Introduction
Avant Wordle, Casse-tête Sudoku était à la mode et il est toujours très populaire. Ces dernières années, l'utilisation de à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience les méthodes pour résoudre le puzzle ont été un thème dominant. Voir "Résoudre le casse-tête du Sudoku en utilisant l'optimisation dans Arkieva ».
À l’heure actuelle, l’utilisation de l’intelligence artificielle (IA) se concentre sur l’apprentissage automatique qui englobe un large éventail de méthodes allant de la régression au lasso à l’apprentissage par renforcement. L'utilisation de l'IA a refait surface s'attaquer au complexe ordonnancement défis. Une méthode, la recherche avec retour en arrière, est couramment utilisée et convient parfaitement au Sudoku.
Ce blog fournira une description détaillée sur la façon d'utiliser cette méthode pour résoudre le Sudoku. Il s'avère que le « retour en arrière » peut être trouvé dans les moteurs d'optimisation et d'apprentissage automatique et constitue la pierre angulaire des heuristiques avancées qu'Arkieva utilise pour la planification. L'algorithme est implémenté dans un « Array Programming Language », un langage de programmation orienté fonction qui gère un riche ensemble de structures de tableaux.
Les bases du Sudoku
De Wikipédia: Le Sudoku est un puzzle combinatoire de placement de nombres basé sur la logique. L'objectif est de remplir une grille 9×9 de chiffres afin que chaque colonne, chaque ligne et chacune des neuf sous-grilles 3×3 qui composent la grille (également appelées « cases », « blocs », « régions », ou « sous-carrés ») contient tous les chiffres de 1 à 9. Le puzzle setter fournit une grille partiellement complétée, qui a généralement une solution unique. Les puzzles terminés sont toujours une sorte de carré latin avec une contrainte supplémentaire sur le contenu des régions individuelles. Par exemple, le même nombre entier ne peut pas apparaître deux fois dans la même ligne ou colonne du plateau de jeu 9×9 ou dans l’une des neuf sous-régions 3×3 du plateau de jeu 9×9.
Le tableau 1 présente un exemple de problème. Il y a 9 lignes et 9 colonnes pour un total de 81 cellules. Chacun est autorisé à avoir un et un seul nombre entier parmi neuf entiers compris entre 1 et 9. Dans la solution de départ, une cellule a soit une valeur unique – ce qui fixe la valeur de cette cellule à cette valeur, soit la cellule est vide, indiquant que nous avons besoin pour trouver une valeur pour cette cellule. La cellule (1,1) a la valeur 2 et la cellule (6,5) a la valeur 6. La cellule (1,2) et la cellule (2,3) sont vides et l'algorithme trouvera une valeur pour ces cellules.

La complication
En plus d’appartenir à une et une seule ligne et colonne, une cellule appartient à une et une seule case. Il y a 1 cases, et elles sont indiquées par couleur dans le tableau 9. Le tableau 1 utilise un entier unique compris entre 2 et 1 pour identifier chaque case ou grille. Les cellules avec une valeur de ligne de (9, 1 ou 2) et une valeur de colonne de (3, 1 ou 2) appartiennent à la case 3. La case 1 contient les valeurs de ligne de (6, 4, 5) et les valeurs de colonne (6, 7). , 8). L'identifiant de la boîte est déterminé par la formule BOX_ID = {9x(floor((ROW_ID-3) /1)} + plafond (COL_ID/3). Pour la cellule (3), 5,7 = 6x(floor(3-5 ))/1) + plafond (3/8)= 3×3 + 1 = 3+3.

Le cœur du puzzle
Trouver une valeur entière comprise entre 1 et 9 pour chaque cellule inconnue de telle sorte que les entiers 1 à 9 soient utilisés une et une seule fois pour chaque colonne, chaque ligne et chaque case.
Regardons la cellule (1,3) qui est vide. La ligne 1 contient déjà les valeurs 2 et 7. Celles-ci ne sont pas autorisées dans cette cellule. La colonne 3 contient déjà les valeurs 3, 5,6, 7,9. Ceux-ci ne sont pas autorisés. La case 1 (jaune) contient les valeurs 2, 3 et 8. Celles-ci ne sont pas autorisées. Les valeurs suivantes ne sont pas autorisées (2,7) ; (3, 5, 6, 7, 9) ; (2, 3, 8). Les valeurs uniques non autorisées sont (2, 3, 5, 6, 7, 8, 9). Les seules valeurs candidates sont (1,4).
Une solution consisterait à attribuer temporairement 1 à la cellule (1,3), puis à essayer de trouver des valeurs candidates pour une autre cellule.
Une solution de retour en arrière : démarrage des composants
Structure du tableau
Le point de départ consiste à décider d’une structure de tableau pour stocker le problème source et prendre en charge la recherche. Le tableau 3 présente cette structure de tableau. La colonne 1 est un identifiant entier unique pour chaque cellule. Les valeurs vont de 1 à 81. La colonne 2 est l'ID de ligne de la cellule. La colonne 3 est l'ID de colonne de la cellule. La colonne 4 est l'identifiant de la boîte. La colonne 5 est la valeur de la cellule. Observez qu'une cellule sans valeur reçoit la valeur zéro au lieu de vide ou nulle. Cela reste un « tableau d’entiers uniquement » – bien supérieur en termes de performances.

En APL, ce tableau serait stocké dans un tableau bidimensionnel où la forme est de 2 x 81. Supposons que les éléments du tableau 5 soient stockés dans la variable MAT. Des exemples de fonctions sont :
La commande MAT[1 2 3;]récupère les 3 premières lignes de MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] sécurise les lignes 1, 2, 3 et uniquement les colonnes 4 et 5
1 2
1 0
1 0
(MAT[;5]=0)/MAT[;1] recherche toutes les cellules qui ont besoin d'une valeur.
INSÉRER LE TABLEAU 3
Contrôle d'intégrité : doublons
Avant de commencer la recherche, il est essentiel de vérifier l’intégrité ! C'est la solution de départ réalisable. Ce qui est réalisable pour le Sudoku, c'est qu'il y ait désormais des doublons dans n'importe quelle ligne, colonne ou case. La solution de départ actuelle, par exemple 1, est réalisable. Le tableau 4 présente un exemple où la solution de départ comporte des doublons. La ligne 1 a deux valeurs 2. La zone 1 a deux valeurs 2. La fonction « SANITY_DUPE » gère cette logique.

Contrôle d'intégrité : options pour les cellules sans valeurs
Une information très utile serait toutes les valeurs possibles pour une cellule sans valeur. S’il n’y a pas de candidats, alors cette énigme ne peut pas être résolue. Une cellule ne peut pas prendre une valeur déjà revendiquée par sa voisine. En utilisant le tableau 1 pour la cellule (1,3,'1' – ce dernier 1 est le boxid), ses voisins sont la ligne 1, la colonne 3 et la boîte 1. La ligne 1 a les valeurs (2,7) ; la colonne 3 a les valeurs (3,5,6,7,9) ; la case 1 a les valeurs (2,3,8). La cellule (1,3.1) ne peut pas prendre les valeurs suivantes (2,3,5,6,7,8,9). Les seules options pour la cellule (1,3,1) sont (1,4). Pour la cellule (4,1,2), les valeurs 1, 2, 3, 5, 6, 7, 9 sont déjà utilisées dans la ligne 4, la colonne 1 et/ou la case 4. Les seules valeurs candidates sont (4,8) . La fonction « SANITY_CAND » gère cette logique.
Le tableau 5 montre les candidats, par exemple 1 au début du processus de recherche. Si une cellule s'est déjà vu attribuer une valeur dans les conditions de départ (tableau 1), alors cette valeur est répétée et affichée en rouge. Si une cellule nécessitant une valeur n'a qu'une seule option, celle-ci est affichée en blanc. La cellule (8,7,9) a la valeur unique 7 en blanc. (2,5,8,4,3) sont réclamés par la colonne voisine 7. (1, 2, 9) par la ligne 8. (3,2,6) par la case 9. Seule la valeur 7 n'est pas réclamée.
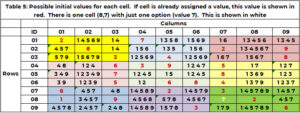
Contrôle de santé mentale : recherche de conflits
Les informations identifiant toutes les options pour les cellules nécessitant une valeur (affichées dans le tableau 4) nous permettent d'identifier un conflit avant de commencer le processus de recherche. Un conflit se produit lorsque deux cellules qui ont besoin d’une valeur n’ont qu’un seul candidat, que la valeur candidate est la même et que les deux cellules sont voisines. D'après le tableau 4, nous savons que la seule cellule qui a besoin d'une valeur et n'a qu'un seul candidat est la cellule (8,7,9). Par exemple 1, il n’y a pas de conflit.
Quel serait un conflit ? Si la seule valeur possible pour la cellule (3,7,3) était 7 (au lieu de 1, 6, 7), alors il y a un conflit. La cellule (8,7) et la cellule (3,7) sont voisines – la même colonne. Cependant, si la seule valeur possible pour la cellule (4,9,2) était 7 (au lieu de 1, 2, 7), cela ne constituerait pas un conflit. Ces cellules ne sont pas voisines.
Résumé du contrôle d'intégrité
- S'il y a des doublons, la solution de départ n'est pas réalisable.
- Si une cellule qui a besoin d’une valeur n’a aucun candidat, alors il n’y a pas de solution possible à ce casse-tête. La liste des valeurs candidates pour chaque cellule peut être utilisée pour réduire l’espace de recherche – à la fois pour le retour en arrière et l’optimisation.
- La capacité à trouver des conflits et à identifier le puzzle n'est pas réalisable – n'a pas de solution – sans un processus de recherche. De plus, il identifie les « cellules à problèmes ».
Une solution de retour en arrière : processus de recherche
Une fois les structures de données de base et la vérification de l'intégrité en place, nous tournons notre attention vers le processus de recherche. Le thème récurrent est encore une fois la mise en place de structures de données pour prendre en charge la recherche.
Suivi de la recherche
Le tableau Traqueur garde une trace des missions effectuées
- La Col 1 est le compteur
- La colonne 2 est le nombre d'options disponibles à attribuer à cette cellule
- 1 signifie 1 option disponible, 2 signifie deux options, etc.
- 0 signifie – aucune option disponible ou réinitialisation à 0 (aucune valeur attribuée) et retour en arrière
- La colonne 3 est la cellule affectée d'un numéro d'index de valeur (1 à 81)
- La colonne 4 est la valeur attribuée à la cellule dans l'historique des traces
- Une valeur de 9999 signifie que cette cellule se trouvait au moment où l'impasse a été trouvée
- La valeur d'un entier compris entre 1 et 9 inclus est la valeur attribuée à cette cellule à ce stade du processus de recherche.
- Une valeur de 0 signifie que cette cellule a besoin d'une affectation
Le réseau de trackers est utilisé pour prendre en charge le processus de recherche. Le tableau HISTOIRE DE PISTE a la même structure que le tracker mais conserve l'historique de l'ensemble du processus de recherche. Le tableau 6 contient une partie de TRACKHIST pour l'exemple 1. Il est expliqué plus en détail dans une section ultérieure.

De plus, le tableau PAV (un vecteur de vecteur), assure le suivi des valeurs précédemment attribuées à cette cellule. Cela garantit que nous ne revisiterons pas une solution qui a échoué – comme ce qui se fait dans TABU.
Il existe un processus de journalisation facultatif dans lequel le processus de recherche écrit chaque étape.
Démarrer la recherche
Une fois la comptabilité et la vérification de la cohérence effectuées, nous pouvons maintenant lancer le processus de recherche. Les étapes sont les suivantes :
- Reste-t-il des cellules qui nécessitent une valeur ? – si non, alors nous avons terminé.
- Pour chaque cellule nécessitant une valeur, recherchez toutes les options candidates pour chaque cellule. Le tableau 4 présente ces valeurs au début du processus de résolution. À chaque itération, ceci est mis à jour pour prendre en compte les valeurs attribuées aux cellules.
- Évaluez les options dans cet ordre.
- Si une cellule a des options ZÉRO, alors instituez un retour en arrière
- Recherchez toutes les cellules avec une option, sélectionnez une de ces cellules, effectuez cette affectation,
- et mettez à jour le tableau de suivi, la solution actuelle et le PAV.
- Si toutes les cellules ont plus d'une option, sélectionnez une cellule et une valeur, puis mettez à jour
- et mettre à jour le tableau de suivi, la solution actuelle et le PAV
Nous utiliserons le tableau 6 qui fait partie de l'historique du processus de résolution (appelé TRACKHIST) pour illustrer chaque étape.
Dans la première itération (CTR=1), la cellule 70 (ligne 8, colonne 7, case 9) est sélectionnée pour se voir attribuer une valeur. Il n'y a que le candidat (7) et cette valeur est attribuée à la cellule 70. De plus, la valeur 7 est ajoutée au vecteur de valeurs précédemment attribuées (PAV) pour la cellule 70.
Dans la deuxième itération, la cellule 30 reçoit la valeur 1. Cette cellule avait deux valeurs candidates. La plus petite valeur candidate est attribuée à la cellule (juste une règle arbitraire pour rendre la logique facile à suivre).
Le processus d'identification d'une cellule qui a besoin d'une valeur et d'attribution d'une valeur fonctionne correctement jusqu'à l'itération (CTR) 20. La cellule 9 a besoin d'une valeur, mais le nombre de candidats est ZÉRO. Il existe deux options :
- Il n’y a pas de solution à cette énigme.
- Nous annulons (reculons) certaines missions et prenons un autre chemin.
Nous avons recherché l'affectation de cellule la plus proche de celle-ci, où il y avait plus d'une option. Dans cet exemple, cela s'est produit à l'itération 18, où la cellule 5 reçoit la valeur 3, mais il y avait deux valeurs candidates pour la cellule 5 : les valeurs 3 et 8.
Entre la cellule 5 (CTR = 18) et la cellule 9 (CTR = 20), la cellule 8 reçoit la valeur 4 (CTR = 19). Nous remettons les cellules 8 et 5 sur la liste « besoin d'une valeur ». Ceci est capturé dans les deuxième et troisième entrées CTR=20, où la valeur est définie sur 0. La valeur 3 est conservée dans le vecteur PAV pour la cellule 5. Autrement dit, le moteur de recherche ne peut pas attribuer la valeur 3 à la cellule 5.
Le moteur de recherche redémarre pour identifier une valeur pour la cellule 5 (le 3 n'étant plus une option) et attribue la valeur 8 à la cellule 5 (CTR=21). Cela continue jusqu'à ce que toutes les cellules aient une valeur ou qu'il y ait une cellule sans option et qu'il n'y ait pas de chemin de retour en arrière. La solution est affichée dans le tableau 7.

Observez que lorsqu'il y a plus d'un candidat pour une cellule, c'est une chance pour un traitement parallèle.
Comparaison avec la solution d'optimisation MILP
En surface, la représentation du puzzle Sudoku est radicalement différente. L'approche de l'IA utilise des nombres entiers et constitue, à tous égards, une représentation plus précise et plus intuitive. De plus, les vérificateurs de bon sens fournissent des informations utiles pour créer une formulation plus forte. La représentation MILP est infinie binaires (0/1). Cependant, les binaires sont des représentations puissantes étant donné la puissance des solveurs MILP modernes.
Cependant, en interne, le solveur MILP ne conserve pas les binaires mais utilise une méthode de tableau clairsemé pour éliminer le stockage de tous les zéros. De plus, les algorithmes permettant de résoudre les binaires n’apparaissent que dans les années 1980 et 1990. L'article de 1983 de Crowder, Johnson et Padberg rapporte sur l'une des premières solutions pratiques d'optimisation avec les binaires. Ils notent l’importance d’un prétraitement intelligent et de méthodes de branchement et de liaison comme étant essentiels à une solution réussie.
L'explosion récente de l'utilisation de la programmation par contraintes et des logiciels tels que solveur local a clairement montré l'importance d'utiliser les méthodes d'IA avec les méthodes d'optimisation originales telles que la programmation linéaire et les moindres carrés.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku

