Rechercher des informations dans un référentiel de documents texte au format libre peut être comme chercher une aiguille dans une botte de foin. Une approche traditionnelle pourrait consister à utiliser le comptage de mots ou une autre analyse de base pour analyser les documents, mais grâce à la puissance de l'IA d'Amazon et des outils d'apprentissage automatique (ML), nous pouvons mieux comprendre le contenu.
Amazon comprendre est un service entièrement géré qui utilise le traitement du langage naturel (NLP) pour extraire des informations sur le contenu des documents. Amazon Comprehend développe des informations en reconnaissant les entités, les phrases clés, les sentiments, les thèmes et les éléments personnalisés d'un document. Amazon Comprehend peut créer de nouvelles informations basées sur la compréhension de la structure du document et des relations entre entités. Par exemple, avec Amazon Comprehend, vous pouvez analyser l'intégralité d'un référentiel de documents à la recherche d'expressions clés.
Amazon Comprehend permet aux experts non-ML d'effectuer facilement des tâches qui prennent normalement des heures. Amazon Comprehend élimine une grande partie du temps nécessaire au nettoyage, à la création et à la formation de votre propre modèle. Pour créer des modèles personnalisés plus approfondis en PNL ou dans tout autre domaine, Amazon Sage Maker vous permet de créer, former et déployer des modèles dans un flux de travail ML beaucoup plus conventionnel si vous le souhaitez.
Dans cet article, nous utilisons Amazon Comprehend et d'autres services AWS pour analyser et extraire de nouvelles informations à partir d'un référentiel de documents. Ensuite, nous utilisons Amazon QuickSight pour générer un visuel de nuage de mots simple mais puissant afin de repérer facilement des thèmes ou des tendances.
Présentation de la solution
Le diagramme suivant illustre l'architecture de la solution.
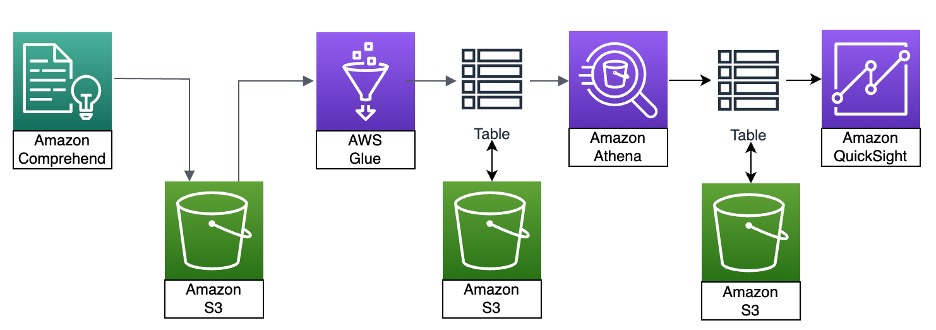
Pour commencer, nous rassemblons les données à analyser et les chargeons dans un Service de stockage simple Amazon (Amazon S3) dans un compte AWS. Dans cet exemple, nous utilisons des fichiers au format texte. Les données sont ensuite analysées par Amazon Comprehend. Amazon Comprehend crée une sortie au format JSON qui doit être transformée et traitée dans un format de base de données à l'aide de Colle AWS. Nous vérifions les données et extrayons des tableaux de données formatés spécifiques à l'aide Amazone Athéna pour une analyse QuickSight à l’aide d’un nuage de mots. Pour plus d'informations sur les visualisations, reportez-vous à Visualisation des données dans Amazon QuickSight.
Pré-requis
Pour cette procédure pas à pas, vous devez disposer des prérequis suivants:
Importer des données dans un compartiment S3
Téléchargez vos données dans un compartiment S3. Pour cet article, nous utilisons le texte au format UTF-8 de la Constitution américaine comme fichier d'entrée. Vous êtes ensuite prêt à analyser les données et à créer des visualisations.
Analyser les données à l'aide d'Amazon Comprehend
Il existe de nombreux types d'informations textuelles et images qui peuvent être traitées à l'aide d'Amazon Comprehend. En plus des fichiers texte, vous pouvez utiliser Amazon Comprehend pour une classification et une reconnaissance d'entité en une seule étape pour accepter les fichiers image, les fichiers PDF et les fichiers Microsoft Word en entrée, qui ne sont pas abordés dans cet article.
Pour analyser vos données, procédez comme suit :
- Sur la console Amazon Comprehend, choisissez Emplois d'analyse dans le volet de navigation.
- Selectionnez Créer une tâche d'analyse.
- Entrez un nom pour votre tâche.
- Pour Type d'analyse, choisissez Expressions-clés.
- Pour Langue¸ choisissez Anglais.
- Pour Emplacement des données d'entrée, spécifiez le dossier que vous avez créé comme condition préalable.
- Pour Emplacement des données de sortie, spécifiez le dossier que vous avez créé comme condition préalable.
- Selectionnez Créer un rôle IAM.
- Entrez un suffixe pour le nom du rôle.
- Selectionnez Créer un emploi.
Le travail s'exécutera et l'état sera affiché sur l'écran. Emplois d'analyse .
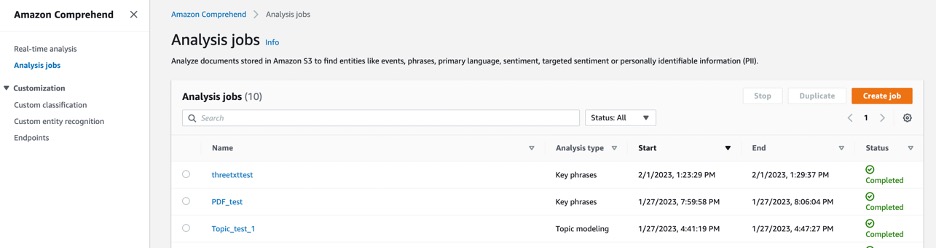
Attendez la fin du travail d'analyse. Amazon Comprehend créera un fichier et le placera dans le dossier de données de sortie que vous avez fourni. Le fichier est au format .gz ou GZIP.
Ce fichier doit être téléchargé et converti dans un format non compressé. Vous pouvez télécharger un objet à partir du dossier de données ou du compartiment S3 à l'aide de la console Amazon S3.
- Sur la console Amazon S3, sélectionnez l'objet et choisissez Télécharger. Si vous souhaitez télécharger l'objet dans un dossier spécifique, choisissez Télécharger sur le Actions menu.
- Après avoir téléchargé le fichier sur votre ordinateur local, ouvrez le fichier compressé et enregistrez-le sous forme de fichier non compressé.
Le fichier non compressé doit être téléchargé dans le dossier de sortie avant que le robot d'exploration AWS Glue puisse le traiter. Pour cet exemple, nous téléchargeons le fichier non compressé dans le même dossier de sortie que celui que nous utiliserons dans les étapes ultérieures.
- Sur la console Amazon S3, accédez à votre compartiment S3 et choisissez Téléchargement.
- Selectionnez Ajouter des fichiers.
- Choisissez les fichiers non compressés sur votre ordinateur local.
- Selectionnez Téléchargement.
Après avoir téléchargé le fichier, supprimez le fichier compressé d'origine.
- Sur la console Amazon S3, sélectionnez le compartiment et choisissez Supprimer.
- Confirmez le nom du fichier pour supprimer définitivement le fichier en entrant le nom du fichier dans la zone de texte.
- Selectionnez Supprimer des objets.
Cela laissera un fichier restant dans le dossier de sortie : le fichier non compressé.
Convertir les données JSON au format tableau à l'aide d'AWS Glue
Au cours de cette étape, vous préparez la sortie Amazon Comprehend à utiliser comme entrée dans Athena. La sortie Amazon Comprehend est au format JSON. Vous pouvez utiliser AWS Glue pour convertir JSON en une structure de base de données qui sera finalement lue par QuickSight.
- Sur la console AWS Glue, choisissez Rampeurs dans le volet de navigation.
- Selectionnez Créer un robot.
- Entrez un nom pour votre robot d'exploration.
- Selectionnez Suivant.
- Pour Vos données sont-elles déjà mappées aux tables Glue, sélectionnez Pas encore.
- Ajoutez une source de données.
- Pour Chemin S3, entrez l'emplacement du dossier de données de sortie Amazon Comprehend.
Assurez-vous d'ajouter la fin / au nom du chemin. AWS Glue recherchera le chemin du dossier pour tous les fichiers.
- Sélectionnez Explorer tous les sous-dossiers.
- Selectionnez Ajouter une source de données S3.
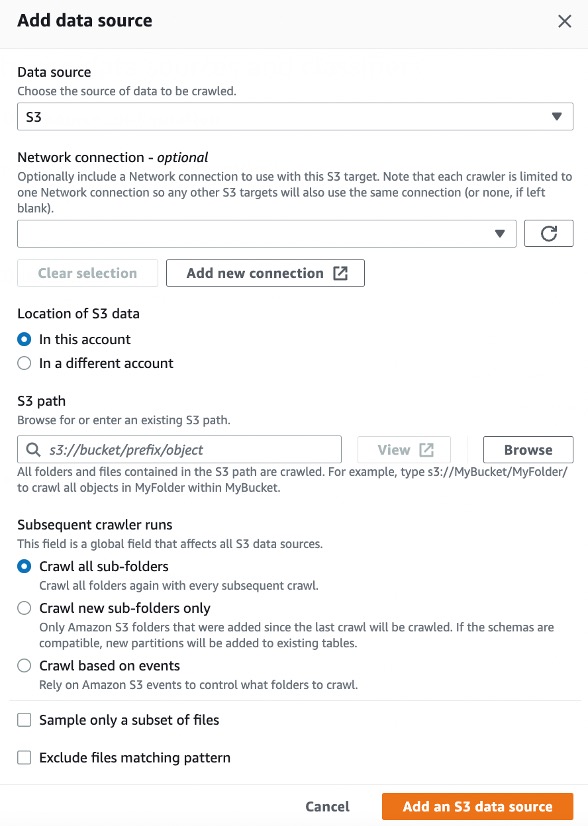
- Créer un nouveau Gestion des identités et des accès AWS (IAM) pour le robot d'exploration.
- Entrez un nom pour le rôle IAM.
- Selectionnez Mettre à jour le rôle IAM choisi pour être sûr que le nouveau rôle est attribué au robot.
- Selectionnez Suivant pour saisir les informations de sortie (base de données).
- Selectionnez Ajouter une base de données.
- Entrez un nom de base de données.
- Selectionnez Suivant.
- Selectionnez Créer un robot.
- Selectionnez Exécuter le robot pour exécuter le robot d'exploration.
Vous pouvez surveiller l'état du robot d'exploration sur la console AWS Glue.
Utilisez Athena pour préparer des tableaux pour QuickSight
Athena extraira les données des tables de base de données créées par le robot d'exploration AWS Glue pour fournir un format que QuickSight utilisera pour créer le nuage de mots.
- Sur la console Athena, choisissez Éditeur de requête dans le volet de navigation.
- Pour La source de données, choisissez AWSDataCatalogue.
- Pour Base de données, choisissez la base de données créée par le robot.
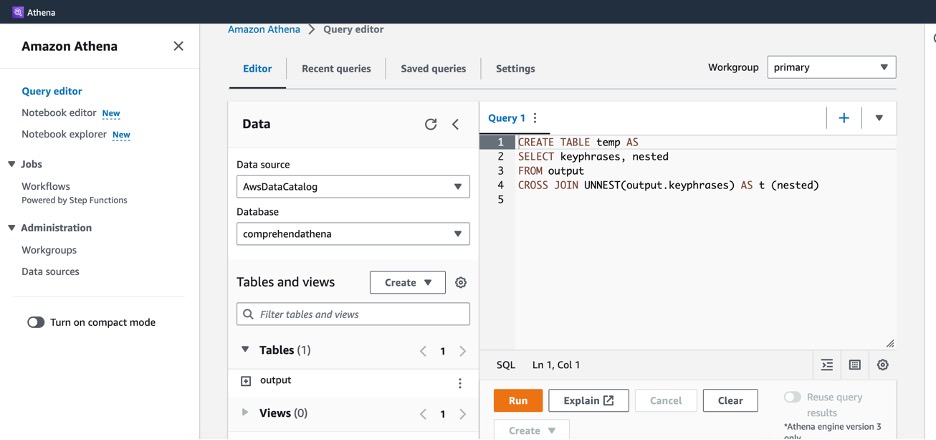
Pour créer une table compatible avec QuickSight, les données doivent être dissociées des tableaux.
- La première étape consiste à créer une base de données temporaire avec les données Amazon Comprehend pertinentes :
- La déclaration suivante se limite aux phrases d'au moins trois mots et regroupe par fréquence des phrases :
Utilisez QuickSight pour visualiser la sortie
Enfin, vous pouvez créer le résultat visuel de l'analyse.
- Sur la console QuickSight, choisissez Nouvelle analyse.
- Selectionnez Nouveau jeu de données.
- Pour Créer un jeu de données, choisissez À partir de nouvelles sources de données.
- Selectionnez Athena comme source de données.
- Entrez un nom pour la source de données et choisissez Créer une source de données.

- Selectionnez Visualiser.
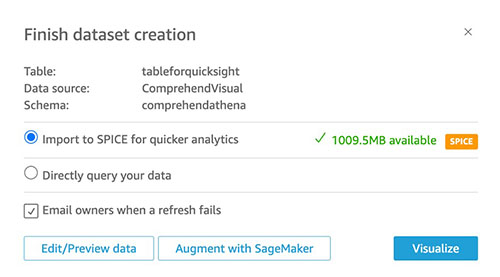
Assurez-vous que QuickSight a accès aux compartiments S3 où les tables Athena sont stockées.
- Sur la console QuickSight, choisissez l'icône du profil utilisateur et choisissez Gérer QuickSight.
![]()
- Selectionnez Sécurité et autorisations.

- Cherchez la rubrique Accès QuickSight aux services AWS.
En configurant l'accès aux services AWS, QuickSight peut accéder aux données de ces services. L'accès des utilisateurs et des groupes peut être contrôlé via les options.
- Vérifiez qu'Amazon S3 dispose d'un accès autorisé.
Vous pouvez maintenant créer le nuage de mots.
- Choisissez le nuage de mots sous Types visuels.
- Faites glisser le texte vers Par groupe et compte jusqu'à Taille.
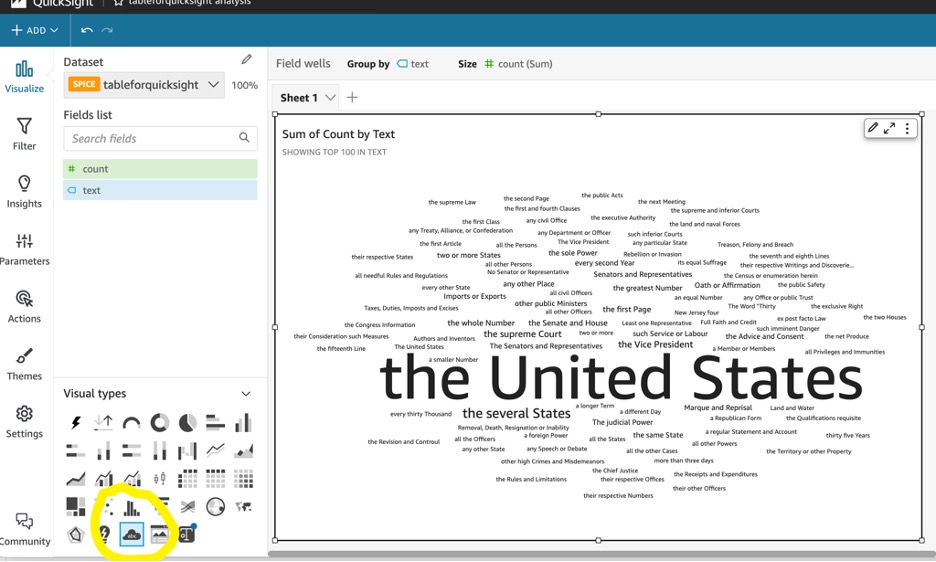
Choisissez le menu d'options (trois points) dans la visualisation pour accéder aux options d'édition. Par exemple, vous souhaiterez peut-être masquer le terme « autre » de l’affichage. Vous pouvez également modifier des éléments tels que le titre et le sous-titre de votre visuel. Pour télécharger le nuage de mots au format PDF, choisissez Télécharger dans la barre d'outils QuickSight.
Nettoyer
Pour éviter d'encourir des frais courants, supprimez toutes les données, processus ou ressources inutilisés fournis sur leur console de service respective.
Conclusion
Amazon Comprehend utilise le NLP pour extraire des informations sur le contenu des documents. Il développe des informations en reconnaissant les entités, les phrases clés, le langage, les sentiments et d'autres éléments communs dans un document. Vous pouvez utiliser Amazon Comprehend pour créer de nouveaux produits basés sur la compréhension de la structure des documents. Par exemple, avec Amazon Comprehend, vous pouvez analyser l'intégralité d'un référentiel de documents à la recherche d'expressions clés.
Cet article décrit les étapes de création d'un nuage de mots pour visualiser une analyse du contenu textuel d'Amazon Comprehend à l'aide des outils AWS et de QuickSight pour visualiser les données.
Restons en contact via la section commentaires !
À propos des auteurs
 Kris Gedman est le leader des ventes pour la vente au détail et les produits de grande consommation dans l'Est des États-Unis chez Amazon Web Services. Lorsqu'il ne travaille pas, il aime passer du temps avec ses amis et sa famille, surtout les étés à Cape Cod. Kris est un guerrier ninja temporairement à la retraite, mais il adore regarder et entraîner ses deux fils pour le moment.
Kris Gedman est le leader des ventes pour la vente au détail et les produits de grande consommation dans l'Est des États-Unis chez Amazon Web Services. Lorsqu'il ne travaille pas, il aime passer du temps avec ses amis et sa famille, surtout les étés à Cape Cod. Kris est un guerrier ninja temporairement à la retraite, mais il adore regarder et entraîner ses deux fils pour le moment.
 Clark Lefavour est un leader des architectes de solutions chez Amazon Web Services, qui soutient les entreprises clientes de la région Est. Clark est basé en Nouvelle-Angleterre et aime passer du temps à concevoir des recettes en cuisine.
Clark Lefavour est un leader des architectes de solutions chez Amazon Web Services, qui soutient les entreprises clientes de la région Est. Clark est basé en Nouvelle-Angleterre et aime passer du temps à concevoir des recettes en cuisine.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- GraphiquePrime. Élevez votre jeu de trading avec ChartPrime. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/visualize-an-amazon-comprehend-analysis-with-a-word-cloud-in-amazon-quicksight/

