Introduction
L’IA générative est actuellement largement utilisée partout dans le monde. La capacité des grands modèles linguistiques à comprendre le texte fourni et à générer un texte basé sur celui-ci a conduit à de nombreuses applications, des chatbots aux analyseurs de texte. Mais souvent, ces grands modèles linguistiques génèrent du texte tel quel, de manière non structurée. Parfois, nous souhaitons que la sortie générée par les LLM soit dans un format de structures, disons un format JSON (JavaScript Object Notation). Disons que nous analysons une publication sur les réseaux sociaux en utilisant LLM, et nous avons besoin de la sortie générée par LLM dans le code lui-même en tant que variable JSON/python pour effectuer une autre tâche. Y parvenir avec Prompt Engineering est possible, mais cela prend beaucoup de temps de bricoler les invites. Pour résoudre ce problème, LangChain a introduit Output Parses, qui peuvent être utilisés pour convertir le stockage de sortie du LLM en un format structuré.

Objectifs d'apprentissage
- Interprétation de la sortie générée par les grands modèles linguistiques
- Création de structures de données personnalisées avec Pydantic
- Comprendre l'importance des modèles d'invite et générer un formatage de la sortie de LLM
- Apprenez à créer des instructions de format pour la sortie LLM avec LangChain
- Découvrez comment nous pouvons analyser les données JSON dans un objet Pydantic
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Qu'est-ce que LangChain et l'analyse de sortie ?
LangChaîne est une bibliothèque Python qui vous permet de créer des applications avec de grands modèles de langage en un rien de temps. Il prend en charge une grande variété de modèles, notamment les LLM OpenAI GPT, PaLM de Google, et même les modèles open source disponibles dans Hugging Face comme Falcon, Llama et bien d'autres. Avec LangChain, la personnalisation des invites vers les grands modèles de langage est un jeu d'enfant et il est également livré avec un magasin de vecteurs prêt à l'emploi, qui peut stocker les intégrations d'entrées et de sorties. Il peut ainsi être utilisé pour créer des applications capables d'interroger n'importe quel document en quelques minutes.
LangChain permet aux grands modèles linguistiques d'accéder aux informations sur Internet via des agents. Il propose également des analyseurs de sortie, qui nous permettent de structurer les données à partir de la sortie générée par les grands modèles linguistiques. LangChain est livré avec différentes analyses de sortie telles que List Parser, Datetime Parser, Enum Parser, etc. Dans cet article, nous examinerons l'analyseur JSON, qui nous permet d'analyser la sortie générée par les LLM au format JSON. Ci-dessous, nous pouvons observer un flux typique de la façon dont une sortie LLM est analysée dans un objet Pydantic, créant ainsi des données prêtes à l'emploi dans des variables Python.

Mise en route – Configuration du modèle
Dans cette section, nous allons configurer le modèle avec LangChain. Nous utiliserons PaLM comme grand modèle de langage tout au long de cet article. Nous utiliserons Google Colab pour notre environnement. Vous pouvez remplacer PaLM par n’importe quel autre modèle de langage étendu. Nous commencerons par importer d’abord les modules requis.
!pip install google-generativeai langchain- Cela téléchargera la bibliothèque LangChain et la bibliothèque google-generativeai pour travailler avec le modèle PaLM.
- La bibliothèque langchain est requise pour créer des invites personnalisées et analyser la sortie générée par les grands modèles de langage
- La bibliothèque google-generativeai nous permettra d'interagir avec le modèle PaLM de Google.
Clé API PaLM
Pour travailler avec PaLM, nous aurons besoin d'une clé API, que nous pouvons obtenir en nous inscrivant sur le site MakerSuite. Ensuite, nous importerons toutes nos bibliothèques nécessaires et transmettrons la clé API pour instancier le modèle PaLM.
import os
import google.generativeai as palm
from langchain.embeddings import GooglePalmEmbeddings
from langchain.llms import GooglePalm os.environ['GOOGLE_API_KEY']= 'YOUR API KEY'
palm.configure(api_key=os.environ['GOOGLE_API_KEY']) llm = GooglePalm()
llm.temperature = 0.1 prompts = ["Name 5 planets and line about them"]
llm_result = llm._generate(prompts)
print(llm_result.generations[0][0].text)- Ici, nous avons d'abord créé une instance de Google PaLM (Pathways Language Model) et l'avons assignée à la variable llm
- Dans l'étape suivante, nous définissons le la réactivité de notre modèle à 0.1, en le fixant à un niveau bas parce que nous ne voulons pas que le modèle hallucine
- Ensuite, nous avons créé une invite sous forme de liste et l'avons transmise à la variable instructions
- Pour transmettre l'invite au PaLM, nous appelons le ._générer() méthode, puis transmettez-lui la liste d'invites et les résultats sont stockés dans la variable llm_result
- Enfin, nous imprimons le résultat à la dernière étape en appelant le .générations et le convertir en texte en appelant le .text méthode
Le résultat de cette invite peut être vu ci-dessous
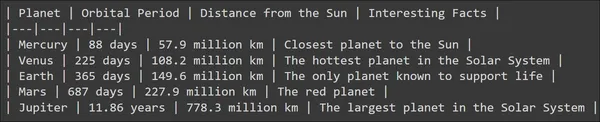
Nous pouvons voir que le Large Language Model a généré un résultat équitable et le LLM a également essayé d'y ajouter une certaine structure en ajoutant quelques lignes. Mais que se passe-t-il si je souhaite stocker les informations de chaque modèle dans une variable ? Que se passe-t-il si je souhaite stocker le nom de la planète, la période d'orbite et la distance au soleil, le tout séparément dans une variable ? Le résultat généré par le modèle tel quel ne peut pas être utilisé directement pour y parvenir. D’où le besoin d’analyses de sortie.
Création d'un analyseur de sortie Pydantic et d'un modèle d'invite
Dans cette section, discutez de l'analyseur de sortie pydantic de langchain. Dans l'exemple précédent, la sortie était dans un format non structuré. Regardez comment nous pouvons stocker les informations générées par le Large Language Model dans un format structuré.
Implémentation du code
Commençons par regarder le code suivant :
from pydantic import BaseModel, Field, validator
from langchain.output_parsers import PydanticOutputParser class PlanetData(BaseModel): planet: str = Field(description="This is the name of the planet") orbital_period: float = Field(description="This is the orbital period in the number of earth days") distance_from_sun: float = Field(description="This is a float indicating distance from sun in million kilometers") interesting_fact: str = Field(description="This is about an interesting fact of the planet")- Ici, nous importons le package Pydantic pour créer une structure de données. Et dans cette structure de données, nous stockerons la sortie en analysant la sortie du LLM.
- Ici, nous avons créé une structure de données en utilisant Pydantic appelée PlanèteDonnées qui stocke les données suivantes
- Planète: C'est le nom de la planète que nous donnerons en entrée au modèle
- Période d'orbite : Il s'agit d'une valeur flottante qui contient la période orbitale en jours terrestres pour une planète particulière.
- Distance du Soleil : Il s'agit d'un flotteur indiquant la distance d'une planète au Soleil
- Fait intéressant: Il s'agit d'une chaîne contenant un fait intéressant sur la planète demandé.
Maintenant, notre objectif est d'interroger le grand modèle linguistique pour obtenir des informations sur une planète et de stocker toutes ces données dans la structure de données PlanetData en analysant la sortie LLM. Pour analyser une sortie LLM dans une structure de données Pydantic, LangChain propose un analyseur appelé PydanticOutputParser. Nous transmettons la classe PlanetData à cet analyseur, qui peut être défini comme suit :
planet_parser = PydanticOutputParser(pydantic_object=PlanetData)Nous stockons l'analyseur dans une variable nommée planète_parser. L'objet analyseur a une méthode appelée get_format_instructions() qui indique au LLM comment générer la sortie. Essayons de l'imprimer
from pprint import pp
pp(planet_parser.get_format_instructions())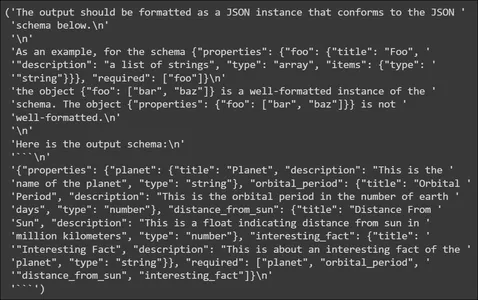
Dans ce qui précède, nous voyons que les instructions de format contiennent des informations sur la façon de formater la sortie générée par le LLM. Il indique au LLM de générer les données dans un schéma JSON, afin que ce JSON puisse être analysé dans la structure de données Pydantic. Il fournit également un exemple de schéma de sortie. Ensuite, nous allons créer un modèle d'invite.
Modèle d'invite
from langchain import PromptTemplate, LLMChain template_string = """You are an expert when it comes to answering questions about planets You will be given a planet name and you will output the name of the planet, it's orbital period in days Also it's distance from sun in million kilometers and an interesting fact ```{planet_name}``` {format_instructions} """ planet_prompt = PromptTemplate( template=template_string, input_variables=["planet_name"], partial_variables={"format_instructions": planet_parser
.get_format_instructions()}
)
- Dans notre modèle d'invite, nous disons que nous donnerons un nom de planète en entrée et que le LLM doit générer une sortie qui inclut des informations telles que la période d'orbite, la distance par rapport au Soleil et un fait intéressant sur la planète.
- Ensuite, nous attribuons ce modèle au Modèle d'invite() puis fournissez le nom de la variable d'entrée au variables_d'entrée paramètre, dans notre cas c'est le nom_planète
- Nous donnons également des instructions dans le format que nous avons vues précédemment, qui indiquent au LLM comment générer la sortie au format JSON.
Essayons de donner un nom de planète et observons à quoi ressemble l'invite avant d'être envoyée au grand modèle de langage.
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
pp(input_prompt.to_string())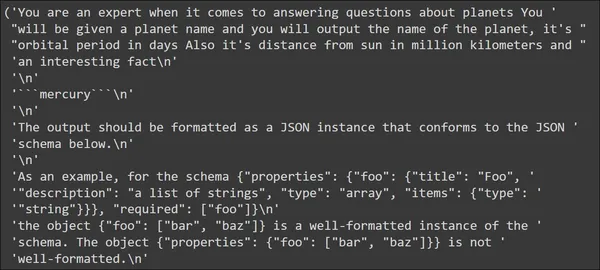
Dans le résultat, nous voyons que le modèle que nous avons défini apparaît en premier avec l'entrée « mercure ». Viennent ensuite les instructions de format. Ces instructions de format contiennent les instructions que le LLM peut utiliser pour générer des données JSON.
Test du grand modèle de langage
Dans cette section, nous enverrons notre contribution au LLM et observerons les données générées. Dans la section précédente, voyez comment sera notre chaîne d’entrée lorsqu’elle sera envoyée au LLM.
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
output = llm(input_prompt.to_string())
pp(output)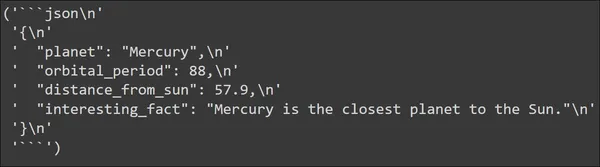
Nous pouvons voir le résultat généré par le Large Language Model. La sortie est en effet générée au format JSON. Les données JSON contiennent toutes les clés que nous avons définies dans notre structure de données PlanetData. Et chaque clé a une valeur que nous attendons d’elle.
Nous devons maintenant analyser ces données JSON selon la structure de données que nous avons créée. Cela peut être facilement fait avec le PydanticOutputParser que nous avons défini précédemment. Regardons ce code :
parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun(in Million KM): ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)L'appel de la méthode parse() pour le planet_parser prendra la sortie, puis l'analysera et la convertira en un objet Pydantic, dans notre cas, un objet de PlanetData. Ainsi, la sortie, c'est-à-dire le JSON généré par le Large Language Model, est analysée dans la structure de données PlannetData et nous pouvons maintenant accéder aux données individuelles à partir de celle-ci. Le résultat de ce qui précède sera

Nous voyons que les paires clé-valeur des données JSON ont été correctement analysées dans les données Pydantic. Essayons avec une autre planète et observons le résultat
input_prompt = planet_prompt.format_prompt(planet_name='venus')
output = llm(input_prompt.to_string()) parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun: ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)
Nous voyons que pour l'entrée « Venus », le LLM a pu générer un JSON comme sortie et il a été analysé avec succès dans Pydantic Data. De cette façon, grâce à l'analyse des résultats, nous pouvons utiliser directement les informations générées par les grands modèles linguistiques.
Applications potentielles et cas d'utilisation
Dans cette section, nous passerons en revue quelques applications/cas d'utilisation potentiels du monde réel, dans lesquels nous pouvons utiliser ces techniques d'analyse de sortie. Utilisez l'analyse en extraction/après extraction, c'est-à-dire lorsque nous extrayons tout type de données, nous souhaitons les analyser afin que les informations extraites puissent être consommées par d'autres applications. Certaines des applications incluent :
- Extraction et analyse des réclamations relatives aux produits : Lorsqu'une nouvelle marque arrive sur le marché et lance ses nouveaux produits, la première chose qu'elle veut faire est de vérifier les performances du produit, et l'un des meilleurs moyens de l'évaluer est d'analyser les publications des consommateurs utilisant ces produits sur les réseaux sociaux. Les analyseurs de sortie et les LLM permettent d'extraire des informations, telles que les noms de marque et de produit, et même les plaintes des publications d'un consommateur sur les réseaux sociaux. Ces grands modèles linguistiques stockent ces données dans des variables pythoniques via une analyse de sortie, vous permettant de les utiliser pour des visualisations de données.
- Service à la Clientèle: Lors de la création de chatbots avec des LLM pour le support client, une tâche importante sera d'extraire les informations de l'historique des discussions du client. Ces informations contiennent des détails clés tels que les problèmes auxquels les consommateurs sont confrontés en ce qui concerne le produit/service. Vous pouvez facilement extraire ces détails à l'aide des analyseurs de sortie LangChain au lieu de créer du code personnalisé pour extraire ces informations.
- Informations sur l'offre d'emploi : Lors du développement de plateformes de recherche d'emploi comme Indeed, LinkedIn, etc., nous pouvons utiliser les LLM pour extraire les détails des offres d'emploi, notamment les titres de poste, les noms d'entreprises, les années d'expérience et les descriptions de poste. L'analyse des résultats peut enregistrer ces informations sous forme de données JSON structurées pour la correspondance des tâches et les recommandations. L'analyse de ces informations à partir de la sortie LLM directement via les analyseurs de sortie LangChain supprime une grande partie du code redondant nécessaire pour effectuer cette opération d'analyse distincte.
Conclusion
Les grands modèles linguistiques sont excellents, car ils peuvent littéralement s'adapter à tous les cas d'utilisation grâce à leurs extraordinaires capacités de génération de texte. Mais le plus souvent, ils ne parviennent pas à utiliser réellement le résultat généré, où nous devons passer beaucoup de temps à analyser le résultat. Dans cet article, nous avons examiné ce problème et comment nous pouvons le résoudre à l'aide des analyseurs de sortie de LangChain, en particulier l'analyseur JSON qui peut analyser les données JSON générées à partir de LLM et les convertir en un objet Pydantic.
Faits marquants
Certains des principaux points à retenir de cet article incluent :
- LangChain est une bibliothèque Python qui peut créer des applications avec les grands modèles de langage existants.
- LangChain fournit des analyseurs de sortie qui nous permettent d'analyser la sortie générée par les grands modèles linguistiques.
- Pydantic nous permet de définir des structures de données personnalisées, qui peuvent être utilisées lors de l'analyse de la sortie des LLM.
- Outre l'analyseur Pydantic JSON, LangChain fournit également différents analyseurs de sortie tels que l'analyseur List, l'analyseur Datetime, l'analyseur Enum, etc.
Foire aux Questions
R. JSON, acronyme de JavaScript Object Notation, est un format de données structurées. Il contient des données sous forme de paires clé-valeur.
A. Pydantic est une bibliothèque Python qui crée des structures de données personnalisées et effectue la validation des données. Il vérifie si chaque élément de données correspond au type attribué, validant ainsi les données fournies.
A. Faites cela avec Prompt Engineering, où bricoler l'invite pourrait nous amener à faire en sorte que le LLM génère des données JSON en sortie. Pour faciliter ce processus, LangChain dispose d'analyseurs de sortie que vous pouvez utiliser pour cette tâche.
A. Les analyseurs de sortie dans LangChain nous permettent de formater la sortie générée par les grands modèles de langage de manière structurée. Cela nous permet d'accéder facilement aux informations des grands modèles linguistiques pour d'autres tâches.
A. LangChain est livré avec différents analyseurs de sortie comme Pydantic Parser, List Parsr, Enum Parser, Datetime Parser, etc.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/11/structured-llm-output-storage-and-parsing-in-python/

