Introduction
La machine à vecteurs de support (SVM) à une classe est une variante de la SVM traditionnelle. Il est spécifiquement adapté pour détecter les anomalies. Son objectif principal est de localiser les cas qui s'écartent notablement de la norme. Contrairement aux classiques Machine Learning modèles axés sur la classification binaire ou multiclasse, le SVM à une classe se spécialise dans la détection des valeurs aberrantes ou des nouveautés au sein des ensembles de données. Dans cet article, vous découvrirez en quoi la machine à vecteurs de support (SVM) à une classe diffère de la SVM traditionnelle. Vous apprendrez également comment fonctionne OC-SVM et comment le mettre en œuvre. Vous découvrirez également ses hyperparamètres.
Objectifs d'apprentissage
- Comprendre les anomalies
- En savoir plus sur le SVM à une classe
- Comprendre en quoi elle diffère de la machine à vecteurs de support (SVM) traditionnelle
- Hyperparamètres d'OC-SVM dans Sklearn
- Comment détecter les anomalies à l'aide d'OC-SVM
- Cas d'utilisation de SVM à une classe
Table des matières
Comprendre les anomalies
Les anomalies sont des observations ou des instances qui s'écartent considérablement du comportement normal d'un ensemble de données. Ces écarts peuvent se manifester sous diverses formes, telles que des valeurs aberrantes, du bruit, des erreurs ou des modèles inattendus. Les anomalies sont souvent fascinantes car elles peuvent représenter des informations précieuses. Ils peuvent fournir des informations telles que l’identification de transactions frauduleuses, la détection de dysfonctionnements d’équipement ou la découverte de nouveaux phénomènes. La détection des valeurs aberrantes et des nouveautés identifie les anomalies et les observations anormales ou inhabituelles.
Lisez aussi: Un guide de bout en bout sur la détection des anomalies
SVM à une classe
Introduction aux machines à vecteurs de support (SVM)
Machines à vecteurs de support (SVM) sont un populaire algorithme d'apprentissage supervisé pour les tâches de classification et de régression. Les SVM fonctionnent en trouvant l'hyperplan optimal qui sépare les différentes classes dans l'espace des fonctionnalités tout en maximisant la marge entre elles. Cet hyperplan est basé sur un sous-ensemble de points de données d'entraînement appelés vecteurs de support.
SVM monoclasse vs SVM traditionnel
- Les SVM à une classe représentent une variante de l'algorithme SVM traditionnel principalement utilisé pour les tâches de détection des valeurs aberrantes et des nouveautés. Contrairement aux SVM traditionnels, qui gèrent les tâches de classification binaire, les SVM à une classe s'entraînent exclusivement sur les points de données d'une seule classe, appelée classe cible. SVM à une classe vise à apprendre une fonction de frontière ou de décision qui encapsule la classe cible dans l'espace des fonctionnalités, modélisant efficacement le comportement normal des données.
- Les SVM traditionnels visent à trouver une limite de décision qui maximise la marge entre les différentes classes, permettant une classification optimale des nouveaux points de données. D'un autre côté, One-Class SVM cherche à trouver une limite qui encapsule la classe cible tout en minimisant le risque d'inclure des valeurs aberrantes ou de nouvelles instances en dehors de cette limite.
- Les SVM traditionnels nécessitent des données étiquetées avec des instances de plusieurs classes, ce qui les rend adaptées aux tâches de classification supervisées. En revanche, un SVM à une classe permet une application dans des scénarios dans lesquels seules les données de la classe cible sont disponibles, ce qui le rend bien adapté aux tâches de détection d'anomalies et de détection de nouveautés non supervisées.
Pour en savoir plus : Classification à une classe à l'aide de machines à vecteurs de support
Ils diffèrent tous deux par leurs formulations de marges souples et la manière dont ils les utilisent :
(Une marge souple dans SVM est utilisée pour permettre un certain degré d'erreur de classification)
SVM à une classe vise à découvrir un hyperplan avec une marge maximale dans l'espace des fonctionnalités en séparant les données cartographiées de l'origine. Sur un ensemble de données Dn = {x1, . . . , xn} avec xi ∈ X (xi est une caractéristique) et n dimensions :
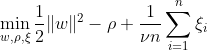
Cette équation représente la formulation du problème principal pour OC-SVM, où w est l'hyperplan de séparation, ρ est le décalage par rapport à l'origine et ξi sont les variables de marge. Ils autorisent une marge souple mais pénalisent les violations ξi. Un hyperparamètre ν ∈ (0, 1] contrôle l'effet de la variable slack et doit être ajusté en fonction des besoins. L'objectif est de minimiser la norme de w tout en pénalisant les écarts par rapport à la marge. De plus, cela permet à une fraction des données de se situent dans la marge ou du mauvais côté de l’hyperplan.
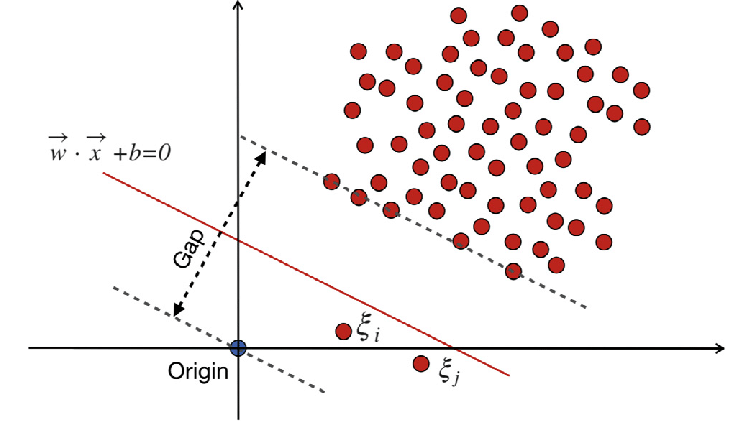
WX + b =0 est la limite de décision, et les variables de marge pénalisent les écarts.
Machines vectorielles à support traditionnel (SVM)
Les machines à vecteurs de support traditionnelles (SVM) utilisent la formulation de marge souple pour les erreurs de classification. Ou encore, ils utilisent des points de données qui se situent dans la marge ou du mauvais côté de la limite de décision.
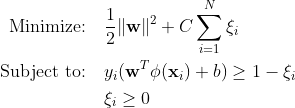
Où :
w est le vecteur poids.
b est le terme de biais.
ξi sont des variables de marge qui permettent une optimisation de la marge souple.
C est le paramètre de régularisation qui contrôle le compromis entre maximiser la marge et minimiser l'erreur de classification.
ϕ(xi) représente la fonction de mappage de fonctionnalités.
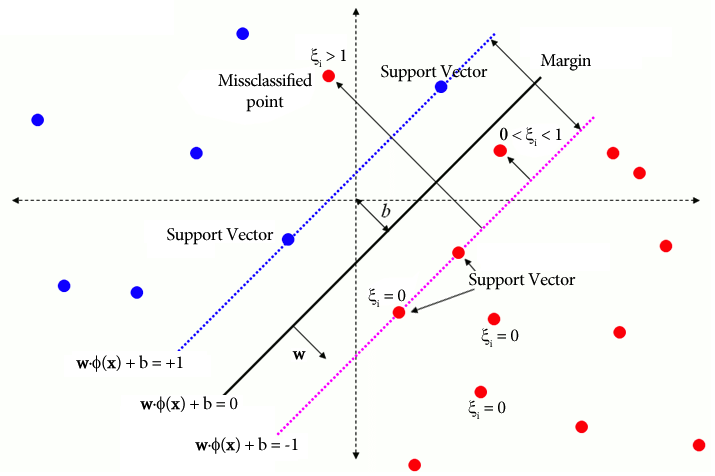
Dans le SVM traditionnel, une méthode d'apprentissage supervisé qui s'appuie sur des étiquettes de classe pour la séparation intègre des variables slack pour permettre un certain niveau d'erreur de classification. L'objectif principal de SVM est de séparer les points de données de classes distinctes en utilisant la limite de décision WX + b = 0. La valeur des variables slack varie en fonction de l'emplacement des points de données : elles sont mises à 0 si les points de données sont situés au-delà des marges. Si le point de données réside dans la marge, les variables de marge sont comprises entre 0 et 1, s'étendant au-delà de la marge opposée si elles sont supérieures à 1.
Les SVM traditionnels et les SVM One-Class avec des formulations à marge souple visent à minimiser la norme du vecteur de poids. Néanmoins, ils diffèrent dans leurs objectifs et dans la manière dont ils traitent les erreurs de classification ou les écarts par rapport aux limites de décision. Les SVM traditionnels optimisent la précision de la classification pour éviter le surajustement, tandis que les SVM à une classe se concentrent sur la modélisation de la classe cible et le contrôle de la proportion de valeurs aberrantes ou d'instances nouvelles.
Lisez aussi: Le guide AZ pour prendre en charge la machine à vecteurs
Hyperparamètres importants dans SVM à une classe
- maintenant : Il s'agit d'un hyperparamètre crucial dans One-Class SVM, qui contrôle la proportion de valeurs aberrantes autorisées. Il fixe une limite supérieure à la fraction des erreurs de formation et une limite inférieure à la fraction des vecteurs de support. Il se situe généralement entre 0 et 1, où des valeurs plus faibles impliquent une marge plus stricte et peuvent capturer moins de valeurs aberrantes, tandis que des valeurs plus élevées sont plus permissives. La valeur par défaut est 0.5.
- kernel: La fonction noyau détermine le type de limite de décision utilisée par le SVM. Les choix courants incluent « linéaire », « rbf » (fonction de base radiale gaussienne), « poly » (polynôme) et « sigmoïde ». Le noyau « rbf » est souvent utilisé car il peut capturer efficacement des relations non linéaires complexes.
- gamma: Il s'agit d'un paramètre pour les hyperplans non linéaires. Il définit l’influence d’un seul exemple de formation. Plus la valeur gamma est grande, plus les autres exemples doivent être proches pour être affectés. Ce paramètre est spécifique au noyau RBF et est généralement défini sur « auto », qui est par défaut 1 / n_features.
- paramètres du noyau (degré, coef0) : Ces paramètres concernent les noyaux polynomiaux et sigmoïdes. « degré » est le degré de la fonction noyau polynomial et « coef0 » est le terme indépendant dans la fonction noyau. Le réglage de ces paramètres peut être nécessaire pour obtenir des performances optimales.
- Tol : C'est le critère d'arrêt. L'algorithme s'arrête lorsque l'écart de dualité est inférieur à la tolérance. C'est un paramètre qui contrôle la tolérance du critère d'arrêt.
Principe de fonctionnement du SVM à une classe
Fonctions du noyau dans SVM à une classe
Les fonctions du noyau jouent un rôle crucial dans One-Class SVM en permettant à l'algorithme de fonctionner dans des espaces de fonctionnalités de plus grande dimension sans calculer explicitement les transformations. Dans One-Class SVM, comme dans les SVM traditionnels, les fonctions du noyau sont utilisées pour mesurer la similarité entre des paires de points de données dans l'espace d'entrée. Les fonctions de noyau courantes utilisées dans SVM à une classe incluent les noyaux gaussiens (RBF), polynomiaux et sigmoïdes. Ces noyaux mappent l'espace d'entrée d'origine dans un espace de dimension supérieure, où les points de données deviennent linéairement séparables ou présentent des modèles plus distincts, facilitant ainsi l'apprentissage. En choisissant une fonction de noyau appropriée et en ajustant ses paramètres, One-Class SVM peut capturer efficacement les relations complexes et les structures non linéaires dans les données, améliorant ainsi sa capacité à détecter les anomalies ou les valeurs aberrantes.
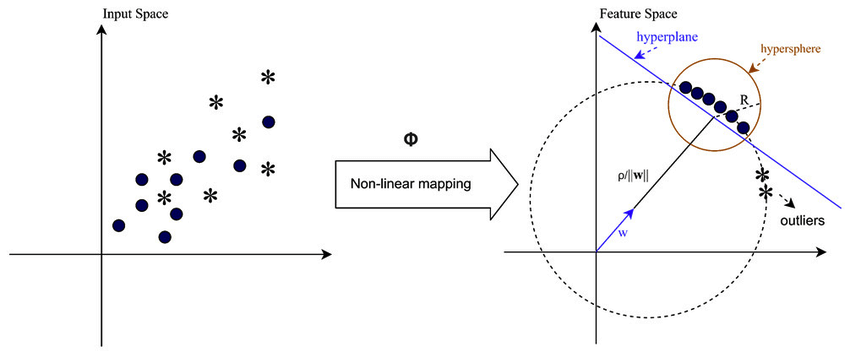
Dans les cas où les données ne sont pas linéairement séparables, par exemple lorsqu'il s'agit de modèles complexes ou qui se chevauchent, les machines à vecteurs de support (SVM) peuvent utiliser un noyau de fonction de base radiale (RBF) pour séparer efficacement les valeurs aberrantes du reste des données. Le noyau RBF transforme les données d'entrée en un espace de fonctionnalités de dimension supérieure qui peut être mieux séparé.
Marge et vecteurs de support
Le concept de vecteurs de marge et de support dans les SVM à une classe est similaire à celui des SVM traditionnels. La marge fait référence à la région située entre la limite de décision (hyperplan) et les points de données les plus proches de chaque classe. Dans One-Class SVM, la marge représente la région où se trouvent la plupart des points de données appartenant à la classe cible. Maximiser la marge est crucial pour le SVM One-Class car cela permet de bien généraliser les nouveaux points de données et d'améliorer la robustesse du modèle. Les vecteurs de support sont les points de données qui se trouvent sur ou dans la marge et contribuent à définir la limite de décision.
Dans One-Class SVM, les vecteurs de support sont les points de données de la classe cible les plus proches de la limite de décision. Ces vecteurs de support jouent un rôle important dans la détermination de la forme et de l’orientation de la limite de décision et, par conséquent, dans les performances globales du modèle SVM à une classe. En identifiant les vecteurs de support, One-Class SVM apprend efficacement la représentation de la classe cible dans l'espace des fonctionnalités et construit une limite de décision qui encapsule la plupart des points de données tout en minimisant le risque d'inclure des valeurs aberrantes ou de nouvelles instances.
Comment les anomalies peuvent-elles être détectées à l’aide d’un SVM à une classe ?
Détection des anomalies à l'aide de SVM (Support Vector Machine) à une classe grâce à des techniques de détection de nouveauté et de détection de valeurs aberrantes :
Détection des valeurs aberrantes
Cela implique d'identifier les observations dans les données d'entraînement qui s'écartent considérablement du reste, souvent appelées valeurs aberrantes. Estimateurs pour détection des valeurs aberrantes viser à s’adapter aux zones où les données d’entraînement sont les plus concentrées, sans tenir compte de ces observations déviantes.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
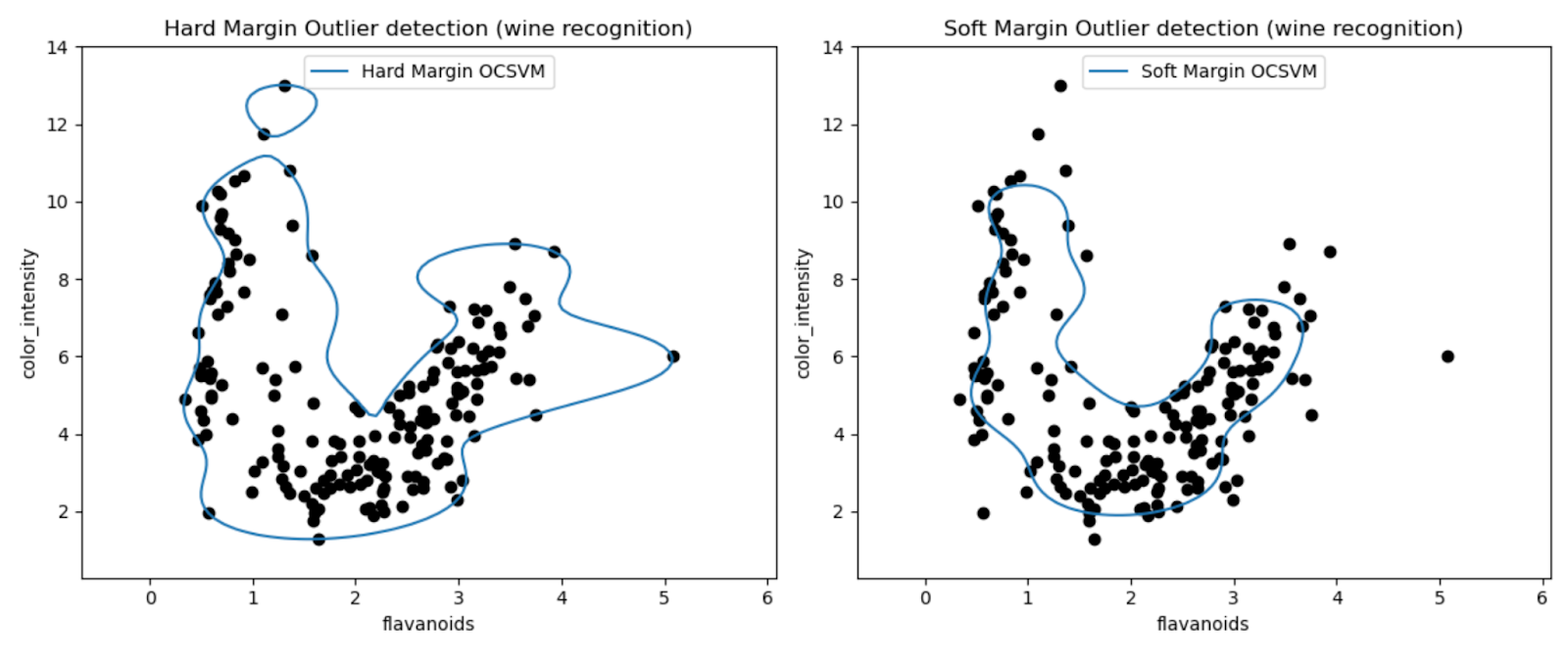
Les graphiques nous permettent d'inspecter visuellement les performances des modèles SVM à une classe dans la détection des valeurs aberrantes dans l'ensemble de données Wine.
En comparant les résultats des modèles SVM One-Class à marge dure et à marge souple, nous pouvons observer comment le choix du paramètre de marge (paramètre nu) affecte la détection des valeurs aberrantes.
Le modèle de marge ferme avec une très petite valeur nu (0.01) aboutit probablement à une limite de décision plus conservatrice. Il englobe étroitement la majorité des points de données et classe potentiellement moins de points comme valeurs aberrantes.
À l’inverse, le modèle de marge souple avec une valeur nu plus élevée (0.35) aboutit probablement à une limite de décision plus flexible. Permettant ainsi une marge plus large et potentiellement capturant davantage de valeurs aberrantes.
Détection de nouveauté
En revanche, nous l'appliquons lorsque les données d'entraînement sont exemptes de valeurs aberrantes, et le but est de déterminer si une nouvelle observation est rare, c'est-à-dire très différente des observations connues. Cette dernière observation est ici appelée une nouveauté.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- Générez un ensemble de données synthétiques avec deux groupes de points de données. Pour ce faire, générez-les avec une distribution normale autour de deux centres différents : (2, 2) et (-2, -2) pour les données d'entraînement et de test. Générez de manière aléatoire vingt points de données uniformément dans une région carrée allant de -4 à 4 le long des deux dimensions. Ces points de données représentent des observations anormales ou des valeurs aberrantes qui s'écartent considérablement du comportement normal observé dans les données du train et des tests.
- La frontière apprise fait référence à la limite de décision apprise par le modèle SVM à une classe. Cette limite sépare les régions de l'espace des fonctionnalités où le modèle considère les points de données comme normaux des valeurs aberrantes.
- Le dégradé de couleurs du bleu au blanc dans les contours représente les différents degrés de confiance ou de certitude que le modèle SVM à une classe attribue aux différentes régions de l'espace des fonctionnalités, les nuances plus foncées indiquant une plus grande confiance dans la classification des points de données comme « normaux ». Le bleu foncé indique les régions avec une forte indication d'être « normales » selon la fonction de décision du modèle. À mesure que la couleur du contour devient plus claire, le modèle est moins sûr de classer les points de données comme « normaux ».
- Le graphique représente visuellement comment le modèle SVM à une classe peut faire la distinction entre les observations régulières et anormales. La limite de décision apprise sépare les régions d'observations normales et anormales. Le SVM à une classe pour la détection de nouveauté prouve son efficacité dans l'identification d'observations anormales dans un ensemble de données donné.
Pour nu=0.5 :
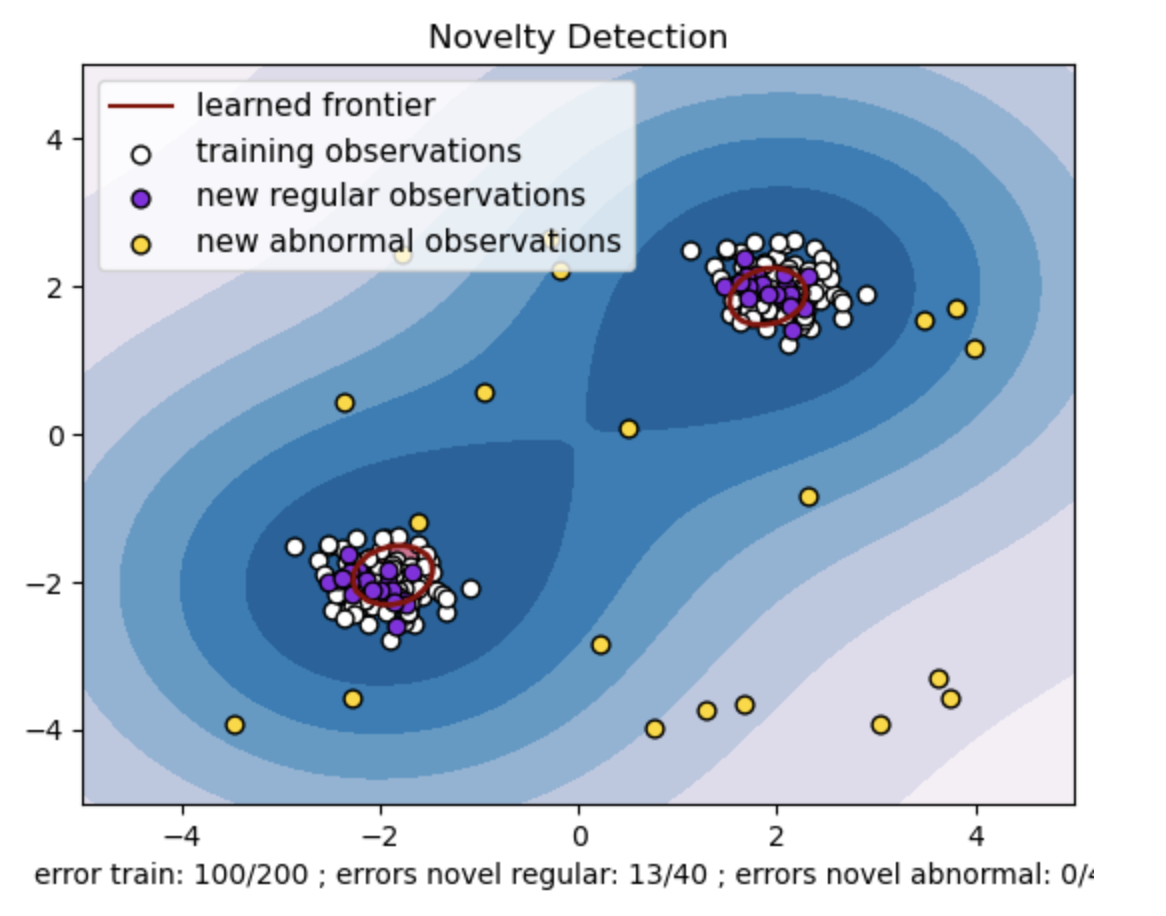
La valeur « nu » dans One-class SVM joue un rôle crucial dans le contrôle de la fraction de valeurs aberrantes tolérée par le modèle. Cela affecte directement la capacité du modèle à identifier les anomalies et influence ainsi la prédiction. Nous pouvons voir que le modèle permet de mal classer 100 points de formation. Une valeur inférieure de nu implique une contrainte plus stricte sur la fraction autorisée de valeurs aberrantes. Le choix de nu influence les performances du modèle dans la détection des anomalies. Cela nécessite également un réglage minutieux en fonction des exigences spécifiques de l'application et des caractéristiques de l'ensemble de données.
Pour gamma=0.5 et nu=0.5
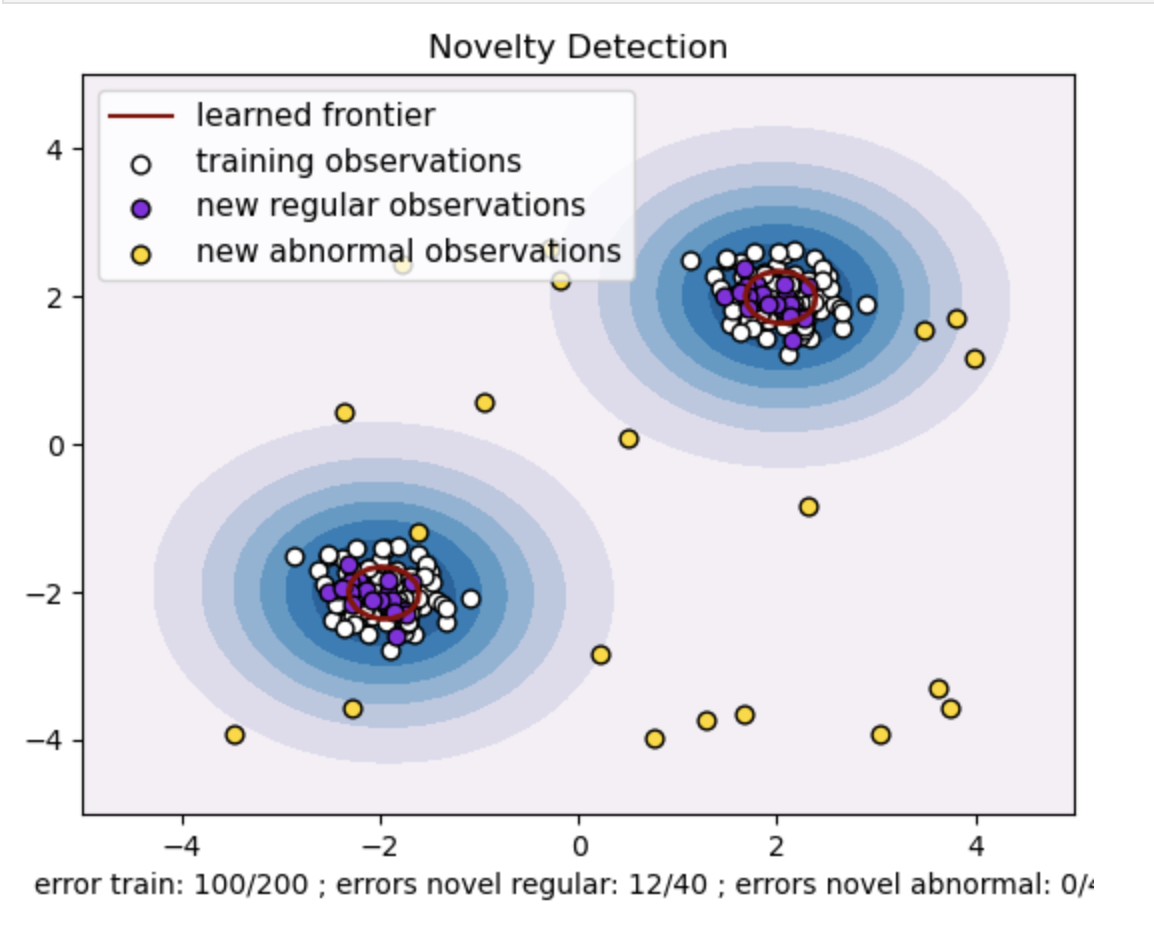
Dans SVM à une classe, l'hyperparamètre gamma représente le coefficient du noyau 'rbf'. Cet hyperparamètre influence la forme de la limite de décision et, par conséquent, affecte les performances prédictives du modèle.
Lorsque le gamma est élevé, un seul exemple d’entraînement limite son influence à son voisinage immédiat. Cela crée une limite de décision plus localisée. Par conséquent, les points de données doivent être plus proches des vecteurs supports pour appartenir à la même classe.
Conclusion
L'utilisation du SVM One-Class pour la détection des anomalies, la détection des valeurs aberrantes et des nouveautés offrent une solution robuste dans divers domaines. Cela est utile dans les scénarios où les données sur les anomalies étiquetées sont rares ou indisponibles. Cela le rend particulièrement utile dans les applications du monde réel où les anomalies sont rares et difficiles à définir explicitement. Ses cas d’usage s’étendent à divers domaines, comme la cybersécurité et le diagnostic de pannes, où les anomalies ont des conséquences. Cependant, si le SVM One-Class présente de nombreux avantages, il est nécessaire de paramétrer les hyperparamètres en fonction des données pour obtenir de meilleurs résultats, ce qui peut parfois s'avérer fastidieux.
Foire aux Questions
A. Le SVM à une classe construit un hyperplan (ou une hypersphère dans des dimensions supérieures) qui encapsule les points de données normaux. Cet hyperplan est positionné pour maximiser la marge entre les données normales et la limite de décision. Les points de données sont classés comme normaux (à l'intérieur de la limite) ou comme anomalies (à l'extérieur de la limite) lors des tests ou de l'inférence.
R. Le SVM à une classe est avantageux car il ne nécessite pas de données étiquetées pour les anomalies pendant la formation. Il peut apprendre à partir d'un ensemble de données contenant uniquement des instances régulières, ce qui le rend adapté aux scénarios dans lesquels les anomalies sont rares et difficiles à obtenir des exemples étiquetés pour la formation.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

