Avec l’adoption rapide des applications d’IA générative, il est nécessaire que ces applications répondent à temps afin de réduire la latence perçue avec un débit plus élevé. Les modèles de base (FM) sont souvent pré-entraînés sur de vastes corpus de données avec des paramètres allant de plusieurs millions à plusieurs milliards et au-delà. Les grands modèles de langage (LLM) sont un type de FM qui génère du texte en réponse à l'inférence de l'utilisateur. L'inférence de ces modèles avec différentes configurations de paramètres d'inférence peut conduire à des latences incohérentes. L'incohérence peut être due au nombre variable de jetons de réponse que vous attendez du modèle ou au type d'accélérateur sur lequel le modèle est déployé.
Dans les deux cas, plutôt que d’attendre la réponse complète, vous pouvez adopter l’approche du streaming de réponses pour vos inférences, qui renvoie des morceaux d’informations dès qu’elles sont générées. Cela crée une expérience interactive en vous permettant de voir les réponses partielles diffusées en temps réel au lieu d'une réponse complète différée.
Avec l'annonce officielle selon laquelle L'inférence en temps réel Amazon SageMaker prend désormais en charge le streaming de réponses, vous pouvez désormais diffuser en continu les réponses d'inférence au client lorsque vous utilisez Amazon Sage Maker inférence en temps réel avec streaming de réponses. Cette solution vous aidera à créer des expériences interactives pour diverses applications d'IA générative telles que les chatbots, les assistants virtuels et les générateurs de musique. Cet article vous montre comment obtenir des temps de réponse plus rapides sous la forme de Time to First Byte (TTFB) et réduire la latence globale perçue lors de l'inférence des modèles Llama 2.
Pour mettre en œuvre la solution, nous utilisons SageMaker, un service entièrement géré pour préparer les données et créer, former et déployer des modèles d'apprentissage automatique (ML) pour tout cas d'utilisation avec une infrastructure, des outils et des flux de travail entièrement gérés. Pour plus d'informations sur les différentes options de déploiement proposées par SageMaker, reportez-vous à FAQ sur l'hébergement de modèles Amazon SageMaker. Voyons comment nous pouvons résoudre les problèmes de latence en utilisant l'inférence en temps réel avec le streaming de réponses.
Vue d'ensemble de la solution
Parce que nous souhaitons résoudre les latences susmentionnées associées à l'inférence en temps réel avec les LLM, comprenons d'abord comment nous pouvons utiliser la prise en charge du streaming de réponses pour l'inférence en temps réel pour Llama 2. Cependant, tout LLM peut tirer parti de la prise en charge du streaming de réponses avec de vrais -inférence temporelle.
Llama 2 est une collection de modèles de texte génératifs pré-entraînés et affinés allant de 7 milliards à 70 milliards de paramètres. Les modèles Llama 2 sont des modèles autorégressifs avec une architecture de décodeur uniquement. Lorsqu'ils sont dotés d'une invite et de paramètres d'inférence, les modèles Llama 2 sont capables de générer des réponses textuelles. Ces modèles peuvent être utilisés pour la traduction, le résumé, la réponse aux questions et le chat.
Pour cet article, nous déployons le modèle Llama 2 Chat meta-llama/Llama-2-13b-chat-hf sur SageMaker pour une inférence en temps réel avec streaming de réponses.
Lorsqu'il s'agit de déployer des modèles sur des points de terminaison SageMaker, vous pouvez conteneuriser les modèles à l'aide de Conteneur d'apprentissage en profondeur AWS (DLC) disponibles pour les bibliothèques open source populaires. Les modèles Llama 2 sont des modèles de génération de texte ; vous pouvez utiliser soit le Conteneurs d'inférence Hugging Face LLM sur SageMaker propulsé par Hugging Face Inférence de génération de texte (TGI) ou les DLC AWS pour Inférence de grand modèle (IMT).
Dans cet article, nous déployons le modèle Llama 2 13B Chat à l'aide de DLC sur SageMaker Hosting pour une inférence en temps réel alimentée par des instances G5. Les instances G5 sont des instances basées sur GPU hautes performances pour les applications gourmandes en graphiques et l'inférence ML. Vous pouvez également utiliser les types d'instance pris en charge p4d, p3, g5 et g4dn avec les modifications appropriées selon la configuration de l'instance.
Pré-requis
Pour mettre en œuvre cette solution, vous devez disposer des éléments suivants :
- Un compte AWS avec un Gestion des identités et des accès AWS (IAM) avec des autorisations pour gérer les ressources créées dans le cadre de la solution.
- Si c'est la première fois que vous travaillez avec Amazon SageMakerStudio, vous devez d'abord créer un Domaine SageMaker.
- Un compte Hugging Face. Inscription avec votre email si vous n’avez pas déjà de compte.
- Pour un accès transparent aux modèles disponibles sur Hugging Face, en particulier aux modèles fermés tels que Llama, à des fins de réglage et d'inférence, vous devez disposer d'un compte Hugging Face pour obtenir un jeton d'accès en lecture. Après avoir créé votre compte Hugging Face, vous identifier visiter https://huggingface.co/settings/tokens pour créer un jeton d'accès en lecture.
- Accédez à Llama 2, en utilisant le même identifiant de messagerie que celui que vous avez utilisé pour vous inscrire à Hugging Face.
- Les modèles Llama 2 disponibles via Hugging Face sont des modèles fermés. L'utilisation du modèle Llama est régie par la licence Meta. Pour télécharger les poids du modèle et le tokenizer, demander l'accès à Llama et acceptez leur licence.
- Une fois l’accès accordé (généralement dans quelques jours), vous recevrez un e-mail de confirmation. Pour cet exemple, nous utilisons le modèle
Llama-2-13b-chat-hf, mais vous devriez également pouvoir accéder à d’autres variantes.
Approche 1 : étreindre le visage TGI
Dans cette section, nous vous montrons comment déployer le meta-llama/Llama-2-13b-chat-hf modélisez vers un point de terminaison en temps réel SageMaker avec streaming de réponses à l'aide de Hugging Face TGI. Le tableau suivant présente les spécifications de ce déploiement.
| Spécification | Valeur |
| Contenant | Visage câlin TGI |
| Nom du modèle | méta-lama/Llama-2-13b-chat-hf |
| Instance ML | ml.g5.12xlarge |
| Inférence | En temps réel avec diffusion des réponses |
Déployer le modèle
Tout d’abord, vous récupérez l’image de base du LLM à déployer. Vous construisez ensuite le modèle sur l'image de base. Enfin, vous déployez le modèle sur l'instance ML pour SageMaker Hosting pour une inférence en temps réel.
Observons comment réaliser le déploiement par programme. Par souci de concision, seul le code qui facilite les étapes de déploiement est abordé dans cette section. Le code source complet du déploiement est disponible dans le notebook llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
Récupérez le dernier DLC Hugging Face LLM optimisé par TGI via des modules pré-construits DLC SageMaker. Vous utilisez cette image pour déployer le meta-llama/Llama-2-13b-chat-hf modèle sur SageMaker. Voir le code suivant :
Définissez l'environnement du modèle avec les paramètres de configuration définis comme suit :
remplacer <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> pour le paramètre de configuration HUGGING_FACE_HUB_TOKEN avec la valeur du jeton obtenu à partir de votre profil Hugging Face comme détaillé dans la section prérequis de cet article. Dans la configuration, vous définissez le nombre de GPU utilisés par réplique d'un modèle sur 4 pour SM_NUM_GPUS. Ensuite, vous pouvez déployer le meta-llama/Llama-2-13b-chat-hf modèle sur une instance ml.g5.12xlarge fournie avec 4 GPU.
Vous pouvez maintenant créer l'instance de HuggingFaceModel avec la configuration d'environnement susmentionnée :
Enfin, déployez le modèle en fournissant des arguments à la méthode de déploiement disponible sur le modèle avec diverses valeurs de paramètres telles que endpoint_name, initial_instance_countet instance_type:
Effectuer une inférence
Le DLC Hugging Face TGI offre la possibilité de diffuser des réponses sans aucune personnalisation ni modification du code du modèle. Vous pouvez utiliser invoque_endpoint_with_response_stream si vous utilisez Boto3 ou InvokeEndpointWithResponseStream lors de la programmation avec le SDK SageMaker Python.
La InvokeEndpointWithResponseStream L'API de SageMaker permet aux développeurs de diffuser les réponses des modèles SageMaker, ce qui peut contribuer à améliorer la satisfaction des clients en réduisant la latence perçue. Ceci est particulièrement important pour les applications créées avec des modèles d’IA génératifs, pour lesquels un traitement immédiat est plus important que d’attendre la réponse complète.
Pour cet exemple, nous utilisons Boto3 pour déduire le modèle et utiliser l'API SageMaker invoke_endpoint_with_response_stream comme suit:
L'argument CustomAttributes est fixé à la valeur accept_eula=false. La accept_eula le paramètre doit être défini sur true pour réussir à obtenir la réponse des modèles Llama 2. Après l'appel réussi en utilisant invoke_endpoint_with_response_stream, la méthode renverra un flux de réponse d'octets.
Le diagramme suivant illustre ce flux de travail.
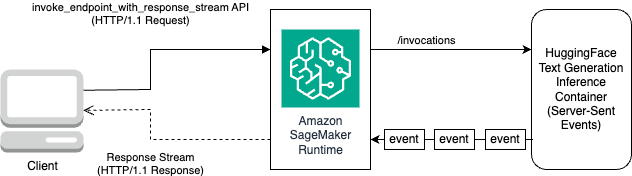
Vous avez besoin d'un itérateur qui parcourt le flux d'octets et les analyse en texte lisible. Le LineIterator la mise en œuvre peut être trouvée sur lama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py. Vous êtes maintenant prêt à préparer l’invite et les instructions pour les utiliser comme charge utile lors de l’inférence du modèle.
Préparez une invite et des instructions
Dans cette étape, vous préparez l'invite et les instructions pour votre LLM. Pour inviter Llama 2, vous devez disposer du modèle d'invite suivant :
Vous créez le modèle d'invite défini par programme dans la méthode build_llama2_prompt, qui correspond au modèle d'invite susmentionné. Vous définissez ensuite les instructions selon le cas d'utilisation. Dans ce cas, nous demandons au modèle de générer un e-mail pour une campagne marketing comme indiqué dans le get_instructions méthode. Le code de ces méthodes se trouve dans le llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb carnet de notes. Construisez l’instruction combinée à la tâche à effectuer comme détaillé dans user_ask_1 comme suit:
Nous transmettons les instructions pour créer l'invite selon le modèle d'invite généré par build_llama2_prompt.
Nous maillons les paramètres d'inférence avec l'invite avec la clé stream avec la valeur True pour former une charge utile finale. Envoyez la charge utile à get_realtime_response_stream, qui sera utilisé pour appeler un point de terminaison avec un streaming de réponse :
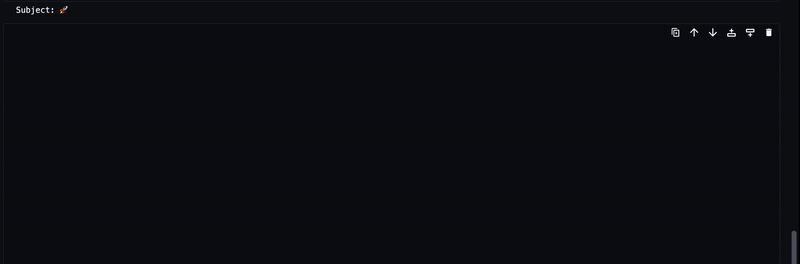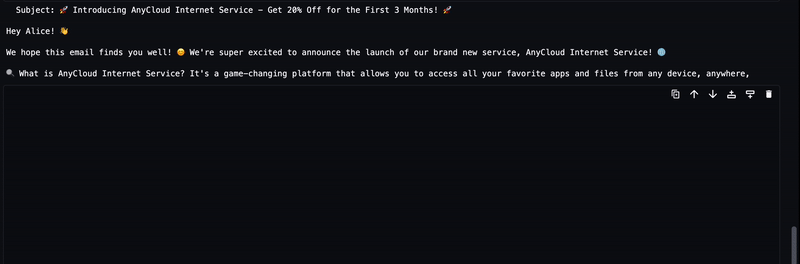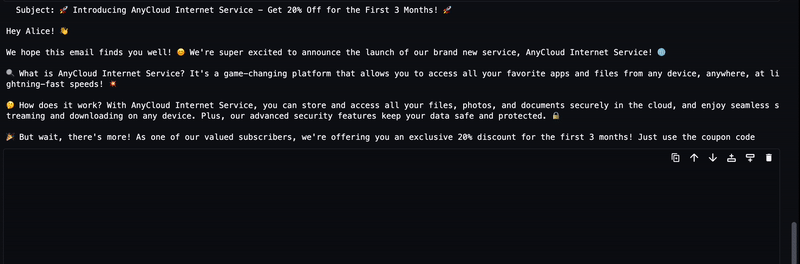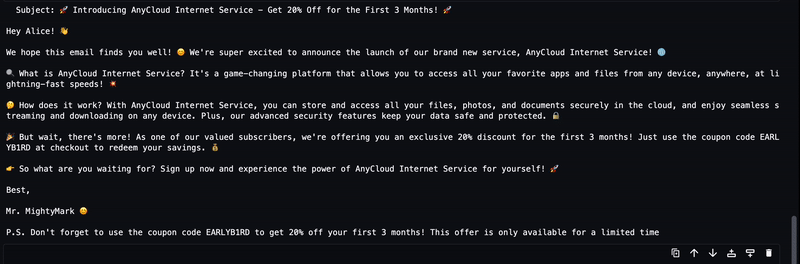
Le texte généré à partir du LLM sera diffusé vers la sortie, comme le montre l'animation suivante.
Approche 2 : LMI avec DJL Serving
Dans cette section, nous montrons comment déployer le meta-llama/Llama-2-13b-chat-hf modélisez vers un point de terminaison en temps réel SageMaker avec streaming de réponses à l'aide de LMI avec DJL Serving. Le tableau suivant présente les spécifications de ce déploiement.
| Spécification | Valeur |
| Contenant | Image du conteneur LMI avec DJL Serving |
| Nom du modèle | méta-lama/Llama-2-13b-chat-hf |
| Instance ML | ml.g5.12xlarge |
| Inférence | En temps réel avec diffusion des réponses |
Vous téléchargez d'abord le modèle et le stockez dans Service de stockage simple Amazon (Amazon S3). Vous précisez ensuite l'URI S3 indiquant le préfixe S3 du modèle dans le serving.properties déposer. Ensuite, vous récupérez l’image de base du LLM à déployer. Vous construisez ensuite le modèle sur l'image de base. Enfin, vous déployez le modèle sur l'instance ML pour SageMaker Hosting pour une inférence en temps réel.
Observons comment réaliser les étapes de déploiement susmentionnées par programme. Par souci de concision, seul le code qui facilite les étapes de déploiement est détaillé dans cette section. Le code source complet de ce déploiement est disponible dans le notebook llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
Téléchargez l'instantané du modèle depuis Hugging Face et téléchargez les artefacts du modèle sur Amazon S3.
Avec les conditions préalables susmentionnées, téléchargez le modèle sur l'instance de notebook SageMaker, puis téléchargez-le dans le compartiment S3 pour un déploiement ultérieur :
Notez que même si vous ne fournissez pas de jeton d'accès valide, le modèle sera téléchargé. Mais lorsque vous déployez un tel modèle, la diffusion du modèle ne réussira pas. Il est donc recommandé de remplacer <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> pour l'argumentation token avec la valeur du token obtenu depuis votre profil Hugging Face comme détaillé dans les prérequis. Pour cet article, nous précisons le nom du modèle officiel pour Llama 2 tel qu'identifié sur Hugging Face avec la valeur meta-llama/Llama-2-13b-chat-hf. Le modèle non compressé sera téléchargé vers local_model_path à la suite de l’exécution du code susmentionné.
Téléchargez les fichiers sur Amazon S3 et obtenez l'URI, qui sera ensuite utilisé dans serving.properties.
Vous emballerez le meta-llama/Llama-2-13b-chat-hf modèle sur l'image du conteneur LMI avec DJL Serving en utilisant la configuration spécifiée via serving.properties. Ensuite, vous déployez le modèle avec les artefacts de modèle empaquetés sur l'image du conteneur sur l'instance SageMaker ML ml.g5.12xlarge. Vous utilisez ensuite cette instance ML pour SageMaker Hosting pour l'inférence en temps réel.
Préparer les artefacts de modèle pour DJL Serving
Préparez vos artefacts de modèle en créant un serving.properties fichier de configuration:
Nous utilisons les paramètres suivants dans ce fichier de configuration :
- moteur – Ceci spécifie le moteur d'exécution que DJL doit utiliser. Les valeurs possibles incluent
Python,DeepSpeed,FasterTransformeretMPI. Dans ce cas, nous le définissons surMPI. La parallélisation et l'inférence de modèle (MPI) facilite le partitionnement du modèle sur tous les GPU disponibles et accélère donc l'inférence. - option.entryPoint – Cette option spécifie quel gestionnaire proposé par DJL Serving vous souhaitez utiliser. Les valeurs possibles sont
djl_python.huggingface,djl_python.deepspeedetdjl_python.stable-diffusion. Nous utilisonsdjl_python.huggingfacepour étreindre le visage accélérer. - option.tensor_parallel_degree – Cette option spécifie le nombre de partitions parallèles tensorielles effectuées sur le modèle. Vous pouvez définir le nombre de périphériques GPU sur lesquels Accelerate doit partitionner le modèle. Ce paramètre contrôle également le nombre de nœuds de calcul par modèle qui seront démarrés lors de l'exécution du service DJL. Par exemple, si nous avons une machine à 4 GPU et que nous créons quatre partitions, nous aurons alors un travailleur par modèle pour répondre aux demandes.
- option.low_cpu_mem_usage – Cela réduit l’utilisation de la mémoire CPU lors du chargement des modèles. Nous vous recommandons de définir ceci sur
TRUE. - option.rolling_batch – Cela permet le traitement par lots au niveau des itérations en utilisant l'une des stratégies prises en charge. Les valeurs incluent
auto,scheduleretlmi-dist. Nous utilisonslmi-distpour activer le traitement par lots continu pour Llama 2. - option.max_rolling_batch_size – Cela limite le nombre de demandes simultanées dans le lot continu. La valeur par défaut est 32.
- option.model_id – Vous devriez remplacer
{{model_id}}avec l'ID de modèle d'un modèle pré-entraîné hébergé dans un référentiel de modèles sur Hugging Face ou chemin S3 vers les artefacts du modèle.
Plus d'options de configuration peuvent être trouvées dans Configurations et paramètres.
Étant donné que DJL Serving s'attend à ce que les artefacts de modèle soient empaquetés et formatés dans un fichier .tar, exécutez l'extrait de code suivant pour compresser et télécharger le fichier .tar sur Amazon S3 :
Récupérez la dernière image du conteneur LMI avec DJL Serving
Ensuite, vous utilisez les DLC disponibles avec SageMaker for LMI pour déployer le modèle. Récupérez l’URI de l’image SageMaker pour le djl-deepspeed conteneur par programmation en utilisant le code suivant :
Vous pouvez utiliser l'image susmentionnée pour déployer le meta-llama/Llama-2-13b-chat-hf modèle sur SageMaker. Vous pouvez maintenant procéder à la création du modèle.
Créer le modèle
Vous pouvez créer le modèle dont le conteneur est construit à l'aide du inference_image_uri et le code de diffusion du modèle situé à l'URI S3 indiqué par s3_code_artifact:
Vous pouvez maintenant créer la configuration du modèle avec tous les détails de la configuration du point de terminaison.
Créer la configuration du modèle
Utilisez le code suivant pour créer une configuration de modèle pour le modèle identifié par model_name:
La configuration du modèle est définie pour le ProductionVariants paramètre InstanceType pour l'instance ML ml.g5.12xlarge. Vous fournissez également le ModelName en utilisant le même nom que celui que vous avez utilisé pour créer le modèle à l'étape précédente, établissant ainsi une relation entre le modèle et la configuration du point de terminaison.
Maintenant que vous avez défini le modèle et la configuration du modèle, vous pouvez créer le point de terminaison SageMaker.
Créer le point de terminaison SageMaker
Créez le point de terminaison pour déployer le modèle à l'aide de l'extrait de code suivant :
Vous pouvez afficher la progression du déploiement à l'aide de l'extrait de code suivant :
Une fois le déploiement réussi, l'état du point de terminaison sera InService. Maintenant que le point de terminaison est prêt, effectuons une inférence avec le streaming de réponses.
Inférence en temps réel avec streaming de réponses
Comme nous l'avons expliqué dans l'approche précédente pour Hugging Face TGI, vous pouvez utiliser la même méthode. get_realtime_response_stream pour appeler le streaming de réponses à partir du point de terminaison SageMaker. Le code pour l'inférence à l'aide de l'approche LMI se trouve dans le llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb carnet de notes. Le LineIterator la mise en œuvre se situe dans lama-2-lmi/utils/LineIterator.py. Notez que le LineIterator pour le modèle Llama 2 Chat déployé sur le conteneur LMI est différent du modèle LineIterator référencé dans la section Hugging Face TGI. Le LineIterator boucle sur le flux d'octets des modèles Llama 2 Chat inférés avec le conteneur LMI avec djl-deepspeed version 0.25.0. La fonction d'assistance suivante analysera le flux de réponse reçu de la demande d'inférence effectuée via le invoke_endpoint_with_response_stream API:
La méthode précédente imprime le flux de données lu par le LineIterator dans un format lisible par l'homme.
Voyons comment préparer l'invite et les instructions pour les utiliser comme charge utile lors de l'inférence du modèle.
Étant donné que vous inférez le même modèle dans Hugging Face TGI et LMI, le processus de préparation de l'invite et des instructions est le même. Vous pouvez donc utiliser les méthodes get_instructions ainsi que build_llama2_prompt pour l'inférence.
La get_instructions La méthode renvoie les instructions. Construisez les instructions combinées à la tâche à effectuer comme détaillé dans user_ask_2 comme suit:
Transmettez les instructions pour créer l'invite selon le modèle d'invite généré par build_llama2_prompt:
Nous associons les paramètres d'inférence ainsi que l'invite pour former une charge utile finale. Ensuite, vous envoyez la charge utile à get_realtime_response_stream, qui est utilisé pour appeler un point de terminaison avec un streaming de réponse :
Le texte généré à partir du LLM sera diffusé vers la sortie, comme le montre l'animation suivante.

Nettoyer
Pour éviter de payer des frais inutiles, utilisez le Console de gestion AWS pour supprimer les points de terminaison et ses ressources associées qui ont été créés lors de l'exécution des approches mentionnées dans l'article. Pour les deux approches de déploiement, effectuez la routine de nettoyage suivante :
remplacer <SageMaker_Real-time_Endpoint_Name> pour variable endpoint_name avec le point final réel.
Pour la deuxième approche, nous avons stocké les artefacts de modèle et de code sur Amazon S3. Vous pouvez nettoyer le compartiment S3 à l'aide du code suivant :
Conclusion
Dans cet article, nous avons expliqué comment un nombre variable de jetons de réponse ou un ensemble différent de paramètres d'inférence peuvent affecter les latences associées aux LLM. Nous avons montré comment résoudre le problème à l’aide du streaming de réponses. Nous avons ensuite identifié deux approches pour déployer et inférer des modèles Llama 2 Chat à l'aide des DLC AWS : LMI et Hugging Face TGI.
Vous devez maintenant comprendre l’importance de la réponse en streaming et comment elle peut réduire la latence perçue. La réponse en streaming peut améliorer l'expérience utilisateur, ce qui autrement vous ferait attendre que le LLM génère l'intégralité de la réponse. De plus, le déploiement de modèles Llama 2 Chat avec streaming de réponses améliore l'expérience utilisateur et rend vos clients satisfaits.
Vous pouvez vous référer aux échantillons AWS officiels amazon-sagemaker-llama2-response-streaming-recettes qui couvre le déploiement d'autres variantes du modèle Llama 2.
Bibliographie
À propos des auteurs
 Navule Pavan Kumar Rao est architecte de solutions chez Amazon Web Services. Il travaille avec des éditeurs de logiciels indépendants en Inde pour les aider à innover sur AWS. Il est l'auteur du livre « Getting Started with V Programming ». Il a poursuivi un Executive M.Tech en science des données à l'Institut indien de technologie (IIT) d'Hyderabad. Il a également poursuivi un Executive MBA en spécialisation informatique de l'École indienne de gestion et d'administration des affaires et est titulaire d'un B.Tech en ingénierie électronique et de communication de l'Institut de technologie et de science Vaagdevi. Pavan est un AWS Certified Solutions Architect Professional et détient d'autres certifications telles que AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP) et Microsoft Certified Technology Specialist (MCTS). Il est également un passionné de l'open source. Pendant son temps libre, il adore écouter les grandes voix magiques de Sia et Rihanna.
Navule Pavan Kumar Rao est architecte de solutions chez Amazon Web Services. Il travaille avec des éditeurs de logiciels indépendants en Inde pour les aider à innover sur AWS. Il est l'auteur du livre « Getting Started with V Programming ». Il a poursuivi un Executive M.Tech en science des données à l'Institut indien de technologie (IIT) d'Hyderabad. Il a également poursuivi un Executive MBA en spécialisation informatique de l'École indienne de gestion et d'administration des affaires et est titulaire d'un B.Tech en ingénierie électronique et de communication de l'Institut de technologie et de science Vaagdevi. Pavan est un AWS Certified Solutions Architect Professional et détient d'autres certifications telles que AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP) et Microsoft Certified Technology Specialist (MCTS). Il est également un passionné de l'open source. Pendant son temps libre, il adore écouter les grandes voix magiques de Sia et Rihanna.
 La haine de Sudhanshu est le principal spécialiste de l'IA/ML chez AWS et travaille avec les clients pour les conseiller dans leur parcours MLOps et IA générative. Dans son rôle précédent chez Amazon, il a conceptualisé, créé et dirigé des équipes chargées de créer des plates-formes d'IA et de gamification open source, et les a commercialisées avec succès auprès de plus de 100 clients. Sudhanshu a à son actif quelques brevets, a écrit deux livres et plusieurs articles et blogs, et a présenté ses points de vue dans divers forums techniques. Il est un leader d'opinion et un conférencier et travaille dans l'industrie depuis près de 25 ans. Il a travaillé avec des clients Fortune 1000 à travers le monde et, plus récemment, avec des clients natifs du numérique en Inde.
La haine de Sudhanshu est le principal spécialiste de l'IA/ML chez AWS et travaille avec les clients pour les conseiller dans leur parcours MLOps et IA générative. Dans son rôle précédent chez Amazon, il a conceptualisé, créé et dirigé des équipes chargées de créer des plates-formes d'IA et de gamification open source, et les a commercialisées avec succès auprès de plus de 100 clients. Sudhanshu a à son actif quelques brevets, a écrit deux livres et plusieurs articles et blogs, et a présenté ses points de vue dans divers forums techniques. Il est un leader d'opinion et un conférencier et travaille dans l'industrie depuis près de 25 ans. Il a travaillé avec des clients Fortune 1000 à travers le monde et, plus récemment, avec des clients natifs du numérique en Inde.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/inference-llama-2-models-with-real-time-response-streaming-using-amazon-sagemaker/

