« Les données sont au centre de chaque application, processus et décision commerciale. Lorsque les données sont utilisées pour améliorer l’expérience client et stimuler l’innovation, elles peuvent conduire à la croissance de l’entreprise. »
- Swami Sivasubramanian, vice-président des bases de données, de l'analyse et de l'apprentissage automatique chez AWS en Avec une approche zéro ETL, AWS aide les constructeurs à réaliser des analyses en temps quasi réel.
Les clients de tous les secteurs sont de plus en plus axés sur les données et cherchent à augmenter leurs revenus, à réduire leurs coûts et à optimiser leurs opérations commerciales en mettant en œuvre des analyses en temps quasi réel sur les données transactionnelles, améliorant ainsi leur agilité. En fonction des besoins des clients et de leurs commentaires, AWS investit et progresse régulièrement pour donner vie à notre vision zéro ETL afin que les constructeurs puissent se concentrer davantage sur la création de valeur à partir des données, au lieu de préparer les données pour l'analyse.
NOTRE zéro-ETL intégration avec Redshift d'Amazon facilite le déplacement des données point à point pour les préparer à l'analyse, à l'intelligence artificielle (IA) et à l'apprentissage automatique (ML) à l'aide d'Amazon Redshift sur des pétaoctets de données. Quelques secondes après l'écriture des données transactionnelles soutenu Les bases de données AWS sans ETL rendent les données disponibles de manière transparente dans Amazon Redshift, éliminant ainsi le besoin de créer et de maintenir des pipelines de données complexes qui effectuent des opérations d'extraction, de transformation et de chargement (ETL).
Pour vous aider à vous concentrer sur la création de valeur à partir des données au lieu d'investir du temps et des ressources indifférenciées dans la création et la gestion de pipelines ETL entre les bases de données transactionnelles et les entrepôts de données, nous a annoncé quatre intégrations de base de données AWS sans ETL avec Amazon Redshift lors d'AWS re:Invent 2023:
Dans cet article, nous fournissons des conseils étape par étape sur la façon de démarrer avec l'analyse opérationnelle en temps quasi réel à l'aide de Intégration Amazon Aurora PostgreSQL zéro ETL avec Amazon Redshift.
Vue d'ensemble de la solution
Pour créer une intégration zéro ETL, vous spécifiez un Édition compatible Amazon Aurora PostgreSQL cluster (compatible avec PostgreSQL 15.4 et prise en charge zéro-ETL) comme source et un entrepôt de données Redshift comme cible. L'intégration réplique les données de la base de données source vers l'entrepôt de données cible.
Vous devez créer des clusters provisionnés de base de données Aurora PostgreSQL dans le Environnement de prévisualisation de base de données Amazon RDS et un Redshift cluster de préversion provisionné or groupe de travail de prévisualisation sans serveur, dans la région AWS USA Est (Ohio). Pour Amazon Redshift, assurez-vous de choisir la piste preview_2023 afin d'utiliser les intégrations zéro ETL.
Le diagramme suivant illustre l'architecture implémentée dans cet article.
Voici les étapes nécessaires pour configurer l’intégration zéro ETL pour cette solution. Pour obtenir des guides de démarrage complets, reportez-vous à Travailler avec les intégrations Aurora zéro-ETL avec Amazon Redshift ainsi que Travailler avec des intégrations zéro ETL.
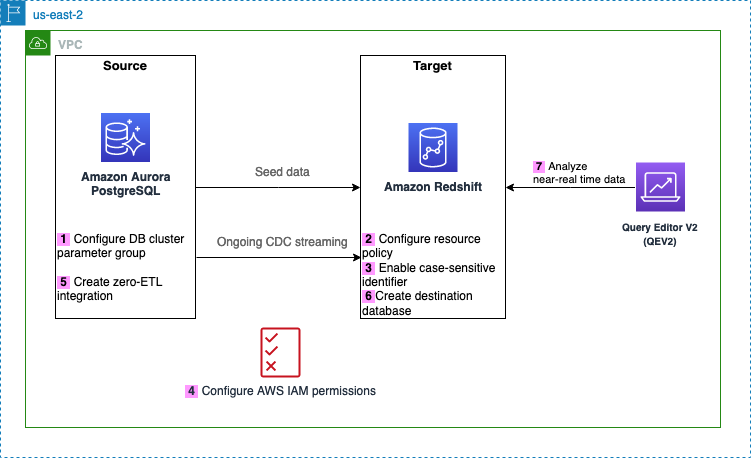
Après l'étape 1, vous pouvez également ignorer les étapes 2 à 4 et commencer directement à créer votre intégration zéro ETL à partir de l'étape 5, auquel cas Amazon RDS affichera un message concernant les configurations manquantes et vous pourrez choisir Fixez-le pour moi pour laisser Amazon RDS configurer automatiquement les étapes.
- Configurez la source Aurora PostgreSQL avec un groupe de paramètres de cluster de base de données personnalisé.
- Configurer le Amazon Redshift sans serveur destination avec la stratégie de ressources requise pour son espace de noms.
- Mettez à jour le groupe de travail Redshift Serverless pour activer les identifiants sensibles à la casse.
- Configurez les autorisations requises.
- Créez l'intégration zéro ETL.
- Créez une base de données à partir de l'intégration dans Amazon Redshift.
- Commencez à analyser les données transactionnelles en temps quasi réel.
Configurer la source Aurora PostgreSQL avec un groupe de paramètres de cluster de base de données personnalisé
Pour les clusters de bases de données Aurora PostgreSQL, vous devez créer le groupe de paramètres personnalisés dans le fichier Environnement de prévisualisation de base de données Amazon RDS, dans la région USA Est (Ohio). Tu peux accéder directement à l'environnement de prévisualisation Amazon RDS.
Pour créer une base de données Aurora PostgreSQL, procédez comme suit :
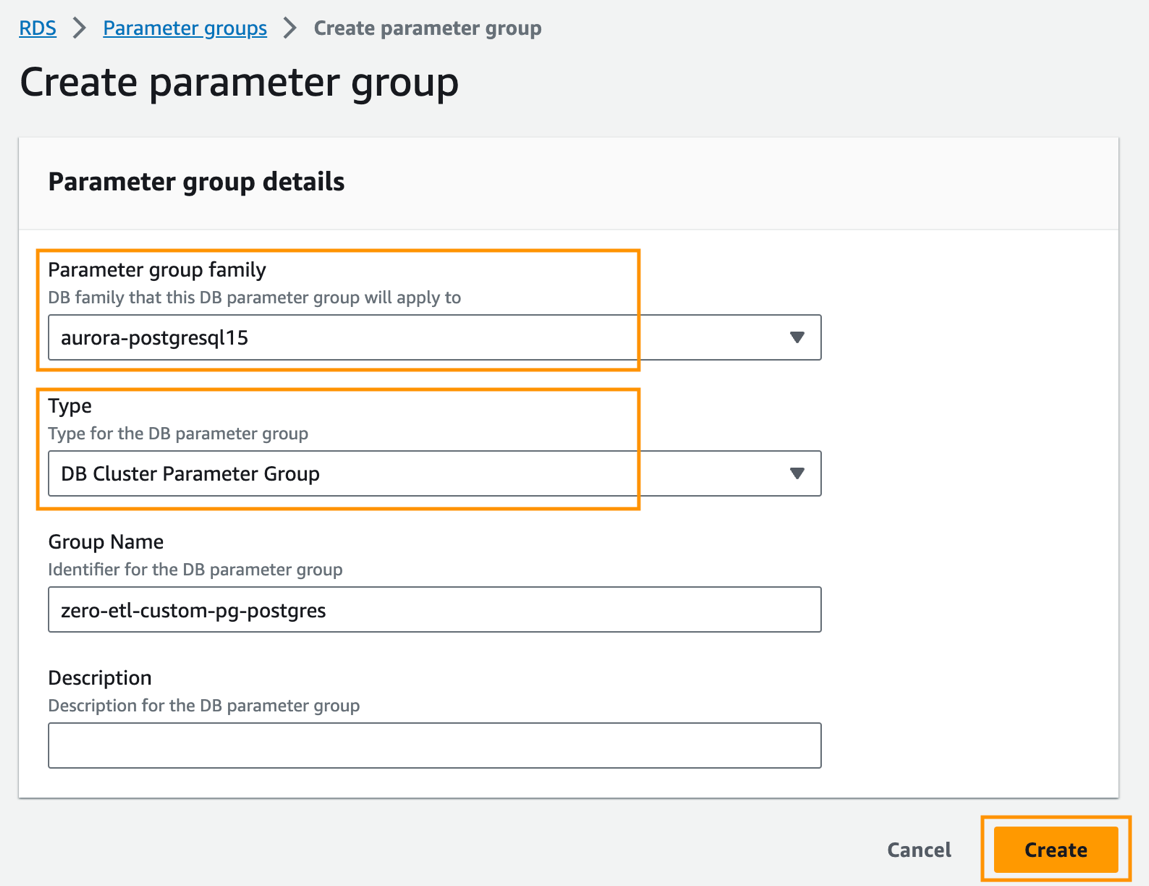
- Sur la console Amazon RDS, choisissez Groupes de paramètres dans le volet de navigation.
- Selectionnez Créer un groupe de paramètres.
- Pour Famille de groupes de paramètres, choisissez
aurora-postgresql15. - Pour Type, choisissez
DB Cluster Parameter Group. - Pour Nom du groupe, entrez un nom (par exemple,
zero-etl-custom-pg-postgres). - Selectionnez Création.
Les intégrations Aurora PostgreSQL zéro ETL avec Amazon Redshift nécessitent des valeurs spécifiques pour le Paramètres du cluster de base de données Aurora, qui nécessite une réplication logique améliorée (aurora.enhanced_logical_replication).
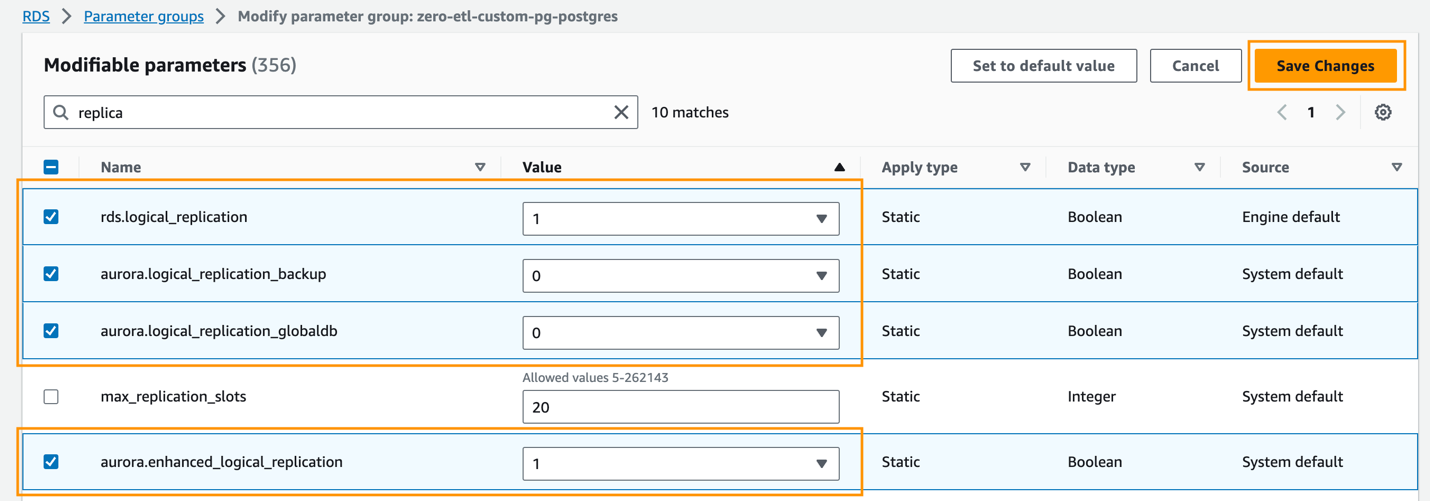
- Sur le Groupes de paramètres page, sélectionnez le groupe de paramètres nouvellement créé.
- Sur le Actions menu, choisissez Modifier.
- Définissez l'Aurora PostgreSQL suivante (famille aurora-postgresql15) paramètres de cluster :
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
L'activation de la réplication logique améliorée (aurora.enhanced_logical_replication) définit automatiquement le paramètre REPLICA IDENTITY sur FULL, ce qui signifie que toutes les valeurs de colonne sont écrites dans le journal d'écriture anticipée (WAL).
- Selectionnez Enregistrer les modifications.
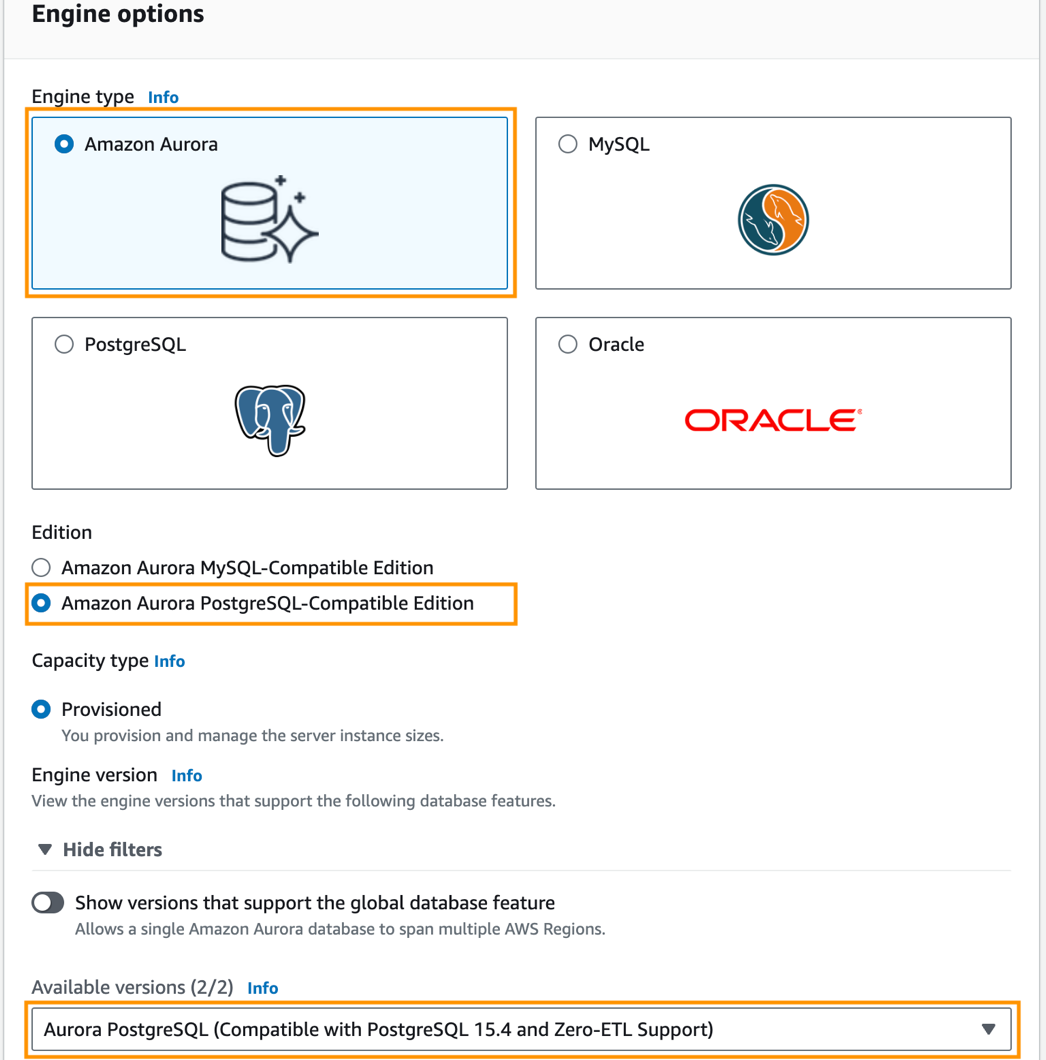
- Selectionnez Bases de données dans le volet de navigation, puis choisissez Créer une base de données.

- Pour Type de moteur, sélectionnez Amazon Aurora.
- Pour Édition, sélectionnez Édition compatible Amazon Aurora PostgreSQL.
- Pour Versions disponibles, choisissez Aurora PostgreSQL (compatible avec PostgreSQL 15.4 et prise en charge Zero-ETL).
- Pour Gabarits, sélectionnez Vidéo.
- Pour Identificateur de cluster de base de données, Entrer
zero-etl-source-pg.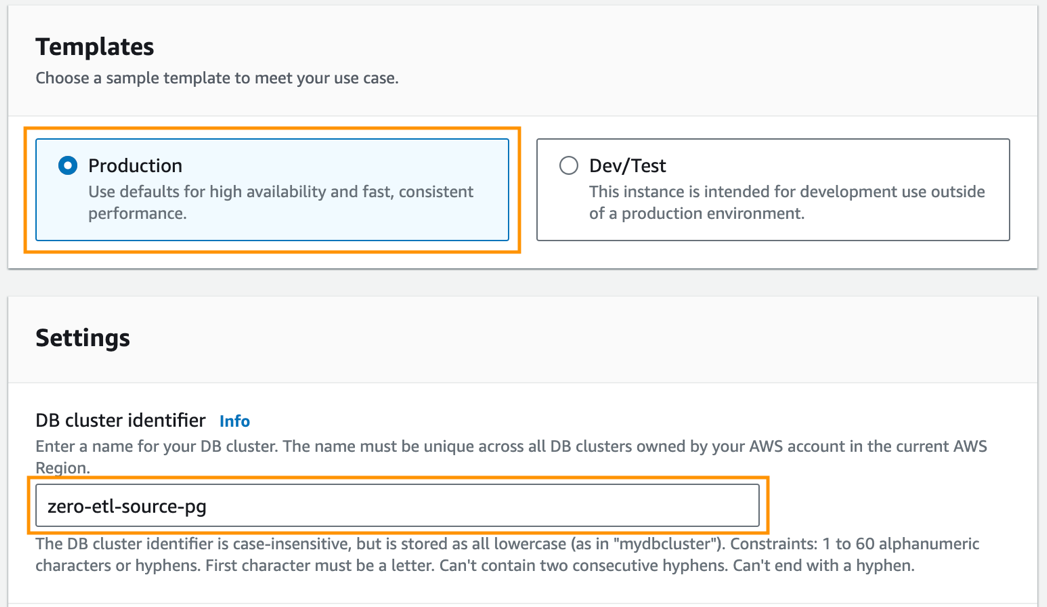
- Sous Paramètres des informations d'identification, saisissez un mot de passe pour Mot de passe maître ou utilisez l'option pour générer automatiquement un mot de passe pour vous.
- Dans le Section de configuration des instances, sélectionnez Classes optimisées en mémoire.
- Choisissez une taille d'instance appropriée (la taille par défaut est
db.r5.2xlarge).
- Sous Configuration supplémentaire, Pour Groupe de paramètres de cluster de base de données, choisissez le groupe de paramètres que vous avez créé précédemment (
zero-etl-custom-pg-postgres).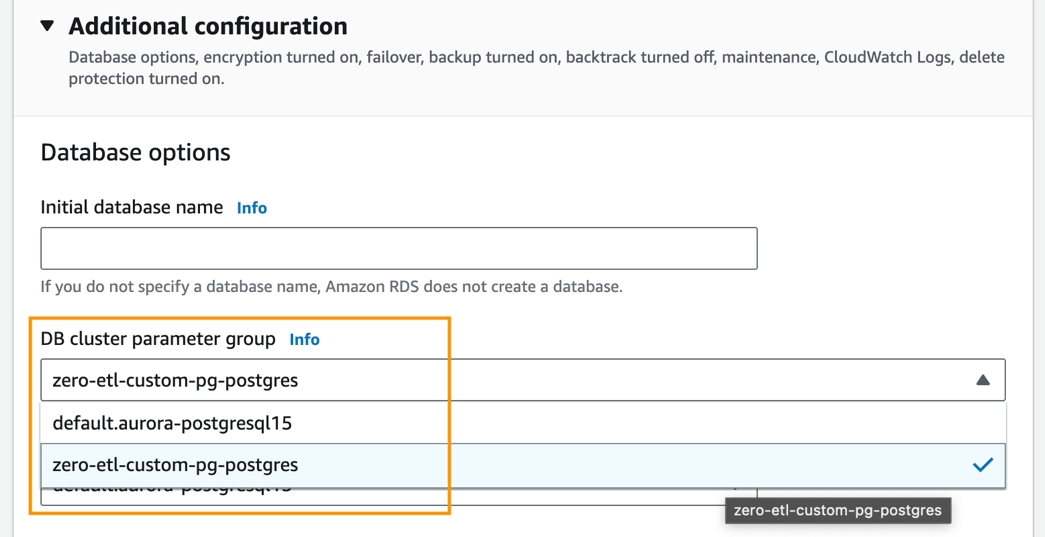
- Laissez les paramètres par défaut pour les configurations restantes.
- Selectionnez Créer une base de données.
Dans quelques minutes, cela devrait faire tourner un cluster Aurora PostgreSQL, avec une instance d'écriture et une instance de lecteur, avec le statut passant de La création à Disponible. Le cluster Aurora PostgreSQL nouvellement créé sera la source de l'intégration zéro ETL.
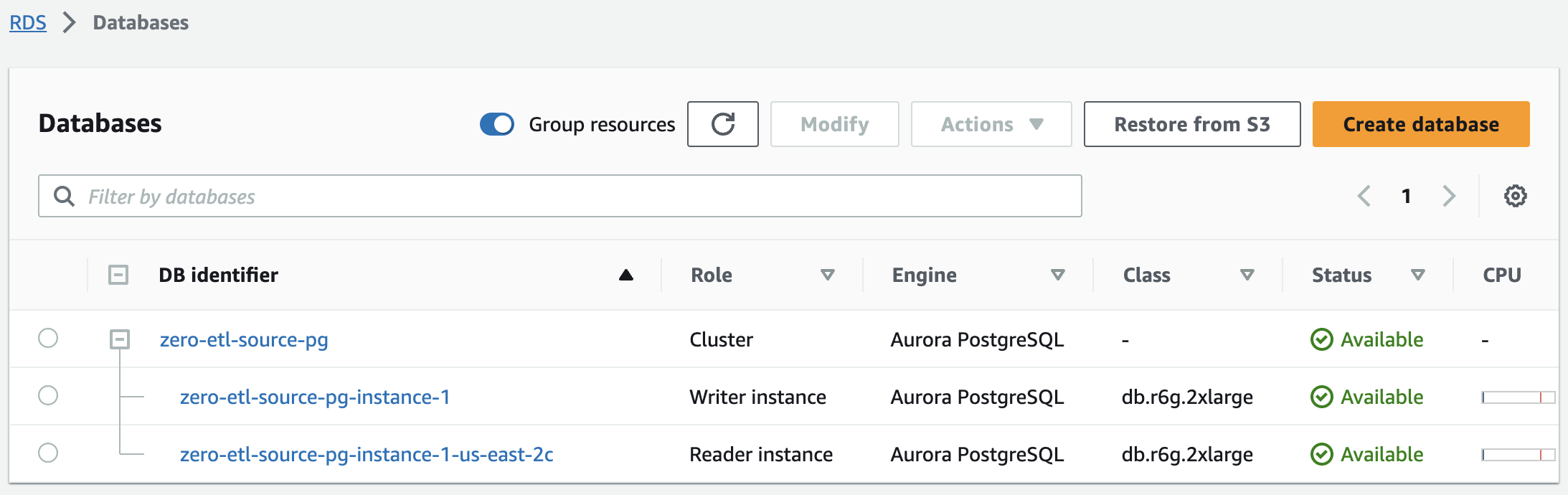
L'étape suivante consiste à créer une base de données nommée dans Amazon Aurora PostgreSQL pour l'intégration zéro ETL.
Le modèle de ressources PostgreSQL vous permet de créer plusieurs bases de données au sein d'un cluster. Par conséquent, lors de l'étape de création d'intégration zéro ETL, vous devez spécifier la base de données que vous souhaitez utiliser comme source pour votre intégration.
Lors de la configuration de PostgreSQL, vous obtenez trois bases de données standard prêtes à l'emploi : template0, template1 et postgres. Chaque fois que vous créez une nouvelle base de données dans PostgreSQL, vous la basez en fait sur l'une de ces trois bases de données de votre cluster. La base de données créée lors de la création du cluster Aurora PostgreSQL est basée sur template0. Le CREATE DATABASE La commande fonctionne en copiant une base de données existante et, si elle n'est pas explicitement spécifiée, par défaut, elle copie le modèle de base de données système standard1. Pour la base de données nommée pour l’intégration zéro-ETL, la base de données doit être créée à l’aide de template1 et non de template0. Par conséquent, si un nom de base de données initial est ajouté sous Configuration supplémentaire, qui serait créé à l'aide de template0 et ne peut pas être utilisé pour une intégration zéro-ETL.
- Pour créer une nouvelle base de données nommée en utilisant
CREATE DATABASEau sein du nouveau cluster Aurora PostgreSQLzero-etl-source-pg, obtenez d'abord le point de terminaison de l'instance d'écriture du cluster PostgreSQL.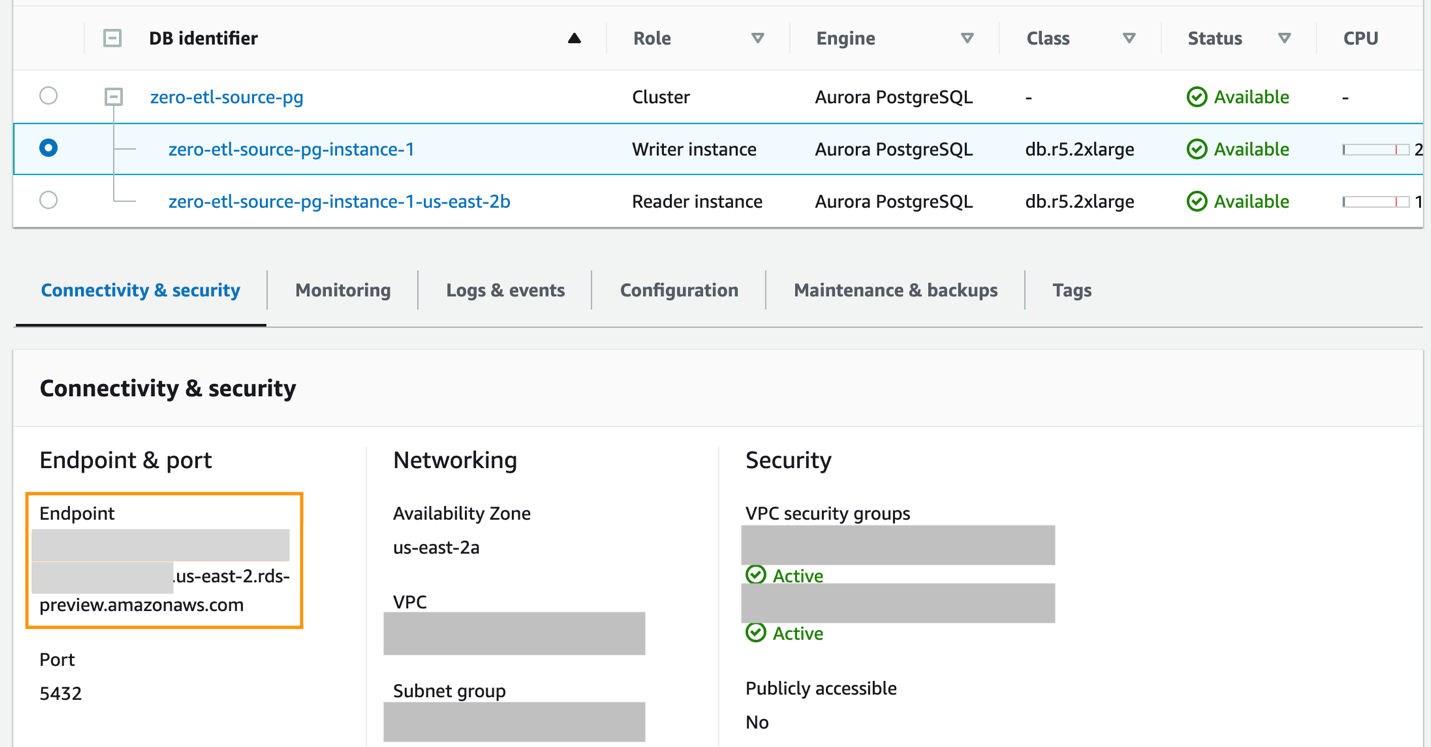
- Depuis un terminal ou via AWS Cloud Shell, SSH dans le cluster PostgreSQL et exécutez les commandes suivantes pour installer psql et créer une nouvelle base de données
zeroetl_db:
L'ajout de template template1 est facultatif, car par défaut, s'il n'est pas mentionné, CREATE DATABASE utilisera template1.
Vous pouvez également vous connecter via un client et créer la base de données. Faire référence à Se connecter à un cluster de base de données Aurora PostgreSQL pour les options de connexion au cluster PostgreSQL.
Configurer Redshift Serverless comme destination
Après avoir créé votre cluster de base de données source Aurora PostgreSQL, vous configurez un entrepôt de données cible Redshift. L'entrepôt de données doit répondre aux exigences suivantes :
- Créé en version préliminaire (pour les sources Aurora PostgreSQL uniquement)
- Utilise un type de nœud RA3 (ra3.16xlarge, ra3.4xlarge ou ra3.xlplus) avec au moins deux nœuds, ou Redshift Serverless
- Chiffré (si vous utilisez un cluster provisionné)
Pour cet article, nous créons et configurons un groupe de travail et un espace de noms Redshift Serverless comme entrepôt de données cible, en suivant ces étapes :
- Sur la console Amazon Redshift, choisissez Tableau de bord sans serveur dans le volet de navigation.
Étant donné que l'intégration zéro ETL d'Amazon Aurora PostgreSQL vers Amazon Redshift a été lancée en version préliminaire (et non à des fins de production), vous devez créer l'entrepôt de données cible dans un environnement de préversion.
- Selectionnez Créer un groupe de travail d'aperçu.
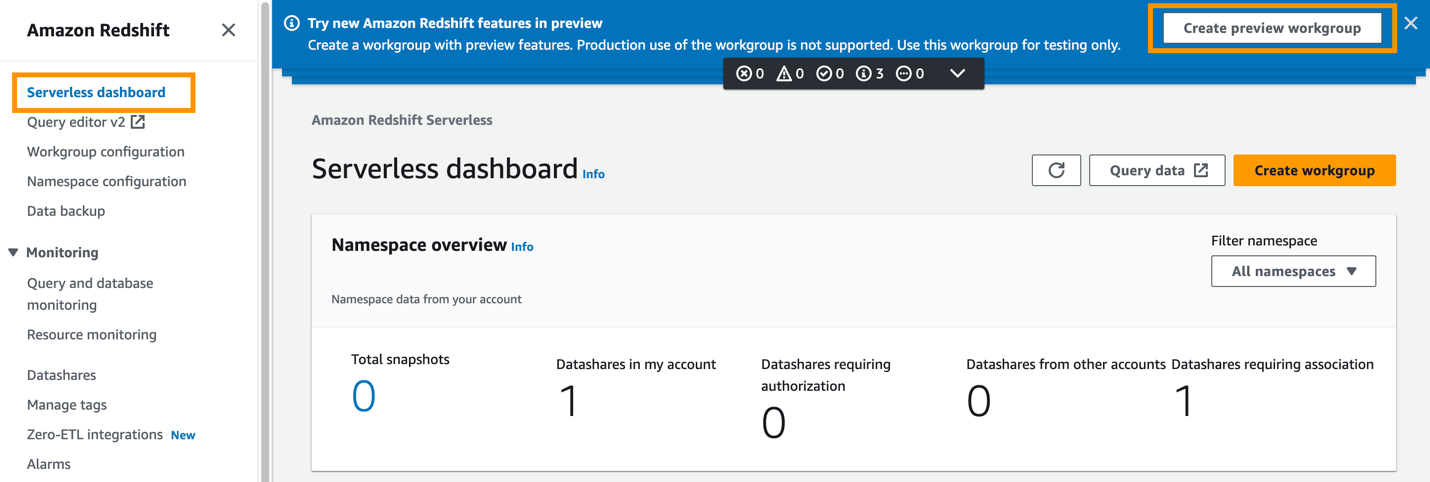
La première étape consiste à configurer le groupe de travail Redshift Serverless.
- Pour Nom du groupe de travail, entrez un nom (par exemple,
zero-etl-target-rs-wg).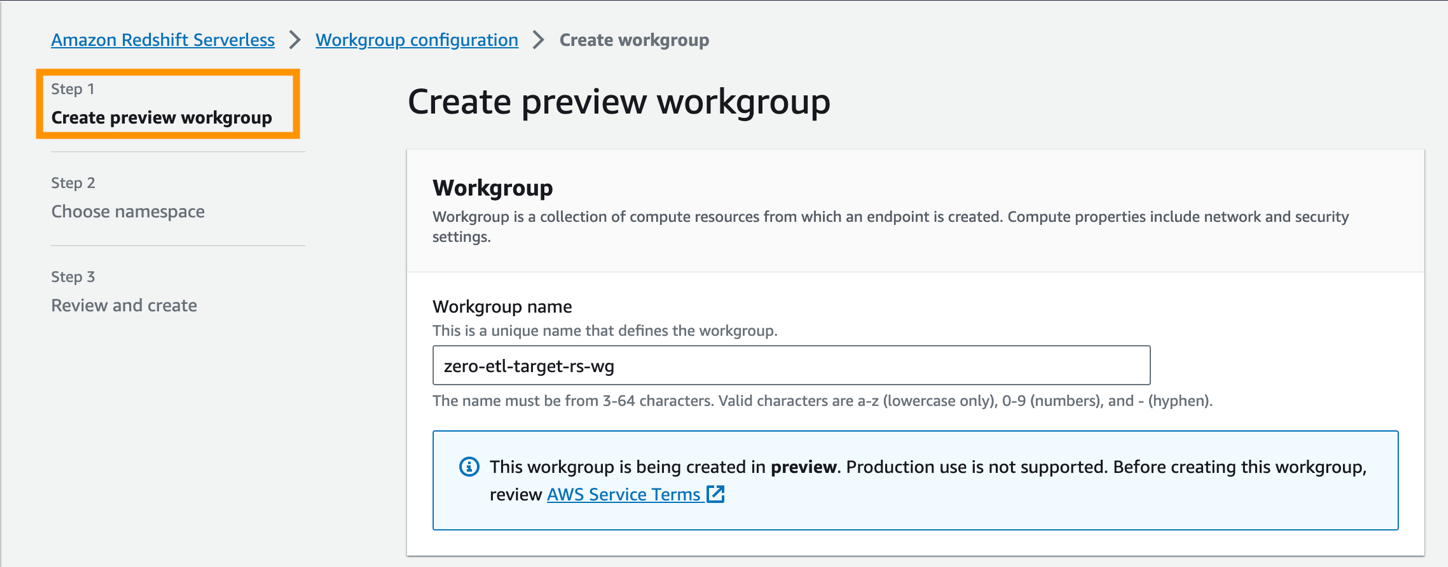
- De plus, vous pouvez choisir la capacité, pour limiter les ressources de calcul de l'entrepôt de données. La capacité peut être configurée par incréments de 8, de 8 à 512 RPU. Pour cet article, définissez ceci sur
8RPU. - Selectionnez Suivant.

Ensuite, vous devez configurer l'espace de noms de l'entrepôt de données.
- Sélectionnez Créer un nouvel espace de noms.
- Pour Espace de noms, entrez un nom (par exemple,
zero-etl-target-rs-ns). - Selectionnez Suivant.
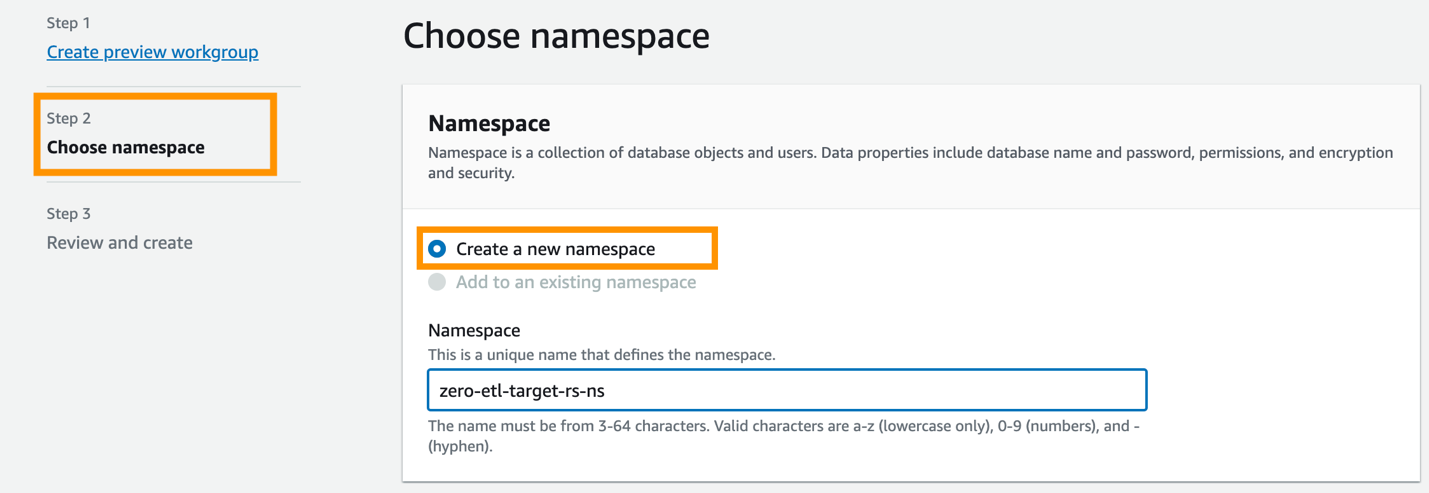
- Selectionnez Créer un groupe de travail.
- Une fois le groupe de travail et l'espace de noms créés, choisissez Configurations d'espace de noms dans le volet de navigation et ouvrez la configuration de l’espace de noms.
- Sur le Politique de ressources onglet, choisissez Ajouter des mandants autorisés.
Un mandataire autorisé identifie l'utilisateur ou le rôle qui peut créer des intégrations zéro ETL dans l'entrepôt de données.

- Pour ARN principal IAM ou ID de compte AWS, vous pouvez saisir soit l'ARN de l'utilisateur ou du rôle AWS, soit l'ID du compte AWS auquel vous souhaitez accorder l'accès pour créer des intégrations sans ETL. (Un identifiant de compte est stocké sous forme d'ARN.)
- Selectionnez Enregistrer les modifications.
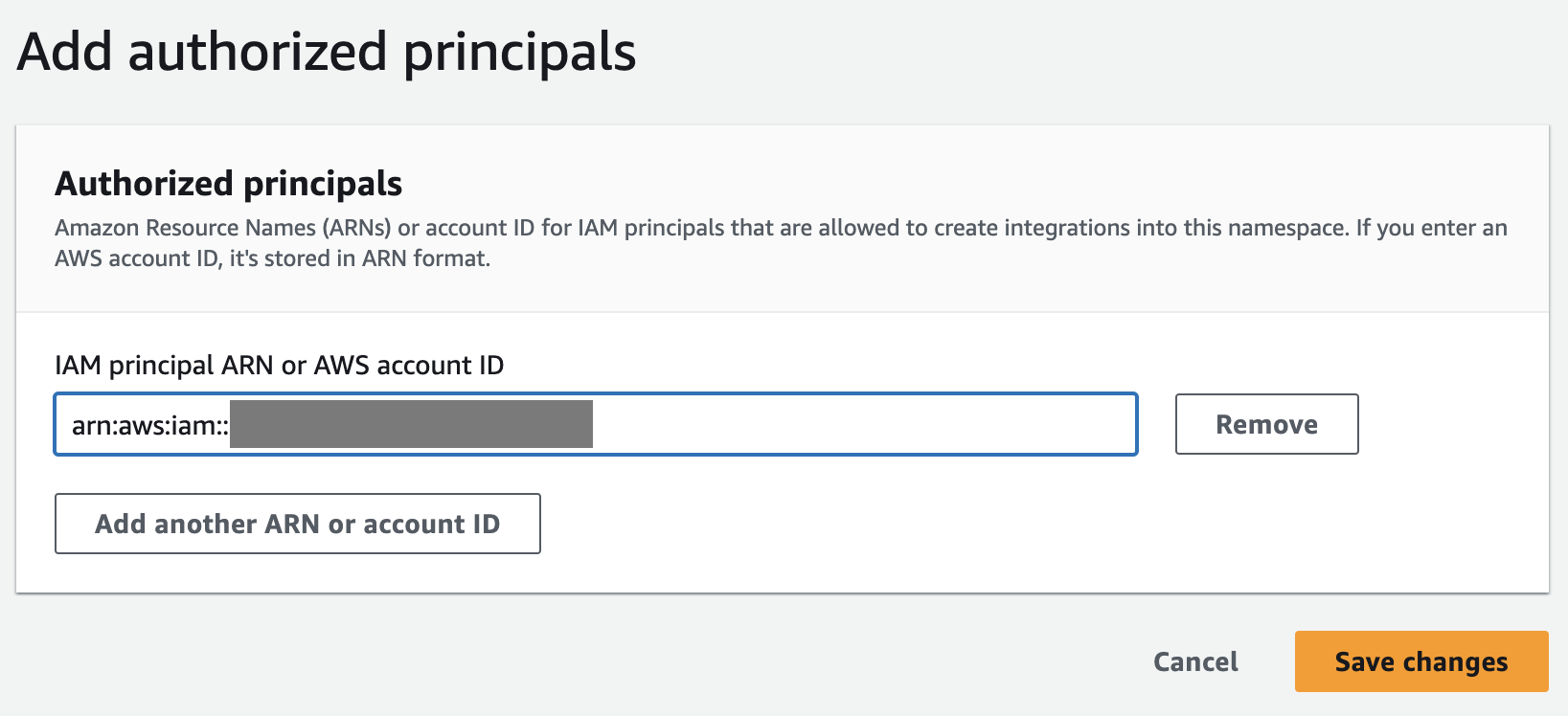
Une fois le principal autorisé configuré, vous devez autoriser la base de données source à mettre à jour votre entrepôt de données Redshift. Par conséquent, vous devez ajouter la base de données source en tant que source d'intégration autorisée à l'espace de noms.
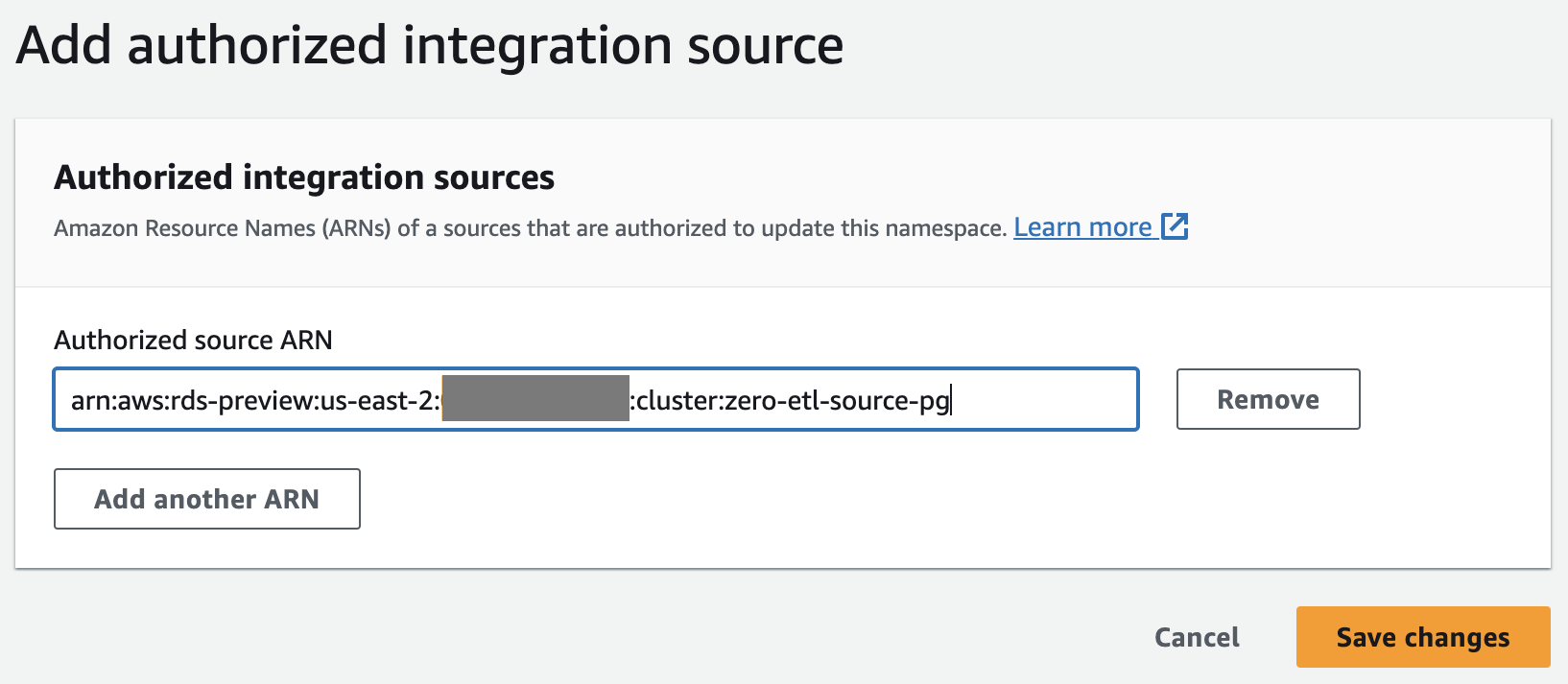
- Selectionnez Ajouter une source d'intégration autorisée.
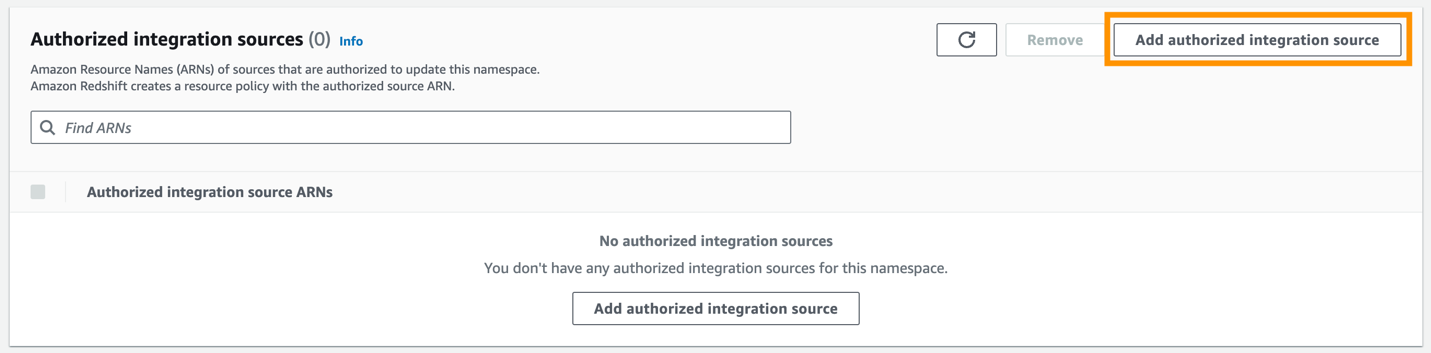
- Pour ARN source autorisé, saisissez l'ARN du cluster Aurora PostgreSQL, car il s'agit de la source de l'intégration zéro ETL.
Vous pouvez obtenir l'ARN du cluster Aurora PostgreSQL sur la console Amazon RDS, le configuration onglet sous Nom de la ressource Amazon.
- Selectionnez Enregistrer les modifications.
Mettre à jour le groupe de travail Redshift Serverless pour activer les identifiants sensibles à la casse
Amazon Aurora PostgreSQL est sensible à la casse par défaut et la sensibilité à la casse est désactivée sur tous les clusters provisionnés et les groupes de travail Redshift Serverless. Pour que l'intégration réussisse, le paramètre de sensibilité à la casse activate_case_sensitive_identifier doit être activé pour l’entrepôt de données.
Afin de modifier le enable_case_sensitive_identifier paramètre dans un groupe de travail Redshift Serverless, vous devez utiliser le Interface de ligne de commande AWS (AWS CLI), car la console Amazon Redshift ne prend actuellement pas en charge la modification des valeurs des paramètres Redshift Serverless. Exécutez la commande suivante pour mettre à jour le paramètre :
Un moyen simple de se connecter à l'AWS CLI consiste à utiliser CloudShell, qui est un shell basé sur un navigateur qui fournit un accès en ligne de commande aux ressources et outils AWS directement à partir d'un navigateur. La capture d'écran suivante illustre comment exécuter la commande dans CloudShell.
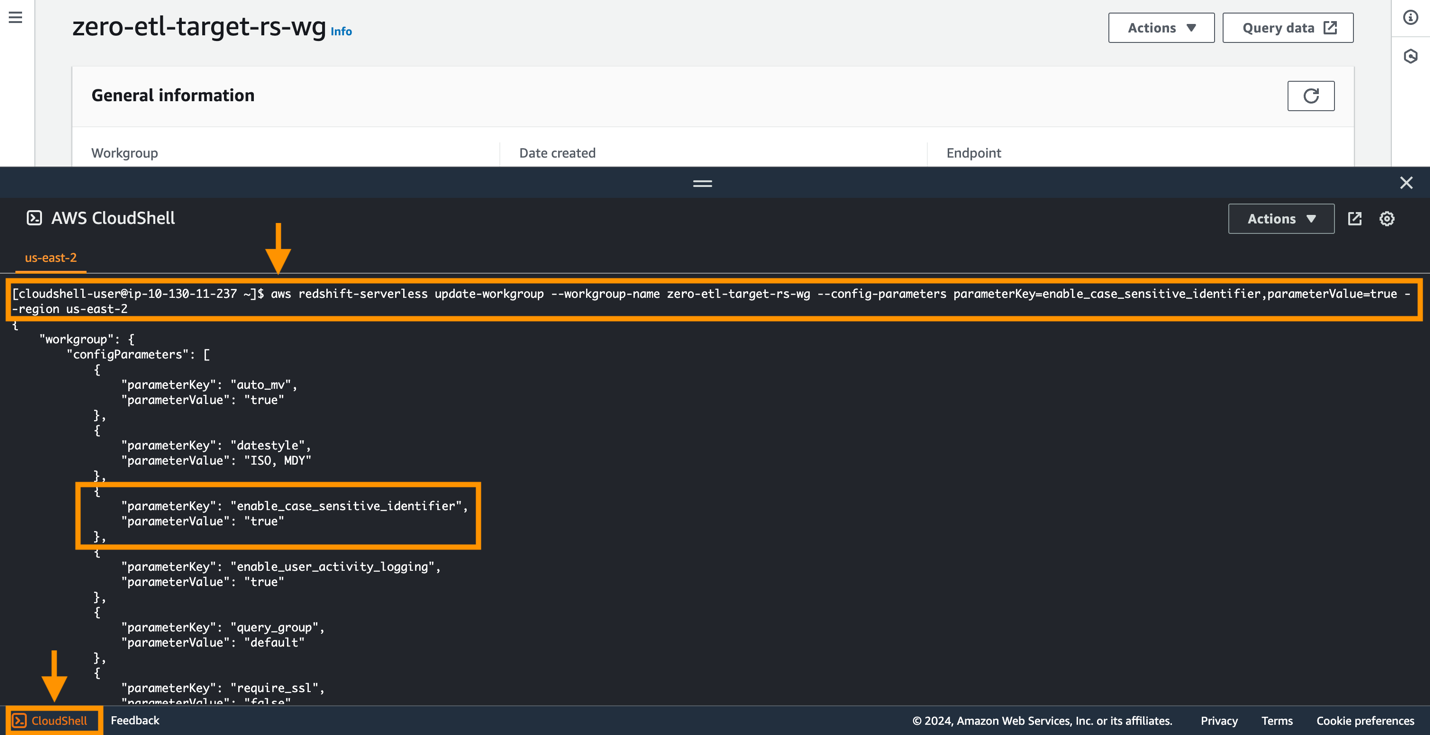
Configurer les autorisations requises
Pour créer une intégration sans ETL, votre utilisateur ou votre rôle doit avoir un lien politique basée sur l'identité avec le bon Gestion des identités et des accès AWS (IAM). Un propriétaire de compte AWS peut configurer les autorisations requises pour les utilisateurs ou les rôles susceptibles de créer des intégrations zéro ETL. L'exemple de stratégie permet au mandataire associé d'effectuer les actions suivantes :
- Créez des intégrations sans ETL pour le cluster de bases de données Aurora source.
- Affichez et supprimez toutes les intégrations sans ETL.
- Créez des intégrations entrantes dans l'entrepôt de données cible. Amazon Redshift a un format ARN différent pour les versions provisionnées et sans serveur :
- Cluster provisionné -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Sans serveur -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
Cette autorisation n'est pas requise si le même compte possède l'entrepôt de données Redshift et que ce compte est un mandataire autorisé pour cet entrepôt de données.
Effectuez les étapes suivantes pour configurer les autorisations :
- Sur la console IAM, choisissez Politiques internes dans le volet de navigation.
- Selectionnez Créer une politique.
- Créez une nouvelle stratégie appelée rds-integrations à l'aide du JSON suivant. Pour l'aperçu Amazon Aurora PostgreSQL, tous les ARN et actions au sein de la Environnement de prévisualisation de base de données Amazon RDS avoir -preview ajouté à l'espace de noms du service. Par conséquent, dans la stratégie suivante, au lieu de rds, vous devez utiliser
rds-preview. Par exemple,rds-preview:CreateIntegration.
- Attachez la stratégie que vous avez créée à vos autorisations d'utilisateur ou de rôle IAM.
Créer l'intégration zéro ETL
Pour créer l'intégration sans ETL, procédez comme suit :
- Sur la console Amazon RDS, choisissez Intégrations sans ETL dans le volet de navigation.
- Selectionnez Créer une intégration sans ETL.
- Pour Identifiant d'intégration, entrez un nom, par exemple
zero-etl-demo. - Selectionnez Suivant.

- Pour Base de données source, choisissez Parcourir les bases de données RDS.
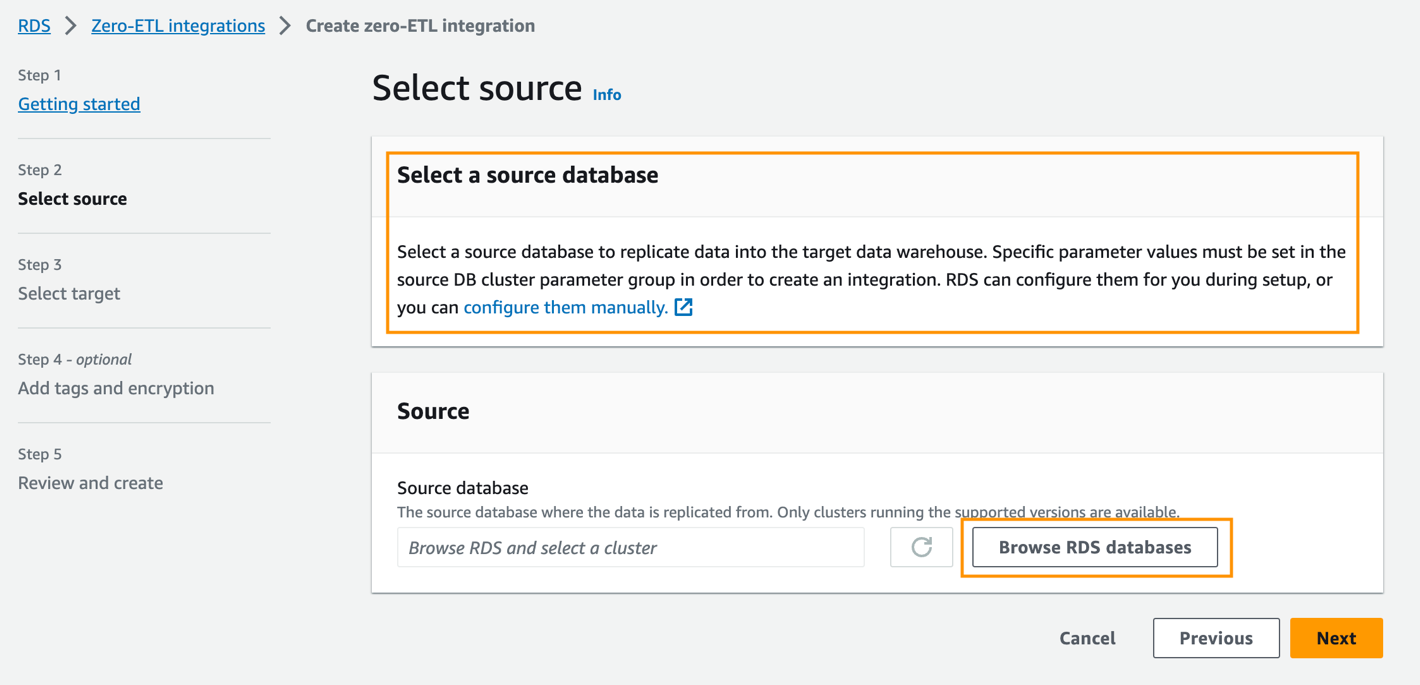
- Sélectionnez la base de données source
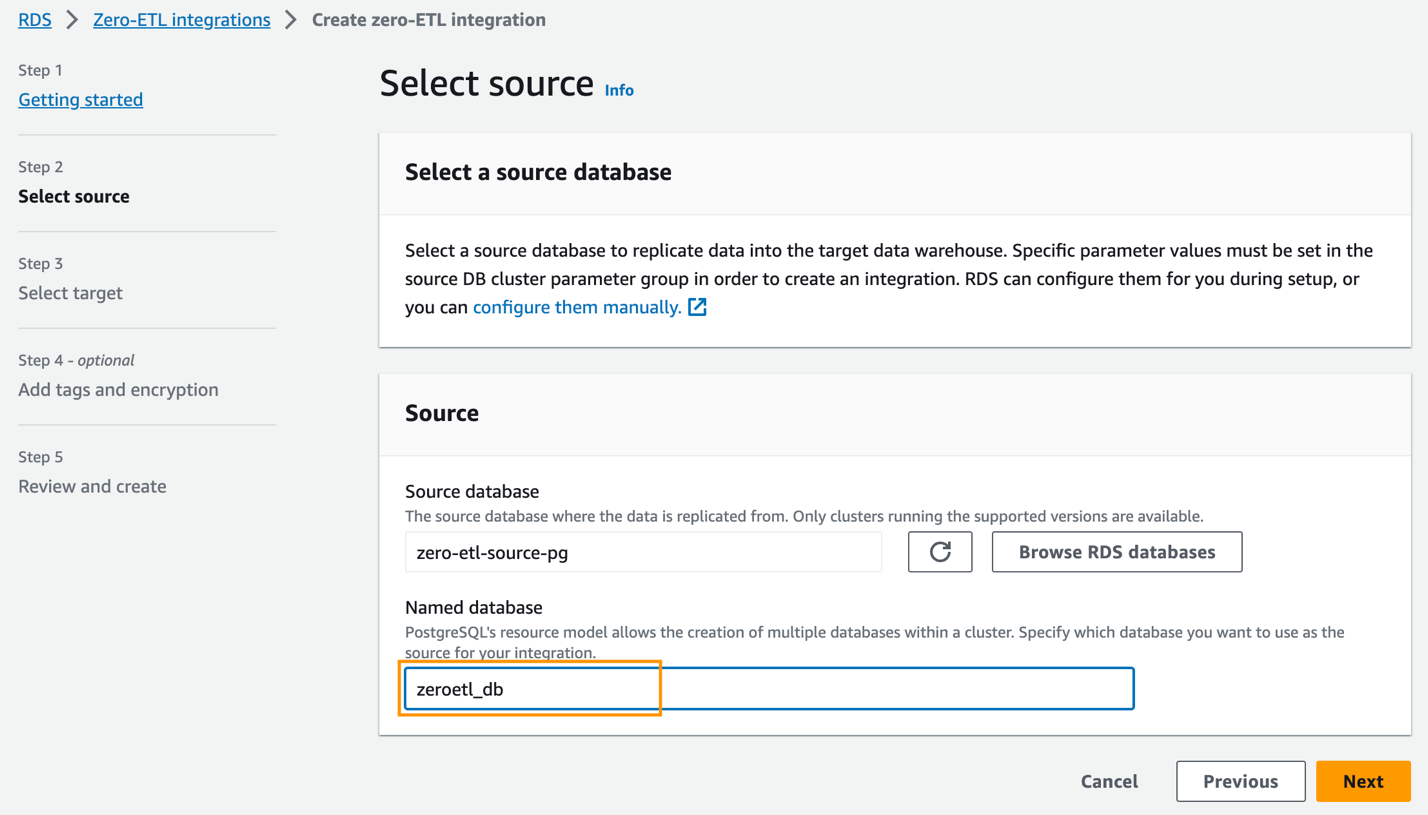
zero-etl-source-pget choisissez Selectionnez. - Pour Base de données nommée, saisissez le nom de la nouvelle base de données créée dans Amazon Aurora PostgreSQL (
zeroetl-db). - Selectionnez Suivant.
- Dans le Section cible, Pour Compte AWS, sélectionnez Utiliser le compte courant.
- Pour Entrepôt de données Amazon Redshift, choisissez Parcourez les entrepôts de données Redshift.

Nous discutons du Spécifiez un autre compte option plus loin dans cette section.
- Sélectionnez l'espace de noms de destination Redshift Serverless (
zero-etl-target-rs-ns), et choisissez Selectionnez.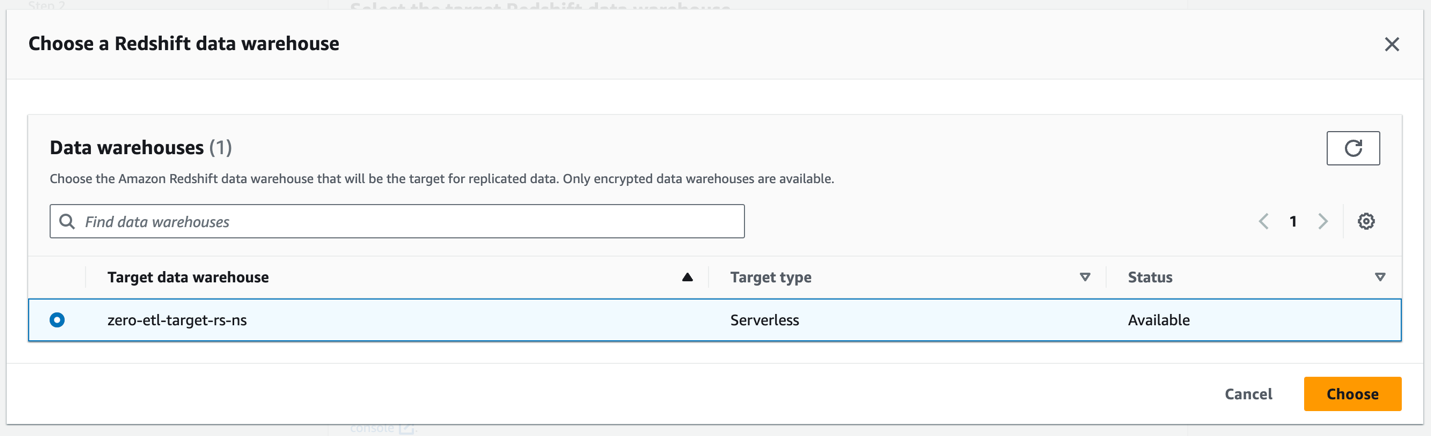
- Ajoutez des balises et un cryptage, le cas échéant, et choisissez Suivant.
- Vérifiez le nom de l'intégration, la source, la cible et d'autres paramètres, puis choisissez Créer une intégration sans ETL.
Vous pouvez choisir l'intégration sur la console Amazon RDS pour afficher les détails et suivre sa progression. Il faut environ 30 minutes pour changer le statut de La création à Actif, en fonction de la taille de l'ensemble de données déjà disponible dans la source.
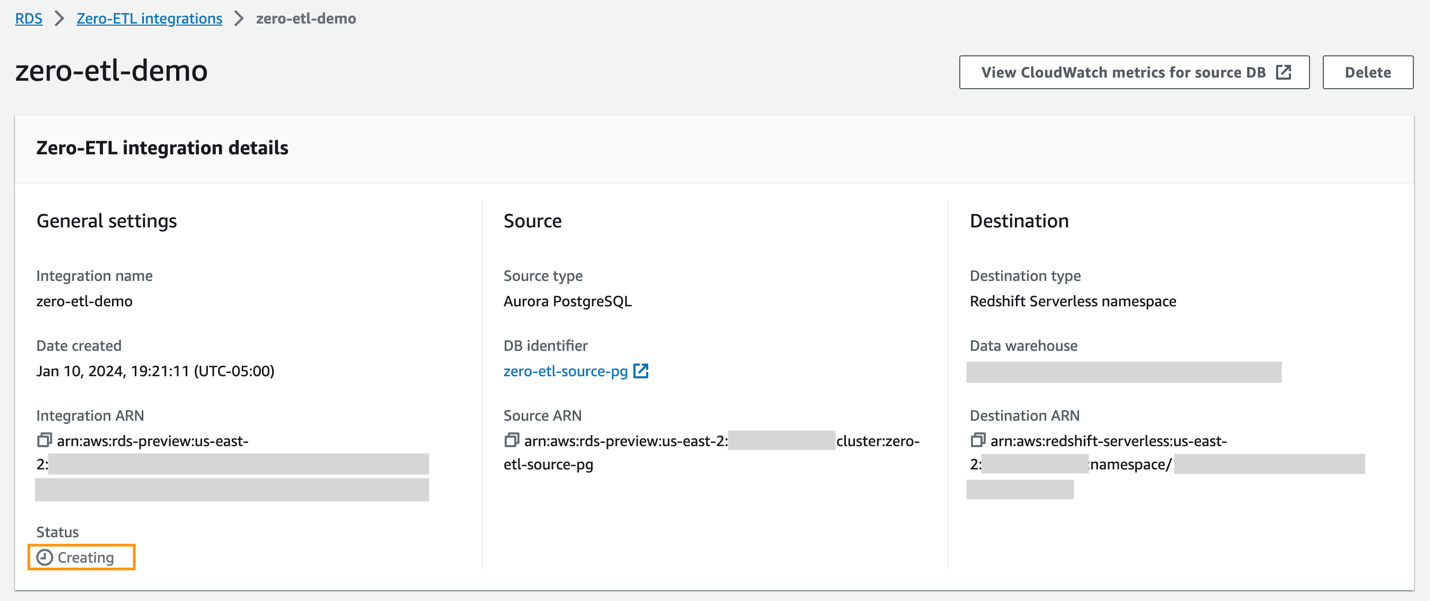
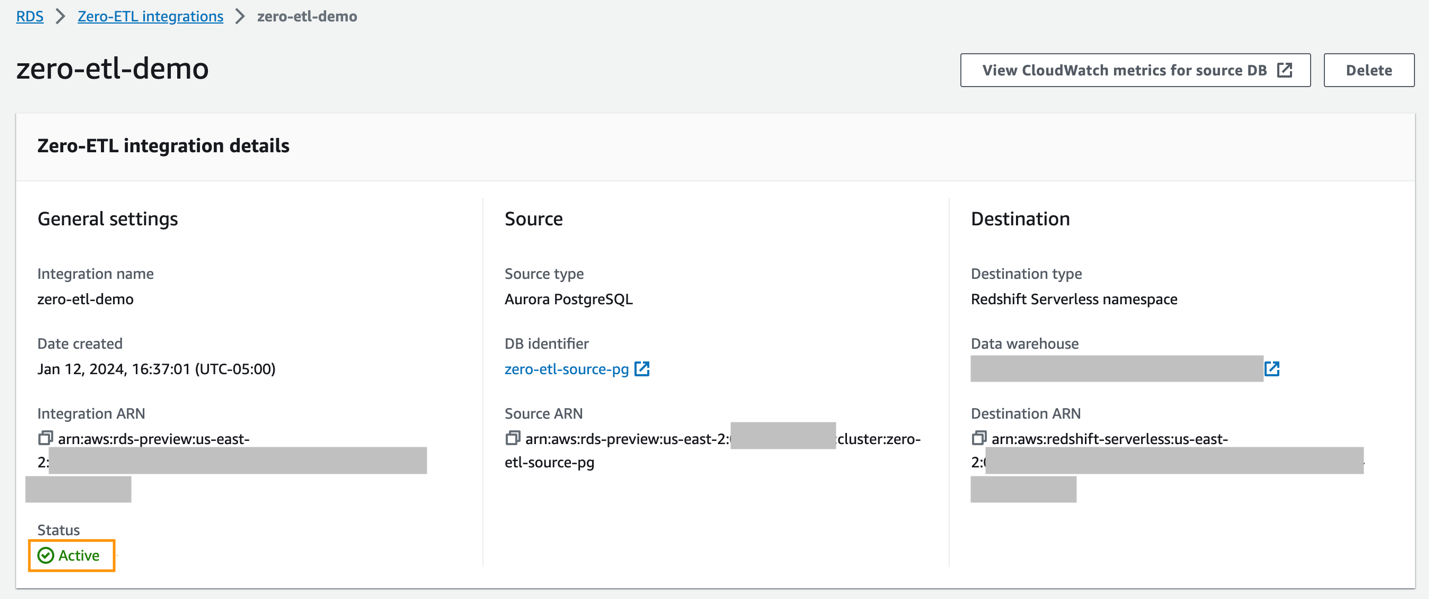
Pour spécifier un entrepôt de données Redshift cible se trouvant dans un autre compte AWS, vous devez créer un rôle qui permet aux utilisateurs du compte actuel d'accéder aux ressources du compte cible. Pour plus d'informations, reportez-vous à Fournir l'accès à un utilisateur IAM dans un autre compte AWS que vous possédez.
Créez un rôle dans le compte cible avec les autorisations suivantes :
Le rôle doit avoir la stratégie d'approbation suivante, qui spécifie l'ID de compte cible. Vous pouvez le faire en créant un rôle avec une entité de confiance en tant qu'ID de compte AWS dans un autre compte.
La capture d'écran suivante illustre la création de ceci sur la console IAM.
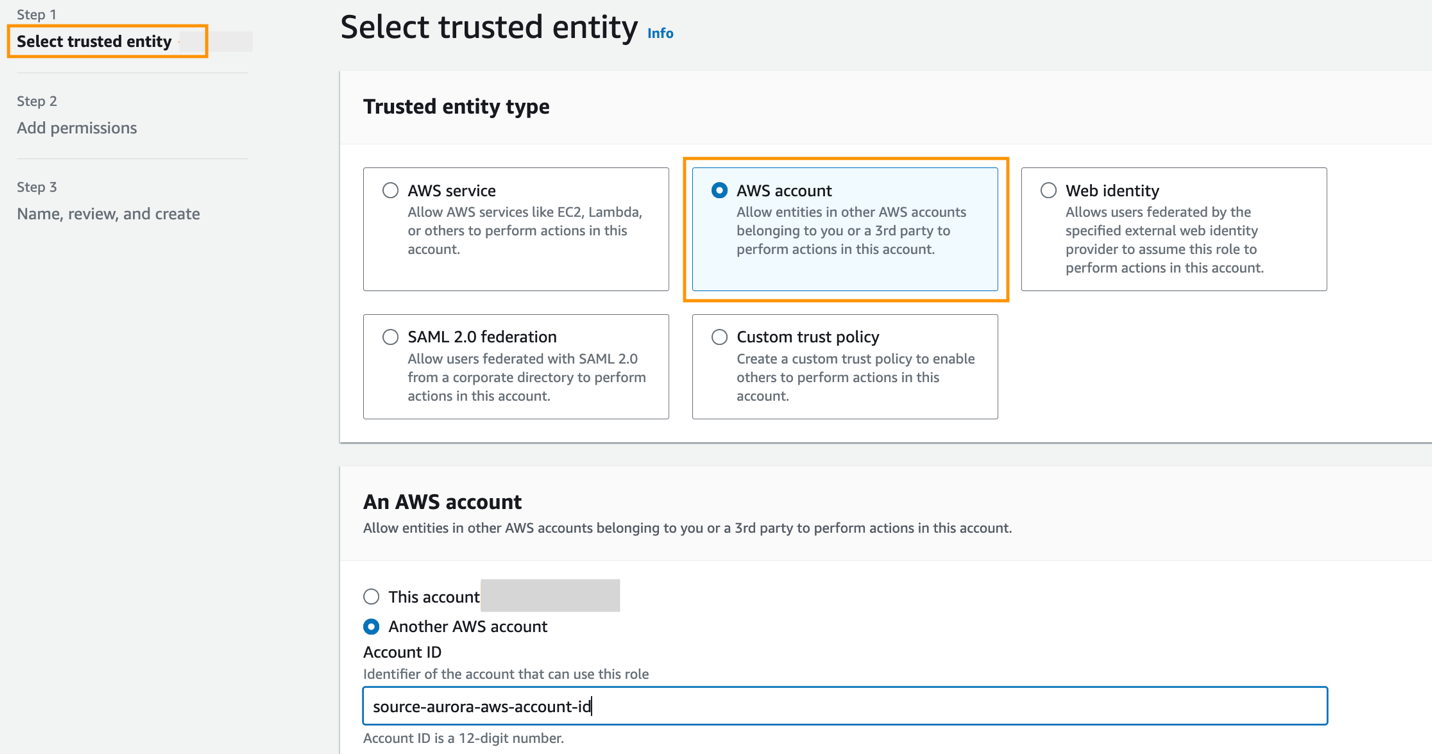
Ensuite, lors de la création de l'intégration zéro ETL, pour Spécifiez un autre compte, choisissez l'ID du compte de destination et le nom du rôle que vous avez créé.
Créer une base de données à partir de l'intégration dans Amazon Redshift
Pour créer votre base de données, procédez comme suit :
- Sur le tableau de bord Redshift Serverless, accédez au
zero-etl-target-rs-nsespace de noms. - Selectionnez Données de requête pour ouvrir l'éditeur de requêtes v2.

- Connectez-vous à l'entrepôt de données Redshift Serverless en choisissant Créer une connexion.
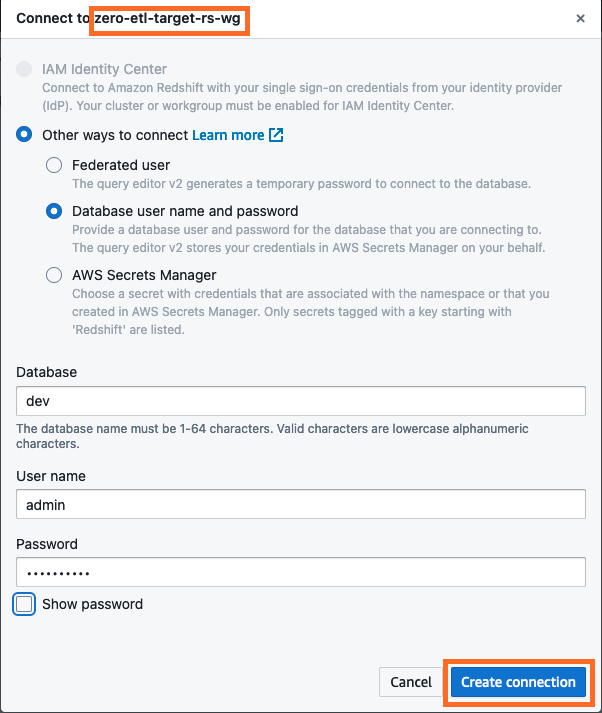
- Obtenez le
integration_iddusvv_integrationtableau système : - Utilisez l'option
integration_idde l'étape précédente pour créer une nouvelle base de données à partir de l'intégration. Vous devez également inclure une référence à la base de données nommée dans le cluster que vous avez spécifié lors de la création de l'intégration.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
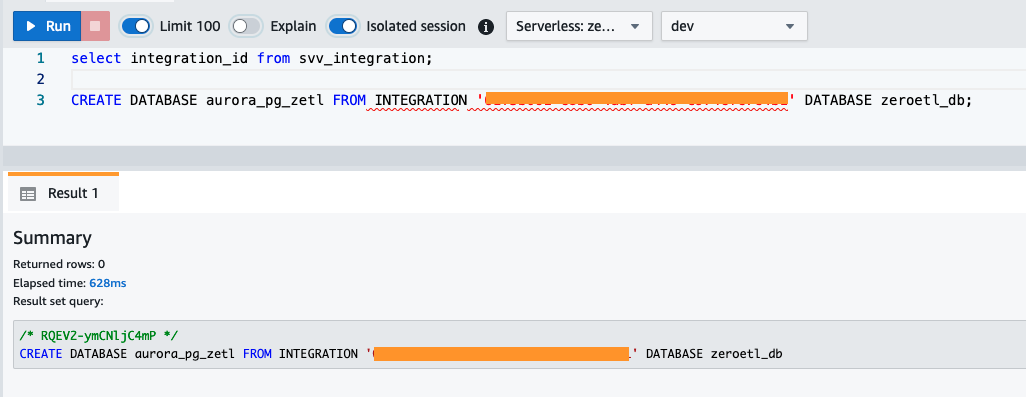
L'intégration est maintenant terminée et un instantané complet de la source sera reflété tel quel dans la destination. Les modifications en cours seront synchronisées presque en temps réel.
Analyser les données transactionnelles en temps quasi réel
Vous pouvez maintenant commencer à analyser les données en temps quasi réel de la source Amazon Aurora PostgreSQL vers la cible Amazon Redshift :
- Connectez-vous à votre base de données Aurora PostgreSQL source. Dans cette démo, nous utilisons psql pour vous connecter à Amazon Aurora PostgreSQL :

- Créez un exemple de table avec une clé primaire. Assurez-vous que toutes les tables à répliquer de la source vers la cible disposent d'une clé primaire. Les tables sans clé primaire ne peuvent pas être répliquées vers la cible.
- Insérez des données factices dans la table des nations et vérifiez si les données sont correctement chargées :

Ces exemples de données doivent maintenant être répliqués dans Amazon Redshift.
Analyser les données source dans la destination
Sur le tableau de bord Redshift Serverless, ouvrez l'éditeur de requêtes v2 et connectez-vous à la base de données aurora_pg_zetl vous avez créé plus tôt.
Exécutez la requête suivante pour valider la réplication réussie des données sources dans Amazon Redshift :
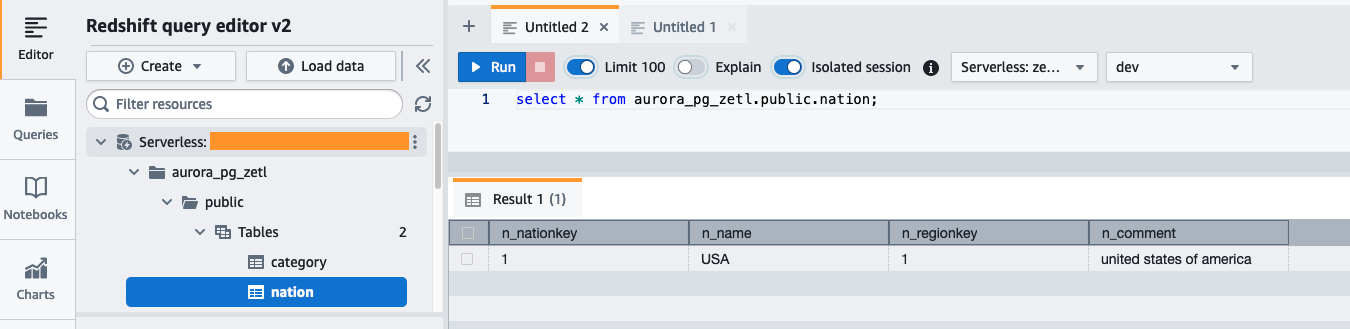
Vous pouvez également utiliser la requête suivante pour valider l'instantané initial ou l'activité de capture de données modifiées (CDC) en cours :
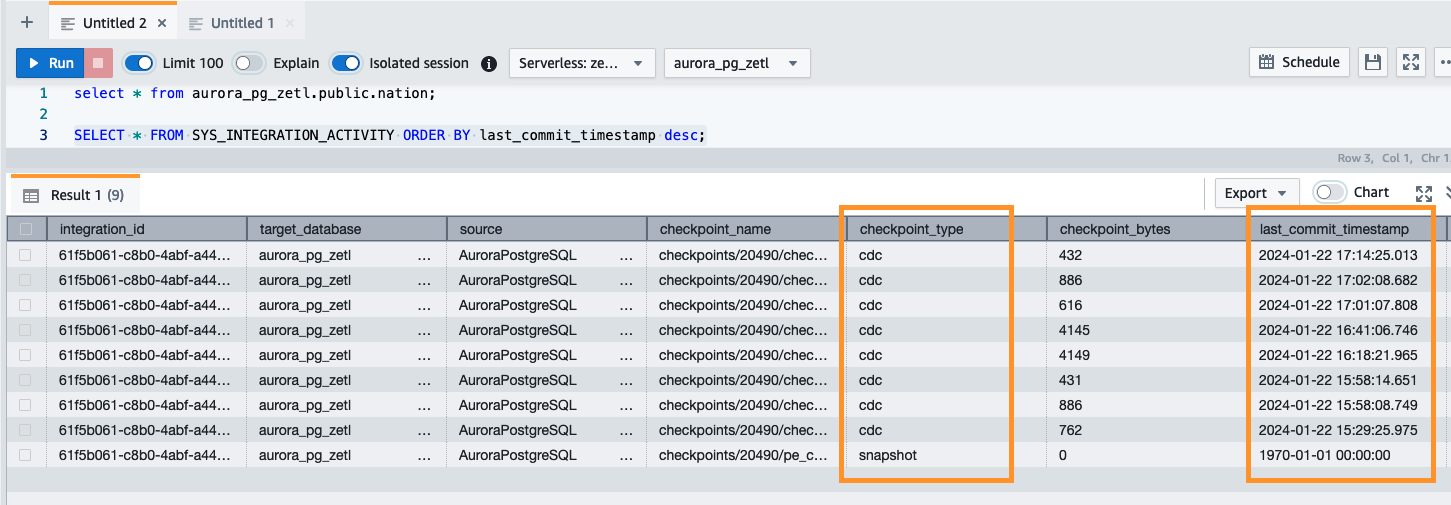
Le Monitoring
Il existe plusieurs options pour obtenir des métriques sur les performances et l'état de l'intégration zéro-ETL d'Aurora PostgreSQL avec Amazon Redshift.
Si vous accédez à la console Amazon Redshift, vous pouvez choisir Intégrations sans ETL dans le volet de navigation. Vous pouvez choisir l'intégration zéro ETL que vous souhaitez et afficher Amazon Cloud Watch métriques liées à l’intégration. Ces métriques sont également directement disponibles dans CloudWatch.
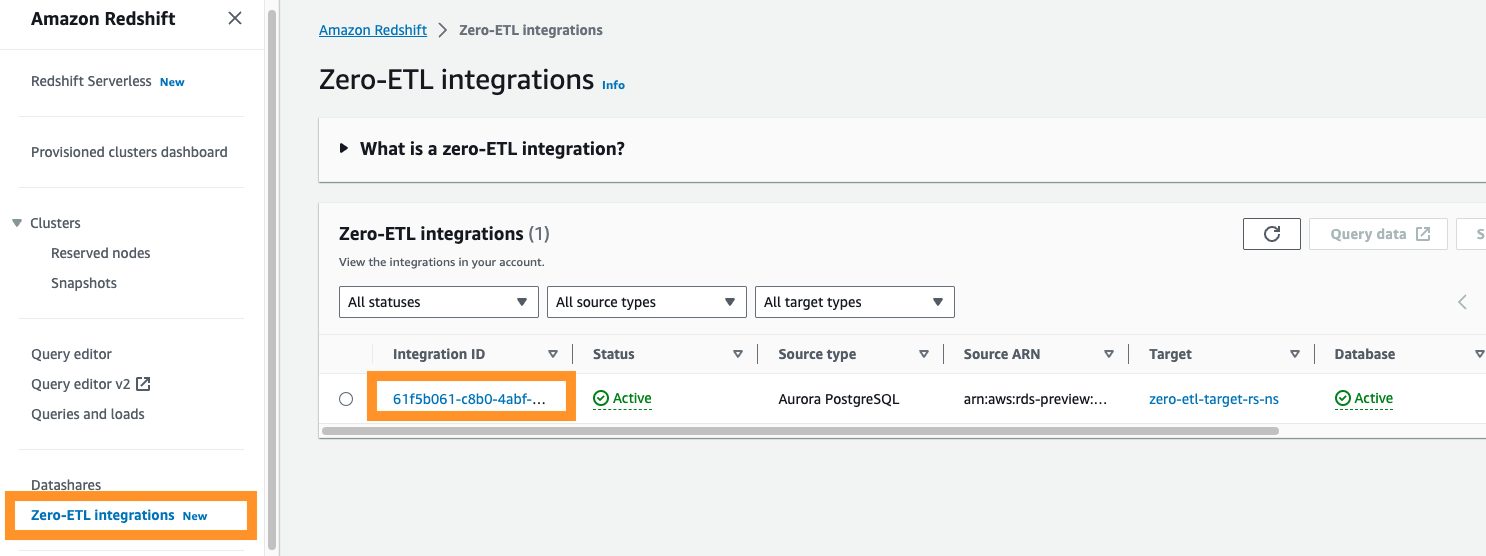
Pour chaque intégration, deux onglets contenant des informations sont disponibles :
- Métriques d'intégration – Affiche des mesures telles que le nombre de tables répliquées avec succès et les détails du décalage
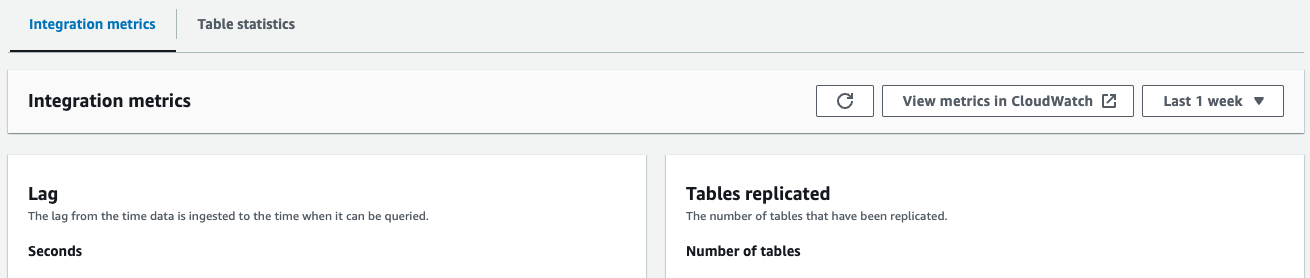
- Statistiques du tableau – Affiche les détails de chaque table répliquée d'Amazon Aurora PostgreSQL vers Amazon Redshift
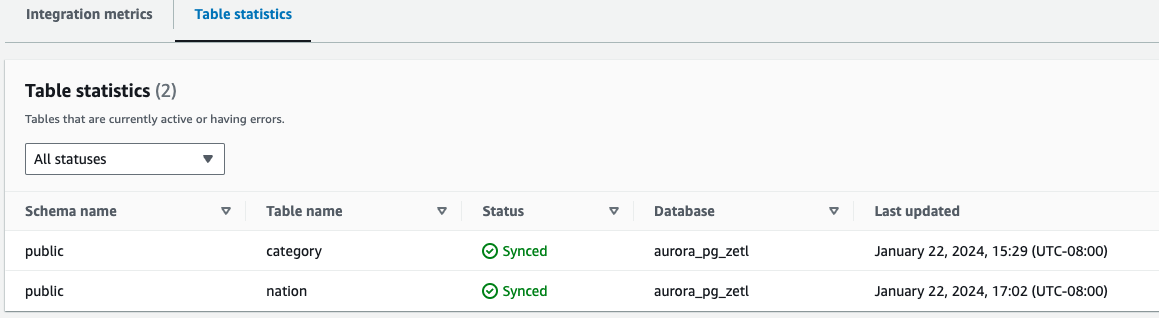
En plus des métriques CloudWatch, vous pouvez interroger les éléments suivants vues système, qui fournissent des informations sur les intégrations :
Nettoyer
Lorsque vous supprimez une intégration ETL zéro, vos données transactionnelles ne sont pas supprimées d'Aurora ou d'Amazon Redshift, mais Aurora n'envoie pas de nouvelles données à Amazon Redshift.
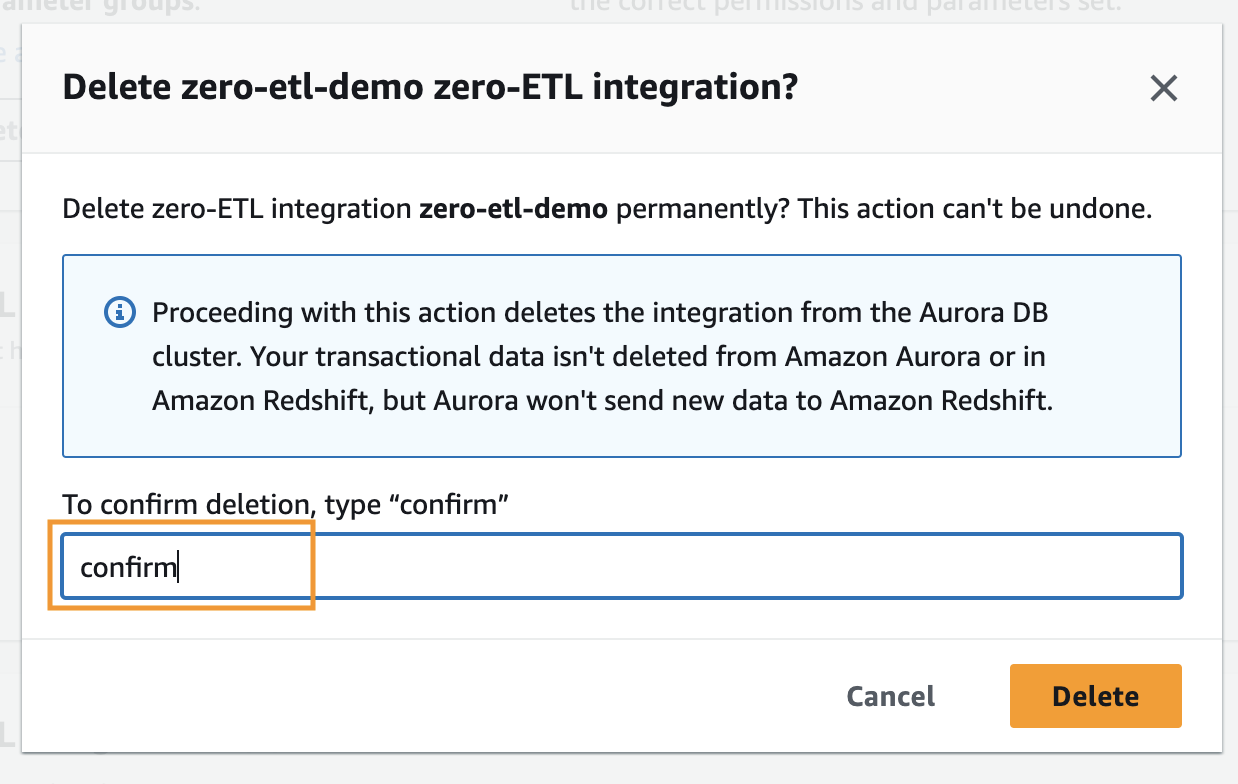
Pour supprimer une intégration sans ETL, procédez comme suit :
- Sur la console Amazon RDS, choisissez Intégrations sans ETL dans le volet de navigation.
- Sélectionnez l'intégration zéro-ETL que vous souhaitez supprimer et choisissez Supprimer.

- Pour confirmer la suppression, entrez confirmer et choisissez Supprimer.
Conclusion
Dans cet article, nous avons expliqué comment configurer l'intégration zéro ETL d'Amazon Aurora PostgreSQL vers Amazon Redshift, une fonctionnalité qui réduit l'effort de maintenance des pipelines de données et permet des analyses en temps quasi réel sur les données transactionnelles et opérationnelles.
Pour en savoir plus sur l'intégration zéro ETL, reportez-vous à Travailler avec les intégrations Aurora zéro-ETL avec Amazon Redshift ainsi que Limites.
À propos des auteurs
 Raks Khare est un architecte de solutions spécialisées en analyse chez AWS basé en Pennsylvanie. Il aide les clients à concevoir des solutions d'analyse de données à grande échelle sur la plate-forme AWS.
Raks Khare est un architecte de solutions spécialisées en analyse chez AWS basé en Pennsylvanie. Il aide les clients à concevoir des solutions d'analyse de données à grande échelle sur la plate-forme AWS.
 Juan Luis Polo Garzón est un architecte de solutions spécialisé associé chez AWS, spécialisé dans les charges de travail d'analyse. Il a de l'expérience en aidant les clients à concevoir, créer et moderniser leurs solutions d'analyse basées sur le cloud. En dehors du travail, il aime voyager, faire du plein air, faire de la randonnée et assister à des événements musicaux en direct.
Juan Luis Polo Garzón est un architecte de solutions spécialisé associé chez AWS, spécialisé dans les charges de travail d'analyse. Il a de l'expérience en aidant les clients à concevoir, créer et moderniser leurs solutions d'analyse basées sur le cloud. En dehors du travail, il aime voyager, faire du plein air, faire de la randonnée et assister à des événements musicaux en direct.
 Sushmita Barthakur est architecte de solutions senior chez Amazon Web Services, aidant les clients d'entreprise à concevoir leurs charges de travail sur AWS. Forte d'une solide expérience en analyse de données et en gestion de données, elle possède une vaste expérience en aidant les clients à concevoir et à créer des solutions de Business Intelligence et d'analyse, à la fois sur site et dans le cloud. Sushmita est basée à Tampa, en Floride et aime voyager, lire et jouer au tennis.
Sushmita Barthakur est architecte de solutions senior chez Amazon Web Services, aidant les clients d'entreprise à concevoir leurs charges de travail sur AWS. Forte d'une solide expérience en analyse de données et en gestion de données, elle possède une vaste expérience en aidant les clients à concevoir et à créer des solutions de Business Intelligence et d'analyse, à la fois sur site et dans le cloud. Sushmita est basée à Tampa, en Floride et aime voyager, lire et jouer au tennis.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

