Des politiques de contrôle efficaces permettent aux entreprises industrielles d’augmenter leur rentabilité en maximisant la productivité tout en réduisant les temps d’arrêt imprévus et la consommation d’énergie. Trouver des politiques de contrôle optimales est une tâche complexe car les systèmes physiques, tels que les réacteurs chimiques et les éoliennes, sont souvent difficiles à modéliser et parce que la dérive dans la dynamique des processus peut entraîner une détérioration des performances au fil du temps. L'apprentissage par renforcement hors ligne est une stratégie de contrôle qui permet aux entreprises industrielles d'élaborer des politiques de contrôle entièrement à partir de données historiques sans avoir besoin d'un modèle de processus explicite. Cette approche ne nécessite pas d'interaction directe avec le processus lors d'une étape d'exploration, ce qui supprime l'un des obstacles à l'adoption de l'apprentissage par renforcement dans les applications critiques pour la sécurité. Dans cet article, nous allons construire une solution de bout en bout pour trouver des politiques de contrôle optimales en utilisant uniquement les données historiques sur Amazon Sage Maker en utilisant celui de Ray RLlib bibliothèque. Pour en savoir plus sur l'apprentissage par renforcement, voir Utilisez l'apprentissage par renforcement avec Amazon SageMaker.
Les cas d'utilisation
Le contrôle industriel implique la gestion de systèmes complexes, tels que les lignes de fabrication, les réseaux énergétiques et les usines chimiques, pour garantir un fonctionnement efficace et fiable. De nombreuses stratégies de contrôle traditionnelles reposent sur des règles et des modèles prédéfinis, qui nécessitent souvent une optimisation manuelle. Il est courant dans certaines industries de surveiller les performances et d'ajuster la politique de contrôle lorsque, par exemple, l'équipement commence à se dégrader ou que les conditions environnementales changent. Le réajustement peut prendre des semaines et nécessiter l’injection d’excitations externes dans le système pour enregistrer sa réponse selon une approche par essais et erreurs.
L'apprentissage par renforcement est apparu comme un nouveau paradigme dans le contrôle des processus permettant d'apprendre des politiques de contrôle optimales en interagissant avec l'environnement. Ce processus nécessite de décomposer les données en trois catégories : 1) les mesures disponibles à partir du système physique, 2) l'ensemble des actions qui peuvent être prises sur le système et 3) une mesure numérique (récompense) des performances de l'équipement. Une politique est formée pour trouver l’action, lors d’une observation donnée, qui est susceptible de produire les récompenses futures les plus élevées.
Dans l'apprentissage par renforcement hors ligne, il est possible de former une politique sur des données historiques avant de la déployer en production. L'algorithme entraîné dans cet article de blog s'appelle «Apprentissage Q conservateur» (CQL). CQL contient un modèle « acteur » et un modèle « critique » et est conçu pour prédire de manière prudente ses propres performances après avoir pris une action recommandée. Dans cet article, le processus est démontré avec un problème de contrôle de poteaux de chariot illustratif. L'objectif est de former un agent à équilibrer un poteau sur un chariot tout en déplaçant simultanément le chariot vers un emplacement désigné. La procédure de formation utilise les données hors ligne, permettant à l'agent d'apprendre à partir d'informations préexistantes. Cette étude de cas sur un poteau de chariot démontre le processus de formation et son efficacité dans des applications potentielles du monde réel.
Vue d'ensemble de la solution
La solution présentée dans cet article automatise le déploiement d'un flux de travail de bout en bout pour l'apprentissage par renforcement hors ligne avec des données historiques. Le diagramme suivant décrit l'architecture utilisée dans ce flux de travail. Les données de mesure sont produites en périphérie par un équipement industriel (ici simulé par un AWS Lambda fonction). Les données sont mises dans un Amazon Kinésis Data Firehose, qui les stocke dans Service de stockage simple Amazon (Amazon S3). Amazon S3 est une solution de stockage durable, performante et peu coûteuse qui vous permet de transmettre de gros volumes de données à un processus de formation en machine learning.
Colle AWS catalogue les données et les rend interrogeables à l'aide Amazone Athéna. Athena transforme les données de mesure sous une forme qu'un algorithme d'apprentissage par renforcement peut ingérer, puis les décharge dans Amazon S3. Amazon SageMaker charge ces données dans une tâche de formation et produit un modèle entraîné. SageMaker sert ensuite ce modèle dans un point de terminaison SageMaker. L'équipement industriel peut ensuite interroger ce point final pour recevoir des recommandations d'action.
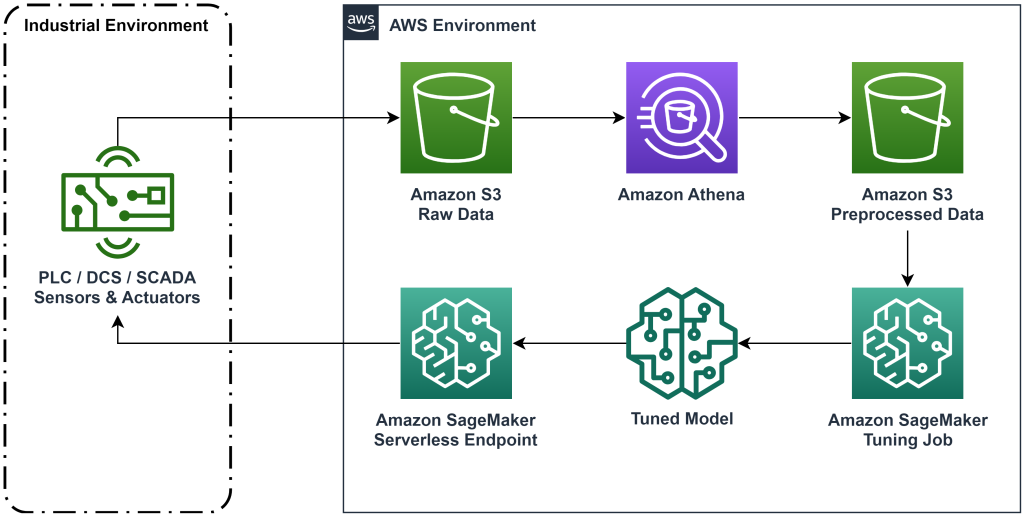
Figure 1 : Diagramme d'architecture montrant le flux de travail d'apprentissage par renforcement de bout en bout.
Dans cet article, nous décomposerons le flux de travail en les étapes suivantes :
- Formulez le problème. Décidez quelles actions peuvent être entreprises, sur quelles mesures fonder des recommandations et déterminez numériquement la performance de chaque action.
- Préparez les données. Transformez le tableau de mesures dans un format que l'algorithme d'apprentissage automatique peut utiliser.
- Entraînez l’algorithme sur ces données.
- Sélectionnez la meilleure séance d'entraînement en fonction des mesures d'entraînement.
- Déployez le modèle sur un point de terminaison SageMaker.
- Évaluer les performances du modèle en production.
Pré-requis
Pour effectuer cette procédure pas à pas, vous devez disposer d'un Compte AWS et une interface de ligne de commande avec AWS SAM installé. Suivez ces étapes pour déployer le modèle AWS SAM afin d'exécuter ce flux de travail et générer des données de formation :
- Téléchargez le référentiel de code avec la commande
- Changez de répertoire pour le dépôt :
- Construisez le dépôt :
- Déployer le dépôt
- Utilisez les commandes suivantes pour appeler un script bash, qui génère des données fictives à l'aide d'une fonction AWS Lambda.
sudo yum install jqcd utilssh generate_mock_data.sh
Procédure pas à pas de la solution
Formuler le problème
Notre système dans cet article de blog est un chariot avec un poteau équilibré sur le dessus. Le système fonctionne bien lorsque le poteau est droit et que la position du chariot est proche de la position de l'objectif. Dans l'étape préalable, nous avons généré des données historiques à partir de ce système.
Le tableau suivant présente les données historiques collectées à partir du système.
| Position du panier | Vitesse du chariot | Angle des pôles | Vitesse angulaire du pôle | Position de but | Force externe | Récompenser | Temps |
| 0.53 | - 0.79 | - 0.08 | 0.16 | 0.50 | - 0.04 | 11.5 | 5: 37: 54 PM |
| 0.51 | - 0.82 | - 0.07 | 0.17 | 0.50 | - 0.04 | 11.9 | 5: 37: 55 PM |
| 0.50 | - 0.84 | - 0.07 | 0.18 | 0.50 | - 0.03 | 12.2 | 5: 37: 56 PM |
| 0.48 | - 0.85 | - 0.07 | 0.18 | 0.50 | - 0.03 | 10.5 | 5: 37: 57 PM |
| 0.46 | - 0.87 | - 0.06 | 0.19 | 0.50 | - 0.03 | 10.3 | 5: 37: 58 PM |
Vous pouvez interroger les informations système historiques à l'aide d'Amazon Athena avec la requête suivante :
L'état de ce système est défini par la position du chariot, la vitesse du chariot, l'angle du poteau, la vitesse angulaire du poteau et la position de l'objectif. L'action entreprise à chaque pas de temps est la force externe appliquée au chariot. L'environnement simulé génère une valeur de récompense qui est plus élevée lorsque le chariot est plus proche de la position cible et que le poteau est plus droit.
Préparer les données
Pour présenter les informations système au modèle d'apprentissage par renforcement, transformez-les en objets JSON avec des clés qui catégorisent les valeurs en catégories d'état (également appelées observations), d'action et de récompense. Stockez ces objets dans Amazon S3. Voici un exemple d'objets JSON produits à partir des pas de temps du tableau précédent.
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
La pile AWS CloudFormation contient une sortie appelée AthenaQueryToCreateJsonFormatedData. Exécutez cette requête dans Amazon Athena pour effectuer la transformation et stocker les objets JSON dans Amazon S3. L'algorithme d'apprentissage par renforcement utilise la structure de ces objets JSON pour comprendre sur quelles valeurs baser les recommandations et le résultat des actions entreprises dans les données historiques.
Agent ferroviaire
Nous pouvons maintenant commencer un travail de formation pour produire un modèle de recommandation d'action entraînée. Amazon SageMaker vous permet de lancer rapidement plusieurs tâches de formation pour voir comment diverses configurations affectent le modèle formé résultant. Appelez la fonction Lambda nommée TuningJobLauncherFunction pour démarrer un travail de réglage d'hyperparamètres qui expérimente quatre ensembles différents d'hyperparamètres lors de l'entraînement de l'algorithme.
Sélectionnez la meilleure course d'entraînement
Pour déterminer lequel des emplois de formation a produit le meilleur modèle, examinez les courbes de perte produites au cours de la formation. Le modèle critique de CQL estime la performance de l'acteur (appelée valeur Q) après avoir effectué une action recommandée. Une partie de la fonction de perte critique inclut l’erreur de différence temporelle. Cette métrique mesure la précision de la valeur Q du critique. Recherchez les cycles d’entraînement avec une valeur Q moyenne élevée et une faible erreur de différence temporelle. Ce papier, Un flux de travail pour l'apprentissage par renforcement robotique hors ligne et sans modèle, explique comment sélectionner la meilleure course d'entraînement. Le référentiel de code contient un fichier, /utils/investigate_training.py, qui crée une figure HTML décrivant la dernière tâche de formation. Exécutez ce fichier et utilisez le résultat pour choisir la meilleure exécution d'entraînement.
Nous pouvons utiliser la valeur moyenne de Q pour prédire les performances du modèle entraîné. Les valeurs Q sont entraînées pour prédire de manière conservatrice la somme des valeurs de récompense futures actualisées. Pour les processus de longue durée, nous pouvons convertir ce nombre en une moyenne pondérée exponentiellement en multipliant la valeur Q par (1 - « taux d'actualisation »). La meilleure séance d'entraînement de cet ensemble a atteint une valeur Q moyenne de 539. Notre taux d'actualisation est de 0.99, le modèle prévoit donc une récompense moyenne d'au moins 5.39 par pas de temps. Vous pouvez comparer cette valeur aux performances historiques du système pour savoir si le nouveau modèle surpassera la stratégie de contrôle historique. Dans cette expérience, la récompense moyenne des données historiques par pas de temps était de 4.3, de sorte que le modèle CQL prédit des performances 25 % supérieures à celles obtenues historiquement par le système.
Déployer le modèle
Les points de terminaison Amazon SageMaker vous permettent de diffuser des modèles d'apprentissage automatique de plusieurs manières différentes pour répondre à une variété de cas d'utilisation. Dans cet article, nous utiliserons le type de point de terminaison sans serveur afin que notre point de terminaison évolue automatiquement en fonction de la demande, et nous ne payons pour l'utilisation du calcul que lorsque le point de terminaison génère une inférence. Pour déployer un point de terminaison sans serveur, incluez un ProductionVariantServerlessConfig dans l' variante de production du SageMaker configuration du point de terminaison. L'extrait de code suivant montre comment le point de terminaison sans serveur dans cet exemple est déployé à l'aide du kit de développement logiciel Amazon SageMaker pour Python. Recherchez l'exemple de code utilisé pour déployer le modèle sur sagemaker-hors ligne-renforcement-learning-ray-cql.
Les fichiers du modèle entraîné se trouvent au niveau des artefacts du modèle S3 pour chaque exécution d'entraînement. Pour déployer le modèle d'apprentissage automatique, recherchez les fichiers de modèle de la meilleure exécution d'entraînement et appelez la fonction Lambda nommée «ModelDeployerFunction" avec un événement qui contient ces données de modèle. La fonction Lambda lancera un point de terminaison sans serveur SageMaker pour servir le modèle formé. Exemple d'événement à utiliser lors de l'appel du "ModelDeployerFunction"
Évaluer les performances du modèle formé
Il est temps de voir comment notre modèle formé se comporte en production ! Pour vérifier les performances du nouveau modèle, appelez la fonction Lambda nommée «RunPhysicsSimulationFunction" avec le nom du point de terminaison SageMaker dans l'événement. Cela exécutera la simulation en utilisant les actions recommandées par le point de terminaison. Exemple d'événement à utiliser lors de l'appel du RunPhysicsSimulatorFunction:
Utilisez la requête Athena suivante pour comparer les performances du modèle entraîné avec les performances historiques du système.
| Origine de l'action | Récompense moyenne par pas de temps |
trained_model |
10.8 |
historic_data |
4.3 |
Les animations suivantes montrent la différence entre un exemple d'épisode issu des données d'entraînement et un épisode dans lequel le modèle entraîné a été utilisé pour choisir l'action à entreprendre. Dans les animations, la boîte bleue est le chariot, la ligne bleue est le poteau et le rectangle vert est l'emplacement du but. La flèche rouge montre la force appliquée au chariot à chaque pas de temps. La flèche rouge dans les données d'entraînement va et vient un peu, car les données ont été générées à l'aide de 50 % d'actions expertes et de 50 % d'actions aléatoires. Le modèle formé a appris une politique de contrôle qui déplace le chariot rapidement vers la position cible, tout en maintenant la stabilité, entièrement en observant des démonstrations non expertes.
 |
 |
Nettoyer
Pour supprimer les ressources utilisées dans ce flux de travail, accédez à la section ressources de la pile Amazon CloudFormation et supprimez les compartiments S3 et les rôles IAM. Supprimez ensuite la pile CloudFormation elle-même.
Conclusion
L'apprentissage par renforcement hors ligne peut aider les entreprises industrielles à automatiser la recherche de politiques optimales sans compromettre la sécurité en utilisant des données historiques. Pour mettre en œuvre cette approche dans vos opérations, commencez par identifier les mesures qui composent un système déterminé par l'état, les actions que vous pouvez contrôler et les mesures qui indiquent les performances souhaitées. Ensuite, accédez ce dépôt GitHub pour la mise en œuvre d'une solution automatique de bout en bout utilisant Ray et Amazon SageMaker.
L'article ne fait qu'effleurer la surface de ce que vous pouvez faire avec Amazon SageMaker RL. Essayez-le et envoyez-nous vos commentaires, soit dans le Forum de discussion Amazon SageMaker ou via vos contacts AWS habituels.
À propos des auteurs
 Walt Mayfield est architecte de solutions chez AWS et aide les entreprises énergétiques à fonctionner de manière plus sûre et plus efficace. Avant de rejoindre AWS, Walt a travaillé comme ingénieur des opérations pour Hilcorp Energy Company. Il aime jardiner et pêcher à la mouche pendant son temps libre.
Walt Mayfield est architecte de solutions chez AWS et aide les entreprises énergétiques à fonctionner de manière plus sûre et plus efficace. Avant de rejoindre AWS, Walt a travaillé comme ingénieur des opérations pour Hilcorp Energy Company. Il aime jardiner et pêcher à la mouche pendant son temps libre.
 Felipe Lopez est architecte de solutions senior chez AWS avec une concentration dans les opérations de production pétrolière et gazière. Avant de rejoindre AWS, Felipe a travaillé chez GE Digital et Schlumberger, où il s'est concentré sur les produits de modélisation et d'optimisation pour les applications industrielles.
Felipe Lopez est architecte de solutions senior chez AWS avec une concentration dans les opérations de production pétrolière et gazière. Avant de rejoindre AWS, Felipe a travaillé chez GE Digital et Schlumberger, où il s'est concentré sur les produits de modélisation et d'optimisation pour les applications industrielles.
 Yingwei Yu est chercheur appliqué au Generative AI Incubator, AWS. Il a de l'expérience de travail avec plusieurs organisations de tous secteurs sur diverses preuves de concept en apprentissage automatique, notamment le traitement du langage naturel, l'analyse de séries chronologiques et la maintenance prédictive. Dans ses temps libres, il aime nager, peindre, faire de la randonnée et passer du temps avec sa famille et ses amis.
Yingwei Yu est chercheur appliqué au Generative AI Incubator, AWS. Il a de l'expérience de travail avec plusieurs organisations de tous secteurs sur diverses preuves de concept en apprentissage automatique, notamment le traitement du langage naturel, l'analyse de séries chronologiques et la maintenance prédictive. Dans ses temps libres, il aime nager, peindre, faire de la randonnée et passer du temps avec sa famille et ses amis.
 Haozhu Wang est un chercheur scientifique chez Amazon Bedrock qui se concentre sur la construction des modèles de fondation Titan d'Amazon. Auparavant, il a travaillé au sein d'Amazon ML Solutions Lab en tant que co-responsable du secteur d'apprentissage par renforcement et a aidé les clients à créer des solutions ML avancées avec les dernières recherches sur l'apprentissage par renforcement, le traitement du langage naturel et l'apprentissage des graphiques. Haozhu a obtenu son doctorat en génie électrique et informatique de l'Université du Michigan.
Haozhu Wang est un chercheur scientifique chez Amazon Bedrock qui se concentre sur la construction des modèles de fondation Titan d'Amazon. Auparavant, il a travaillé au sein d'Amazon ML Solutions Lab en tant que co-responsable du secteur d'apprentissage par renforcement et a aidé les clients à créer des solutions ML avancées avec les dernières recherches sur l'apprentissage par renforcement, le traitement du langage naturel et l'apprentissage des graphiques. Haozhu a obtenu son doctorat en génie électrique et informatique de l'Université du Michigan.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- GraphiquePrime. Élevez votre jeu de trading avec ChartPrime. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

