Cet article est co-écrit avec Andries Engelbrecht et Scott Teal de Snowflake.
Les entreprises évoluent constamment et les responsables des données sont chaque jour mis au défi de répondre à de nouvelles exigences. Pour de nombreuses entreprises et grandes organisations, il n’est pas possible de disposer d’un moteur ou d’un outil de traitement unique pour répondre aux diverses exigences commerciales. Ils comprennent qu'une approche universelle ne fonctionne plus et reconnaissent l'intérêt d'adopter des outils évolutifs et flexibles et des formats de données ouverts pour prendre en charge l'interopérabilité dans une architecture de données moderne afin d'accélérer la fourniture de nouvelles solutions.
Les clients utilisent AWS et Snowflake pour développer des architectures de données spécialement conçues qui fournissent les performances requises pour les cas d'utilisation modernes de l'analyse et de l'intelligence artificielle (IA). La mise en œuvre de ces solutions nécessite le partage de données entre des magasins de données spécialement conçus. C'est pourquoi Snowflake et AWS proposent une prise en charge améliorée d'Apache Iceberg afin de permettre et de faciliter l'interopérabilité des données entre les services de données.
Apache Iceberg est un format de table open source qui offre fiabilité, simplicité et hautes performances pour les grands ensembles de données avec une intégrité transactionnelle entre différents moteurs de traitement. Dans cet article, nous discutons des points suivants :
- Avantages des tables Iceberg pour les lacs de données
- Deux modèles architecturaux pour partager les tables Iceberg entre AWS et Snowflake :
- Gérez vos tables Iceberg avec Colle AWS Catalogue de données
- Gérez vos tables Iceberg avec Snowflake
- Le processus de conversion des tables de lacs de données existantes en tables Iceberg sans copier les données
Maintenant que vous avez une compréhension approfondie des sujets, examinons chacun d’eux en détail.
Avantages d'Apache Iceberg
Apache Iceberg est un format de table de données distribué, piloté par la communauté, sous licence Apache 2.0 et 100 % open source qui permet de simplifier le traitement des données sur de grands ensembles de données stockés dans des lacs de données. Les ingénieurs de données utilisent Apache Iceberg car il est rapide, efficace et fiable à toute échelle et conserve des enregistrements de l'évolution des ensembles de données au fil du temps. Apache Iceberg propose des intégrations avec des frameworks de traitement de données populaires tels qu'Apache Spark, Apache Flink, Apache Hive, Presto, etc.
Les tables Iceberg conservent des métadonnées pour extraire de grandes collections de fichiers, fournissant des fonctionnalités de gestion des données, notamment le voyage dans le temps, la restauration, le compactage des données et l'évolution complète du schéma, réduisant ainsi les frais de gestion. Développé à l'origine chez Netflix avant d'être open source pour l'Apache Software Foundation, Apache Iceberg était une conception vierge visant à résoudre les défis courants des lacs de données tels que expérience utilisateur, fiabilité et performances, et est désormais soutenu par une solide communauté de développeurs axés sur l'amélioration continue et l'ajout de nouvelles fonctionnalités au projet, répondant aux besoins réels des utilisateurs et leur fournissant des options.
Lacs de données transactionnels construits sur AWS et Snowflake
Snowflake propose diverses intégrations pour les tables Iceberg avec plusieurs options de stockage, notamment Amazon S3, et plusieurs options de catalogue, notamment Catalogue de données AWS Glue ainsi que Flocon. AWS fournit des intégrations pour divers services AWS avec les tables Iceberg également, y compris AWS Glue Data Catalog pour le suivi des métadonnées des tables. La combinaison de Snowflake et d'AWS vous offre plusieurs options pour créer un lac de données transactionnelles pour des cas d'utilisation analytiques et autres tels que le partage de données et la collaboration. En ajoutant une couche de métadonnées aux lacs de données, vous obtenez une meilleure expérience utilisateur, une gestion simplifiée ainsi que des performances et une fiabilité améliorées sur de très grands ensembles de données.
Gérez votre table Iceberg avec AWS Glue
Vous pouvez utiliser AWS Glue pour ingérer, cataloguer, transformer et gérer les données sur Service de stockage simple Amazon (Amazon S3). AWS Glue est un service d'intégration de données sans serveur qui vous permet de créer, d'exécuter et de surveiller visuellement des pipelines d'extraction, de transformation et de chargement (ETL) pour charger des données dans vos lacs de données au format Iceberg. Avec AWS Glue, vous pouvez découvrir et vous connecter à plus de 70 sources de données diverses et gérer vos données dans un catalogue de données centralisé. Snowflake s'intègre à AWS Glue Data Catalog pour accéder au catalogue de tables Iceberg et aux fichiers sur Amazon S3 pour les requêtes analytiques. Cela améliore considérablement les performances et les coûts de calcul par rapport à tables externes sur Snowflake, car les métadonnées supplémentaires améliorent l'élagage des plans de requête.
Vous pouvez utiliser cette même intégration pour profiter des fonctionnalités de partage de données et de collaboration de Snowflake. Cela peut s'avérer très puissant si vous disposez de données dans Amazon S3 et devez activer le partage de données Snowflake avec d'autres unités commerciales, partenaires, fournisseurs ou clients.
Le diagramme d'architecture suivant fournit un aperçu général de ce modèle.
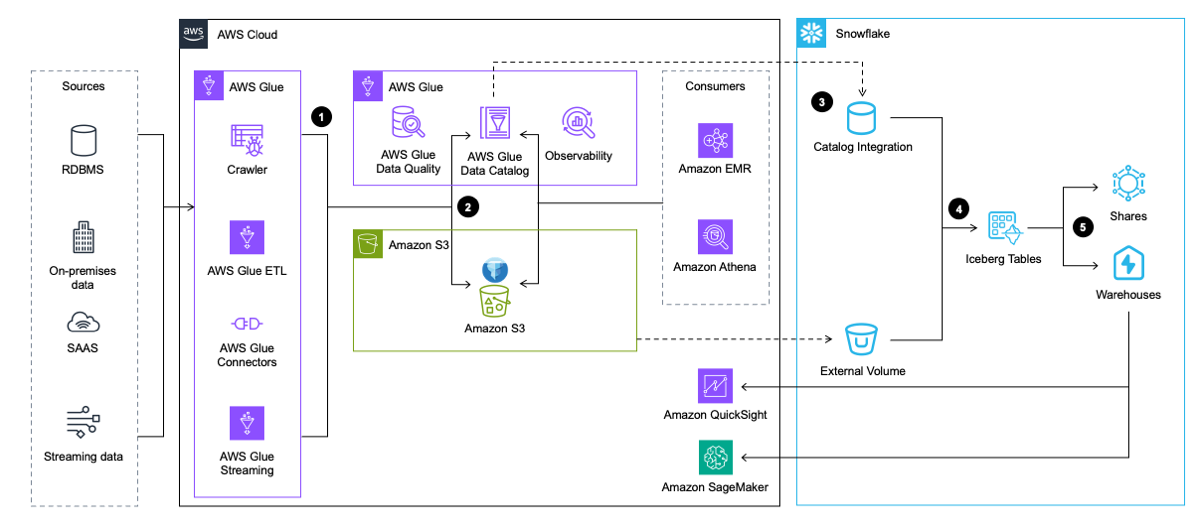
Le workflow comprend les étapes suivantes:
- AWS Glue extrait les données des applications, des bases de données et des sources de streaming. AWS Glue le transforme ensuite et le charge dans le lac de données d'Amazon S3 au format de table Iceberg, tout en insérant et en mettant à jour les métadonnées sur la table Iceberg dans AWS Glue Data Catalog.
- Le robot d'exploration AWS Glue génère et met à jour les métadonnées de la table Iceberg et les stocke dans le catalogue de données AWS Glue pour les tables Iceberg existantes sur un lac de données S3.
- Snowflake s'intègre à AWS Glue Data Catalog pour récupérer l'emplacement de l'instantané.
- En cas de requête, Snowflake utilise l'emplacement de l'instantané d'AWS Glue Data Catalog pour lire les données de la table Iceberg dans Amazon S3.
- Snowflake peut interroger les formats de table Iceberg et Snowflake. Tu peux partager des données pour la collaboration avec un ou plusieurs comptes dans la même région Snowflake. Vous pouvez également utiliser les données dans Snowflake pour visualisation en utilisant Amazon QuickSight, ou utilisez-le pour à des fins d’apprentissage automatique (ML) et d’intelligence artificielle (IA) avec Amazon Sage Maker.
Gérez votre table Iceberg avec Snowflake
Un deuxième modèle assure également l'interopérabilité entre AWS et Snowflake, mais implémente des pipelines d'ingénierie de données pour l'ingestion et la transformation vers Snowflake. Dans ce modèle, les données sont chargées dans les tables Iceberg par Snowflake via des intégrations avec des services AWS comme AWS Glue ou via d'autres sources comme Snowpipe. Snowflake écrit ensuite les données directement sur Amazon S3 au format Iceberg pour un accès en aval par Snowflake et divers services AWS, et Snowflake gère le catalogue Iceberg qui suit les emplacements des instantanés dans les tables auxquelles les services AWS peuvent accéder.
Comme pour le modèle précédent, vous pouvez utiliser des tables Iceberg gérées par Snowflake avec le partage de données Snowflake, mais vous pouvez également utiliser S3 pour partager des ensembles de données dans les cas où une partie n'a pas accès à Snowflake.
Le diagramme d'architecture suivant donne un aperçu de ce modèle avec les tables Iceberg gérées par Snowflake.
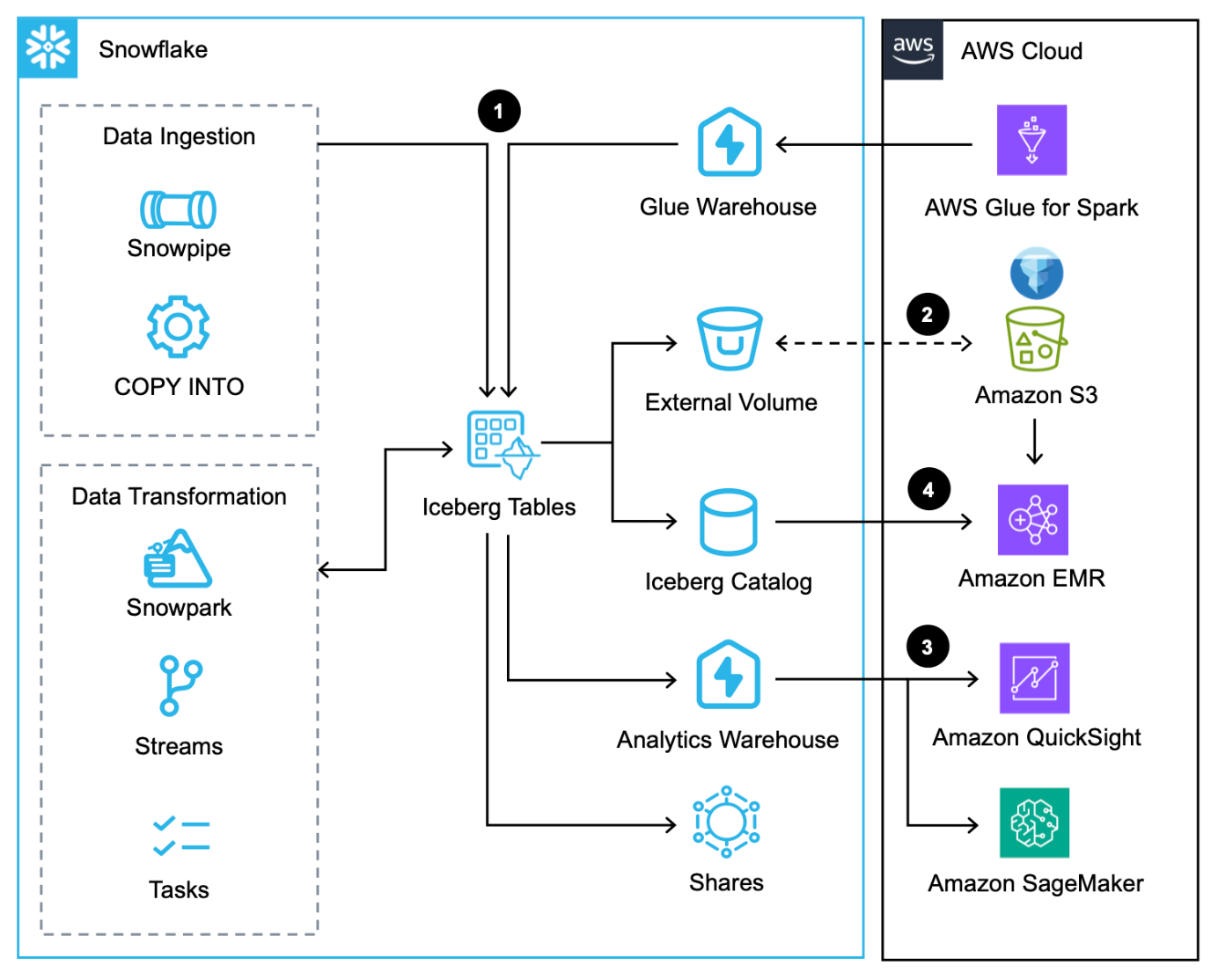
Ce flux de travail comprend les étapes suivantes :
- En plus du chargement des données via le commande COPIER, Pipe à neigeet le connecteur natif Snowflake pour AWS Glue, vous pouvez intégrer des données via le Snowflake Partage de données.
- Snowflake écrit les tables Iceberg sur Amazon S3 et met automatiquement à jour les métadonnées à chaque transaction.
- Les tables Iceberg dans Amazon S3 sont interrogées par Snowflake pour les charges de travail analytiques et ML à l'aide de services tels que QuickSight et SageMaker.
- Les services Apache Spark sur AWS peuvent accéder aux emplacements d'instantanés depuis Snowflake via un SDK Snowflake Iceberg Catalog et analysez directement les fichiers de la table Iceberg dans Amazon S3.
Comparer les solutions
Ces deux modèles mettent en évidence les options disponibles aujourd'hui pour les data personas pour maximiser l'interopérabilité de leurs données entre Snowflake et AWS à l'aide d'Apache Iceberg. Mais quel modèle est idéal pour votre cas d’utilisation ? Si vous utilisez déjà AWS Glue Data Catalog et que vous n'avez besoin que de Snowflake pour les requêtes de lecture, le premier modèle peut intégrer Snowflake à AWS Glue et Amazon S3 pour interroger les tables Iceberg. Si vous n'utilisez pas déjà AWS Glue Data Catalog et que vous avez besoin de Snowflake pour effectuer des lectures et des écritures, le deuxième modèle est probablement une bonne solution qui permet de stocker et d'accéder aux données d'AWS.
Étant donné que les lectures et les écritures fonctionneront probablement table par table plutôt que sur l’ensemble de l’architecture de données, il est conseillé d’utiliser une combinaison des deux modèles.
Migrer les lacs de données existants vers un lac de données transactionnel à l'aide d'Apache Iceberg
Vous pouvez convertir les tables de lacs de données existantes basées sur Parquet, ORC et Avro sur Amazon S3 au format Iceberg pour bénéficier des avantages de l'intégrité transactionnelle tout en améliorant les performances et l'expérience utilisateur. Il existe plusieurs options de migration de table Iceberg (INSTANTANÉ, ÉMIGRERet AJOUTER DES FICHIERS) pour migrer sur place les tables de lacs de données existantes au format Iceberg, ce qui est préférable à la réécriture de tous les fichiers de données sous-jacents – un effort coûteux et chronophage avec de grands ensembles de données. Dans cette section, nous nous concentrons sur ADD_FILES, car il est utile pour les migrations personnalisées.
Pour les options ADD_FILES, vous pouvez utiliser AWS Glue pour générer des métadonnées et des statistiques Iceberg pour une table de lac de données existante et créer de nouvelles tables Iceberg dans AWS Glue Data Catalog pour une utilisation ultérieure sans avoir besoin de réécrire les données sous-jacentes. Pour obtenir des instructions sur la génération de métadonnées et de statistiques Iceberg à l'aide d'AWS Glue, reportez-vous à Migrer un lac de données existant vers un lac de données transactionnel à l'aide d'Apache Iceberg or Convertissez les tables de lac de données Amazon S3 existantes en tables Snowflake Unmanaged Iceberg à l'aide d'AWS Glue.
Cette option nécessite que vous mettiez en pause les pipelines de données lors de la conversion des fichiers en tables Iceberg, ce qui est un processus simple dans AWS Glue car la destination doit simplement être modifiée en table Iceberg.
Conclusion
Dans cet article, vous avez vu les deux modèles d'architecture pour implémenter Apache Iceberg dans un lac de données pour une meilleure interopérabilité entre AWS et Snowflake. Nous avons également fourni des conseils sur la migration des tables de lacs de données existantes vers le format Iceberg.
Inscrivez-vous Journée des développeurs AWS le 10 avril pour vous familiariser non seulement avec Apache Iceberg, mais également avec les pipelines de données en streaming avec Amazon Data Firehose ainsi que Diffusion de Snowpipe, et des applications d'IA générative avec Streamlit en flocon de neige ainsi que Socle amazonien.
À propos des auteurs
 Andries Engelbrecht est un architecte de solutions de partenaire principal chez Snowflake et travaille avec des partenaires stratégiques. Il est activement engagé avec des partenaires stratégiques comme AWS pour soutenir les intégrations de produits et de services ainsi que le développement de solutions conjointes avec des partenaires. Andries a plus de 20 ans d'expérience dans le domaine des données et de l'analyse.
Andries Engelbrecht est un architecte de solutions de partenaire principal chez Snowflake et travaille avec des partenaires stratégiques. Il est activement engagé avec des partenaires stratégiques comme AWS pour soutenir les intégrations de produits et de services ainsi que le développement de solutions conjointes avec des partenaires. Andries a plus de 20 ans d'expérience dans le domaine des données et de l'analyse.
 Deenbandhu Prasad est un spécialiste senior de l'analyse chez AWS, spécialisé dans les services Big Data. Il se passionne pour aider les clients à créer des architectures de données modernes sur le cloud AWS. Il a aidé des clients de toutes tailles à mettre en œuvre des solutions de gestion de données, d'entrepôt de données et de lac de données.
Deenbandhu Prasad est un spécialiste senior de l'analyse chez AWS, spécialisé dans les services Big Data. Il se passionne pour aider les clients à créer des architectures de données modernes sur le cloud AWS. Il a aidé des clients de toutes tailles à mettre en œuvre des solutions de gestion de données, d'entrepôt de données et de lac de données.
 Brian Dolan a rejoint Amazon en tant que responsable des relations militaires en 2012 après sa première carrière en tant qu'aviateur naval. En 2014, Brian a rejoint Amazon Web Services, où il a aidé des clients canadiens, des startups aux entreprises, à explorer le cloud AWS. Plus récemment, Brian était membre de l'équipe de développement commercial non relationnel en tant que spécialiste de la mise sur le marché pour Amazon DynamoDB et Amazon Keyspaces avant de rejoindre l'organisation spécialisée Analytics Worldwide en 2022 en tant que spécialiste de la mise sur le marché pour AWS Glue.
Brian Dolan a rejoint Amazon en tant que responsable des relations militaires en 2012 après sa première carrière en tant qu'aviateur naval. En 2014, Brian a rejoint Amazon Web Services, où il a aidé des clients canadiens, des startups aux entreprises, à explorer le cloud AWS. Plus récemment, Brian était membre de l'équipe de développement commercial non relationnel en tant que spécialiste de la mise sur le marché pour Amazon DynamoDB et Amazon Keyspaces avant de rejoindre l'organisation spécialisée Analytics Worldwide en 2022 en tant que spécialiste de la mise sur le marché pour AWS Glue.
 Nidhi Gupta est un architecte de solutions partenaire senior chez AWS. Elle passe ses journées à travailler avec des clients et des partenaires, à résoudre des défis architecturaux. Elle est passionnée par l'intégration et l'orchestration de données, le traitement sans serveur et Big Data, ainsi que par l'apprentissage automatique. Nidhi possède une vaste expérience dans la direction de la conception d'architecture, de la publication et des déploiements de production pour les charges de travail de données.
Nidhi Gupta est un architecte de solutions partenaire senior chez AWS. Elle passe ses journées à travailler avec des clients et des partenaires, à résoudre des défis architecturaux. Elle est passionnée par l'intégration et l'orchestration de données, le traitement sans serveur et Big Data, ainsi que par l'apprentissage automatique. Nidhi possède une vaste expérience dans la direction de la conception d'architecture, de la publication et des déploiements de production pour les charges de travail de données.
 Scott Sarcelle est responsable du marketing produit chez Snowflake et se concentre sur les lacs de données, le stockage et la gouvernance.
Scott Sarcelle est responsable du marketing produit chez Snowflake et se concentre sur les lacs de données, le stockage et la gouvernance.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

