Cet article est co-écrit avec Preshen Goobiah et Johan Olivier de Capitec.
Apache Spark est un système de traitement distribué open source largement utilisé, réputé pour gérer des charges de travail de données à grande échelle. Il trouve une application fréquente parmi les développeurs Spark travaillant avec Amazon DME, Amazon Sage Maker, Colle AWS et des applications Spark personnalisées.
Redshift d'Amazon offre une intégration transparente avec Apache Spark, vous permettant d'accéder facilement à vos données Redshift sur les clusters provisionnés Amazon Redshift et Amazon Redshift sans serveur. Cette intégration étend les possibilités des solutions d'analyse et d'apprentissage automatique AWS (ML), rendant l'entrepôt de données accessible à une gamme plus large d'applications.
Avec la Intégration Amazon Redshift pour Apache Spark, vous pouvez démarrer rapidement et développer sans effort des applications Spark à l'aide de langages populaires tels que Java, Scala, Python, SQL et R. Vos applications peuvent lire et écrire en toute transparence depuis votre entrepôt de données Amazon Redshift tout en conservant des performances optimales et une cohérence transactionnelle. De plus, vous bénéficierez d'améliorations de performances grâce à des optimisations de refoulement, améliorant encore l'efficacité de vos opérations.
Capitec, la plus grande banque de détail d'Afrique du Sud avec plus de 21 millions de clients, vise à fournir des services financiers simples, abordables et accessibles afin d'aider les Sud-Africains à mieux effectuer leurs opérations bancaires et à vivre mieux. Dans cet article, nous discutons de l'intégration réussie du connecteur open source Amazon Redshift par l'équipe Feature Platform des services partagés de Capitec. Grâce à l'intégration d'Amazon Redshift pour Apache Spark, la productivité des développeurs a été multipliée par 10, les pipelines de génération de fonctionnalités ont été rationalisés et la duplication des données réduite à zéro.
L'opportunité d'affaires
Il existe 19 modèles prédictifs permettant d'utiliser 93 fonctionnalités créées avec AWS Glue dans les divisions de crédit au détail de Capitec. Les enregistrements de fonctionnalités sont enrichis de faits et de dimensions stockés dans Amazon Redshift. Apache PySpark a été sélectionné pour créer des fonctionnalités car il offre un mécanisme rapide, décentralisé et évolutif pour gérer les données provenant de diverses sources.
Ces fonctionnalités de production jouent un rôle crucial en permettant les demandes de prêt à terme fixe en temps réel, les demandes de carte de crédit, la surveillance mensuelle par lots du comportement de crédit et l'identification par lots des salaires quotidiens au sein de l'entreprise.
Le problème de la source de données
Pour garantir la fiabilité des pipelines de données PySpark, il est essentiel de disposer de données cohérentes au niveau des enregistrements provenant des tables dimensionnelles et de faits stockées dans l'Enterprise Data Warehouse (EDW). Ces tables sont ensuite jointes aux tables d'Enterprise Data Lake (EDL) au moment de l'exécution.
Lors du développement de fonctionnalités, les ingénieurs de données ont besoin d'une interface transparente avec l'EDW. Cette interface leur permet d'accéder et d'intégrer les données nécessaires de l'EDW dans les pipelines de données, permettant un développement et des tests efficaces des fonctionnalités.
Processus de solution précédent
Dans la solution précédente, les ingénieurs de données de l'équipe produit passaient 30 minutes par exécution pour exposer manuellement les données Redshift à Spark. Les étapes comprenaient les suivantes :
- Construisez une requête prédite en Python.
- soumettre un DÉCHARGER requête via le API de données Amazon Redshift.
- Cataloguez les données dans le catalogue de données AWS Glue via le kit AWS SDK for Pandas à l'aide de l'échantillonnage.
Cette approche posait des problèmes pour les grands ensembles de données, nécessitait une maintenance récurrente de la part de l'équipe de la plateforme et était complexe à automatiser.
Présentation de la solution actuelle
Capitec a pu résoudre ces problèmes grâce à l'intégration d'Amazon Redshift pour Apache Spark dans les pipelines de génération de fonctionnalités. L'architecture est définie dans le schéma suivant.
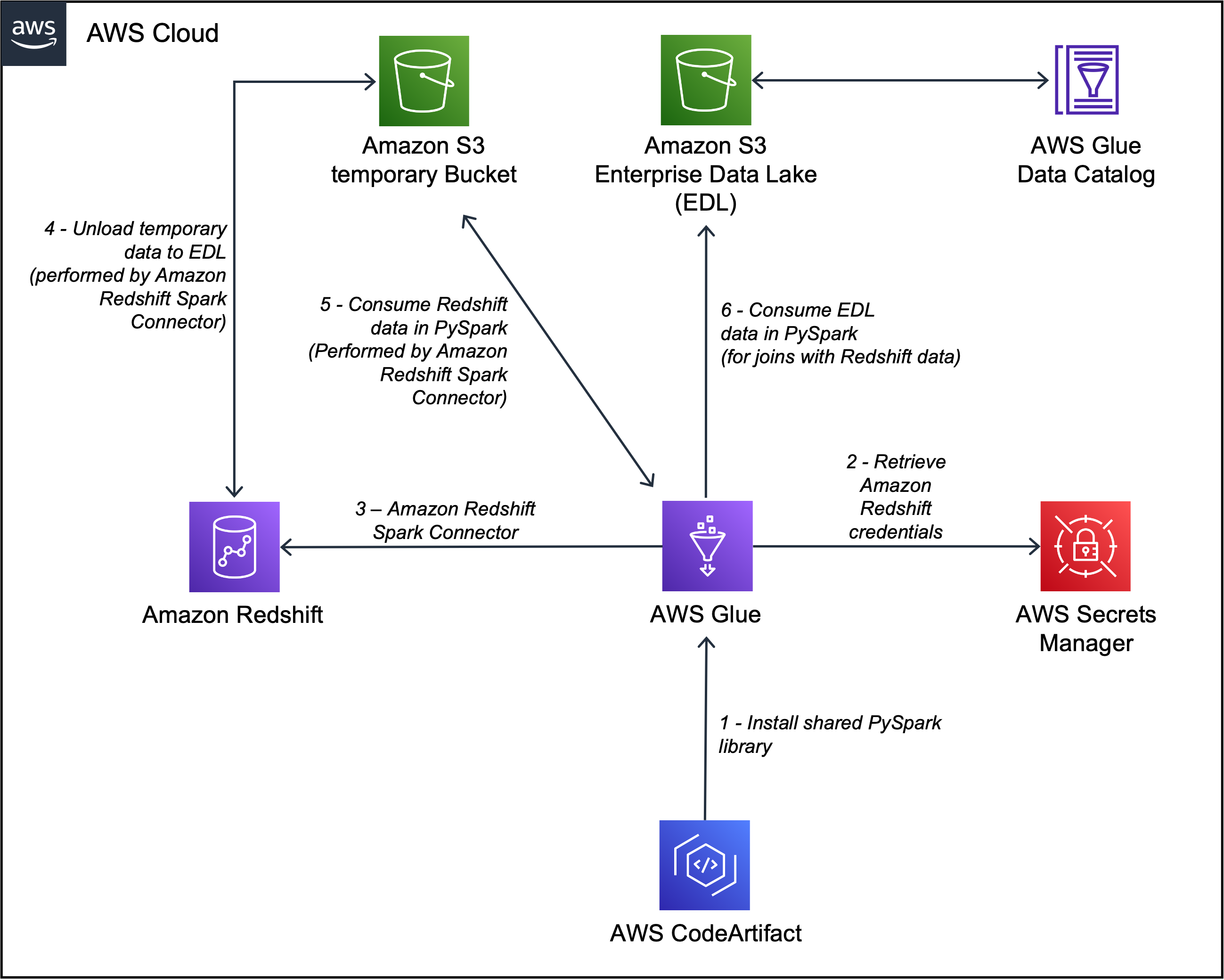
Le workflow comprend les étapes suivantes:
- Les bibliothèques internes sont installées dans la tâche AWS Glue PySpark via Code AWSArtifact.
- Une tâche AWS Glue récupère les informations d'identification du cluster Redshift à partir de AWS Secrets Manager et configure la connexion Amazon Redshift (injecte les informations d'identification du cluster, les emplacements de déchargement, les formats de fichiers) via la bibliothèque interne partagée. L'intégration Amazon Redshift pour Apache Spark prend également en charge l'utilisation Gestion des identités et des accès AWS (IAM) à récupérer les informations d'identification et se connecter à Amazon Redshift.
- La requête Spark est traduite en requête optimisée Amazon Redshift et soumise à l'EDW. Ceci est accompli par l'intégration Amazon Redshift pour Apache Spark.
- L'ensemble de données EDW est déchargé dans un préfixe temporaire dans un Service de stockage simple Amazon (Amazon S3) seau.
- L'ensemble de données EDW du compartiment S3 est chargé dans les exécuteurs Spark via l'intégration Amazon Redshift pour Apache Spark.
- L'ensemble de données EDL est chargé dans les exécuteurs Spark via le catalogue de données AWS Glue.
Ces composants fonctionnent ensemble pour garantir que les ingénieurs de données et les pipelines de données de production disposent des outils nécessaires pour mettre en œuvre l'intégration Amazon Redshift pour Apache Spark, exécuter des requêtes et faciliter le déchargement des données d'Amazon Redshift vers l'EDL.
Utilisation de l'intégration Amazon Redshift pour Apache Spark dans AWS Glue 4.0
Dans cette section, nous démontrons l'utilité de l'intégration d'Amazon Redshift pour Apache Spark en enrichissant une table de demande de prêt résidant dans le lac de données S3 avec les informations client de l'entrepôt de données Redshift dans PySpark.
La dimclient Le tableau dans Amazon Redshift contient les colonnes suivantes :
- Clé Client -INT8
- ClientAltKey – VARCHAR50
- PartyIdentifierNuméro – VARCHAR20
- DateCréationClient - DATE
- Est annulé -INT2
- La ligne est actuelle -INT2
La loanapplication Le tableau du catalogue de données AWS Glue contient les colonnes suivantes :
- ID d'enregistrement -GRAND
- Date du journal – HORODATAGE
- PartyIdentifierNuméro - CHAÎNE
La table Redshift est lue via l'intégration Amazon Redshift pour Apache Spark et mise en cache. Voir le code suivant :
Les enregistrements de demande de prêt sont lus à partir du lac de données S3 et enrichis avec les dimclient tableau sur les informations d'Amazon Redshift :
De ce fait, le dossier de demande de prêt (issu du lac de données S3) est enrichi avec les ClientCreateDate colonne (d’Amazon Redshift).

Comment l'intégration d'Amazon Redshift pour Apache Spark résout le problème de sourcing des données
L'intégration d'Amazon Redshift pour Apache Spark résout efficacement le problème d'approvisionnement en données grâce aux mécanismes suivants :
- Lecture juste à temps – L'intégration Amazon Redshift pour le connecteur Apache Spark lit les tables Redshift juste à temps, garantissant ainsi la cohérence des données et du schéma. Ceci est particulièrement précieux pour Type 2 : dimension à changement lent (SCD) et la durée d'accumulation des faits instantanés. En combinant ces tables Redshift avec les tables AWS Glue Data Catalog du système source de l'EDL dans les pipelines de production PySpark, le connecteur permet une intégration transparente des données provenant de plusieurs sources tout en préservant l'intégrité des données.
- Requêtes Redshift optimisées – L'intégration Amazon Redshift pour Apache Spark joue un rôle crucial dans la conversion du plan de requête Spark en une requête Redshift optimisée. Ce processus de conversion simplifie l'expérience de développement de l'équipe produit en adhérant au principe de localité des données. Les requêtes optimisées utilisent les capacités et les optimisations de performances d'Amazon Redshift, garantissant une récupération et un traitement efficaces des données d'Amazon Redshift pour les pipelines PySpark. Cela permet de rationaliser le processus de développement tout en améliorant les performances globales des opérations d'approvisionnement en données.
Obtenir les meilleures performances
L'intégration Amazon Redshift pour Apache Spark applique automatiquement le refoulement des prédicats et des requêtes pour optimiser les performances. Vous pouvez améliorer les performances en utilisant le format Parquet par défaut utilisé pour le déchargement avec cette intégration.
Pour plus de détails et des exemples de code, reportez-vous à Nouveau – Intégration Amazon Redshift avec Apache Spark.
Avantages de la solution
L'adoption de l'intégration a apporté plusieurs avantages importants à l'équipe :
- Productivité améliorée des développeurs – L'interface PySpark fournie par l'intégration a multiplié par 10 la productivité des développeurs, permettant une interaction plus fluide avec Amazon Redshift.
- Élimination de la duplication des données – Les tables Redshift en double et cataloguées par AWS Glue dans le lac de données ont été éliminées, ce qui a permis d'obtenir un environnement de données plus rationalisé.
- Charge EDW réduite – L'intégration a facilité le déchargement sélectif des données, minimisant la charge sur l'EDW en extrayant uniquement les données nécessaires.
En utilisant l'intégration Amazon Redshift pour Apache Spark, Capitec a ouvert la voie à un traitement des données amélioré, à une productivité accrue et à un écosystème d'ingénierie de fonctionnalités plus efficace.
Conclusion
Dans cet article, nous avons expliqué comment l'équipe Capitec a mis en œuvre avec succès l'intégration Apache Spark Amazon Redshift pour Apache Spark afin de simplifier ses flux de travail de calcul de fonctionnalités. Ils ont souligné l'importance d'utiliser des pipelines de données PySpark décentralisés et modulaires pour créer des fonctionnalités de modèle prédictif.
Actuellement, l'intégration d'Amazon Redshift pour Apache Spark est utilisée par 7 pipelines de données de production et 20 pipelines de développement, démontrant son efficacité dans l'environnement de Capitec.
À l'avenir, l'équipe Feature Platform de services partagés de Capitec prévoit d'étendre l'adoption de l'intégration Amazon Redshift pour Apache Spark dans différents domaines d'activité, dans le but d'améliorer davantage les capacités de traitement des données et de promouvoir des pratiques efficaces d'ingénierie des fonctionnalités.
Pour plus d'informations sur l'utilisation de l'intégration Amazon Redshift pour Apache Spark, consultez les ressources suivantes :
À propos des auteurs
 Preshen Goobiah est l'ingénieur principal en apprentissage automatique pour la plate-forme de fonctionnalités chez Capitec. Il se concentre sur la conception et la création de composants Feature Store destinés à une utilisation en entreprise. Dans ses temps libres, il aime lire et voyager.
Preshen Goobiah est l'ingénieur principal en apprentissage automatique pour la plate-forme de fonctionnalités chez Capitec. Il se concentre sur la conception et la création de composants Feature Store destinés à une utilisation en entreprise. Dans ses temps libres, il aime lire et voyager.
 Johan Olivier est ingénieur senior en apprentissage automatique pour la plateforme modèle de Capitec. C'est un entrepreneur et un passionné de résolution de problèmes. Il aime la musique et socialiser pendant son temps libre.
Johan Olivier est ingénieur senior en apprentissage automatique pour la plateforme modèle de Capitec. C'est un entrepreneur et un passionné de résolution de problèmes. Il aime la musique et socialiser pendant son temps libre.
 Sudipta Bagchi est architecte de solutions spécialisé senior chez Amazon Web Services. Il possède plus de 12 ans d'expérience dans le domaine des données et de l'analyse et aide les clients à concevoir et à créer des solutions d'analyse évolutives et hautement performantes. En dehors du travail, il adore courir, voyager et jouer au cricket. Connectez-vous avec lui sur LinkedIn.
Sudipta Bagchi est architecte de solutions spécialisé senior chez Amazon Web Services. Il possède plus de 12 ans d'expérience dans le domaine des données et de l'analyse et aide les clients à concevoir et à créer des solutions d'analyse évolutives et hautement performantes. En dehors du travail, il adore courir, voyager et jouer au cricket. Connectez-vous avec lui sur LinkedIn.
 Syed Humair est architecte de solutions spécialiste senior de l'analyse chez Amazon Web Services (AWS). Il possède plus de 17 ans d'expérience dans l'architecture d'entreprise, axée sur les données et l'IA/ML, aidant les clients AWS du monde entier à répondre à leurs exigences commerciales et techniques. Vous pouvez vous connecter avec lui sur LinkedIn.
Syed Humair est architecte de solutions spécialiste senior de l'analyse chez Amazon Web Services (AWS). Il possède plus de 17 ans d'expérience dans l'architecture d'entreprise, axée sur les données et l'IA/ML, aidant les clients AWS du monde entier à répondre à leurs exigences commerciales et techniques. Vous pouvez vous connecter avec lui sur LinkedIn.
 Vuyisa Maswana est architecte de solutions senior chez AWS, basé au Cap. Vuyisa s'attache fortement à aider ses clients à élaborer des solutions techniques pour résoudre les problèmes commerciaux. Il soutient Capitec dans son parcours AWS depuis 2019.
Vuyisa Maswana est architecte de solutions senior chez AWS, basé au Cap. Vuyisa s'attache fortement à aider ses clients à élaborer des solutions techniques pour résoudre les problèmes commerciaux. Il soutient Capitec dans son parcours AWS depuis 2019.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/

