडब्ल्यूएस री:इन्वेंट, वीमेन इन मैन्युफैक्चरिंग वेस्ट, यूट्यूब वेबिनार और जीएचसी 23 में बोलती हैं। अपने खाली समय में, वह समुद्र तट के किनारे लंबी सैर करना पसंद करती हैं।
 रूपिंदर ग्रेवाल AWS के साथ एक वरिष्ठ AI/ML विशेषज्ञ समाधान वास्तुकार हैं। वह वर्तमान में अमेज़ॅन सेजमेकर पर मॉडल और एमएलओपीएस की सेवा पर ध्यान केंद्रित करते हैं। इस भूमिका से पहले, उन्होंने मशीन लर्निंग इंजीनियर के रूप में मॉडल निर्माण और होस्टिंग का काम किया। काम के अलावा, उन्हें टेनिस खेलना और पहाड़ी रास्तों पर बाइक चलाना पसंद है।
रूपिंदर ग्रेवाल AWS के साथ एक वरिष्ठ AI/ML विशेषज्ञ समाधान वास्तुकार हैं। वह वर्तमान में अमेज़ॅन सेजमेकर पर मॉडल और एमएलओपीएस की सेवा पर ध्यान केंद्रित करते हैं। इस भूमिका से पहले, उन्होंने मशीन लर्निंग इंजीनियर के रूप में मॉडल निर्माण और होस्टिंग का काम किया। काम के अलावा, उन्हें टेनिस खेलना और पहाड़ी रास्तों पर बाइक चलाना पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

