À mesure que les entreprises collectent des quantités croissantes de données provenant de diverses sources, la structure et l'organisation de ces données doivent souvent évoluer au fil du temps pour répondre à l'évolution des besoins analytiques. Cependant, la modification des partitions de schéma et de table dans les lacs de données traditionnels peut être une tâche perturbatrice et chronophage, nécessitant de renommer ou de recréer des tables entières et de retraiter de grands ensembles de données. Cela entrave l’agilité et le temps nécessaire à la compréhension.
L'évolution du schéma permet d'ajouter, de supprimer, de renommer ou de modifier des colonnes sans avoir besoin de réécrire les données existantes. Ceci est essentiel pour que les entreprises en évolution rapide souhaitent augmenter leurs structures de données afin de prendre en charge de nouveaux cas d'utilisation. Par exemple, une entreprise de commerce électronique peut ajouter de nouveaux attributs démographiques de clients ou des indicateurs de statut de commande pour enrichir les analyses. Iceberg Apache gère ces changements de schéma de manière rétrocompatible grâce à son architecture innovante d'évolution des tables de métadonnées.
De même, l’évolution des partitions permet d’ajouter, de supprimer ou de diviser des partitions en toute transparence. Par exemple, une place de marché de commerce électronique peut initialement diviser les données de commande par jour. À mesure que les commandes s'accumulent et que les requêtes quotidiennes deviennent inefficaces, elles peuvent être divisées en partitions journalières et d'ID client. Le partitionnement des tables organise les grands ensembles de données de la manière la plus efficace possible pour les performances des requêtes. Iceberg donne aux entreprises la flexibilité d'ajuster progressivement les cloisons plutôt que de nécessiter des procédures de reconstruction fastidieuses. De nouvelles partitions peuvent être ajoutées de manière entièrement compatible sans temps d'arrêt ni nécessité de réécrire les fichiers de données existants.
Cet article montre comment exploiter Iceberg, Service de stockage simple Amazon (Amazon S3), Colle AWS, Formation AWS Lakeet Gestion des identités et des accès AWS (IAM) pour mettre en œuvre un lac de données transactionnelles permettant une évolution transparente. En permettant des ajustements faciles des schémas et des partitions à mesure que les informations sur les données évoluent, vous pouvez bénéficier de la flexibilité évolutive nécessaire à la réussite de votre entreprise.
Présentation de la solution
Pour notre exemple de cas d’utilisation, une grande entreprise de commerce électronique fictive traite des milliers de commandes chaque jour. Lorsque les commandes sont reçues, mises à jour, annulées, expédiées, livrées ou retournées, les modifications sont apportées dans leur système sur site et ces modifications doivent être répliquées dans un lac de données S3 afin que les analystes de données puissent exécuter des requêtes via Amazone Athéna. Les modifications peuvent également contenir des mises à jour de schéma. En raison des exigences de sécurité des différentes organisations, elles doivent gérer un contrôle d'accès précis pour les analystes via Lake Formation.
Le diagramme suivant illustre l'architecture de la solution.
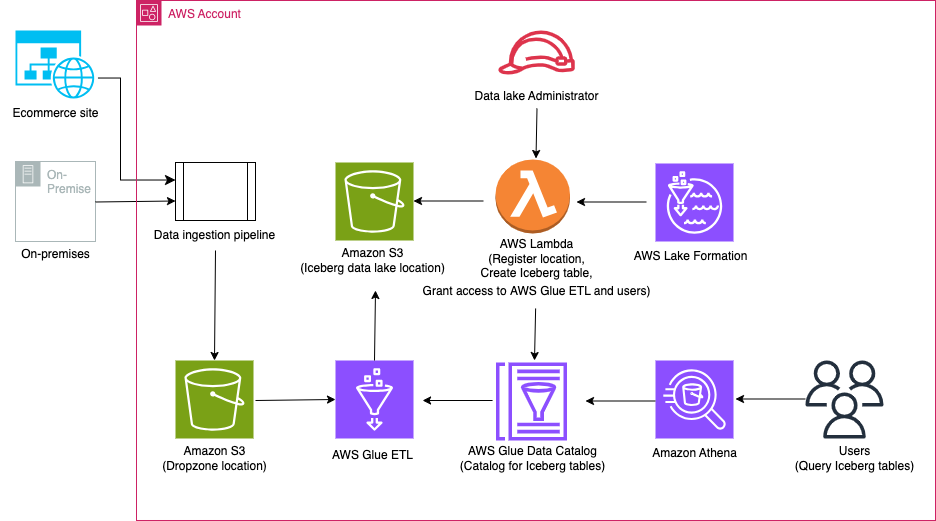
Le workflow de la solution comprend les étapes clés suivantes :
- Ingérez des données sur site vers un emplacement Dropzone à l'aide d'un pipeline d'ingestion de données.
- Fusionnez les données de l'emplacement Dropzone dans Iceberg à l'aide d'AWS Glue.
- Interrogez les données à l’aide d’Athena.
Pré-requis
Pour cette procédure pas à pas, vous devez disposer des prérequis suivants:
Configurer l'infrastructure avec AWS CloudFormation
Pour créer votre infrastructure avec un AWS CloudFormation modèle, procédez comme suit :
- Connectez-vous en tant qu'administrateur à votre compte AWS.
- Ouvrez la console AWS CloudFormation.
- Selectionnez Lancer la pile:

- Pour Nom de la pile, entrez un nom (pour ce post, icebergdemo1).
- Selectionnez Suivant.
- Fournissez des informations sur les paramètres suivants :
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- Selectionnez Suivant.
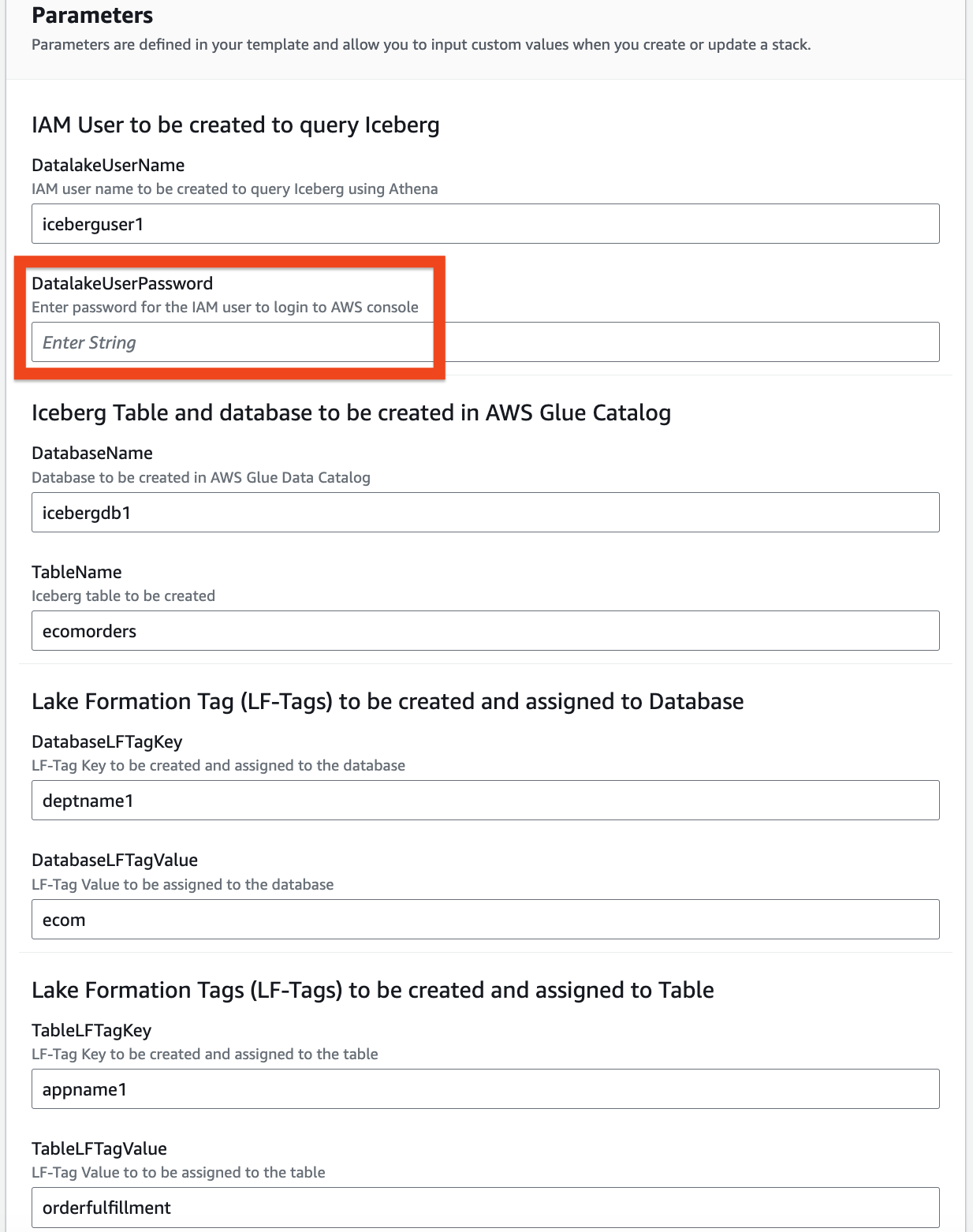
- Selectionnez Encore une fois.
- Dans le Avis , vérifiez les valeurs que vous avez saisies.
- Sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM avec des noms personnalisés et choisissez Envoyer.
Dans quelques minutes, l'état de la pile passera à CREATE_COMPLETE.
Vous pouvez aller à la Onglet Sorties de la pile pour voir toutes les ressources qu'elle a provisionnées. Les ressources sont préfixées par le nom de la pile que vous avez fourni (pour cet article, icebergdemo1).
Créez une table Iceberg à l'aide de Lambda et accordez l'accès à l'aide de Lake Formation
Pour créer une table Iceberg et y accorder l'accès, procédez comme suit :
- Accédez à la Ressources de la pile CloudFormation icebergdemo1 et recherchez l'ID logique nommé
LambdaFunctionIceberg. - Choisissez le lien hypertexte de l'identifiant physique associé.
Vous êtes redirigé vers la fonction Lambda icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- Sur le configuration onglet, choisissez Variables d'environnement dans le volet de gauche.

- Sur le Code onglet, vous pouvez inspecter le code de fonction.
La fonction utilise le AWS SDK pour Python (Boto3) API pour provisionner les ressources. Il assume le rôle d'administrateur de lac de données provisionné pour effectuer les tâches suivantes :
- Subvention DATA_LOCATION_ACCESS accès au rôle d'administrateur du lac de données sur l'emplacement du lac de données enregistré
- Création Étiquettes de formation de lac (étiquettes LF)
- Créez une base de données dans le catalogue de données AWS Glue à l'aide d'AWS Glue créer_base de données API
- Attribuer des balises LF à la base de données
- Accordez l'accès DESCRIBE à la base de données à l'aide des balises LF à l'utilisateur IAM du lac de données et au rôle IAM AWS Glue ETL.
- Créez une table Iceberg à l'aide d'AWS Glue créer_table API:
- Attribuer des balises LF à la table
- Accordez DESCRIBE et SELECT sur la table Iceberg LF-Tags pour l'utilisateur IAM du lac de données
- Accordez l'accès ALL, DESCRIBE, SELECT, INSERT, DELETE et ALTER sur la table Iceberg LF-Tags au rôle IAM AWS Glue ETL.
- Sur le Teste onglet, choisissez Teste pour exécuter la fonction.

Une fois la fonction terminée, vous verrez le message « Exécution de la fonction : réussie ».
Lake Formation vous aide à gérer, sécuriser et partager globalement des données à des fins d'analyse et d'apprentissage automatique. Avec Lake Formation, vous pouvez gérer un contrôle d'accès précis pour les données de votre lac de données sur Amazon S3 et ses métadonnées dans le catalogue de données.
Pour ajouter un emplacement Amazon S3 comme stockage Iceberg dans votre lac de données, enregistrer l'emplacement avec la Formation du Lac. Vous pouvez ensuite utiliser les autorisations de Lake Formation pour un contrôle d'accès plus précis aux objets du catalogue de données qui pointent vers cet emplacement et aux données sous-jacentes de cet emplacement.
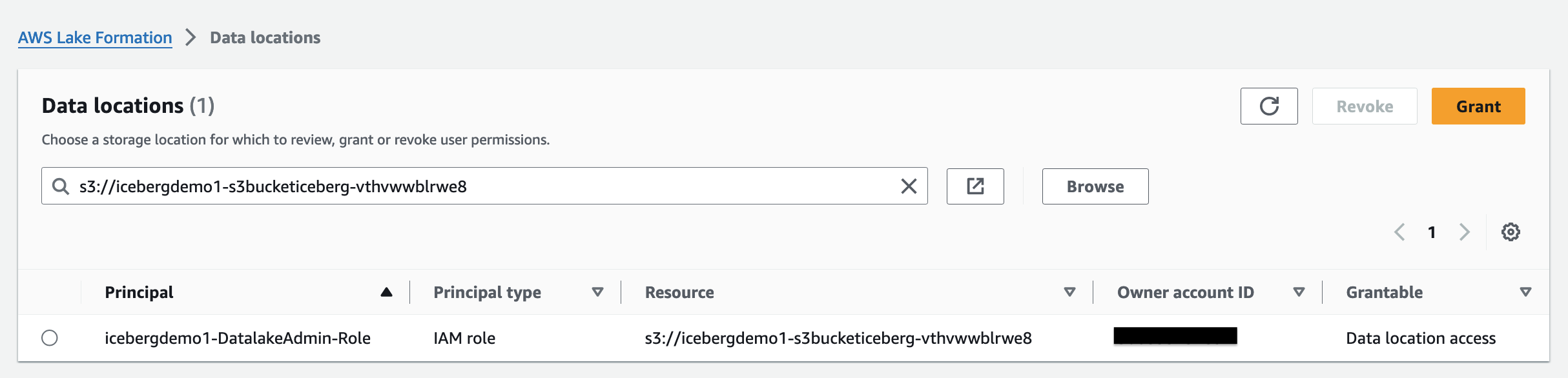
La pile CloudFormation a enregistré l'emplacement du lac de données.

Autorisations de localisation des données dans Lake Formation permettent aux responsables de créer et de modifier des ressources de catalogue de données qui pointent vers les emplacements Amazon S3 enregistrés désignés. Les autorisations de localisation des données fonctionnent en plus de Lake Formation autorisations de données pour sécuriser les informations dans votre lac de données.
Contrôle d'accès basé sur des balises de Lake Formation (LF-TBAC) est une stratégie d'autorisation qui définit les autorisations en fonction des attributs. Dans Lake Formation, ces attributs sont appelés LF-Tags. Vous pouvez attacher des balises LF aux ressources Data Catalog, aux principaux Lake Formation et aux colonnes de table. Vous pouvez attribuer et révoquer des autorisations sur les ressources de Lake Formation à l'aide de ces balises LF. Lake Formation autorise les opérations sur ces ressources lorsque la balise du principal correspond à la balise de ressource.
Vérifiez la table Iceberg depuis la console Lake Formation
Pour vérifier la table Iceberg, procédez comme suit :
- Sur la console Lake Formation, choisissez Bases de données dans le volet de navigation.
- Ouvrez la page de détails pour
icebergdb1.
Vous pouvez voir la base de données associée LF-Tags.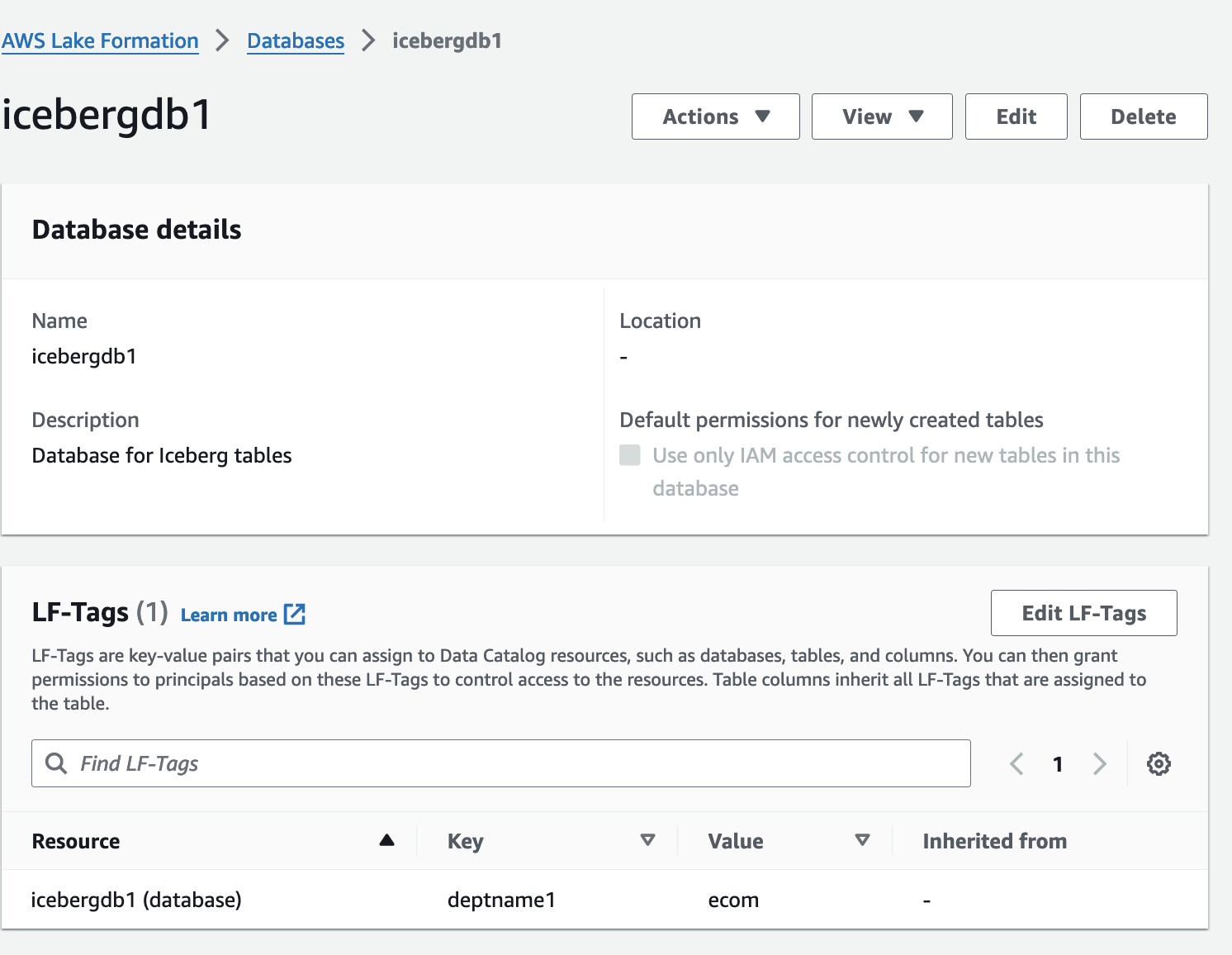
- Selectionnez Tables dans le volet de navigation.
- Ouvrez la page de détails pour
ecomorders.
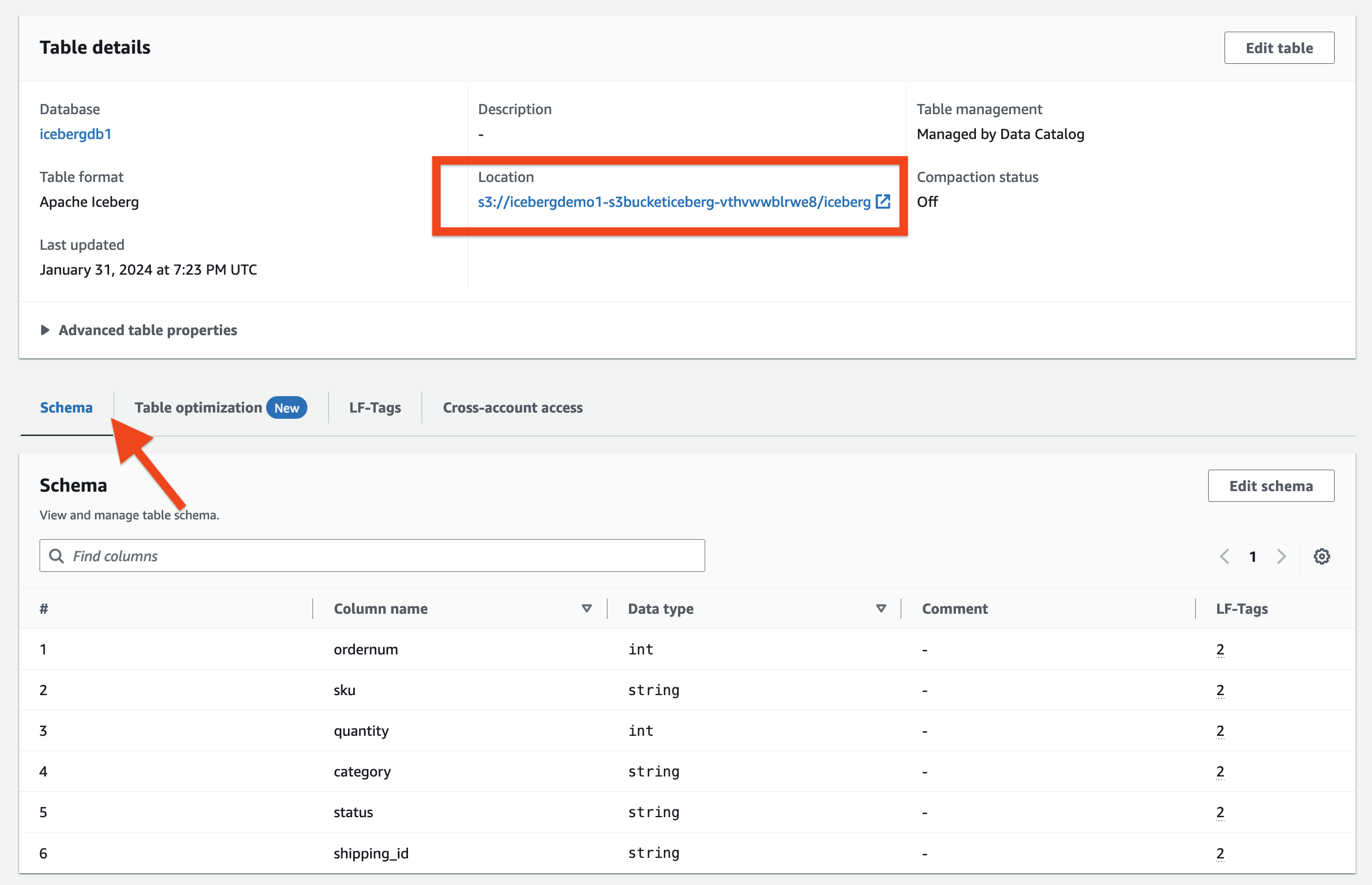
Dans le Détails du tableau section, vous pouvez observer ce qui suit :
- Format de tableau montre comme Iceberg Apache
- Gestion de la table montre comme Géré par Data Catalog
- Localisation répertorie l'emplacement du lac de données de la table Iceberg
Dans le Étiquettes LF section, vous pouvez voir le tableau associé LF-Tags.
Dans le Détails du tableau section, développez Propriétés avancées des tables pour afficher les éléments suivants :
metadata_locationpointe vers l'emplacement du fichier de métadonnées de la table Icebergtable_typemontre commeICEBERG
Sur le Programme , vous pouvez visualiser les colonnes définies sur la table Iceberg.
Intégrez Iceberg au catalogue de données AWS Glue et à Amazon S3
Iceberg suit les fichiers de données individuels dans une table plutôt que dans des répertoires. Lorsqu'il y a une validation explicite sur la table, Iceberg crée des fichiers de données et les ajoute à la table. Iceberg conserve l'état de la table dans les fichiers de métadonnées. Tout changement dans l'état de la table crée un nouveau fichier de métadonnées qui remplace atomiquement les anciennes métadonnées. Les fichiers de métadonnées suivent le schéma de la table, la configuration du partitionnement et d'autres propriétés.
Iceberg nécessite que les systèmes de fichiers prenant en charge les opérations soient compatibles avec les magasins d'objets comme Amazon S3.
Iceberg crée des instantanés du contenu de la table. Chaque instantané est un ensemble complet de fichiers de données dans la table à un moment donné. Les fichiers de données dans les instantanés sont stockés dans un ou plusieurs fichiers manifestes contenant une ligne pour chaque fichier de données de la table, ses données de partition et ses métriques.
Le diagramme suivant illustre cette hiérarchie.
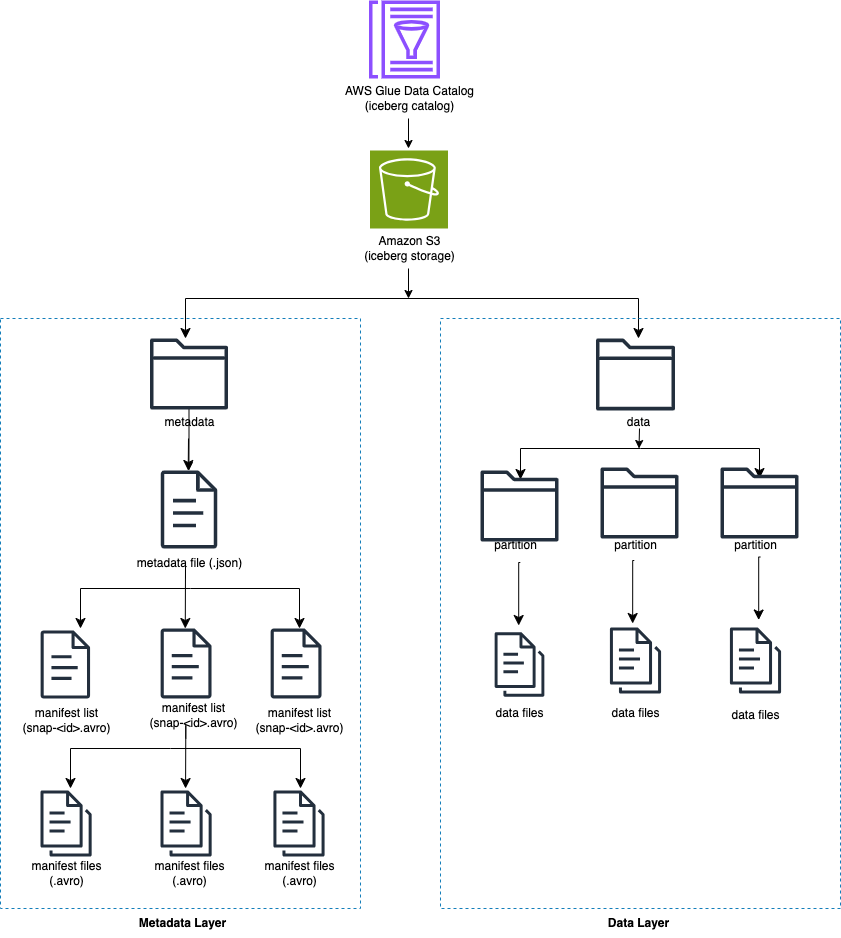
Lorsque vous créez une table Iceberg, elle crée d'abord le dossier de métadonnées, puis un fichier de métadonnées dans le dossier de métadonnées. Le dossier de données est créé lorsque vous chargez des données dans la table Iceberg.

Contenu du fichier de métadonnées Iceberg
Le fichier de métadonnées Iceberg contient de nombreuses informations, notamment les suivantes :
- format-version –Version du tableau Iceberg
- Localisation – Emplacement Amazon S3 de la table
- Schémas – Nom et type de données de toutes les colonnes de la table
- spécifications de partition – Colonnes partitionnées
- ordres de tri – Ordre de tri des colonnes
- propriétés – Propriétés du tableau
- identifiant-instantané-actuel – Instantané actuel
- réfs – Références des tableaux
- des instantanés – Liste des instantanés, chacun contenant les informations suivantes :
- numéro de séquence – Numéro de séquence des instantanés par ordre chronologique (le nombre le plus élevé représente l'instantané actuel, 1 pour le premier instantané)
- identifiant d'instantané – Identifiant de l'instantané
- horodatage-ms – Horodatage de la validation de l'instantané
- résumé – Synthèse des changements engagés
- liste-manifeste – Liste des manifestes ; ce nom de fichier commence par snap-<snapshot-id>
- identifiant de schéma – Numéro d’ordre du schéma par ordre chronologique (le numéro le plus élevé représente le schéma actuel)
- journal d'instantané – Liste des instantanés par ordre chronologique
- journal des métadonnées – Liste des fichiers de métadonnées par ordre chronologique
Le fichier de métadonnées contient toutes les modifications historiques apportées aux données et au schéma de la table. Examiner directement le contenu du fichier métafichier peut être une tâche fastidieuse. Heureusement, vous pouvez interroger le Métadonnées d'iceberg utilisant Athena.
Cadre Iceberg dans AWS Glue
AWS Glue 4.0 prend en charge les tables Iceberg enregistrées auprès de Lake Formation. Dans les tâches AWS Glue ETL, vous avez besoin du code suivant pour activer le cadre Iceberg:
Pour l'accès en lecture/écriture aux données sous-jacentes, en plus des autorisations Lake Formation, le rôle AWS Glue IAM pour exécuter les tâches AWS Glue ETL a été accordé. formation du lac : GetDataAccess Autorisation IAM. Avec cette autorisation, Lake Formation accorde la demande d'informations d'identification temporaires pour accéder aux données.
La pile CloudFormation a provisionné les quatre tâches AWS Glue ETL pour vous. Le nom de chaque tâche commence par le nom de votre pile (icebergdemo1). Effectuez les étapes suivantes pour afficher les tâches :
- Connectez-vous en tant qu'administrateur à votre compte AWS.
- Sur la console AWS Glue, choisissez Emplois ETL dans le volet de navigation.
- Rechercher des emplois avec
icebergdemo1dans le nom.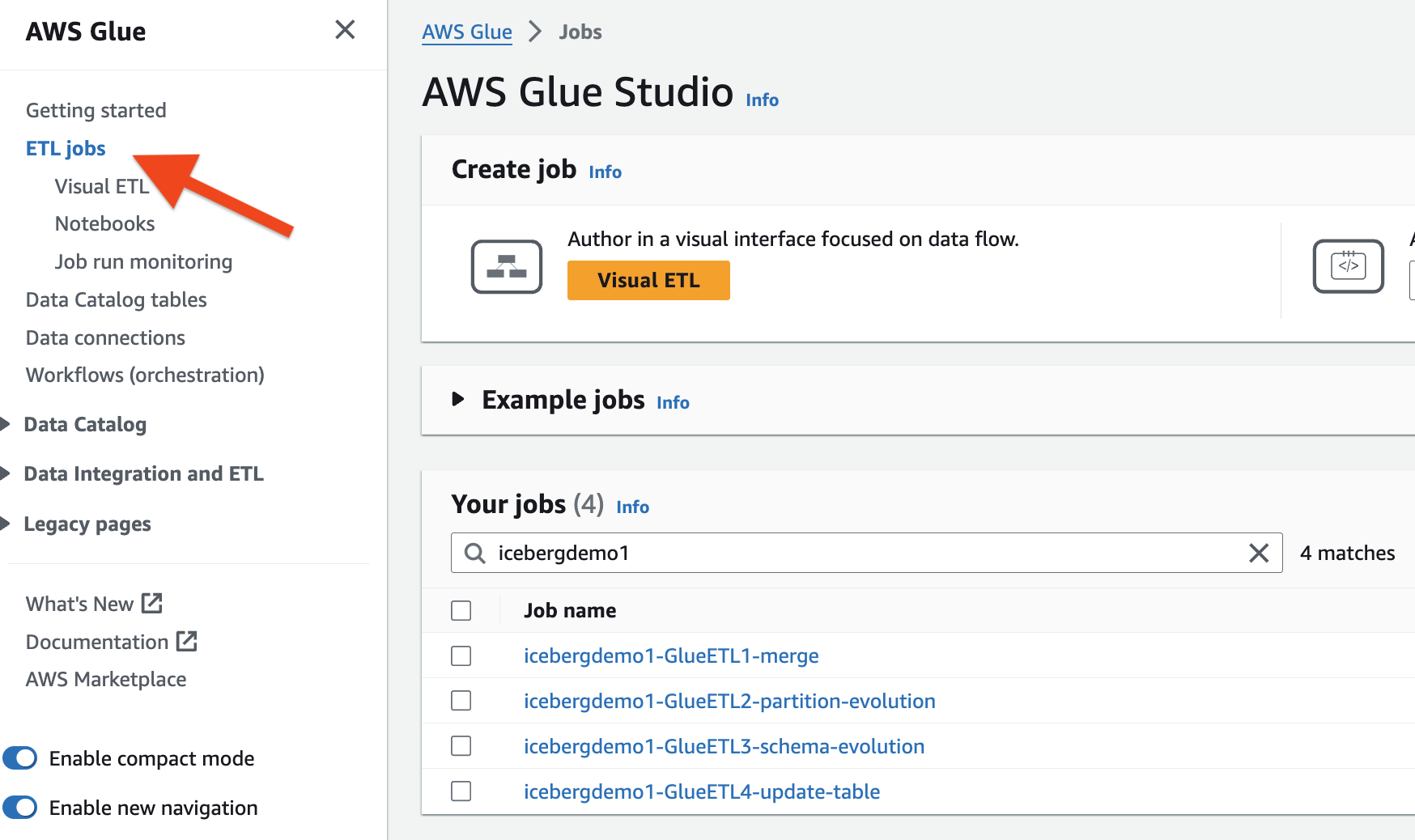
Fusionner les données de Dropzone dans la table Iceberg
Pour notre cas d'utilisation, l'entreprise ingère quotidiennement les données de ses commandes de commerce électronique depuis son emplacement sur site vers un emplacement Amazon S3 Dropzone. La pile CloudFormation a chargé trois fichiers avec des exemples de commandes pendant 3 jours, comme le montrent les figures suivantes. Vous voyez les données à l'emplacement Dropzone s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
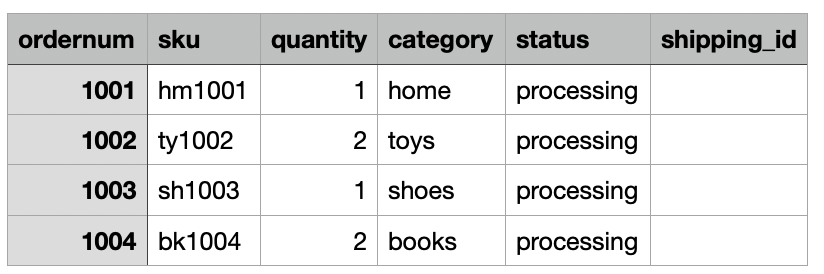


Le travail AWS Glue ETL icebergdemo1-GlueETL1-merge s'exécutera quotidiennement pour fusionner les données dans la table Iceberg. Il a la logique suivante pour ajouter ou mettre à jour les données sur Iceberg :
- Créez un Spark DataFrame à partir des données d'entrée :
- Pour une nouvelle commande, ajoutez-la au tableau
- Si la table a une commande correspondante, mettez à jour le statut et
shipping_id:
Effectuez les étapes suivantes pour exécuter la tâche de fusion AWS Glue :
- Sur la console AWS Glue, choisissez Emplois ETL dans le volet de navigation.
- Sélectionnez le travail ETL
icebergdemo1-GlueETL1-merge. - Sur le Actions menu déroulant, choisissez Exécuter avec des paramètres.
- Sur le Paramètres d'exécution page, allez à Paramètres du travail.
- Pour le
--dropzone_pathparamètre, fournissez l’emplacement S3 des données d’entrée (icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - Exécutez la tâche pour ajouter toutes les commandes : 1001, 1002, 1003 et 1004.
- Pour le
--dropzone_path parameter, remplacez l'emplacement S3 paricebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - Exécutez à nouveau le travail pour ajouter les commandes 2001 et 2002 et mettre à jour les commandes 1001, 1002 et 1003.
- Pour le
--dropzone_pathparamètre, modifiez l’emplacement S3 enicebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - Exécutez à nouveau le travail pour ajouter la commande 3001 et mettre à jour les commandes 1001, 1003, 2001 et 2002.
Accédez au dossier de données de la table pour voir les fichiers de données écrits par Iceberg lorsque vous avez fusionné les données dans la table à l'aide du travail Glue ETL. icebergdemo1-GlueETL1-merge.

Interroger Iceberg en utilisant Athena
La pile CloudFormation a créé l'utilisateur IAM iceberguser1, qui dispose d'un accès en lecture sur la table Iceberg à l'aide de LF-Tags. Pour interroger Iceberg à l'aide d'Athena via cet utilisateur, procédez comme suit :
- Se connecter en tant que
iceberguser1à la Console de gestion AWS. - Sur la console Athena, choisissez Groupes de travail dans le volet de navigation.
- Localisez le groupe de travail que CloudFormation a provisionné (
icebergdemo1-workgroup) - Vérifiez la version 3 du moteur Athena.
La version 3 du moteur Athena prend en charge Formats de fichiers Icebergs, dont Parquet, ORC et Avro.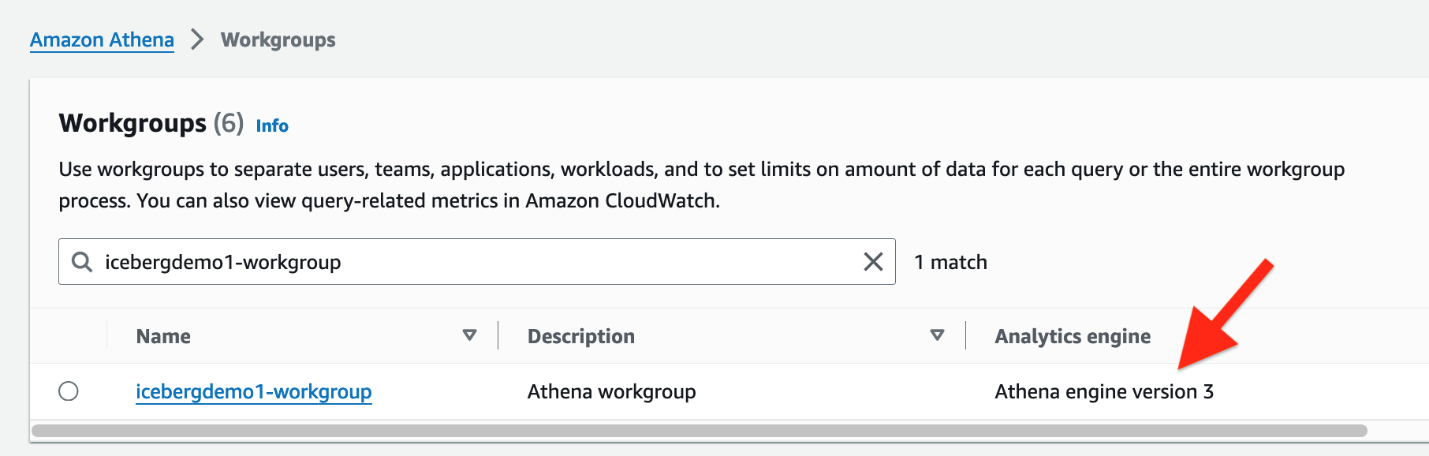
- Accédez à l'éditeur de requêtes Athena.
- Choisissez le groupe de travail icebergdemo1-workgroup dans le menu déroulant.
- Pour Base de données, choisissez
icebergdb1. Vous verrez le tableauecomorders. - Exécutez la requête suivante pour voir les données dans la table Iceberg :
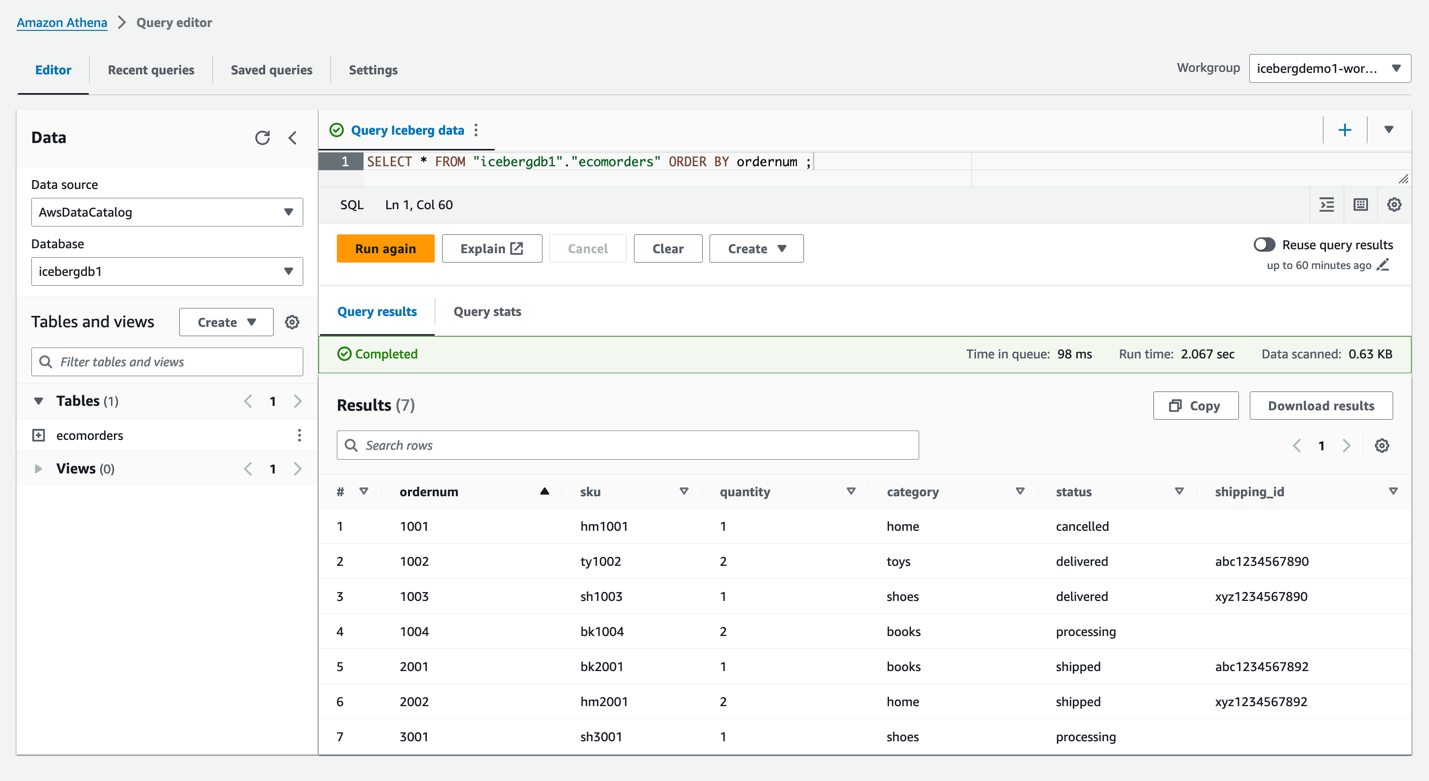
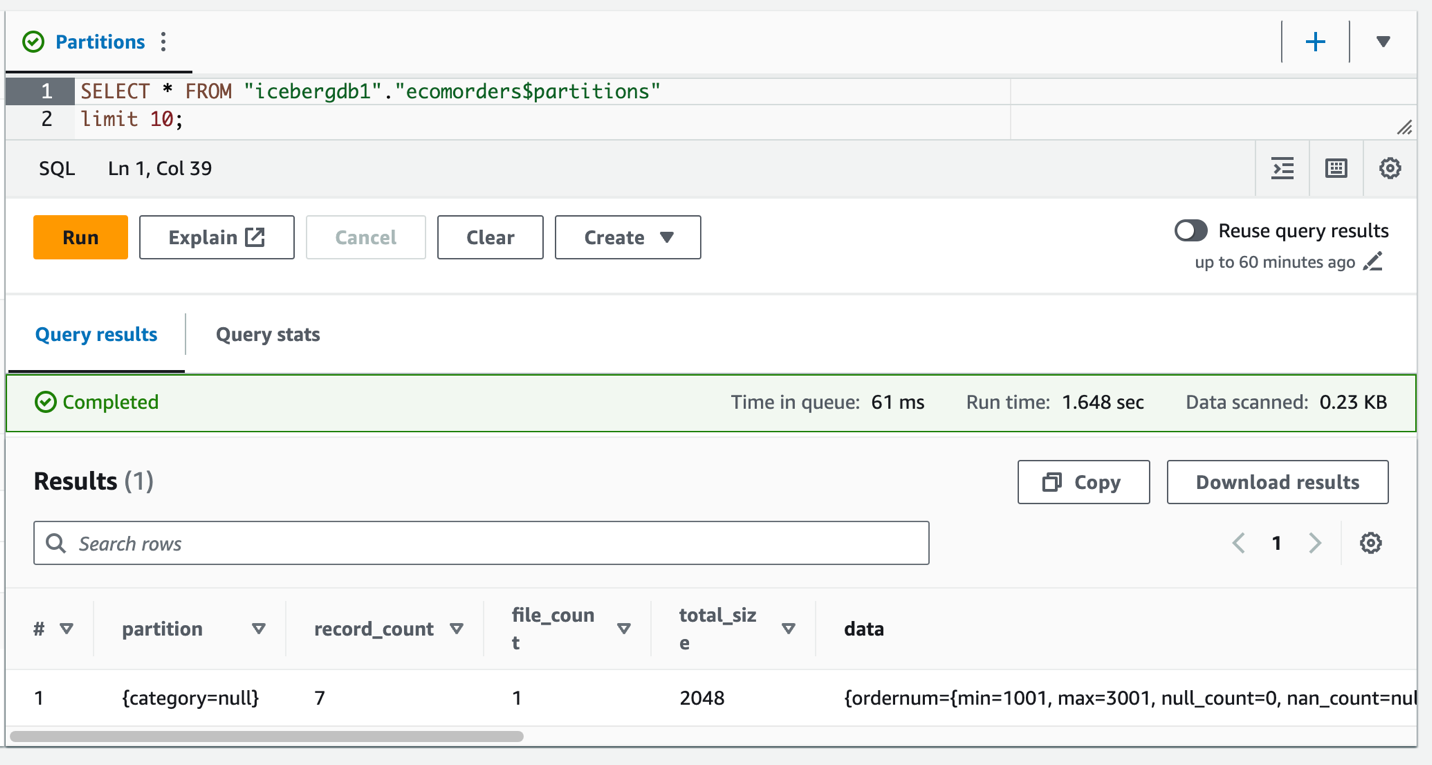
- Exécutez la requête suivante pour voir les partitions actuelles de la table :
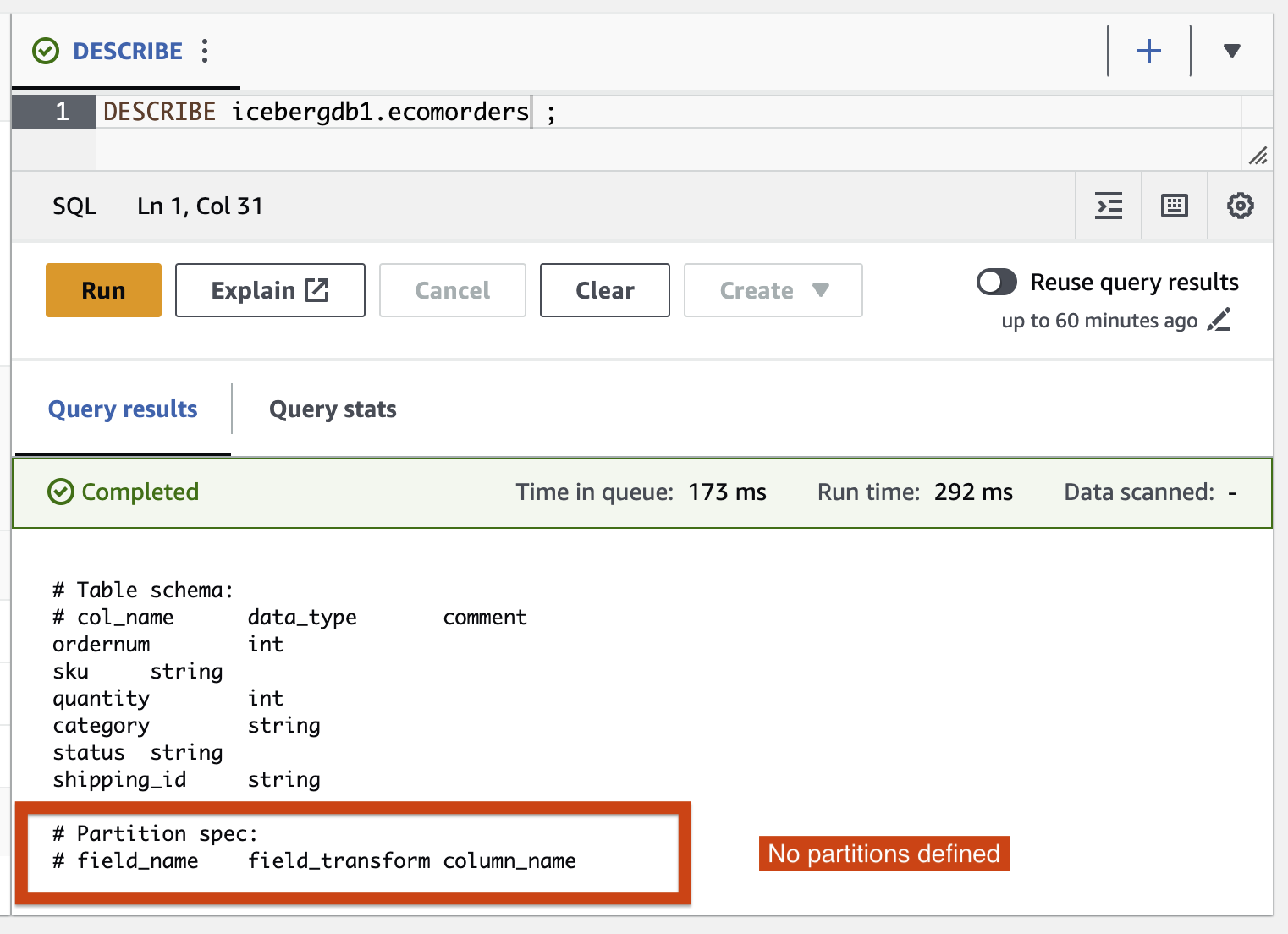
Partition-spec décrit comment la table est partitionnée. Dans cet exemple, il n'y a aucun champ partitionné car vous n'avez défini aucune partition sur la table.
Évolution de la partition des icebergs
Vous devrez peut-être modifier la structure de votre partition ; par exemple, en raison de changements de tendance dans les modèles de requêtes courants dans les analyses en aval. Un changement de structure de partition pour des tables traditionnelles est une opération importante qui nécessite une copie complète des données.
Iceberg simplifie les choses. Lorsque vous modifiez la structure des partitions sur Iceberg, vous n'avez pas besoin de réécrire les fichiers de données. Les anciennes données écrites avec des partitions antérieures restent inchangées. Les nouvelles données sont écrites en utilisant les nouvelles spécifications dans une nouvelle présentation. Les métadonnées de chacune des versions de partition sont conservées séparément.
Ajoutons la catégorie de champ de partition à la table Iceberg à l'aide de la tâche AWS Glue ETL icebergdemo1-GlueETL2-partition-evolution:
Sur la console AWS Glue, exécutez la tâche ETL icebergdemo1-GlueETL2-partition-evolution. Une fois le travail terminé, vous pouvez interroger les partitions à l'aide d'Athena.
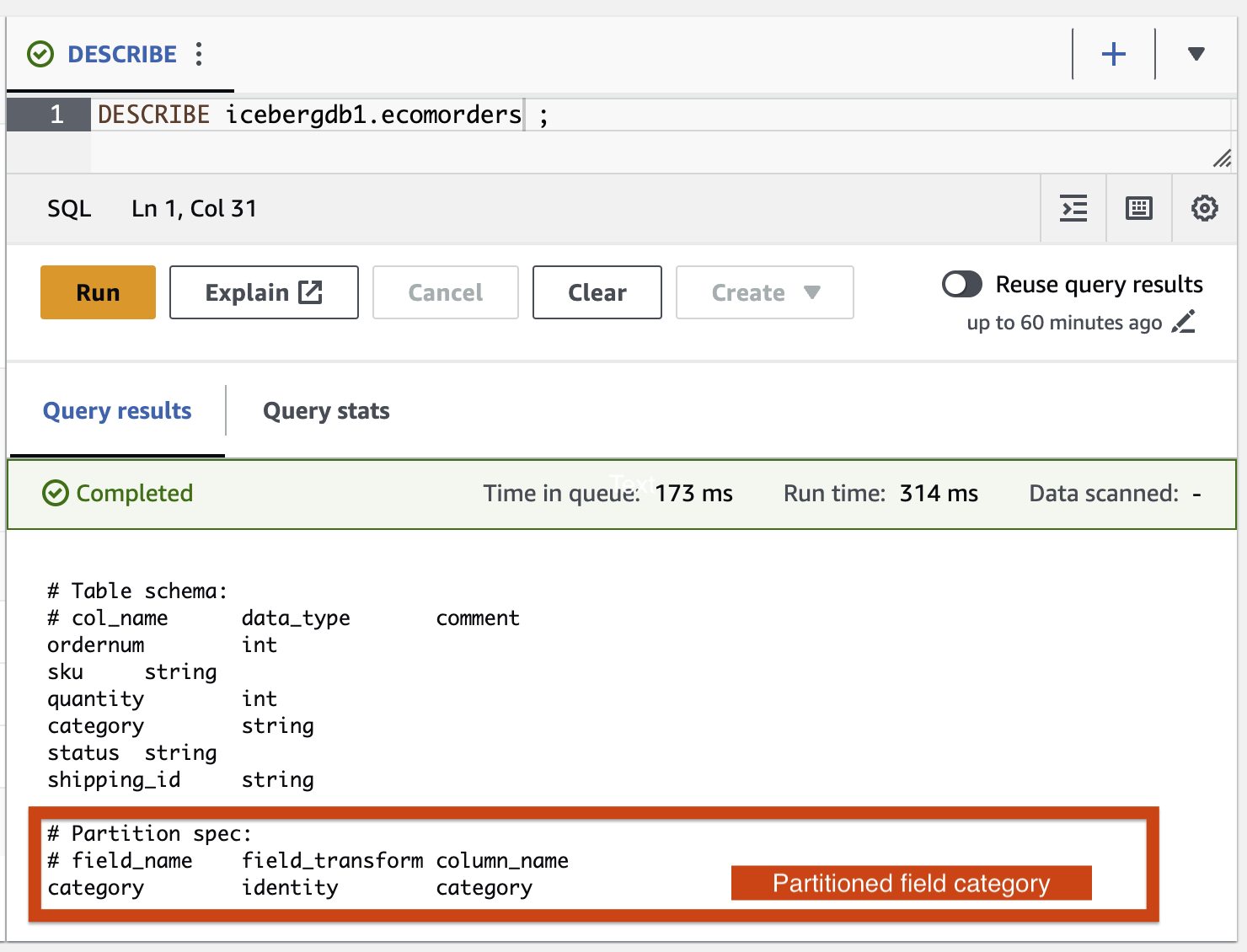
Vous pouvez voir la catégorie du champ de partition, mais les valeurs de partition sont nulles. Il n'y a pas de nouveaux fichiers de données dans le dossier de données, car l'évolution de la partition est une opération de métadonnées et ne réécrit pas les fichiers de données. Lorsque vous ajoutez ou mettez à jour des données, vous verrez les valeurs de partition correspondantes renseignées.
Evolution du schéma Iceberg
Iceberg prend en charge l'évolution des tables sur place. Tu peux faire évoluer un schéma de table tout comme SQL. Les mises à jour du schéma Iceberg sont des modifications de métadonnées, donc aucun fichier de données n'a besoin d'être réécrit pour effectuer l'évolution du schéma.
Pour explorer l'évolution du schéma Iceberg, exécutez le travail ETL icebergdemo1-GlueETL3-schema-evolution via la console AWS Glue. La tâche exécute les instructions SparkSQL suivantes :
Dans l'éditeur de requêtes Athena, exécutez la requête suivante :

Vous pouvez vérifier les modifications du schéma apportées à la table Iceberg :
- Une nouvelle colonne a été ajoutée appelée
shipping_carrier - La colonne
shipping_ida été renommétracking_number - Le type de données de la colonne
ordernumest passé de int à bigint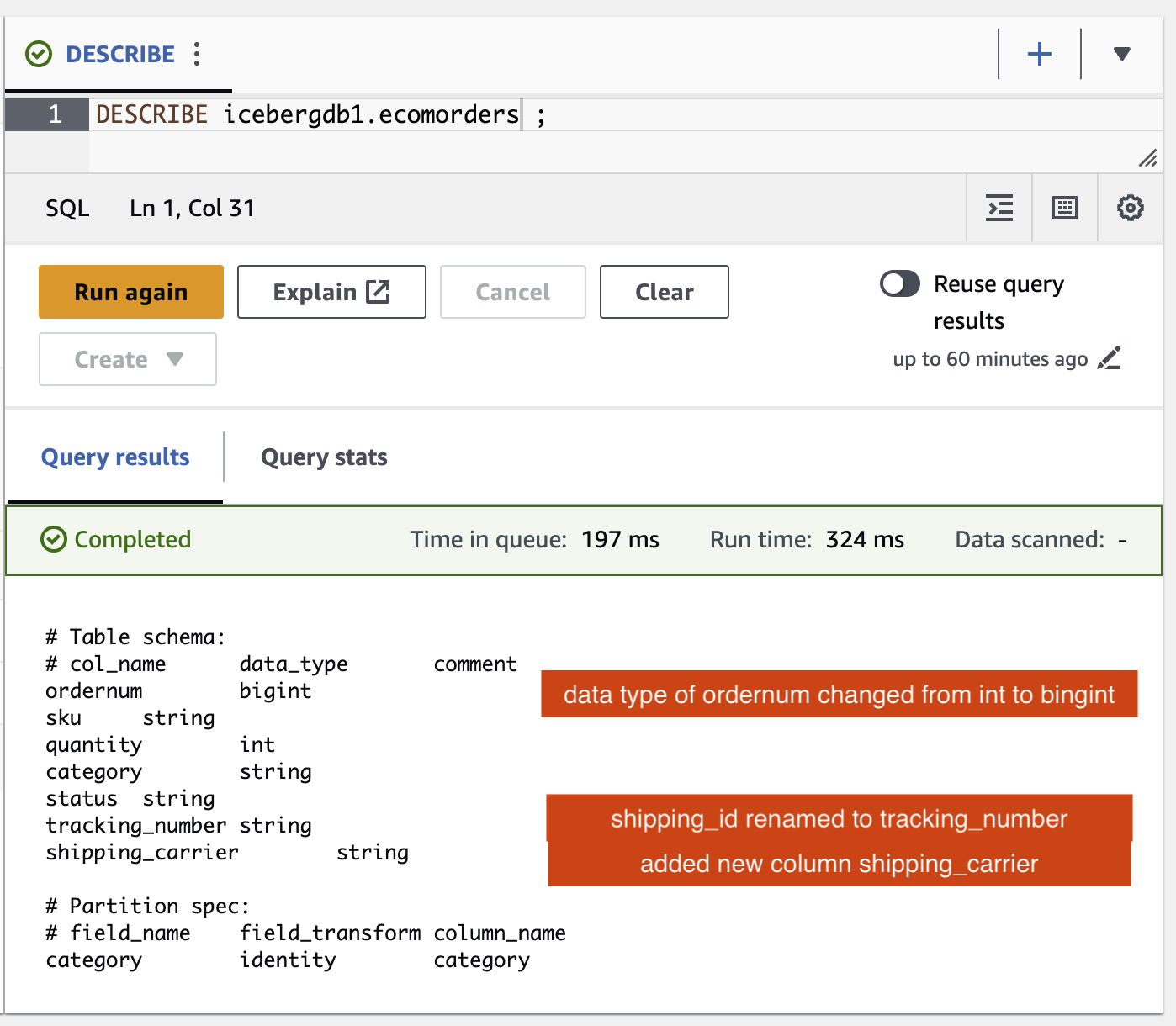
Mise à jour de position
Les données tracking_number contient le transporteur concaténé avec le numéro de suivi. Supposons que nous souhaitions diviser ces données afin de conserver le transporteur dans le shipping_carrier champ et le numéro de suivi dans le tracking_number champ.
Sur la console AWS Glue, exécutez la tâche ETL icebergdemo1-GlueETL4-update-table. La tâche exécute l'instruction SparkSQL suivante pour mettre à jour la table :
Interrogez la table Iceberg pour vérifier les données mises à jour sur tracking_number ainsi que shipping_carrier.
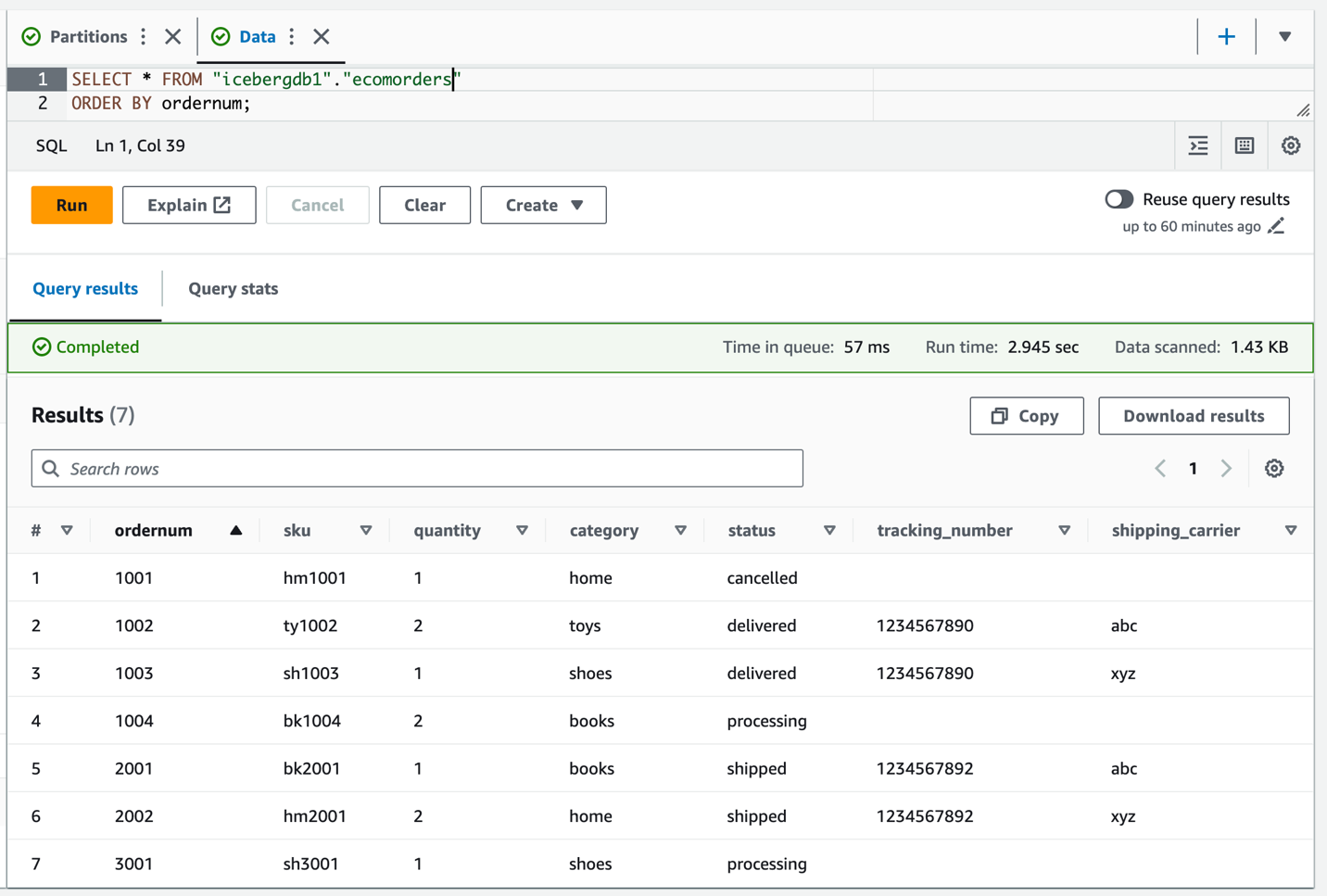
Maintenant que les données ont été mises à jour sur la table, vous devriez voir les valeurs de partition renseignées pour la catégorie :

Nettoyer
Pour éviter de devoir payer des frais futurs, nettoyez les ressources que vous avez créées :
- Sur la console Lambda, ouvrez la page de détails de la fonction
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - Dans le Variables d'environnement section, choisissez la clé
Task_To_Performet mettez à jour la valeur àCLEANUP. - Exécutez la fonction qui supprime la base de données, la table et leurs balises LF associées.
- Sur la console AWS CloudFormation, supprimez la pile icebergdemo1.
Conclusion
Dans cet article, vous avez créé une table Iceberg à l'aide de l'API AWS Glue et utilisé Lake Formation pour contrôler l'accès à la table Iceberg dans un lac de données transactionnelles. Avec les tâches AWS Glue ETL, vous avez fusionné des données dans la table Iceberg et effectué une évolution de schéma et une évolution de partition sans réécrire ni recréer la table Iceberg. Avec Athena, vous avez interrogé les données et métadonnées Iceberg.
Sur la base des concepts et des démonstrations de cet article, vous pouvez désormais créer un lac de données transactionnelles dans une entreprise à l'aide d'Iceberg, AWS Glue, Lake Formation et Amazon S3.
À propos de l’auteur
 Satya Adimula est un architecte de données senior chez AWS basé à Boston. Avec plus de deux décennies d'expérience dans le domaine des données et de l'analyse, Satya aide les organisations à tirer des informations commerciales de leurs données à grande échelle.
Satya Adimula est un architecte de données senior chez AWS basé à Boston. Avec plus de deux décennies d'expérience dans le domaine des données et de l'analyse, Satya aide les organisations à tirer des informations commerciales de leurs données à grande échelle.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

