Les grands modèles linguistiques (LLM) ont révolutionné le domaine du traitement du langage naturel (NLP), en améliorant des tâches telles que la traduction linguistique, la synthèse de texte et l'analyse des sentiments. Cependant, à mesure que ces modèles continuent de croître en taille et en complexité, la surveillance de leurs performances et de leur comportement devient de plus en plus difficile.
La surveillance des performances et du comportement des LLM est une tâche essentielle pour garantir leur sécurité et leur efficacité. L'architecture que nous proposons fournit une solution évolutive et personnalisable pour la surveillance LLM en ligne, permettant aux équipes d'adapter votre solution de surveillance à vos cas d'utilisation et à vos exigences spécifiques. En utilisant les services AWS, notre architecture offre une visibilité en temps réel sur le comportement LLM et permet aux équipes d'identifier et de résoudre rapidement tout problème ou anomalie.
Dans cet article, nous démontrons quelques métriques pour la surveillance LLM en ligne et leur architecture respective pour une mise à l'échelle à l'aide des services AWS tels que Amazon Cloud Watch ainsi que AWS Lambda. Cela offre une solution personnalisable au-delà de ce qui est possible avec évaluation du modèle des emplois avec Socle amazonien.
Présentation de la solution
La première chose à considérer est que différentes métriques nécessitent des considérations de calcul différentes. Une architecture modulaire, dans laquelle chaque module peut intégrer des données d'inférence de modèle et produire ses propres métriques, est nécessaire.
Nous suggérons que chaque module transmette les requêtes d'inférence entrantes au LLM, en transmettant les paires d'invite et d'achèvement (réponse) aux modules de calcul métrique. Chaque module est responsable du calcul de ses propres métriques en ce qui concerne l'invite de saisie et l'achèvement (réponse). Ces métriques sont transmises à CloudWatch, qui peut les regrouper et fonctionner avec les alarmes CloudWatch pour envoyer des notifications sur des conditions spécifiques. Le diagramme suivant illustre cette architecture.
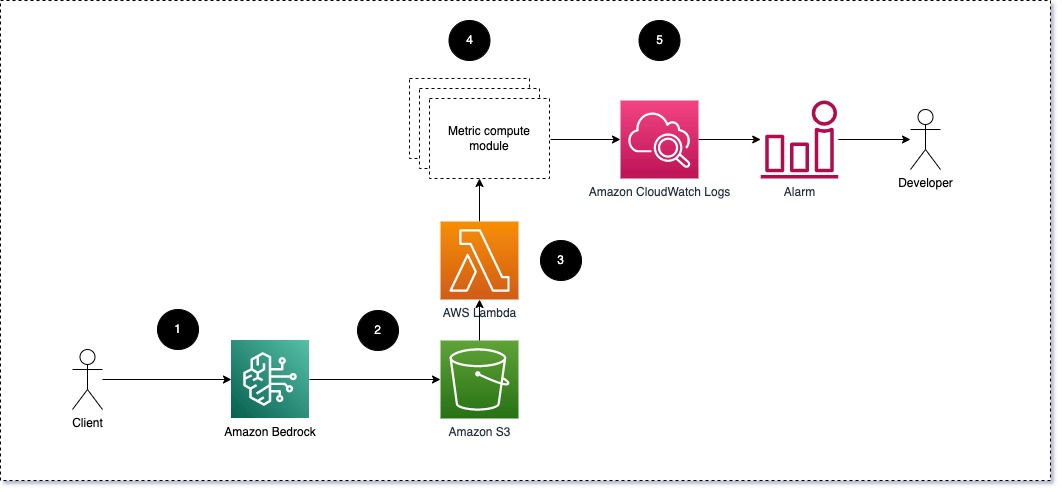
Fig 1 : Module de calcul métrique – aperçu de la solution
Le workflow comprend les étapes suivantes:
- Un utilisateur envoie une demande à Amazon Bedrock dans le cadre d'une application ou d'une interface utilisateur.
- Amazon Bedrock enregistre la demande et l'achèvement (réponse) dans Service de stockage simple Amazon (Amazon S3) selon la configuration de journalisation des appels.
- Le fichier enregistré sur Amazon S3 crée un événement qui déclenche une fonction Lambda. La fonction appelle les modules.
- Les modules publient leurs métriques respectives sur Métriques CloudWatch.
- Alarmes peut informer l'équipe de développement de valeurs de métriques inattendues.
La deuxième chose à considérer lors de la mise en œuvre de la surveillance LLM est de choisir les bonnes mesures à suivre. Bien qu'il existe de nombreuses mesures potentielles que vous pouvez utiliser pour surveiller les performances du LLM, nous expliquons certaines des plus larges dans cet article.
Dans les sections suivantes, nous mettons en évidence quelques-unes des métriques de module pertinentes et leur architecture de module de calcul de métrique respective.
Similitude sémantique entre l'invite et l'achèvement (réponse)
Lors de l'exécution de LLM, vous pouvez intercepter l'invite et l'achèvement (réponse) de chaque requête et les transformer en intégrations à l'aide d'un modèle d'intégration. Les intégrations sont des vecteurs de grande dimension qui représentent la signification sémantique du texte. Titan d'Amazonie fournit de tels modèles via Titan Embeddings. En prenant une distance telle que le cosinus entre ces deux vecteurs, vous pouvez quantifier la similitude sémantique de l'invite et de l'achèvement (réponse). Vous pouvez utiliser SciPy or scikit-apprendre pour calculer la distance cosinus entre les vecteurs. Le diagramme suivant illustre l'architecture de ce module de calcul métrique.
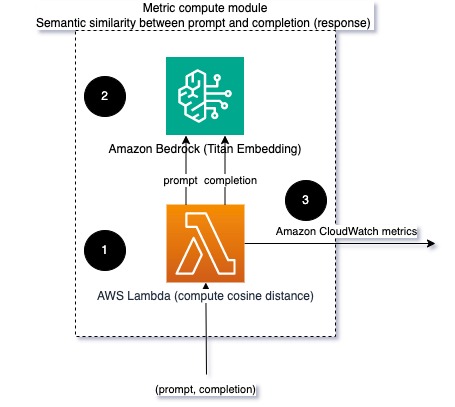
Fig 2 : Module de calcul métrique – similarité sémantique
Ce flux de travail comprend les étapes clés suivantes :
- Une fonction Lambda reçoit un message diffusé via Amazon Kinésis contenant une paire d'invite et d'achèvement (réponse).
- La fonction obtient une intégration pour l'invite et l'achèvement (réponse) et calcule la distance cosinusoïdale entre les deux vecteurs.
- La fonction envoie ces informations aux métriques CloudWatch.
Sentiment et toxicité
La surveillance des sentiments vous permet d'évaluer le ton général et l'impact émotionnel des réponses, tandis que l'analyse de toxicité fournit une mesure importante de la présence de propos offensants, irrespectueux ou préjudiciables dans les résultats du LLM. Tout changement de sentiment ou de toxicité doit être étroitement surveillé pour garantir que le modèle se comporte comme prévu. Le diagramme suivant illustre le module de calcul métrique.

Fig 3 : Module de calcul métrique – sentiment et toxicité
Le workflow comprend les étapes suivantes:
- Une fonction Lambda reçoit une paire d'invite et d'achèvement (réponse) via Amazon Kinesis.
- Grâce à l'orchestration AWS Step Functions, la fonction appelle Amazon comprendre pour détecter le sentiment ainsi que toxicité.
- La fonction enregistre les informations dans les métriques CloudWatch.
Pour plus d'informations sur la détection des sentiments et de la toxicité avec Amazon Comprehend, reportez-vous à Construire un prédicteur de toxicité textuel robuste ainsi que Signaler le contenu nuisible à l'aide de la détection de toxicité Amazon Comprehend.
Taux de refus
Une augmentation des refus, par exemple lorsqu'un LLM refuse d'être terminé en raison d'un manque d'informations, pourrait signifier soit que des utilisateurs malveillants tentent d'utiliser le LLM d'une manière destinée à le jailbreaker, soit que les attentes des utilisateurs ne sont pas satisfaites et qu'ils reçoivent des réponses de faible valeur. Une façon d'évaluer la fréquence à laquelle cela se produit consiste à comparer les refus standards du modèle LLM utilisé avec les réponses réelles du LLM. Par exemple, voici quelques-unes des expressions de refus courantes de Claude v2 LLM d'Anthropic :
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Sur un ensemble fixe d'invites, une augmentation de ces refus peut être le signe que le modèle est devenu trop prudent ou sensible. Le cas inverse doit également être évalué. Cela pourrait être le signe que le modèle est désormais plus enclin à s’engager dans des conversations toxiques ou nuisibles.
Pour aider à modéliser l'intégrité et le taux de refus, nous pouvons comparer la réponse avec un ensemble d'expressions de refus connues du LLM. Il pourrait s'agir d'un véritable classificateur pouvant expliquer pourquoi le modèle a refusé la demande. Vous pouvez prendre la distance cosinusoïdale entre la réponse et les réponses de refus connues du modèle surveillé. Le diagramme suivant illustre ce module de calcul métrique.
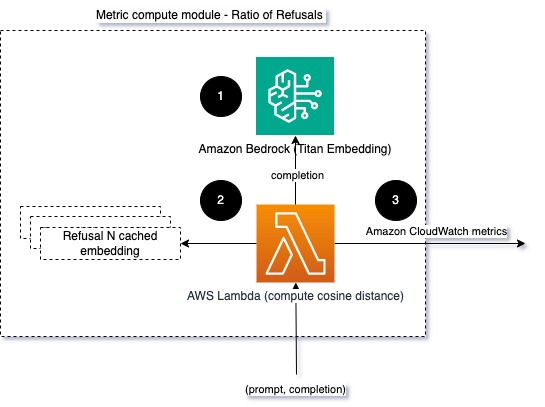
Fig 4 : Module de calcul métrique – taux de refus
Le flux de travail comprend les étapes suivantes :
- Une fonction Lambda reçoit une invite et un achèvement (réponse) et obtient une intégration de la réponse à l'aide d'Amazon Titan.
- La fonction calcule la distance cosinusoïdale ou euclidienne entre la réponse et les invites de refus existantes mises en cache en mémoire.
- La fonction envoie cette moyenne aux métriques CloudWatch.
Une autre option est d'utiliser correspondance floue pour une approche simple mais moins puissante pour comparer les refus connus aux résultats du LLM. Se référer au Documentation Python à titre d'exemple.
Résumé
L'observabilité des LLM est une pratique essentielle pour garantir une utilisation fiable et digne de confiance des LLM. Surveiller, comprendre et garantir l'exactitude et la fiabilité des LLM peuvent vous aider à atténuer les risques associés à ces modèles d'IA. En surveillant les hallucinations, les mauvaises réponses (réponses) et les invites, vous pouvez vous assurer que votre LLM reste sur la bonne voie et offre la valeur que vous et vos utilisateurs recherchez. Dans cet article, nous avons discuté de quelques mesures pour présenter des exemples.
Pour plus d'informations sur l'évaluation des modèles de fondation, reportez-vous à Utilisez SageMaker Clarify pour évaluer les modèles de base, et parcourez davantage exemples de cahiers disponible dans notre référentiel GitHub. Vous pouvez également explorer les moyens d'opérationnaliser les évaluations LLM à grande échelle dans Opérationnalisez l'évaluation LLM à grande échelle à l'aide des services Amazon SageMaker Clarify et MLOps.. Enfin, nous vous recommandons de vous référer à Évaluer les grands modèles de langage pour en vérifier la qualité et la responsabilité pour en savoir plus sur l’évaluation des LLM.
À propos des auteurs
 Bruno Klein est un ingénieur senior en apprentissage automatique chez AWS Professional Services Analytics Practice. Il aide les clients à mettre en œuvre des solutions Big Data et analytiques. En dehors du travail, il aime passer du temps en famille, voyager et essayer de nouveaux plats.
Bruno Klein est un ingénieur senior en apprentissage automatique chez AWS Professional Services Analytics Practice. Il aide les clients à mettre en œuvre des solutions Big Data et analytiques. En dehors du travail, il aime passer du temps en famille, voyager et essayer de nouveaux plats.
 Roushabh Lokhande est un ingénieur senior en données et ML chez AWS Professional Services Analytics Practice. Il aide les clients à mettre en œuvre des solutions de Big Data, d'apprentissage automatique et d'analyse. En dehors du travail, il aime passer du temps en famille, lire, courir et jouer au golf.
Roushabh Lokhande est un ingénieur senior en données et ML chez AWS Professional Services Analytics Practice. Il aide les clients à mettre en œuvre des solutions de Big Data, d'apprentissage automatique et d'analyse. En dehors du travail, il aime passer du temps en famille, lire, courir et jouer au golf.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

