Dans le monde dynamique du cloud computing, garantir la résilience et la disponibilité des applications critiques est primordial. Reprise après sinistre (DR) est le processus par lequel une organisation anticipe et gère les catastrophes liées à la technologie. Pour les organisations mettant en œuvre une orchestration des charges de travail critiques à l’aide Flux de travail gérés par Amazon pour Apache Airflow (Amazon MWAA), il est crucial de mettre en place un plan de reprise après sinistre pour garantir la continuité des activités.
Dans cette série, nous explorons la nécessité d'une reprise après sinistre Amazon MWAA et prescrivons des solutions qui protégeront les environnements Amazon MWAA contre les perturbations involontaires. Cela vous permet de définir, d'éviter et de gérer les risques de perturbation dans le cadre de votre plan de continuité d'activité. Cet article se concentre sur la conception de l’architecture globale de DR. Un prochain article de cette série se concentrera sur la mise en œuvre des composants individuels à l'aide des services AWS.
La nécessité d'une reprise après sinistre Amazon MWAA
Amazon MWAA, un service entièrement géré pour Flux d'air Apache, apporte une immense valeur aux organisations en automatisant l'orchestration des flux de travail pour les charges de travail d'extraction, de transformation et de chargement (ETL), DevOps et d'apprentissage automatique (ML). Amazon MWAA a un architecture distribuée avec plusieurs composants tels que le planificateur, le travailleur, le serveur Web, la file d'attente et la base de données. Cela rend difficile la mise en œuvre d’une stratégie globale de reprise après sinistre.
Un environnement Amazon MWAA actif analyse en permanence Airflow Graphes acycliques dirigés (DAG), en les lisant à partir d'un Service de stockage simple Amazon (Amazon S3). L'indisponibilité de la source DAG en raison de l'inaccessibilité du réseau, d'une corruption involontaire ou de suppressions entraîne des temps d'arrêt prolongés et une interruption du service.
Dans Airflow, la base de données de métadonnées est un composant principal stockant les variables de configuration, les rôles, les autorisations et les historiques d'exécution du DAG. Une base de données de métadonnées saine est donc essentielle pour votre environnement Airflow. Comme pour tout composant principal d'Airflow, il est essentiel de disposer d'un plan de sauvegarde et de reprise après sinistre pour la base de données de métadonnées.
Amazon MWAA déploie des composants Airflow sur plusieurs Zones de disponibilité au sein de votre VPC dans votre choix Région AWS. Cela offre une tolérance aux pannes et une récupération automatique en cas de défaillance d’une seule zone de disponibilité. Pour les charges de travail critiques, il est également important d'être résilient aux déficiences d'une région unitaire grâce à des déploiements multi-régions pour garantir une haute disponibilité et la continuité des activités.
L'équilibre entre les coûts de maintenance des infrastructures redondantes, la complexité et le temps de récupération est essentiel pour les environnements Amazon MWAA. Les organisations recherchent des solutions rentables qui minimisent leurs Objectif de temps de récupération (RTO) et Objectif du point de récupération (RPO) pour respecter leurs accords de niveau de service, être économiquement viable et répondre aux demandes de leurs clients.
Détecter les catastrophes dans l'environnement principal : surveillance proactive via des métriques et des alarmes
Une détection rapide des sinistres dans l’environnement principal est cruciale pour une reprise après sinistre rapide. Surveillance de la Amazon Cloud Watch Métrique SchedulerHeartbeat fournit des informations sur l’état du flux d’air d’un environnement Amazon MWAA actif. Vous pouvez ajouter d'autres mesures de vérification de l'état aux critères d'évaluation, telles que la vérification de la disponibilité des systèmes en amont ou en aval et de l'accessibilité du réseau. Combiné avec Alarmes CloudWatch, vous pouvez envoyer des notifications lorsque ces seuils sur un certain nombre de périodes ne sont pas atteints. Vous pouvez ajouter des alarmes aux tableaux de bord pour surveiller et recevoir des alertes sur vos ressources et applications AWS dans plusieurs régions.
AWS publie nos informations les plus récentes sur la disponibilité des services sur le Tableau de bord de l’état des services. Vous pouvez vérifier à tout moment pour obtenir des informations sur l'état actuel ou vous abonner à un flux RSS pour être informé des interruptions de chaque service individuel dans votre région d'exploitation. Le Tableau de bord de santé AWS fournit des informations sur les événements AWS Health qui peuvent affecter votre compte.
En combinant la surveillance des métriques, les tableaux de bord disponibles et les alarmes automatiques, vous pouvez détecter rapidement l'indisponibilité de votre environnement principal, permettant ainsi la transition de mesures proactives vers votre plan de reprise après sinistre. Il est essentiel de prendre en compte la détection, la notification, l’escalade, la découverte et la déclaration des incidents dans la planification et la mise en œuvre de votre DR afin de fournir des objectifs réalistes et réalisables qui apportent une valeur commerciale.
Dans les sections suivantes, nous abordons deux solutions stratégiques Amazon MWAA DR et leur architecture.
Solution stratégique de reprise après incident 1 : sauvegarde et restauration
La stratégie de sauvegarde et de restauration implique de générer des sauvegardes de composants Airflow dans la même région ou dans une région différente de celle de votre environnement Amazon MWAA principal. Pour garantir la continuité, vous pouvez les répliquer de manière asynchrone dans votre région DR, avec un impact minimal sur les performances de votre environnement Amazon MWAA principal. En cas de rare dysfonctionnement régional primaire ou d'interruption de service, cette stratégie créera un nouvel environnement Amazon MWAA et y récupérera les données historiques à partir des sauvegardes existantes. Cependant, il est important de noter que pendant le processus de récupération, il y aura une période pendant laquelle aucun environnement Airflow ne sera opérationnel pour traiter les flux de travail jusqu'à ce que le nouvel environnement soit entièrement provisionné et marqué comme disponible.
Cette stratégie fournit une solution peu coûteuse et peu complexe qui convient également pour atténuer la perte ou la corruption de données au sein de votre région principale. La quantité de données sauvegardées et le temps nécessaire pour créer un nouvel environnement Amazon MWAA (généralement 20 à 30 minutes) affectent la rapidité avec laquelle la restauration peut avoir lieu. Pour permettre un redéploiement rapide de l'infrastructure sans erreur, déployez à l'aide de infrastructure comme code (IaC). Sans IaC, il peut s'avérer complexe de restaurer un environnement de reprise après sinistre analogue, ce qui entraînera une augmentation des temps de récupération et éventuellement un dépassement de votre RTO.
Explorons la configuration requise lorsque votre environnement Amazon MWAA principal est en cours d'exécution, comme le montre la figure suivante.
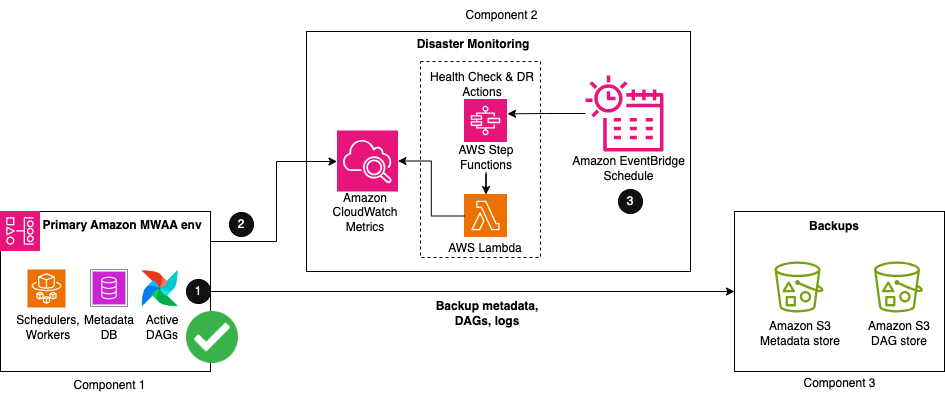
La solution comprend trois éléments clés. Le premier composant est l'environnement principal, dans lequel les flux de travail Airflow sont initialement déployés et exécutés activement. Le deuxième composant est le composant de surveillance des catastrophes, composé de CloudWatch et d'une combinaison d'un Fonctions d'étape AWS machine à états et un AWS Lambda fonction. Le troisième composant sert à créer et à stocker des sauvegardes de toutes les configurations et métadonnées nécessaires à la restauration. Cela peut être dans la même région que votre région principale ou répliqué dans votre région DR à l'aide de Réplication inter-régions S3 (CRR). Pour CRR, vous payez également le transfert de données inter-régions depuis Amazon S3 vers chaque région de destination.
Les trois premières étapes du flux de travail sont les suivantes :
- Dans le cadre de votre processus de création de sauvegarde, les métadonnées Airflow sont répliquées dans un compartiment S3 à l'aide d'un exporter le DAG utilitaire, exécutez-le périodiquement en fonction de votre intervalle RPO.
- Votre environnement Amazon MWAA principal existant émet automatiquement l'état de santé de son planificateur au CloudWatch. PlanificateurHeartbeat métrique.
- Fonctions d'une étape en plusieurs étapes machine d'état est déclenché à partir d'un périodique Amazon Event Bridge calendrier pour surveiller l’état de santé du planificateur. En tant qu'étape principale de la machine à états, une fonction Lambda évalue l'état du PlanificateurHeartbeat métrique. Si la métrique est jugée saine, aucune mesure n’est prise.
La figure suivante illustre les étapes supplémentaires du flux de travail de la solution.
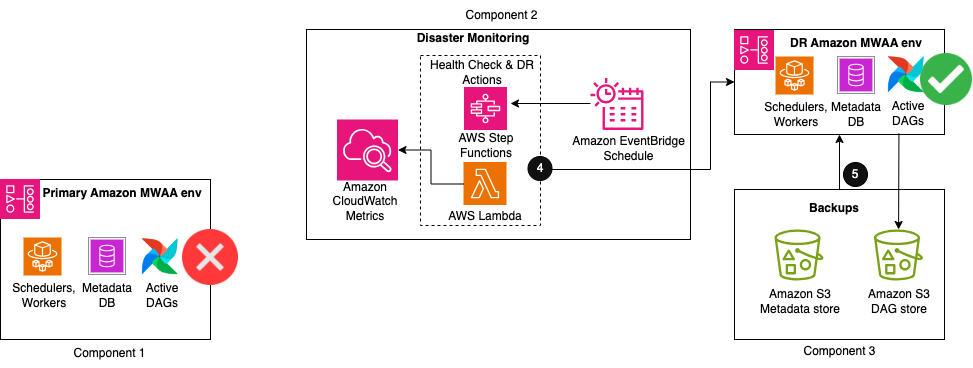
- Lorsque le nombre de pulsations s'écarte du nombre normal pendant un certain temps, une série d'actions est lancée pour restaurer vers un nouvel environnement Amazon MWAA dans la région DR. Ces actions incluent le démarrage de la création d'un nouvel environnement Amazon MWAA, la réplication des configurations de l'environnement principal, puis l'attente que le nouvel environnement soit disponible.
- Lorsque l'environnement est disponible, un importer un DAG L'utilitaire est exécuté pour restaurer le contenu des métadonnées à partir des sauvegardes. Toutes les exécutions de DAG qui ont été interrompues lors de la dégradation de l'environnement principal doivent être réexécutées manuellement pour maintenir les accords de niveau de service. Les futures exécutions du DAG sont mises en file d’attente pour s’exécuter selon leur prochaine planification configurée.
Solution stratégique de reprise après incident 2 : environnements actifs-passifs avec synchronisation périodique des données
Les environnements actif-passif avec stratégie de synchronisation périodique des données se concentrent sur le maintien de la synchronisation récurrente des données entre un environnement DR Amazon MWAA principal actif et passif. En mettant à jour et en synchronisant périodiquement les magasins DAG et les bases de données de métadonnées, cette stratégie garantit que l'environnement DR reste à jour ou presque avec l'environnement principal. La région DR peut être identique ou différente de celle de votre environnement Amazon MWAA principal. En cas de sinistre, des sauvegardes sont disponibles pour revenir à un bon état antérieur connu afin de minimiser la perte ou la corruption de données.
Cette stratégie offre un RTO et un RPO faibles avec une synchronisation fréquente, permettant une récupération rapide avec une perte de données minimale. Les coûts d'infrastructure et les déploiements de code sont combinés pour maintenir à la fois les environnements principal et DR Amazon MWAA. Votre environnement DR est disponible immédiatement pour exécuter des DAG.
La figure suivante illustre la configuration requise lorsque votre environnement Amazon MWAA principal est en cours d'exécution.
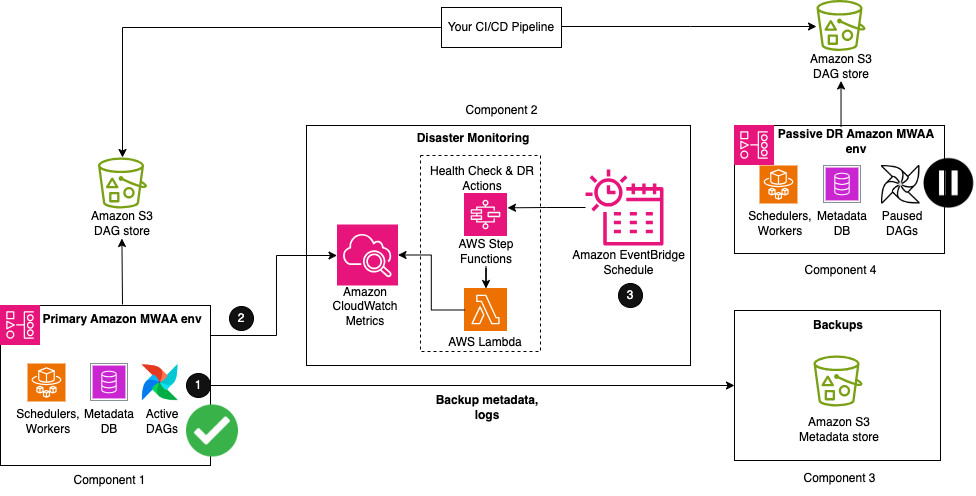
La solution comprend quatre éléments clés. Semblable à la solution de sauvegarde et de restauration, le premier composant est l'environnement principal, dans lequel le flux de travail est initialement déployé et s'exécute activement. Le deuxième composant est le composant de surveillance des sinistres, composé de CloudWatch et d'une combinaison d'une machine d'état Step Functions et d'une fonction Lambda. Le troisième composant crée et stocke des sauvegardes pour toutes les configurations et métadonnées requises pour la synchronisation de la base de données. Cela peut se trouver dans la même région que votre région principale ou être répliqué dans votre région DR à l'aide de la réplication inter-régions Amazon S3. Comme mentionné précédemment, pour CRR, vous payez également pour le transfert de données inter-régions depuis Amazon S3 vers chaque région de destination. Le dernier composant est un environnement Amazon MWAA passif qui a le même code Airflow et les mêmes configurations d'environnement que le composant principal. Les DAG sont déployés dans l'environnement DR en utilisant le même pipeline d'intégration continue et de livraison continue (CI/CD) que le principal. Contrairement au principal, les DAG sont conservés dans un état de pause pour ne pas provoquer d'exécutions en double.
Les premières étapes du workflow sont similaires à la stratégie de sauvegarde et de restauration :
- Dans le cadre de votre processus de création de sauvegarde, les métadonnées Airflow sont répliquées dans un compartiment S3 à l'aide d'un utilitaire DAG d'exportation, exécuté périodiquement en fonction de votre intervalle RPO.
- Votre environnement Amazon MWAA principal existant émet automatiquement l'état de santé de son planificateur à CloudWatch PlanificateurHeartbeat métrique.
- Une machine d'état Step Functions en plusieurs étapes est déclenchée à partir d'une planification Amazon EventBridge périodique pour surveiller l'état de santé du planificateur. En tant qu'étape principale de la machine à états, une fonction Lambda évalue l'état du PlanificateurHeartbeat métrique. Si la métrique est jugée saine, aucune mesure n’est prise.
La figure suivante illustre les dernières étapes du flux de travail.
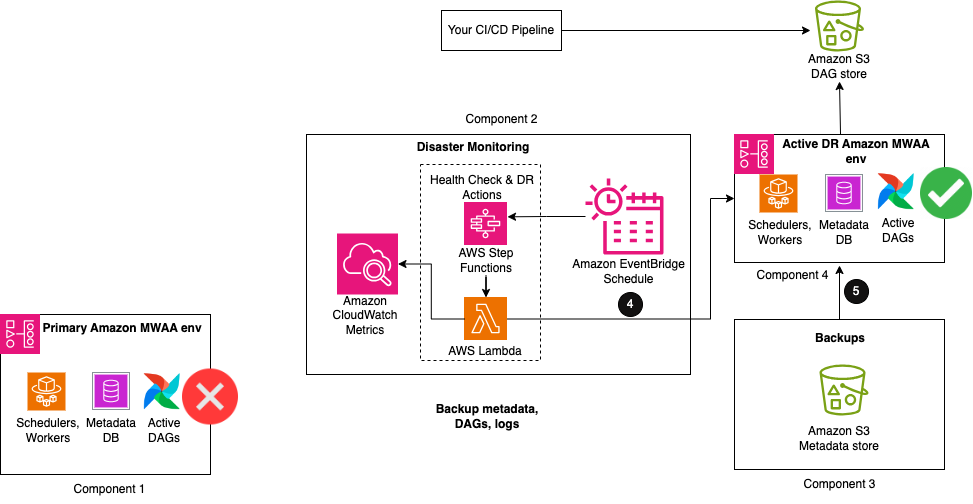
- Lorsque le nombre de battements de cœur s'écarte du nombre normal pendant un certain temps, des actions DR sont lancées.
- Dans un premier temps, une fonction Lambda déclenche un utilitaire d'importation DAG pour restaurer le contenu des métadonnées des sauvegardes vers l'environnement passif Amazon MWAA DR. Une fois les importations terminées, le même DAG peut réactiver les autres DAG Airflow, les rendant ainsi actifs pour les exécutions futures. Toutes les exécutions de DAG qui ont été interrompues lors de la dégradation de l'environnement principal doivent être réexécutées manuellement pour maintenir les accords de niveau de service. Les futures exécutions du DAG sont mises en file d’attente pour s’exécuter selon leur prochaine planification configurée.
Meilleures pratiques pour améliorer la résilience d'Amazon MWAA
Pour améliorer la résilience de votre environnement Amazon MWAA et garantir une reprise après sinistre fluide, envisagez de mettre en œuvre les bonnes pratiques suivantes :
- Mécanismes de sauvegarde et de restauration robustes – La mise en œuvre de mécanismes complets de sauvegarde et de restauration des données Amazon MWAA est essentielle. La suppression régulière des métadonnées existantes en fonction des politiques de rétention de votre organisation réduit les temps de sauvegarde et rend votre environnement Amazon MWAA plus performant.
- Automatisation à l'aide d'IaC – Utiliser des outils d’automatisation et d’orchestration tels que AWS CloudFormation, Kit de développement AWS Cloud (AWS CDK), ou Terraform peut rationaliser le déploiement et la gestion de la configuration des environnements Amazon MWAA. Cela garantit la cohérence, la reproductibilité et une récupération plus rapide lors des scénarios de reprise après sinistre.
- DAG et tâches idempotentes – Dans Airflow, un DAG est considéré comme idempotent si réexécuter plusieurs fois le même DAG avec les mêmes entrées a le même effet que de l’exécuter une seule fois. La conception de DAG idempotents et le maintien des tâches atomiques réduisent le temps de récupération en cas d'échec lorsque vous devez réexécuter manuellement un DAG interrompu dans votre environnement récupéré.
- Tests et validations réguliers – Une solide stratégie Amazon MWAA DR doit inclure des exercices de tests et de validation réguliers. En simulant des scénarios de catastrophe, vous pouvez identifier les lacunes de vos plans de reprise après sinistre, affiner les processus et garantir que vos environnements Amazon MWAA sont entièrement récupérables.
Conclusion
Dans cet article, nous avons exploré les défis liés à la reprise après sinistre d'Amazon MWAA et discuté des meilleures pratiques pour améliorer la résilience. Nous avons examiné deux solutions de stratégie de reprise après sinistre : la sauvegarde et la restauration et les environnements actif-passif avec synchronisation périodique des données. En mettant en œuvre ces solutions et en suivant les bonnes pratiques, vous pouvez protéger vos environnements Amazon MWAA, minimiser les temps d'arrêt et atténuer l'impact des catastrophes. Des tests, une validation et une adaptation réguliers à l'évolution des exigences sont cruciaux pour une stratégie de reprise après sinistre Amazon MWAA efficace. En évaluant et en affinant continuellement vos plans de reprise après sinistre, vous pouvez garantir la résilience et le fonctionnement ininterrompu de vos environnements Amazon MWAA, même face à des événements imprévus.
Pour plus de détails et des exemples de code sur Amazon MWAA, reportez-vous au Guide de l'utilisateur Amazon MWAA et par Exemples de dépôt GitHub d'Amazon MWAA.
À propos des auteurs
 Parnab Basak est architecte de solutions senior et spécialiste du sans serveur chez AWS. Il se spécialise dans la création de nouvelles solutions cloud natives en utilisant des pratiques de développement de logiciels modernes telles que le sans serveur, le DevOps et l'analyse. Parnab travaille en étroite collaboration dans le domaine des services d'analyse et d'intégration, aidant les clients à adopter les services AWS pour leurs besoins d'orchestration de flux de travail.
Parnab Basak est architecte de solutions senior et spécialiste du sans serveur chez AWS. Il se spécialise dans la création de nouvelles solutions cloud natives en utilisant des pratiques de développement de logiciels modernes telles que le sans serveur, le DevOps et l'analyse. Parnab travaille en étroite collaboration dans le domaine des services d'analyse et d'intégration, aidant les clients à adopter les services AWS pour leurs besoins d'orchestration de flux de travail.
 Chandan Rupakheti est architecte de solutions et spécialiste du sans serveur chez AWS. Il est un leader technique, un chercheur et un mentor passionné, doté du don de créer des solutions innovantes dans le cloud et de rassembler les parties prenantes dans leur parcours cloud. En dehors de sa vie professionnelle, il aime passer du temps avec sa famille et ses amis en plus d'écouter et de jouer de la musique.
Chandan Rupakheti est architecte de solutions et spécialiste du sans serveur chez AWS. Il est un leader technique, un chercheur et un mentor passionné, doté du don de créer des solutions innovantes dans le cloud et de rassembler les parties prenantes dans leur parcours cloud. En dehors de sa vie professionnelle, il aime passer du temps avec sa famille et ses amis en plus d'écouter et de jouer de la musique.
 Vinod Jayendra est responsable du support entreprise pour les comptes ISV chez Amazon Web Services, où il aide les clients à résoudre leurs problèmes d'architecture, d'exploitation et d'optimisation des coûts. Avec un accent particulier sur les technologies sans serveur, il s'appuie sur sa vaste expérience en développement d'applications pour proposer des solutions de premier plan. Au-delà du travail, il trouve de la joie à passer du temps de qualité en famille, à se lancer dans des aventures à vélo et à entraîner des équipes sportives de jeunes.
Vinod Jayendra est responsable du support entreprise pour les comptes ISV chez Amazon Web Services, où il aide les clients à résoudre leurs problèmes d'architecture, d'exploitation et d'optimisation des coûts. Avec un accent particulier sur les technologies sans serveur, il s'appuie sur sa vaste expérience en développement d'applications pour proposer des solutions de premier plan. Au-delà du travail, il trouve de la joie à passer du temps de qualité en famille, à se lancer dans des aventures à vélo et à entraîner des équipes sportives de jeunes.
 Rupesh Tiwari est architecte de solutions senior chez AWS à New York, avec un accent sur les services financiers. Il a plus de 18 ans d'expérience en informatique dans les domaines de la finance, de l'assurance et de l'éducation, et se spécialise dans l'architecture d'applications à grande échelle et les charges de travail de Big Data natives du cloud. Dans ses temps libres, Rupesh aime chanter au karaoké, regarder des séries télévisées comiques et créer des moments joyeux avec sa famille.
Rupesh Tiwari est architecte de solutions senior chez AWS à New York, avec un accent sur les services financiers. Il a plus de 18 ans d'expérience en informatique dans les domaines de la finance, de l'assurance et de l'éducation, et se spécialise dans l'architecture d'applications à grande échelle et les charges de travail de Big Data natives du cloud. Dans ses temps libres, Rupesh aime chanter au karaoké, regarder des séries télévisées comiques et créer des moments joyeux avec sa famille.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/disaster-recovery-strategies-for-amazon-mwaa-part-1/

