Introduction
L’avènement de l’IA et de l’apprentissage automatique a révolutionné la façon dont nous interagissons avec l’information, en la rendant plus facile à récupérer, à comprendre et à utiliser. Dans ce guide pratique, nous explorons la création d'un assistant de questions-réponses sophistiqué optimisé par LLamA2 et LLamAIndex, exploitant des modèles de langage et des cadres d'indexation de pointe pour naviguer sans effort dans une mer de documents PDF. Ce didacticiel est conçu pour donner aux développeurs, aux scientifiques des données et aux passionnés de technologie les outils et les connaissances nécessaires pour créer un système de génération de récupération augmentée (RAG) qui repose sur les épaules des géants du domaine de la PNL.
Dans notre quête pour démystifier la création d'un assistant questions-réponses basé sur l'IA, ce guide constitue un pont entre des concepts théoriques complexes et leur application pratique dans des scénarios du monde réel. En intégrant la compréhension avancée du langage de LLamA2 aux capacités efficaces de récupération d'informations de LLamAIndex, nous visons à construire un système qui répond aux questions avec précision et approfondit notre compréhension du potentiel et des défis dans le domaine de la PNL. Cet article constitue une feuille de route complète pour les passionnés et les professionnels, mettant en évidence la synergie entre les modèles de pointe et les exigences en constante évolution des technologies de l'information.

Objectifs d'apprentissage
- Développez un système RAG en utilisant le modèle LLamA2 de Hugging Face.
- Intégrez plusieurs documents PDF.
- Indexez les documents pour une récupération efficace.
- Créez un système de requêtes.
- Créez un assistant robuste capable de répondre à diverses questions.
- Concentrez-vous sur la mise en œuvre pratique plutôt que sur les seuls aspects théoriques.
- Participez à du codage pratique et à des applications du monde réel.
- Rendre le monde complexe de la PNL accessible et engageant.
Table des matières
Modèle LLamA2
LLamA2 est un phare d'innovation dans le traitement du langage naturel, repoussant les limites de ce qui est possible avec les modèles de langage. Son architecture, conçue à la fois pour l'efficience et l'efficacité, permet une compréhension et une génération sans précédent de textes de type humain. Contrairement à ses prédécesseurs comme BERT et GPT, LLamA2 propose une approche plus nuancée du traitement du langage, ce qui le rend particulièrement apte aux tâches nécessitant une compréhension approfondie, telles que la réponse à des questions. Son utilité dans diverses tâches de PNL, du résumé à la traduction, met en valeur sa polyvalence et sa capacité à relever des défis linguistiques complexes.

Comprendre LLamAIndex
L'indexation est l'épine dorsale de tout système efficace de recherche d'informations. LLamAIndex, un framework conçu pour l'indexation et l'interrogation de documents, se distingue en offrant un moyen transparent de gérer de vastes collections de documents. Il ne s'agit pas seulement de stocker des informations ; il s'agit de le rendre accessible et récupérable en un clin d'œil.

L'importance de LLamAIndex ne peut être surestimée, car elle permet le traitement des requêtes en temps réel sur de vastes bases de données, garantissant ainsi que notre assistant Q&A peut fournir des réponses rapides et précises tirées d'une base de connaissances complète.
Tokenisation et intégrations
La première étape pour comprendre les modèles de langage consiste à décomposer le texte en éléments gérables, un processus connu sous le nom de tokenisation. Cette tâche fondamentale est cruciale pour préparer les données en vue d’un traitement ultérieur. Après la tokenisation, le concept d'intégration entre en jeu, traduisant des mots et des phrases en vecteurs numériques.
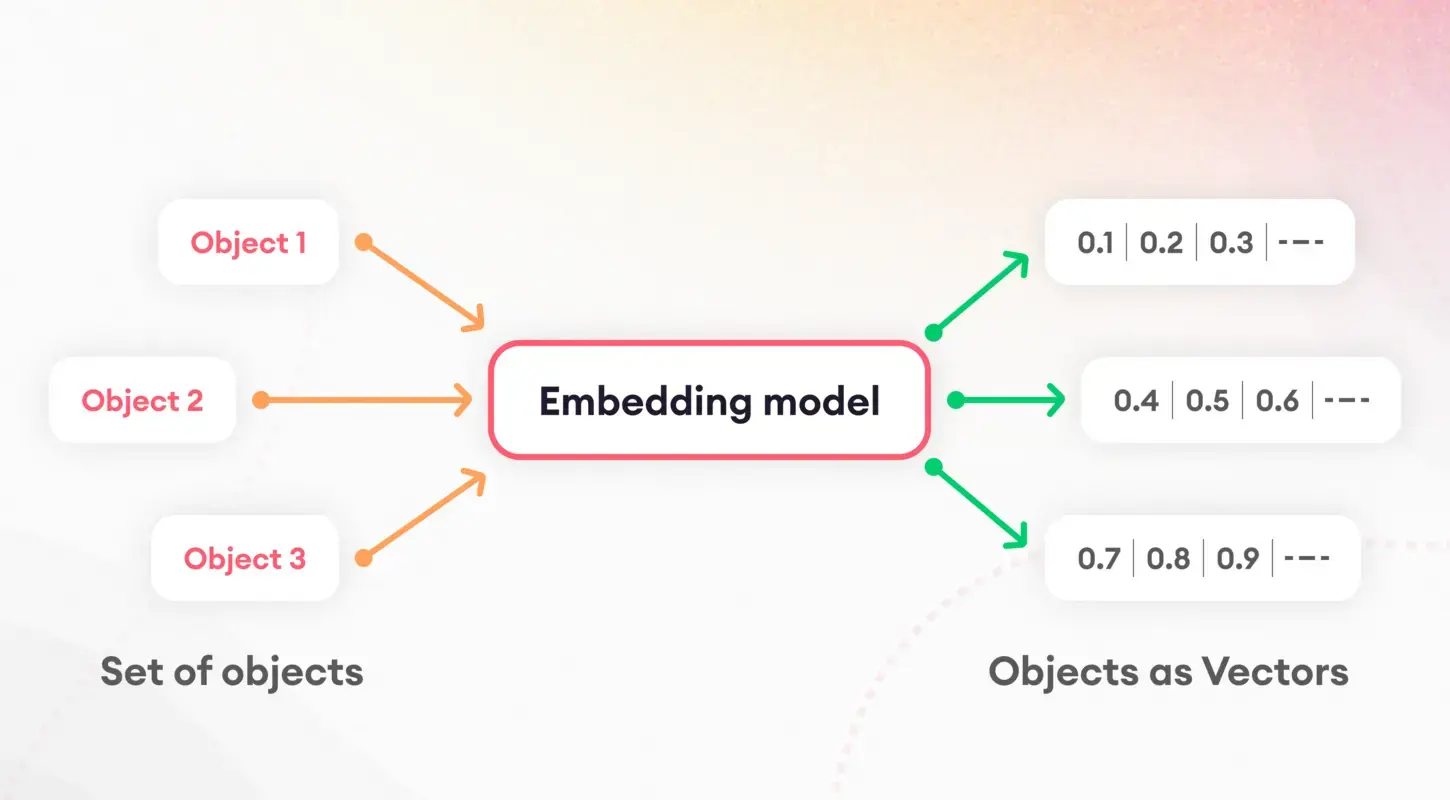
Ces intégrations capturent l'essence des caractéristiques linguistiques, permettant aux modèles de discerner et d'utiliser les propriétés sémantiques sous-jacentes du texte. En particulier, les intégrations de phrases jouent un rôle central dans des tâches telles que la similarité et la récupération de documents, constituant la base de notre stratégie d'indexation.
Quantification du modèle
La quantification du modèle présente une stratégie pour améliorer les performances et l'efficacité de notre assistant Q&A. En réduisant la précision des calculs numériques du modèle, nous pouvons réduire considérablement sa taille et accélérer les temps d'inférence. Tout en introduisant un compromis entre précision et efficacité, ce processus est particulièrement utile dans les environnements aux ressources limitées tels que les appareils mobiles ou les applications Web. Grâce à une application minutieuse, la quantification nous permet de maintenir des niveaux élevés de précision tout en bénéficiant d’une latence et d’exigences de stockage réduites.
ServiceContext et moteur de requête
Le ServiceContext au sein de LLamAIndex est une plate-forme centrale pour la gestion des ressources et des configurations, garantissant le fonctionnement fluide et efficace de notre système. La colle maintient notre application ensemble, permettant une intégration transparente entre les Modèle LLamA2, le processus d'intégration et les documents indexés. D'un autre côté, le moteur de requêtes est le cheval de bataille qui traite les requêtes des utilisateurs, en exploitant les données indexées pour récupérer rapidement les informations pertinentes. Cette double configuration garantit que notre assistant Q&A peut facilement gérer des requêtes complexes, fournissant des réponses rapides et précises aux utilisateurs.
Implémentation
Passons à la mise en œuvre. Veuillez noter que j'ai utilisé Google Colab pour créer ce projet.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexCes commandes préparent le terrain en installant les bibliothèques nécessaires, notamment des transformateurs pour l'interaction du modèle et des phrases_transformers pour les intégrations. L'installation de llama_index est cruciale pour notre framework d'indexation.
Ensuite, nous initialisons nos composants (assurez-vous de créer un dossier nommé « données » dans la section Fichiers de Google Colab, puis téléchargez le PDF dans le dossier) :
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptAprès avoir configuré notre environnement et lu les documents, nous créons une invite système pour guider les réponses du modèle LLamA2. Ce modèle joue un rôle déterminant pour garantir que les résultats du modèle correspondent à nos attentes en matière d'exactitude et de pertinence.
!huggingface-cli login
La commande ci-dessus est une passerelle pour accéder au vaste référentiel de modèles de Hugging Face. Il nécessite un jeton pour l'authentification.
Vous devez visiter le lien suivant : Étreindre le visage (assurez-vous d'abord de vous connecter à Hugging Face), puis créez un nouveau jeton, fournissez un nom pour le projet, sélectionnez Type comme lu, puis cliquez sur Générer un jeton.
Cette étape souligne l’importance de sécuriser et de personnaliser votre environnement de développement.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)Ici, nous initialisons le modèle LLamA2 avec des paramètres spécifiques adaptés à notre système de questions-réponses. Cette configuration met en valeur la polyvalence du modèle et sa capacité à s'adapter à différents contextes et applications.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))Le choix du modèle d'intégration est essentiel pour capturer l'essence sémantique de nos documents. En utilisant Sentence Transformers, nous garantissons que notre système peut évaluer avec précision la similarité et la pertinence du contenu textuel, améliorant ainsi l'efficacité du processus d'indexation.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)Le ServiceContext est instancié avec les paramètres par défaut, reliant notre modèle LLamA2 et intégrant le modèle dans un cadre cohérent. Cette étape garantit que tous les composants du système sont harmonisés et prêts pour les opérations d'indexation et d'interrogation.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()Ces lignes marquent le point culminant de notre processus de configuration, où nous indexons nos documents et préparons le moteur de requête. Cette configuration est essentielle pour la transition de la préparation des données vers des informations exploitables, permettant à notre assistant Q&A de répondre aux requêtes basées sur le contenu indexé.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)Enfin, nous avons testé notre système en lui demandant des résumés et des informations dérivées de notre collection de documents. Cette interaction démontre l'utilité pratique de notre assistant Q&A et présente l'intégration transparente de LLamA2, LLamAIndex et du logiciel sous-jacent. Technologies PNL qui le rendent possible.
Sortie :

Implications éthiques et juridiques
Le développement de systèmes de questions et réponses basés sur l’IA met au premier plan plusieurs considérations éthiques et juridiques. Il est crucial de remédier aux biais potentiels dans les données de formation, tout en garantissant l’équité et la neutralité des réponses. De plus, le respect des réglementations sur la confidentialité des données est primordial, car ces systèmes traitent souvent des informations sensibles. Les développeurs doivent relever ces défis avec diligence et intégrité, en s'engageant à respecter des principes éthiques qui protègent les utilisateurs et l'intégrité des informations fournies.
Orientations futures et défis
Le domaine des systèmes de questions-réponses regorge d’opportunités d’innovation, depuis les interactions multimodales jusqu’aux applications spécifiques à un domaine. Cependant, ces avancées comportent leurs propres défis, notamment la mise à l'échelle pour s'adapter à de vastes collections de documents et la garantie de la diversité des requêtes des utilisateurs. Le développement et le perfectionnement continus de modèles comme LLamA2 et de cadres d'indexation comme LLamAIndex sont essentiels pour surmonter ces obstacles et repousser les limites de ce qui est possible en PNL.
Études de cas et exemples
Les implémentations concrètes de systèmes de questions-réponses, tels que les robots de service client et les outils pédagogiques, soulignent la polyvalence et l'impact de technologies telles que LLamA2 et LLamAIndex. Ces études de cas démontrent les applications pratiques de l’IA dans divers secteurs et mettent en évidence les réussites et les leçons apprises, fournissant ainsi des informations précieuses pour les développements futurs.
Conclusion
Ce guide a parcouru le paysage de la création d'un assistant questions-réponses basé sur PDF, depuis les concepts fondamentaux de LLamA2 et LLamAIndex jusqu'aux étapes pratiques de mise en œuvre. Alors que nous continuons à explorer et à étendre les capacités de l’IA en matière de récupération et de traitement de l’information, le potentiel de transformation de notre interaction avec la connaissance est illimité. Forts de ces outils et informations, le voyage vers des systèmes plus intelligents et plus réactifs ne fait que commencer.
Faits marquants
- Révolutionner l'interaction avec l'information : l'intégration de l'IA et de l'apprentissage automatique, illustrée par LLamA2 et LLamAIndex, a transformé la façon dont nous accédons et utilisons l'information, ouvrant la voie à des assistants de questions-réponses sophistiqués capables de parcourir sans effort de vastes collections de documents PDF.
- Pont pratique entre la théorie et l'application : ce guide comble le fossé entre les concepts théoriques et la mise en œuvre pratique, permettant aux développeurs et aux passionnés de technologie de créer des systèmes de génération de récupération augmentée (RAG) qui exploitent des modèles NLP et des cadres d'indexation de pointe.
- Importance d'une indexation efficace : LLamAIndex joue un rôle crucial dans la récupération efficace des informations en indexant de vastes collections de documents. Cela garantit des réponses rapides et précises aux requêtes des utilisateurs et améliore la fonctionnalité globale de l'assistant Q&A.
- Optimisation des performances et de l'efficacité : des techniques telles que la quantification de modèle améliorent les performances et l'efficacité des assistants Q&A, permettant de réduire la latence et les besoins de stockage sans compromettre la précision.
- Considérations éthiques et orientations futures : le développement de systèmes de questions et réponses basés sur l'IA nécessite de prendre en compte les implications éthiques et juridiques, notamment l'atténuation des préjugés et la confidentialité des données. À l’avenir, les progrès des systèmes de questions-réponses présentent des opportunités d’innovation tout en posant également des défis en termes d’évolutivité et de diversité des requêtes des utilisateurs.
Questions fréquemment posées
Rép. LLamA2 offre une approche plus nuancée du traitement du langage, permettant des tâches de compréhension approfondie telles que la réponse à des questions. Son architecture donne la priorité à l'efficience et à l'efficacité, ce qui la rend polyvalente sur diverses tâches de PNL.
Rép. LLamAIndex est un framework d'indexation et d'interrogation de documents, facilitant le traitement des requêtes en temps réel sur de vastes bases de données. Il garantit que les assistants questions-réponses peuvent récupérer rapidement les informations pertinentes à partir de bases de connaissances complètes.
Rép. Les intégrations, en particulier les intégrations de phrases, capturent l'essence sémantique du contenu textuel, permettant une évaluation précise de la similarité et de la pertinence. Cela améliore l'efficacité du processus d'indexation, améliorant ainsi la capacité de l'assistant à fournir des réponses pertinentes.
Rép. La quantification du modèle optimise les performances et l'efficacité en réduisant la taille des calculs numériques, diminuant ainsi les besoins en latence et en stockage. Tout en introduisant un compromis entre précision et efficacité, cette solution s'avère précieuse dans les environnements aux ressources limitées.
Rép. Les développeurs doivent remédier aux biais potentiels dans les données de formation, garantir l'équité et la neutralité des réponses et respecter les réglementations sur la confidentialité des données. Le respect des principes éthiques protège les utilisateurs et maintient l’intégrité des informations fournies par l’assistant Q&A.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

