Introduction
Dans le sujet passionnant de la vision par ordinateur, où les images contiennent de nombreux secrets et informations, distinguer et mettre en évidence les éléments est crucial. La segmentation d'images, le processus de division d'images en régions ou objets significatifs, est essentielle dans diverses applications allant de l'imagerie médicale à la conduite autonome et à la reconnaissance d'objets. La segmentation précise et automatique a longtemps été un défi, les approches traditionnelles étant souvent insuffisantes en termes de précision et d'efficacité. Entrez dans l'architecture UNET, une méthode intelligente qui a révolutionné la segmentation des images. Avec sa conception simple et ses techniques inventives, UNET a ouvert la voie à des résultats de segmentation plus précis et plus robustes. Que vous soyez un nouveau venu dans le domaine passionnant de la vision par ordinateur ou un praticien expérimenté cherchant à améliorer vos capacités de segmentation, cet article de blog approfondi dévoilera les complexités d'UNET et fournira une compréhension complète de son architecture, de ses composants et de son utilité.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Comprendre le réseau de neurones à convolution
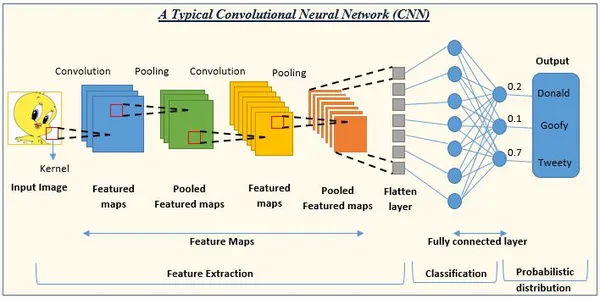
Les CNN sont un modèle d'apprentissage en profondeur fréquemment utilisé dans les tâches de vision par ordinateur, notamment la classification d'images, la reconnaissance d'objets et la segmentation d'images. Les CNN sont principalement destinés à apprendre et à extraire des informations pertinentes à partir d'images, ce qui les rend extrêmement utiles dans l'analyse de données visuelles.
Les composants critiques des CNN
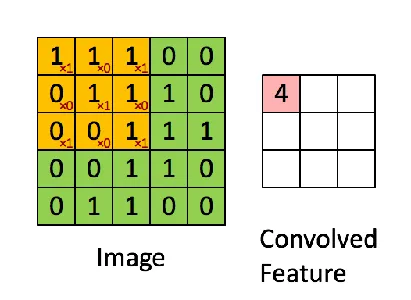
- Couches convolutives : Les CNN comprennent une collection de filtres apprenables (noyaux) convolués avec l'image d'entrée ou les cartes de caractéristiques. Chaque filtre applique une multiplication et une sommation élément par élément pour produire une carte de caractéristiques mettant en évidence des modèles spécifiques ou des caractéristiques locales dans l'entrée. Ces filtres peuvent capturer de nombreux éléments visuels, tels que les bords, les coins et les textures.
- Regrouper les couches : Créez les cartes d'entités par les couches convolutives qui sont sous-échantillonnées à l'aide de couches de regroupement. La mise en commun réduit les dimensions spatiales des cartes d'entités tout en conservant les informations les plus critiques, en réduisant la complexité de calcul des couches successives et en rendant le modèle plus résistant aux fluctuations d'entrée. L'opération de regroupement la plus courante est le regroupement maximal, qui prend la valeur la plus significative dans un voisinage donné.
- Fonctions d'activation : Introduisez la non-linéarité dans le modèle CNN à l'aide de fonctions d'activation. Appliquez-les aux sorties des couches convolutionnelles ou de regroupement élément par élément, permettant au réseau de comprendre les associations complexes et de prendre des décisions non linéaires. En raison de sa simplicité et de son efficacité pour résoudre le problème du gradient de fuite, la fonction d'activation de l'unité linéaire rectifiée (ReLU) est courante dans les CNN.
- Couches entièrement connectées : Les couches entièrement connectées, également appelées couches denses, utilisent les entités récupérées pour terminer l'opération de classification ou de régression finale. Ils connectent chaque neurone d'une couche à chaque neurone de la suivante, permettant au réseau d'apprendre des représentations globales et de faire des jugements de haut niveau basés sur les entrées combinées des couches précédentes.
Le réseau commence par une pile de couches convolutives pour capturer les fonctionnalités de bas niveau, suivies de couches de regroupement. Les couches convolutives plus profondes apprennent des caractéristiques de niveau supérieur à mesure que le réseau évolue. Enfin, utilisez une ou plusieurs couches complètes pour l'opération de classification ou de régression.
Besoin d'un réseau entièrement connecté
Les CNN traditionnels sont généralement destinés aux travaux de classification d'images dans lesquels une seule étiquette est attribuée à l'ensemble de l'image d'entrée. D'autre part, les architectures CNN traditionnelles ont des problèmes avec des tâches plus fines comme la segmentation sémantique, dans laquelle chaque pixel d'une image doit être trié en différentes classes ou régions. Les réseaux entièrement convolutifs (FCN) entrent en jeu ici.
Limites des architectures CNN traditionnelles dans les tâches de segmentation
Perte d'informations spatiales : Les CNN traditionnels utilisent des couches de regroupement pour réduire progressivement la dimensionnalité spatiale des cartes d'entités. Bien que ce sous-échantillonnage aide à capturer des caractéristiques de haut niveau, il entraîne une perte d'informations spatiales, ce qui rend difficile la détection et la division précises des objets au niveau du pixel.
Taille d'entrée fixe : Les architectures CNN sont souvent conçues pour accepter des images d'une taille spécifique. Cependant, les images d'entrée peuvent avoir différentes dimensions dans les tâches de segmentation, ce qui rend les entrées de taille variable difficiles à gérer avec des CNN typiques.
Précision de localisation limitée : Les CNN traditionnels utilisent souvent des couches entièrement connectées à la fin pour fournir un vecteur de sortie de taille fixe pour la classification. Parce qu'ils ne conservent pas d'informations spatiales, ils ne peuvent pas localiser avec précision des objets ou des régions dans l'image.
Réseaux entièrement convolutifs (FCN) comme solution de segmentation sémantique
En travaillant exclusivement sur des couches convolutives et en maintenant les informations spatiales sur l'ensemble du réseau, les réseaux entièrement convolutifs (FCN) répondent aux contraintes des architectures CNN classiques dans les tâches de segmentation. Les FCN sont destinés à faire des prédictions pixel par pixel, chaque pixel de l'image d'entrée étant affecté à une étiquette ou une classe. Les FCN permettent la construction d'une carte de segmentation dense avec des prévisions au niveau des pixels en suréchantillonnant les cartes de caractéristiques. Les convolutions transposées (également appelées déconvolutions ou couches de suréchantillonnage) sont utilisées pour remplacer les couches complètement liées après la conception CNN. La résolution spatiale des cartes de caractéristiques est augmentée par des convolutions transposées, ce qui leur permet d'avoir la même taille que l'image d'entrée.
Lors du suréchantillonnage, les FCN utilisent généralement des connexions de saut, en contournant des couches spécifiques et en reliant directement les cartes d'entités de niveau inférieur avec celles de niveau supérieur. Ces relations de saut aident à préserver les détails fins et les informations contextuelles, améliorant ainsi la précision de la localisation des régions segmentées. Les FCN sont extrêmement efficaces dans diverses applications de segmentation, notamment la segmentation d'images médicales, l'analyse de scènes et la segmentation d'instances. Il peut désormais gérer des images d'entrée de différentes tailles, fournir des prédictions au niveau des pixels et conserver des informations spatiales sur le réseau en exploitant les FCN pour la segmentation sémantique.
Segmentation d'image
La segmentation des images est un processus fondamental dans vision par ordinateur dans lequel une image est divisée en plusieurs parties ou segments significatifs et séparés. Contrairement à la classification d'image, qui fournit une seule étiquette à une image complète, la segmentation ajoute des étiquettes à chaque pixel ou groupe de pixels, divisant essentiellement l'image en parties sémantiquement significatives. La segmentation d'image est importante car elle permet une compréhension plus détaillée du contenu d'une image. Nous pouvons extraire des informations considérables sur les limites, les formes, les tailles et les relations spatiales des objets en segmentant une image en plusieurs parties. Cette analyse fine est essentielle dans diverses tâches de vision par ordinateur, permettant des applications améliorées et prenant en charge des interprétations de données visuelles de niveau supérieur.

Comprendre l'architecture UNET
Les technologies traditionnelles de segmentation d'image, telles que l'annotation manuelle et la classification par pixel, présentent divers inconvénients qui les rendent inutiles et difficiles pour des travaux de segmentation précis et efficaces. En raison de ces contraintes, des solutions plus avancées, comme le UNET architecture, ont été développés. Examinons les défauts des méthodes précédentes et pourquoi UNET a été créé pour surmonter ces problèmes.
- Annotation manuelle : L'annotation manuelle implique l'esquisse et le marquage des limites de l'image ou des régions d'intérêt. Bien que cette méthode produise des résultats de segmentation fiables, elle prend du temps, demande beaucoup de travail et est susceptible d'erreurs humaines. L'annotation manuelle n'est pas évolutive pour les grands ensembles de données, et le maintien de la cohérence et de l'accord inter-annotateurs est difficile, en particulier dans les tâches de segmentation sophistiquées.
- Classification par pixel : Une autre approche courante est la classification par pixel, dans laquelle chaque pixel d'une image est classé indépendamment, généralement à l'aide d'algorithmes tels que des arbres de décision, des machines à vecteurs de support (SVM) ou des forêts aléatoires. La catégorisation par pixel, en revanche, a du mal à saisir le contexte global et les dépendances entre les pixels environnants, ce qui entraîne des problèmes de sur- ou de sous-segmentation. Il ne peut pas prendre en compte les relations spatiales et échoue souvent à offrir des limites d'objet précises.
Surmonte les défis
L'architecture UNET a été développée pour répondre à ces limitations et surmonter les défis rencontrés par les approches traditionnelles de la segmentation d'images. Voici comment UNET s'attaque à ces problèmes :
- Apprentissage de bout en bout : UNET utilise une technique d'apprentissage de bout en bout, ce qui signifie qu'il apprend à segmenter des images directement à partir de paires entrée-sortie sans annotation de l'utilisateur. UNET peut automatiquement extraire les fonctionnalités clés et exécuter une segmentation précise en s'entraînant sur un grand ensemble de données étiquetées, éliminant ainsi le besoin d'annotations manuelles à forte intensité de main-d'œuvre.
- Architecture entièrement convolutive : UNET est basé sur une architecture entièrement convolutive, ce qui implique qu'il est entièrement composé de couches convolutives et n'inclut aucune couche entièrement connectée. Cette architecture permet à UNET de fonctionner sur des images d'entrée de n'importe quelle taille, augmentant sa flexibilité et son adaptabilité à diverses tâches de segmentation et variations d'entrée.
- Architecture en U avec Skip Connections : L'architecture caractéristique du réseau comprend un chemin d'encodage (chemin de contraction) et un chemin de décodage (chemin d'expansion), lui permettant de collecter des informations locales et un contexte global. Les connexions de saut comblent l'écart entre les chemins d'encodage et de décodage, en conservant les informations critiques des couches précédentes et en permettant une segmentation plus précise.
- Informations contextuelles et localisation : Les connexions de saut sont utilisées par UNET pour agréger des cartes d'entités multi-échelles à partir de plusieurs couches, permettant au réseau d'absorber des informations contextuelles et de capturer des détails à différents niveaux d'abstraction. Cette intégration d'informations améliore la précision de la localisation, permettant des limites d'objet exactes et des résultats de segmentation précis.
- Augmentation et régularisation des données : UNET utilise des techniques d'augmentation et de régularisation des données pour améliorer sa résilience et sa capacité de généralisation pendant la formation. Pour augmenter la diversité des données d'entraînement, l'augmentation des données implique l'ajout de nombreuses transformations aux images d'entraînement, telles que des rotations, des retournements, des mises à l'échelle et des déformations. Les techniques de régularisation telles que l'abandon et la normalisation par lots empêchent le surajustement et améliorent les performances du modèle sur des données inconnues.
Présentation de l'architecture UNET
UNET est une architecture de réseau neuronal entièrement convolutionnel (FCN) conçue pour les applications de segmentation d'images. Il a été proposé pour la première fois en 2015 par Olaf Ronneberger, Philipp Fischer et Thomas Brox. UNET est fréquemment utilisé pour sa précision dans la segmentation des images et est devenu un choix populaire dans diverses applications d'imagerie médicale. UNET combine un chemin d'encodage, également appelé chemin de contraction, avec un chemin de décodage appelé chemin d'expansion. L'architecture tire son nom de son aspect en forme de U lorsqu'elle est représentée dans un diagramme. Grâce à cette architecture en forme de U, le réseau peut enregistrer à la fois les caractéristiques locales et le contexte global, ce qui donne des résultats de segmentation exacts.
Composants critiques de l'architecture UNET
- Chemin d'accès contractuel (chemin d'encodage) : Le chemin contractuel d'UNET comprend des couches convolutives suivies d'opérations de mise en commun maximales. Cette méthode capture des caractéristiques de bas niveau à haute résolution en réduisant progressivement les dimensions spatiales de l'image d'entrée.
- Chemin d'expansion (chemin de décodage) : Les convolutions transposées, également appelées déconvolutions ou couches de suréchantillonnage, sont utilisées pour suréchantillonner les cartes de caractéristiques à partir du chemin de codage dans le chemin d'expansion UNET. La résolution spatiale des cartes d'entités est augmentée pendant la phase de suréchantillonnage, permettant au réseau de reconstituer une carte de segmentation dense.
- Ignorer les connexions : Les connexions de saut sont utilisées dans UNET pour connecter les couches correspondantes des chemins d'encodage aux chemins de décodage. Ces liens permettent au réseau de collecter des données locales et globales. Le réseau conserve les informations spatiales essentielles et améliore la précision de la segmentation en intégrant des cartes d'entités de couches antérieures à celles de la route de décodage.
- Enchaînement: La concaténation est couramment utilisée pour implémenter des connexions de saut dans UNET. Les cartes de caractéristiques provenant du chemin de codage sont concaténées avec les cartes de caractéristiques suréchantillonnées provenant du chemin de décodage pendant la procédure de suréchantillonnage. Cette concaténation permet au réseau d'incorporer des informations multi-échelles pour une segmentation appropriée, en exploitant le contexte de haut niveau et les fonctionnalités de bas niveau.
- Couches entièrement convolutionnelles : UNET comprend des couches convolutionnelles sans couches entièrement connectées. Cette architecture convolutive permet à UNET de gérer des images de tailles illimitées tout en préservant les informations spatiales sur le réseau, ce qui le rend flexible et adaptable à diverses tâches de segmentation.
Le chemin d'encodage, ou le chemin de contrat, est un composant essentiel de l'architecture UNET. Il est chargé d'extraire des informations de haut niveau de l'image d'entrée tout en réduisant progressivement les dimensions spatiales.
Couches convolutionnelles
Le processus de codage commence par un ensemble de couches convolutionnelles. Les couches convolutives extraient des informations à plusieurs échelles en appliquant un ensemble de filtres apprenables à l'image d'entrée. Ces filtres fonctionnent sur le champ récepteur local, permettant au réseau de capturer des modèles spatiaux et des caractéristiques mineures. Avec chaque couche convolutive, la profondeur des cartes d'entités augmente, permettant au réseau d'apprendre des représentations plus complexes.
Fonction d'activation
Après chaque couche convolutionnelle, une fonction d'activation telle que l'unité linéaire rectifiée (ReLU) est appliquée élément par élément pour induire une non-linéarité dans le réseau. La fonction d'activation aide le réseau à apprendre les corrélations non linéaires entre les images d'entrée et les caractéristiques récupérées.
Mise en commun des couches
Les couches de regroupement sont utilisées après les couches convolutives pour réduire la dimensionnalité spatiale des cartes d'entités. Les opérations, telles que le regroupement maximal, divisent les cartes d'entités en régions qui ne se chevauchent pas et ne conservent que la valeur maximale à l'intérieur de chaque zone. Il réduit la résolution spatiale en sous-échantillonnant les cartes d'entités, permettant au réseau de capturer des données plus abstraites et de niveau supérieur.
Le travail du chemin d'encodage consiste à capturer des caractéristiques à différentes échelles et niveaux d'abstraction de manière hiérarchique. Le processus d'encodage se concentre sur l'extraction du contexte global et des informations de haut niveau à mesure que les dimensions spatiales diminuent.
Ignorer les connexions
La disponibilité de connexions de saut qui relient les niveaux appropriés du chemin de codage au chemin de décodage est l'une des caractéristiques distinctives de l'architecture UNET. Ces liens de saut sont essentiels au maintien des données clés pendant le processus d'encodage.
Les cartes d'entités des couches précédentes collectent des détails locaux et des informations détaillées pendant le chemin d'encodage. Ces cartes de caractéristiques sont concaténées avec les cartes de caractéristiques suréchantillonnées dans le pipeline de décodage à l'aide de connexions de saut. Cela permet au réseau d'intégrer des données multi-échelles, des fonctionnalités de bas niveau et un contexte de haut niveau dans le processus de segmentation.
En conservant les informations spatiales des couches précédentes, UNET peut localiser de manière fiable les objets et conserver des détails plus fins dans les résultats de segmentation. Les connexions de saut d'UNET aident à résoudre le problème de la perte d'informations causée par le sous-échantillonnage. Les liens de saut permettent une meilleure intégration des informations locales et globales, améliorant ainsi les performances globales de segmentation.
Pour résumer, l'approche de codage UNET est essentielle pour capturer des caractéristiques de haut niveau et réduire les dimensions spatiales de l'image d'entrée. Le chemin de codage extrait progressivement des représentations abstraites via des couches convolutionnelles, des fonctions d'activation et des couches de regroupement. En intégrant les caractéristiques locales et le contexte global, l'introduction de liens de saut permet de préserver les informations spatiales critiques, facilitant ainsi des résultats de segmentation fiables.
Chemin de décodage dans UNET
Un composant essentiel de l'architecture UNET est le chemin de décodage, également appelé chemin d'expansion. Il est responsable du suréchantillonnage des cartes de caractéristiques du chemin d'encodage et de la construction du masque de segmentation final.
Couches de suréchantillonnage (convolutions transposées)
Pour augmenter la résolution spatiale des cartes de caractéristiques, la méthode de décodage UNET comprend des couches de suréchantillonnage, souvent effectuées à l'aide de convolutions ou de déconvolutions transposées. Les circonvolutions transposées sont essentiellement l'opposé des circonvolutions régulières. Ils améliorent les dimensions spatiales plutôt que de les diminuer, permettant un suréchantillonnage. En construisant un noyau clairsemé et en l'appliquant à la carte de caractéristiques d'entrée, les convolutions transposées apprennent à suréchantillonner les cartes de caractéristiques. Le réseau apprend à combler les lacunes entre les emplacements spatiaux actuels au cours de ce processus, augmentant ainsi la résolution des cartes d'entités.
Enchaînement
Les cartes d'entités des couches précédentes sont concaténées avec les cartes d'entités suréchantillonnées pendant la phase de décodage. Cette concaténation permet au réseau d'agréger des informations multi-échelles pour une segmentation correcte, en tirant parti du contexte de haut niveau et des fonctionnalités de bas niveau. Outre le suréchantillonnage, le chemin de décodage UNET inclut des connexions de saut à partir des niveaux comparables du chemin de codage.
Le réseau peut récupérer et intégrer des caractéristiques à grain fin perdues pendant le codage en concaténant des cartes de caractéristiques à partir de connexions de saut. Il permet une localisation et une délimitation plus précises des objets dans le masque de segmentation.
Le processus de décodage dans UNET reconstruit une carte de segmentation dense qui s'adapte à la résolution spatiale de l'image d'entrée en suréchantillonnant progressivement les cartes d'entités et en incluant des liens de saut.
La fonction du chemin de décodage est de récupérer les informations spatiales perdues lors du chemin de codage et d'affiner les résultats de segmentation. Il combine des détails d'encodage de bas niveau avec un contexte de haut niveau obtenu à partir des couches de suréchantillonnage pour fournir un masque de segmentation précis et complet.
UNET peut augmenter la résolution spatiale des cartes de caractéristiques en utilisant des convolutions transposées dans le processus de décodage, les suréchantillonnant ainsi pour correspondre à la taille de l'image d'origine. Les convolutions transposées aident le réseau à générer un masque de segmentation dense et à grain fin en apprenant à combler les lacunes et à élargir les dimensions spatiales.
En résumé, le processus de décodage dans UNET reconstruit le masque de segmentation en améliorant la résolution spatiale des cartes d'entités via des couches de suréchantillonnage et des connexions de saut. Les convolutions transposées sont essentielles dans cette phase car elles permettent au réseau de suréchantillonner les cartes de caractéristiques et de créer un masque de segmentation détaillé qui correspond à l'image d'entrée d'origine.
Contraction et expansion des chemins dans UNET
L'architecture UNET suit une structure "encodeur-décodeur", où le chemin de contraction représente l'encodeur et le chemin d'expansion représente le décodeur. Cette conception ressemble à l'encodage d'informations sous une forme compressée, puis à leur décodage pour reconstruire les données d'origine.
Chemin contractuel (encodeur)
L'encodeur dans UNET est le chemin contractuel. Il extrait le contexte et comprime l'image d'entrée en diminuant progressivement les dimensions spatiales. Cette méthode comprend des couches convolutives suivies de procédures de regroupement telles que le regroupement maximal pour sous-échantillonner les cartes d'entités. Le chemin contractuel est responsable de l'obtention de caractéristiques de haut niveau, de l'apprentissage du contexte global et de la diminution de la résolution spatiale. Il se concentre sur la compression et l'abstraction de l'image d'entrée, capturant efficacement les informations pertinentes pour la segmentation.
Chemin d'expansion (décodeur)
Le décodeur dans UNET est le chemin d'expansion. En suréchantillonnant les cartes de caractéristiques à partir du chemin contractuel, il récupère les informations spatiales et génère la carte de segmentation finale. L'itinéraire d'expansion comprend des couches de suréchantillonnage, souvent réalisées avec des convolutions ou des déconvolutions transposées pour augmenter la résolution spatiale des cartes de caractéristiques. Le chemin d'expansion reconstruit les dimensions spatiales d'origine via des connexions de saut en intégrant les cartes d'entités suréchantillonnées avec les cartes équivalentes du chemin de contraction. Cette méthode permet au réseau de récupérer des fonctionnalités détaillées et de localiser correctement les éléments.
La conception de l'UNET capture le contexte mondial et les détails locaux en mélangeant les voies contractuelles et en expansion. Le chemin de contraction comprime l'image d'entrée dans une représentation compacte, a décidé de construire une carte de segmentation détaillée par le chemin d'expansion. La voie d'expansion concerne le décodage de la représentation compressée en une carte de segmentation dense et précise. Il reconstruit les informations spatiales manquantes et affine les résultats de la segmentation. Cette structure d'encodeur-décodeur permet une segmentation de précision à l'aide d'un contexte de haut niveau et d'informations spatiales à grain fin.
En résumé, les itinéraires de contraction et d'expansion d'UNET ressemblent à une structure « encodeur-décodeur ». Le chemin d'expansion est le décodeur, récupérant les informations spatiales et générant la carte de segmentation finale. En revanche, le chemin de contraction sert d'encodeur, capturant le contexte et compressant l'image d'entrée. Cette architecture permet à UNET d'encoder et de décoder efficacement les informations, permettant une segmentation d'image précise et approfondie.
Ignorer les connexions dans UNET
Les connexions de saut sont essentielles à la conception UNET car elles permettent aux informations de voyager entre les chemins de contraction (codage) et d'expansion (décodage). Ils sont essentiels pour maintenir les informations spatiales et améliorer la précision de la segmentation.
Préserver les informations spatiales
Certaines informations spatiales peuvent être perdues pendant le chemin de codage lorsque les cartes d'entités subissent des procédures de sous-échantillonnage telles que la mise en commun maximale. Cette perte d'informations peut entraîner une précision de localisation moindre et une perte de détails fins dans le masque de segmentation.
En établissant des connexions directes entre les couches correspondantes dans les processus de codage et de décodage, les connexions de saut aident à résoudre ce problème. Les connexions de saut protègent les informations spatiales vitales qui seraient autrement perdues lors du sous-échantillonnage. Ces connexions permettent aux informations du flux de codage d'éviter le sous-échantillonnage et d'être transmises directement au chemin de décodage.
Fusion d'informations multi-échelles
Les connexions de saut permettent la fusion d'informations multi-échelles à partir de nombreuses couches de réseau. Les niveaux ultérieurs du processus de codage capturent des informations contextuelles et sémantiques de haut niveau, tandis que les couches antérieures capturent des détails locaux et des informations à grain fin. UNET peut combiner avec succès des informations locales et globales en connectant ces cartes de caractéristiques du chemin de codage aux couches équivalentes dans le chemin de décodage. Cette intégration d'informations multi-échelles améliore globalement la précision de la segmentation. Le réseau peut utiliser des données de bas niveau du chemin de codage pour affiner les résultats de segmentation dans le chemin de décodage, permettant une localisation plus précise et une meilleure délimitation des limites d'objet.
Combiner le contexte de haut niveau et les détails de bas niveau
Les connexions de saut permettent au chemin de décodage de combiner le contexte de haut niveau et les détails de bas niveau. Les cartes de caractéristiques concaténées provenant des connexions de saut comprennent les cartes de caractéristiques suréchantillonnées du chemin de décodage et les cartes de caractéristiques du chemin de codage.
Cette combinaison permet au réseau de tirer parti du contexte de haut niveau enregistré dans le chemin de décodage et des caractéristiques à grain fin capturées dans le chemin de codage. Le réseau peut intégrer des informations de plusieurs tailles, permettant une segmentation plus précise et détaillée.
UNET peut tirer parti des informations multi-échelles, préserver les détails spatiaux et fusionner le contexte de haut niveau avec les détails de bas niveau en ajoutant des connexions de saut. En conséquence, la précision de la segmentation s'améliore, la localisation des objets s'améliore et les informations à grain fin dans le masque de segmentation sont conservées.
En conclusion, les connexions de saut dans les UNET sont essentielles pour maintenir les informations spatiales, intégrer des informations multi-échelles et améliorer la précision de la segmentation. Ils fournissent un flux d'informations direct sur les routes d'encodage et de décodage, permettant au réseau de collecter des détails locaux et globaux, ce qui se traduit par une segmentation d'image plus précise et détaillée.
Fonction de perte dans UNET
Il est essentiel de sélectionner une fonction de perte appropriée lors de la formation d'UNET et de l'optimisation de ses paramètres pour les tâches de segmentation d'image. UNET utilise fréquemment des fonctions de perte adaptées à la segmentation telles que le coefficient de Dice ou la perte d'entropie croisée.
Perte de coefficient de dés
Le coefficient Dice est une statistique de similarité qui calcule le chevauchement entre les masques de segmentation anticipés et réels. La perte de coefficient de dés, ou perte de dés souple, est calculée en soustrayant un du coefficient de dés. Lorsque les masques de vérité anticipé et de terrain s'alignent bien, la perte est minimisée, ce qui entraîne un coefficient de Dice plus élevé.
La perte de coefficient Dice est particulièrement efficace pour les ensembles de données déséquilibrés dans lesquels la classe d'arrière-plan comporte de nombreux pixels. En pénalisant les faux positifs et les faux négatifs, il encourage le réseau à diviser avec précision les régions de premier plan et d'arrière-plan.
Perte d'entropie croisée
Utilisez la fonction de perte d'entropie croisée dans les tâches de segmentation d'image. Il mesure la dissemblance entre les probabilités de classe prédites et les étiquettes de vérité terrain. Traitez chaque pixel comme un problème de classification indépendant dans la segmentation d'image, et la perte d'entropie croisée est calculée pixel par pixel.
La perte d'entropie croisée encourage le réseau à attribuer des probabilités élevées aux étiquettes de classe correctes pour chaque pixel. Il pénalise les écarts par rapport à la vérité terrain, favorisant des résultats de segmentation précis. Cette fonction de perte est efficace lorsque les classes de premier plan et d'arrière-plan sont équilibrées ou lorsque plusieurs classes sont impliquées dans la tâche de segmentation.
Le choix entre la perte de coefficient Dice et la perte d'entropie croisée dépend des exigences spécifiques de la tâche de segmentation et des caractéristiques de l'ensemble de données. Les deux fonctions de perte présentent des avantages et peuvent être combinées ou personnalisées en fonction de besoins spécifiques.
1 : Importer des bibliothèques
import tensorflow as tf
import os
import numpy as np
from tqdm import tqdm
from skimage.io import imread, imshow
from skimage.transform import resize
import matplotlib.pyplot as plt
import random2 : Dimensions de l'image – Paramètres
IMG_WIDTH = 128
IMG_HEIGHT = 128
IMG_CHANNELS = 33 : Définir le caractère aléatoire
seed = 42
np.random.seed = seed4 : Importation de l'ensemble de données
# Data downloaded from - https://www.kaggle.com/competitions/data-science-bowl-2018/data #importing datasets
TRAIN_PATH = 'stage1_train/'
TEST_PATH = 'stage1_test/'5 : Lecture de toutes les images présentes dans le sous-dossier
train_ids = next(os.walk(TRAIN_PATH))[1]
test_ids = next(os.walk(TEST_PATH))[1]6 : Formation
X_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
Y_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)7 : Redimensionner les images
print('Resizing training images and masks')
for n, id_ in tqdm(enumerate(train_ids), total=len(train_ids)): path = TRAIN_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_train[n] = img #Fill empty X_train with values from img mask = np.zeros((IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool) for mask_file in next(os.walk(path + '/masks/'))[2]: mask_ = imread(path + '/masks/' + mask_file) mask_ = np.expand_dims(resize(mask_, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True), axis=-1) mask = np.maximum(mask, mask_) Y_train[n] = mask 8 : Tester les images
# test images
X_test = np.zeros((len(test_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
sizes_test = []
print('Resizing test images') for n, id_ in tqdm(enumerate(test_ids), total=len(test_ids)): path = TEST_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] sizes_test.append([img.shape[0], img.shape[1]]) img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_test[n] = img print('Done!')9 : Vérification aléatoire des images
image_x = random.randint(0, len(train_ids))
imshow(X_train[image_x])
plt.show()
imshow(np.squeeze(Y_train[image_x]))
plt.show()10 : Construire le modèle
inputs = tf.keras.layers.Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
s = tf.keras.layers.Lambda(lambda x: x / 255)(inputs)11 : Chemins
#Contraction path
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(s)
c1 = tf.keras.layers.Dropout(0.1)(c1)
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)
p1 = tf.keras.layers.MaxPooling2D((2, 2))(c1) c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)
c2 = tf.keras.layers.Dropout(0.1)(c2)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)
p2 = tf.keras.layers.MaxPooling2D((2, 2))(c2) c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)
c3 = tf.keras.layers.Dropout(0.2)(c3)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)
p3 = tf.keras.layers.MaxPooling2D((2, 2))(c3) c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p3)
c4 = tf.keras.layers.Dropout(0.2)(c4)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)
p4 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(c4) c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p4)
c5 = tf.keras.layers.Dropout(0.3)(c5)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)12 : Chemins d'expansion
u6 = tf.keras.layers.Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(c5)
u6 = tf.keras.layers.concatenate([u6, c4])
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
c6 = tf.keras.layers.Dropout(0.2)(c6)
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c6) u7 = tf.keras.layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(c6)
u7 = tf.keras.layers.concatenate([u7, c3])
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
c7 = tf.keras.layers.Dropout(0.2)(c7)
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c7) u8 = tf.keras.layers.Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(c7)
u8 = tf.keras.layers.concatenate([u8, c2])
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
c8 = tf.keras.layers.Dropout(0.1)(c8)
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c8) u9 = tf.keras.layers.Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(c8)
u9 = tf.keras.layers.concatenate([u9, c1], axis=3)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
c9 = tf.keras.layers.Dropout(0.1)(c9)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c9)13 : Sorties
outputs = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid')(c9)14 : Résumé
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()15 : Point de contrôle du modèle
checkpointer = tf.keras.callbacks.ModelCheckpoint('model_for_nuclei.h5', verbose=1, save_best_only=True) callbacks = [ tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), tf.keras.callbacks.TensorBoard(log_dir='logs')] results = model.fit(X_train, Y_train, validation_split=0.1, batch_size=16, epochs=25, callbacks=callbacks)16 : Dernière étape – Prédiction
idx = random.randint(0, len(X_train)) preds_train = model.predict(X_train[:int(X_train.shape[0]*0.9)], verbose=1)
preds_val = model.predict(X_train[int(X_train.shape[0]*0.9):], verbose=1)
preds_test = model.predict(X_test, verbose=1) preds_train_t = (preds_train > 0.5).astype(np.uint8)
preds_val_t = (preds_val > 0.5).astype(np.uint8)
preds_test_t = (preds_test > 0.5).astype(np.uint8) # Perform a sanity check on some random training samples
ix = random.randint(0, len(preds_train_t))
imshow(X_train[ix])
plt.show()
imshow(np.squeeze(Y_train[ix]))
plt.show()
imshow(np.squeeze(preds_train_t[ix]))
plt.show() # Perform a sanity check on some random validation samples
ix = random.randint(0, len(preds_val_t))
imshow(X_train[int(X_train.shape[0]*0.9):][ix])
plt.show()
imshow(np.squeeze(Y_train[int(Y_train.shape[0]*0.9):][ix]))
plt.show()
imshow(np.squeeze(preds_val_t[ix]))
plt.show()Conclusion
Dans cet article de blog complet, nous avons couvert l'architecture UNET pour la segmentation d'images. En s'attaquant aux contraintes des méthodologies antérieures, l'architecture UNET a révolutionné la segmentation des images. Ses routes d'encodage et de décodage, ses connexions de saut et d'autres modifications, telles que U-Net++, Attention U-Net et Dense U-Net, se sont révélées très efficaces pour capturer le contexte, maintenir les informations spatiales et améliorer la précision de la segmentation. Le potentiel de segmentation précise et automatique avec UNET offre de nouvelles voies pour améliorer la vision par ordinateur et au-delà. Nous encourageons les lecteurs à en savoir plus sur UNET et à expérimenter sa mise en œuvre afin de maximiser son utilité dans leurs projets de segmentation d'images.
Faits marquants
1. La segmentation des images est essentielle dans les tâches de vision par ordinateur, permettant la division des images en régions ou objets significatifs.
2. Les approches traditionnelles de la segmentation d'images, telles que l'annotation manuelle et la classification par pixel, ont des limites en termes d'efficacité et de précision.
3. Développer l'architecture UNET pour répondre à ces limitations et obtenir des résultats de segmentation précis.
4. Il s'agit d'un réseau neuronal entièrement convolutif (FCN) combinant un chemin de codage pour capturer des caractéristiques de haut niveau et une méthode de décodage pour générer le masque de segmentation.
5. Ignorer les connexions dans UNET préserve les informations spatiales, améliore la propagation des caractéristiques et améliore la précision de la segmentation.
6. A trouvé des applications réussies dans l'imagerie médicale, l'analyse d'images satellites et le contrôle de la qualité industrielle, obtenant des références notables et une reconnaissance dans les compétitions.
Foire aux Questions
A. L'architecture U-Net est une architecture de réseau neuronal convolutionnel (CNN) courante pour les tâches de segmentation d'images. Initialement développé pour la segmentation d'images biomédicales, il a depuis trouvé des applications dans divers domaines. L'architecture U-Net gère les informations locales et globales et possède une structure codeur-décodeur en forme de U.
A. L'architecture U-Net se compose d'un chemin d'encodeur et d'un chemin de décodeur. Le chemin du codeur réduit progressivement les dimensions spatiales de l'image d'entrée tout en augmentant le nombre de canaux de caractéristiques. Cela aide à extraire des fonctionnalités abstraites et de haut niveau. Le chemin du décodeur effectue des opérations de suréchantillonnage et de concaténation. Et récupérez les dimensions spatiales tout en réduisant le nombre de canaux de fonctionnalités. Le réseau apprend à combiner les caractéristiques de bas niveau du chemin du codeur avec les caractéristiques de haut niveau du chemin du décodeur pour générer des masques de segmentation.
A. L'architecture U-Net offre plusieurs avantages pour les tâches de segmentation d'images. Premièrement, sa conception en forme de U permet de combiner des fonctionnalités de bas niveau et de haut niveau, permettant une meilleure localisation des objets. Deuxièmement, les connexions de saut entre les chemins d'encodeur et de décodeur aident à préserver les informations spatiales, permettant une segmentation plus précise. Enfin, l'architecture U-Net a un nombre relativement faible de paramètres, ce qui la rend plus efficace en termes de calcul que les autres architectures.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/08/unet-architecture-mastering-image-segmentation/

