Quand migration des charges de travail Hadoop vers Amazon EMR, il est souvent difficile d'identifier la configuration de cluster optimale sans analyser manuellement les charges de travail existantes. Pour résoudre ce problème, nous introduisons l'outil d'évaluation du coût total de possession (TCO) de la migration Hadoop. Vous disposez désormais d'un outil d'évaluation du coût total de possession de la migration Hadoop dans le kit de livraison de migration AWS ProServe Hadoop (HMDK). L'outil TCO HMDK en libre-service accélère la conception de nouveaux Amazon DME clusters en analysant la charge de travail Hadoop existante et en calculant le coût total de possession (TCO) exécuté sur le futur système Amazon EMR. Le rapport sur le coût total de possession d'Amazon EMR avec la nouvelle conception d'Amazon EMR peut démontrer la migration d'Amazon EMR avec des économies détaillées et des avantages commerciaux.
Dans cet article, nous présentons un cas d'utilisation et les fonctions et composants de l'outil. Nous partageons également des études de cas pour vous montrer les avantages de l'utilisation de l'outil. Enfin, nous vous montrons les informations techniques pour utiliser l'outil.
Présentation des cas d'utilisation
La migration des charges de travail Hadoop vers Amazon EMR accélère la modernisation de l'analyse du Big Data, augmente la productivité et réduit les coûts opérationnels. La refactorisation du calcul et du stockage couplés vers une architecture de découplage est une solution de données moderne. Il permet le calcul tel que les instances EMR et le stockage tel que Service de stockage simple Amazon (Amazon S3) lacs de données à l'échelle. Pour divers travaux Hadoop, les clients disposent d'options de déploiement sur mesure d'Amazon EMR entièrement géré, Amazon EMR sur Amazon EKS ainsi que EMR sans serveur. Le futur cluster EMR optimisé donne les mêmes résultats et valeurs avec un coût total de possession beaucoup plus faible par rapport au cluster Hadoop source. Mais nous avons besoin d'un rapport TCO pour présenter les détails de la réduction des coûts, comme le montre la figure suivante.

En règle générale, le début d'une migration Hadoop nécessite que les experts Hadoop passent des semaines, voire des mois, à évaluer les charges de travail actuelles du cluster Hadoop en vue d'un plan de migration ultérieure. Cela pourrait retarder l'acceptation du projet sans un bon rapport TCO.
Pour accélérer les migrations Hadoop et atténuer les efforts d'évaluation de la charge de travail par les PME, AWS ProServe a créé l'outil d'évaluation du coût total de possession de la migration Hadoop dans le kit de livraison de migration AWS ProServe Hadoop.
Présentation de l'outil HMDK TCO
En tant qu'accélérateur de migration Hadoop, l'outil HMDK TCO comporte trois composants :
- Collecteur de bûches YARN – Récupère les journaux de charge de travail existants à partir du gestionnaire de ressources YARN
- Analyseur de journaux YARN – Fournit un aperçu temporel approfondi sur les différents aspects des emplois
- Calculateur TCO – Génère un TCO sur 3 ans ou 1 an calculé automatiquement
L'outil TCO HMDK en libre-service est disponible en téléchargement sur GitHub.
L'utilisation de l'outil se déroule en trois étapes :
- Tout d'abord, le collecteur de journaux YARN communique avec le système Hadoop actuel pour récupérer les journaux YARN.
- Avec les journaux YARN collectés, l'étape suivante consiste à utiliser l'analyseur de journaux YARN et à configurer la pile d'analyseurs de journaux à l'aide de AWS CloudFormation. Les résultats de l'analyseur de journaux révèlent des informations sur la charge de travail Hadoop avec diverses vues et métriques des applications Hadoop présentées dans Amazon QuickSight tableaux de bord, ce qui débouche sur la conception d'un futur cluster EMR.
- Enfin, le calculateur TCO génère le rapport TCO en simulant l'utilisation horaire des ressources d'un futur cluster EMR. Pour accélérer l'évaluation de la migration Hadoop, le rapport TCO fournit des informations et des valeurs cruciales permettant aux parties prenantes de votre entreprise de prendre une décision d'adhésion.
Le diagramme suivant illustre cette architecture.

Les informations sur la charge de travail Hadoop vous permettent de concevoir un cluster EMR bien architecturé pour atteindre performances et rentabilité de manière agile. Pour mener des conceptions bien architecturées, vous devez choisir entre diverses spécifications système d'un cluster EMR et plusieurs considérations de coût.
Les spécifications du système sont les suivantes :
- Nombre de clusters EMR – Amazon EMR vous permet d'exécuter plusieurs clusters élastiques dans le cloud AWS pour servir le même objectif qu'un cluster Hadoop statique partagé sur site
- Types de cluster EMR (persistant ou transitoire) – Concevez votre système pour conserver un minimum de clusters persistants afin de réduire les coûts
- Types d'instance et configuration (mémoire, vCore, etc.) – Choisissez la bonne instance pour votre travail
- Allocation des ressources pour les applications et utilisation du cluster – Sur la base de l'analyse de la charge de travail sur site, concevoir une allocation efficace des ressources et une utilisation efficace des ressources dans les futurs clusters EMR
Les considérations de coût sont les suivantes :
- Dernière liste de prix (parmi des milliers d'instances EC2 disponibles) – L'outil HMDK TCO effectue le calcul du prix avec Cloud de calcul élastique Amazon (Amazon EC2) les types d'instances, les configurations et leurs prix.
- Coût de stockage Amazon S3 (standard, Glacier, etc.) – La réplication des données n'est plus nécessaire pour la fiabilité. Vous pouvez utiliser le stockage fatigué dans Amazon S3 pour réduire les coûts.
Collecteur de bûches YARN
L'outil HMDK TCO offre un moyen simple de capturer les journaux Hadoop YARN, qui incluent les statistiques d'exécution des tâches Hadoop et les utilisations de ressources correspondantes. La capture d'écran suivante est un exemple de journal YARN.
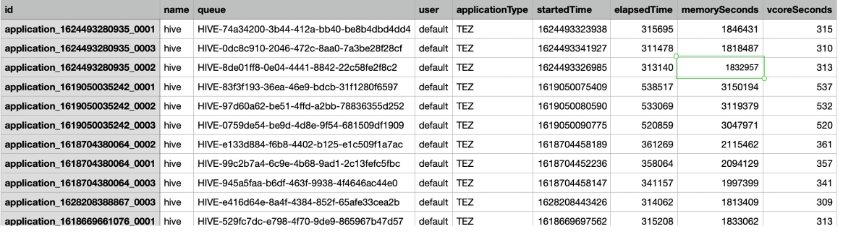
L'outil prend en charge le protocole HTTPS pour communiquer avec YARN Resource Manager. L'outil transporte les journaux JSON YARN en tant qu'entrées vers un analyseur Python, qui convertit les journaux YARN du format JSON au format CSV. Les nouveaux journaux au format CSV sont les fichiers d'entrée standard pour l'analyseur de journaux YARN.
Pour plus d'informations, consultez le GitHub repo.
Analyseur de journaux YARN et cas d'utilisation de conception optimisée
Avec le journal, nous pouvons suivre les étapes de la TCO fil-log-analyse README fichier pour utiliser AWS CloudFormation pour configurer les ressources QuickSight.
L'analyseur de journaux HMDK TCO génère un tableau de bord QuickSight sur diverses métriques :
- Chronologie des travaux – Combien de travaux sont en cours d'exécution en même temps
- Utilisateur du travail – Répartition des utilisateurs et des files d'attente
- Type d'application et type de moteur – Répartition par types d'applications (Spark, Hive, Presto) et type de moteur d'exécution (MapReduce, Spark, Tez)
- Temps écoulé – Le délai de traitement d'une demande
- Ressources – Mémoire et CPU
La capture d'écran suivante montre un exemple de tableau de bord.

Les tableaux de bord QuickSight présentent des informations basées sur des journaux YARN consécutifs collectés sur une période suffisamment longue (par exemple, une fenêtre de 2 semaines). Les informations des journaux révèlent les types d'applications, les utilisateurs, les files d'attente, la cadence d'exécution, les périodes et les utilisations des ressources. Les données vous aident également à découvrir les travaux par lots quotidiens ou les travaux ad hoc, les travaux de longue durée et la consommation de ressources. Ces informations vous aident à concevoir les clusters appropriés, tels que les clusters transitoires ou les clusters permanents de base, et à choisir la bonne instance EC2 pour les tâches gourmandes en mémoire ou en calcul. Avec les résultats de l'analyseur de journaux, l'outil TCO calcule automatiquement le TCO d'un futur cluster EMR.
Voyons quelques cas d'utilisation réels de clients dans les sections suivantes.
Cas 1 : Utiliser judicieusement les clusters transitoires et persistants
Pour ce cas d'utilisation, un client du secteur financier dispose d'un cluster Hadoop à 11 nœuds.
Le tableau de bord de la chronologie QuickSight affiche les exécutions de travail aux heures de pointe en raison du travail par lots quotidien. Cela nous guide pour concevoir deux clusters pour répondre aux charges de travail existantes. Lorsque nous gardons un cluster persistant à une taille minimale, nous pouvons avoir le cluster EMR transitoire pour gérer le travail de style batch aux heures de pointe.
Par conséquent, nous avons conçu les clusters pour avoir un cluster persistant avec 2 nœuds de données, tandis que les nœuds transitoires peuvent évoluer de 0 à 10 entre 1h00 et 4h00.
La figure suivante illustre cette conception.

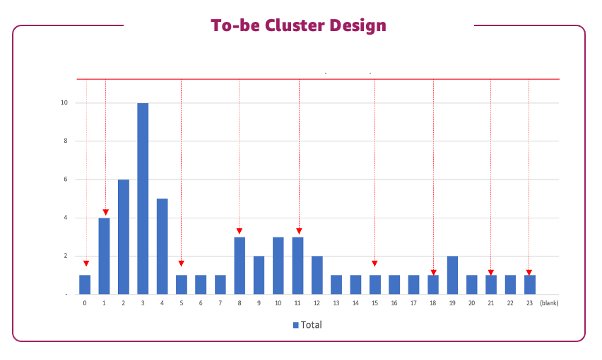
Cette conception équilibrée utilisant des clusters transitoires et persistants a permis de réaliser des économies d'environ 80 % par rapport à une conception lift-and-shift.
Cas 2 : Identifiez l'utilisation de la file d'attente Hadoop et les tâches de longue durée pour concevoir plusieurs clusters et des exécutions optimisées
Pour notre prochain cas d'utilisation, une entreprise exécute 196 nœuds à l'aide de Hadoop 3.1 avec des tâches telles que Hive, Spark et Kafka. La file d'attente par défaut Hadoop et quatre autres files d'attente ont été utilisées pour regrouper diverses charges de travail. Comme illustré dans la figure suivante, certaines tâches de très longue durée sont observées dans le cluster partagé, ce qui entraîne des tâches en file d'attente qui ont une concurrence au niveau des ressources et une allocation de ressources déséquilibrée.


Le tableau de bord utilisateur QuickSight nous guide à travers l'utilisation de la file d'attente, le tableau de bord du temps écoulé nous guide à travers les travaux de longue durée et le tableau de bord des ressources nous guide à travers l'utilisation de la mémoire et du vCore pour les travaux.
Par conséquent, nous concevons une solution pour transférer les travaux de file d'attente à exécuter dans des clusters séparés, et les travaux de file d'attente par défaut sont divisés pour s'exécuter dans différents clusters. En identifiant les travaux de longue durée et en comprenant les besoins en ressources, nous pourrions concevoir un cluster pour exécuter ces travaux plus efficacement.
Cette conception permet au travail de s'exécuter plus rapidement et aux clusters d'être utilisés plus efficacement tout en réduisant les coûts.
Conception de grappe
L'outil HMDK TCO fournit un modèle de conception de cluster comme dans l'exemple suivant.

Ici, nous avons deux clusters, un transitoire et un persistant, pour gérer les tâches Spark et Tez en conséquence. L'heure de début et de fin de chaque cluster peut être déterminée à partir de l'analyse du journal. Avec cette conception de cluster, nous pouvons obtenir les prévisions horaires d'utilisation des ressources de charge de travail. Ensuite, le calculateur TCO obtient toutes les informations nécessaires pour générer des coûts en fonction des variables de simulation TCO que vous choisissez.
Calculateur TCO
Le calculateur HMDK TCO est un composant guidant la conception du cluster EMR à l'aide du modèle de conception EMR. Ensuite, il génère les prévisions horaires d'utilisation des ressources agrégées à l'aide d'un programme Python. Le composant fournit des directives et un modèle Excel pour saisir les paramètres du système et de la spécification des coûts. Le composant a la logique avec une liste de prix Amazon EMR intégrée. Le coût TCO sur 1 an et 3 ans peut être généré automatiquement par le modèle TCO Excel prenant en charge les macros.
La figure suivante montre les détails de notre simulation HMDK TCO.

Les figures suivantes montrent le rapport TCO.

Résultats de l'engagement de l'outil TCO
Dans cette section, nous partageons certains des résultats d'engagement des clients après avoir utilisé l'outil TCO pendant 1 à 2 semaines. De plus, avec l'outil TCO, nous pouvons refactoriser les clusters Hadoop sur site en clusters EMR en utilisant Amazon S3 comme lac de données. La solution de données moderne de migration vers Amazon EMR offre une évolutivité illimitée avec une efficacité opérationnelle et des économies de coûts.
Le tableau suivant illustre quatre études de cas de certains engagements utilisant l'outil.
| Cas# | Description du cas | Résultat de la mission |
| 1 | Sous la pression de la licence Hadoop, ils ont migré vers AWS en utilisant Amazon EMR et ont utilisé Spark pour remplacer Hive. Ils ont conçu les nouveaux clusters EMR en utilisant une conception équilibrée de clusters transitoires et persistants. | Ils peuvent obtenir des informations sur les tâches grâce à l'outil et concevoir les nouveaux clusters EMR pour répondre aux charges de travail existantes, et s'attendre à réaliser 80 % d'économies de coûts et six fois l'amélioration des performances. |
| 2 | Leur objectif était de migrer un cluster Hadoop avec plus de 1,000 3 nœuds de HDFS vers Amazon SXNUMX et Hive vers Spark, et de reconcevoir le cluster en utilisant une conception équilibrée de clusters transitoires et persistants. | Ils peuvent obtenir des informations sur les tâches et reconcevoir le cluster avec un coût total de possession d'un an de l'architecture de reconception optimisée qui devrait permettre de réaliser des économies de 1 %. |
| 3 | Leur objectif était de migrer vers Hadoop 3.1. Ils ont transféré le travail basé sur la file d'attente Hadoop, qui partageait le même cluster, vers deux clusters transitoires et cinq clusters persistants avec une utilisation optimisée des ressources pour chaque exécution de travail, et ont traité plus rapidement les travaux de longue durée. | Ils peuvent obtenir rapidement les résultats du coût total de possession d'Amazon EMR en 2 semaines. Les clients obtiennent des informations sur leurs charges de travail et leurs tâches de longue durée et font le travail plus rapidement et à moindre coût. |
| 4 | Leur objectif était de migrer de Hive 1 vers Spark et de concevoir un cluster EMR à mise à l'échelle automatique. | Ils peuvent obtenir les résultats du coût total de possession d'Amazon EMR en 1 semaine. Ils s'attendent à voir 75 % d'économies sur les clusters EMR repensés et 10 fois sur l'amélioration des performances. |
Conclusion
Cet article a présenté des cas d'utilisation, des fonctions et des composants de l'outil HMDK TCO. Grâce aux études de cas abordées dans cet article, vous avez découvert des exemples réels de l'utilisation de l'outil et de ses avantages. L'outil HMDK TCO est conçu pour automatiser l'évaluation de la charge de travail du cluster Hadoop source avec un calcul TCO calculé, et cela peut être fait en 2 à 3 semaines au lieu de mois.
De plus en plus de clients adoptent l'outil HMDK TCO pour accélérer leur migration vers Amazon EMR.
Pour plonger dans l'outil HMDK TCO, reportez-vous au prochain article de cette série, Comment l'outil AWS ProServe Hadoop TCO accélère les migrations de charge de travail Hadoop vers Amazon EMR.
À propos des auteurs
 Parc Sungyoul est Senior Practice Manager chez AWS ProServe. Il aide les clients à innover dans leur entreprise avec les services AWS Analytics, IoT et AI/ML. Il est spécialisé dans les services et technologies de mégadonnées et s'intéresse à la création de résultats commerciaux pour les clients.
Parc Sungyoul est Senior Practice Manager chez AWS ProServe. Il aide les clients à innover dans leur entreprise avec les services AWS Analytics, IoT et AI/ML. Il est spécialisé dans les services et technologies de mégadonnées et s'intéresse à la création de résultats commerciaux pour les clients.
 Jiseong Kim est architecte de données senior chez AWS ProServe. Il travaille principalement avec des entreprises clientes pour faciliter la migration et la modernisation des lacs de données, et fournit des conseils et une assistance technique sur des projets de Big Data tels que Hadoop, Spark, l'entreposage de données, le traitement de données en temps réel et l'apprentissage automatique à grande échelle. Il comprend également comment appliquer les technologies pour résoudre les problèmes de Big Data et construire une architecture de données bien conçue.
Jiseong Kim est architecte de données senior chez AWS ProServe. Il travaille principalement avec des entreprises clientes pour faciliter la migration et la modernisation des lacs de données, et fournit des conseils et une assistance technique sur des projets de Big Data tels que Hadoop, Spark, l'entreposage de données, le traitement de données en temps réel et l'apprentissage automatique à grande échelle. Il comprend également comment appliquer les technologies pour résoudre les problèmes de Big Data et construire une architecture de données bien conçue.
 George Zhao est architecte de données senior chez AWS ProServe. C'est un leader expérimenté de l'analyse qui travaille avec les clients d'AWS pour fournir des solutions de données modernes. Il est également un spécialiste du domaine ProServe Amazon EMR qui renseigne les consultants ProServe sur les meilleures pratiques et les kits de livraison pour les migrations Hadoop vers Amazon EMR. Ses domaines d'intérêt sont les lacs de données et la fourniture d'architectures de données modernes dans le cloud.
George Zhao est architecte de données senior chez AWS ProServe. C'est un leader expérimenté de l'analyse qui travaille avec les clients d'AWS pour fournir des solutions de données modernes. Il est également un spécialiste du domaine ProServe Amazon EMR qui renseigne les consultants ProServe sur les meilleures pratiques et les kits de livraison pour les migrations Hadoop vers Amazon EMR. Ses domaines d'intérêt sont les lacs de données et la fourniture d'architectures de données modernes dans le cloud.
 Kalen Zhang était le responsable technique du segment mondial des données et de l'analyse des partenaires chez AWS. En tant que conseillère de confiance en matière de données et d'analyse, elle a organisé des initiatives stratégiques pour la transformation des données, dirigé des programmes de migration et de modernisation des charges de travail de données et d'analyse, et accéléré les parcours de migration des clients avec des partenaires à grande échelle. Elle est spécialisée dans les systèmes distribués, la gestion des données d'entreprise, l'analyse avancée et les initiatives stratégiques à grande échelle.
Kalen Zhang était le responsable technique du segment mondial des données et de l'analyse des partenaires chez AWS. En tant que conseillère de confiance en matière de données et d'analyse, elle a organisé des initiatives stratégiques pour la transformation des données, dirigé des programmes de migration et de modernisation des charges de travail de données et d'analyse, et accéléré les parcours de migration des clients avec des partenaires à grande échelle. Elle est spécialisée dans les systèmes distribués, la gestion des données d'entreprise, l'analyse avancée et les initiatives stratégiques à grande échelle.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/introducing-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/

