Le traitement des données de flux vous permet d'agir sur les données en temps réel. L'analyse de données en temps réel peut vous aider à obtenir des réponses ponctuelles et optimisées tout en améliorant l'expérience client globale.
Apache Flink est un cadre de calcul distribué qui permet le traitement de données en temps réel avec état. Il fournit un ensemble unique d'API pour créer des travaux par lots et en continu, ce qui permet aux développeurs de travailler facilement avec des données limitées et illimitées. Apache Flink fournit différents niveaux d'abstraction pour couvrir une variété de cas d'utilisation de traitement d'événements.
Analyse des données Amazon Kinesis est un service AWS qui fournit une infrastructure sans serveur pour l'exécution des applications Apache Flink. Cela permet aux développeurs de créer facilement des applications Apache Flink hautement disponibles, tolérantes aux pannes et évolutives sans avoir besoin de devenir un expert dans la création, la configuration et la maintenance des clusters Apache Flink sur AWS.
Les charges de travail de streaming de données nécessitent souvent que les données du flux soient enrichies via des sources externes (telles que des bases de données ou d'autres flux de données). Par exemple, supposons que vous receviez des données de coordonnées d'un appareil GPS et que vous deviez comprendre comment ces coordonnées correspondent à des emplacements géographiques physiques ; vous devez l'enrichir avec des données de géolocalisation. Vous pouvez utiliser plusieurs approches pour enrichir vos données en temps réel dans Kinesis Data Analytics en fonction de votre cas d'utilisation et du niveau d'abstraction Apache Flink. Chaque méthode a des effets différents sur le débit, le trafic réseau et l'utilisation du processeur (ou de la mémoire). Dans cet article, nous couvrons ces approches et discutons de leurs avantages et inconvénients.
Modèles d'enrichissement des données
L'enrichissement des données est un processus qui ajoute un contexte supplémentaire et améliore les données collectées. Les données supplémentaires sont souvent collectées à partir de diverses sources. Le format et la fréquence des mises à jour des données peuvent aller d'une fois par mois à plusieurs fois par seconde. Le tableau suivant montre quelques exemples de différentes sources, formats et fréquences de mise à jour.
| Données | Format | Fréquence de mise à jour |
| Plages d'adresses IP par pays | CSV | Une fois par mois |
| Organigramme de l'entreprise | JSON | Deux fois par an |
| Noms de machine par ID | CSV | Une fois par jour |
| Informations sur les employés | Table (Base de données relationnelle) | Quelques fois par jour |
| Information client | Table (Base de données non relationnelle) | Quelques fois par heure |
| Commandes client | Table (Base de données relationnelle) | Plusieurs fois par seconde |
Selon le cas d'utilisation, votre application d'enrichissement de données peut avoir des exigences différentes en termes de latence, de débit ou d'autres facteurs. Le reste de l'article approfondit les différents modèles d'enrichissement des données dans Kinesis Data Analytics, qui sont répertoriés dans le tableau suivant avec leurs principales caractéristiques. Vous pouvez choisir le meilleur modèle en fonction du compromis entre ces caractéristiques.
| Modèle d'enrichissement | Latence | Cadence de production | Précision si les données de référence changent | Utilisation de la mémoire | Complexité |
| Précharger les données de référence dans la mémoire Apache Flink Task Manager | Faible | Haute | Faible | Haute | Faible |
| Préchargement partitionné des données de référence dans l'état Apache Flink | Faible | Haute | Faible | Faible | Faible |
| Préchargement partitionné périodique des données de référence dans l'état Apache Flink | Faible | Haute | Technique | Faible | Technique |
| Recherche asynchrone par enregistrement avec carte non ordonnée | Technique | Technique | Haute | Faible | Faible |
| Recherche asynchrone par enregistrement à partir d'un système de cache externe | Faible ou moyen (selon le stockage et la mise en œuvre du cache) | Technique | Haute | Faible | Technique |
| Enrichir les flux à l'aide de l'API Table | Faible | Haute | Haute | Bas - Moyen (selon l'opérateur de jointure sélectionné) | Faible |
Enrichir les données de streaming en préchargeant les données de référence
Lorsque les données de référence sont de petite taille et de nature statique (par exemple, des données de pays incluant le code du pays et le nom du pays), il est recommandé d'enrichir vos données de streaming en préchargeant les données de référence, ce que vous pouvez faire de plusieurs manières.
Pour voir l'implémentation du code pour le préchargement des données de référence de différentes manières, reportez-vous au GitHub repo. Suivez les instructions du référentiel GitHub pour exécuter le code et comprendre le modèle de données.
Préchargement des données de référence dans la mémoire d'Apache Flink Task Manager
La méthode d'enrichissement la plus simple et la plus rapide consiste à charger les données d'enrichissement dans la mémoire en tas de chacun des gestionnaires de tâches Apache Flink. Pour implémenter cette méthode, vous créez une nouvelle classe en étendant le RichFlatMapFunction classe abstraite. Vous définissez une variable statique globale dans votre définition de classe. La variable peut être de n'importe quel type, la seule limitation est qu'elle doit s'étendre java.io.Serializable-par exemple, java.util.HashMap. Dans le open() méthode, vous définissez une logique qui charge les données statiques dans votre variable définie. La open() La méthode est toujours appelée en premier, lors de l'initialisation de chaque tâche dans les gestionnaires de tâches d'Apache Flink, ce qui garantit que toutes les données de référence sont chargées avant le début du traitement. Vous implémentez votre logique de traitement en remplaçant le processElement() méthode. Vous implémentez votre logique de traitement et accédez à la donnée de référence par sa clé à partir de la variable globale définie.
Le diagramme d'architecture suivant montre le chargement complet des données de référence dans chaque emplacement de tâche du gestionnaire de tâches.
Cette méthode présente les avantages suivants :
- Facilité de mise en œuvre
- Faible latence
- Peut prendre en charge un débit élevé
Cependant, il présente les inconvénients suivants :
- Si les données de référence sont de grande taille, le gestionnaire de tâches Apache Flink peut manquer de mémoire.
- Les données de référence peuvent devenir obsolètes au fil du temps.
- Plusieurs copies des mêmes données de référence sont chargées dans chaque emplacement de tâche du gestionnaire de tâches.
- Les données de référence doivent être petites pour tenir dans la mémoire allouée à un seul emplacement de tâche. Dans Kinesis Data Analytics, chaque unité de traitement Kinesis (KPU) dispose de 4 Go de mémoire, dont 3 Go peuvent être utilisés pour la mémoire de tas. Si
ParallelismPerKPUdans Kinesis Data Analytics est défini sur 1, un emplacement de tâche s'exécute dans chaque gestionnaire de tâches et l'emplacement de tâche peut utiliser la totalité des 3 Go de mémoire de tas. SiParallelismPerKPUest défini sur une valeur supérieure à 1, les 3 Go de mémoire de tas sont répartis sur plusieurs emplacements de tâches dans le gestionnaire de tâches. Si vous déployez Apache Flink dans Amazon DME ou en mode autogéré, vous pouvez réglertaskmanager.memory.task.heap.sizepour augmenter la mémoire de tas d'un gestionnaire de tâches.
Préchargement partitionné des données de référence dans Apache Flink State
Dans cette approche, les données de référence sont chargées et conservées dans le magasin d'état Apache Flink au démarrage de l'application Apache Flink. Pour optimiser l'utilisation de la mémoire, le flux de données principal est d'abord divisé par un champ spécifié via le keyBy() opérateur sur tous les créneaux de tâches. De plus, seule la partie des données de référence qui correspond à chaque tranche de tâche est chargée dans la mémoire d'état.
Ceci est réalisé dans Apache Flink en créant la classe PartitionPreLoadEnrichmentData, prolongeant la RichFlatMapFunction classe abstraite. Dans la méthode open, vous remplacez le ValueStateDescriptor méthode pour créer un handle d'état. Dans l'exemple référencé, le descripteur est nommé locationRefData, le type de clé d'état est String et le type de valeur est Location. Dans ce code, nous utilisons ValueState par rapport à MapState car nous ne détenons que les données de référence de localisation pour une clé particulière. Par exemple, lorsque nous interrogeons Amazon S3 pour obtenir les données de référence d'emplacement, nous interrogeons le rôle spécifique et obtenons un emplacement particulier en tant que valeur.
Dans Apache Flink, ValueState est utilisé pour contenir une valeur spécifique pour une clé, alors que MapState est utilisé pour contenir une combinaison de paires clé-valeur.
Cette technique est utile lorsque vous disposez d'un grand ensemble de données statiques qu'il est difficile d'intégrer dans la mémoire dans son ensemble pour chaque partition.
Le diagramme d'architecture suivant montre la charge des données de référence pour la clé spécifique pour chaque partition du flux.
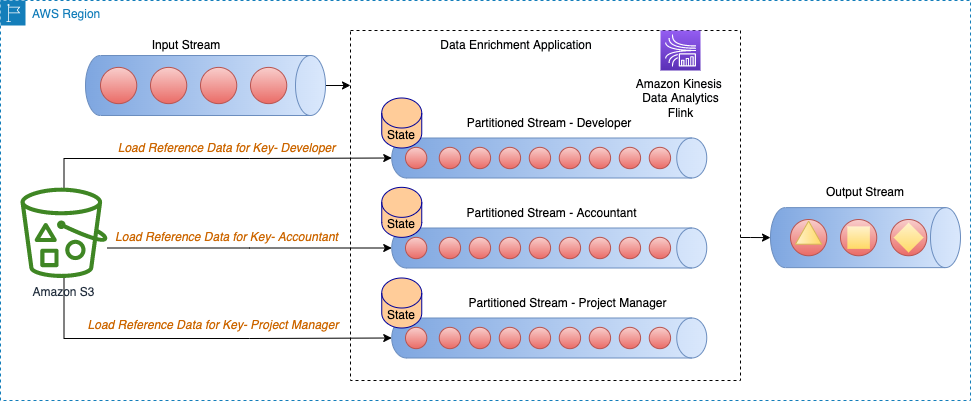
Par exemple, nos données de référence dans l'exemple de code GitHub ont des rôles qui sont mappés à chaque bâtiment. Étant donné que le flux est partitionné par rôles, seules les informations de construction spécifiques par rôle doivent être chargées pour chaque partition en tant que données de référence.
Cette méthode présente les avantages suivants :
- Faible latence.
- Peut prendre en charge un débit élevé.
- Les données de référence pour une partition spécifique sont chargées dans l'état à clé.
- Dans Kinesis Data Analytics, le magasin d'état par défaut configuré est RocksDB. RocksDB peut utiliser une partie importante de 1 Go de mémoire gérée et de 50 Go d'espace disque fournis par chaque KPU. Cela laisse suffisamment de place pour que les données de référence se développent.
Cependant, il présente les inconvénients suivants :
- Les données de référence peuvent devenir obsolètes au fil du temps
Préchargement partitionné périodique des données de référence dans Apache Flink State
Cette approche est une mise au point de la technique précédente, où chaque donnée de référence partitionnée est rechargée périodiquement pour actualiser les données de référence. Ceci est utile si vos données de référence changent occasionnellement.
Le diagramme d'architecture suivant montre le chargement périodique des données de référence pour la clé spécifique pour chaque partition du flux.

Dans cette approche, la classe PeriodicPerPartitionLoadEnrichmentData est créé, étendant la KeyedProcessFunction classer. Semblable au modèle précédent, dans le contexte de l'exemple GitHub, ValueState est recommandé ici car chaque partition ne charge qu'une seule valeur pour la clé. De la même manière que mentionné précédemment, dans le open méthode, vous définissez la ValueStateDescriptor pour gérer l'état de la valeur et définir un contexte d'exécution pour accéder à l'état.
au sein de la processElement méthode, chargez l'état de la valeur et attachez les données de référence (dans l'exemple GitHub référencé, buildingNo aux données client). Enregistrez également un service de minuterie à invoquer lorsque le temps de traitement dépasse le temps donné. Dans l'exemple de code, le service de minuterie est planifié pour être appelé périodiquement (par exemple, toutes les 60 secondes). Dans le onTimer , mettez à jour l'état en effectuant un appel pour recharger les données de référence pour le rôle spécifique.
Cette méthode présente les avantages suivants :
- Faible latence.
- Peut prendre en charge un débit élevé.
- Les données de référence pour des partitions spécifiques sont chargées dans l'état avec clé.
- Les données de référence sont actualisées périodiquement.
- Dans Kinesis Data Analytics, le magasin d'état par défaut configuré est RocksDB. De plus, 50 Go d'espace disque fournis par chaque KPU. Cela laisse suffisamment de place pour que les données de référence se développent.
Cependant, il présente les inconvénients suivants :
- Si les données de référence changent fréquemment, l'application a toujours des données obsolètes en fonction de la fréquence à laquelle l'état est rechargé
- L'application peut faire face à des pics de charge lors du rechargement des données de référence
Enrichir les données de streaming à l'aide de la recherche par enregistrement
Bien que le préchargement des données de référence fournisse une faible latence et un débit élevé, il peut ne pas convenir à certains types de charges de travail, telles que les suivantes :
- Mises à jour des données de référence à haute fréquence
- Apache Flink doit passer un appel externe pour calculer la logique métier
- La précision de la sortie est importante et l'application ne doit pas utiliser de données obsolètes
Normalement, pour ces types de cas d'utilisation, les développeurs font un compromis entre un débit élevé et une faible latence pour la précision des données. Dans cette section, vous découvrirez quelques implémentations courantes pour l'enrichissement des données par enregistrement, ainsi que leurs avantages et inconvénients.
Recherche asynchrone par enregistrement avec carte non ordonnée
Dans une implémentation de recherche synchrone par enregistrement, l'application Apache Flink doit attendre de recevoir la réponse après avoir envoyé chaque requête. Cela oblige le processeur à rester inactif pendant une période de temps de traitement significative. Au lieu de cela, l'application peut envoyer une requête pour d'autres éléments du flux pendant qu'elle attend la réponse pour le premier élément. De cette façon, le temps d'attente est amorti sur plusieurs requêtes et augmente donc le débit du processus. Apache Flink fournit E/S asynchrones pour l'accès aux données externes. Lors de l'utilisation de ce modèle, vous devez choisir entre unorderedWait (où il émet le résultat à l'opérateur suivant dès que la réponse est reçue, sans tenir compte de l'ordre de l'élément sur le flux) et orderedWait (où il attend que toutes les opérations d'E/S en cours soient terminées, puis envoie les résultats à l'opérateur suivant dans le même ordre que celui dans lequel les éléments d'origine ont été placés sur le flux). Habituellement, lorsque les consommateurs en aval ne tiennent pas compte de l'ordre des éléments dans le flux, unorderedWait offre un meilleur débit et moins de temps d'inactivité. Visite Enrichissez votre flux de données de manière asynchrone à l'aide de Kinesis Data Analytics pour Apache Flink pour en savoir plus sur ce modèle.
Le diagramme d'architecture suivant montre comment une application Apache Flink sur Kinesis Data Analytics effectue des appels asynchrones vers un moteur de base de données externe (par exemple Amazon DynamoDB) pour chaque événement du flux principal.
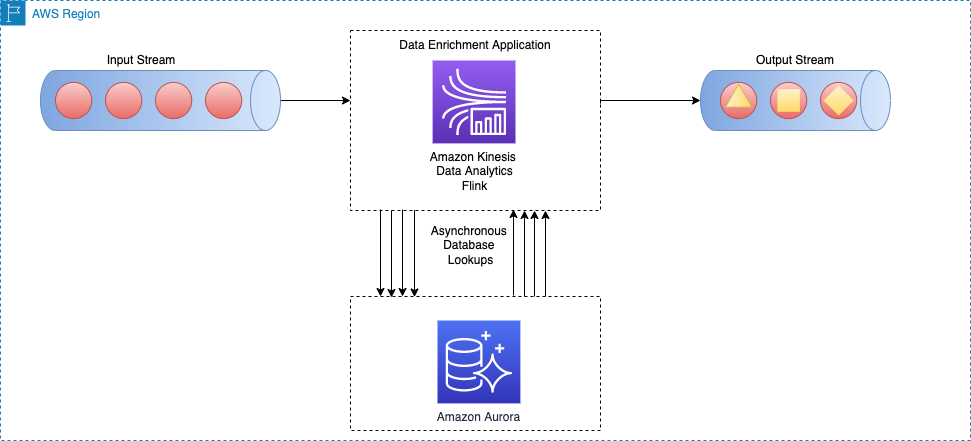
Cette méthode présente les avantages suivants :
- Toujours raisonnablement simple et facile à mettre en œuvre
- Lit les données de référence les plus récentes
Cependant, il présente les inconvénients suivants :
- Il génère une charge de lecture importante pour le système externe (par exemple, un moteur de base de données ou une API externe) qui héberge les données de référence
- Dans l'ensemble, il peut ne pas convenir aux systèmes qui nécessitent un débit élevé avec une faible latence
Recherche asynchrone par enregistrement à partir d'un système de cache externe
Une façon d'améliorer le modèle précédent consiste à utiliser un système de cache pour améliorer le temps de lecture pour chaque appel d'E/S de recherche. Vous pouvez utiliser AmazonElastiCache en la mise en cache, qui accélère les performances des applications et des bases de données, ou en tant que magasin de données principal pour les cas d'utilisation qui ne nécessitent pas de durabilité, comme les magasins de sessions, les classements de jeux, le streaming et l'analyse. ElastiCache est compatible avec Redis et Memcached.
Pour que ce modèle fonctionne, vous devez implémenter un modèle de mise en cache pour remplir les données dans le stockage du cache. Vous pouvez choisir entre une approche proactive ou réactive en fonction des objectifs de votre application et des exigences de latence. Pour plus d'informations, reportez-vous à Modèles de mise en cache.
Le schéma d'architecture suivant montre comment une application Apache Flink appelle pour lire les données de référence à partir d'un stockage de cache externe (par exemple, Amazon ElastiCache pour Redis). Les modifications de données doivent être répliquées à partir de la base de données principale (par exemple, Amazon Aurora) au stockage en cache en implémentant l'une des modèles de mise en cache.
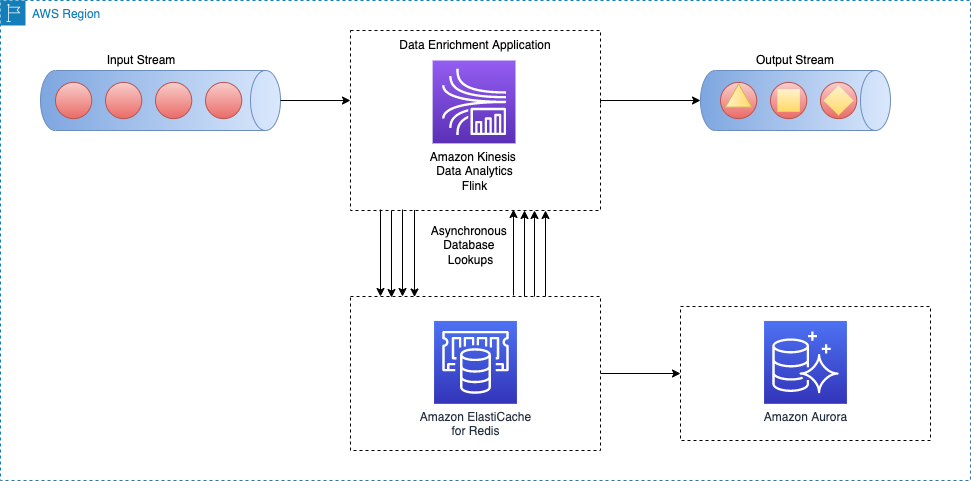
L'implémentation de ce modèle d'enrichissement de données est similaire au modèle de recherche asynchrone par enregistrement ; la seule différence est que l'application Apache Flink établit une connexion au stockage de cache, au lieu de se connecter à la base de données primaire.
Cette méthode présente les avantages suivants :
- Meilleur débit car la mise en cache peut accélérer les performances des applications et des bases de données
- Protège la source de données principale du trafic de lecture créé par l'application de traitement de flux
- Peut fournir une latence de lecture plus faible pour chaque appel de recherche
- Dans l'ensemble, peut ne pas convenir aux systèmes à débit moyen à élevé qui souhaitent améliorer la fraîcheur des données
Cependant, il présente les inconvénients suivants :
- Complexité supplémentaire de la mise en œuvre d'un modèle de cache pour remplir et synchroniser les données entre la base de données principale et le stockage de cache
- Il est possible que l'application de traitement de flux Apache Flink lise des données de référence obsolètes en fonction du modèle de mise en cache mis en œuvre
- Selon le modèle de cache choisi (proactif ou réactif), le temps de réponse pour chaque E/S d'enrichissement peut différer, par conséquent le temps de traitement global du flux peut être imprévisible
Alternativement, vous pouvez éviter ces complexités en utilisant le Connecteur Apache Flink JDBC pour les API Flink SQL. Nous discutons plus en détail des données de flux d'enrichissement via les API Flink SQL plus loin dans cet article.
Enrichir les données du flux via un autre flux
Dans ce modèle, les données du flux principal sont enrichies avec les données de référence d'un autre flux de données. Ce modèle convient aux cas d'utilisation dans lesquels les données de référence sont mises à jour fréquemment et il est possible d'effectuer une capture de données modifiées (CDC) et de publier les événements sur un service de streaming de données tel qu'Apache Kafka ou Flux de données Amazon Kinesis. Ce modèle est utile dans les cas d'utilisation suivants, par exemple :
- Les bons de commande des clients sont publiés dans un flux de données Kinesis, puis associés aux informations de facturation des clients dans un Flux DynamoDB
- Les événements de données capturés à partir d'appareils IoT doivent être enrichis avec des données de référence dans un tableau dans Service de base de données relationnelle Amazon (Amazon RDS)
- Les événements du journal réseau doivent s'enrichir avec le nom de la machine sur les adresses IP source (et de destination)
Le diagramme d'architecture suivant montre comment une application Apache Flink sur Kinesis Data Analytics joint les données du flux principal aux données CDC dans un flux DynamoDB.

Pour enrichir les données de streaming à partir d'un autre flux, nous utilisons un flux commun pour diffuser les modèles de jointure, que nous expliquons dans les sections suivantes.
Enrichir les flux à l'aide de l'API Table
Les API Apache Flink Table fournissent une abstraction plus élevée pour travailler avec des événements de données. Avec API de tableau, vous pouvez définir votre flux de données sous forme de table et y attacher le schéma de données.
Dans ce modèle, vous définissez des tables pour chaque flux de données, puis joignez ces tables pour atteindre les objectifs d'enrichissement des données. Prise en charge des API Apache Flink Table différents types de conditions de jointure, comme la jointure interne et la jointure externe. Cependant, vous voulez les éviter si vous avez affaire à des flux illimités, car ils consomment beaucoup de ressources. Pour limiter l'utilisation des ressources et exécuter efficacement les jointures, vous devez utiliser des jointures par intervalles ou temporelles. Une jointure d'intervalle nécessite un prédicat d'équi-jointure et une condition de jointure qui délimite le temps des deux côtés. Pour mieux comprendre comment implémenter une jointure par intervalle, reportez-vous à Premiers pas avec les API Apache Flink SQL dans Kinesis Data Analytics Studio.
Par rapport aux jointures d'intervalle, les jointures de table temporelle ne fonctionnent pas avec une période de temps pendant laquelle différentes versions d'un enregistrement sont conservées. Les enregistrements du flux principal sont toujours joints à la version correspondante des données de référence à l'heure spécifiée par le filigrane. Par conséquent, moins de versions des données de référence restent dans l'état.
Notez que les données de référence peuvent ou non être associées à un élément temporel. Si ce n'est pas le cas, vous devrez peut-être ajouter un élément de temps de traitement pour la jointure avec le flux temporel.
Dans l'exemple d'extrait de code suivant, le update_time colonne est ajoutée à la currency_rates table de référence à partir des métadonnées de capture de données modifiées telles que Debezium. De plus, il est utilisé pour définir un filigrane stratégie pour la table.
À propos des auteurs
 Ali Alémi est un architecte de solutions spécialiste du streaming chez AWS. Ali conseille les clients AWS sur les meilleures pratiques architecturales et les aide à concevoir des systèmes de données d'analyse en temps réel fiables, sécurisés, efficaces et rentables. Il travaille à partir des cas d'utilisation des clients et conçoit des solutions de données pour résoudre leurs problèmes commerciaux. Avant de rejoindre AWS, Ali a accompagné plusieurs clients du secteur public et partenaires de conseil AWS dans leur parcours de modernisation des applications et de migration vers le cloud.
Ali Alémi est un architecte de solutions spécialiste du streaming chez AWS. Ali conseille les clients AWS sur les meilleures pratiques architecturales et les aide à concevoir des systèmes de données d'analyse en temps réel fiables, sécurisés, efficaces et rentables. Il travaille à partir des cas d'utilisation des clients et conçoit des solutions de données pour résoudre leurs problèmes commerciaux. Avant de rejoindre AWS, Ali a accompagné plusieurs clients du secteur public et partenaires de conseil AWS dans leur parcours de modernisation des applications et de migration vers le cloud.
 Subham Rakchit est un architecte de solutions spécialisées en streaming pour l'analyse chez AWS basé au Royaume-Uni. Il travaille avec les clients pour concevoir et construire des plateformes de recherche et de diffusion de données qui les aident à atteindre leur objectif commercial. En dehors du travail, il aime passer du temps à résoudre des puzzles avec sa fille.
Subham Rakchit est un architecte de solutions spécialisées en streaming pour l'analyse chez AWS basé au Royaume-Uni. Il travaille avec les clients pour concevoir et construire des plateformes de recherche et de diffusion de données qui les aident à atteindre leur objectif commercial. En dehors du travail, il aime passer du temps à résoudre des puzzles avec sa fille.
 Dr Sam Mokhtari est architecte de solutions senior chez AWS. Son principal domaine de profondeur est les données et l'analyse, et il a publié plus de 30 articles influents dans ce domaine. Il est également un conseiller respecté en matière de données et d'analyse qui a dirigé plusieurs projets de mise en œuvre à grande échelle dans différents secteurs, notamment l'énergie, la santé, les télécommunications et les transports.
Dr Sam Mokhtari est architecte de solutions senior chez AWS. Son principal domaine de profondeur est les données et l'analyse, et il a publié plus de 30 articles influents dans ce domaine. Il est également un conseiller respecté en matière de données et d'analyse qui a dirigé plusieurs projets de mise en œuvre à grande échelle dans différents secteurs, notamment l'énergie, la santé, les télécommunications et les transports.

