कई उद्यम अपने ऑन-प्रिमाइसेस डेटा स्टोर को AWS क्लाउड पर स्थानांतरित कर रहे हैं। डेटा माइग्रेशन के दौरान, एक प्रमुख आवश्यकता उन सभी डेटा को मान्य करना है जिन्हें स्रोत से लक्ष्य तक ले जाया गया है। यह डेटा सत्यापन एक महत्वपूर्ण कदम है, और यदि सही ढंग से नहीं किया गया, तो संपूर्ण परियोजना विफल हो सकती है। हालाँकि, स्रोत और लक्ष्य के बीच डेटा की तुलना करके माइग्रेशन सटीकता निर्धारित करने के लिए कस्टम समाधान विकसित करना अक्सर समय लेने वाला हो सकता है।
इस पोस्ट में, हम कॉन्फ़िगरेशन-आधारित टूल का उपयोग करके माइग्रेशन के बाद बड़े डेटासेट को मान्य करने के लिए चरण-दर-चरण प्रक्रिया से गुजरते हैं अमेज़ॅन ईएमआर और अपाचे ग्रिफिन ओपन सोर्स लाइब्रेरी। ग्रिफ़िन बड़े डेटा के लिए एक खुला स्रोत डेटा गुणवत्ता समाधान है, जो बैच और स्ट्रीमिंग मोड दोनों का समर्थन करता है।
आज के डेटा-संचालित परिदृश्य में, जहां संगठन पेटाबाइट डेटा से निपटते हैं, स्वचालित डेटा सत्यापन ढांचे की आवश्यकता तेजी से महत्वपूर्ण हो गई है। मैन्युअल सत्यापन प्रक्रियाएं न केवल समय लेने वाली होती हैं, बल्कि त्रुटियों की भी संभावना होती हैं, खासकर जब बड़ी मात्रा में डेटा से निपटते हैं। स्वचालित डेटा सत्यापन ढाँचे बड़े डेटासेट की कुशलतापूर्वक तुलना करके, विसंगतियों की पहचान करके और बड़े पैमाने पर डेटा सटीकता सुनिश्चित करके एक सुव्यवस्थित समाधान प्रदान करते हैं। ऐसे ढांचे के साथ, संगठन अपने डेटा की अखंडता में विश्वास बनाए रखते हुए मूल्यवान समय और संसाधनों को बचा सकते हैं, जिससे सूचित निर्णय लेने में सक्षम बनाया जा सकता है और समग्र परिचालन दक्षता में वृद्धि हो सकती है।
इस ढांचे के लिए निम्नलिखित असाधारण विशेषताएं हैं:
- कॉन्फ़िगरेशन-संचालित ढांचे का उपयोग करता है
- निर्बाध एकीकरण के लिए प्लग-एंड-प्ले कार्यक्षमता प्रदान करता है
- किसी भी असमानता की पहचान करने के लिए गणना तुलना आयोजित करता है
- मजबूत डेटा सत्यापन प्रक्रियाओं को लागू करता है
- व्यवस्थित जांच के माध्यम से डेटा गुणवत्ता सुनिश्चित करता है
- गहन विश्लेषण के लिए बेमेल रिकॉर्ड वाली फ़ाइल तक पहुंच प्रदान करता है
- अंतर्दृष्टि और ट्रैकिंग उद्देश्यों के लिए व्यापक रिपोर्ट तैयार करता है
समाधान अवलोकन
यह समाधान निम्नलिखित सेवाओं का उपयोग करता है:
- अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) या Hadoop डिस्ट्रिब्यूटेड फ़ाइल सिस्टम (HDFS) स्रोत और लक्ष्य के रूप में।
- अमेज़ॅन ईएमआर PySpark स्क्रिप्ट चलाने के लिए। हम HDFS या Amazon S3 पर बनाई गई Hadoop तालिकाओं के बीच डेटा को सत्यापित करने के लिए ग्रिफिन के शीर्ष पर एक पायथन रैपर का उपयोग करते हैं।
- एडब्ल्यूएस गोंद तकनीकी तालिका को सूचीबद्ध करने के लिए, जो ग्रिफिन कार्य के परिणामों को संग्रहीत करती है।
- अमेज़न एथेना परिणामों को सत्यापित करने के लिए आउटपुट तालिका को क्वेरी करना।
हम उन तालिकाओं का उपयोग करते हैं जो प्रत्येक स्रोत और लक्ष्य तालिका के लिए गिनती संग्रहीत करती हैं और ऐसी फ़ाइलें भी बनाती हैं जो स्रोत और लक्ष्य के बीच रिकॉर्ड का अंतर दिखाती हैं।
निम्नलिखित चित्र समाधान वास्तुकला को दर्शाता है।
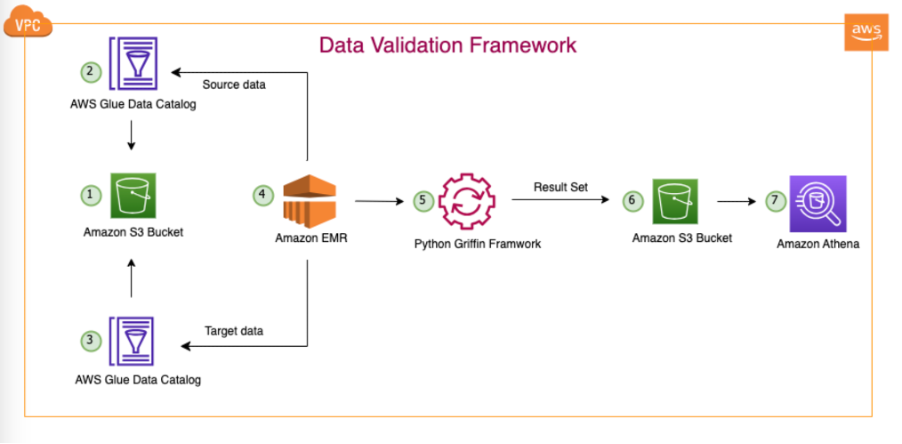
चित्रित वास्तुकला और हमारे विशिष्ट डेटा लेक उपयोग के मामले में, हमारा डेटा या तो अमेज़ॅन एस3 में रहता है या प्रतिकृति टूल का उपयोग करके परिसर से अमेज़ॅन एस3 में स्थानांतरित किया जाता है। एडब्ल्यूएस डेटासिंक or एडब्ल्यूएस डेटाबेस प्रवासन सेवा (एडब्ल्यूएस डीएमएस)। हालाँकि यह समाधान हाइव मेटास्टोर और एडब्ल्यूएस ग्लू डेटा कैटलॉग दोनों के साथ सहजता से इंटरैक्ट करने के लिए डिज़ाइन किया गया है, हम इस पोस्ट में अपने उदाहरण के रूप में डेटा कैटलॉग का उपयोग करते हैं।
यह ढांचा अमेज़ॅन ईएमआर के भीतर संचालित होता है, जो निर्धारित आवृत्ति के अनुसार स्वचालित रूप से दैनिक आधार पर निर्धारित कार्यों को चलाता है। यह अमेज़ॅन एस3 में रिपोर्ट तैयार और प्रकाशित करता है, जिसे एथेना के माध्यम से एक्सेस किया जा सकता है। इस ढांचे की एक उल्लेखनीय विशेषता गिनती बेमेल और डेटा विसंगतियों का पता लगाने की क्षमता है, इसके अलावा अमेज़ॅन एस 3 में एक फ़ाइल उत्पन्न करना है जिसमें पूर्ण रिकॉर्ड शामिल हैं जो मेल नहीं खाते हैं, जिससे आगे के विश्लेषण की सुविधा मिलती है।
इस उदाहरण में, हम स्रोत और लक्ष्य के बीच सत्यापन के लिए ऑन-प्रिमाइसेस डेटाबेस में तीन तालिकाओं का उपयोग करते हैं: balance_sheet, covid, तथा survery_financial_report.
.. पूर्वापेक्षाएँ
आरंभ करने से पहले, सुनिश्चित करें कि आपके पास निम्नलिखित शर्तें हैं:
समाधान तैनात करें
आपके लिए आरंभ करना आसान बनाने के लिए, हमने एक क्लाउडफॉर्मेशन टेम्पलेट बनाया है जो आपके लिए समाधान को स्वचालित रूप से कॉन्फ़िगर और तैनात करता है। निम्नलिखित चरणों को पूरा करें:
- अपने AWS खाते में एक S3 बकेट बनाएं जिसे कहा जाता है
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(अपना AWS खाता आईडी और AWS क्षेत्र प्रदान करें)। - निम्नलिखित को अनज़िप करें पट्टिका आपके स्थानीय सिस्टम के लिए।
- फ़ाइल को अपने स्थानीय सिस्टम पर अनज़िप करने के बाद, बदलें जिसे आपने अपने खाते में बनाया है (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) निम्नलिखित फ़ाइलों में:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- अपने स्थानीय फ़ोल्डर के सभी फ़ोल्डरों और फ़ाइलों को अपने S3 बकेट में अपलोड करें:
- निम्न को चलाएँ CloudFormation टेम्पलेट आपके खाते में।
CloudFormation टेम्प्लेट एक डेटाबेस बनाता है जिसे कहा जाता है griffin_datavalidation_blog और एक AWS ग्लू क्रॉलर बुलाया गया griffin_data_validation_blog .zip फ़ाइल में डेटा फ़ोल्डर के शीर्ष पर।
- चुनें अगला.
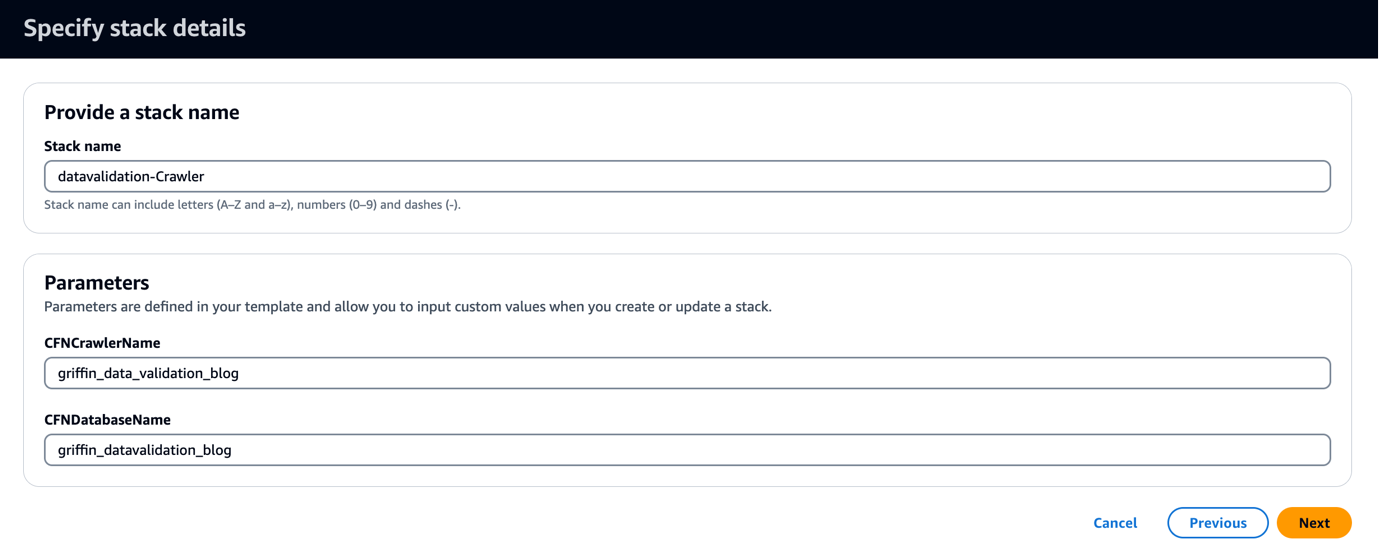
- चुनें अगला फिर से।
- पर समीक्षा पेज, का चयन करें मैं स्वीकार करता हूं कि AWS CloudFormation कस्टम नाम के साथ IAM संसाधन बना सकता है.
- चुनें स्टैक बनाएँ.
आप ऐसा कर सकते हैं स्टैक आउटपुट देखें पर एडब्ल्यूएस प्रबंधन कंसोल या निम्नलिखित AWS CLI कमांड का उपयोग करके:
- AWS ग्लू क्रॉलर चलाएँ और सत्यापित करें कि डेटा कैटलॉग में छह तालिकाएँ बनाई गई हैं।
- निम्न को चलाएँ CloudFormation टेम्पलेट आपके खाते में।
यह टेम्प्लेट ग्रिफ़िन-संबंधित JAR और कलाकृतियों की प्रतिलिपि बनाने के लिए बूटस्ट्रैप स्क्रिप्ट के साथ एक EMR क्लस्टर बनाता है। यह तीन EMR चरण भी चलाता है:
- ग्रिफिन फ्रेमवर्क द्वारा निर्मित सत्यापन मैट्रिक्स को देखने के लिए दो एथेना टेबल और दो एथेना दृश्य बनाएं
- स्रोत और लक्ष्य तालिका की तुलना करने के लिए सभी तीन तालिकाओं के लिए गणना सत्यापन चलाएँ
- स्रोत और लक्ष्य तालिका के बीच तुलना करने के लिए सभी तीन तालिकाओं के लिए रिकॉर्ड-स्तर और स्तंभ-स्तरीय सत्यापन चलाएँ
- के लिए सबनेटआईडी, अपनी सबनेट आईडी दर्ज करें।
- चुनें अगला.
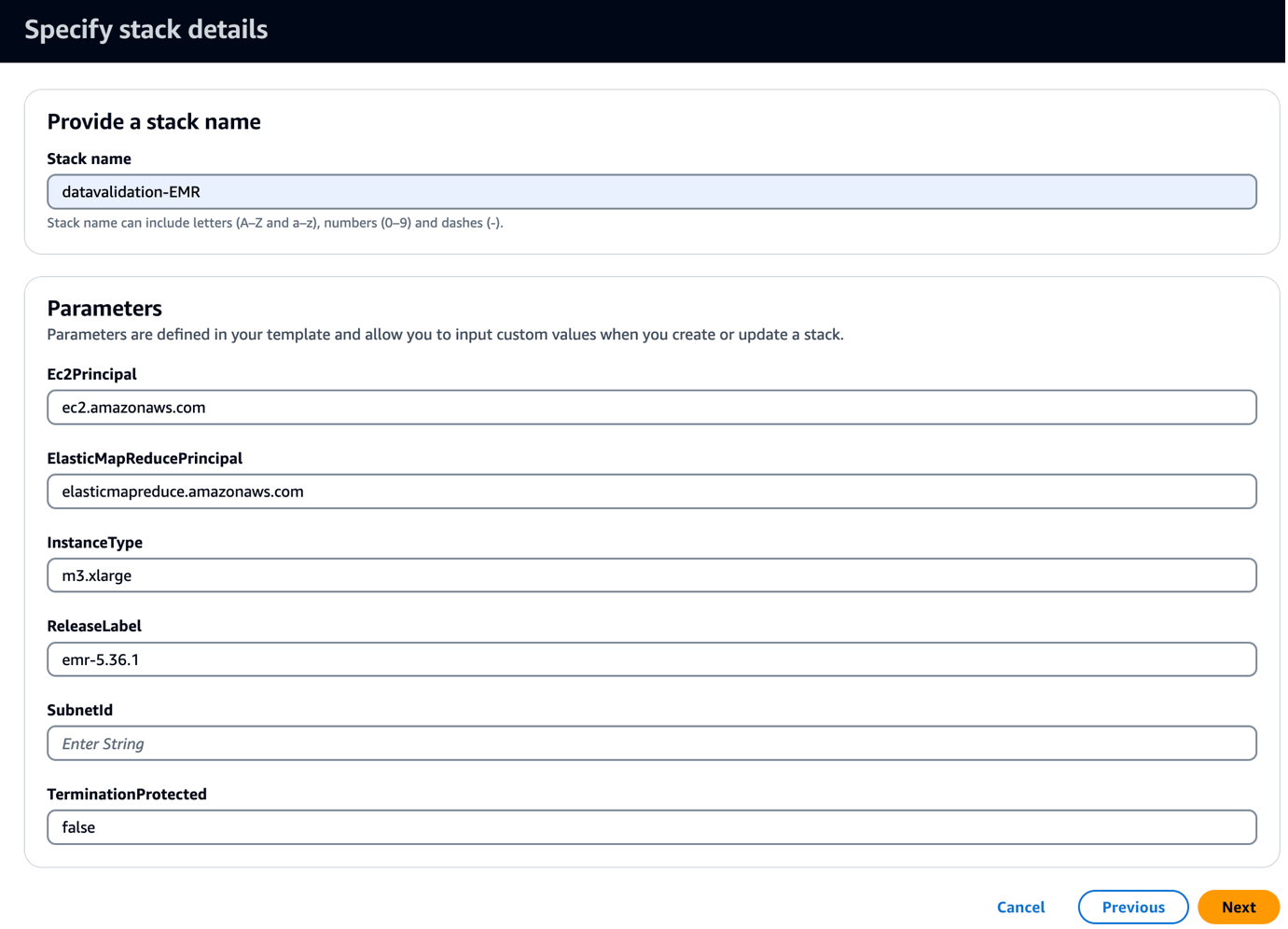
- चुनें अगला फिर से।
- पर समीक्षा पेज, का चयन करें मैं स्वीकार करता हूं कि AWS CloudFormation कस्टम नाम के साथ IAM संसाधन बना सकता है.
- चुनें स्टैक बनाएँ.
आप स्टैक आउटपुट को कंसोल पर या निम्नलिखित AWS CLI कमांड का उपयोग करके देख सकते हैं:
तैनाती को पूरा होने में लगभग 5 मिनट लगते हैं। जब स्टैक पूरा हो जाए, तो आपको इसे देखना चाहिए EMRCluster संसाधन लॉन्च किया गया और आपके खाते में उपलब्ध है।
जब ईएमआर क्लस्टर लॉन्च किया जाता है, तो यह क्लस्टर लॉन्च के बाद के हिस्से के रूप में निम्नलिखित चरण चलाता है:
- बूटस्ट्रैप क्रिया - यह इस ढांचे के लिए ग्रिफिन JAR फ़ाइल और निर्देशिका स्थापित करता है। यह अगले चरण में उपयोग करने के लिए नमूना डेटा फ़ाइलें भी डाउनलोड करता है।
- एथेना_टेबल_क्रिएशन - यह परिणाम रिपोर्ट पढ़ने के लिए एथेना में तालिकाएँ बनाता है।
- गिनती_सत्यापन - यह डेटा कैटलॉग तालिका से स्रोत और लक्ष्य डेटा के बीच डेटा गणना की तुलना करने का कार्य चलाता है और परिणामों को S3 बकेट में संग्रहीत करता है, जिसे एथेना तालिका के माध्यम से पढ़ा जाएगा।
- शुद्धता - यह डेटा कैटलॉग तालिका से स्रोत और लक्ष्य डेटा के बीच डेटा पंक्तियों की तुलना करने और परिणामों को S3 बकेट में संग्रहीत करने का कार्य चलाता है, जिसे एथेना तालिका के माध्यम से पढ़ा जाएगा।
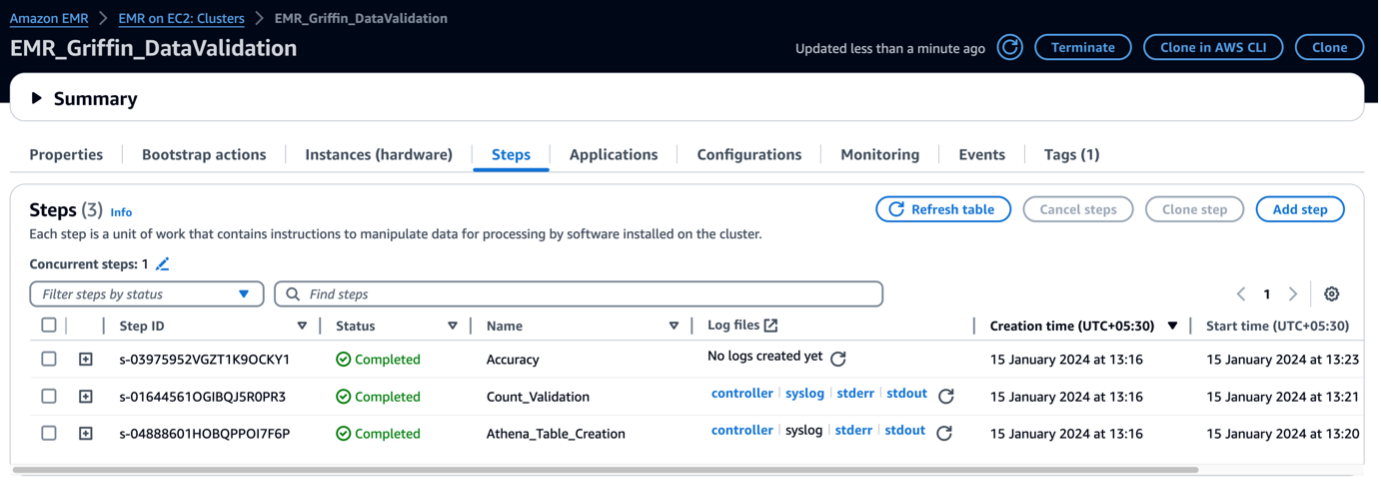
जब ईएमआर चरण पूरे हो जाते हैं, तो आपकी तालिका की तुलना हो जाती है और एथेना में देखने के लिए स्वचालित रूप से तैयार हो जाती है। सत्यापन के लिए किसी मैन्युअल हस्तक्षेप की आवश्यकता नहीं है।
पायथन ग्रिफिन के साथ डेटा सत्यापित करें
जब आपका ईएमआर क्लस्टर तैयार हो जाता है और सभी कार्य पूरे हो जाते हैं, तो इसका मतलब है कि गिनती सत्यापन और डेटा सत्यापन पूरा हो गया है। परिणाम अमेज़ॅन S3 में संग्रहीत किए गए हैं और एथेना तालिका उसके शीर्ष पर पहले से ही बनाई गई है। आप परिणाम देखने के लिए एथेना तालिकाओं को क्वेरी कर सकते हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
निम्नलिखित स्क्रीनशॉट सभी तालिकाओं के लिए गिनती परिणाम दिखाता है।
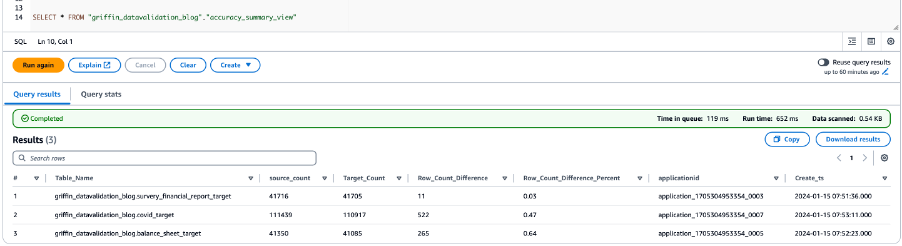
निम्नलिखित स्क्रीनशॉट सभी तालिकाओं के लिए डेटा सटीकता परिणाम दिखाता है।
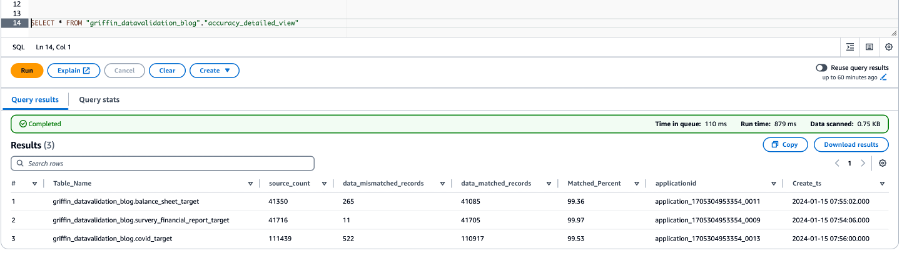
निम्नलिखित स्क्रीनशॉट बेमेल रिकॉर्ड के साथ प्रत्येक तालिका के लिए बनाई गई फ़ाइलों को दिखाता है। कार्य से सीधे प्रत्येक तालिका के लिए अलग-अलग फ़ोल्डर तैयार किए जाते हैं।
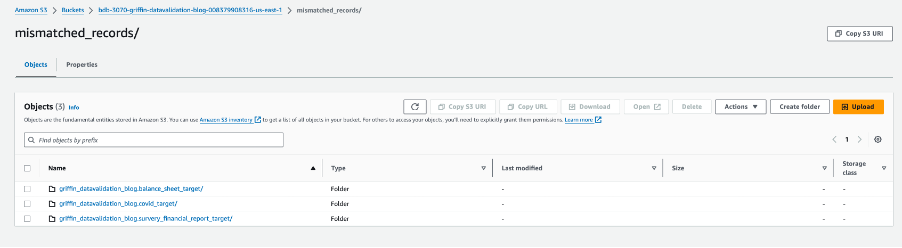
प्रत्येक तालिका फ़ोल्डर में कार्य चलने वाले प्रत्येक दिन के लिए एक निर्देशिका होती है।
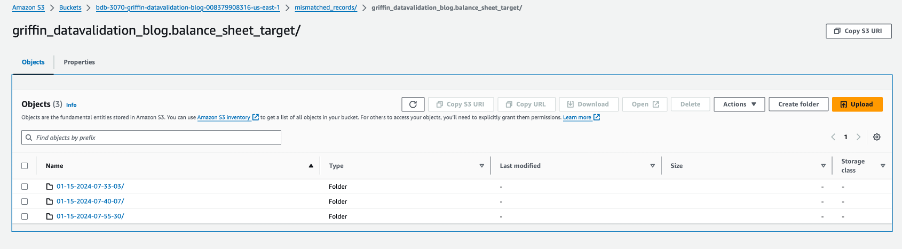
उस विशिष्ट तिथि के भीतर, एक फ़ाइल का नाम __missRecords ऐसे रिकॉर्ड शामिल हैं जो मेल नहीं खाते.

निम्न स्क्रीनशॉट की सामग्री को दर्शाता है __missRecords फ़ाइल.

क्लीन अप
अतिरिक्त शुल्क से बचने के लिए, समाधान पूरा होने पर अपने संसाधनों को साफ करने के लिए निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस गोंद डेटाबेस हटाएं
griffin_datavalidation_blogऔर डेटाबेस छोड़ेंgriffin_datavalidation_blogझरना। - बकेट से आपके द्वारा बनाए गए उपसर्गों और ऑब्जेक्ट को हटा दें
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - CloudFormation स्टैक को हटाएं, जो आपके अतिरिक्त संसाधनों को हटा देता है।
निष्कर्ष
इस पोस्ट में दिखाया गया है कि आप पोस्ट-माइग्रेशन डेटा सत्यापन प्रक्रिया को तेज करने के लिए पायथन ग्रिफिन का उपयोग कैसे कर सकते हैं। पायथन ग्रिफिन आपको गिनती और पंक्ति- और कॉलम-स्तरीय सत्यापन की गणना करने में मदद करता है, बिना कोई कोड लिखे बेमेल रिकॉर्ड की पहचान करता है।
डेटा गुणवत्ता उपयोग मामलों के बारे में अधिक जानकारी के लिए, देखें AWS Glue डेटा कैटलॉग से AWS Glue डेटा गुणवत्ता के साथ आरंभ करना और एडब्ल्यूएस गोंद डेटा गुणवत्ता.
लेखक के बारे में
 दीपल महाजन अमेज़ॅन वेब सर्विसेज में एक लीड कंसल्टेंट के रूप में कार्य करता है, जो वैश्विक ग्राहकों को अत्यधिक सुरक्षित, स्केलेबल, विश्वसनीय और लागत-कुशल क्लाउड एप्लिकेशन विकसित करने में विशेषज्ञ मार्गदर्शन प्रदान करता है। वित्त, दूरसंचार, खुदरा और स्वास्थ्य सेवा जैसे विभिन्न क्षेत्रों में सॉफ्टवेयर विकास, वास्तुकला और विश्लेषण में समृद्ध अनुभव के साथ, वह अपनी भूमिका में अमूल्य अंतर्दृष्टि लाते हैं। पेशेवर क्षेत्र से परे, डिपल को नए गंतव्यों की खोज करने में आनंद आता है, वह पहले ही अपनी इच्छा सूची में 14 में से 30 देशों का दौरा कर चुका है।
दीपल महाजन अमेज़ॅन वेब सर्विसेज में एक लीड कंसल्टेंट के रूप में कार्य करता है, जो वैश्विक ग्राहकों को अत्यधिक सुरक्षित, स्केलेबल, विश्वसनीय और लागत-कुशल क्लाउड एप्लिकेशन विकसित करने में विशेषज्ञ मार्गदर्शन प्रदान करता है। वित्त, दूरसंचार, खुदरा और स्वास्थ्य सेवा जैसे विभिन्न क्षेत्रों में सॉफ्टवेयर विकास, वास्तुकला और विश्लेषण में समृद्ध अनुभव के साथ, वह अपनी भूमिका में अमूल्य अंतर्दृष्टि लाते हैं। पेशेवर क्षेत्र से परे, डिपल को नए गंतव्यों की खोज करने में आनंद आता है, वह पहले ही अपनी इच्छा सूची में 14 में से 30 देशों का दौरा कर चुका है।
 अखिल AWS प्रोफेशनल सर्विसेज में लीड कंसल्टेंट हैं। वह ग्राहकों को स्केलेबल डेटा एनालिटिक्स समाधान डिजाइन करने और बनाने में मदद करता है और डेटा पाइपलाइनों और डेटा वेयरहाउस को AWS में स्थानांतरित करता है। अपने खाली समय में उन्हें यात्रा करना, गेम खेलना और फिल्में देखना पसंद है।
अखिल AWS प्रोफेशनल सर्विसेज में लीड कंसल्टेंट हैं। वह ग्राहकों को स्केलेबल डेटा एनालिटिक्स समाधान डिजाइन करने और बनाने में मदद करता है और डेटा पाइपलाइनों और डेटा वेयरहाउस को AWS में स्थानांतरित करता है। अपने खाली समय में उन्हें यात्रा करना, गेम खेलना और फिल्में देखना पसंद है।
 रमेश रघुपति एडब्ल्यूएस में डब्ल्यूडब्ल्यूसीओ प्रोसर्व के साथ एक वरिष्ठ डेटा वास्तुकार हैं। वह AWS ग्राहकों के साथ AWS क्लाउड पर डेटा वेयरहाउस और डेटा लेक को आर्किटेक्ट करने, तैनात करने और माइग्रेट करने के लिए काम करता है। काम पर नहीं होने पर, रमेश यात्रा करना, परिवार के साथ समय बिताना और योग करना पसंद करता है।
रमेश रघुपति एडब्ल्यूएस में डब्ल्यूडब्ल्यूसीओ प्रोसर्व के साथ एक वरिष्ठ डेटा वास्तुकार हैं। वह AWS ग्राहकों के साथ AWS क्लाउड पर डेटा वेयरहाउस और डेटा लेक को आर्किटेक्ट करने, तैनात करने और माइग्रेट करने के लिए काम करता है। काम पर नहीं होने पर, रमेश यात्रा करना, परिवार के साथ समय बिताना और योग करना पसंद करता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

