तार्किक और विश्लेषणात्मक प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कार्यों को हल करने में जनरेटिव भाषा मॉडल उल्लेखनीय रूप से कुशल साबित हुए हैं। इसके अलावा, का उपयोग शीघ्र इंजीनियरिंग अपने प्रदर्शन को उल्लेखनीय रूप से बढ़ा सकते हैं। उदाहरण के लिए, विचार की शृंखला (सीओटी) जटिल बहु-चरणीय समस्याओं के लिए मॉडल की क्षमता में सुधार करने के लिए जाना जाता है। तर्क-वितर्क से जुड़े कार्यों में सटीकता को अतिरिक्त रूप से बढ़ावा देने के लिए, a आत्म स्थिरता प्रोत्साहन दृष्टिकोण का सुझाव दिया गया है, जो भाषा निर्माण के दौरान लालची को स्टोकेस्टिक डिकोडिंग से बदल देता है।
अमेज़ॅन बेडरॉक एक पूरी तरह से प्रबंधित सेवा है जो एकल एपीआई के माध्यम से अग्रणी एआई कंपनियों और अमेज़ॅन से उच्च प्रदर्शन वाले फाउंडेशन मॉडल का विकल्प प्रदान करती है, साथ ही निर्माण क्षमताओं का एक व्यापक सेट भी प्रदान करती है। जनरेटिव ए.आई. सुरक्षा, गोपनीयता और जिम्मेदार AI वाले एप्लिकेशन। साथ बैच निष्कर्ष एपीआई, आप बैचों में फाउंडेशन मॉडल के साथ अनुमान चलाने और अधिक कुशलता से प्रतिक्रिया प्राप्त करने के लिए अमेज़ॅन बेडरॉक का उपयोग कर सकते हैं। यह पोस्ट दिखाती है कि अंकगणित और बहुविकल्पीय तर्क कार्यों पर मॉडल प्रदर्शन को बढ़ाने के लिए अमेज़ॅन बेडरॉक पर बैच अनुमान के माध्यम से स्व-स्थिरता संकेत कैसे लागू किया जाए।
समाधान का अवलोकन
भाषा मॉडल की स्व-संगति प्रेरणा कई प्रतिक्रियाओं की पीढ़ी पर निर्भर करती है जिन्हें अंतिम उत्तर में एकत्रित किया जाता है। सीओटी जैसे एकल-पीढ़ी के दृष्टिकोण के विपरीत, स्व-स्थिरता नमूना-और-सीमांत प्रक्रिया मॉडल पूर्णता की एक श्रृंखला बनाती है जो अधिक सुसंगत समाधान की ओर ले जाती है। किसी दिए गए संकेत के लिए अलग-अलग प्रतिक्रियाओं का सृजन लालची, डिकोडिंग रणनीति के बजाय स्टोकेस्टिक के उपयोग के कारण संभव है।
निम्नलिखित आंकड़े से पता चलता है कि आत्म-स्थिरता लालची सीओटी से किस प्रकार भिन्न है क्योंकि यह तर्क पथों का एक विविध सेट उत्पन्न करता है और उन्हें अंतिम उत्तर देने के लिए एकत्रित करता है।

पाठ निर्माण के लिए डिकोडिंग रणनीतियाँ
डिकोडर-केवल भाषा मॉडल द्वारा उत्पन्न पाठ शब्द दर शब्द प्रकट होता है, जिसके बाद के टोकन की भविष्यवाणी पिछले संदर्भ के आधार पर की जाती है। किसी दिए गए संकेत के लिए, मॉडल एक संभाव्यता वितरण की गणना करता है जो अनुक्रम में प्रत्येक टोकन के अगले दिखाई देने की संभावना को दर्शाता है। डिकोडिंग में इन संभाव्यता वितरणों को वास्तविक पाठ में अनुवाद करना शामिल है। पाठ निर्माण की मध्यस्थता एक सेट द्वारा की जाती है अनुमान पैरामीटर जो अक्सर डिकोडिंग विधि के हाइपरपैरामीटर होते हैं। एक उदाहरण है तापमान, जो अगले टोकन की संभाव्यता वितरण को नियंत्रित करता है और मॉडल के आउटपुट की यादृच्छिकता को प्रभावित करता है।
लालची डिकोडिंग एक नियतात्मक डिकोडिंग रणनीति है जो प्रत्येक चरण में उच्चतम संभावना वाले टोकन का चयन करती है। हालांकि सीधा और कुशल, दृष्टिकोण दोहराव वाले पैटर्न में गिरने का जोखिम रखता है, क्योंकि यह व्यापक संभावना स्थान की उपेक्षा करता है। अनुमान के समय तापमान पैरामीटर को 0 पर सेट करना अनिवार्य रूप से लालची डिकोडिंग को लागू करने के बराबर है।
सैम्पलिंग अनुमानित संभाव्यता वितरण के आधार पर प्रत्येक बाद के टोकन को यादृच्छिक रूप से चुनकर डिकोडिंग प्रक्रिया में स्टोचैस्टिसिटी का परिचय देता है। इस यादृच्छिकता के परिणामस्वरूप अधिक आउटपुट परिवर्तनशीलता होती है। स्टोकेस्टिक डिकोडिंग संभावित आउटपुट की विविधता को पकड़ने में अधिक कुशल साबित होती है और अक्सर अधिक कल्पनाशील प्रतिक्रियाएं उत्पन्न करती है। उच्च तापमान मान अधिक उतार-चढ़ाव लाते हैं और मॉडल की प्रतिक्रिया की रचनात्मकता को बढ़ाते हैं।
संकेत देने वाली तकनीकें: सीओटी और आत्म-स्थिरता
त्वरित इंजीनियरिंग के माध्यम से भाषा मॉडल की तर्क क्षमता को बढ़ाया जा सकता है। विशेष रूप से, सीओटी को दिखाया गया है तर्क प्राप्त करें जटिल एनएलपी कार्यों में। लागू करने का एक तरीका ए शून्य-गोली सीओटी "कदम दर कदम सोचने" के निर्देश के साथ त्वरित वृद्धि के माध्यम से है। दूसरा मॉडल को मध्यवर्ती तर्क चरणों के उदाहरणों के सामने उजागर करना है कुछ-शॉट संकेत पहनावा। दोनों परिदृश्य आम तौर पर लालची डिकोडिंग का उपयोग करते हैं। अंकगणित, सामान्य ज्ञान और प्रतीकात्मक तर्क कार्यों पर सरल निर्देश संकेत की तुलना में सीओटी महत्वपूर्ण प्रदर्शन लाभ की ओर ले जाता है।
आत्म-स्थिरता को प्रेरित करना इस धारणा पर आधारित है कि तर्क प्रक्रिया में विविधता लाने से मॉडलों को सही उत्तर पर पहुंचने में मदद मिल सकती है। इस लक्ष्य को तीन चरणों में प्राप्त करने के लिए तकनीक स्टोकेस्टिक डिकोडिंग का उपयोग करती है:
- तर्क प्राप्त करने के लिए सीओटी उदाहरणों के साथ भाषा मॉडल को प्रेरित करें।
- तर्क पथों का एक विविध सेट उत्पन्न करने के लिए लालची डिकोडिंग को एक नमूना रणनीति के साथ बदलें।
- प्रतिक्रिया सेट में सबसे सुसंगत उत्तर खोजने के लिए परिणामों को एकत्रित करें।
लोकप्रिय अंकगणित और सामान्य ज्ञान तर्क बेंचमार्क पर सीओटी प्रॉम्प्टिंग को बेहतर प्रदर्शन करने के लिए आत्म-स्थिरता दिखाई गई है। दृष्टिकोण की एक सीमा इसकी बड़ी कम्प्यूटेशनल लागत है।
यह पोस्ट दिखाती है कि कैसे स्व-स्थिरता संकेत दो एनएलपी तर्क कार्यों पर जेनरेटिव भाषा मॉडल के प्रदर्शन को बढ़ाता है: अंकगणितीय समस्या-समाधान और बहु-विकल्प डोमेन-विशिष्ट प्रश्न उत्तर। हम अमेज़ॅन बेडरॉक पर बैच अनुमान का उपयोग करके दृष्टिकोण प्रदर्शित करते हैं:
- हम ज्यूपिटरलैब में अमेज़ॅन बेडरॉक पायथन एसडीके तक पहुंचते हैं अमेज़न SageMaker नोटबुक उदाहरण।
- अंकगणितीय तर्क के लिए, हम संकेत देते हैं सुसंगत आदेश ग्रेड स्कूल गणित समस्याओं के GSM8K डेटासेट पर।
- बहुविकल्पीय तर्क के लिए, हम संकेत देते हैं AI21 लैब्स जुरासिक-2 मिड AWS सर्टिफाइड सॉल्यूशंस आर्किटेक्ट - एसोसिएट परीक्षा से प्रश्नों के एक छोटे नमूने पर।
.. पूर्वापेक्षाएँ
यह पूर्वाभ्यास निम्नलिखित पूर्वावश्यकताएँ मानता है:

इस पोस्ट में दिखाए गए कोड को चलाने की अनुमानित लागत $100 है, यह मानते हुए कि आप तापमान-आधारित नमूने के लिए एक मान का उपयोग करके 30 तर्क पथों के साथ एक बार स्व-स्थिरता संकेत चलाते हैं।
अंकगणितीय तर्क क्षमताओं की जांच के लिए डेटासेट
GSM8K उच्च भाषाई विविधता की विशेषता वाले मानव-इकट्ठे ग्रेड स्कूल गणित समस्याओं का एक डेटासेट है। प्रत्येक समस्या को हल करने के लिए 2-8 कदम उठाने पड़ते हैं और बुनियादी अंकगणितीय परिचालनों के साथ प्रारंभिक गणनाओं के अनुक्रम को निष्पादित करने की आवश्यकता होती है। इस डेटा का उपयोग आमतौर पर जेनरेटिव भाषा मॉडल की बहु-चरणीय अंकगणितीय तर्क क्षमताओं को बेंचमार्क करने के लिए किया जाता है। GSM8K ट्रेन सेट इसमें 7,473 रिकॉर्ड शामिल हैं। निम्नलिखित एक उदाहरण है:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
अमेज़ॅन बेडरॉक के साथ बैच अनुमान चलाने के लिए सेट अप करें
बैच अनुमान आपको अमेज़ॅन बेडरॉक पर अतुल्यकालिक रूप से एकाधिक अनुमान कॉल चलाने और बड़े डेटासेट पर मॉडल अनुमान के प्रदर्शन में सुधार करने की अनुमति देता है। यह सेवा इस लेखन के समय पूर्वावलोकन में है और केवल एपीआई के माध्यम से उपलब्ध है। को देखें बैच अनुमान चलाएँ कस्टम एसडीके के माध्यम से बैच अनुमान एपीआई तक पहुंचने के लिए।
डाउनलोड करने और अनज़िप करने के बाद पायथन एसडीके सेजमेकर नोटबुक इंस्टेंस में, आप ज्यूपिटर नोटबुक सेल में निम्नलिखित कोड चलाकर इसे इंस्टॉल कर सकते हैं:
इनपुट डेटा को Amazon S3 पर फ़ॉर्मेट करें और अपलोड करें
बैच अनुमान के लिए इनपुट डेटा को JSONL प्रारूप में तैयार करने की आवश्यकता है recordId और modelInput चांबियाँ। उत्तरार्द्ध को अमेज़ॅन बेडरॉक पर लागू किए जाने वाले मॉडल के बॉडी फ़ील्ड से मेल खाना चाहिए। विशेष रूप से, कुछ कोहेयर कमांड के लिए समर्थित अनुमान पैरामीटर रहे temperature यादृच्छिकता के लिए, max_tokens आउटपुट लंबाई के लिए, और num_generations एकाधिक प्रतिक्रियाएँ उत्पन्न करने के लिए, जिनमें से सभी को एक साथ पारित किया जाता है prompt as modelInput:
देख नींव मॉडल के लिए अनुमान पैरामीटर अन्य मॉडल प्रदाताओं सहित अधिक जानकारी के लिए।
अंकगणितीय तर्क पर हमारे प्रयोग कोहेयर कमांड को अनुकूलित या फाइन-ट्यूनिंग किए बिना कुछ-शॉट सेटिंग में किए जाते हैं। हम विचार श्रृंखला से आठ कुछ-शॉट उदाहरणों के समान सेट का उपयोग करते हैं (टेबल 20) और आत्म-स्थिरता (टेबल 17) कागजात. GSM8K ट्रेन सेट से प्रत्येक प्रश्न के साथ उदाहरणों को जोड़कर संकेत बनाए जाते हैं।
हम ने ठीक किया max_tokens 512 और num_generations 5 तक, कोहेरे कमांड द्वारा अनुमत अधिकतम। लालची डिकोडिंग के लिए, हम सेट करते हैं temperature 0 तक और आत्म-स्थिरता के लिए, हम तापमान 0.5, 0.7, और 1 पर तीन प्रयोग चलाते हैं। प्रत्येक सेटिंग संबंधित तापमान मूल्यों के अनुसार अलग-अलग इनपुट डेटा उत्पन्न करती है। डेटा को JSONL के रूप में स्वरूपित किया गया है और Amazon S3 में संग्रहीत किया गया है।
अमेज़ॅन बेडरॉक में बैच इंफ़ेक्शन जॉब बनाएं और चलाएं
बैच अनुमान रोजगार सृजन के लिए अमेज़ॅन बेडरॉक क्लाइंट की आवश्यकता होती है। हम S3 इनपुट और आउटपुट पथ निर्दिष्ट करते हैं और प्रत्येक आमंत्रण कार्य को एक अद्वितीय नाम देते हैं:
नौकरियाँ हैं बनाया अमेज़ॅन बेडरॉक एपीआई के पैरामीटर के रूप में आईएएम भूमिका, मॉडल आईडी, नौकरी का नाम और इनपुट/आउटपुट कॉन्फ़िगरेशन पास करके:
लिस्टिंग, निगरानी, तथा रोक बैच अनुमान नौकरियां उनके संबंधित एपीआई कॉल द्वारा समर्थित हैं। सृजन पर, नौकरियाँ सबसे पहले दिखाई देती हैं Submitted, फिर ऐसे InProgress, और अंत में जैसे Stopped, Failedया, Completed.
यदि कार्य सफलतापूर्वक पूर्ण हो जाते हैं, तो उत्पन्न सामग्री को उसके अद्वितीय आउटपुट स्थान का उपयोग करके अमेज़ॅन S3 से पुनर्प्राप्त किया जा सकता है।
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
आत्म-स्थिरता अंकगणितीय कार्यों पर मॉडल सटीकता को बढ़ाती है
GSM8K डेटासेट पर सटीकता के मामले में कोहेयर कमांड की सेल्फ-कंसिस्टेंसी प्रॉम्प्टिंग एक लालची CoT बेसलाइन से बेहतर प्रदर्शन करती है। आत्म-स्थिरता के लिए, हम तीन अलग-अलग तापमानों पर 30 स्वतंत्र तर्क पथों का नमूना लेते हैं topP और topK उनके लिए सेट करें डिफ़ॉल्ट मान. अंतिम समाधान बहुमत मतदान के माध्यम से सबसे सुसंगत घटना को चुनकर एकत्रित किए जाते हैं। बराबरी की स्थिति में, हम बेतरतीब ढंग से बहुमत की प्रतिक्रियाओं में से एक को चुनते हैं। हम 100 से अधिक रनों के औसत से सटीकता और मानक विचलन मानों की गणना करते हैं।
निम्नलिखित आंकड़ा लालची सीओटी (नीला) और 8 (पीला), 0.5 (हरा), और 0.7 (नारंगी) तापमान मूल्यों पर नमूना की संख्या के एक फ़ंक्शन के रूप में लालची सीओटी (नीला) और आत्म-स्थिरता के साथ प्रेरित कोहेयर कमांड से जीएसएम 1.0 के डेटासेट पर सटीकता दिखाता है। तर्क पथ.
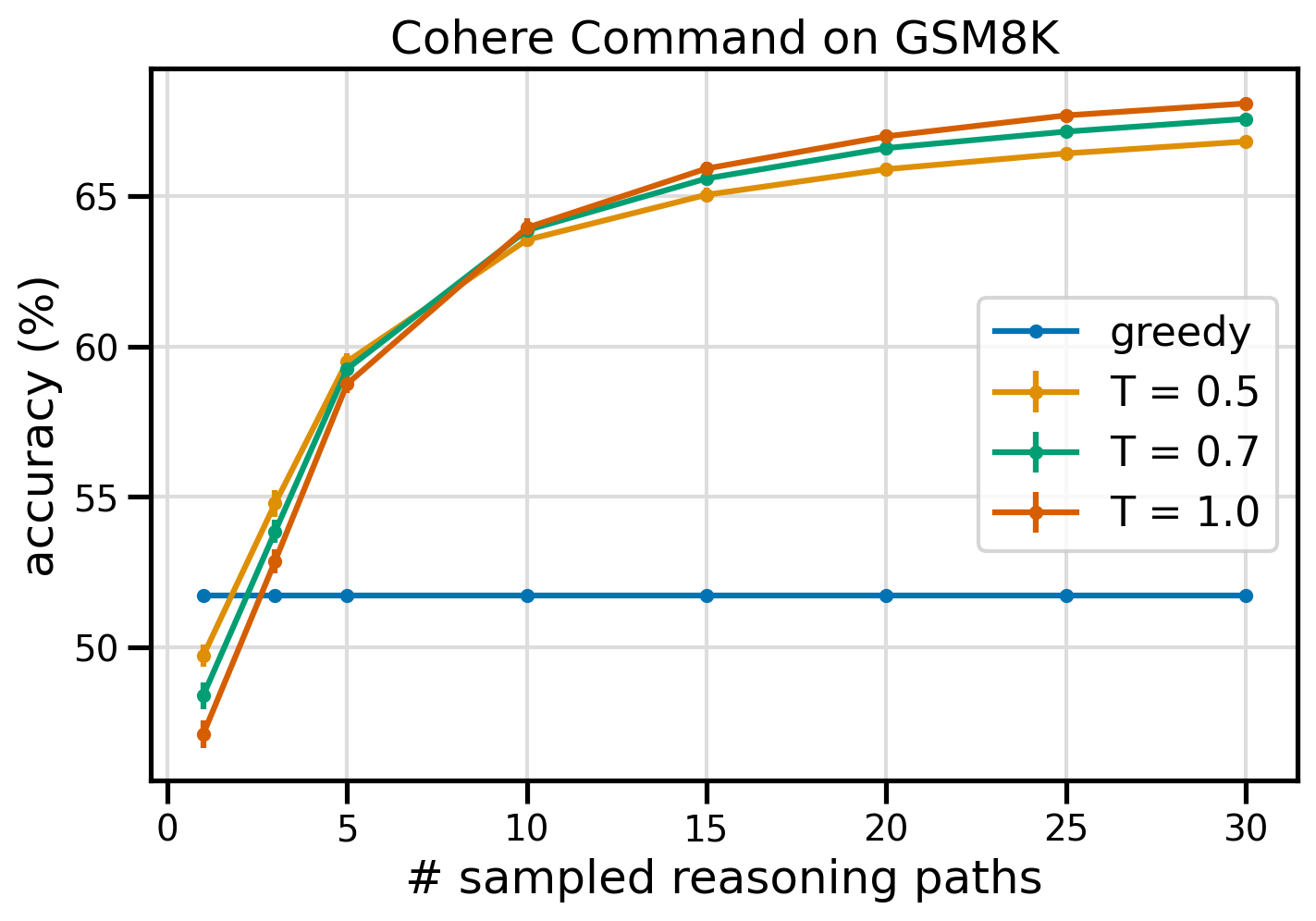
पूर्ववर्ती आंकड़े से पता चलता है कि स्व-स्थिरता लालची सीओटी पर अंकगणितीय सटीकता को बढ़ाती है जब नमूना पथों की संख्या तीन से कम होती है। आगे के तर्क पथों के साथ प्रदर्शन लगातार बढ़ता है, जो विचार पीढ़ी में विविधता लाने के महत्व की पुष्टि करता है। Cohere Command, T=8 पर 51.7 स्व-सुसंगत तर्क पथों के साथ CoT बनाम 68% के साथ पूछे जाने पर GSM30K प्रश्न सेट को 1.0% सटीकता के साथ हल करता है। सभी तीन सर्वेक्षण किए गए तापमान मान समान परिणाम देते हैं, कम नमूना पथों पर कम तापमान तुलनात्मक रूप से अधिक प्रदर्शन करने वाला होता है।
दक्षता और लागत पर व्यावहारिक विचार
स्व-स्थिरता बढ़ी हुई प्रतिक्रिया समय और प्रति संकेत एकाधिक आउटपुट उत्पन्न करते समय होने वाली लागत से सीमित है। एक व्यावहारिक उदाहरण के रूप में, 7,473 GSM8K रिकॉर्ड पर कोहेयर कमांड के साथ लालची पीढ़ी के लिए बैच अनुमान 20 मिनट से भी कम समय में समाप्त हो गया। कार्य ने इनपुट के रूप में 5.5 मिलियन टोकन लिए और 630,000 आउटपुट टोकन उत्पन्न किए। वर्तमान में अमेज़ॅन बेडरॉक अनुमान कीमतें, कुल लागत लगभग $9.50 थी।
कोहेयर कमांड के साथ आत्म-संगति के लिए, हम अनुमान पैरामीटर का उपयोग करते हैं num_generations प्रति संकेत एकाधिक पूर्णताएँ बनाने के लिए। इस लेखन के समय, अमेज़ॅन बेडरॉक अधिकतम पांच पीढ़ियों और तीन समवर्ती की अनुमति देता है Submitted बैच अनुमान नौकरियां। नौकरियाँ आगे बढ़ती हैं InProgress स्थिति क्रमिक रूप से, इसलिए पांच से अधिक पथों का नमूना लेने के लिए एकाधिक आमंत्रण की आवश्यकता होती है।
निम्नलिखित चित्र GSM8K डेटासेट पर कोहेयर कमांड के लिए रनटाइम दिखाता है। कुल रनटाइम x अक्ष पर और रनटाइम प्रति नमूना तर्क पथ पर y अक्ष पर दिखाया गया है। लालची पीढ़ी सबसे कम समय में चलती है लेकिन प्रति नमूना पथ पर अधिक समय लागत लगती है।

लालची पीढ़ी संपूर्ण GSM20K सेट को 8 मिनट से भी कम समय में पूरा करती है और एक अद्वितीय तर्क पथ का नमूना पेश करती है। पाँच नमूनों के साथ स्व-स्थिरता को पूरा करने में लगभग 50% अधिक समय लगता है और इसकी लागत लगभग $14.50 है, लेकिन उस समय में पाँच पथ (500% से अधिक) उत्पन्न होते हैं। प्रत्येक अतिरिक्त पाँच नमूना पथों के साथ कुल रनटाइम और लागत में चरण-वार वृद्धि होती है। लागत-लाभ विश्लेषण से पता चलता है कि 1-2 नमूना पथों के साथ 5-10 बैच अनुमान नौकरियां आत्म-स्थिरता के व्यावहारिक कार्यान्वयन के लिए अनुशंसित सेटिंग हैं। यह लागत और विलंबता को कम रखते हुए उन्नत मॉडल प्रदर्शन प्राप्त करता है।
आत्म-स्थिरता अंकगणितीय तर्क से परे मॉडल के प्रदर्शन को बढ़ाती है
स्व-संगति प्रोत्साहन की उपयुक्तता साबित करने के लिए एक महत्वपूर्ण प्रश्न यह है कि क्या यह विधि आगे के एनएलपी कार्यों और भाषा मॉडल में सफल होती है। अमेज़ॅन से संबंधित उपयोग के मामले के विस्तार के रूप में, हम नमूना प्रश्नों पर एक छोटे आकार का विश्लेषण करते हैं AWS सॉल्यूशंस आर्किटेक्ट एसोसिएट सर्टिफिकेशन. यह AWS तकनीक और सेवाओं पर एक बहुविकल्पीय परीक्षा है जिसके लिए डोमेन ज्ञान और कई विकल्पों के बीच तर्क करने और निर्णय लेने की क्षमता की आवश्यकता होती है।
हम से एक डेटासेट तैयार करते हैं एसएए-C01 और एसएए-C03 नमूना परीक्षा प्रश्न. 20 उपलब्ध प्रश्नों में से, हम पहले 4 को कुछ-शॉट उदाहरणों के रूप में उपयोग करते हैं और मॉडल को शेष 16 का उत्तर देने के लिए प्रेरित करते हैं। इस बार, हम एआई21 लैब्स जुरासिक-2 मिड मॉडल के साथ अनुमान लगाते हैं और अधिकतम 10 तर्क पथ उत्पन्न करते हैं। तापमान 0.7. नतीजे बताते हैं कि आत्म-निरंतरता प्रदर्शन को बढ़ाती है: हालांकि लालची सीओटी 11 सही उत्तर देता है, आत्म-निरंतरता 2 और पर सफल होती है।
निम्न तालिका 5 से अधिक रनों के औसत से 10 और 100 नमूना पथों के लिए सटीकता परिणाम दिखाती है।
| . | लालची डिकोडिंग | टी = 0.7 |
| # नमूना पथ: 5 | 68.6 | 74.1 0.7 ± |
| # नमूना पथ: 10 | 68.6 | 78.9 ± 0.3 |
निम्नलिखित तालिका में, हम दो परीक्षा प्रश्न प्रस्तुत करते हैं जिनका लालची सीओटी द्वारा गलत उत्तर दिया गया है, जबकि आत्म-स्थिरता सफल होती है, प्रत्येक मामले में सही (हरा) या गलत (लाल) तर्क चिह्नों पर प्रकाश डाला गया है जिसने मॉडल को सही या गलत प्रतिक्रिया देने के लिए प्रेरित किया। यद्यपि स्व-संगति द्वारा उत्पन्न प्रत्येक नमूना पथ सही नहीं है, लेकिन नमूना पथों की संख्या बढ़ने पर बहुमत सही उत्तर पर केंद्रित हो जाता है। हम देखते हैं कि 5-10 रास्ते आम तौर पर लालची परिणामों में सुधार करने के लिए पर्याप्त होते हैं, उन मूल्यों के मुकाबले दक्षता के मामले में रिटर्न कम हो जाता है।
| सवाल |
एक वेब एप्लिकेशन ग्राहकों को S3 बकेट में ऑर्डर अपलोड करने की अनुमति देता है। परिणामी अमेज़ॅन S3 ईवेंट एक लैम्ब्डा फ़ंक्शन को ट्रिगर करता है जो एक संदेश को SQS कतार में सम्मिलित करता है। एक एकल EC2 उदाहरण कतार से संदेशों को पढ़ता है, उन्हें संसाधित करता है, और उन्हें अद्वितीय ऑर्डर आईडी द्वारा विभाजित डायनेमोडीबी तालिका में संग्रहीत करता है। अगले महीने ट्रैफ़िक में 10 गुना वृद्धि होने की उम्मीद है और एक समाधान आर्किटेक्ट संभावित स्केलिंग समस्याओं के लिए आर्किटेक्चर की समीक्षा कर रहा है। नए ट्रैफ़िक को समायोजित करने के लिए स्केल करने में सक्षम होने के लिए किस घटक को पुनः आर्किटेक्चर की आवश्यकता होने की सबसे अधिक संभावना है? A. लैम्ब्डा फ़ंक्शन |
AWS पर चलने वाला एक एप्लिकेशन अपने डेटाबेस के लिए Amazon Aurora Multi-AZ DB क्लस्टर परिनियोजन का उपयोग करता है। प्रदर्शन मेट्रिक्स का मूल्यांकन करते समय, एक समाधान आर्किटेक्ट ने पाया कि डेटाबेस रीड उच्च I/O का कारण बन रहा है और डेटाबेस के विरुद्ध लिखने के अनुरोधों में विलंबता जोड़ रहा है। पढ़ने के अनुरोधों को लिखने के अनुरोधों से अलग करने के लिए समाधान वास्तुकार को क्या करना चाहिए? A. ऑरोरा डेटाबेस पर रीड-थ्रू कैशिंग सक्षम करें। |
| सही जवाब | C - एक एकल EC2 उदाहरण स्केल नहीं करेगा और वास्तुकला में विफलता का एक एकल बिंदु है। एक बेहतर समाधान यह होगा कि 2 उपलब्धता क्षेत्रों में ऑटो स्केलिंग समूह में EC2 इंस्टेंसेस कतार से संदेश पढ़ें। अन्य प्रतिक्रियाएँ सभी प्रबंधित सेवाएँ हैं जिन्हें स्केल करने के लिए कॉन्फ़िगर किया जा सकता है या स्वचालित रूप से स्केल किया जाएगा। | C - ऑरोरा रेप्लिकास रीड ट्रैफिक को ऑफलोड करने का एक तरीका प्रदान करता है। ऑरोरा रेप्लिकाज़ मुख्य डेटाबेस के समान अंतर्निहित भंडारण साझा करते हैं, इसलिए अंतराल समय आम तौर पर बहुत कम होता है। ऑरोरा रेप्लिकाज़ के अपने स्वयं के समापन बिंदु हैं, इसलिए रीड ट्रैफ़िक को नए समापन बिंदुओं पर निर्देशित करने के लिए एप्लिकेशन को कॉन्फ़िगर करने की आवश्यकता होगी। |
| लालची डिकोडिंग | EC2 इंस्टेंस को सीधे स्केल करना संभव नहीं हो सकता है, क्योंकि इंस्टेंस का आकार बदलना संभव नहीं हो सकता है। लैम्ब्डा फ़ंक्शन को स्केल करना पर्याप्त नहीं हो सकता है, क्योंकि लैम्ब्डा फ़ंक्शंस में 6 जीबी मेमोरी आवंटन सीमा होती है। SQS कतार को स्केल करना पर्याप्त नहीं हो सकता है, क्योंकि SQS में 10,000 संदेश की सीमा है। अधिक क्षमता इकाइयों का प्रावधान करके DynamoDB तालिकाओं को बढ़ाया जा सकता है। सही उत्तर है डी. | मल्टी-एज़ेड स्टैंडबाय इंस्टेंस से पढ़ने के लिए एप्लिकेशन को संशोधित करना (विकल्प बी) सबसे अच्छा तरीका है. स्टैंडबाय इंस्टेंस को प्राथमिक इंस्टेंस से एसिंक्रोनस रूप से दोहराया जाता है, इसलिए रीड ऑपरेशंस लिखने के ऑपरेशंस में हस्तक्षेप नहीं करेगा। रीड-थ्रू कैशिंग सक्षम करना (विकल्प ए) या ऑरोरा प्रतिकृति (विकल्प सी) बनाने से I/O विवाद समस्या का समाधान नहीं होगा. दूसरा ऑरोरा डेटाबेस बनाने और इसे रीड प्रतिकृति (विकल्प डी) के रूप में जोड़ने से I/O विवाद समस्या का समाधान नहीं होगा। सही जवाब बी है। |
| नमूना पथ #1 | EC2 इंस्टेंस को उसके मौजूदा आकार से 10 गुना तक स्केल करना लागत या प्रदर्शन के नजरिए से संभव नहीं हो सकता है। इसके लिए एक बड़े उदाहरण की आवश्यकता होगी, जो महंगा हो सकता है। लोड को साझा करने के लिए छोटे उदाहरणों (जैसे, ऑटो स्केलिंग ग्रुप) के झुंड का उपयोग करना अधिक लागत प्रभावी तरीका हो सकता है। इस मामले में, EC2 इंस्टेंस को फिर से आर्किटेक्चर करने की आवश्यकता होगी। सही जवाब सी है। | उपयुक्त एंडपॉइंट का उपयोग करने के लिए एप्लिकेशन को संशोधित करना एक व्यावहारिक समाधान नहीं है क्योंकि इसके लिए एप्लिकेशन कोड में बदलाव की आवश्यकता होगी। सही उत्तर C है: एक ऑरोरा प्रतिकृति बनाएं और उचित समापन बिंदुओं का उपयोग करने के लिए एप्लिकेशन को संशोधित करें। |
| नमूना पथ #2 | एकल EC2 उदाहरण को स्केल करना अन्य सेवा घटकों को स्केल करने की तुलना में अधिक कठिन और समस्याग्रस्त है। Amazon SQS, Lambda, और DynamoDB सभी स्वचालित रूप से स्केल कर सकते हैं बढ़े हुए भार से निपटने के लिए. सही जवाब सी है। |
(सी) एक ऑरोरा प्रतिकृति बनाएं और उचित समापन बिंदुओं का उपयोग करने के लिए एप्लिकेशन को संशोधित करें। ऑरोरा रेप्लिका को कॉन्फ़िगर करके, आप पढ़ने वाले ट्रैफ़िक को लिखने वाले ट्रैफ़िक से अलग कर सकते हैं। ऑरोरा रेप्लिकाज़ विभिन्न समापन बिंदु URL का उपयोग करते हैं, जो आपको पढ़ने वाले ट्रैफ़िक को प्राथमिक डेटाबेस के बजाय प्रतिकृति पर निर्देशित करने की अनुमति देता है। प्रतिकृति प्राथमिक डेटाबेस में लिखने के अनुरोधों के समानांतर पढ़ने के अनुरोधों को संसाधित कर सकती है, I/O और विलंबता को कम करना। |
क्लीन अप
अमेज़ॅन बेडरॉक में रनिंग बैच अनुमान अमेज़ॅन बेडरॉक मूल्य निर्धारण के अनुसार शुल्क के अधीन है। जब आप वॉकथ्रू पूरा कर लें, तो अपने सेजमेकर नोटबुक इंस्टेंस को हटा दें और भविष्य के शुल्कों से बचने के लिए अपने S3 बकेट से सभी डेटा हटा दें।
विचार
यद्यपि प्रदर्शित समाधान आत्म-संगति के साथ प्रेरित होने पर भाषा मॉडल के बेहतर प्रदर्शन को दर्शाता है, यह ध्यान रखना महत्वपूर्ण है कि वॉकथ्रू उत्पादन के लिए तैयार नहीं है। उत्पादन में तैनात होने से पहले, आपको निम्नलिखित आवश्यकताओं को ध्यान में रखते हुए, अवधारणा के इस प्रमाण को अपने कार्यान्वयन में अनुकूलित करना चाहिए:
- अनधिकृत उपयोग को रोकने के लिए एपीआई और डेटाबेस तक पहुंच प्रतिबंध।
- IAM भूमिका पहुंच और सुरक्षा समूहों के संबंध में AWS सुरक्षा सर्वोत्तम प्रथाओं का पालन।
- त्वरित इंजेक्शन हमलों को रोकने के लिए उपयोगकर्ता इनपुट का सत्यापन और स्वच्छता।
- परीक्षण और ऑडिटिंग को सक्षम करने के लिए ट्रिगर प्रक्रियाओं की निगरानी और लॉगिंग।
निष्कर्ष
इस पोस्ट से पता चलता है कि स्व-स्थिरता संकेत जटिल एनएलपी कार्यों में जेनरेटिव भाषा मॉडल के प्रदर्शन को बढ़ाता है जिनके लिए अंकगणित और बहुविकल्पीय तार्किक कौशल की आवश्यकता होती है। स्व-स्थिरता विभिन्न तर्क पथ उत्पन्न करने के लिए तापमान-आधारित स्टोकेस्टिक डिकोडिंग का उपयोग करती है। इससे सही उत्तरों पर पहुंचने के लिए विविध और उपयोगी विचार प्राप्त करने की मॉडल की क्षमता बढ़ जाती है।
अमेज़ॅन बेडरॉक बैच अनुमान के साथ, भाषा मॉडल कोहेयर कमांड को अंकगणितीय समस्याओं के एक सेट के लिए आत्मनिर्भर उत्तर उत्पन्न करने के लिए प्रेरित किया जाता है। लालची डिकोडिंग के साथ सटीकता 51.7% से सुधरकर टी=68 पर 30 तर्क पथों के स्व-स्थिरता नमूने के साथ 1.0% हो जाती है। पाँच पथों का नमूना लेने से सटीकता पहले से ही 7.5 प्रतिशत अंक बढ़ जाती है। यह दृष्टिकोण अन्य भाषा मॉडल और तर्क कार्यों के लिए हस्तांतरणीय है, जैसा कि AWS प्रमाणन परीक्षा पर AI21 लैब्स जुरासिक -2 मिड मॉडल के परिणामों से पता चलता है। छोटे आकार के प्रश्न सेट में, पांच नमूना पथों के साथ आत्म-संगति लालची सीओटी की तुलना में सटीकता को 5 प्रतिशत अंक बढ़ा देती है।
हम आपको जेनेरिक भाषा मॉडल के साथ अपने स्वयं के अनुप्रयोगों में बेहतर प्रदर्शन के लिए स्व-स्थिरता संकेत लागू करने के लिए प्रोत्साहित करते हैं। बारे में और सीखो सुसंगत आदेश और AI21 लैब्स जुरासिक मॉडल अमेज़न बेडरॉक पर उपलब्ध हैं। बैच अनुमान के बारे में अधिक जानकारी के लिए देखें बैच अनुमान चलाएँ.
आभार
लेखक सहायक प्रतिक्रिया के लिए तकनीकी समीक्षक अमीन ताजगार्डून और पैट्रिक मैकस्वीनी को धन्यवाद देता है।
लेखक के बारे में

लूसिया संतामारिया अमेज़ॅन के एमएल विश्वविद्यालय में एक वरिष्ठ एप्लाइड वैज्ञानिक हैं, जहां उन्होंने व्यावहारिक शिक्षा के माध्यम से कंपनी में एमएल योग्यता के स्तर को बढ़ाने पर ध्यान केंद्रित किया है। लूसिया के पास खगोल भौतिकी में पीएचडी है और वह तकनीकी ज्ञान और उपकरणों तक पहुंच को लोकतांत्रिक बनाने को लेकर उत्साहित हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

