ZOO Digital fournit des services de localisation et multimédia de bout en bout pour adapter le contenu télévisuel et cinématographique original à différentes langues, régions et cultures. Cela facilite la mondialisation pour les meilleurs créateurs de contenu du monde. Reconnu par les plus grands noms du divertissement, ZOO Digital propose des services de localisation et de médias de haute qualité à grande échelle, notamment le doublage, le sous-titrage, la création de scripts et la conformité.
Les flux de travail de localisation typiques nécessitent une diarisation manuelle des locuteurs, dans laquelle un flux audio est segmenté en fonction de l'identité du locuteur. Ce processus fastidieux doit être terminé avant que le contenu puisse être doublé dans une autre langue. Avec les méthodes manuelles, la localisation d’un épisode de 30 minutes peut prendre entre 1 et 3 heures. Grâce à l'automatisation, ZOO Digital vise à réaliser la localisation en moins de 30 minutes.
Dans cet article, nous discutons du déploiement de modèles d'apprentissage automatique (ML) évolutifs pour la journalisation du contenu multimédia à l'aide de Amazon Sage Maker, en mettant l'accent sur ChuchotementX .
Contexte
La vision de ZOO Digital est de fournir un traitement plus rapide du contenu localisé. Cet objectif est entravé par la nature manuelle intensive de l'exercice, aggravée par le petit effectif de personnes qualifiées capables de localiser le contenu manuellement. ZOO Digital travaille avec plus de 11,000 600 indépendants et a localisé plus de 2022 millions de mots rien qu'en XNUMX. Cependant, l'offre de personnes qualifiées est dépassée par la demande croissante de contenu, ce qui nécessite une automatisation pour faciliter les flux de travail de localisation.
Dans le but d'accélérer la localisation des flux de travail de contenu grâce à l'apprentissage automatique, ZOO Digital a engagé AWS Prototyping, un programme d'investissement d'AWS pour co-construire des charges de travail avec ses clients. L'engagement s'est concentré sur la fourniture d'une solution fonctionnelle pour le processus de localisation, tout en fournissant une formation pratique aux développeurs de ZOO Digital sur SageMaker, Amazon Transcribeet Amazon Traduire.
Défi client
Après la transcription d'un titre (un film ou un épisode d'une série télévisée), les locuteurs doivent être attribués à chaque segment de discours afin qu'ils puissent être correctement attribués aux artistes vocaux qui joueront les personnages. Ce processus est appelé diarisation du locuteur. ZOO Digital est confronté au défi de créer un journal de contenu à grande échelle tout en étant économiquement viable.
Vue d'ensemble de la solution
Dans ce prototype, nous avons stocké les fichiers multimédias originaux dans un emplacement spécifié Service de stockage simple Amazon (Amazon S3). Ce compartiment S3 a été configuré pour émettre un événement lorsque de nouveaux fichiers y sont détectés, déclenchant un AWS Lambda fonction. Pour obtenir des instructions sur la configuration de ce déclencheur, reportez-vous au didacticiel Utilisation d'un déclencheur Amazon S3 pour appeler une fonction Lambda. Par la suite, la fonction Lambda a appelé le point de terminaison SageMaker pour l'inférence à l'aide de l'attribut Client d'exécution Boto3 SageMaker.
La ChuchotementX modèle, basé sur Le murmure d'OpenAI, effectue des transcriptions et une diarisation des ressources multimédias. Il est construit sur le Chuchotement plus rapide réimplémentation, offrant une transcription jusqu'à quatre fois plus rapide avec un alignement amélioré de l'horodatage au niveau des mots par rapport à Whisper. De plus, il introduit la diarisation des haut-parleurs, non présente dans le modèle Whisper original. WhisperX utilise le modèle Whisper pour les transcriptions, le Wav2Vec2 modèle pour améliorer l'alignement de l'horodatage (garantissant la synchronisation du texte transcrit avec les horodatages audio), et le pyannote modèle de diarisation. FFmpeg est utilisé pour charger l'audio à partir du support source, prenant en charge divers formats multimédias. L'architecture du modèle transparente et modulaire permet une certaine flexibilité, car chaque composant du modèle peut être remplacé selon les besoins futurs. Cependant, il est essentiel de noter que WhisperX ne dispose pas de fonctionnalités de gestion complètes et n'est pas un produit de niveau entreprise. Sans maintenance et support, il peut ne pas convenir au déploiement en production.
Dans cette collaboration, nous avons déployé et évalué WhisperX sur SageMaker, à l'aide d'un point de terminaison d'inférence asynchrone pour héberger le modèle. Les points de terminaison asynchrones SageMaker prennent en charge des tailles de téléchargement allant jusqu'à 1 Go et intègrent des fonctionnalités de mise à l'échelle automatique qui atténuent efficacement les pics de trafic et réduisent les coûts pendant les heures creuses. Les points de terminaison asynchrones sont particulièrement adaptés au traitement de fichiers volumineux, tels que les films et les séries télévisées dans notre cas d'utilisation.
Le diagramme suivant illustre les éléments essentiels des expériences que nous avons menées dans le cadre de cette collaboration.

Dans les sections suivantes, nous approfondissons les détails du déploiement du modèle WhisperX sur SageMaker et évaluons les performances de diarisation.
Téléchargez le modèle et ses composants
WhisperX est un système qui comprend plusieurs modèles de transcription, d'alignement forcé et de diarisation. Pour un fonctionnement fluide de SageMaker sans avoir besoin de récupérer les artefacts du modèle pendant l'inférence, il est essentiel de pré-télécharger tous les artefacts du modèle. Ces artefacts sont ensuite chargés dans le conteneur de service SageMaker lors du lancement. Étant donné que ces modèles ne sont pas directement accessibles, nous proposons des descriptions et des exemples de code à partir de la source WhisperX, fournissant des instructions sur le téléchargement du modèle et de ses composants.
WhisperX utilise six modèles :
La plupart de ces modèles peuvent être obtenus auprès de Étreindre le visage en utilisant la bibliothèque huggingface_hub. Nous utilisons ce qui suit download_hf_model() fonction pour récupérer ces artefacts de modèle. Un jeton d'accès de Hugging Face, généré après avoir accepté les accords d'utilisation pour les modèles pyannote suivants, est requis :
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
Le modèle VAD est récupéré depuis Amazon S3 et le modèle Wav2Vec2 est récupéré depuis le module torchaudio.pipelines. Sur la base du code suivant, nous pouvons récupérer tous les artefacts des modèles, y compris ceux de Hugging Face, et les enregistrer dans le répertoire de modèle local spécifié :
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Sélectionnez le conteneur AWS Deep Learning approprié pour servir le modèle
Une fois les artefacts du modèle enregistrés à l'aide de l'exemple de code précédent, vous pouvez choisir des modèles prédéfinis. Conteneurs AWS Deep Learning (DLC) parmi les suivants GitHub repo. Lors de la sélection de l'image Docker, tenez compte des paramètres suivants : framework (Hugging Face), tâche (inférence), version Python et matériel (par exemple, GPU). Nous vous recommandons d'utiliser l'image suivante : 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Cette image contient tous les packages système nécessaires préinstallés, tels que ffmpeg. N'oubliez pas de remplacer [REGION] par la région AWS que vous utilisez.
Pour les autres packages Python requis, créez un requirements.txt fichier avec une liste de packages et leurs versions. Ces packages seront installés lors de la création du DLC AWS. Voici les packages supplémentaires nécessaires pour héberger le modèle WhisperX sur SageMaker :
Créez un script d'inférence pour charger les modèles et exécuter l'inférence
Ensuite, nous créons un personnalisé inference.py script pour décrire comment le modèle WhisperX et ses composants sont chargés dans le conteneur et comment le processus d'inférence doit être exécuté. Le script contient deux fonctions : model_fn ainsi que transform_fnL’ model_fn La fonction est invoquée pour charger les modèles à partir de leurs emplacements respectifs. Par la suite, ces modèles sont transmis au transform_fn fonctionnent pendant l’inférence, où les processus de transcription, d’alignement et de diarisation sont effectués. Ce qui suit est un exemple de code pour inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
Dans le répertoire du modèle, à côté du requirements.txt dossier, s’assurer de la présence de inference.py dans un sous-répertoire de code. Le models le répertoire doit ressembler à ce qui suit :
Créer une archive tar des modèles
Après avoir créé les modèles et les répertoires de code, vous pouvez utiliser les lignes de commande suivantes pour compresser le modèle dans une archive tar (fichier .tar.gz) et le télécharger sur Amazon S3. Au moment de la rédaction de cet article, en utilisant le modèle Large V2 plus rapide, l'archive tar résultante représentant le modèle SageMaker a une taille de 3 Go. Pour plus d'informations, reportez-vous à Modèles d'hébergement de modèles dans Amazon SageMaker, Partie 2 : Premiers pas avec le déploiement de modèles en temps réel sur SageMaker.
Créez un modèle SageMaker et déployez un point de terminaison avec un prédicteur asynchrone
Vous pouvez désormais créer le modèle SageMaker, la configuration du point de terminaison et le point de terminaison asynchrone avec AsyncPredictor en utilisant l'archive tar modèle créée à l'étape précédente. Pour obtenir des instructions, reportez-vous à Créer un point de terminaison d'inférence asynchrone.
Évaluer les performances de la diarisation
Pour évaluer les performances de diarisation du modèle WhisperX dans divers scénarios, nous avons sélectionné trois épisodes chacun parmi deux titres anglais : un titre dramatique composé d'épisodes de 30 minutes et un titre documentaire composé d'épisodes de 45 minutes. Nous avons utilisé la boîte à outils de métriques de pyannote, pyannote.metrics, pour calculer le taux d'erreur de diarisation (DER). Lors de l'évaluation, les transcriptions manuellement transcrites et journalisées fournies par ZOO ont servi de vérité terrain.
Nous avons défini le DER comme suit :
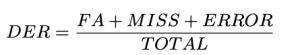
Total est la durée de la vidéo de vérité terrain. FA (Fausse alarme) est la longueur des segments qui sont considérés comme de la parole dans les prédictions, mais pas dans la vérité terrain. Miss est la longueur des segments qui sont considérés comme de la parole dans la vérité terrain, mais pas dans la prédiction. Erreur, Également appelé Confusion, est la longueur des segments attribués aux différents locuteurs dans la prédiction et la vérité terrain. Toutes les unités sont mesurées en secondes. Les valeurs typiques de DER peuvent varier en fonction de l'application spécifique, de l'ensemble de données et de la qualité du système de diarisation. Notez que DER peut être supérieur à 1.0. Un DER inférieur est préférable.
Pour pouvoir calculer le DER pour un média, une diarisation de la vérité terrain est requise ainsi que les sorties WhisperX transcrites et journalisées. Ceux-ci doivent être analysés et aboutir à des listes de tuples contenant une étiquette de locuteur, une heure de début de segment de parole et une heure de fin de segment de parole pour chaque segment de parole dans le média. Les étiquettes des haut-parleurs n'ont pas besoin de correspondre entre les diarisations WhisperX et celles de la vérité terrain. Les résultats sont basés principalement sur la durée des segments. pyannote.metrics prend ces tuples de diarisations de vérité terrain et de diarisations de sortie (appelées dans la documentation pyannote.metrics comme référence ainsi que hypothèse) pour calculer le DER. Le tableau suivant résume nos résultats.
| Type de vidéo | L' | Correct | Miss | Erreur | Fausse alarme |
| Films dramatique | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Documentaire | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Moyen | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Ces résultats révèlent une différence de performance significative entre les titres dramatiques et documentaires, le modèle obtenant des résultats nettement meilleurs (en utilisant le DER comme mesure globale) pour les épisodes dramatiques par rapport au titre documentaire. Une analyse plus approfondie des titres donne un aperçu des facteurs potentiels contribuant à cet écart de performance. Un facteur clé pourrait être la présence fréquente de musique de fond chevauchant le discours dans le titre du documentaire. Bien que le prétraitement des médias pour améliorer la précision de la diarisation, comme la suppression du bruit de fond pour isoler la parole, dépassait la portée de ce prototype, il ouvre des perspectives pour des travaux futurs qui pourraient potentiellement améliorer les performances de WhisperX.
Conclusion
Dans cet article, nous avons exploré le partenariat de collaboration entre AWS et ZOO Digital, utilisant des techniques d'apprentissage automatique avec SageMaker et le modèle WhisperX pour améliorer le flux de travail de diarisation. L'équipe AWS a joué un rôle central en assistant ZOO dans le prototypage, l'évaluation et la compréhension du déploiement efficace de modèles ML personnalisés, spécifiquement conçus pour la diarisation. Cela comprenait l'intégration de la mise à l'échelle automatique pour l'évolutivité à l'aide de SageMaker.
L’exploitation de l’IA pour la diarisation entraînera des économies substantielles en termes de coûts et de temps lors de la génération de contenu localisé pour ZOO. En aidant les transcripteurs à créer et à identifier rapidement et précisément les locuteurs, cette technologie répond à la nature traditionnellement longue et sujette aux erreurs de cette tâche. Le processus conventionnel implique souvent plusieurs passages dans la vidéo et des étapes de contrôle qualité supplémentaires pour minimiser les erreurs. L'adoption de l'IA pour la diarisation permet une approche plus ciblée et plus efficace, augmentant ainsi la productivité dans un délai plus court.
Nous avons décrit les étapes clés pour déployer le modèle WhisperX sur le point de terminaison asynchrone SageMaker et vous encourageons à l'essayer vous-même à l'aide du code fourni. Pour plus d'informations sur les services et la technologie de ZOO Digital, visitez Site officiel de ZOO Digital. Pour plus de détails sur le déploiement du modèle OpenAI Whisper sur SageMaker et diverses options d'inférence, reportez-vous à Héberger le modèle Whisper sur Amazon SageMaker : explorer les options d'inférence. N'hésitez pas à partager vos réflexions dans les commentaires.
À propos des auteurs
 Ying Hou, Ph.D., est architecte de prototypage d'apprentissage automatique chez AWS. Ses principaux domaines d'intérêt englobent le Deep Learning, avec un accent sur GenAI, Computer Vision, NLP et la prédiction de données de séries chronologiques. Dans ses temps libres, elle aime passer des moments de qualité avec sa famille, se plonger dans des romans et faire des randonnées dans les parcs nationaux du Royaume-Uni.
Ying Hou, Ph.D., est architecte de prototypage d'apprentissage automatique chez AWS. Ses principaux domaines d'intérêt englobent le Deep Learning, avec un accent sur GenAI, Computer Vision, NLP et la prédiction de données de séries chronologiques. Dans ses temps libres, elle aime passer des moments de qualité avec sa famille, se plonger dans des romans et faire des randonnées dans les parcs nationaux du Royaume-Uni.
 Ethan Cumberland est ingénieur de recherche en IA chez ZOO Digital, où il travaille sur l'utilisation de l'IA et de l'apprentissage automatique comme technologies d'assistance pour améliorer les flux de travail en matière de parole, de langage et de localisation. Il possède une formation en génie logiciel et en recherche dans le domaine de la sécurité et du maintien de l'ordre, se concentrant sur l'extraction d'informations structurées du Web et l'exploitation de modèles ML open source pour analyser et enrichir les données collectées.
Ethan Cumberland est ingénieur de recherche en IA chez ZOO Digital, où il travaille sur l'utilisation de l'IA et de l'apprentissage automatique comme technologies d'assistance pour améliorer les flux de travail en matière de parole, de langage et de localisation. Il possède une formation en génie logiciel et en recherche dans le domaine de la sécurité et du maintien de l'ordre, se concentrant sur l'extraction d'informations structurées du Web et l'exploitation de modèles ML open source pour analyser et enrichir les données collectées.
 Gaurav Kaila dirige l'équipe de prototypage AWS pour le Royaume-Uni et l'Irlande. Son équipe travaille avec des clients de divers secteurs pour imaginer et co-développer des charges de travail critiques pour l'entreprise avec pour mandat d'accélérer l'adoption des services AWS.
Gaurav Kaila dirige l'équipe de prototypage AWS pour le Royaume-Uni et l'Irlande. Son équipe travaille avec des clients de divers secteurs pour imaginer et co-développer des charges de travail critiques pour l'entreprise avec pour mandat d'accélérer l'adoption des services AWS.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

