Avec l'avènement de l'IA générative, les modèles de base (FM) actuels, tels que les grands modèles de langage (LLM) Claude 2 et Llama 2, peuvent effectuer une gamme de tâches génératives telles que la réponse à des questions, la synthèse et la création de contenu sur des données textuelles. Cependant, les données du monde réel existent sous plusieurs modalités, telles que le texte, les images, la vidéo et l'audio. Prenez par exemple un diaporama PowerPoint. Il peut contenir des informations sous forme de texte ou intégrées dans des graphiques, des tableaux et des images.
Dans cet article, nous présentons une solution qui utilise des FM multimodaux tels que le Intégrations multimodales Amazon Titan modèle et LLaVA1.5 et les services AWS, notamment Socle amazonien ainsi que Amazon Sage Maker pour effectuer des tâches génératives similaires sur des données multimodales.
Vue d'ensemble de la solution
La solution fournit une implémentation permettant de répondre aux questions en utilisant les informations contenues dans le texte et les éléments visuels d'un diaporama. La conception s'appuie sur le concept de Retrieval Augmented Generation (RAG). Traditionnellement, RAG a été associé à des données textuelles pouvant être traitées par les LLM. Dans cet article, nous étendons RAG pour inclure également des images. Cela fournit une puissante capacité de recherche pour extraire du contenu contextuellement pertinent à partir d'éléments visuels tels que des tableaux et des graphiques ainsi que du texte.
Il existe différentes manières de concevoir une solution RAG incluant des images. Nous avons présenté une approche ici et suivrons avec une approche alternative dans le deuxième article de cette série en trois parties.
Cette solution comprend les composants suivants :
- Modèle d'intégration multimodale Amazon Titan – Ce FM est utilisé pour générer des intégrations pour le contenu du diaporama utilisé dans cet article. En tant que modèle multimodal, ce modèle Titan peut traiter du texte, des images ou une combinaison en entrée et générer des intégrations. Le modèle Titan Multimodal Embeddings génère des vecteurs (embeddings) de 1,024 XNUMX dimensions et est accessible via Amazon Bedrock.
- Assistant du Grand Langage et de la Vision (LLaVA) – LLaVA est un modèle multimodal open source pour la compréhension visuelle et linguistique et est utilisé pour interpréter les données des diapositives, y compris les éléments visuels tels que les graphiques et les tableaux. Nous utilisons la version à 7 milliards de paramètres LLaVA1.5-7b dans cette solution.
- Amazon Sage Maker – Le modèle LLaVA est déployé sur un point de terminaison SageMaker à l'aide des services d'hébergement SageMaker, et nous utilisons le point de terminaison résultant pour exécuter des inférences sur le modèle LLaVA. Nous utilisons également des notebooks SageMaker pour orchestrer et démontrer cette solution de bout en bout.
- Amazon OpenSearch sans serveur – OpenSearch Serverless est une configuration sans serveur à la demande pour Service Amazon OpenSearch. Nous utilisons OpenSearch Serverless comme base de données vectorielle pour stocker les intégrations générées par le modèle Titan Multimodal Embeddings. Un index créé dans la collection OpenSearch Serverless sert de magasin de vecteurs pour notre solution RAG.
- Ingestion Amazon OpenSearch (OSI) – OSI est un collecteur de données sans serveur entièrement géré qui fournit des données aux domaines OpenSearch Service et aux collections OpenSearch Serverless. Dans cet article, nous utilisons un pipeline OSI pour fournir des données au magasin de vecteurs OpenSearch Serverless.
Architecture de la solution
La conception de la solution se compose de deux parties : l'ingestion et l'interaction de l'utilisateur. Lors de l'ingestion, nous traitons le diaporama d'entrée en convertissant chaque diapositive en image, générons des intégrations pour ces images, puis remplissons le magasin de données vectorielles. Ces étapes sont terminées avant les étapes d'interaction avec l'utilisateur.
Dans la phase d'interaction de l'utilisateur, une question de l'utilisateur est convertie en intégrations et une recherche de similarité est exécutée sur la base de données vectorielles pour trouver une diapositive susceptible de contenir des réponses à la question de l'utilisateur. Nous fournissons ensuite cette diapositive (sous forme de fichier image) au modèle LLaVA et à la question de l'utilisateur comme invite pour générer une réponse à la requête. Tout le code de cet article est disponible dans le GitHub dépôt.
Le diagramme suivant illustre l’architecture d’ingestion.
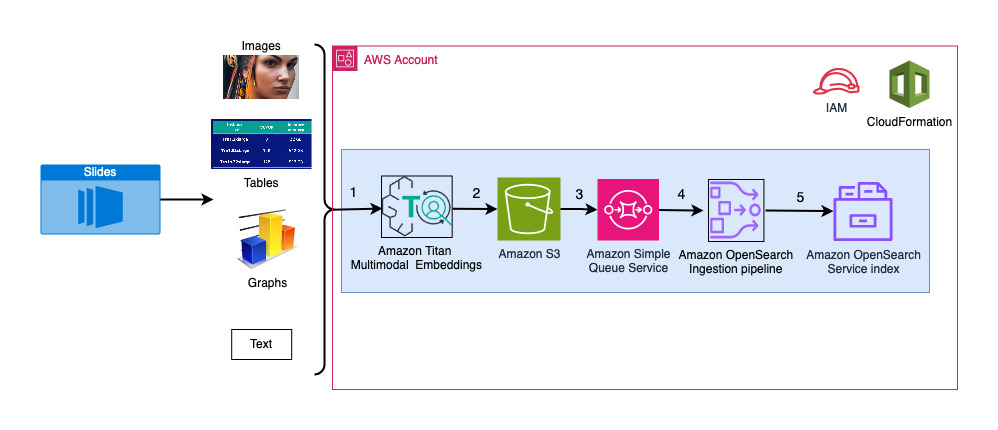
Les étapes du flux de travail sont les suivantes :
- Les diapositives sont converties en fichiers image (une par diapositive) au format JPG et transmises au modèle Titan Multimodal Embeddings pour générer des intégrations. Dans cet article, nous utilisons le diaporama intitulé Former et déployer Stable Diffusion à l'aide d'AWS Trainium et AWS Inferentia du sommet AWS à Toronto, en juin 2023, pour démontrer la solution. La banque d'échantillons comporte 31 diapositives. Nous générons donc 31 ensembles d'intégrations vectorielles, chacune avec 1,024 XNUMX dimensions. Nous ajoutons des champs de métadonnées supplémentaires à ces intégrations vectorielles générées et créons un fichier JSON. Ces champs de métadonnées supplémentaires peuvent être utilisés pour effectuer des requêtes de recherche enrichies à l'aide des puissantes capacités de recherche d'OpenSearch.
- Les intégrations générées sont regroupées dans un seul fichier JSON qui est téléchargé sur Service de stockage simple Amazon (Amazon S3).
- Via Notifications d'événements Amazon S3, un événement est mis dans un Service Amazon Simple Queue (Amazon SQS) file d'attente.
- Cet événement dans la file d'attente SQS agit comme un déclencheur pour exécuter le pipeline OSI, qui à son tour ingère les données (fichier JSON) sous forme de documents dans l'index OpenSearch Serverless. Notez que l'index OpenSearch Serverless est configuré comme récepteur pour ce pipeline et est créé dans le cadre de la collection OpenSearch Serverless.
Le diagramme suivant illustre l'architecture d'interaction utilisateur.
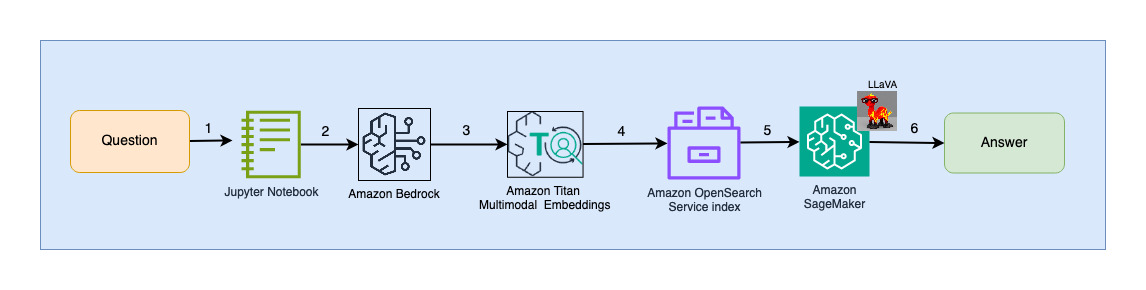
Les étapes du flux de travail sont les suivantes :
- Un utilisateur soumet une question relative au diaporama qui a été ingéré.
- L'entrée de l'utilisateur est convertie en intégrations à l'aide du modèle Titan Multimodal Embeddings accessible via Amazon Bedrock. Une recherche vectorielle OpenSearch est effectuée à l’aide de ces intégrations. Nous effectuons une recherche du k-voisin le plus proche (k=1) pour récupérer l'intégration la plus pertinente correspondant à la requête de l'utilisateur. Le réglage k=1 récupère la diapositive la plus pertinente par rapport à la question de l'utilisateur.
- Les métadonnées de la réponse d'OpenSearch Serverless contiennent un chemin vers l'image correspondant à la diapositive la plus pertinente.
- Une invite est créée en combinant la question de l'utilisateur et le chemin de l'image et fournie à LLaVA hébergée sur SageMaker. Le modèle LLaVA est capable de comprendre la question de l'utilisateur et d'y répondre en examinant les données de l'image.
- Le résultat de cette inférence est renvoyé à l'utilisateur.
Ces étapes sont abordées en détail dans les sections suivantes. Voir le Résultats section pour les captures d’écran et les détails sur la sortie.
Pré-requis
Pour mettre en œuvre la solution fournie dans cet article, vous devez disposer d'un Compte AWS et familiarité avec FMs, Amazon Bedrock, SageMaker et OpenSearch Service.
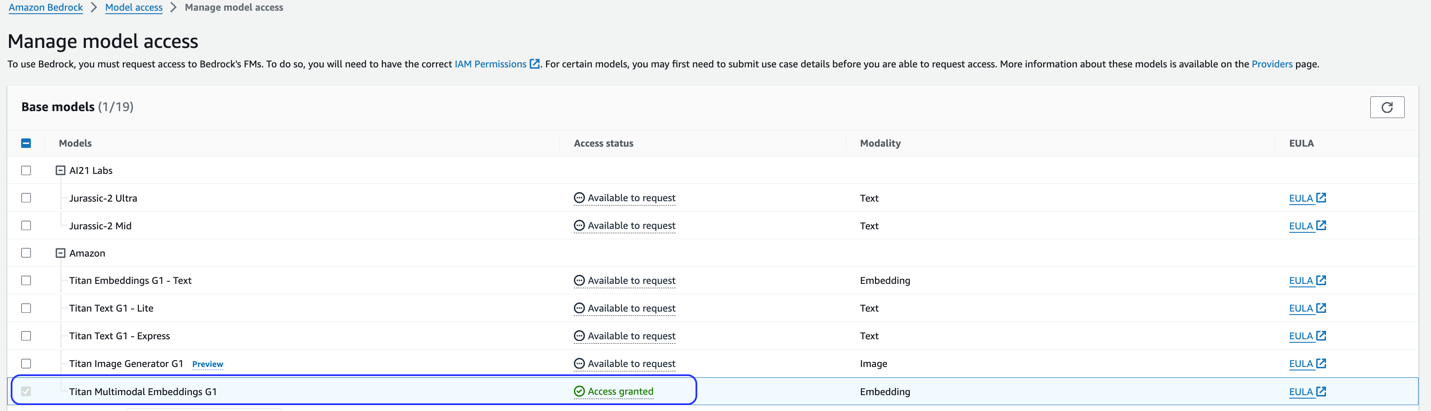
Cette solution utilise le modèle Titan Multimodal Embeddings. Assurez-vous que ce modèle est activé pour une utilisation dans Amazon Bedrock. Sur la console Amazon Bedrock, choisissez Accès au modèle dans le volet de navigation. Si Titan Multimodal Embeddings est activé, l'état d'accès indiquera Accès accordé.
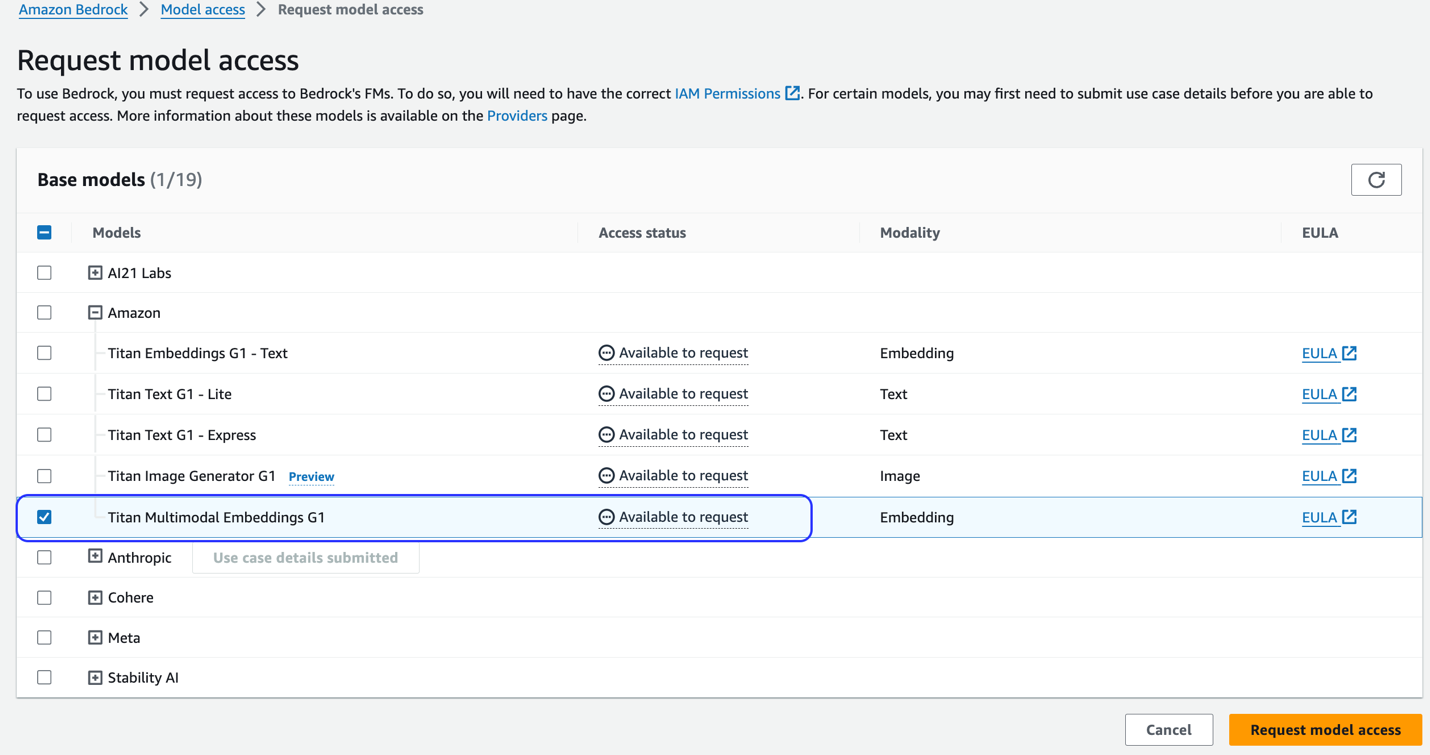
Si le modèle n'est pas disponible, activez l'accès au modèle en choisissant Gérer l'accès au modèle, En sélectionnant Intégrations multimodales Titan G1et choisir Demander l'accès au modèle. Le modèle est activé pour une utilisation immédiate.
Utilisez un modèle AWS CloudFormation pour créer la pile de solutions
Utilisez l'un des éléments suivants AWS CloudFormation modèles (selon votre région) pour lancer les ressources de la solution.
| Région AWS | Lien |
|---|---|
us-east-1 |
|
us-west-2 |
Une fois la pile créée avec succès, accédez au dossier de la pile. Sortie sur la console AWS CloudFormation et notez la valeur de MultimodalCollectionEndpoint, que nous utilisons dans les étapes suivantes.
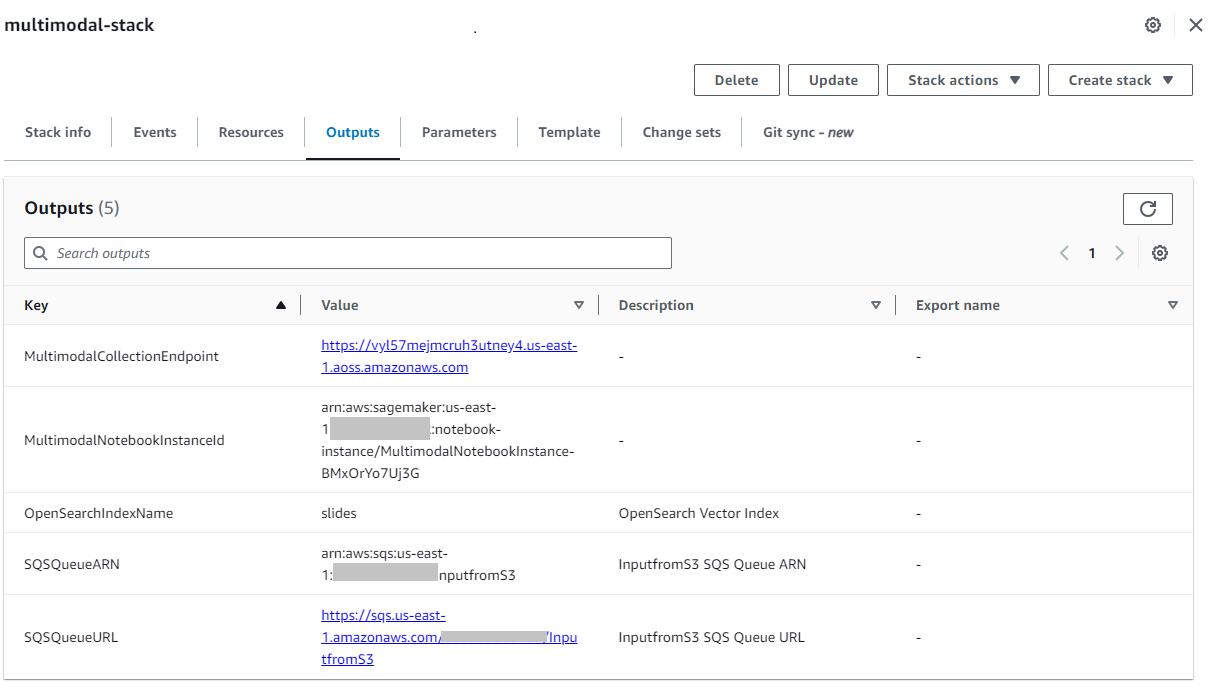
Le modèle CloudFormation crée les ressources suivantes :
- Rôles IAM - Ce qui suit Gestion des identités et des accès AWS (IAM) sont créés. Mettez à jour ces rôles pour postuler autorisations de moindre privilège.
SMExecutionRoleavec accès complet à Amazon S3, SageMaker, OpenSearch Service et Bedrock.OSPipelineExecutionRoleavec accès à des actions Amazon SQS et OSI spécifiques.
- Bloc-notes SageMaker – Tout le code de cet article est exécuté via ce notebook.
- Collection sans serveur OpenSearch – Il s’agit de la base de données vectorielles pour stocker et récupérer les intégrations.
- Pipeline OSI – Il s’agit du pipeline permettant d’ingérer des données dans OpenSearch Serverless.
- Seau S3 – Toutes les données de cette publication sont stockées dans ce compartiment.
- file d'attente SQS – Les événements déclenchant l'exécution du pipeline OSI sont placés dans cette file d'attente.
Le modèle CloudFormation configure le pipeline OSI avec le traitement Amazon S3 et Amazon SQS comme source et un index OpenSearch Serverless comme récepteur. Tous les objets créés dans le compartiment S3 spécifié et le préfixe (multimodal/osi-embeddings-json) déclenchera des notifications SQS, qui sont utilisées par le pipeline OSI pour ingérer des données dans OpenSearch Serverless.
Le modèle CloudFormation crée également réseau et, chiffrementet accès aux données politiques requises pour la collection OpenSearch Serverless. Mettez à jour ces stratégies pour appliquer les autorisations de moindre privilège.
Notez que le nom du modèle CloudFormation est référencé dans les blocs-notes SageMaker. Si le nom du modèle par défaut est modifié, assurez-vous de le mettre à jour dans globals.py
Testez la solution
Une fois les étapes préalables terminées et la pile CloudFormation créée avec succès, vous êtes maintenant prêt à tester la solution :
- Sur la console SageMaker, choisissez Carnets dans le volet de navigation.
- Sélectionnez le
MultimodalNotebookInstanceinstance de bloc-notes et choisissez Ouvrez JupyterLab.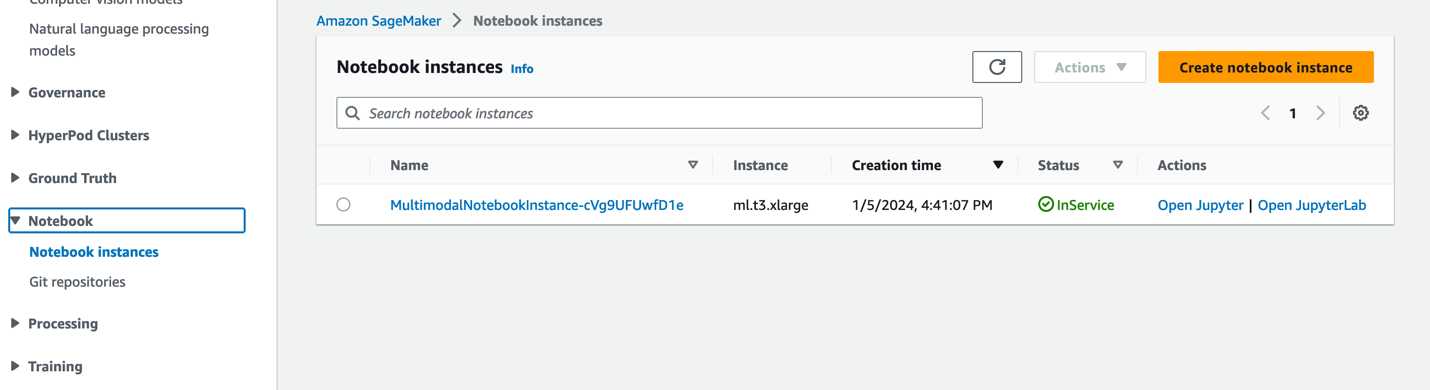
- In Navigateur de fichiers, accédez au dossier notebooks pour voir les notebooks et les fichiers de support.
Les cahiers sont numérotés dans l'ordre dans lequel ils sont exécutés. Les instructions et les commentaires dans chaque bloc-notes décrivent les actions effectuées par ce bloc-notes. Nous exécutons ces cahiers un par un.
- Selectionnez 0_deploy_llava.ipynb pour l'ouvrir dans JupyterLab.
- Sur le Courir menu, choisissez Exécuter toutes les cellules pour exécuter le code dans ce notebook.
Ce notebook déploie le modèle LLaVA-v1.5-7B sur un point de terminaison SageMaker. Dans ce notebook, nous téléchargeons le modèle LLaVA-v1.5-7B depuis HuggingFace Hub, remplaçons le script inference.py par llava_inference.pyet créez un fichier model.tar.gz pour ce modèle. Le fichier model.tar.gz est téléchargé sur Amazon S3 et utilisé pour déployer le modèle sur le point de terminaison SageMaker. Le llava_inference.py Le script contient du code supplémentaire pour permettre de lire un fichier image à partir d'Amazon S3 et d'exécuter une inférence dessus.
- Selectionnez 1_data_prep.ipynb pour l'ouvrir dans JupyterLab.
- Sur le Courir menu, choisissez Exécuter toutes les cellules pour exécuter le code dans ce notebook.
Ce bloc-notes télécharge le jeu de diapositives, convertit chaque diapositive au format de fichier JPG et les télécharge dans le compartiment S3 utilisé pour cet article.
- Selectionnez 2_data_ingestion.ipynb pour l'ouvrir dans JupyterLab.
- Sur le Courir menu, choisissez Exécuter toutes les cellules pour exécuter le code dans ce notebook.
Nous faisons ce qui suit dans ce cahier :
- Nous créons un index dans la collection OpenSearch Serverless. Cet index stocke les données d'intégration pour le diaporama. Voir le code suivant :
- Nous utilisons le modèle Titan Multimodal Embeddings pour convertir les images JPG créées dans le bloc-notes précédent en intégrations vectorielles. Ces intégrations et métadonnées supplémentaires (telles que le chemin S3 du fichier image) sont stockées dans un fichier JSON et téléchargées sur Amazon S3. Notez qu'un seul fichier JSON est créé, qui contient les documents pour toutes les diapositives (images) converties en intégrations. L'extrait de code suivant montre comment une image (sous la forme d'une chaîne codée en Base64) est convertie en intégrations :
- Cette action déclenche le pipeline d'ingestion OpenSearch, qui traite le fichier et l'ingère dans l'index OpenSearch Serverless. Voici un exemple du fichier JSON créé. (Un vecteur à quatre dimensions est affiché dans l'exemple de code. Le modèle Titan Multimodal Embeddings génère 1,024 XNUMX dimensions.)
- Selectionnez 3_rag_inference.ipynb pour l'ouvrir dans JupyterLab.
- Sur le Courir menu, choisissez Exécuter toutes les cellules pour exécuter le code dans ce notebook.
Ce notebook implémente la solution RAG : nous convertissons la question de l'utilisateur en intégrations, trouvons une image similaire (diapositive) dans la base de données vectorielles et fournissons l'image récupérée à LLaVA pour générer une réponse à la question de l'utilisateur. Nous utilisons le modèle d'invite suivant :
L'extrait de code suivant fournit le workflow RAG :
Résultats
Ce qui suit est une compilation de quelques questions et réponses d'utilisateurs générées par notre implémentation. Le Question La colonne capture la question de l'utilisateur et la Compagnie de Solution column est la réponse textuelle générée par LLaVA. Image(s) est la correspondance de diapositive k-la plus proche (k=1) renvoyée par la recherche vectorielle OpenSearch Serverless. Cette diapositive est interprétée par LLaVA pour apporter la réponse.
Résultats RAG multimodaux
| Question | Compagnie de Solution | Image(s) |
|---|---|---|
| Comment Inf2 se compare-t-il en termes de performances à des instances EC2 comparables ? J'ai besoin de chiffres. | Selon le diaporama, les instances Inf2 d'AWS Inferentia2 offrent un débit jusqu'à 4 fois plus élevé et une latence 10 fois inférieure par rapport aux instances EC2 comparables. |  |
| Selon le volant d'inertie AI/ML, que fournissent les services AWS AI/ML ? | Les services AWS AI/ML offrent de meilleures capacités $/perfer, de nouvelles capacités et un investissement dans l'innovation. | 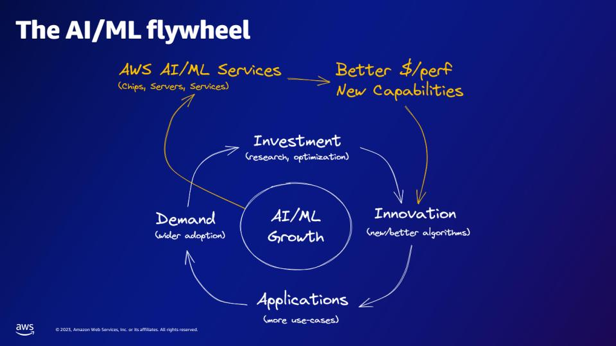 |
| Par rapport au GPT-2, combien de paramètres supplémentaires le GPT-3 possède-t-il ? Quelle est la différence numérique entre la taille des paramètres de GPT-2 et GPT-3 ? | Selon la diapositive, GPT-3 possède 175 milliards de paramètres, tandis que GPT-2 en possède 1.5 milliard. La différence numérique entre la taille des paramètres de GPT-2 et GPT-3 est de 173.5 milliards. | 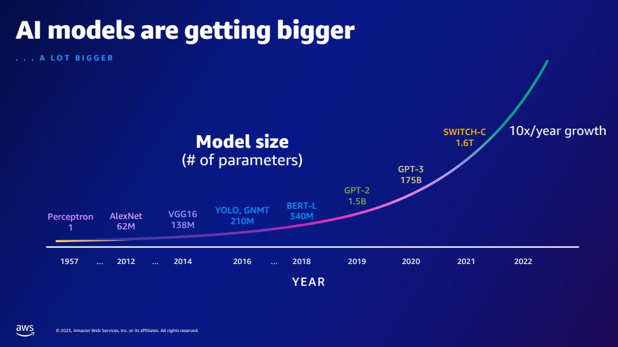 |
| Que sont les quarks en physique des particules ? | Je n'ai pas trouvé la réponse à cette question dans le diaporama. |  |
N'hésitez pas à étendre cette solution à vos diaporamas. Mettez simplement à jour la variable SLIDE_DECK dans globals.py avec une URL vers votre diaporama et exécutez les étapes d'ingestion détaillées dans la section précédente.
Conseil
Vous pouvez utiliser les tableaux de bord OpenSearch pour interagir avec l'API OpenSearch afin d'exécuter des tests rapides sur votre index et vos données ingérées. La capture d'écran suivante montre un exemple GET de tableau de bord OpenSearch.
Nettoyer
Pour éviter de devoir payer des frais futurs, supprimez les ressources que vous avez créées. Vous pouvez le faire en supprimant la pile via la console CloudFormation.

De plus, supprimez le point de terminaison d’inférence SageMaker créé pour l’inférence LLaVA. Vous pouvez le faire en décommentant l'étape de nettoyage dans 3_rag_inference.ipynb et en exécutant la cellule, ou en supprimant le point de terminaison via la console SageMaker : choisissez Inférence ainsi que Endpoints dans le volet de navigation, puis sélectionnez le point de terminaison et supprimez-le.
Conclusion
Les entreprises génèrent constamment du nouveau contenu et les présentations de diapositives constituent un mécanisme couramment utilisé pour partager et diffuser des informations en interne avec l'organisation et en externe avec les clients ou lors de conférences. Au fil du temps, des informations riches peuvent rester enfouies et cachées dans des modalités non textuelles comme les graphiques et les tableaux de ces diaporamas. Vous pouvez utiliser cette solution et la puissance des FM multimodaux tels que le modèle Titan Multimodal Embeddings et LLaVA pour découvrir de nouvelles informations ou découvrir de nouvelles perspectives sur le contenu des présentations de diapositives.
Nous vous encourageons à en savoir plus en explorant Amazon SageMaker JumpStart, Modèles Amazon Titan, Amazon Bedrock et OpenSearch Service, et créer une solution à l'aide de l'exemple d'implémentation fourni dans cet article.
Recherchez deux articles supplémentaires dans le cadre de cette série. La partie 2 couvre une autre approche que vous pourriez adopter pour parler à votre diaporama. Cette approche génère et stocke des inférences LLaVA et utilise ces inférences stockées pour répondre aux requêtes des utilisateurs. La troisième partie compare les deux approches.
À propos des auteurs
 Amit Arora est un architecte spécialiste de l'IA et du ML chez Amazon Web Services, aidant les entreprises clientes à utiliser des services d'apprentissage automatique basés sur le cloud pour faire évoluer rapidement leurs innovations. Il est également chargé de cours auxiliaire dans le cadre du programme de science et d'analyse des données MS à l'Université de Georgetown à Washington DC.
Amit Arora est un architecte spécialiste de l'IA et du ML chez Amazon Web Services, aidant les entreprises clientes à utiliser des services d'apprentissage automatique basés sur le cloud pour faire évoluer rapidement leurs innovations. Il est également chargé de cours auxiliaire dans le cadre du programme de science et d'analyse des données MS à l'Université de Georgetown à Washington DC.
 Manju Prasad est architecte de solutions senior au sein des comptes stratégiques chez Amazon Web Services. Elle se concentre sur la fourniture de conseils techniques dans une variété de domaines, y compris l'IA/ML à un client de renom en M&E. Avant de rejoindre AWS, elle a conçu et construit des solutions pour des entreprises du secteur des services financiers ainsi que pour une startup.
Manju Prasad est architecte de solutions senior au sein des comptes stratégiques chez Amazon Web Services. Elle se concentre sur la fourniture de conseils techniques dans une variété de domaines, y compris l'IA/ML à un client de renom en M&E. Avant de rejoindre AWS, elle a conçu et construit des solutions pour des entreprises du secteur des services financiers ainsi que pour une startup.
 Archana Inapudi est un architecte de solutions senior chez AWS qui soutient les clients stratégiques. Elle a plus d'une décennie d'expérience en aidant les clients à concevoir et à créer des solutions d'analyse de données et de bases de données. Elle est passionnée par l'utilisation de la technologie pour apporter de la valeur aux clients et obtenir des résultats commerciaux.
Archana Inapudi est un architecte de solutions senior chez AWS qui soutient les clients stratégiques. Elle a plus d'une décennie d'expérience en aidant les clients à concevoir et à créer des solutions d'analyse de données et de bases de données. Elle est passionnée par l'utilisation de la technologie pour apporter de la valeur aux clients et obtenir des résultats commerciaux.
 Antara Raïsa est un architecte de solutions IA et ML chez Amazon Web Services qui soutient des clients stratégiques basés à Dallas, au Texas. Elle a également une expérience de travail avec de grandes entreprises partenaires chez AWS, où elle a travaillé en tant qu'architecte de solutions de réussite partenaire pour des clients natifs du numérique.
Antara Raïsa est un architecte de solutions IA et ML chez Amazon Web Services qui soutient des clients stratégiques basés à Dallas, au Texas. Elle a également une expérience de travail avec de grandes entreprises partenaires chez AWS, où elle a travaillé en tant qu'architecte de solutions de réussite partenaire pour des clients natifs du numérique.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/

