Vers la fin de 2022, AWS a annoncé la disponibilité générale de l'ingestion de streaming en temps réel à Redshift d'Amazon en Flux de données Amazon Kinesis ainsi que Amazon Managed Streaming pour Apache Kafka (Amazon MSK), éliminant ainsi le besoin de transférer les données en continu dans Service de stockage simple Amazon (Amazon S3) avant de l'ingérer dans Amazon Redshift.
Ingestion en streaming d'Amazon MSK vers Amazon Redshift, représente une approche de pointe en matière de traitement et d'analyse de données en temps réel. Amazon MSK constitue un service hautement évolutif et entièrement géré pour Apache Kafka, permettant une collecte et un traitement transparents de vastes flux de données. L'intégration de données en streaming dans Amazon Redshift apporte une valeur immense en permettant aux organisations d'exploiter le potentiel de l'analyse en temps réel et de la prise de décision basée sur les données.
Cette intégration vous permet d'obtenir une faible latence, mesurée en secondes, tout en ingérant des centaines de mégaoctets de données en streaming par seconde dans Amazon Redshift. Dans le même temps, cette intégration permet de garantir que les informations les plus récentes sont facilement disponibles pour analyse. Étant donné que l'intégration ne nécessite pas de données intermédiaires dans Amazon S3, Amazon Redshift peut ingérer des données en streaming avec une latence plus faible et sans coût de stockage intermédiaire.
Vous pouvez configurer l'ingestion de streaming Amazon Redshift sur un cluster Redshift à l'aide d'instructions SQL pour vous authentifier et vous connecter à une rubrique MSK. Cette solution constitue une excellente option pour les ingénieurs de données qui cherchent à simplifier les pipelines de données et à réduire les coûts opérationnels.
Dans cet article, nous fournissons un aperçu complet de la façon de configurer Ingestion de flux Amazon Redshift d'Amazon MSK.
Vue d'ensemble de la solution
Le diagramme d'architecture suivant décrit les services et fonctionnalités AWS que vous utiliserez.

Le workflow comprend les étapes suivantes:
- Vous commencez par configurer un Connexion Amazon MSK connecteur source, pour créer une rubrique MSK, générer des données fictives et les écrire dans la rubrique MSK. Pour cet article, nous travaillons avec des données clients fictives.
- L'étape suivante consiste à se connecter à un cluster Redshift à l'aide du Éditeur de requête v2.
- Enfin, vous configurez un schéma externe et créez une vue matérialisée dans Amazon Redshift, pour consommer les données de la rubrique MSK. Cette solution ne s'appuie pas sur un connecteur récepteur MSK Connect pour exporter les données d'Amazon MSK vers Amazon Redshift.
Le diagramme d'architecture de solution suivant décrit plus en détail la configuration et l'intégration des services AWS que vous utiliserez.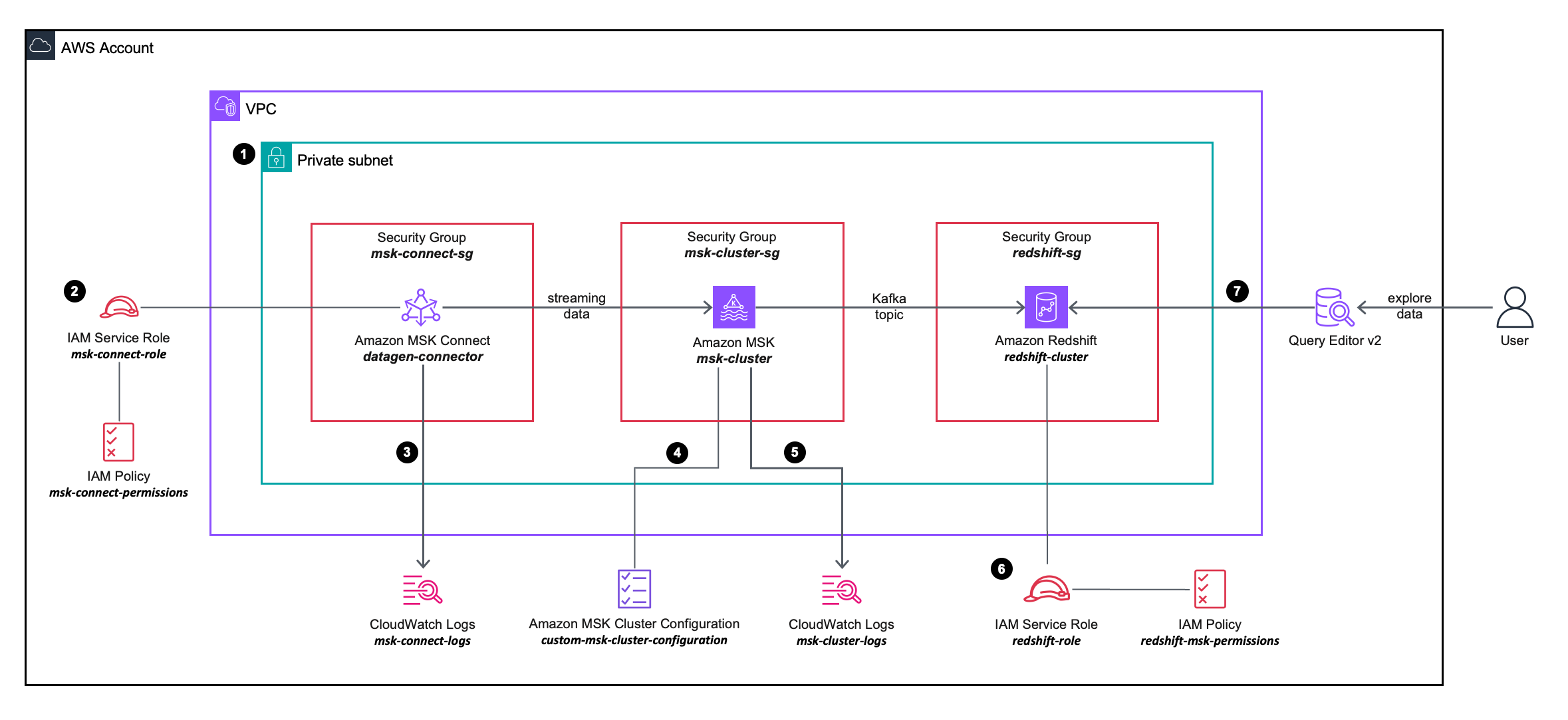
Le workflow comprend les étapes suivantes:
- Vous déployez un connecteur source MSK Connect, un cluster MSK et un cluster Redshift dans les sous-réseaux privés d'un VPC.
- Le connecteur source MSK Connect utilise des autorisations granulaires définies dans un Gestion des identités et des accès AWS (IAM) politique en ligne attaché à un Rôle IAM, qui permet au connecteur source d'effectuer des actions sur le cluster MSK.
- Les journaux du connecteur source MSK Connect sont capturés et envoyés à un Amazon Cloud Watch groupe de journaux.
- Le cluster MSK utilise un configuration de cluster MSK personnalisée, permettant au connecteur MSK Connect de créer des sujets sur le cluster MSK.
- Les journaux du cluster MSK sont capturés et envoyés à un groupe de journaux Amazon CloudWatch.
- Le cluster Redshift utilise des autorisations granulaires définies dans une stratégie en ligne IAM attachée à un rôle IAM, ce qui permet au cluster Redshift d'effectuer des actions sur le cluster MSK.
- Vous pouvez utiliser l'éditeur de requête v2 pour vous connecter au cluster Redshift.
Pré-requis
Pour simplifier le provisionnement et la configuration des ressources prérequises, vous pouvez utiliser les éléments suivants AWS CloudFormation modèle:
![]()
Effectuez les étapes suivantes lors du lancement de la pile :
- Pour Nom de la pile, entrez un nom significatif pour la pile, par exemple,
prerequisites. - Selectionnez Suivant.
- Selectionnez Suivant.
- Sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM avec des noms personnalisés.
- Selectionnez Soumettre.
La pile CloudFormation crée les ressources suivantes :
- Un VPC
custom-vpc, créé sur trois zones de disponibilité, avec trois sous-réseaux publics et trois sous-réseaux privés:- Les sous-réseaux publics sont associés à une table de routage publique et le trafic sortant est dirigé vers une passerelle Internet.
- Les sous-réseaux privés sont associés à une table de routage privée et le trafic sortant est envoyé vers une passerelle NAT.
- An passerelle internet attaché au Amazon VPC.
- A passerelle NAT qui est associé à un IP élastique et est déployé dans l'un des sous-réseaux publics.
- Trois sièges d’ groupes de sécurité:
msk-connect-sg, qui sera ultérieurement associé au connecteur MSK Connect.redshift-sg, qui sera ultérieurement associé au cluster Redshift.msk-cluster-sg, qui sera ensuite associé au cluster MSK. Il autorise le trafic entrant depuismsk-connect-sgetredshift-sg.
- Deux groupes de journaux CloudWatch :
msk-connect-logs, à utiliser pour les journaux MSK Connect.msk-cluster-logs, à utiliser pour les journaux du cluster MSK.
- Deux rôles IAM :
msk-connect-role, qui inclut des autorisations IAM granulaires pour MSK Connect.redshift-role, qui inclut des autorisations IAM granulaires pour Amazon Redshift.
- A configuration de cluster MSK personnalisée, permettant au connecteur MSK Connect de créer des sujets sur le cluster MSK.
- Un cluster MSK, avec trois courtiers déployés sur les trois sous-réseaux privés de
custom-vpc. Lamsk-cluster-sggroupe de sécurité et lecustom-msk-cluster-configurationla configuration est appliquée au cluster MSK. Les journaux du courtier sont livrés aumsk-cluster-logsGroupe de journaux CloudWatch. - A Groupe de sous-réseaux du cluster Redshift, qui utilise les trois sous-réseaux privés de
custom-vpc. - Un cluster Redshift, avec un seul nœud déployé dans un sous-réseau privé au sein du groupe de sous-réseaux du cluster Redshift. Le
redshift-sggroupe de sécurité etredshift-roleLes rôles IAM sont appliqués au cluster Redshift.
Créer un plugin personnalisé MSK Connect
Pour ce poste, nous utilisons un Générateur de données Amazon MSK déployé dans MSK Connect, pour générer des données client fictives et les écrire dans une rubrique MSK.
Effectuez les étapes suivantes:
- Télécharger Générateur de données Amazon MSK Fichier JAR avec dépendances de GitHub.

- Téléchargez le fichier JAR dans un compartiment S3 de votre compte AWS.
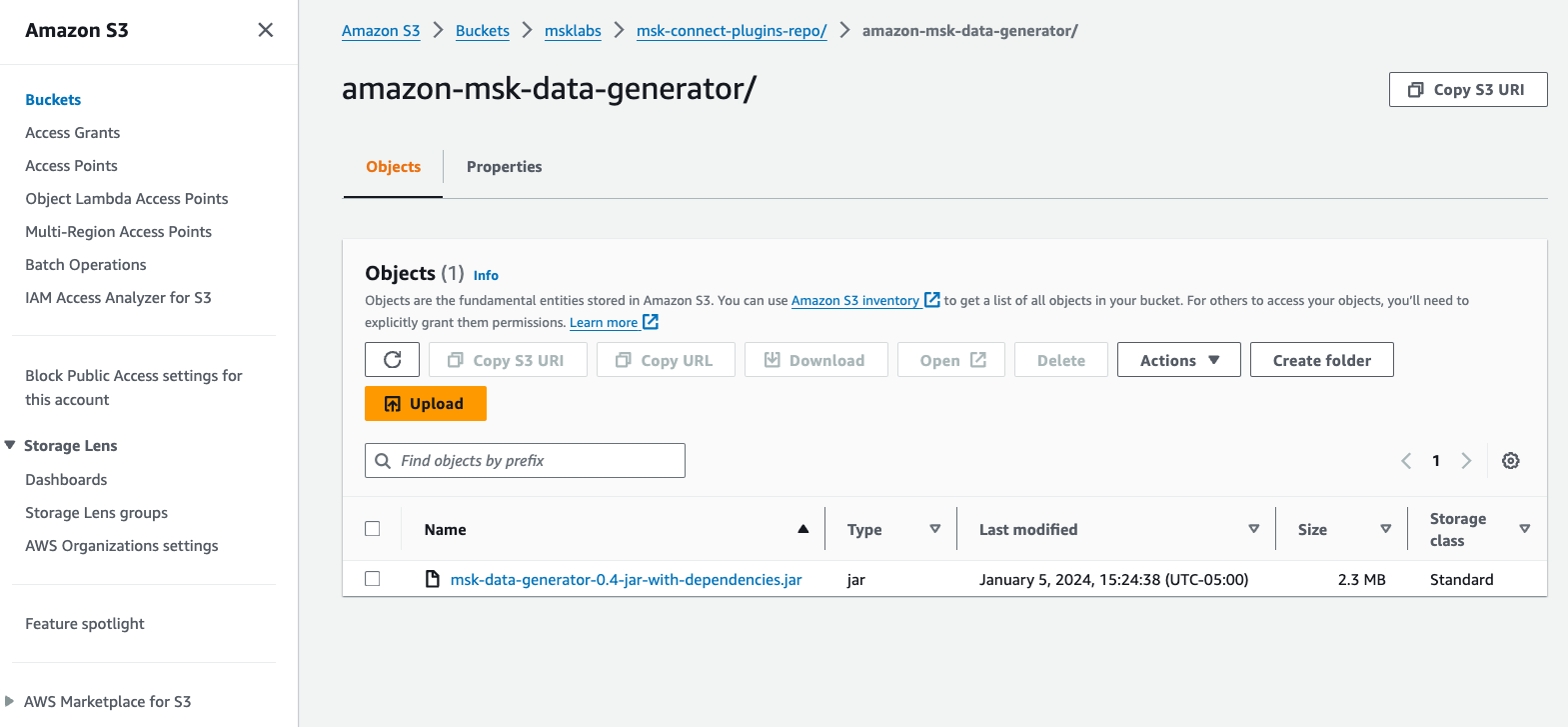
- Sur la console Amazon MSK, choisissez Plugins personnalisés sous MSK Connecter dans le volet de navigation.
- Selectionnez Créez un plugin personnalisé.
- Selectionnez Parcourir S3, recherchez le fichier JAR du générateur de données Amazon MSK que vous avez téléchargé sur Amazon S3, puis choisissez Selectionnez.
- Pour Nom du plug-in personnalisé, Entrer
msk-datagen-plugin. - Selectionnez Créez un plugin personnalisé.
Lorsque le plugin personnalisé est créé, vous verrez que son statut est Actif, et vous pouvez passer à l'étape suivante.
Créer un connecteur MSK Connect
Effectuez les étapes suivantes pour créer votre connecteur :
- Sur la console Amazon MSK, choisissez Connecteurs RF sous MSK Connecter dans le volet de navigation.
- Selectionnez Créez un connecteur.
- Pour Type de plugin personnalisé, choisissez Utilisez le plugin existant.
- Sélectionnez
msk-datagen-plugin, Puis choisissez Suivant. - Pour Nom du connecteur, Entrer
msk-datagen-connector. - Pour Type de grappe, choisissez Cluster Apache Kafka autogéré.
- Pour VPC, choisissez
custom-vpc. - Pour Sous-réseau 1, choisissez le sous-réseau privé dans votre première zone de disponibilité.
Pour le custom-vpc créé par le modèle CloudFormation, nous utilisons des plages CIDR impaires pour les sous-réseaux publics, et même des plages CIDR pour les sous-réseaux privés :
-
- Les CIDR pour les sous-réseaux publics sont 10.10.1.0/24, 10.10.3.0/24 et 10.10.5.0/24.
- Les CIDR pour les sous-réseaux privés sont 10.10.2.0/24, 10.10.4.0/24 et 10.10.6.0/24.
- Pour Sous-réseau 2, sélectionnez le sous-réseau privé dans votre deuxième zone de disponibilité.
- Pour Sous-réseau 3, sélectionnez le sous-réseau privé dans votre troisième zone de disponibilité.
- Pour Serveurs d'amorçage, saisissez la liste des serveurs d'amorçage pour l'authentification TLS de votre cluster MSK.
À récupérer les serveurs d'amorçage de votre cluster MSK, accédez à la console Amazon MSK, choisissez Clusters, choisissez msk-cluster, Puis choisissez Afficher les informations sur les clients. Copiez les valeurs TLS pour les serveurs d'amorçage.
- Pour Groupes de sécurité, choisissez Utiliser des groupes de sécurité spécifiques ayant accès à ce clusteret choisissez
msk-connect-sg. - Pour Configuration du connecteur, remplacez les paramètres par défaut par les suivants :
- Pour Capacité du connecteur, choisissez Provisionné.
- Pour Nombre de MCU par travailleur, choisissez 1.
- Pour Nombre de travailleurs, choisissez 1.
- Pour Configuration du nœud de calcul, choisissez Utiliser la configuration par défaut de MSK.
- Pour Autorisations d'accès, choisissez
msk-connect-role. - Selectionnez Suivant.
- Pour Chiffrement, sélectionnez Trafic crypté TLS.
- Selectionnez Suivant.
- Pour Livraison de journaux, choisissez Diffuser vers Amazon CloudWatch Logs.
- Selectionnez Explorer, sélectionnez
msk-connect-logset choisissez Selectionnez. - Selectionnez Suivant.
- Revoir et choisir Créez un connecteur.
Une fois le connecteur personnalisé créé, vous verrez que son statut est Fonctionnement, et vous pouvez passer à l'étape suivante.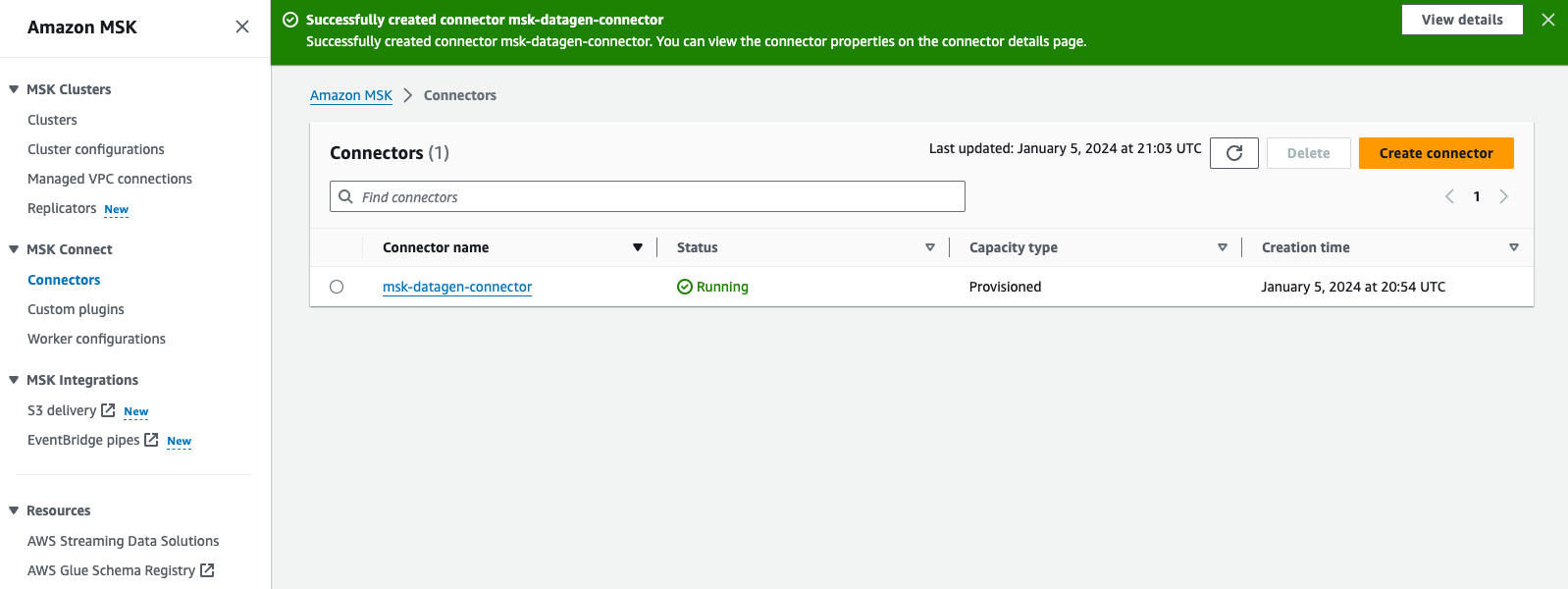
Configurer l'ingestion de streaming Amazon Redshift pour Amazon MSK
Effectuez les étapes suivantes pour configurer l'ingestion de streaming :
- Connectez-vous à votre cluster Redshift à l'aide de Query Editor v2 et authentifiez-vous avec le nom d'utilisateur de la base de données
awsuser, et mot de passeAwsuser123. - Créez un schéma externe à partir d'Amazon MSK à l'aide de l'instruction SQL suivante.
Dans le code suivant, entrez les valeurs du redshift-role Le rôle IAM et le msk-cluster ARN du cluster.
- Selectionnez Courir pour exécuter l'instruction SQL.
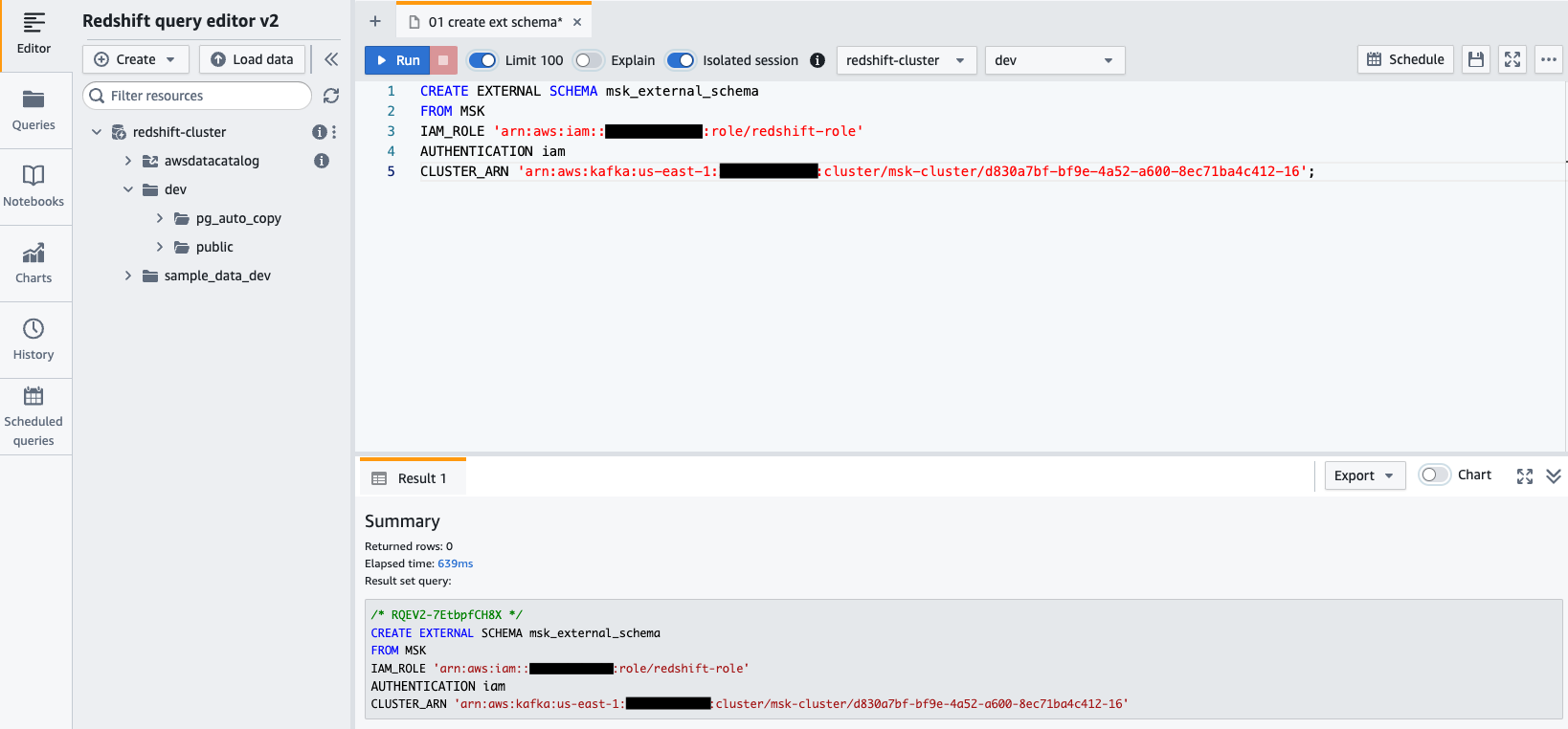
- Créer un vue matérialisée en utilisant l'instruction SQL suivante :
- Selectionnez Courir pour exécuter l'instruction SQL.
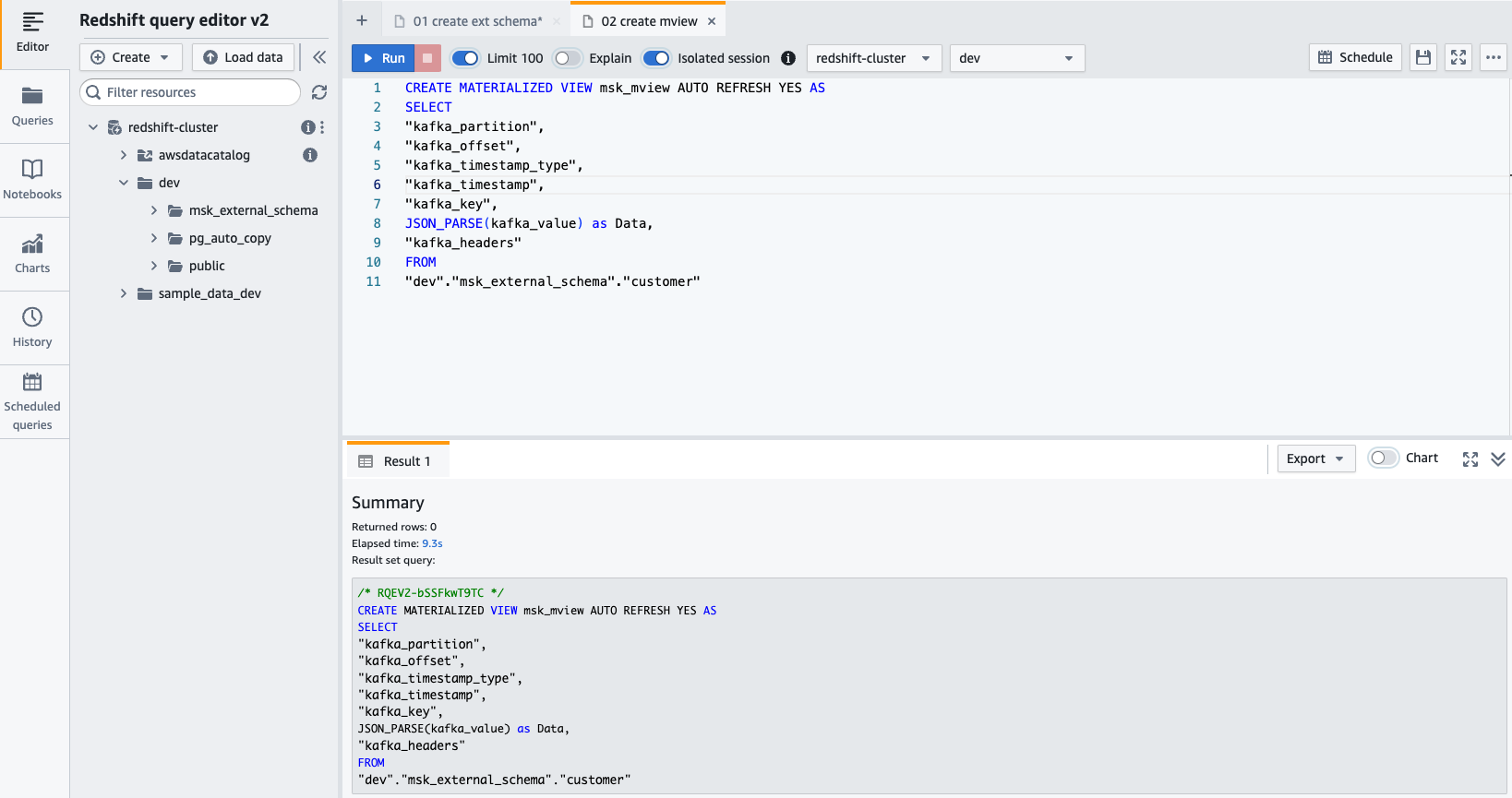
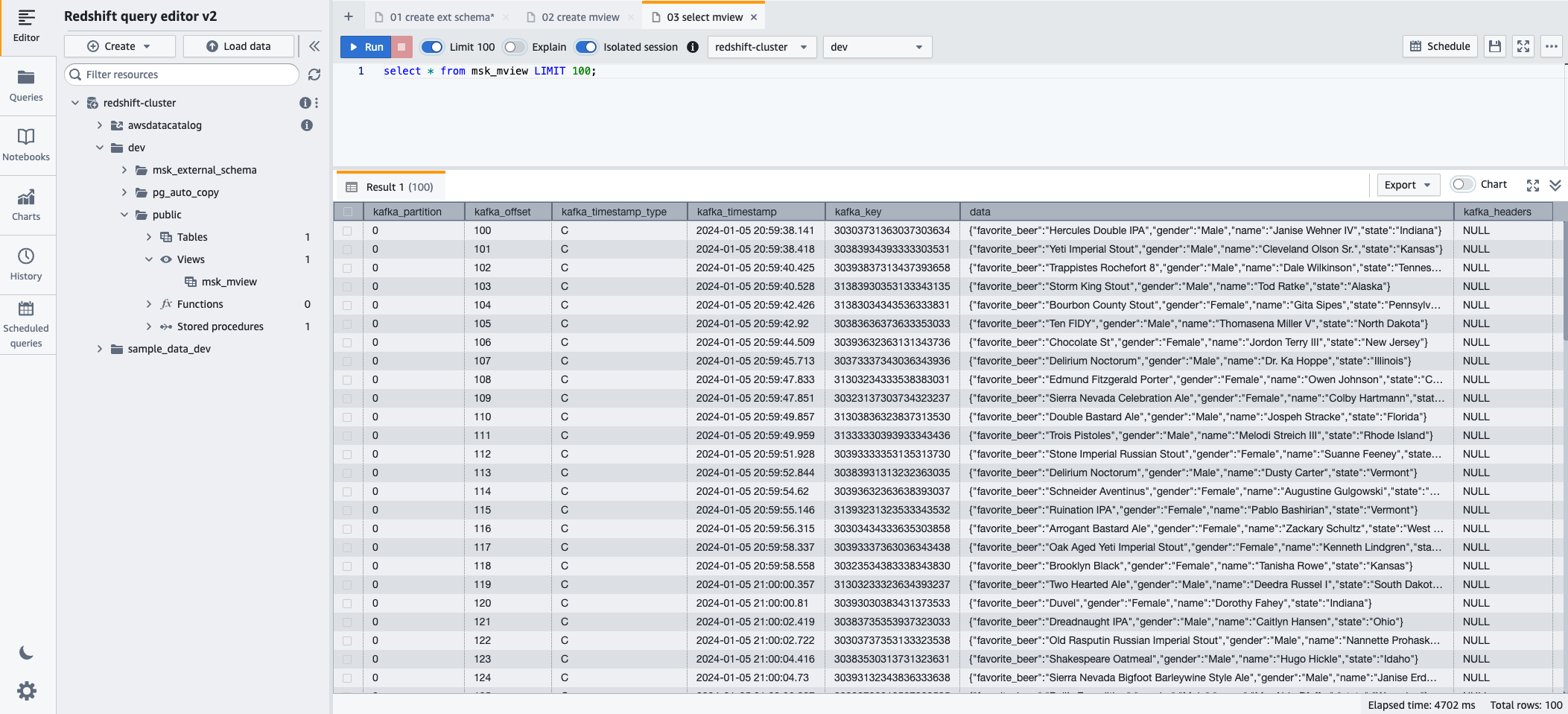
- Vous pouvez désormais interroger la vue matérialisée à l'aide de l'instruction SQL suivante :
- Selectionnez Courir pour exécuter l'instruction SQL.
- Pour surveiller la progression des enregistrements chargés via l'ingestion de streaming, vous pouvez profiter de l'option SYS_STREAM_SCAN_STATES vue de surveillance à l'aide de l'instruction SQL suivante :
- Selectionnez Courir pour exécuter l'instruction SQL.
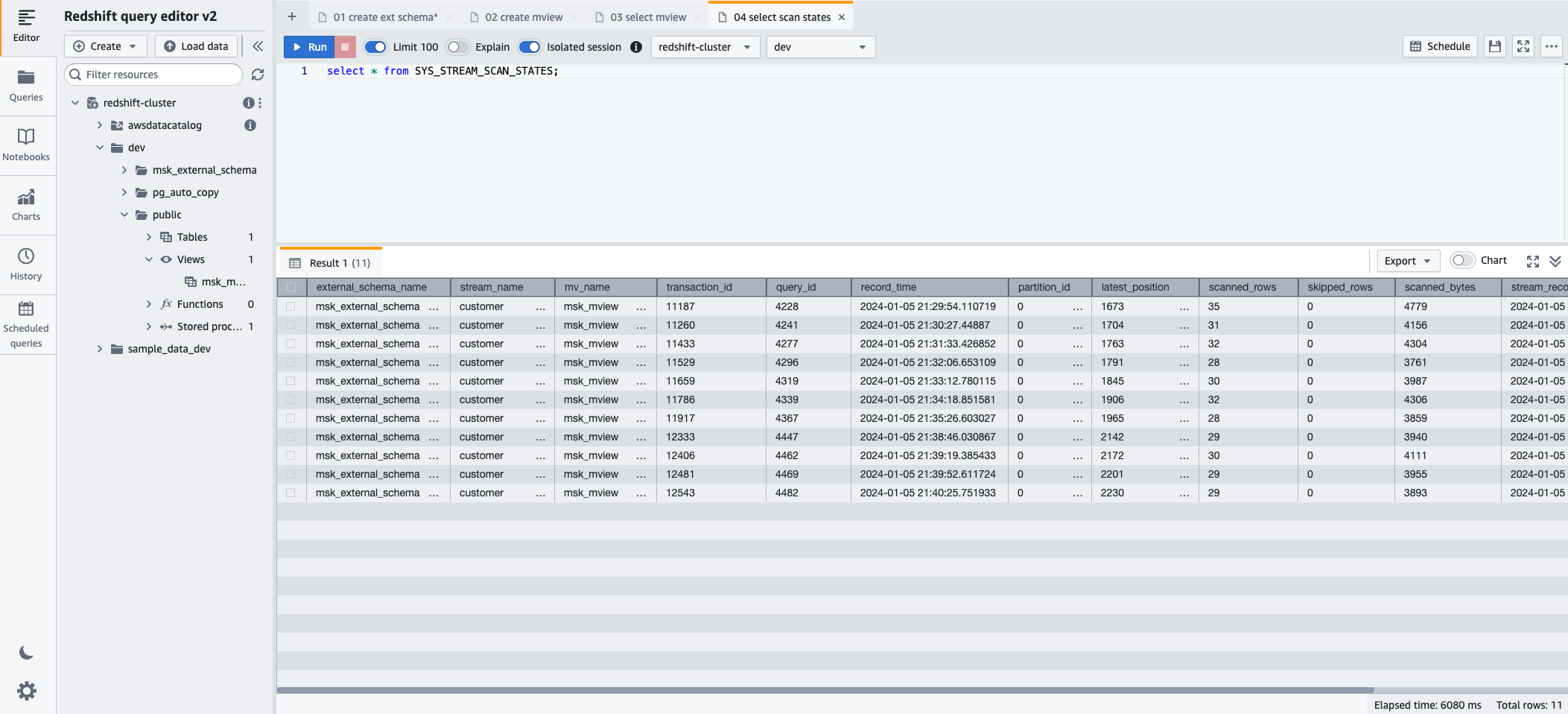
- Pour surveiller les erreurs rencontrées sur les enregistrements chargés via l'ingestion de streaming, vous pouvez profiter de l'option SYS_STREAM_SCAN_ERRORS vue de surveillance à l'aide de l'instruction SQL suivante :
- Selectionnez Courir pour exécuter l'instruction SQL.
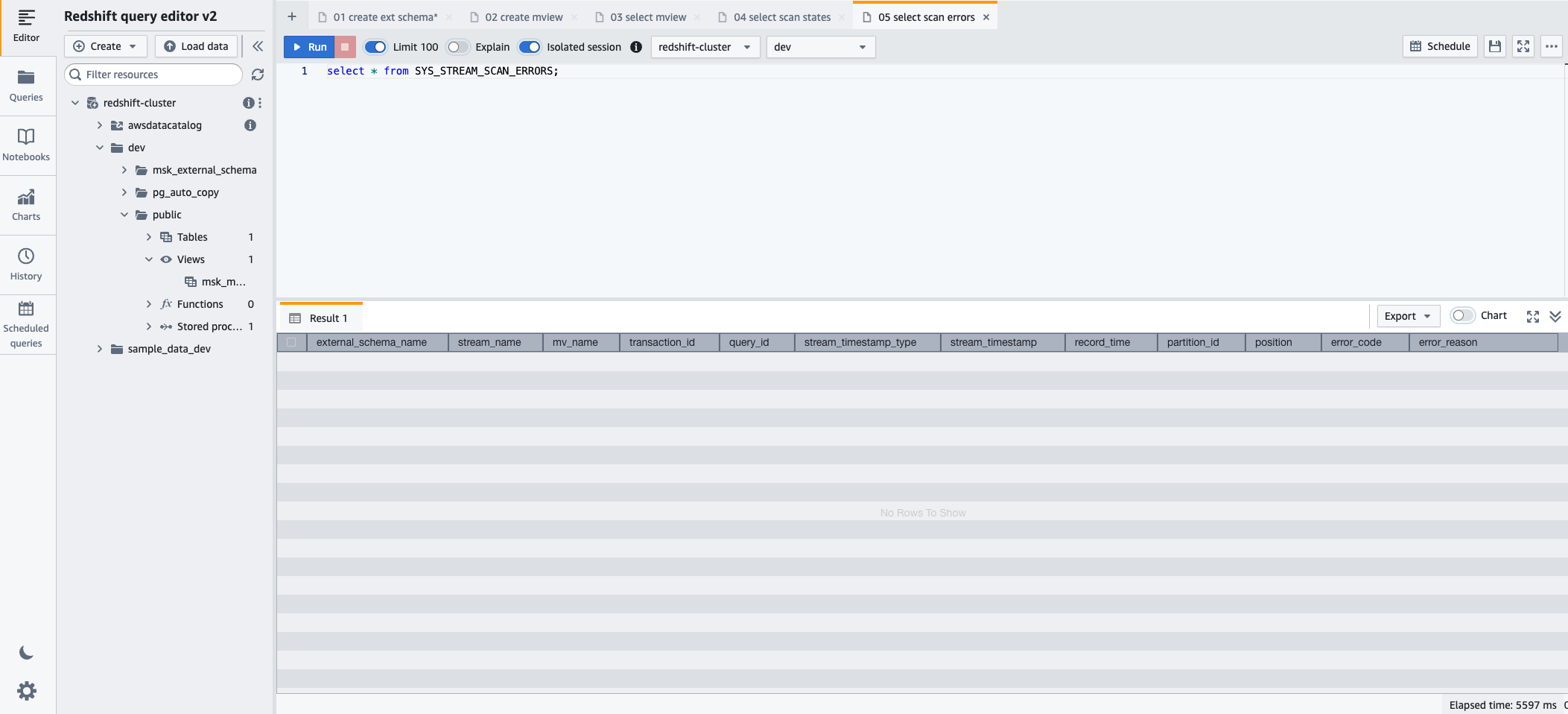
Nettoyer
Après avoir suivi, si vous n'avez plus besoin des ressources que vous avez créées, supprimez-les dans l'ordre suivant pour éviter d'encourir des frais supplémentaires :
- Supprimer le connecteur MSK Connect
msk-datagen-connector. - Supprimez le plug-in MSK Connect
msk-datagen-plugin. - Supprimez le fichier JAR du générateur de données Amazon MSK que vous avez téléchargé et supprimez le compartiment S3 que vous avez créé.
- Après avoir supprimé votre connecteur MSK Connect, vous pouvez supprimer le modèle CloudFormation. Toutes les ressources créées par le modèle CloudFormation seront automatiquement supprimées de votre compte AWS.
Conclusion
Dans cet article, nous avons montré comment configurer l'ingestion de streaming Amazon Redshift à partir d'Amazon MSK, en mettant l'accent sur la confidentialité et la sécurité.
La combinaison de la capacité d'Amazon MSK à gérer des flux de données à haut débit avec les solides capacités analytiques d'Amazon Redshift permet aux entreprises d'obtenir rapidement des informations exploitables. Cette intégration de données en temps réel améliore l'agilité et la réactivité des organisations dans la compréhension de l'évolution des tendances en matière de données, des comportements des clients et des modèles opérationnels. Il permet de prendre des décisions éclairées et opportunes, acquérant ainsi un avantage concurrentiel dans le paysage commercial dynamique d'aujourd'hui.
Cette solution s'applique également aux clients qui souhaitent utiliser Amazon MSK sans serveur ainsi que Amazon Redshift sans serveur.
Nous espérons que cet article a été une bonne occasion d'en savoir plus sur l'intégration et la configuration des services AWS. Faites-nous part de vos commentaires dans la section commentaires.
À propos des auteurs
 Sébastien Vlad est un architecte de solutions partenaire senior chez Amazon Web Services, passionné par les solutions de données et d'analyse et par la réussite des clients. Sebastian travaille avec des entreprises clientes pour les aider à concevoir et à créer des solutions modernes, sécurisées et évolutives afin d'atteindre leurs résultats commerciaux.
Sébastien Vlad est un architecte de solutions partenaire senior chez Amazon Web Services, passionné par les solutions de données et d'analyse et par la réussite des clients. Sebastian travaille avec des entreprises clientes pour les aider à concevoir et à créer des solutions modernes, sécurisées et évolutives afin d'atteindre leurs résultats commerciaux.
 Sharad Paï est consultant technique principal chez AWS. Il se spécialise dans l'analyse du streaming et aide les clients à créer des solutions évolutives à l'aide d'Amazon MSK et d'Amazon Kinesis. Il a plus de 16 ans d'expérience dans le secteur et travaille actuellement avec des clients médias qui hébergent des plateformes de diffusion en direct sur AWS, gérant une simultanéité de pointe de plus de 50 millions. Avant de rejoindre AWS, la carrière de Sharad en tant que principal développeur de logiciels comprenait 9 années de codage, travaillant avec des technologies open source telles que JavaScript, Python et PHP.
Sharad Paï est consultant technique principal chez AWS. Il se spécialise dans l'analyse du streaming et aide les clients à créer des solutions évolutives à l'aide d'Amazon MSK et d'Amazon Kinesis. Il a plus de 16 ans d'expérience dans le secteur et travaille actuellement avec des clients médias qui hébergent des plateformes de diffusion en direct sur AWS, gérant une simultanéité de pointe de plus de 50 millions. Avant de rejoindre AWS, la carrière de Sharad en tant que principal développeur de logiciels comprenait 9 années de codage, travaillant avec des technologies open source telles que JavaScript, Python et PHP.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/simplify-data-streaming-ingestion-for-analytics-using-amazon-msk-and-amazon-redshift/

