A zamanin bayanai, ƙungiyoyi suna ƙara yin amfani da tafkunan bayanai don adanawa da kuma nazarin ɗimbin bayanai da aka tsara da marasa tsari. Tafkunan bayanai suna ba da wurin adana bayanai daga tushe daban-daban, suna ba ƙungiyoyi damar buɗe bayanai masu mahimmanci da kuma fitar da yanke shawara ta hanyar bayanai. Koyaya, yayin da adadin bayanai ke ci gaba da girma, inganta tsarin bayanai da tsari ya zama mahimmanci don ingantaccen bincike da bincike.
Ɗaya daga cikin manyan ƙalubalen da ke cikin tafkin bayanai shine yuwuwar yin jinkirin aiwatar da bincike, musamman lokacin da ake mu'amala da manyan bayanai. Ana iya danganta wannan ga abubuwa kamar tsarin bayanan da ba su da inganci, wanda ke haifar da yawan bincikar bayanai da rashin ingantaccen amfani da kayan ƙididdigewa. Don magance wannan ƙalubalen, ayyuka gama gari kamar rarrabawa da guga na iya haɓaka aikin tambaya da rage farashin ƙididdiga.
Sashewa wata dabara ce da ke raba babban saitin bayanai zuwa ƙarami, ƙarin sassa masu iya sarrafawa bisa ƙayyadaddun sharudda, kamar kwanan wata, yanki, ko nau'in samfur. Ta hanyar rarraba bayanai, tambayoyin bincike na ƙasa na iya tsallake ɓangarori marasa mahimmanci, rage adadin bayanan da ake buƙatar dubawa da sarrafa su. Kuna iya amfani da ginshiƙan ɓangarori a cikin jumlar WHERE a cikin tambayoyin don bincika takamaiman ɓangarori waɗanda tambayar ku ke buƙata kawai. Wannan na iya haifar da saurin lokacin aiki na tambaya da ingantaccen amfani da albarkatu. Yana aiki da kyau sosai lokacin da aka zaɓi ginshiƙai tare da ƙananan kadinity azaman maɓalli.
Idan kuna da babban ginshiƙi na kardinati wanda wasu lokuta kuna buƙatar tace ta abokan cinikin VIP? Kowane abokin ciniki yawanci ana gano shi da ID, wanda zai iya zama miliyoyi. Rarraba bai dace da irin waɗannan manyan ginshiƙan kardinati ba saboda kun ƙare da ƙananan fayiloli, jinkirin tacewa, da babba. Sabis na Sauƙi na Amazon (Amazon S3) Farashin API (an ƙirƙiri prefix S3 ɗaya akan ƙimar ginshiƙin ɓangaren). Ko da yake za ku iya amfani da rarrabawa tare da maɓallin halitta kamar birni ko jiha don taƙaita saitin bayananku zuwa wani mataki, har yanzu yana da mahimmanci a yi tambaya a cikin ɓangarorin tushen kwanan wata idan bayananku jerin lokaci ne.
Wannan shi ne inda guga ya shigo cikin wasa. Bucketing yana tabbatar da cewa duk layuka masu kima iri ɗaya na ginshiƙai ɗaya ko fiye sun ƙare a cikin fayil iri ɗaya. Maimakon fayil ɗaya a kowace ƙima, kamar rarrabuwa, ana amfani da aikin hash don rarraba dabi'u a ko'ina cikin ƙayyadaddun adadin fayiloli. Ta hanyar tsara bayanai ta wannan hanya, za ku iya yin ingantaccen tacewa, saboda kawai buckets masu dacewa da ake buƙatar sarrafa su, ƙara rage yawan ƙididdiga.
Akwai zaɓuɓɓuka da yawa don aiwatar da bucket akan AWS. Ɗaya hanyar ita ce amfani da Athena na Amazon Ƙirƙiri sanarwa AS SELECT (CTAS), wanda ke ba ka damar ƙirƙirar tebur bucket kai tsaye daga tambaya. A madadin, zaka iya amfani AWS Manne don Apache Spark, wanda ke ba da tallafin ginanniyar tallafi don daidaitawar bucket yayin aiwatar da canjin bayanai. AWS Glue yana ba ku damar ayyana sigogin bucket, kamar adadin buckets da ginshiƙan da za a kai, samar da ingantaccen tsarin bayanai don ingantaccen tambaya tare da Athena.
A cikin wannan sakon, mun tattauna yadda ake aiwatar da bucketing akan tafkunan bayanan AWS, gami da amfani da bayanin Athena CTAS da AWS Glue don Apache Spark. Hakanan muna rufe bucket don tebur na Apache Iceberg.
Misali yanayin amfani
A cikin wannan sakon, kuna amfani da bayanan jama'a, da NOAA Integrated Surface Database. Masu nazarin bayanai suna gudanar da tambayoyin lokaci ɗaya don bayanai a cikin shekaru 5 da suka gabata ta hanyar Athena. Yawancin tambayoyin don takamaiman tashoshi ne masu takamaiman nau'ikan rahoto. Ana buƙatar kammala tambayoyin a cikin daƙiƙa 10, kuma farashin yana buƙatar haɓakawa a hankali. A cikin wannan yanayin, kai injiniyan bayanai ne ke da alhakin inganta aikin tambaya da farashi.
Misali, idan manazarci yana son dawo da bayanai don takamaiman tasha (misali, ID na tasha 123456) tare da nau'in rahoto na musamman (misali, CRN01), tambayar na iya yin kama da wannan tambaya:
A cikin yanayin NOAA Integrated Surface Database, da station_id ginshiƙi yana da ƙila ya sami babban kadinanci, tare da manyan abubuwan gano tasha. A daya bangaren kuma, da report_type ginshiƙi na iya samun ɗan ƙaranci mai ƙima, tare da ƙayyadaddun nau'ikan rahoto. Ganin wannan yanayin, yana da kyau a raba bayanan ta hanyar report_type da guga da shi station_id.
Tare da wannan dabarar rarrabuwar kawuna da bucketing, Athena na iya fara kawar da ɓangarori don nau'ikan rahoton da ba su da mahimmanci, sannan bincika kawai buckets a cikin ɓangaren da suka dace waɗanda suka dace da ƙayyadaddun ID na tashar, da rage yawan adadin bayanan da aka sarrafa da haɓaka lokacin aiki. Wannan hanyar ba kawai ta cika buƙatun aikin aikin ba, har ma tana taimakawa haɓaka farashi ta hanyar rage adadin bayanan da aka bincika da kuma cajin kowace tambaya.
A cikin wannan post ɗin, mun bincika yadda shimfidar bayanai ke shafar aikin tambaya, musamman, bucketing. Mun kuma kwatanta hanyoyi daban-daban guda uku don cimma bucketing. Tebur mai zuwa yana wakiltar sharuɗɗan da za a ƙirƙira teburin.
| . | noaa_remote_original | athena_ba_bucketed | athena_bucket | manne_bucketed | athena_bucketed_iceberg |
| format | CSV | parquet | parquet | parquet | parquet |
| matsawa | n / a | Cirewa | Cirewa | Cirewa | Cirewa |
| An ƙirƙira ta hanyar | n / a | Athena CTAS | Athena CTAS | Farashin ETL | Athena CTAS tare da Iceberg |
| engine | n / a | Murna | Murna | Apache Spark | Apache Iceberg |
| An raba? | Ee amma ta hanya daban | A | A | A | A |
| An bucket? | A'a | A'a | A | A | A |
noaa_remote_original an raba ta year shafi, amma ba ta hanyar report_type shafi. Wannan jeri yana wakiltar idan an raba teburin da ainihin ginshiƙai waɗanda aka yi amfani da su a cikin tambayoyin.
Teburin tushe
Don wannan sakon, kuna ƙirƙirar tebur da yawa tare da yanayi daban-daban: wasu ba tare da guga ba wasu kuma tare da guga, don nuna halayen aikin guga. Da farko, bari mu ƙirƙiri tebur na asali ta amfani da bayanan NOAA. A matakai na gaba, kuna shigar da bayanai daga wannan tebur don ƙirƙirar teburin gwaji.
Akwai hanyoyi da yawa don ayyana ma'anar tebur: Gudun DDL, AWS Glue crawler, AWS Glue Data Catalog API, da sauransu. A cikin wannan mataki, kuna gudanar da DDL ta hanyar Athena console.
Kammala matakai masu zuwa don ƙirƙirar "bucketing_blog"."noaa_remote_original" tebur a cikin Data Catalog:
- Bude wasan bidiyo na Athena.
- A cikin editan tambaya, gudanar da DDL mai zuwa don ƙirƙirar sabon bayanai na AWS Glue:
- Ma database karkashin data, i
bucketing_blogdon saita bayanan bayanai na yanzu. - Gudun DDL mai zuwa don ƙirƙirar tebur na asali:
Saboda bayanan tushen sun nakalto filayen, muna amfani da su OpenCSVSerde maimakon tsoho LazySimpleSerde.
Waɗannan fayilolin CSV suna da layin kai, wanda muke gaya wa Athena ta tsallake ta ƙara skip.header.line.count kuma saita darajar zuwa 1.
Don ƙarin bayani, koma zuwa BudeCSVSerDe don sarrafa CSV.
- Gudun DDL mai zuwa don ƙara ɓangarori. Muna ƙara ɓangarori kawai na shekaru 5 daga cikin shekaru 124 dangane da buƙatun yanayin amfani:
- Gudun DML mai zuwa don tabbatarwa idan za ku iya yin nasarar neman bayanan:
Yanzu kun shirya don fara tambayar tebur na asali don bincika aikin tushe.
- Gudanar da tambaya akan tebur na asali don kimanta aikin tambayar azaman tushen tushe. Tambayar da ke gaba tana zabar rikodi don takamaiman tashoshi biyar tare da nau'in rahoto
CRN05: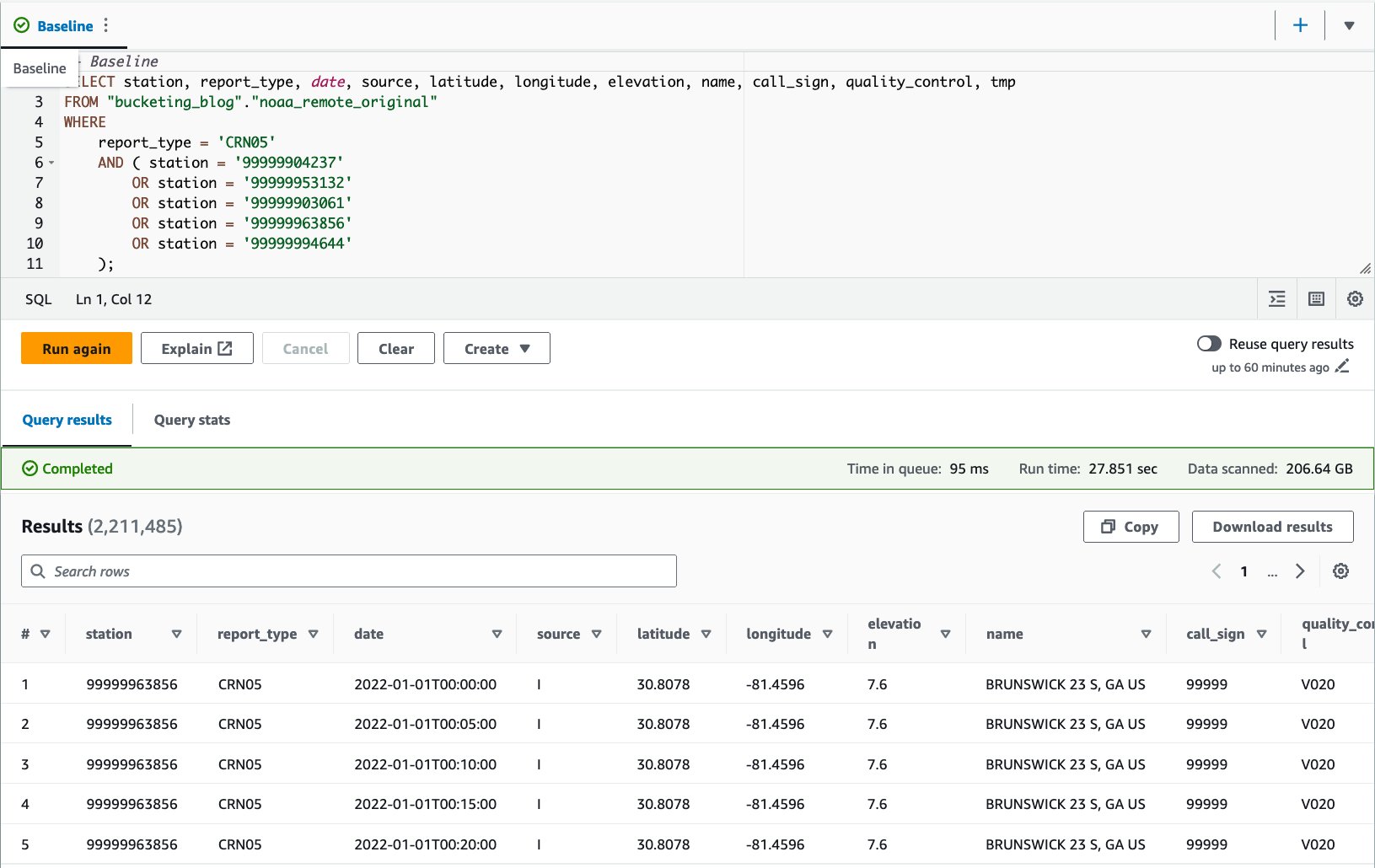
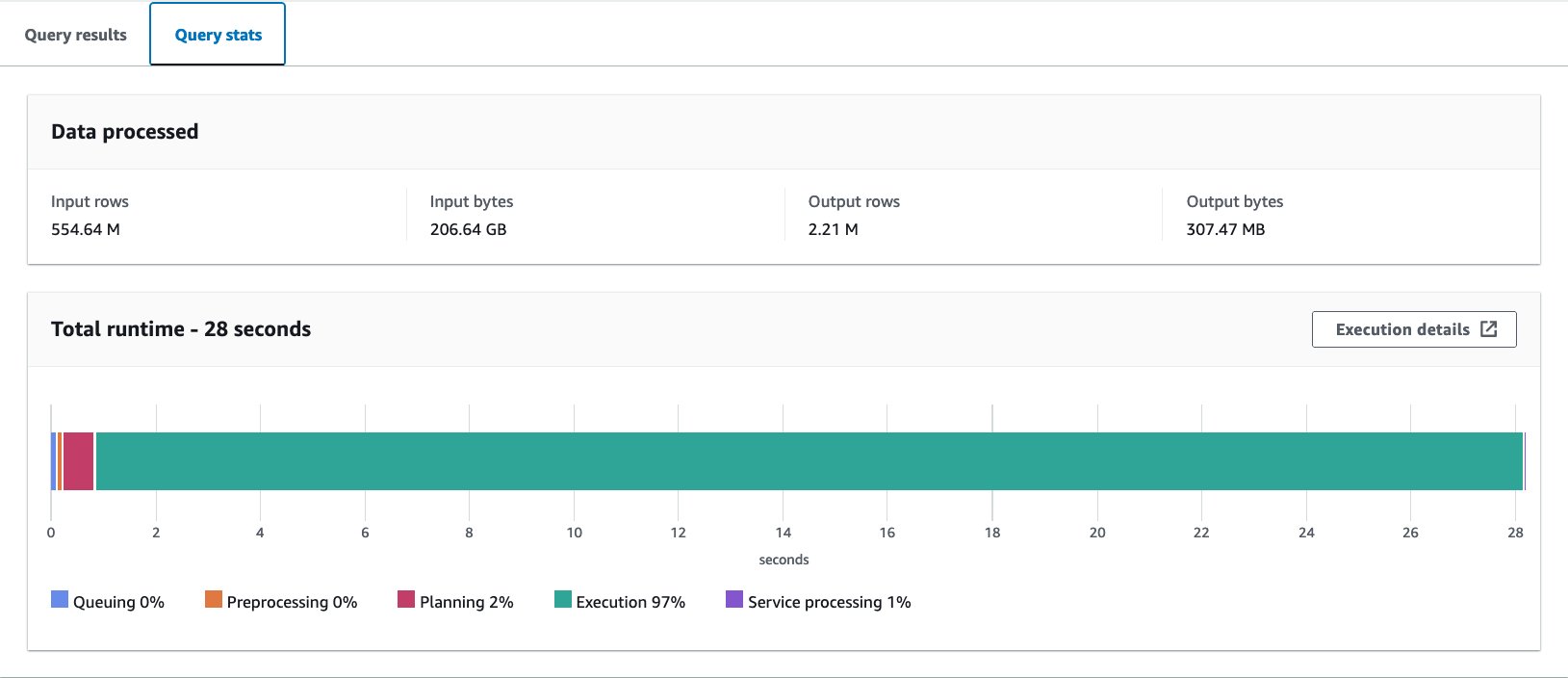
Mun gudanar da wannan tambayar sau 10. Matsakaicin lokacin gudanar da bincike na tambayoyin 10 shine daƙiƙa 27.6, wanda ya fi tsayin daka fiye da burinmu na daƙiƙa 10, kuma ana duba bayanan 155.75 GB don dawo da bayanan miliyan 1.65. Wannan shine aikin tushe na ɗanyen tebur na asali. Lokaci yayi da za a fara inganta shimfidar bayanai daga wannan tushe.
Na gaba, kuna ƙirƙirar tebur tare da yanayi daban-daban daga asali: ɗaya ba tare da guga ba kuma ɗaya tare da guga, kuma kwatanta su.
Inganta shimfidar bayanai ta amfani da Athena CTAS
A wannan sashe, muna amfani da tambayar Athena CTAS don inganta shimfidar bayanai da tsarin sa.
Da farko, bari mu ƙirƙiri tebur mai rabo amma ba tare da guga ba. An raba sabon tebur da ginshiƙi report_type saboda yawancin tambayoyin da ake sa ran suna amfani da wannan shafi a cikin jumlar INA, kuma ana adana abubuwa azaman Parquet tare da matsawa Snappy.
- Bude editan tambaya Athena.
- Gudanar da tambaya mai zuwa, samar da guga na S3 da prefix:
Ya kamata bayananku suyi kama da hotunan kariyar kwamfuta masu zuwa.
Akwai fayiloli 30 a ƙarƙashin ɓangaren.
Na gaba, kun ƙirƙiri tebur tare da bucketing salon Hive. Adadin buckets yana buƙatar a hankali a hankali ta hanyar gwaje-gwaje don yanayin amfanin ku. Gabaɗaya magana, ƙarin buckets ɗin da kuke da shi, ƙarami granularity, wanda zai haifar da kyakkyawan aiki. A gefe guda, ƙananan fayiloli da yawa na iya haifar da rashin aiki a cikin tsarawa da sarrafa tambaya. Hakanan, guga yana aiki ne kawai idan kuna tambayar ƴan ƙididdiga na maɓallin guga. Yawan ƙimar da kuka ƙara zuwa tambayar ku, mafi kusantar cewa za ku ƙarasa karanta duk buckets.
Mai zuwa shine tambayar tushe don ingantawa:
A cikin wannan misali, za a guga teburin cikin buckets 16 ta babban ginshiƙi mai girma (station), wanda ya kamata a yi amfani da shi don jumlar INA a cikin tambayar. Duk sauran sharuɗɗan sun kasance iri ɗaya. Tambayar asali tana da ƙima biyar a cikin ID na tashar, kuma kuna tsammanin tambayoyin za su kasance a kusa da wannan lambar a mafi yawan, wanda bai isa ba fiye da adadin buckets, don haka 16 ya kamata yayi aiki da kyau. Yana yiwuwa a ƙididdige adadin buckets mafi girma, amma CTAS ba za a iya amfani da shi ba idan jimillar adadin ya wuce 100.
- Gudanar da tambaya mai zuwa:
Tambayar ta ƙirƙiri abubuwan S3 da aka tsara kamar yadda aka nuna a cikin hotuna masu zuwa.
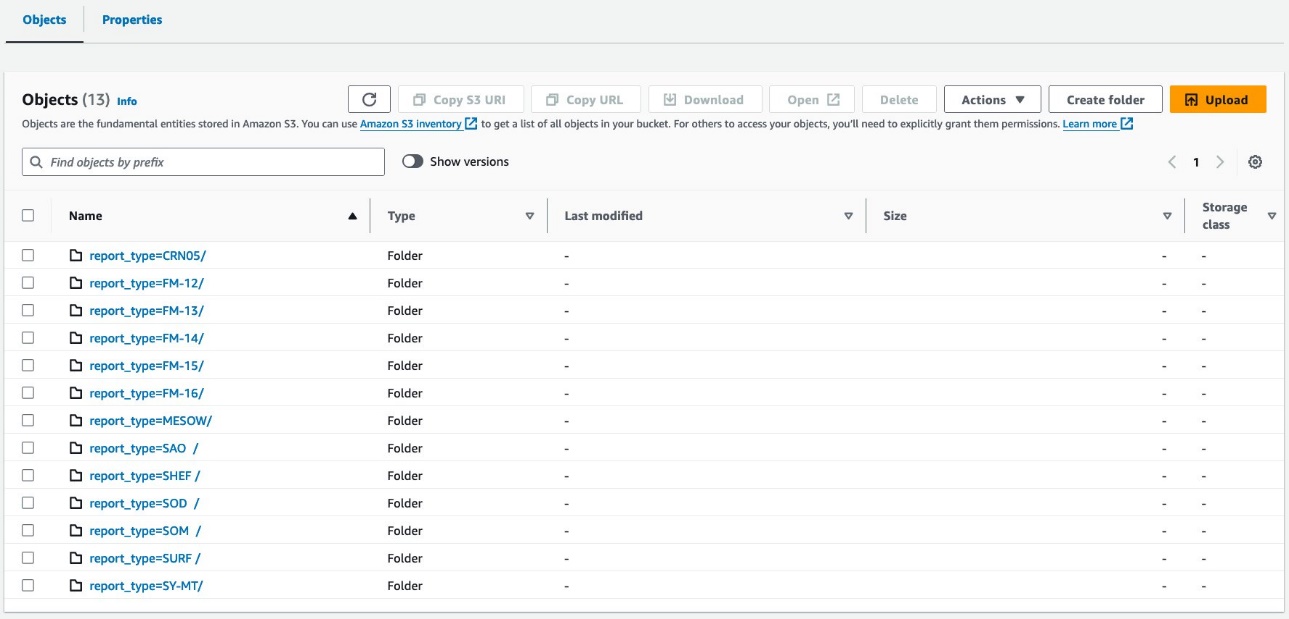

Tsarin matakin tebur yayi kama da daidai tsakanin athena_non_bucketed da kuma athena_bucketed: akwai partitions 13 a kowane tebur. Bambanci shine adadin abubuwan da ke ƙarƙashin sassan. Akwai abubuwa 16 (guga) a kowane bangare, na kusan 10-25 MB kowanne a wannan yanayin. Adadin guga yana dawwama a ƙayyadaddun ƙimar ba tare da la'akari da adadin bayanai ba, amma girman guga ya dogara da adadin bayanai.
Yanzu kun shirya yin tambaya akan kowane tebur don kimanta aikin tambaya. Tambayar za ta zaɓi rikodin tare da takamaiman tashoshi biyar da nau'in rahoto CRN05 shekaru 5 da suka gabata. Ko da yake ba za ka iya ganin waɗanne bayanai na takamaiman tasha ke cikin wanne guga ba, Athena ta ƙididdige ta kuma ta same ta daidai.
- Nemi teburin da ba bucket ba tare da bayanin mai zuwa:

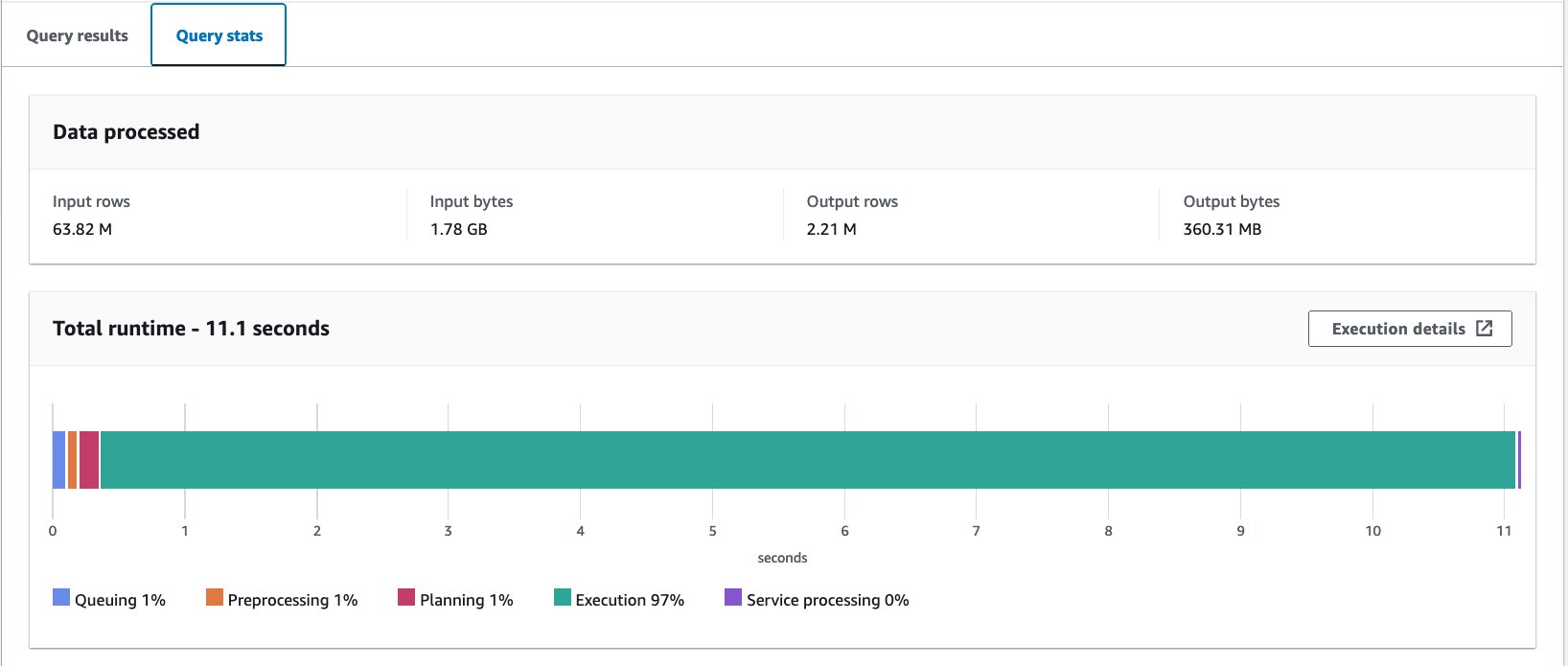
Mun gudanar da wannan tambayar sau 10. Matsakaicin lokacin aiki na tambayoyin 10 shine daƙiƙa 10.95, kuma ana bincika 358 MB na bayanai don dawo da bayanai miliyan 2.21. Dukkanin lokacin aiki da girman sikanin an ragu sosai saboda kun raba bayanan, kuma yanzu kuna iya karanta bangare ɗaya kawai inda aka tsallake kashi 12 na 13. Bugu da kari, adadin bayanan da aka bincika ya ragu daga 206 GB zuwa 360 MB, wanda shine raguwar 99.8%. Wannan ba kawai saboda rabuwar ba ne, har ma saboda canjin tsarin sa zuwa Parquet da matsawa tare da Snappy.
- Tambayi tebirin bucket tare da bayanin mai zuwa:
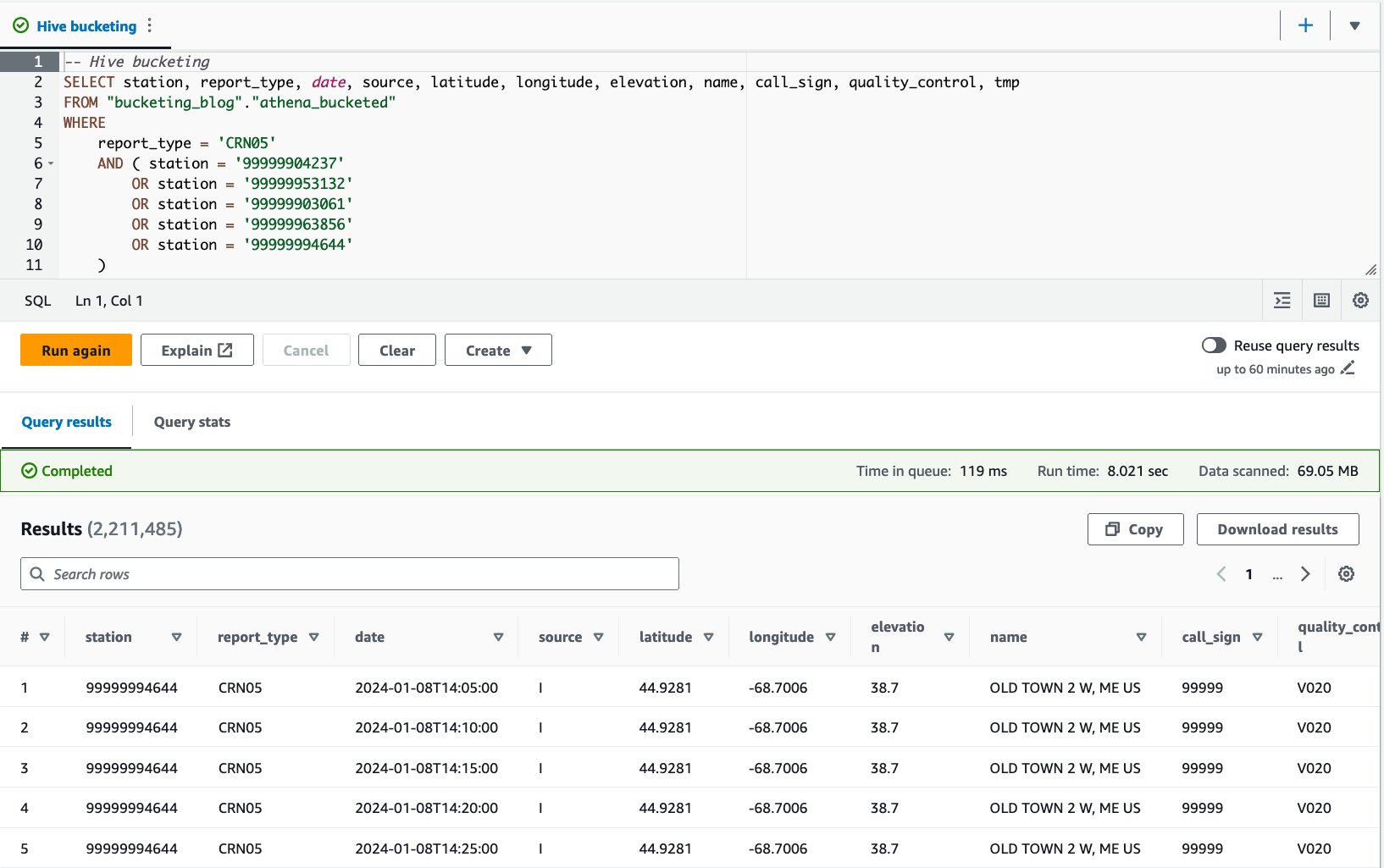
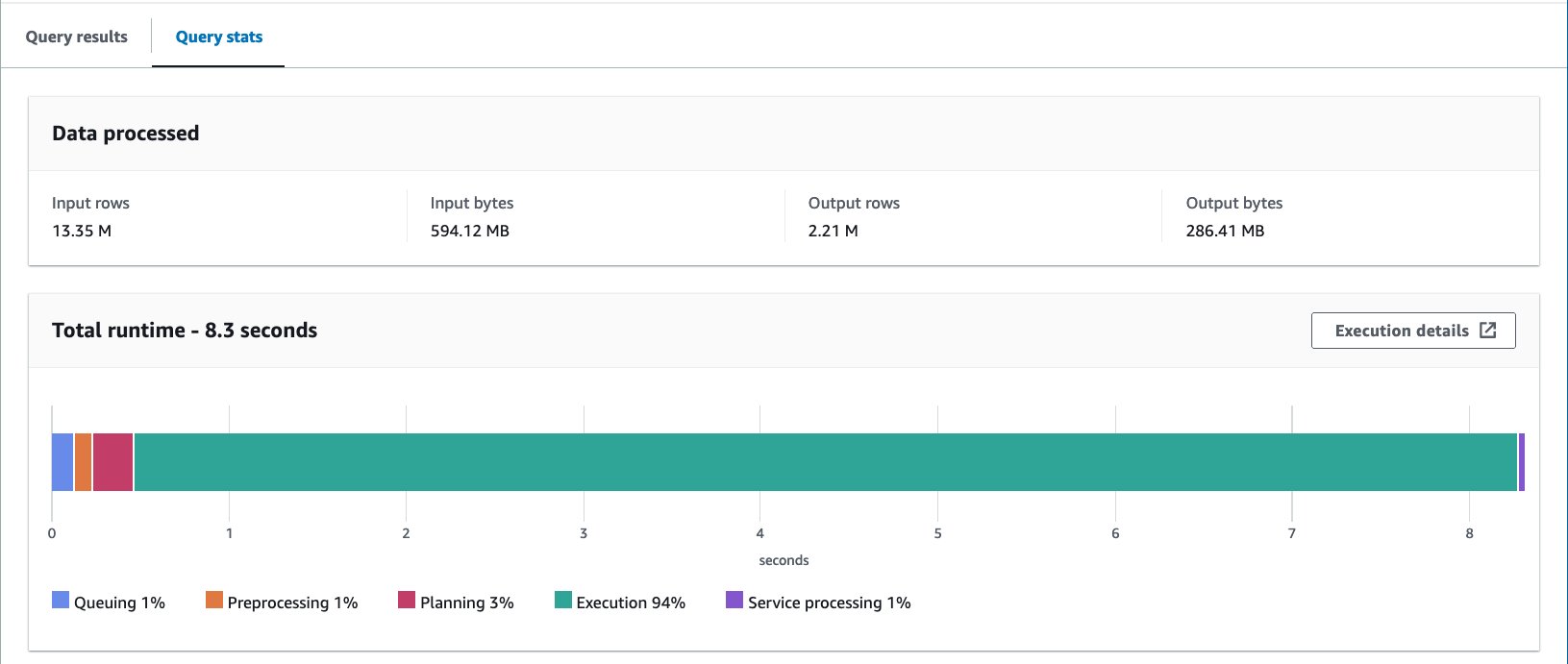
Mun gudanar da wannan tambayar sau 10. Matsakaicin lokacin aiki na tambayoyin 10 shine daƙiƙa 7.82, kuma ana bincika 69 MB na bayanai don dawo da bayanai miliyan 2.21. Wannan yana nufin rage matsakaicin lokacin gudu daga 10.95 zuwa 7.82 seconds (-29%), da kuma raguwa mai ban mamaki na bayanan da aka duba daga 358 MB zuwa 69 MB (-81%) don dawo da adadin adadin bayanai idan aka kwatanta da teburin da ba bucket. . A wannan yanayin, duka lokacin aiki da bayanan da aka bincika an inganta su ta hanyar guga. Wannan yana nufin guga ya ba da gudummawa ba kawai ga aiki ba har ma don rage farashi.
sharudda
Kamar yadda aka fada a baya, girman guga a hankali don haɓaka aikin tambayar ku. Bucketing yana aiki ne kawai idan kuna tambayar ƴan ƙididdiga na maɓallin guga. Yi la'akari da ƙirƙirar ƙarin guga fiye da adadin ƙimar da ake tsammani a cikin ainihin tambaya.
Bugu da ƙari, tambayar Athena CTAS tana iyakance don ƙirƙirar har zuwa ɓangarori 100 a lokaci ɗaya. Idan kuna buƙatar babban adadin ɓangarori, kuna iya amfani da cirewar AWS Glue, canzawa, da kaya (ETL), kodayake akwai aiki don raba cikin maganganun SQL da yawa.
Inganta shimfidar bayanai ta amfani da AWS Glue ETL
Apache Spark shine tushen tushen tsarin sarrafawa wanda ke ba da damar ETL mai sassauƙa tare da PySpark, Scala, da Spark SQL. Yana ba ku damar rarrabawa da guga bayanan ku bisa ga buƙatun ku. Spark yana da zaɓuɓɓukan daidaitawa da yawa don haɓaka ayyuka. Kuna iya aiki da kai da saka idanu akan ayyukan Spark ba tare da wahala ba. A cikin wannan sashin, muna amfani da ayyukan AWS Glue ETL don gudanar da lambar Spark don inganta shimfidar bayanai.
Ba kamar bucketing Athena ba, AWS Glue ETL yana amfani da bucket na tushen Spark azaman algorithm na guga. Duk abin da kuke buƙatar yi shine ƙara kayan tebur masu zuwa akan tebur: bucketing_format = 'spark'. Don cikakkun bayanai game da wannan kayan tebur, duba Rarraba da guga a cikin Athena.
Cika waɗannan matakai don ƙirƙirar tebur tare da guga ta hanyar AWS Glue ETL:
- A kan AWS Glue console, zaɓi Ayyukan ETL a cikin hanyar kewayawa.
- zabi Jobirƙiri aiki kuma zaɓi Visual ETL.
- A karkashin Ƙara nodes, i Bayanan Bayani na AWS domin Sources.
- Ma database, i
bucketing_blog. - Ma Table, i
noaa_remote_original. - A karkashin Ƙara nodes, i Canja Tsarin domin Canji.
- A karkashin Ƙara nodes, i Canji na Musamman domin Canji.
- Ma sunan, shiga
ToS3WithBucketing. - Ma Node iyaye, i Canja Tsarin.
- Ma Lambar toshe, shigar da snippet code mai zuwa:
Hoton hoto mai zuwa yana nuna aikin da aka ƙirƙira ta amfani da AWS Glue Studio don samar da tebur da bayanai.
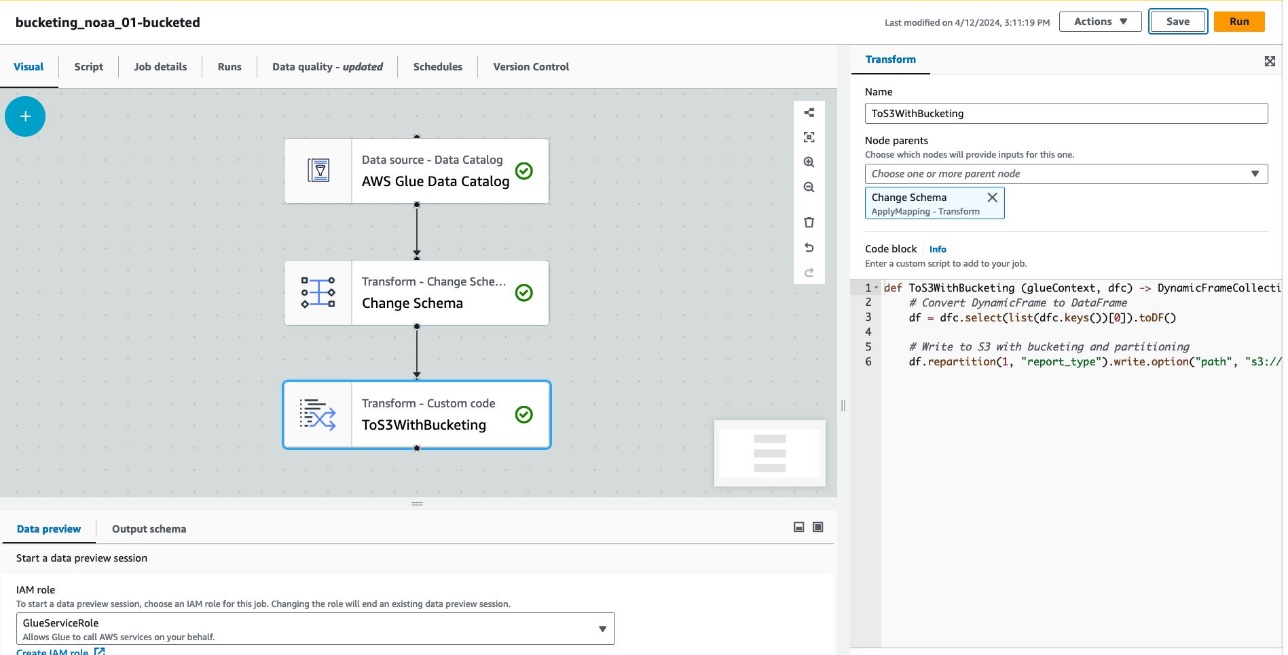
Kowane kumburi yana wakiltar waɗannan abubuwa:
- The Bayanan Bayani na AWS kumburi yana lodin
noaa_remote_originaltebur daga Data Catalog - The Canja Tsarin kumburi yana tabbatar da cewa yana loda ginshiƙan rajista a cikin Kas ɗin Bayanai
- The ToS3WithBucketing node yana rubuta bayanai zuwa Amazon S3 tare da rarrabuwa biyu da bucket na tushen Spark
An yi nasarar rubuta aikin a cikin editan gani.
- A karkashin Bayanin aiki, domin Matsayin IAM, zabi naka Gano AWS da Gudanar da Samun Dama (IAM) rawar don wannan aikin.
- Ma Nau'in ma'aikaci, i G.8X.
- Ma Yawan ma'aikata da ake nema, shiga 5.
- zabi Ajiye, sannan zaba Run.
Bayan wadannan matakai, tebur glue_bucketed. an halicce shi.
- zabi Tables a cikin filin kewayawa, kuma zaɓi tebur
glue_bucketed. - a Actions menu, zaɓi Gyara tebur karkashin Sarrafa.
- a cikin Kaddarorin tebur sashe, zabi Add.
- Ƙara maɓalli biyu tare da maɓalli
bucketing_formatda kuma tartsatsi darajar.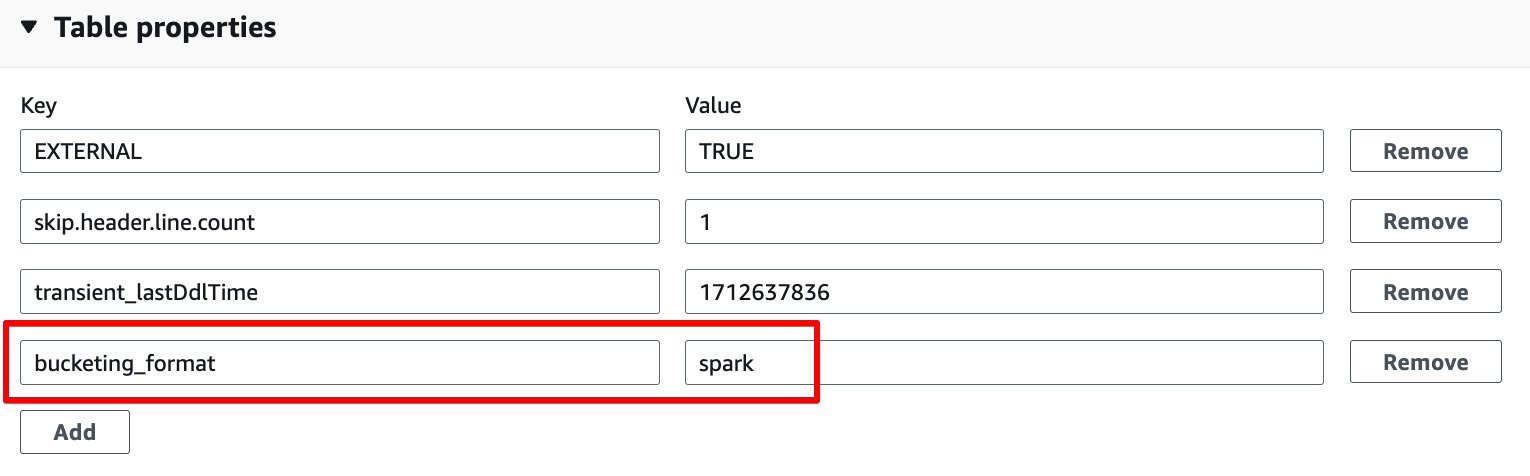
- zabi Ajiye.
Yanzu lokaci ya yi da za a tambayi tebur.
- Tambayi tebirin bucket tare da bayanin mai zuwa:

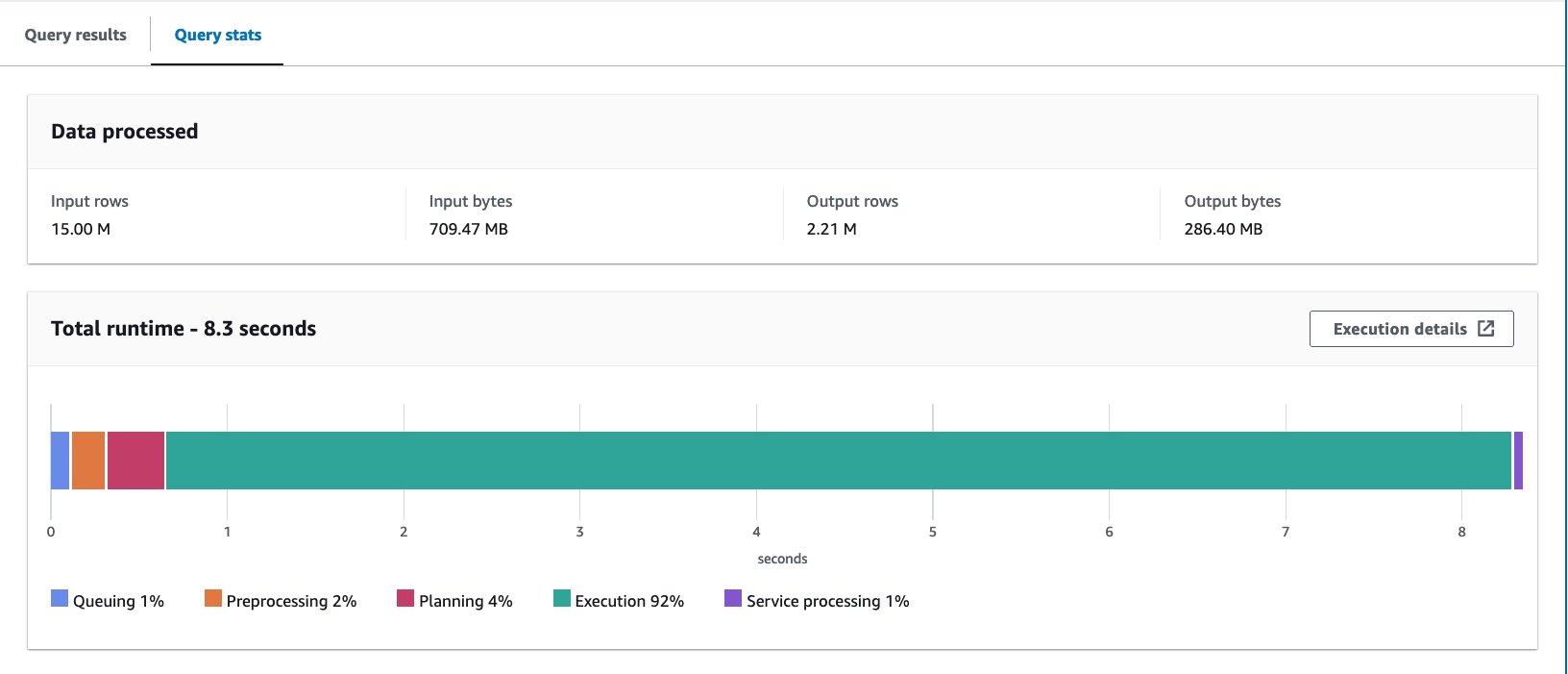
Mun gudanar da tambayar sau 10. Matsakaicin lokacin aiki na tambayoyin 10 shine daƙiƙa 7.09, kuma ana bincika 88 MB na bayanai don dawo da bayanai miliyan 2.21. A wannan yanayin, duka lokacin aiki da bayanan da aka bincika an inganta su ta hanyar guga. Wannan yana nufin guga ya ba da gudummawa ba kawai ga aiki ba har ma don rage farashi.
Dalilin manyan bytes da aka duba idan aka kwatanta da misalin Athena CTAS shine cewa an rarraba dabi'u daban-daban a cikin wannan tebur. A cikin teburin guga na AWS Glue, an rarraba ƙimar akan fayiloli biyar. A cikin tebur bucketed na Athena CTAS, an rarraba ƙimar akan fayiloli huɗu. Ka tuna cewa ana rarraba layuka cikin guga ta amfani da aikin hash. Algorithm na Spark bucketing yana amfani da aikin zanta daban fiye da Hive, kuma a wannan yanayin, ya haifar da rarraba daban-daban a cikin fayilolin.
sharudda
Manne DynamicFrame baya goyan bayan bucket na asali. Kuna buƙatar amfani da Spark DataFrame maimakon DynamicFrame zuwa teburin guga.
Don bayani game da kyakkyawan aiki na AWS Glue ETL, koma zuwa Mafi kyawun ayyuka don daidaitawa AWS Glue don ayyukan Apache Spark.
Haɓaka shimfidar bayanan Iceberg tare da ɓoyayyun ɓarna
Apache Iceberg babban tsari ne na buɗaɗɗen tebur don manyan tebur na nazari, yana kawo aminci da sauƙi na teburin SQL zuwa babban bayanai. Kwanan nan, an sami buƙatu mai yawa don amfani da tebur na Apache Iceberg don cimma ƙarfin ci gaba kamar ciniki na ACID, tambayar balaguron lokaci, da ƙari.
A Iceberg, bucketing yana aiki daban da hanyar tebur Hive da muka gani zuwa yanzu. A cikin Iceberg, guga wani yanki ne na rarrabuwa, kuma ana iya amfani da shi ta amfani da canjin ɓangaren guga. Yadda kuke amfani da shi da sakamakon ƙarshe yayi kama da bucketing a cikin teburan Hive. Don ƙarin cikakkun bayanai game da canjin guga na Iceberg, koma zuwa Cikakkun Canjin Guga.
Cika matakai masu zuwa:
- Bude editan tambaya Athena.
- Gudun tambaya mai zuwa don ƙirƙirar tebur na Iceberg tare da ɓoyayyun ɓarna tare da guga:
Ya kamata bayananku suyi kama da hoton allo mai zuwa.

Akwai manyan fayiloli guda biyu: data da kuma metadata. Rage ƙasa zuwa data.
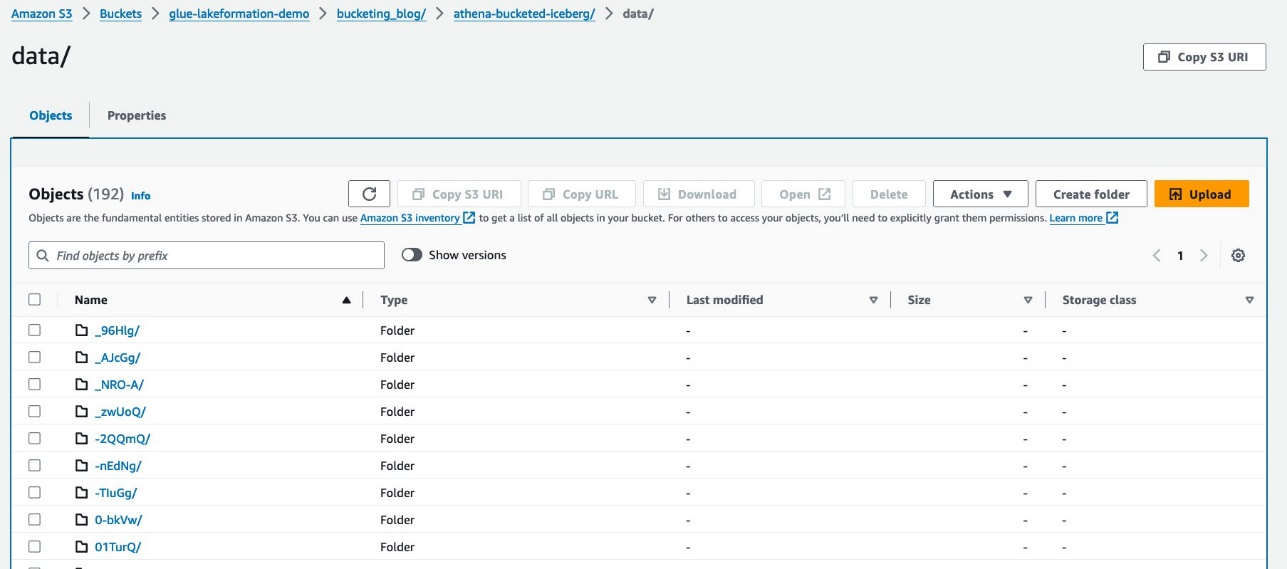
Kuna ganin prefixes bazuwar ƙarƙashin sa data babban fayil. Zaɓi na farko don duba cikakkun bayanai.
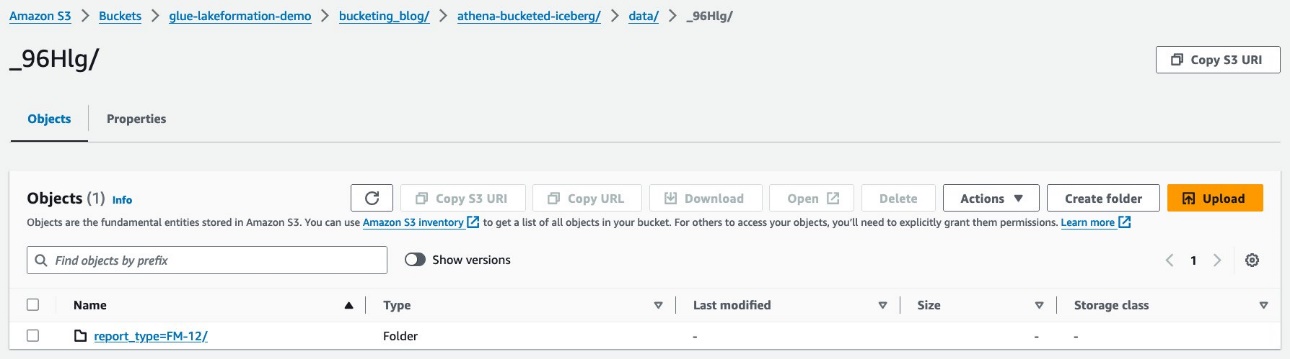
Kuna ganin babban matakin bangare bisa ga report_type shafi. Rage ƙasa zuwa mataki na gaba.

Za ka ga kashi na biyu-leki, bucketed tare da station shafi.
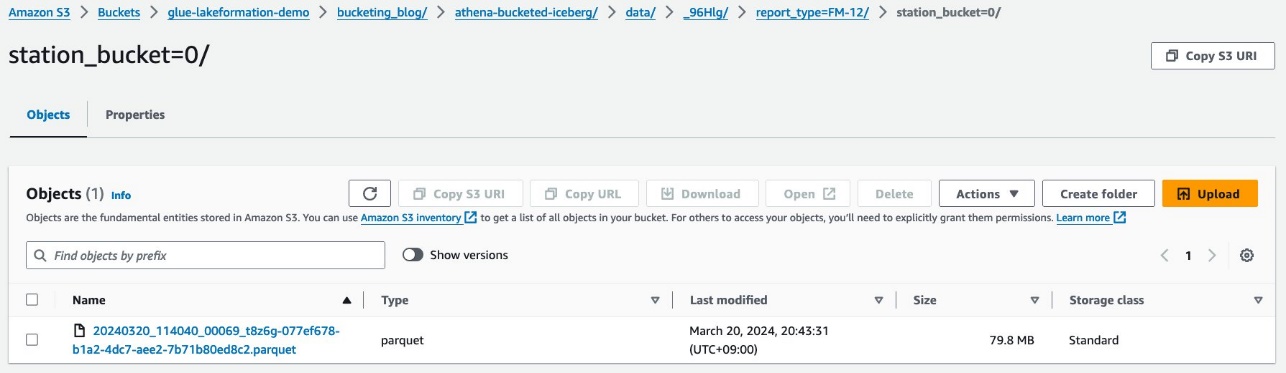
Fayilolin bayanan Parquet suna ƙarƙashin waɗannan manyan fayiloli.
- Tambayi tebirin bucket tare da bayanin mai zuwa:
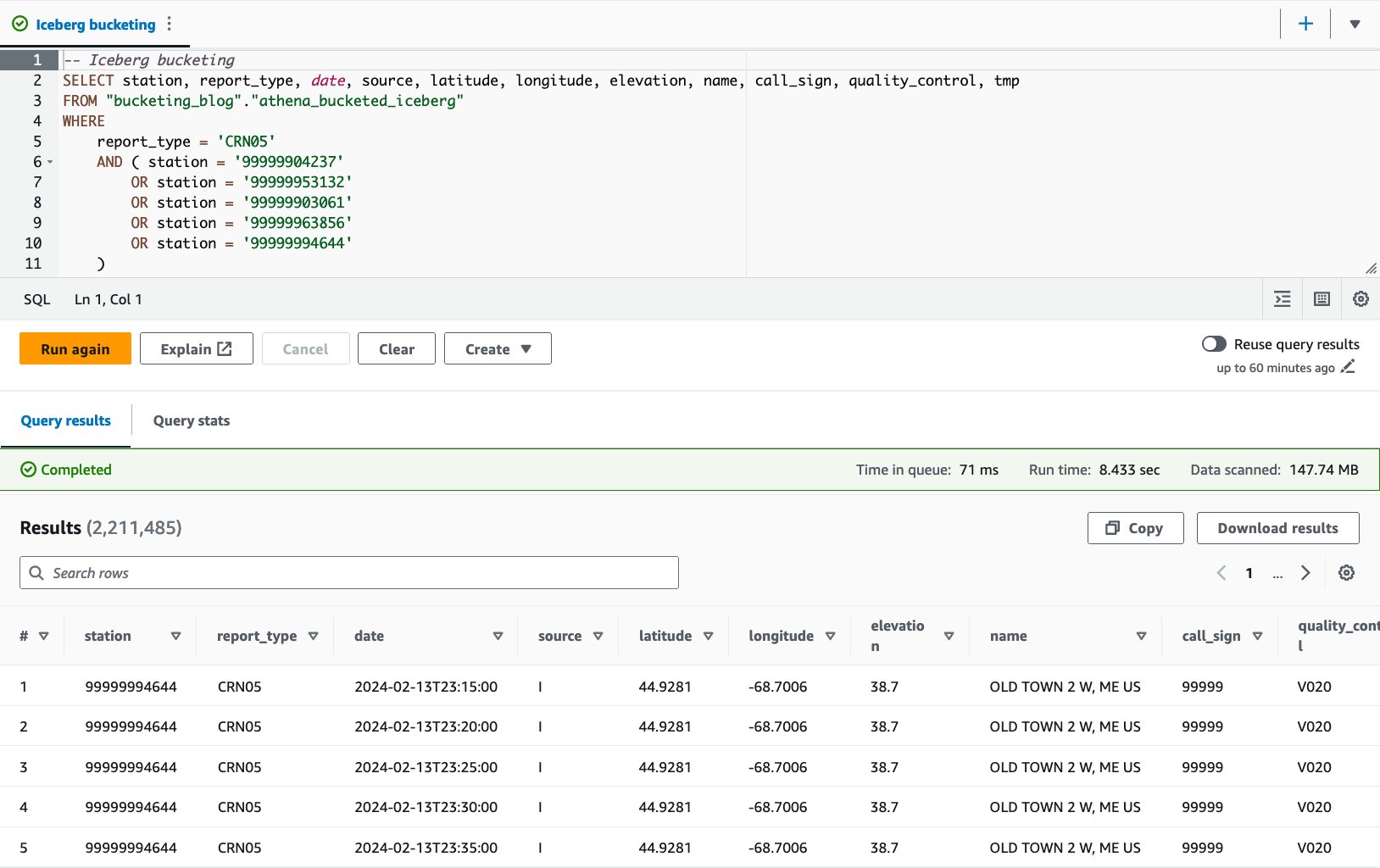
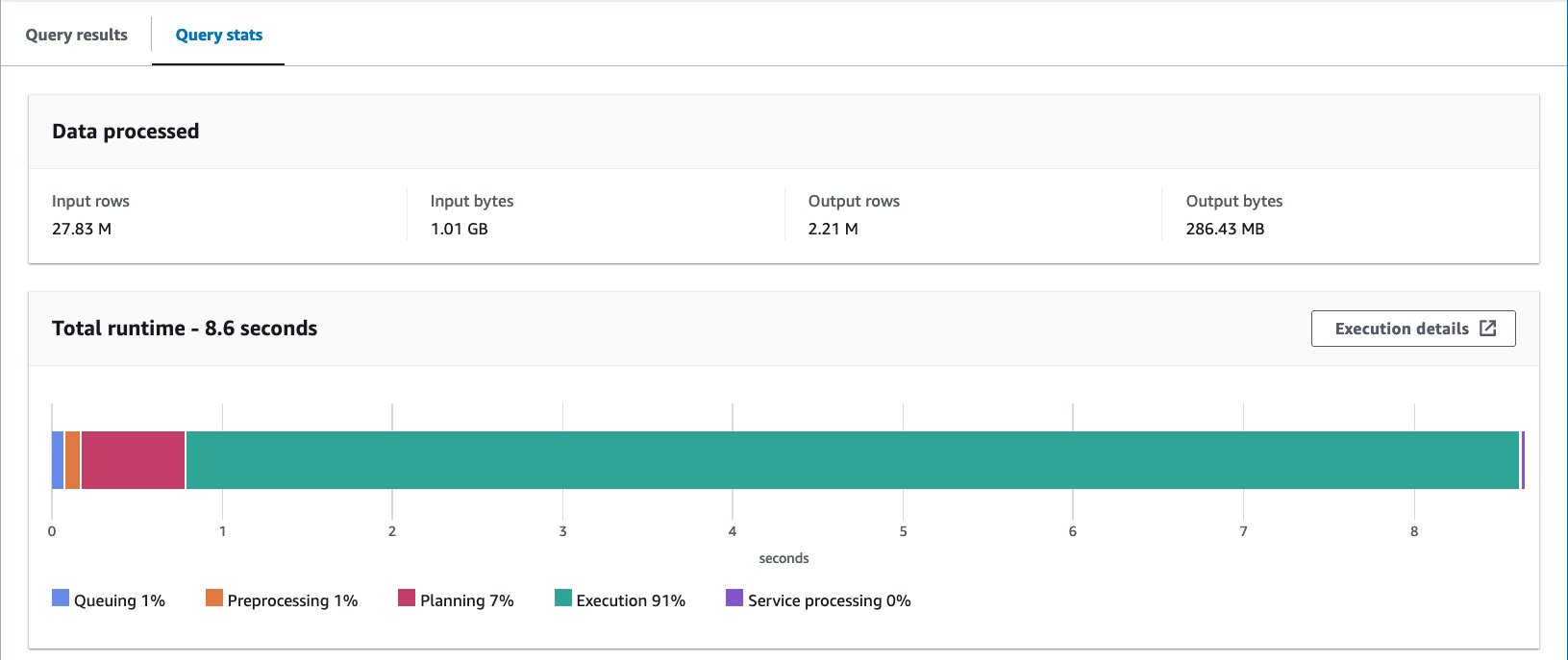
Tare da tebur mai bucket na Iceberg, matsakaicin lokacin gudu na tambayoyin 10 shine daƙiƙa 8.03, kuma ana bincika 148 MB na bayanai don dawo da bayanan miliyan 2.21. Wannan ba shi da inganci fiye da bucket tare da AWS Glue ko Athena, amma la'akari da fa'idodin fasalin Iceberg daban-daban, yana cikin kewayon karɓuwa.
results
Tebur mai zuwa yana taƙaita duk sakamakon.
| . | noaa_remote_original | athena_ba_bucketed | athena_bucket | manne_bucketed | athena_bucketed_iceberg |
| format | CSV | parquet | parquet | parquet | Iceberg (Parquet) |
| matsawa | n / a | Cirewa | Cirewa | Cirewa | Cirewa |
| An ƙirƙira ta hanyar | n / a | Athena CTAS | Athena CTAS | Farashin ETL | Athena CTAS tare da Iceberg |
| engine | n / a | Murna | Murna | Apache Spark | Apache Iceberg |
| Girman tebur (GB) | 155.8 | 5.0 | 5.0 | 5.8 | 5.0 |
| Adadin Abubuwan S3 | 53360 | 376 | 192 | 192 | 195 |
| An raba? | Ee amma ta hanya daban | A | A | A | A |
| An bucket? | A'a | A'a | A | A | A |
| Tsarin guga | n / a | n / a | hive | walƙiya | Iceberg |
| Yawan guga | n / a | n / a | 16 | 16 | 16 |
| Matsakaicin lokacin gudu (minti) | 29.178 | 10.950 | 7.815 | 7.089 | 8.030 |
| Girman da aka duba (MB) | 206640.0 | 358.6 | 69.1 | 87.8 | 147.7 |
tare da athena_bucketed, glue_bucketed, Da kuma athena_bucketed_iceberg, kun sami damar cimma burin latency na daƙiƙa 10. Tare da guga, kun ga raguwar 25-40% a cikin lokacin aiki da raguwar 60-85% a girman sikanin, wanda zai iya ba da gudummawa ga latency da haɓaka farashi.
Kamar yadda kuke gani daga sakamakon, duk da cewa rarrabawa yana ba da gudummawa sosai don rage duka lokacin aiki da girman binciken, guga kuma yana iya ba da gudummawa don rage su gaba.
Athena CTAS yana da sauƙi kuma yana sauri isa don kammala aikin bucketing. AWS Glue ETL ya fi sassauƙa kuma mai daidaitawa don cimma manyan lamuran amfani. Kuna iya zaɓar kowane hanya bisa ga buƙatun ku da amfani da harka, saboda kuna iya cin gajiyar guga ta kowane zaɓi.
Kammalawa
A cikin wannan sakon, mun nuna yadda ake haɓaka shimfidar bayanan teburin ku tare da rarrabawa da guga ta hanyar Athena CTAS da AWS Glue ETL. Mun nuna cewa guga yana ba da gudummawa ga haɓaka jinkirin tambaya da rage girman sikirin don ƙara haɓaka farashi. Mun kuma tattauna guga don tebur na Iceberg ta hanyar ɓoyayyiyar ɓoyayyiya.
Bucketing dabara ɗaya kawai don inganta shimfidar bayanai ta hanyar rage sikanin bayanai. Don inganta tsarin bayananku gaba ɗaya, muna ba da shawarar yin la'akari da wasu zaɓuɓɓuka kamar rarrabawa, ta amfani da tsarin fayil ɗin columnar, da matsawa tare da guga. Wannan na iya ba da damar bayanan ku don ƙara haɓaka aikin tambaya.
Barka da guga!
Game da Authors
 Takeshi Nakatani Babban Babban Mashawarcin Bayanai ne akan ƙungiyar Sabis na Ƙwararrun a Tokyo. Yana da shekaru 26 na gwaninta a cikin masana'antar IT, tare da gwaninta wajen tsara kayan aikin bayanai. A kwanakinsa na hutu, yana iya zama ɗan dutsen dutse ko mai tuka babur.
Takeshi Nakatani Babban Babban Mashawarcin Bayanai ne akan ƙungiyar Sabis na Ƙwararrun a Tokyo. Yana da shekaru 26 na gwaninta a cikin masana'antar IT, tare da gwaninta wajen tsara kayan aikin bayanai. A kwanakinsa na hutu, yana iya zama ɗan dutsen dutse ko mai tuka babur.
 Noritaka Sekiyama Babban Babban Babban Gine-ginen Bayanai akan ƙungiyar AWS Glue. Yana da alhakin gina kayan aikin software don taimakawa abokan ciniki. A lokacin hutunsa, yana jin daɗin yin keke da keken titinsa.
Noritaka Sekiyama Babban Babban Babban Gine-ginen Bayanai akan ƙungiyar AWS Glue. Yana da alhakin gina kayan aikin software don taimakawa abokan ciniki. A lokacin hutunsa, yana jin daɗin yin keke da keken titinsa.
- Ƙunshin Ƙarfafa SEO & Rarraba PR. Samun Girma a Yau.
- PlatoData.Network Tsaye Generative Ai. Karfafa Kanka. Shiga Nan.
- PlatoAiStream. Web3 Mai hankali. Ilmi Ya Faru. Shiga Nan.
- PlatoESG. Carbon, CleanTech, Kuzari, Muhalli, Solar, Gudanar da Sharar gida. Shiga Nan.
- PlatoHealth. Biotech da Clinical Trials Intelligence. Shiga Nan.
- Source: https://aws.amazon.com/blogs/big-data/optimize-data-layout-by-bucketing-with-amazon-athena-and-aws-glue-to-accelerate-downstream-queries/

