Ceci est le deuxième article d'une série en deux parties dans laquelle je propose un guide pratique pour les organisations afin que vous puissiez évaluer la qualité des modèles de résumé de texte pour votre domaine.
Pour une introduction à la synthèse de texte, un aperçu de ce didacticiel et les étapes de création d'une ligne de base pour notre projet (également appelée section 1), reportez-vous au premier message.
Ce poste est divisé en trois sections :
- Section 2 : Générer des résumés avec un modèle zéro coup
- Section 3 : Entraîner un modèle de synthèse
- Section 4 : Évaluer le modèle entraîné
Section 2 : Générer des résumés avec un modèle zéro coup
Dans cet article, nous utilisons le concept de apprentissage zéro coup (ZSL), ce qui signifie que nous utilisons un modèle qui a été formé pour résumer le texte, mais qui n'a vu aucun exemple de jeu de données arXiv. C'est un peu comme essayer de peindre un portrait quand tout ce que vous avez fait dans votre vie est la peinture de paysage. Vous savez peindre, mais vous ne connaissez peut-être pas trop les subtilités de la peinture de portrait.
Pour cette section, nous utilisons les éléments suivants cahier.
Pourquoi l'apprentissage zéro coup ?
ZSL est devenu populaire au cours des dernières années car il vous permet d'utiliser des modèles NLP de pointe sans formation. Et leurs performances sont parfois assez étonnantes : les Grand groupe de travail de recherche scientifique a récemment publié son modèle T0pp (prononcé "T Zero Plus Plus"), qui a été formé spécifiquement pour la recherche sur l'apprentissage multitâche zéro coup. Il peut souvent surpasser les modèles six fois plus grands sur le BIG-banc référence, et peut surpasser GPT-3 (16 fois plus grand) sur plusieurs autres benchmarks NLP.
Un autre avantage de ZSL est qu'il ne faut que deux lignes de code pour l'utiliser. En l'essayant, nous créons une deuxième ligne de base, que nous utilisons pour quantifier le gain de performances du modèle après avoir affiné le modèle sur notre ensemble de données.
Mettre en place un pipeline d'apprentissage zéro coup
Pour utiliser les modèles ZSL, nous pouvons utiliser Hugging Face's API de pipeline. Cette API nous permet d'utiliser un modèle de résumé de texte avec seulement deux lignes de code. Il prend en charge les principales étapes de traitement dans un modèle NLP :
- Prétraitez le texte dans un format que le modèle peut comprendre.
- Passez les entrées prétraitées au modèle.
- Post-traitez les prédictions du modèle afin de pouvoir leur donner un sens.
Il utilise les modèles de synthèse déjà disponibles sur le Moyeu de modèle de visage étreignant.
Pour l'utiliser, exécutez le code suivant :
C'est ça! Le code télécharge un modèle de résumé et crée des résumés localement sur votre machine. Si vous vous demandez quel modèle il utilise, vous pouvez soit le rechercher dans le code source ou utilisez la commande suivante :
Lorsque nous exécutons cette commande, nous voyons que le modèle par défaut pour la synthèse de texte s'appelle sshleifer/distilbart-cnn-12-6:
![]()
Nous pouvons trouver le carte modèle pour ce modèle sur le site Web Hugging Face, où l'on peut également voir que le modèle a été formé sur deux ensembles de données : Ensemble de données CNN Dailymail et par Ensemble de données Extreme Summarization (XSum). Il convient de noter que ce modèle n'est pas familier avec l'ensemble de données arXiv et n'est utilisé que pour résumer des textes similaires à ceux sur lesquels il a été formé (principalement des articles de presse). Les nombres 12 et 6 dans le nom du modèle font référence au nombre de couches d'encodeur et de couches de décodeur, respectivement. Expliquer ce que c'est n'entre pas dans le cadre de ce didacticiel, mais vous pouvez en savoir plus à ce sujet dans le post Présentation de BART par Sam Shleifer, qui a créé le modèle.
Nous utilisons le modèle par défaut à l'avenir, mais je vous encourage à essayer différents modèles pré-formés. Tous les modèles qui se prêtent à la synthèse se trouvent sur le Site Web de l'étreinte du visage. Pour utiliser un modèle différent, vous pouvez spécifier le nom du modèle lors de l'appel de l'API Pipeline :
Résumé extractif vs résumé abstrait
Nous n'avons pas encore parlé de deux approches possibles mais différentes du résumé de texte : extractif vs. abstrait. Le résumé extractif est la stratégie consistant à concaténer des extraits tirés d'un texte dans un résumé, tandis que le résumé abstrait consiste à paraphraser le corpus à l'aide de phrases nouvelles. La plupart des modèles de synthèse sont basés sur des modèles qui génèrent du nouveau texte (ce sont des modèles de génération de langage naturel, comme, par exemple, GPT-3). Cela signifie que les modèles de résumé génèrent également du nouveau texte, ce qui en fait des modèles de résumé abstraits.
Générer des résumés instantanés
Maintenant que nous savons comment l'utiliser, nous voulons l'utiliser sur notre jeu de données de test, le même jeu de données que nous avons utilisé dans section 1 pour créer la ligne de base. Nous pouvons le faire avec la boucle suivante :
Nous utilisons les min_length et max_length paramètres pour contrôler le résumé généré par le modèle. Dans cet exemple, nous posons min_length à 5 car nous voulons que le titre contienne au moins cinq mots. Et en estimant les résumés de référence (les titres réels des documents de recherche), nous déterminons que 20 pourrait être une valeur raisonnable pour max_length. Mais encore une fois, ce n'est qu'un premier essai. Lorsque le projet est en phase d'expérimentation, ces deux paramètres peuvent et doivent être modifiés pour voir si les performances du modèle changent.
Paramètres supplémentaires
Si vous êtes déjà familiarisé avec la génération de texte, vous savez peut-être que de nombreux autres paramètres influencent le texte généré par un modèle, tels que la recherche de faisceau, l'échantillonnage et la température. Ces paramètres vous donnent plus de contrôle sur le texte généré, par exemple rendre le texte plus fluide et moins répétitif. Ces techniques ne sont pas disponibles dans l'API Pipeline. Vous pouvez voir dans le code source qui min_length et max_length sont les seuls paramètres pris en compte. Cependant, après avoir formé et déployé notre propre modèle, nous avons accès à ces paramètres. Plus d'informations à ce sujet dans la section 4 de cet article.
Évaluation du modèle
Une fois que nous avons généré les résumés zéro-shot, nous pouvons à nouveau utiliser notre fonction ROUGE pour comparer les résumés candidats avec les résumés de référence :
L'exécution de ce calcul sur les résumés qui ont été générés avec le modèle ZSL nous donne les résultats suivants :
![]()
Lorsque nous comparons ceux-ci avec notre ligne de base, nous constatons que ce modèle ZSL est en fait moins performant que notre heuristique simple consistant à ne prendre que la première phrase. Encore une fois, ce n'est pas inattendu : bien que ce modèle sache comment résumer des articles de presse, il n'a jamais vu un exemple de résumé d'un résumé d'un article de recherche universitaire.
Comparaison de référence
Nous avons maintenant créé deux lignes de base : une utilisant une heuristique simple et une avec un modèle ZSL. En comparant les scores ROUGE, nous voyons que l'heuristique simple surpasse actuellement le modèle d'apprentissage en profondeur.
![]()
Dans la section suivante, nous prenons ce même modèle d'apprentissage en profondeur et essayons d'améliorer ses performances. Pour ce faire, nous l'entraînons sur le jeu de données arXiv (cette étape est également appelée réglage fin). On profite du fait qu'il sait déjà résumer du texte en général. Nous lui montrons ensuite de nombreux exemples de notre jeu de données arXiv. Les modèles d'apprentissage en profondeur sont exceptionnellement efficaces pour identifier les modèles dans les ensembles de données après leur formation, nous nous attendons donc à ce que le modèle s'améliore dans cette tâche particulière.
Section 3 : Entraîner un modèle de synthèse
Dans cette section, nous entraînons le modèle que nous avons utilisé pour les résumés zéro-shot dans la section 2 (sshleifer/distilbart-cnn-12-6) sur notre jeu de données. L'idée est d'enseigner au modèle à quoi ressemblent les résumés de résumés d'articles de recherche en lui montrant de nombreux exemples. Au fil du temps, le modèle devrait reconnaître les modèles de cet ensemble de données, ce qui lui permettra de créer de meilleurs résumés.
Il convient de noter une fois de plus que si vous avez des données étiquetées, à savoir des textes et des résumés correspondants, vous devez les utiliser pour former un modèle. Ce n'est qu'ainsi que le modèle peut apprendre les modèles de votre jeu de données spécifique.
Le code complet pour la formation du modèle est dans ce qui suit cahier.
Configurer une tâche de formation
Parce que la formation d'un modèle d'apprentissage en profondeur prendrait quelques semaines sur un ordinateur portable, nous utilisons Amazon Sage Maker emplois de formation à la place. Pour plus de détails, reportez-vous à Former un modèle avec Amazon SageMaker. Dans cet article, je souligne brièvement l'avantage d'utiliser ces tâches d'entraînement, outre le fait qu'elles nous permettent d'utiliser des instances de calcul GPU.
Supposons que nous ayons un cluster d'instances GPU que nous pouvons utiliser. Dans ce cas, nous souhaitons probablement créer une image Docker pour exécuter la formation afin de pouvoir facilement répliquer l'environnement de formation sur d'autres machines. Nous installons ensuite les packages requis et, comme nous souhaitons utiliser plusieurs instances, nous devons également mettre en place une formation distribuée. Lorsque la formation est terminée, nous souhaitons éteindre rapidement ces ordinateurs car ils sont coûteux.
Toutes ces étapes sont abstraites loin de nous lors de l'utilisation des emplois de formation. En fait, nous pouvons former un modèle de la même manière que celle décrite en spécifiant les paramètres de formation, puis en appelant simplement une méthode. SageMaker s'occupe du reste, y compris l'arrêt des instances GPU lorsque la formation est terminée afin de ne pas engager de frais supplémentaires.
De plus, Hugging Face et AWS ont annoncé un partenariat plus tôt en 2022 qui facilite encore plus la formation des modèles Hugging Face sur SageMaker. Cette fonctionnalité est disponible via le développement de Hugging Face Conteneurs AWS Deep Learning (DLC). Ces conteneurs incluent Hugging Face Transformers, Tokenizers et la bibliothèque Datasets, ce qui nous permet d'utiliser ces ressources pour les tâches de formation et d'inférence. Pour une liste des images DLC disponibles, voir disponible Images de conteneurs d'apprentissage en profondeur. Ils sont maintenus et régulièrement mis à jour avec des correctifs de sécurité. Nous pouvons trouver de nombreux exemples de la façon de former des modèles de visage étreignant avec ces DLC et le Kit de développement logiciel Python pour étreindre le visage dans ce qui suit GitHub repo.
Nous utilisons l'un de ces exemples comme modèle car il fait presque tout ce dont nous avons besoin pour notre objectif : former un modèle de synthèse sur un jeu de données spécifique de manière distribuée (en utilisant plusieurs instances GPU).
Une chose, cependant, nous devons tenir compte du fait que cet exemple utilise un jeu de données directement à partir du hub de jeu de données Hugging Face. Étant donné que nous souhaitons fournir nos propres données personnalisées, nous devons modifier légèrement le bloc-notes.
Transmettre les données à la tâche d'entraînement
Pour tenir compte du fait que nous apportons notre propre ensemble de données, nous devons utiliser Voies. Pour plus d'informations, reportez-vous à Comment Amazon SageMaker fournit des informations sur la formation.
Personnellement, je trouve ce terme un peu déroutant, donc dans mon esprit, je pense toujours cartographie quand j'entends Voies, car cela m'aide à mieux visualiser ce qui se passe. Laissez-moi vous expliquer : comme nous l'avons déjà appris, le travail de formation fait tourner un groupe de Cloud de calcul élastique Amazon (Amazon EC2) et copie une image Docker dessus. Cependant, nos ensembles de données sont stockés dans Service de stockage simple Amazon (Amazon S3) et n'est pas accessible par cette image Docker. Au lieu de cela, la tâche de formation doit copier les données d'Amazon S3 vers un fichier prédéfini.
ined chemin localement dans cette image Docker. Pour ce faire, nous indiquons à la tâche de formation où les données résident dans Amazon S3 et où sur l'image Docker les données doivent être copiées afin que la tâche de formation puisse y accéder. Nous Localisation l'emplacement Amazon S3 avec le chemin local.
Nous définissons le chemin local dans la section des hyperparamètres de la tâche d'entraînement :
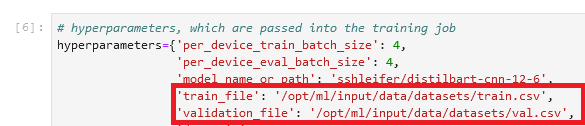
Ensuite, nous indiquons à la tâche d'entraînement où les données résident dans Amazon S3 lors de l'appel de la méthode fit(), qui démarre l'entraînement :
![]()
Notez que le nom du dossier après /opt/ml/input/data correspond au nom de la chaîne (datasets). Cela permet à la tâche de formation de copier les données d'Amazon S3 vers le chemin local.
Commencer la formation
Nous sommes maintenant prêts à commencer le travail de formation. Comme mentionné précédemment, nous le faisons en appelant le fit() méthode. La tâche d'entraînement dure environ 40 minutes. Vous pouvez suivre la progression et voir des informations supplémentaires sur la console SageMaker.
![]()
Lorsque le travail de formation est terminé, il est temps d'évaluer notre modèle nouvellement formé.
Section 4 : Évaluer le modèle entraîné
L'évaluation de notre modèle formé est très similaire à ce que nous avons fait dans la section 2, où nous avons évalué le modèle ZSL. Nous appelons le modèle et générons des résumés candidats et les comparons aux résumés de référence en calculant les scores ROUGE. Mais maintenant, le modèle se trouve dans Amazon S3 dans un fichier appelé model.tar.gz (pour trouver l'emplacement exact, vous pouvez vérifier le travail de formation sur la console). Alors, comment accéder au modèle pour générer des résumés ?
Nous avons deux options : déployer le modèle sur un point de terminaison SageMaker ou le télécharger localement, comme nous l'avons fait dans la section 2 avec le modèle ZSL. Dans ce tutoriel, j'ai déployer le modèle sur un point de terminaison SageMaker car c'est plus pratique et en choisissant une instance plus puissante pour le point de terminaison, nous pouvons réduire considérablement le temps d'inférence. Le dépôt GitHub contient un cahier qui montre comment évaluer le modèle localement.
Déployer un modèle
Il est généralement très facile de déployer un modèle entraîné sur SageMaker (voir à nouveau l'exemple suivant sur GitHub de Visage étreignant). Une fois le modèle formé, nous pouvons appeler estimator.deploy() et SageMaker fait le reste pour nous en arrière-plan. Parce que dans notre tutoriel nous passons d'un notebook à l'autre, nous devons d'abord localiser la tâche d'entraînement et le modèle associé, avant de pouvoir le déployer :
![]()
Après avoir récupéré l'emplacement du modèle, nous pouvons le déployer sur un point de terminaison SageMaker :
Le déploiement sur SageMaker est simple car il utilise le Boîte à outils d'inférence de visage étreignant SageMaker, une bibliothèque open source pour servir les modèles Transformers sur SageMaker. Normalement, nous n'avons même pas besoin de fournir un script d'inférence ; la boîte à outils s'en charge. Dans ce cas, cependant, la boîte à outils utilise à nouveau l'API Pipeline, et comme nous l'avons vu dans la section 2, l'API Pipeline ne nous permet pas d'utiliser des techniques avancées de génération de texte telles que la recherche de faisceau et l'échantillonnage. Pour éviter cette limitation, nous fournissons notre script d'inférence personnalisé.
Première évaluation
Pour la première évaluation de notre modèle nouvellement formé, nous utilisons les mêmes paramètres que dans la section 2 avec le modèle zéro-shot pour générer les résumés candidats. Cela permet de faire une comparaison pomme à pomme :
Nous comparons les résumés générés par le modèle avec les résumés de référence :
![]()
C'est encourageant ! Notre première tentative d'entraînement du modèle, sans aucun réglage d'hyperparamètre, a considérablement amélioré les scores ROUGE.
![]()
Deuxième évaluation
Il est maintenant temps d'utiliser des techniques plus avancées telles que la recherche de faisceau et l'échantillonnage pour jouer avec le modèle. Pour une explication détaillée de ce que fait chacun de ces paramètres, reportez-vous à Comment générer du texte : utiliser différentes méthodes de décodage pour la génération de langage avec Transformers. Essayons avec un ensemble semi-aléatoire de valeurs pour certains de ces paramètres :
Lors de l'exécution de notre modèle avec ces paramètres, nous obtenons les scores suivants :
![]()
Cela n'a pas fonctionné tout à fait comme nous l'espérions - les scores ROUGE ont en fait légèrement baissé. Cependant, ne laissez pas cela vous décourager d'essayer différentes valeurs pour ces paramètres. En fait, c'est le point où nous terminons la phase de configuration et passons à la phase d'expérimentation du projet.
Conclusion et prochaines étapes
Nous avons terminé la mise en place de la phase d'expérimentation. Dans cette série en deux parties, nous avons téléchargé et préparé nos données, créé une ligne de base avec une heuristique simple, créé une autre ligne de base à l'aide de l'apprentissage à tir zéro, puis formé notre modèle et constaté une augmentation significative des performances. Il est maintenant temps de jouer avec chaque partie que nous avons créée afin de créer des résumés encore meilleurs. Considérer ce qui suit:
- Prétraitez correctement les données – Par exemple, supprimez les mots vides et la ponctuation. Ne sous-estimez pas cette partie : dans de nombreux projets de science des données, le prétraitement des données est l'un des aspects les plus importants (sinon le plus important), et les scientifiques des données consacrent généralement la majeure partie de leur temps à cette tâche.
- Essayez différents modèles – Dans notre tutoriel, nous avons utilisé le modèle standard de résumé (
sshleifer/distilbart-cnn-12-6), Mais beaucoup plus de modèles sont disponibles que vous pouvez utiliser pour cette tâche. L'un d'entre eux pourrait mieux correspondre à votre cas d'utilisation. - Effectuer un réglage des hyperparamètres – Lors de la formation du modèle, nous avons utilisé un certain ensemble d'hyperparamètres (taux d'apprentissage, nombre d'époques, etc.). Ces paramètres ne sont pas figés, bien au contraire. Vous devez modifier ces paramètres pour comprendre comment ils affectent les performances de votre modèle.
- Utiliser différents paramètres pour la génération de texte – Nous avons déjà effectué une série de créations de résumés avec différents paramètres pour utiliser la recherche de faisceau et l'échantillonnage. Essayez différentes valeurs et paramètres. Pour plus d'informations, reportez-vous à Comment générer du texte : utiliser différentes méthodes de décodage pour la génération de langage avec Transformers.
J'espère que vous êtes arrivé à la fin et que vous avez trouvé ce tutoriel utile.
À propos de l’auteur
![]() Heiko Hotz est architecte de solutions senior pour l'IA et l'apprentissage automatique et dirige la communauté de traitement du langage naturel (NLP) au sein d'AWS. Avant d'occuper ce poste, il était responsable de la science des données pour le service client européen d'Amazon. Heiko aide nos clients à réussir leur parcours IA/ML sur AWS et a travaillé avec des organisations de nombreux secteurs, notamment l'assurance, les services financiers, les médias et le divertissement, la santé, les services publics et la fabrication. Pendant son temps libre, Heiko voyage autant que possible.
Heiko Hotz est architecte de solutions senior pour l'IA et l'apprentissage automatique et dirige la communauté de traitement du langage naturel (NLP) au sein d'AWS. Avant d'occuper ce poste, il était responsable de la science des données pour le service client européen d'Amazon. Heiko aide nos clients à réussir leur parcours IA/ML sur AWS et a travaillé avec des organisations de nombreux secteurs, notamment l'assurance, les services financiers, les médias et le divertissement, la santé, les services publics et la fabrication. Pendant son temps libre, Heiko voyage autant que possible.
- Coinsmart. Le meilleur échange Bitcoin et Crypto d'Europe.
- Platoblockchain. Intelligence métaverse Web3. Connaissance amplifiée. ACCÈS LIBRE.
- CryptoHawk. Radar Altcoins. Essai gratuit.
- Source : https://aws.amazon.com/blogs/machine-learning/part-2-set-up-a-text-summarization-project-with-hugging-face-transformers/

