Amazon EMRStudio est un environnement de développement intégré (IDE) qui permet aux data scientists et aux ingénieurs de données de développer, visualiser et déboguer des applications d'ingénierie et de science des données écrites en R, Python, Scala et PySpark. EMR Studio fournit des blocs-notes et des outils Jupyter entièrement gérés tels que Spark UI et YARN Timeline Server via les espaces de travail EMR Studio. Vous pouvez attacher un espace de travail EMR Studio à un cluster EMR, utiliser la puissance de calcul du cluster EMR et exécuter des tâches de science des données sur le cluster. Les données sont souvent stockées dans des lacs de données gérés par Formation AWS Lake, vous permettant d'appliquer un contrôle d'accès précis via un simple mécanisme d'octroi ou de révocation.
Nous sommes heureux de vous présenter rôles d'exécution pour les espaces de travail EMR Studio. Vous pouvez désormais définir un rôle d'exécution et l'attribuer à un cluster EMR lors de l'attachement d'un espace de travail EMR Studio. Les tâches sur le cluster EMR utiliseront ce rôle d'exécution pour accéder aux ressources AWS. Après avoir configuré un rôle d'exécution, vous pouvez également utiliser Lake Formation et appliquer un contrôle d'accès aux données précis pour les tâches soumises par l'espace de travail EMR Studio.
Auparavant, lors de l'association d'espaces de travail EMR Studio à des clusters EMR, tous les espaces de travail devaient utiliser le même Gestion des identités et des accès AWS (IAM), à savoir le rôle du cluster Cloud de calcul élastique Amazon (Amazon EC2). Par conséquent, tous les espaces de travail attachés au même cluster EMR disposaient du même accès aux données. Pour contrôler l'accès aux sources de données, chaque espace de travail EMR Studio devait utiliser un cluster EMR différent et plusieurs profils d'instance EMR étaient nécessaires.
À partir de la version d'Amazon EMR 6.11, vous pouvez désormais choisir un rôle d'exécution lorsque vous attachez un espace de travail EMR Studio à un cluster EMR. Ce rôle d'exécution limite l'accès au niveau de l'espace de travail. Vos tâches Apache Livy et Apache Spark exécutées à partir des espaces de travail EMR Studio auront l'autorisation d'accéder uniquement aux données et aux ressources autorisées par les stratégies attachées au rôle d'exécution. De plus, lorsque les données sont accessibles à partir de lacs de données gérés avec Lake Formation, vous pouvez appliquer un contrôle d'accès aux données plus précis à l'aide des autorisations de Lake Formation. Cela vous aide à réduire les frais opérationnels.
Dans cet article, nous montrons comment configurer les rôles d'exécution pour les espaces de travail EMR Studio et attacher un espace de travail à un cluster EMR avec des rôles d'exécution. Étant donné que les grandes entreprises utilisent généralement plusieurs comptes AWS et que bon nombre de ces comptes peuvent avoir besoin d'accéder à un lac de données géré par un seul compte AWS, notre exemple utilise deux comptes AWS. Nous expliquons comment contrôler l'accès aux rôles d'exécution EMR Studio, gérer l'accès aux données entre les comptes dans un lac de données via Lake Formation et appliquer les autorisations au niveau des tables et des colonnes pour les rôles d'exécution EMR.
Vue d'ensemble de la solution
Pour démontrer un contrôle d'accès précis, nous créons un exemple Colle AWS base de données nommée société et gérer l’autorisation de la base de données dans Lake Formation. La base de données se compose de deux tables distinctes :
- employés – Ce tableau stocke des informations sur les employés de l'entreprise, notamment le numéro d'identification de l'employé, le nom, le service et le salaire.
- Annonces – Ce tableau stocke des informations sur les produits vendus par l'entreprise, notamment l'identifiant du produit, le nom, la catégorie et le prix.
Pour démontrer le contrôle d’accès aux données, nous considérons les utilisateurs de données suivants :
- Alice, data scientist dans l'équipe commerciale – Elle doit avoir un accès en lecture seule à toutes les colonnes du
productstable et colonnes sélectionnées, y compris l'uID, le nom et le département dans leemployeestable - Bob, data scientist dans l'équipe des ressources humaines – Il doit avoir un accès en lecture seule à toutes les colonnes de
employeestable et ne devrait pas avoir accès auproductstable
Pour démontrer le partage de données entre comptes, nous considérons deux comptes :
- Compte producteur de données – Nous appelons ce compte
123456789012dans cet article. Ce compte gère les données brutes dans Service de stockage simple Amazon (Amazon S3) et écrit des données dans le lac de données. Lecompanyla base de données et les tables doivent être dans ce compte. - Compte consommateur de données – Nous appelons ce compte
111122223333dans cet article. Ce compte est accessible directement par les utilisateurs pour l'analyse des données et n'a pas d'accès en écriture aux données. Ce compte devrait être accessible par Alice et Bob.
L'architecture est implémentée comme suit :
- Le compte producteur de données gère un lac de données. Les données brutes sont stockées dans des compartiments S3 et cataloguées dans le catalogue de données AWS Glue.
- Lake Formation dans le compte producteur de données régit l'accès aux données via le catalogue de données et permet le partage de données entre comptes avec le compte consommateur de données.
- Lake Formation dans le compte consommateur de données régit l’accès entre comptes au lac de données au niveau de la table et les autorisations Lake Formation à granularité fine. Pour plus d'informations, reportez-vous à Méthodes de contrôle d'accès précis.
- Les espaces de travail EMR Studio dans le compte consommateur de données utilisent des rôles d'exécution lors de l'exécution de tâches sur un cluster EMR.
- Le cluster EMR se connecte à Glue Data Catalog dans le compte consommateur de données et interroge les données du lac de données via le partage de données entre comptes.
Le diagramme suivant illustre cette architecture.

Dans les sections suivantes, nous passons en revue les étapes permettant de partager des données entre comptes via Lake Formation, d'exécuter un espace de travail EMR Studio avec des rôles d'exécution et de démontrer un contrôle d'accès précis.
Pré-requis
Vous devez avoir les prérequis suivants :
Créer l'infrastructure dans le compte du producteur de données
Effectuez les étapes suivantes pour créer les ressources d'infrastructure :
- Connectez-vous au compte AWS du producteur de données (
123456789012). - Selectionnez Lancer la pile pour déployer un modèle CloudFormation pour créer les ressources nécessaires.

- Pour DataLakeBucketSuffixe, saisissez le suffixe du compartiment S3 utilisé par le lac de données. Le nom complet du compartiment S3 à créer sera
{AwsAccoundId}-{AwsRegion}-{DataLakeBucketSuffix}. - Une fois la pile CloudFormation créée, accédez au Sortie onglet de la pile et capturer la valeur de
DataLakeS3Bucketà utiliser à l'étape suivante.
Créez des fichiers de données et téléchargez-les sur Amazon S3 dans le compte du producteur de données
Configurez votre AWS CLI pour utiliser l'identité IAM avec l'autorisation de téléchargement vers DataLakeS3BucketName dans le compte AWS du producteur de données (123456789012), ou vous pouvez vous connecter à CloudShell à l'aide du Console de gestion AWS. Effectuez les étapes suivantes :
- Sur votre ordinateur local, déplacez-vous vers un répertoire de votre choix avec la commande cd, par exemple :
cd ~. - Exécutez le scénario avec
chmod 744 create_sample_data.sh && ./create_sample_data.sh <DataLakeS3BucketName>.
Le script créera un sous-répertoire tmp dans votre répertoire de travail actuel, créez les données de test dans des fichiers CSV et téléchargez les fichiers dans le DataLakeS3BucketName Godet S3.
Configurer Lake Formation dans le compte du producteur de données
Dans cette section, nous passons en revue les étapes de configuration de Lake Formation dans le compte du producteur de données.
Configurer les paramètres de version de partage de données entre comptes de Lake Formation
Lake Formation prend en charge plusieurs versions de partage de données. Pour cet article, nous utilisons la version 3. Pour en savoir plus sur les différences entre les versions de partage de données, reportez-vous à Mise à jour des paramètres de version de partage de données entre comptes. Pour modifier la version du partage de données, voir Pour activer la nouvelle version.
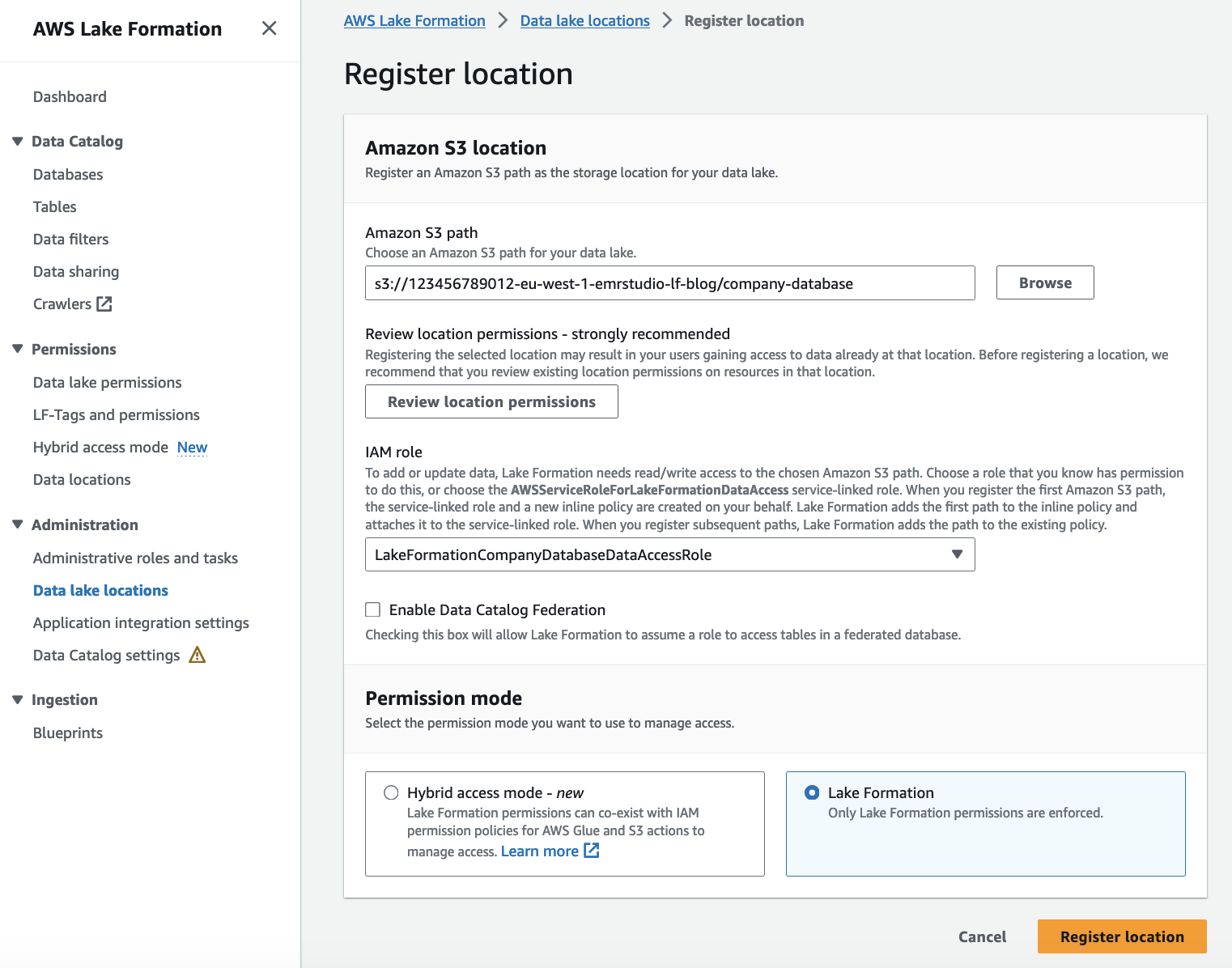
Enregistrez l'emplacement Amazon S3 comme emplacement du lac de données
Lorsque vous enregistrer un emplacement Amazon S3 avec Lake Formation, vous spécifiez un rôle IAM avec des autorisations de lecture/écriture sur cet emplacement. Après l'enregistrement, lorsque les clusters EMR demanderont l'accès à cet emplacement Amazon S3, Lake Formation fournira les informations d'identification temporaires du rôle fourni pour accéder aux données. Nous avons déjà créé le rôle LakeFormationCompanyDatabaseDataAccessRole à cet effet à l’étape précédente. Pour enregistrer l'emplacement Amazon S3 en tant qu'emplacement du lac de données, procédez comme suit :
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du producteur de données (
123456789012). - Dans le volet de navigation, choisissez Emplacements des lacs de données sous Administration.
- Selectionnez Enregistrer l'emplacement.
- Pour Chemin Amazon S3, Entrer
s3://<DataLakeS3BucketName>/company-database. - Pour Rôle IAM, Entrer
LakeFormationCompanyDatabaseDataAccessRole. - Pour Mode d'autorisation, sélectionnez Formation du lac.
- Selectionnez Enregistrer l'emplacement.
Révoquer les autorisations accordées à IAMAllowedPrincipals
La IAMAllowedPrincipals Le groupe inclut tous les utilisateurs et rôles IAM autorisés à accéder à vos ressources Data Catalog par vos stratégies IAM. À appliquer le modèle Lake Formation, nous devons le faire révoquer l'autorisation de IAMAllowedPrincipals en suivant les étapes suivantes :
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du producteur de données.
- Dans le volet de navigation, choisissez Autorisations du lac de données sous Autorisations.
- Filtrer les autorisations par
Database = companyainsi quePrinciple=IAMAllowedPrinciples. - Sélectionnez toutes les autorisations accordées au principal
IAMAllowedPrincipalset choisissez Révoquer.

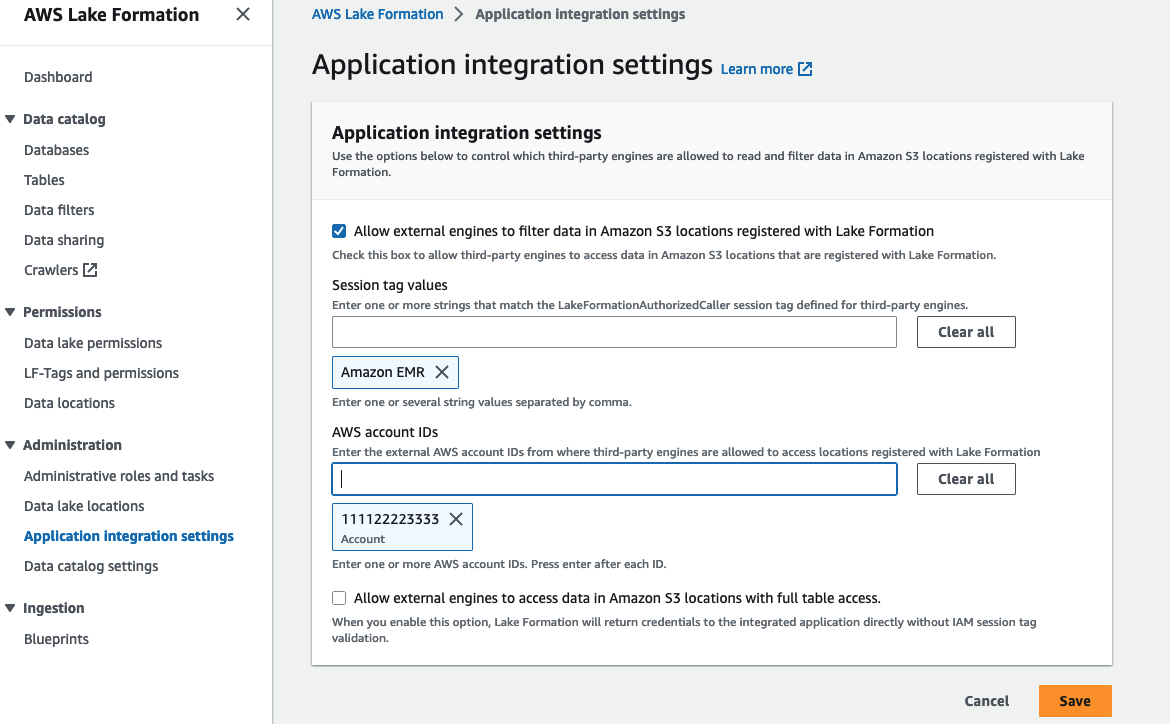
Configurer les paramètres d'intégration des applications
Pour appliquer les autorisations pour le cluster EMR, vous devez enregistrer une valeur de balise de session auprès de Lake Formation. Lake Formation utilise cette balise de session pour autoriser les appelants et donner accès au lac de données. Nous nous inscrivons Amazon EMR comme valeur de balise de session. Cette valeur sera référencée dans le configuration de sécurité lors de la création du cluster EMR.
Configurez la balise de session en procédant comme suit :
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du producteur de données.
- Selectionnez Paramètres d'intégration d'applications sous Administration dans le volet de navigation.
- Sélectionnez Autoriser les moteurs externes à filtrer les données dans les emplacements Amazon S3 enregistrés auprès de Lake Formation.
- Pour Valeurs des balises de session, Entrer
Amazon EMR. - Pour ID de compte AWS, saisissez l'ID du compte AWS du consommateur de données (
111122223333). - Selectionnez Épargnez.
Partager la base de données et les tables avec le compte consommateur de données
Nous accordons désormais des autorisations au compte AWS du consommateur de données, y compris des autorisations pouvant être accordées. Cela permet à l'administrateur du lac de données Lake Formation du compte du consommateur de données de contrôler l'accès aux données du compte.
Accorder des autorisations de base de données au compte consommateur de données
Effectuez les étapes suivantes:
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du producteur de données.
- Dans le volet de navigation, choisissez Bases de données.
- Sélectionnez la base de données
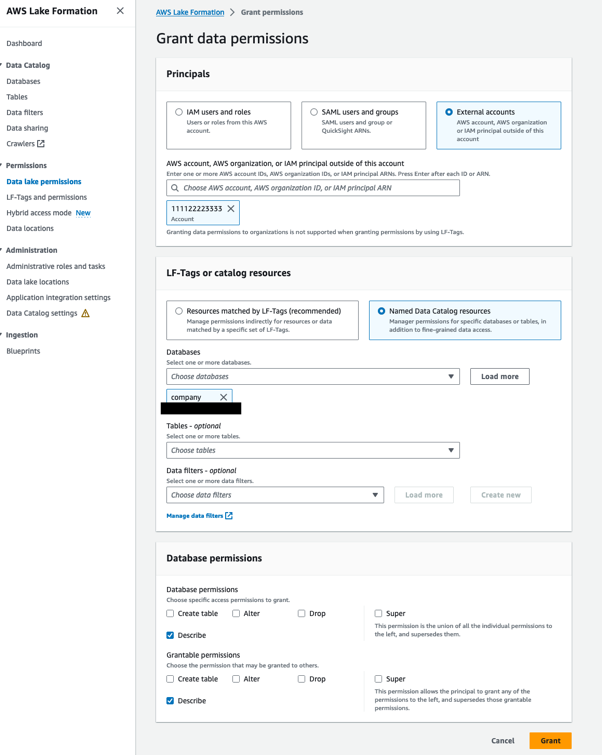
companyet sur le Actions menu, sous Permissions, choisissez Subvention. - Dans le Principes
section, sélectionnez Comptes externes et entrez le compte AWS du consommateur de données (
111122223333). - Dans le LF-Tags ou ressources de catalogue section, choisissez
companyen Bases de données. - Dans le Autorisations de base de données section, sélectionnez Décrire à la fois Autorisations de base de données ainsi que Autorisations accordables.
Cela permet à l'administrateur du lac de données du compte de consommateur de données de décrire la base de données et d'accorder des autorisations de description à d'autres mandataires du compte de consommateur de données.
- Selectionnez Subvention.
Accorder des autorisations de table au compte consommateur de données
Effectuez les étapes suivantes:
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du producteur de données.
- Dans le volet de navigation, choisissez Tables.
- Sélectionnez le
productstable, qui appartient aucompanybase de données, et sur le Actions menu, sous Permissions, choisissez Subvention. - Dans le Principes
section, sélectionnez Comptes externes et entrez dans le compte AWS du consommateur de données (
111122223333). - Dans le LF-Tags ou ressources de catalogue section, sélectionnez Ressources de catalogue de données nommées et précisez les éléments suivants :
- Pour Bases de données, choisissez
company. - Pour Tables, choisissez
productsainsi queemployees.
- Pour Bases de données, choisissez
- Dans le Droits de table section, choisissez Sélectionnez ainsi que Décrire à la fois Droits de table ainsi que Autorisations accordables.
Cela permet à l'administrateur du lac de données du compte de consommateur de données de sélectionner et de décrire les tables, et d'accorder des autorisations de sélection et de description de table à d'autres mandataires du compte de consommateur de données.
- Dans le Autorisations de données section, sélectionnez Tous les accès aux données.
- Selectionnez Subvention.

Nous avons maintenant terminé la configuration du compte producteur de données.
Configurer l'infrastructure dans le compte du consommateur de données
Effectuez les étapes suivantes pour créer les ressources d'infrastructure :
- Connectez-vous au compte du consommateur de données (
111122223333). - Selectionnez Lancer la pile pour déployer un modèle CloudFormation pour créer les ressources nécessaires.

- Pour Étiquette de version, saisissez l'étiquette de version Amazon EMR à utiliser, qui ne peut être que emr-6.11 ou version ultérieure.
- Pour Type d'instance, choisissez le type d'instance pour le cluster EMR, tel que r4.4xlarge.
- Pour EMRS3BucketNameSuffixe, saisissez le suffixe du compartiment S3 pour stocker les journaux du cluster EMR et les fichiers de bloc-notes EMR. Le nom complet du compartiment S3 à créer sera
{AWSAccoundId}-{AWSRegion}-{EMRS3BucketNameSuffix}. - Pour S3PathToInTransitCertificate, entrez le chemin S3 du fichier .zip qui contient les fichiers .pem utilisés pour le chiffrement en transit.
Pour obtenir des instructions sur la création du fichier .zip contenant les fichiers .pem et sur leur téléchargement dans votre compartiment S3, reportez-vous à Fournir des certificats pour chiffrer les données en transit avec le chiffrement Amazon EMR.
- Une fois la pile CloudFormation créée, accédez au Sortie onglet de la pile.
- Capturer la valeur de
EMRStudioLinkà utiliser pour vous connecter à EMR Studio.
Accepter le partage de ressources dans le compte consommateur de données
Pour accéder aux ressources partagées, vous devez d’abord accepter l’invitation.
- Ouvrez la console AWS RAM du compte consommateur de données avec l'identité IAM qui dispose d'un accès AWS RAM.
- Dans le volet de navigation, choisissez Partages de ressources sous Partagé avec moi.
Vous devriez voir deux partages de ressources en attente depuis le compte du producteur de données.
- Acceptez les deux partages de ressources.
Vous devriez voir le company base de données, employees tableau, et products tableau dans le catalogue de données.
Configurer Lake Formation dans le compte consommateur de données
Dans cette section, nous passons en revue les étapes de configuration de Lake Formation dans le compte consommateur de données.
Configurer les paramètres d'intégration des applications
Semblable à la configuration dans le compte du producteur de données, vous devez enregistrer Amazon EMR en tant que balise de session. Cette valeur est référencée dans le configuration de sécurité lors de la création du cluster EMR dans la pile CloudFormation.
Pour ce faire, procédez comme suit :
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du consommateur de données (
111122223333). - Selectionnez Paramètres d'intégration d'applications sous Administration dans le volet de navigation.
- Sélectionnez Autoriser les moteurs externes à filtrer les données dans les emplacements Amazon S3 enregistrés auprès de Lake Formation.
- Pour Valeurs des balises de session, Entrer
Amazon EMR. - Pour ID de compte AWS, saisissez l'ID du compte AWS du consommateur de données (
111122223333). - Selectionnez Épargnez.
Accorder des autorisations de description aux rôles d'exécution sur la base de données par défaut
Si vous n'avez pas de base de données par défaut dans Lake Formation ou si votre base de données par défaut dispose déjà d'autorisations à accorder à IAMAllowedPrinciples, vous pouvez sauter cette étape.
Amazon EMR vérifiera par défaut la base de données par défaut. Si vous disposez déjà d'une base de données par défaut dans votre Lake Formation, accordez l'autorisation de description aux rôles d'exécution sur la base de données par défaut en procédant comme suit :
- Ouvrez la console Lake Formation avec l'utilisateur administrateur du lac de données Lake Formation dans le compte du consommateur de données.
- Dans le volet de navigation, choisissez Bases de données.
- Sélectionnez la base de données par défaut, vérifiez que l'ID du compte propriétaire est le compte consommateur de données (
111122223333), et sur le Actions menu, choisissez Subvention. - Dans le Rubrique Principes, sélectionnez Utilisateurs et rôles IAM.
- Pour Utilisateurs et rôles IAM, choisissez
sales-runtime-roleainsi quehuman-resource-runtime-role. - Pour LF-Tags ou ressources de catalogue, sélectionnez Ressources de catalogue de données nommées et choisissez la valeur par défaut pour Bases de données.
- Dans le Autorisations de base de données section, pour Autorisations de base de données, choisissez Décrire.
- Selectionnez Subvention.
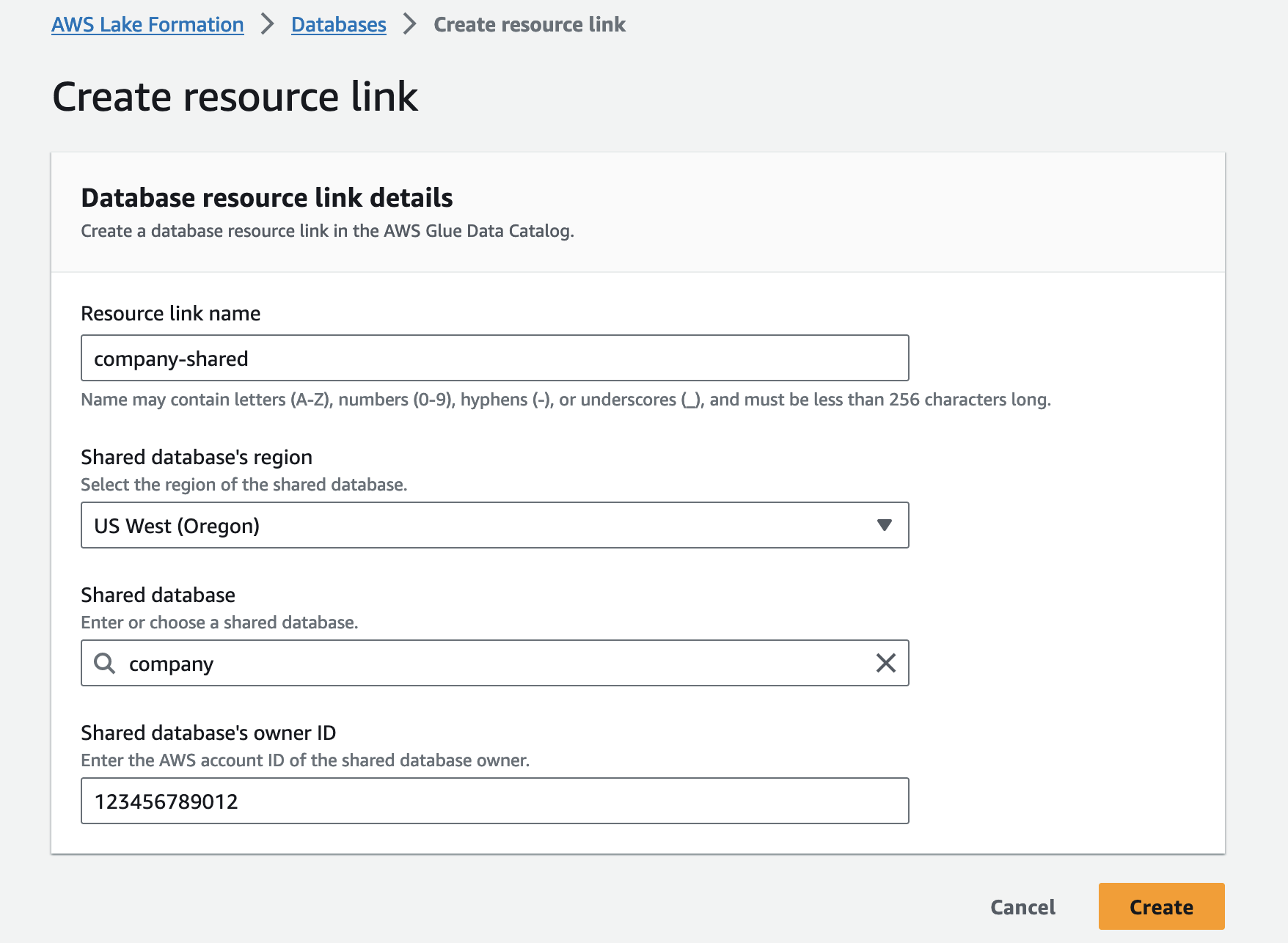
Créer un lien de ressource pour la base de données partagée
Pour accéder aux ressources de base de données et de table partagées par le compte AWS du producteur de données, vous devez créer un lien de ressource dans le compte AWS du consommateur de données. Un lien de ressource est un objet Data Catalog qui est un lien vers une base de données ou une table locale ou partagée. Après avoir créé un lien de ressource vers une base de données ou une table, vous pouvez utiliser le nom du lien de ressource partout où vous utiliseriez le nom de la base de données ou de la table. Au cours de cette étape, vous accordez l'autorisation sur les liens de ressources vers les principes de rôle d'exécution. Les rôles d'exécution accéderont ensuite aux données des bases de données partagées et des tables sous-jacentes via le lien de ressource.
Pour créer un lien de ressource, procédez comme suit :
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du consommateur de données.
- Dans le volet de navigation, choisissez Bases de données.
- Sélectionnez le
companybase de données, vérifiez que l'ID du compte propriétaire est le compte producteur de données (123456789012), et sur le Actions menu, choisissez Créer des liens de ressources. - Pour Nom du lien de la ressource, saisissez le nom du lien de ressource (par exemple,
company-shared). - Pour Région de la base de données partagée, choisissez la Région du
companybase de données. - Pour Base de données partagée, choisissez la base de données de l'entreprise.
- Pour ID du propriétaire de la base de données partagée, saisissez l'ID du compte du producteur de données (
123456789012). - Selectionnez Création.
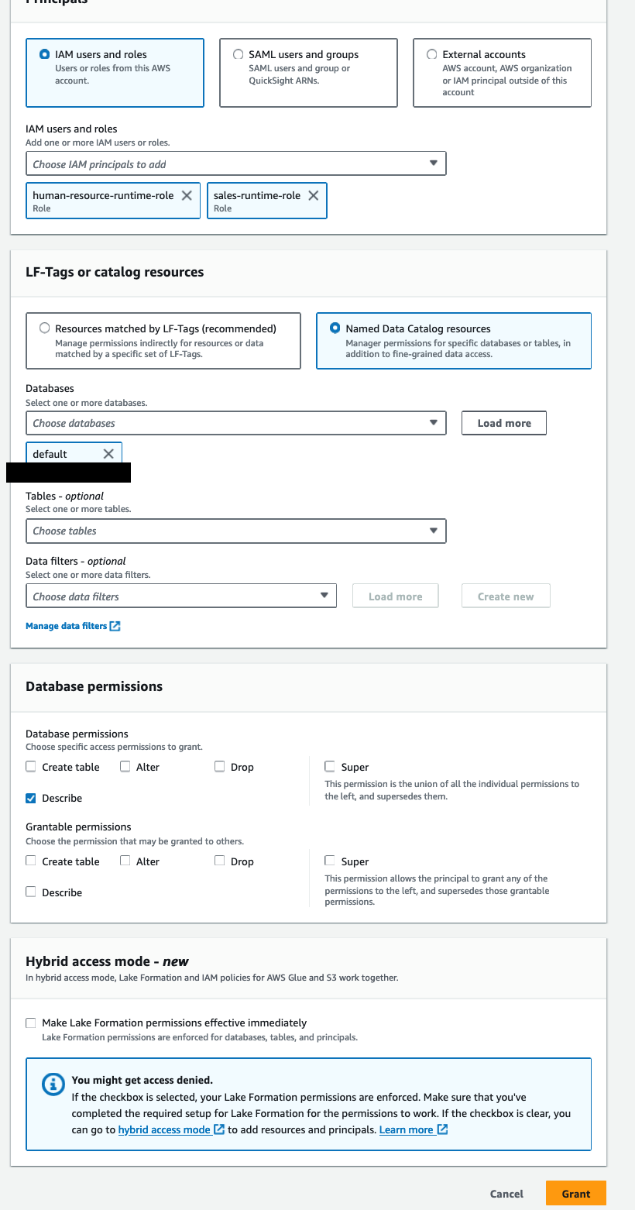
Accorder des autorisations sur le lien de ressource au principe du rôle d'exécution
Accordez des autorisations sur le lien de ressource vers sales-runtime-role et human-resource-runtime-role en procédant comme suit :
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du consommateur de données.
- Dans le volet de navigation, choisissez Bases de données.
- Sélectionnez le lien de ressource (
company-shared) et sur le Actions menu, choisissez Subvention. - Dans le Principes
section, sélectionnez Utilisateurs et rôles IAMet choisissez
sales-runtime-roleainsi quehuman-resource-runtime-role. - Dans le LF-Tags ou ressources de catalogue section, pour Bases de données, choisissez
company-shared. - Dans le Autorisations de lien de ressource section, sélectionnez Décrire.
Cela permet aux rôles d'exécution de décrire le lien de ressource. Nous n'effectuons aucune sélection pour les autorisations pouvant être accordées, car les rôles d'exécution ne devraient pas pouvoir accorder d'autorisations à d'autres principes.
- Selectionnez Subvention.
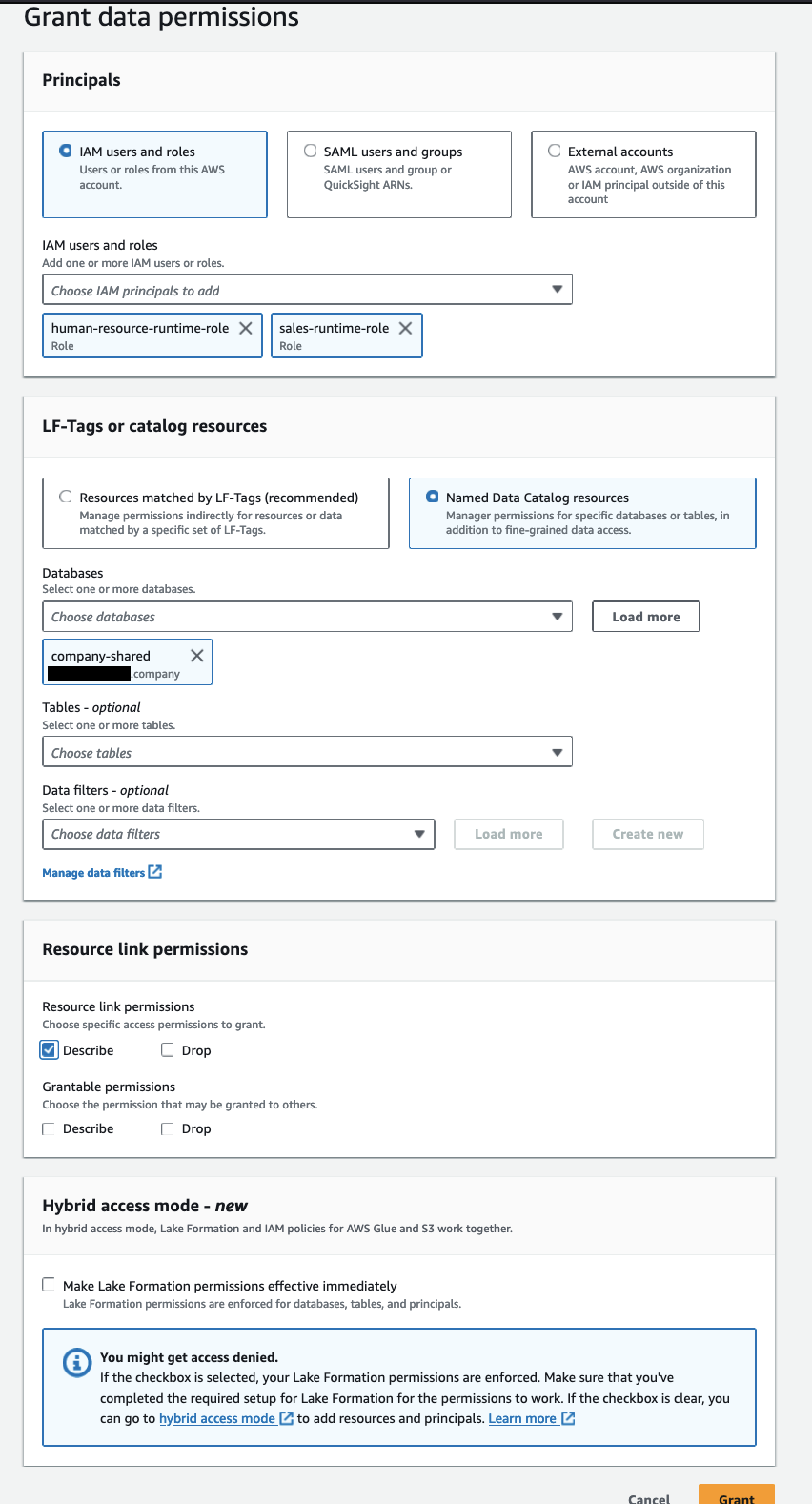
Accorder l'autorisation sur les tables au principe du rôle d'exécution
Vous devez accorder des autorisations sur les tables pour sales-runtime-role ainsi que human-resource-runtime-role pour autoriser l'accès aux données :
Human-resource-runtime-roledoit avoir des autorisations de description et de sélection sur toutes les colonnes duemployeestable, et aucune autorisation sur laproductstableau.Sales-runtime-roledevrait avoir des autorisations de sélection sur les colonnesuid,nameetdepartmentdans l'employeestableau, et décrivez et sélectionnez les autorisations sur toutes les colonnes duproductstableau.
Accorder l'autorisation sur la table des employés au rôle d'exécution des ressources humaines
Effectuez les étapes suivantes:
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du consommateur de données.
- Dans le volet de navigation, choisissez Bases de données.
- Sélectionnez le lien de ressource (
company-shared) et sur le Actions menu, choisissez Subvention conforme à l'objectif. - Dans le Rubrique Principes, sélectionnez Utilisateurs et rôles IAM, Puis choisissez
human-resource-runtime-role. - Dans le LF-Tags ou ressources de catalogue section, sélectionnez Ressources de catalogue de données nommées et précisez les éléments suivants :
- Pour Bases de données, choisissez
company. - Pour Tables¸ choisissez
employees.
- Pour Bases de données, choisissez
- Dans le Droits de table section, pour Droits de table, sélectionnez Décrire ainsi que Sélectionnez.
- Dans le Autorisations de données section, sélectionnez Tous les accès aux données.
- Selectionnez Subvention.

Accorder l'autorisation sur la table des employés au rôle d'exécution des ventes
Effectuez les étapes suivantes:
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du consommateur de données.
- Dans le volet de navigation, choisissez Bases de données.
- Sélectionnez le lien de ressource (
company-shared) et sur le Actions menu, choisissez Subvention conforme à l'objectif. - Dans le Rubrique Principes, sélectionnez Utilisateurs et rôles IAM, Puis choisissez
sales-runtime-role. - Dans le LF-Tags ou ressources de catalogue section, sélectionnez Ressources de catalogue de données nommées et précisez les éléments suivants :
- Pour Bases de données, choisissez
company. - Pour Tables, choisissez
employees.
- Pour Bases de données, choisissez
- Dans le Droits de table section, pour Droits de table, sélectionnez Sélectionnez.
- Dans le Autorisations de données section, sélectionnez Accès basé sur les colonnes.
- Sélectionnez Inclure les colonnes Et choisissez le
uid,nameetdepartmentcolonnes. - Selectionnez Subvention.
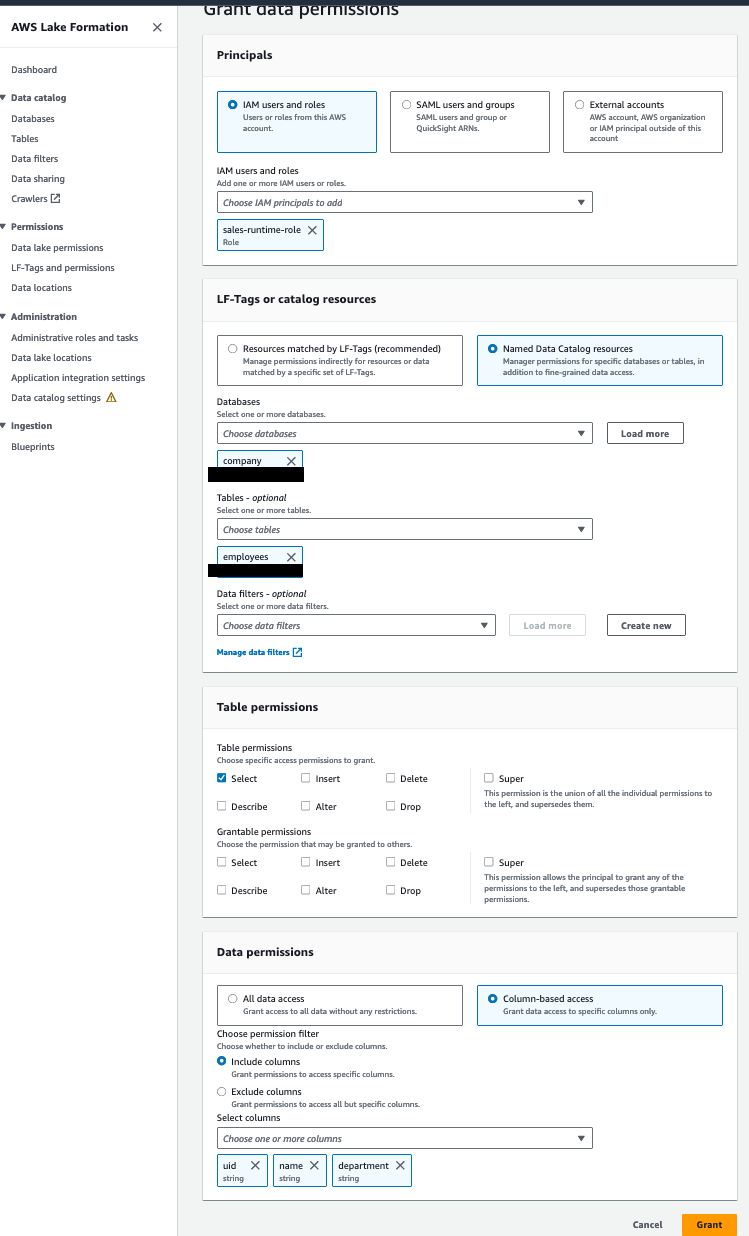
Accorder l'autorisation sur la table des produits au rôle d'exécution des ventes
Effectuez les étapes suivantes:
- Ouvrez la console Lake Formation avec l'administrateur du lac de données Lake Formation dans le compte du consommateur de données.
- Dans le volet de navigation, choisissez Bases de données.
- Sélectionnez le lien de ressource (
company-shared) et sur le Actions menu, choisissez Subvention conforme à l'objectif. - Dans le Rubrique Principes, sélectionnez Utilisateurs et rôles IAM, Puis choisissez
sales-runtime-role. - Dans le LF-Tags ou ressources de catalogue section, sélectionnez Ressources de catalogue de données nommées et précisez les éléments suivants :
- Pour Bases de données, choisissez
company. - Pour Tables, choisissez
products.
- Pour Bases de données, choisissez
- Dans le Droits de table section, pour Droits de table, sélectionnez Sélectionnez ainsi que Décrire.
- Dans le Autorisations de données section, sélectionnez Tous les accès aux données.
- Selectionnez Subvention.

Connectez-vous à EMR Studio et utilisez l'espace de travail EMR Studio
Changez de rôle à alice-role or bob-role sur la console en utilisant différents navigateurs Web pour tester l'accès. Ouvrez le EMRStudioLink URL de la sortie de la pile CloudFormation pour vous connecter à EMR Studio avec chaque rôle, puis procédez comme suit :
- Selectionnez Espaces de travail dans le volet de navigation et choisissez Créer un espace de travail.
- Entrez un nom et une description pour l'espace de travail.
- Selectionnez Créer un espace de travail.
Un nouvel onglet contenant JupyterLab s'ouvrira automatiquement lorsque l'espace de travail sera prêt. Activez les fenêtres contextuelles dans votre navigateur si nécessaire.
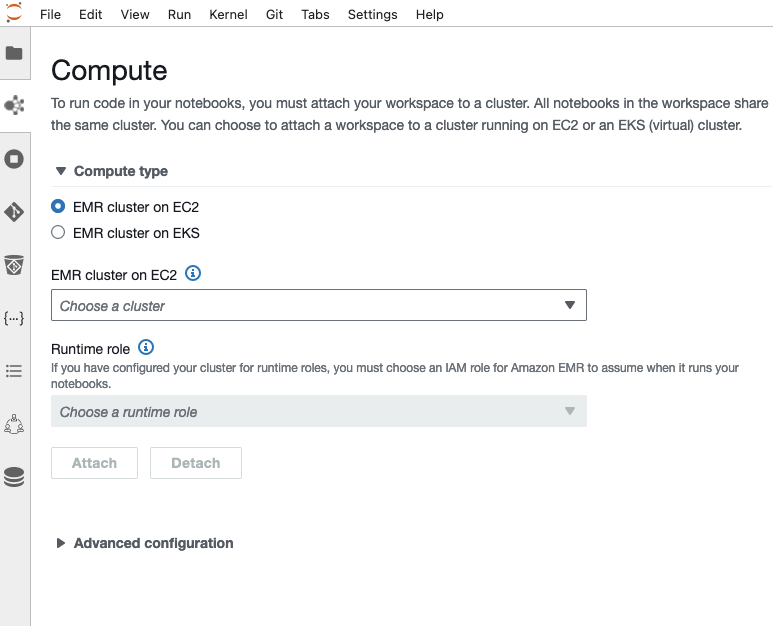
- Choisissez le calcul dans le volet de navigation pour associer l'espace de travail EMR Studio à un moteur de calcul.
- Sélectionnez Cluster EMR sur EC2 en Type de calcul.
- Choisissez l'ID de cluster EMR que vous avez créé avec AWS CloudFormation.
- Pour Rôle d'exécution, choisissez
sales-runtime-rolesi vous êtes connecté en tant quealice-role. Choisirhuman-resource-runtime-rolesi vous êtes connecté en tant quebob-role. - Selectionnez Attacher.
Exécutez le code dans l'espace de travail EMR Studio et vérifiez l'accès aux données
Exécutez le code suivant dans l'espace de travail EMR Studio avec un noyau PySpark après vous être connecté avec alice-role ou bob-role :
Vous devriez voir des résultats différents lorsque vous utilisez différents rôles.
Selon notre configuration d'accès aux données dans Lake Formation, Alice aura un accès complet aux données pour le products tableau. Elle peut visualiser toutes les colonnes sauf celle du salaire dans le employees tableau.
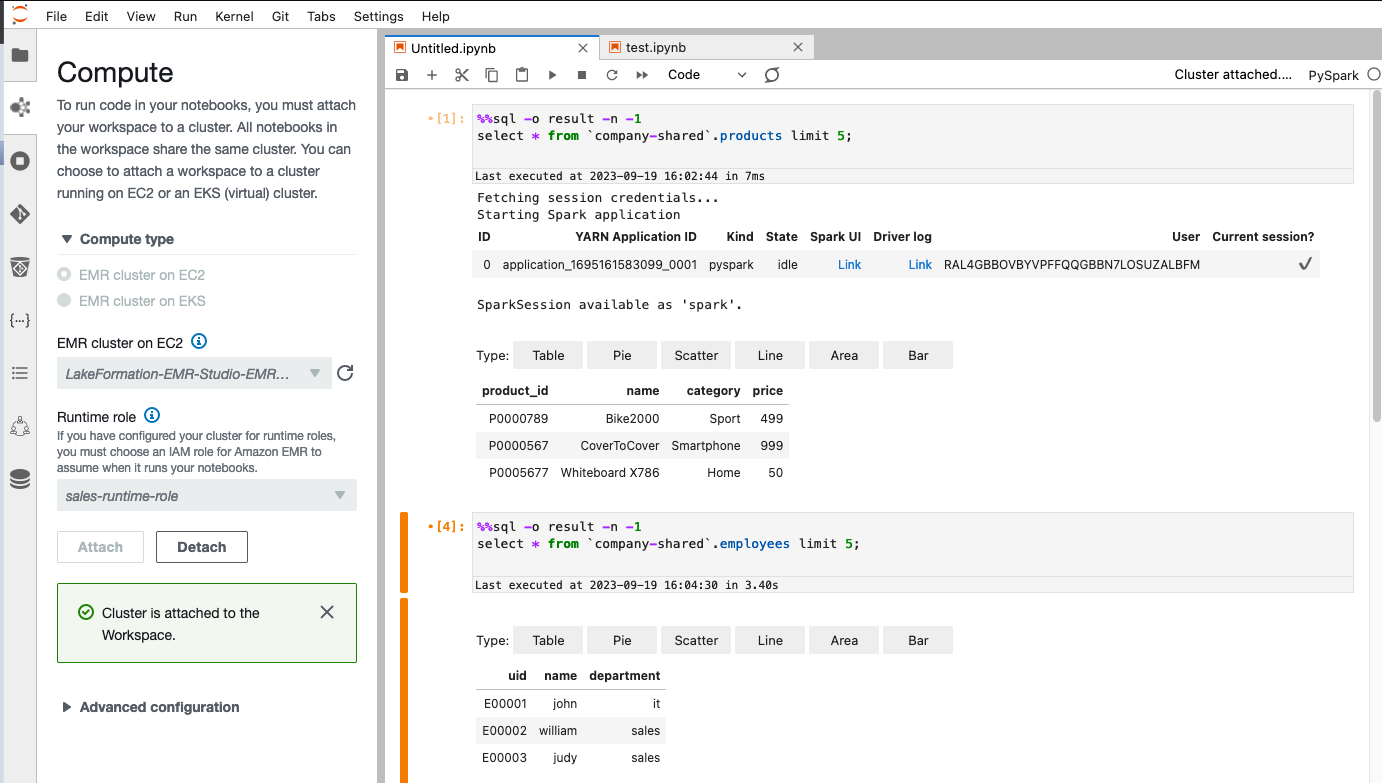
Pour Bob, selon notre configuration d'accès aux données dans Lake Formation, il aura un accès complet aux données du employees table, mais il n'a pas accès à la products tableau.

Nettoyer
Lorsque vous avez fini d'expérimenter cette solution, nettoyez vos ressources :
- Arrêtez et supprimez les espaces de travail EMR Studio créés dans le compte AWS du consommateur de données.
- Supprimez tout le contenu du compartiment S3
EMRS3Bucketdans le compte AWS du consommateur de données. - Supprimez la pile CloudFormation dans le compte AWS du consommateur de données.
- Supprimez tout le contenu du compartiment S3
DataLakeS3Bucketdans le compte AWS du producteur de données. - Supprimez la pile CloudFormation dans le compte AWS du producteur de données.
Conclusion
Cet article montre comment vous pouvez utiliser les rôles d'exécution pour vous connecter à un espace de travail EMR Studio avec Amazon EMR afin d'appliquer un contrôle d'accès aux données précis entre comptes avec Lake Formation. Nous avons également démontré comment plusieurs utilisateurs d'EMR Studio peuvent se connecter au même cluster EMR, chacun utilisant un rôle d'exécution doté d'autorisations correspondant à leur niveau individuel d'accès aux données.
Pour en savoir plus sur l'utilisation des espaces de travail EMR Studio avec Lake Formation, reportez-vous à Exécuter un espace de travail EMR Studio avec un rôle d'exécution. Nous vous encourageons à essayer cette nouvelle fonctionnalité et à nous contacter si vous avez des questions ou des commentaires !
À propos des auteurs
 Ashley Zhou est ingénieur en développement logiciel chez AWS. Elle s'intéresse à l'analyse de données et aux systèmes distribués.
Ashley Zhou est ingénieur en développement logiciel chez AWS. Elle s'intéresse à l'analyse de données et aux systèmes distribués.
 Srividya Parthasarathy est architecte Big Data senior au sein de l'équipe AWS Lake Formation. Elle aime créer des solutions d'analyse et de maillage de données sur AWS et les partager avec la communauté.
Srividya Parthasarathy est architecte Big Data senior au sein de l'équipe AWS Lake Formation. Elle aime créer des solutions d'analyse et de maillage de données sur AWS et les partager avec la communauté.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/use-iam-runtime-roles-with-amazon-emr-studio-workspaces-and-aws-lake-formation-for-cross-account-fine-grained-access-control/

