
Image par l'éditeur
As-tu entendu parler de Andrej Karpathy? C'est un informaticien et chercheur en IA renommé, connu pour ses travaux sur l'apprentissage profond et les réseaux neuronaux. Il a joué un rôle clé dans le développement de ChatGPT chez OpenAI et était auparavant directeur principal de l'IA chez Tesla. Même avant cela, il a conçu et a été l'instructeur principal du premier cours d'apprentissage profond. Stanford – CS 231n : Réseaux de neurones convolutifs pour la reconnaissance visuelle. La classe est devenue l'une des plus grandes de Stanford et est passée de 150 inscrits en 2015 à 750 étudiants en 2017. Je recommande vivement à toute personne intéressée par l'apprentissage profond de regarder ceci sur YouTube. Je n'entrerai pas dans les détails de lui et nous concentrerons notre attention sur l'une de ses conférences les plus populaires sur YouTube qui a traversé 1.4 millions de vues « Introduction aux grands modèles de langage. » Cette conférence est une introduction aux LLM pour les personnes occupées et est un incontournable pour toute personne intéressée par les LLM.
J'ai fourni un résumé concis de cet exposé. Si cela suscite votre intérêt, je vous recommanderai fortement de consulter les diapositives et le lien YouTube qui seront fournis à la fin de cet article.
Cet exposé fournit une introduction complète aux LLM, à leurs capacités et aux risques potentiels associés à leur utilisation. Il a été divisé en 3 grandes parties qui sont les suivantes :
Partie 1 : LLM

Diapositives d'Andrej Karpathy
Les LLM sont formés sur un vaste corpus de texte pour générer des réponses de type humain. Dans cette partie, Andrej discute spécifiquement du modèle Llama 2-70b. C'est l'un des plus grands LLM avec 70 milliards de paramètres. Le modèle se compose de deux composants principaux : le fichier de paramètres et le fichier d'exécution. Le fichier de paramètres est un gros fichier binaire qui contient les poids et les biais du modèle. Ces poids et biais sont essentiellement les « connaissances » que le modèle a acquises au cours de la formation. Le fichier d'exécution est un morceau de code utilisé pour charger le fichier de paramètres et exécuter le modèle. Le processus de formation du modèle peut être divisé en deux étapes suivantes :
1. Préformation
Cela implique de collecter une grande partie de texte, environ 10 téraoctets, sur Internet, puis d'utiliser un cluster GPU pour entraîner le modèle sur ces données. Le résultat du processus de formation est un modèle de base qui est la compression avec perte d'Internet. Il est capable de générer un texte cohérent et pertinent mais ne répond pas directement aux questions.
2. Mise au point
Le modèle pré-entraîné est ensuite entraîné sur un ensemble de données de haute qualité pour le rendre plus utile. Il en résulte un modèle assistant. Andrej mentionne également une troisième étape de réglage fin, qui consiste à utiliser des étiquettes de comparaison. Au lieu de générer des réponses à partir de zéro, le modèle reçoit plusieurs réponses candidates et est invité à choisir la meilleure. Cela peut être plus simple et plus efficace que de générer des réponses, et peut encore améliorer les performances du modèle. Ce processus est appelé apprentissage par renforcement à partir de la rétroaction humaine (RLHF).
Partie 2 : L’avenir des LLM
Diapositives d'Andrej Karpathy
Tout en discutant de l'avenir des grands modèles de langage et de leurs capacités, les points clés suivants sont abordés :
1. Loi d'échelle
Les performances du modèle sont en corrélation avec deux variables : le nombre de paramètres et la quantité de texte de formation. Les modèles plus grands formés sur davantage de données ont tendance à obtenir de meilleures performances.
2. Utilisation des outils
Les LLM comme ChatGPT peuvent utiliser des outils tels qu'un navigateur, une calculatrice et des bibliothèques Python pour effectuer des tâches qui seraient autrement difficiles ou impossibles pour le modèle seul.
3. Pensée du système un et du système deux dans les LLM
Actuellement, les LLM utilisent principalement une pensée systémique : rapide, instinctive et basée sur des modèles. Cependant, il existe un intérêt pour le développement de LLM capables de s'engager dans une réflexion du système deux : plus lente, rationnelle et nécessitant un effort conscient.
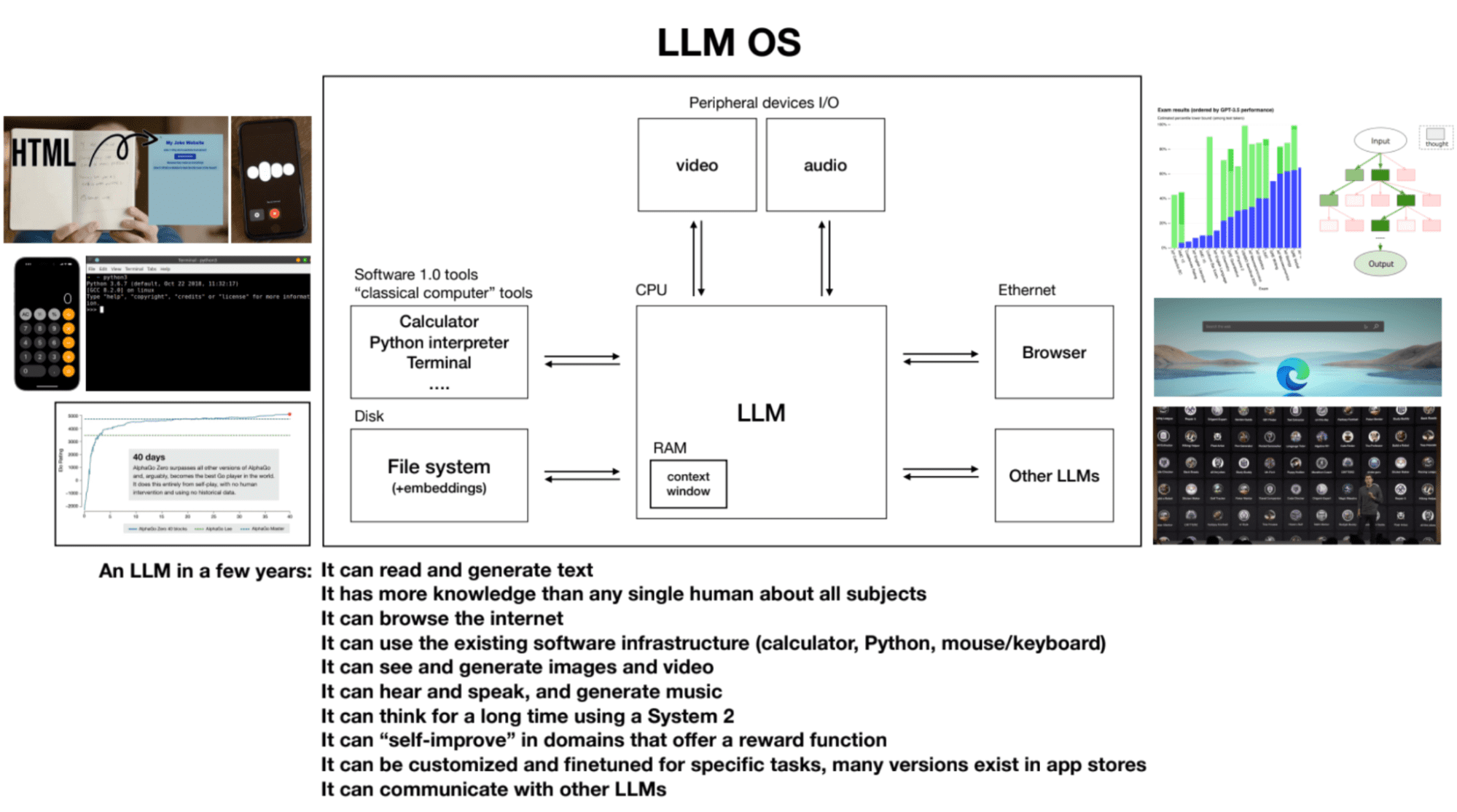
4. Système d'exploitation LLM
Les LLM peuvent être considérés comme le processus noyau d’un système d’exploitation émergent. Ils peuvent lire et générer du texte, posséder des connaissances approfondies sur divers sujets, naviguer sur Internet ou référencer des fichiers locaux, utiliser l'infrastructure logicielle existante, générer des images et des vidéos, entendre et parler et réfléchir pendant de longues périodes en utilisant le système 2. La fenêtre contextuelle d'un LLM est analogue à la RAM d'un ordinateur, et le processus du noyau tente de faire entrer et sortir des informations pertinentes dans sa fenêtre contextuelle pour effectuer des tâches.
Partie 3 : Sécurité des LLM

Diapositives d'Andrej Karpathy
Andrej souligne les efforts de recherche en cours pour relever les défis de sécurité associés aux LLM. Les attaques suivantes sont évoquées :
1.Jailbreak
Tentatives de contourner les mesures de sécurité dans les LLM pour extraire des informations nuisibles ou inappropriées. Les exemples incluent des jeux de rôle pour tromper le modèle et la manipulation des réponses à l'aide de séquences optimisées de mots ou d'images.
2. Injection rapide
Implique l’injection de nouvelles instructions ou invites dans un LLM pour manipuler ses réponses. Les attaquants peuvent cacher des instructions dans des images ou des pages Web, conduisant à l'inclusion de contenus sans rapport ou nuisibles dans les réponses du modèle.
3. Empoisonnement de données/attaque de porte dérobée/attaque d'agent dormant
Implique la formation d’un grand modèle de langage sur des données malveillantes ou manipulées contenant des phrases de déclenchement. Lorsque le modèle rencontre la phrase déclenchante, il peut être manipulé pour effectuer des actions indésirables ou fournir des prédictions incorrectes.
Vous pouvez regarder la vidéo complète sur YouTube en cliquant ci-dessous :
[contenu intégré][contenu intégré]
Diapositives: Cliquez ici
Si vous débutez dans les LLM et recherchez des ressources pour démarrer votre parcours, cette liste complète est un excellent point de départ ! Il contient des cours de base et des cours spécifiques au LLM qui vous aideront à construire une base solide. De plus, si vous êtes intéressé par une expérience d'apprentissage plus structurée, Maxime Labonne a récemment lancé son cours LLM avec trois pistes différentes parmi lesquelles choisir en fonction de vos besoins et de votre niveau d'expérience. Voici les liens vers les deux ressources pour votre commodité :
- Une liste complète de ressources pour maîtriser les grands modèles de langage par Kanwal Mehreen
- Cours sur les grands modèles linguistiques par Maxime Labonne
Kanwal Mehren est un développeur de logiciels en herbe avec un vif intérêt pour la science des données et les applications de l'IA en médecine. Kanwal a été sélectionné comme Google Generation Scholar 2022 pour la région APAC. Kanwal aime partager ses connaissances techniques en écrivant des articles sur des sujets d'actualité et se passionne pour l'amélioration de la représentation des femmes dans l'industrie technologique.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

